Downloaded 26 times


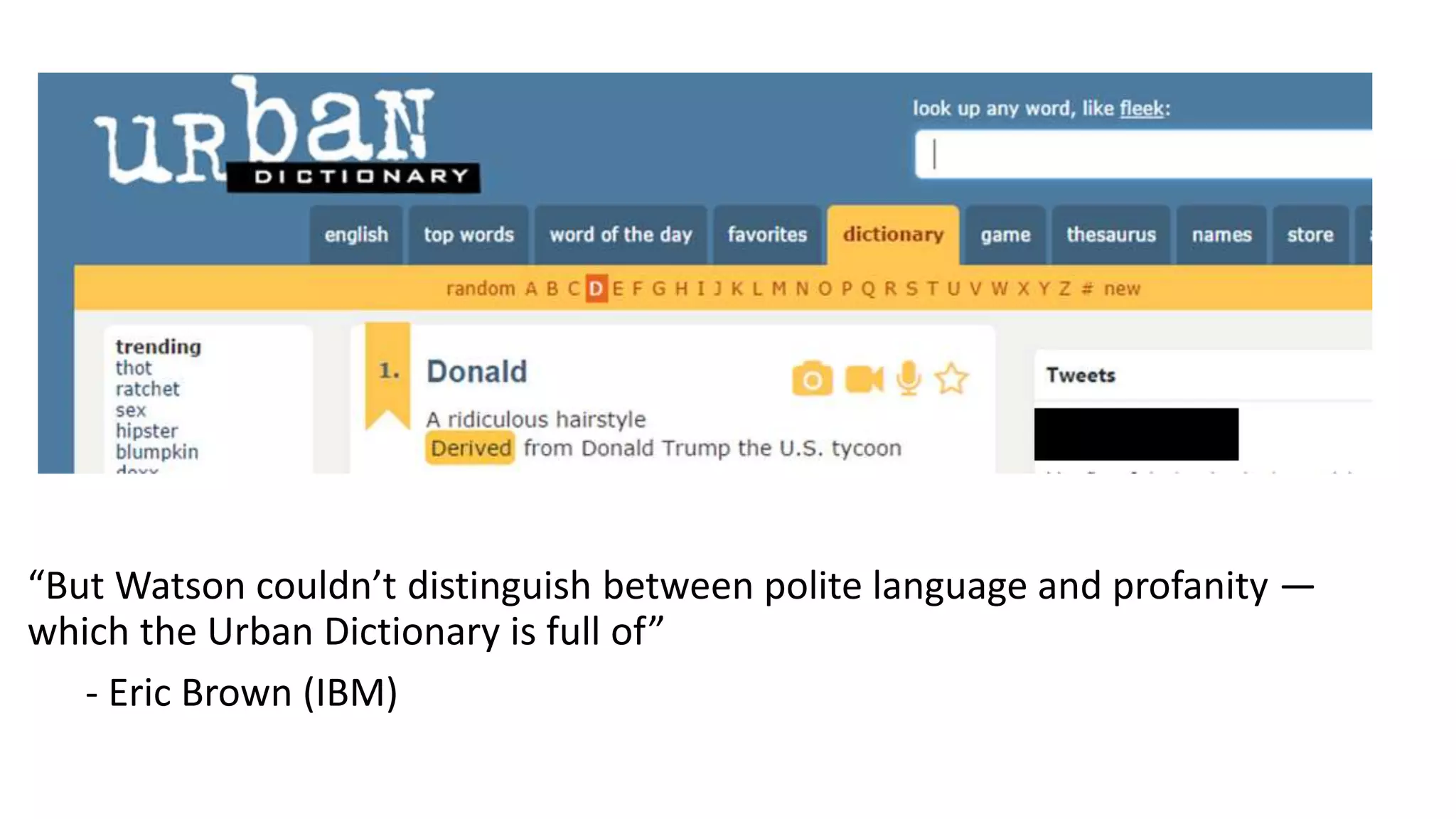



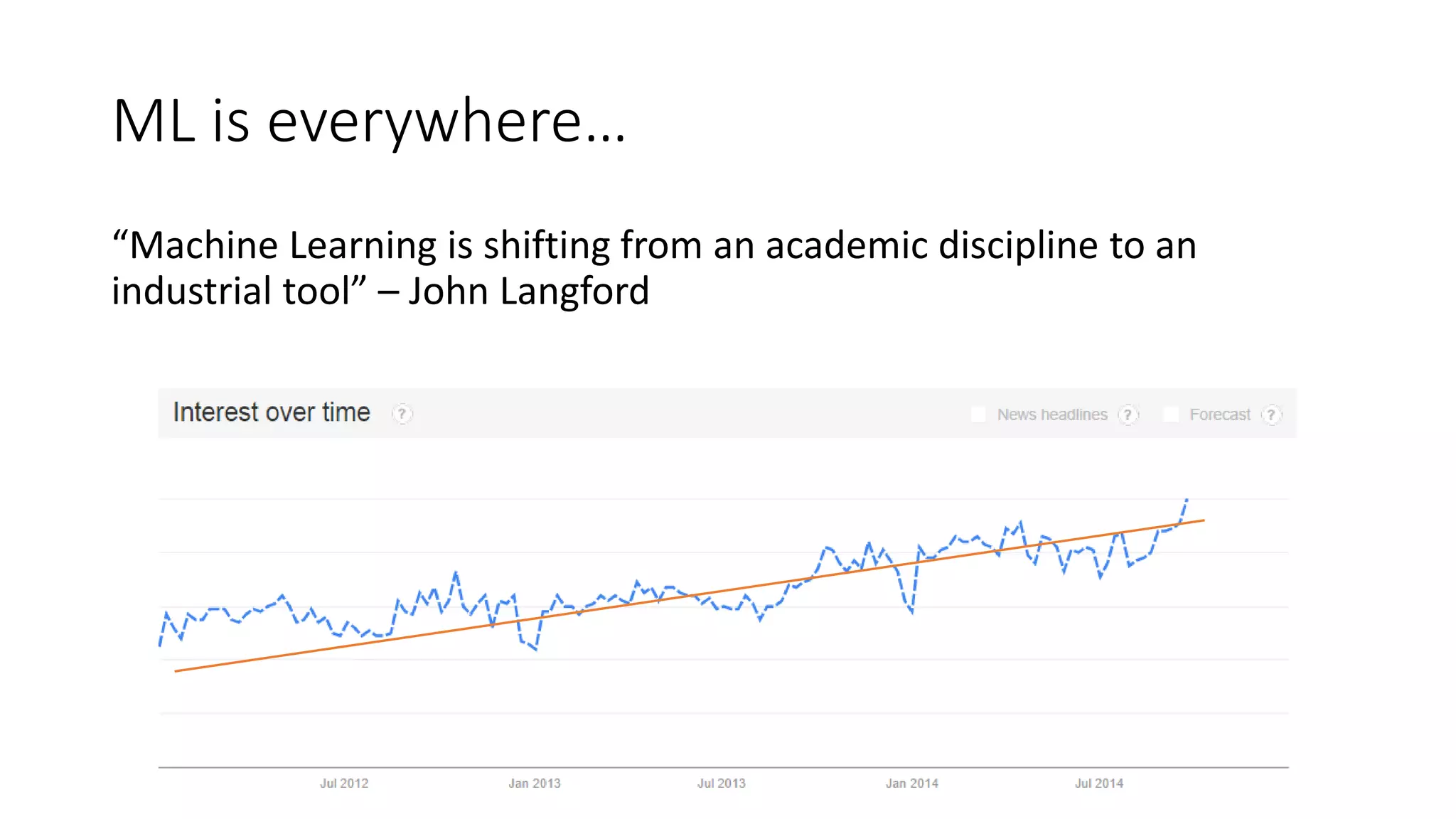

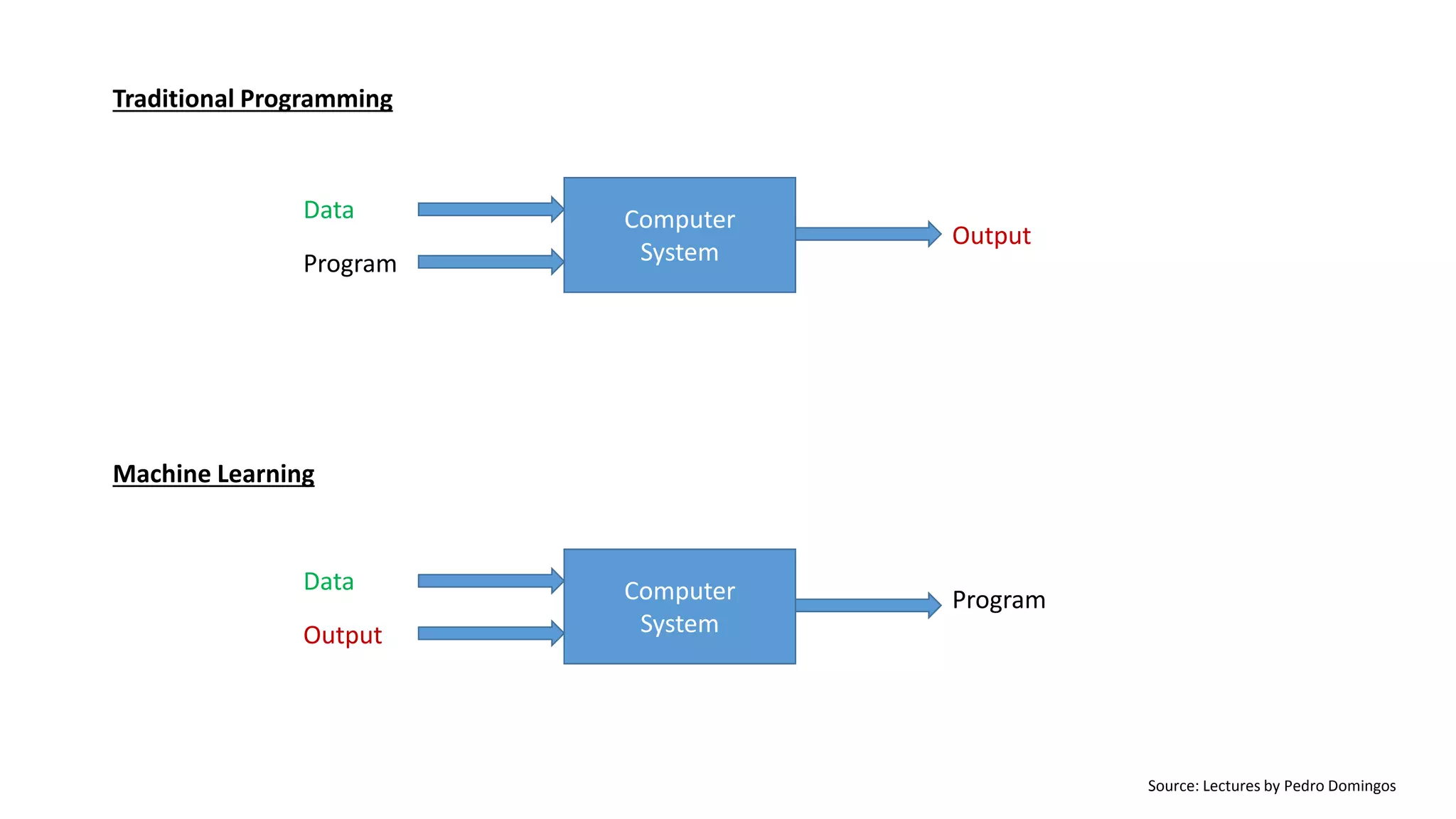
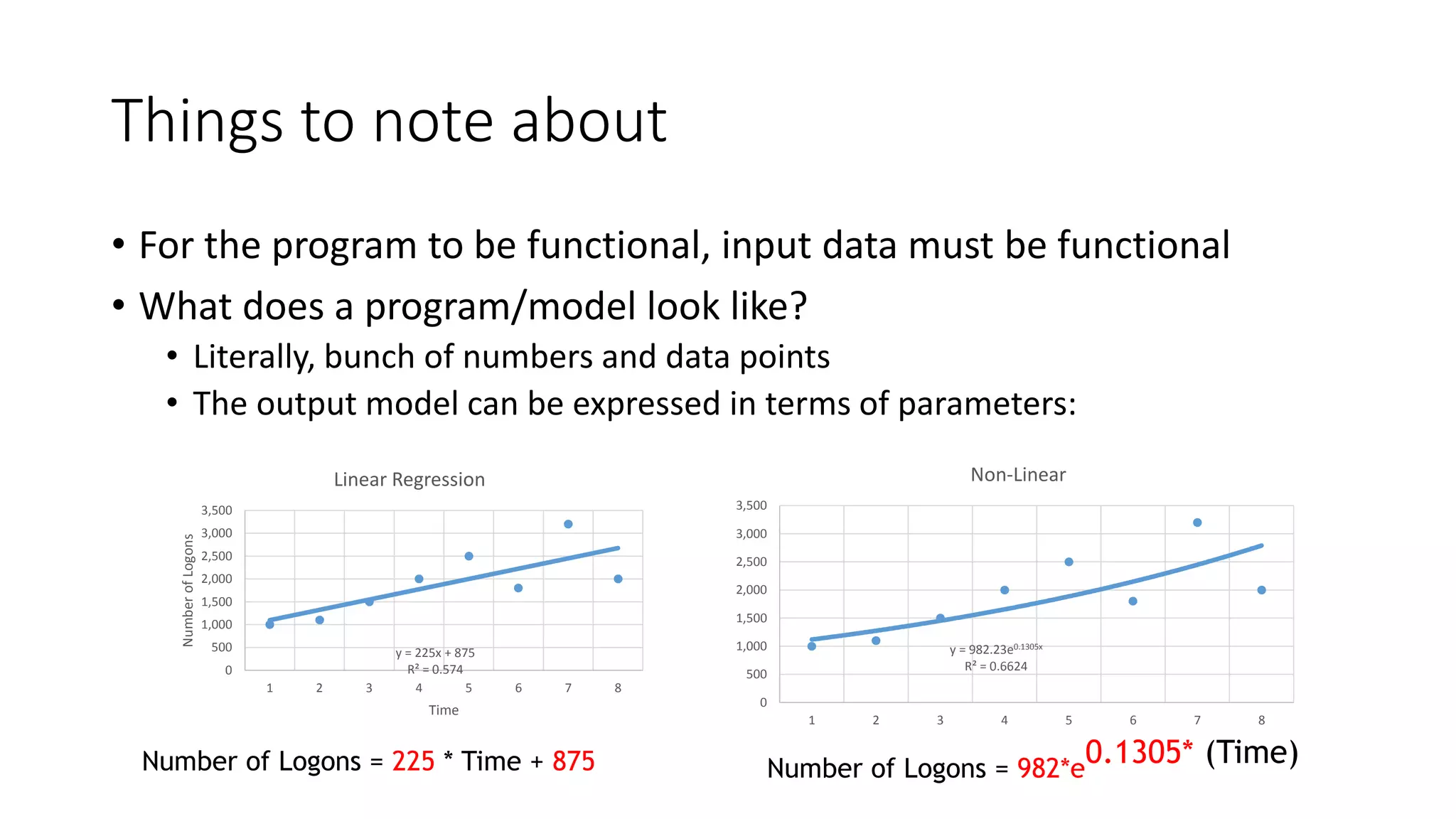

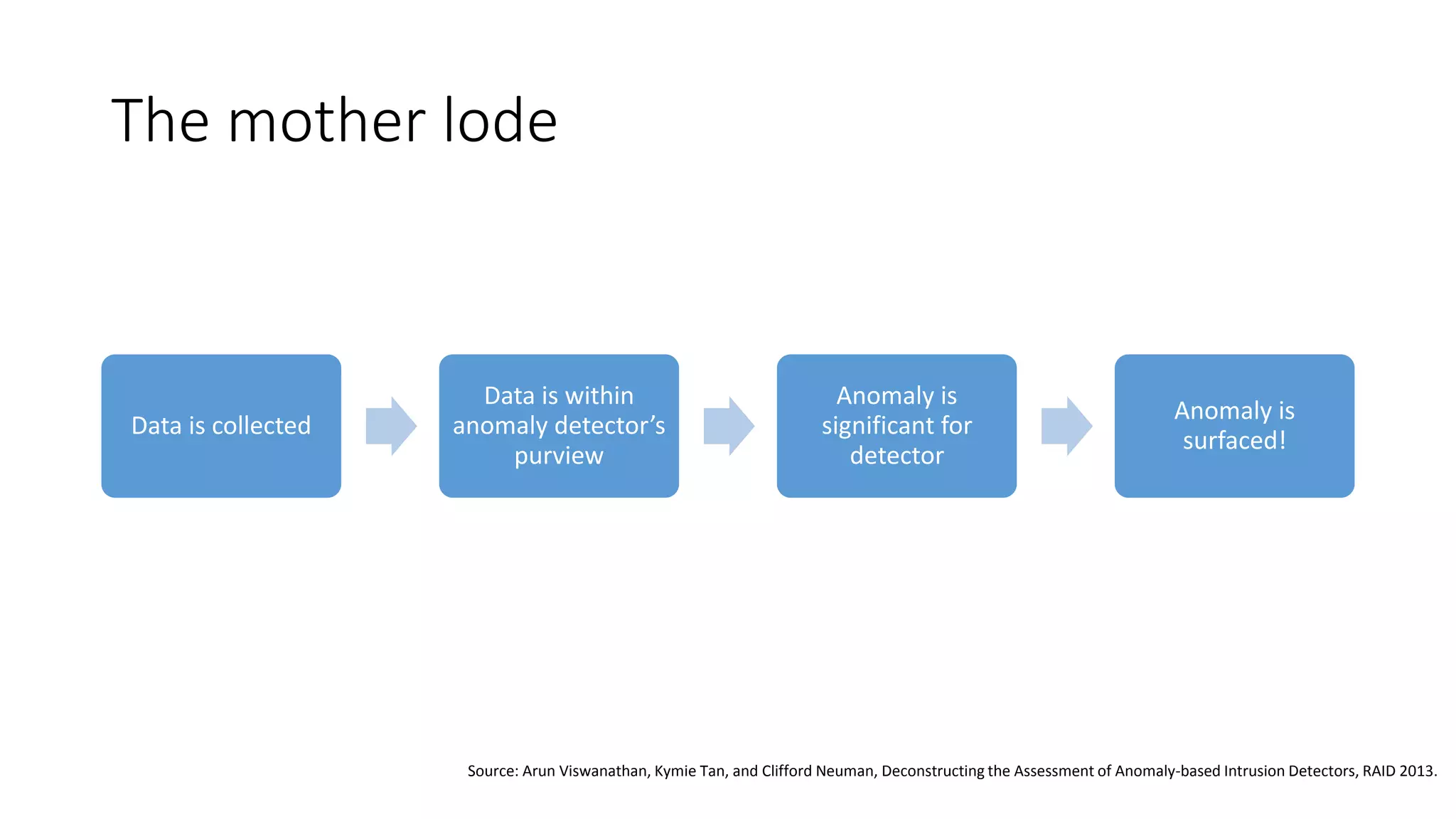








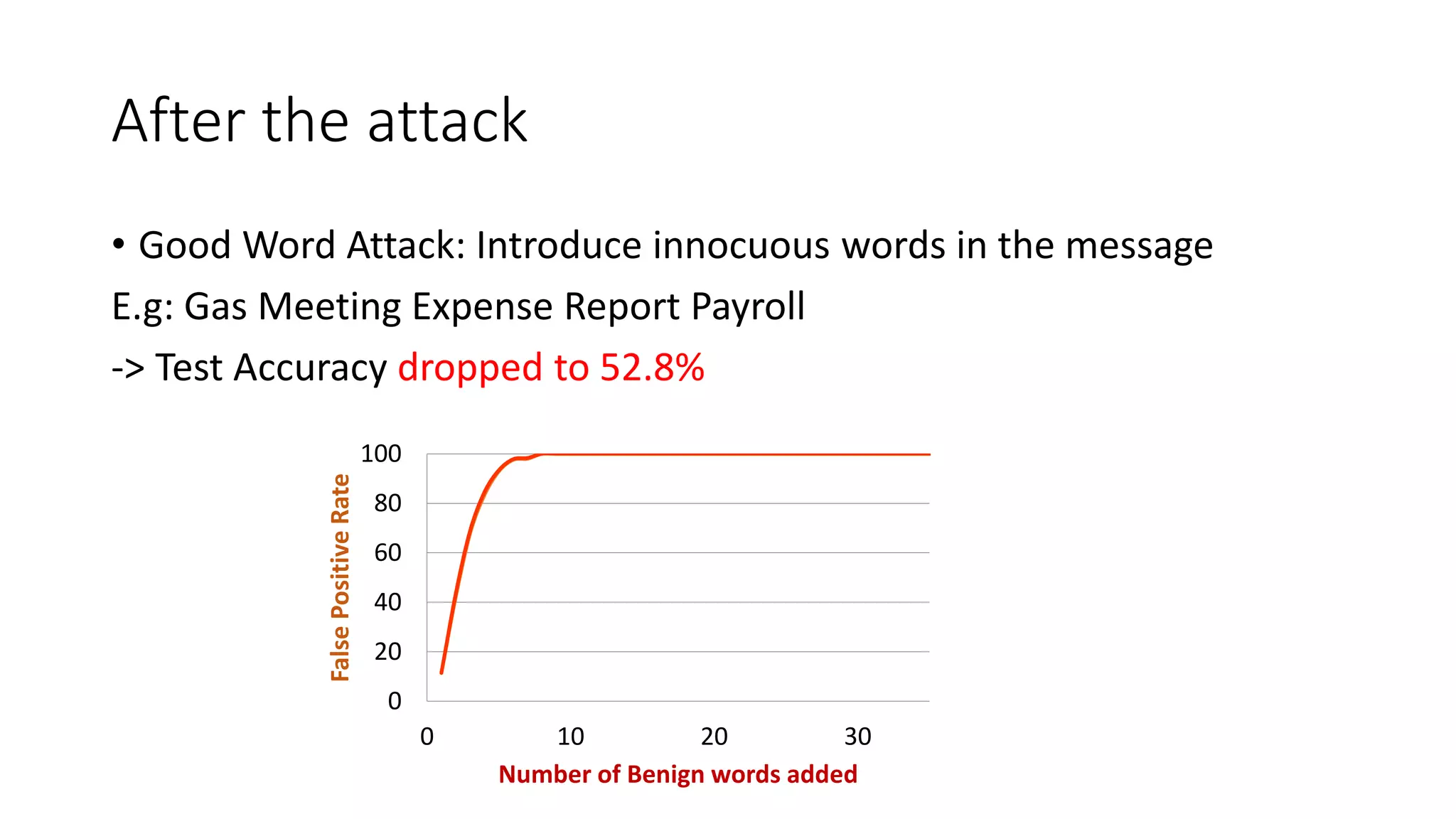


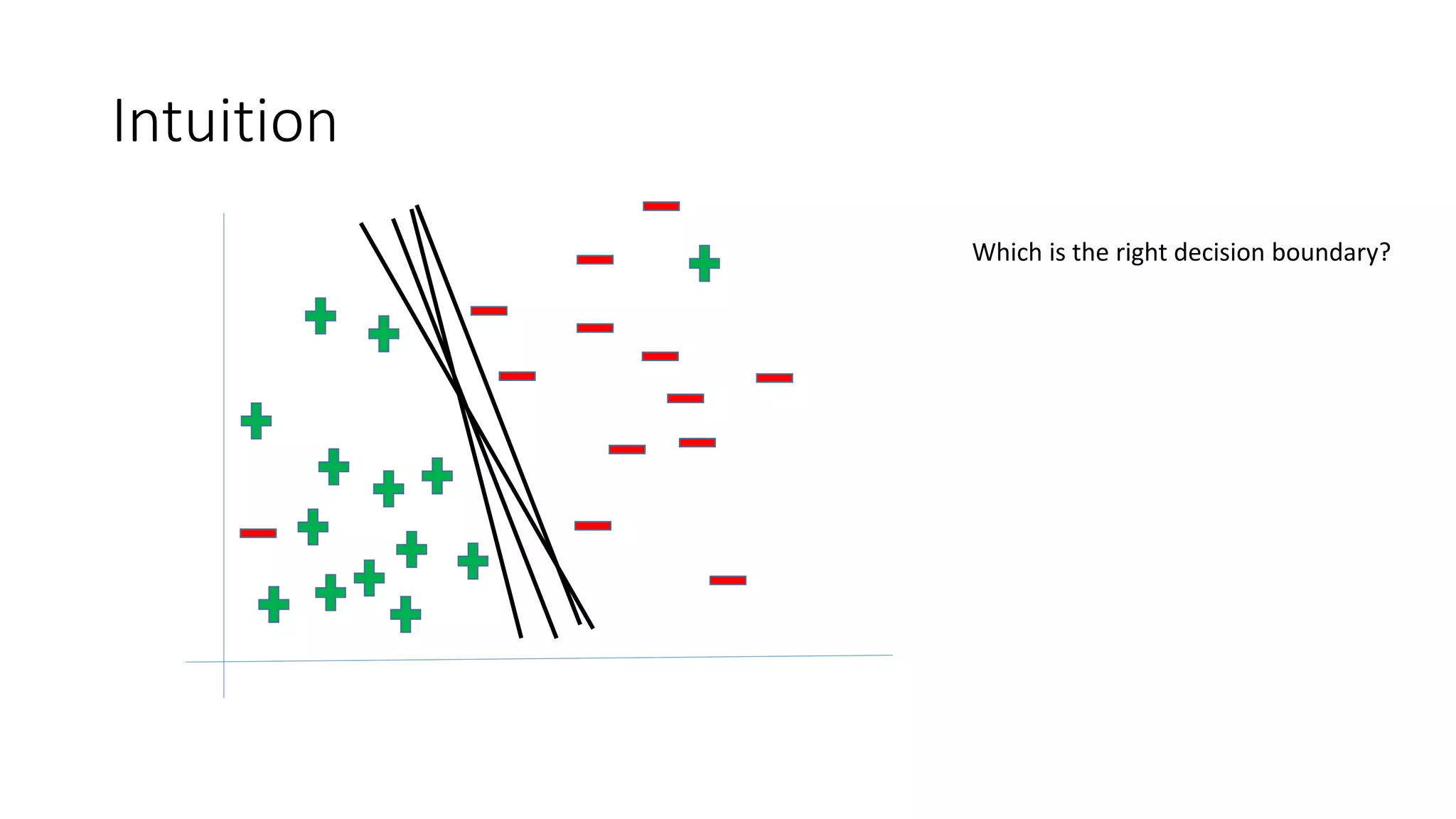
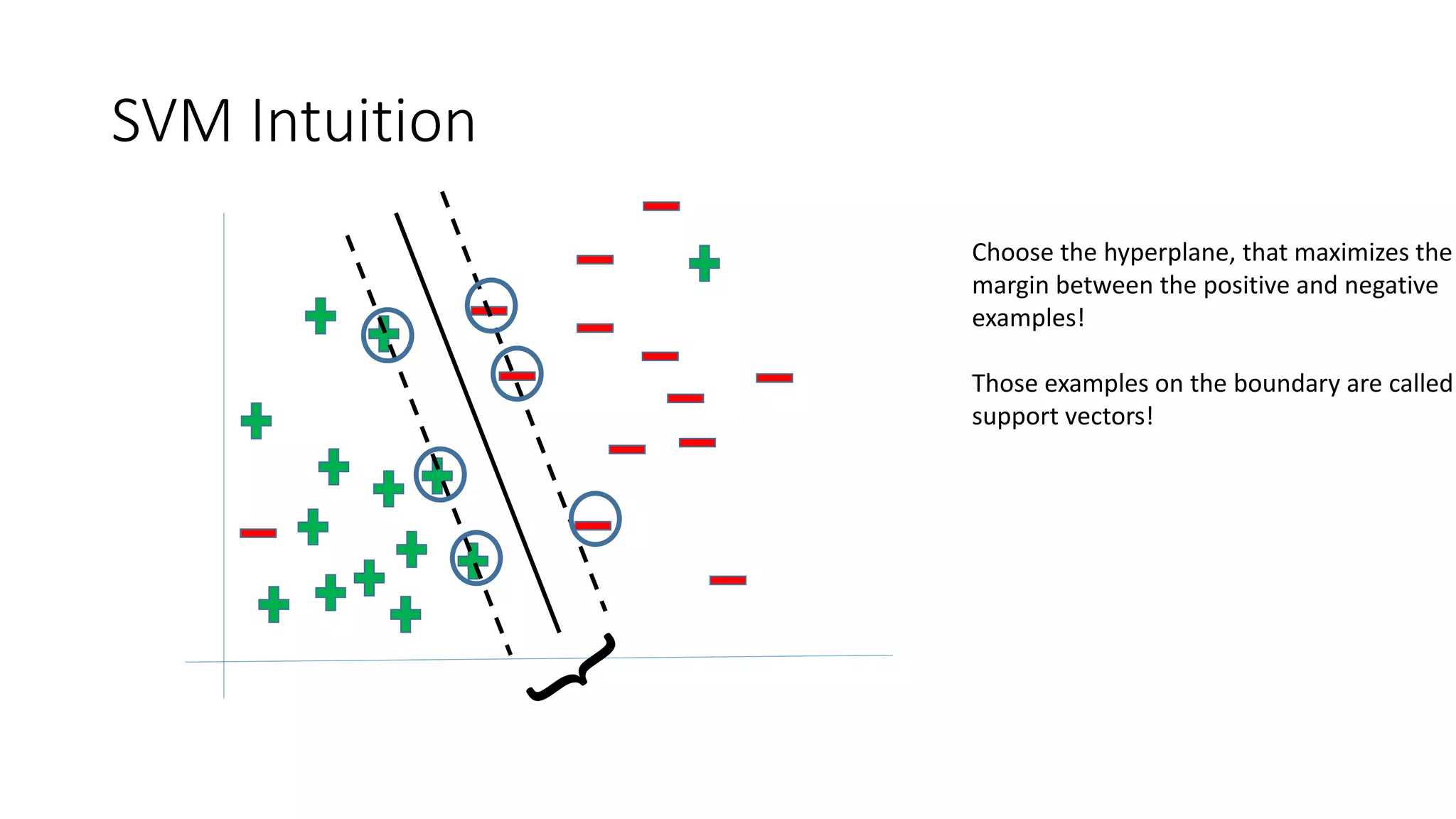



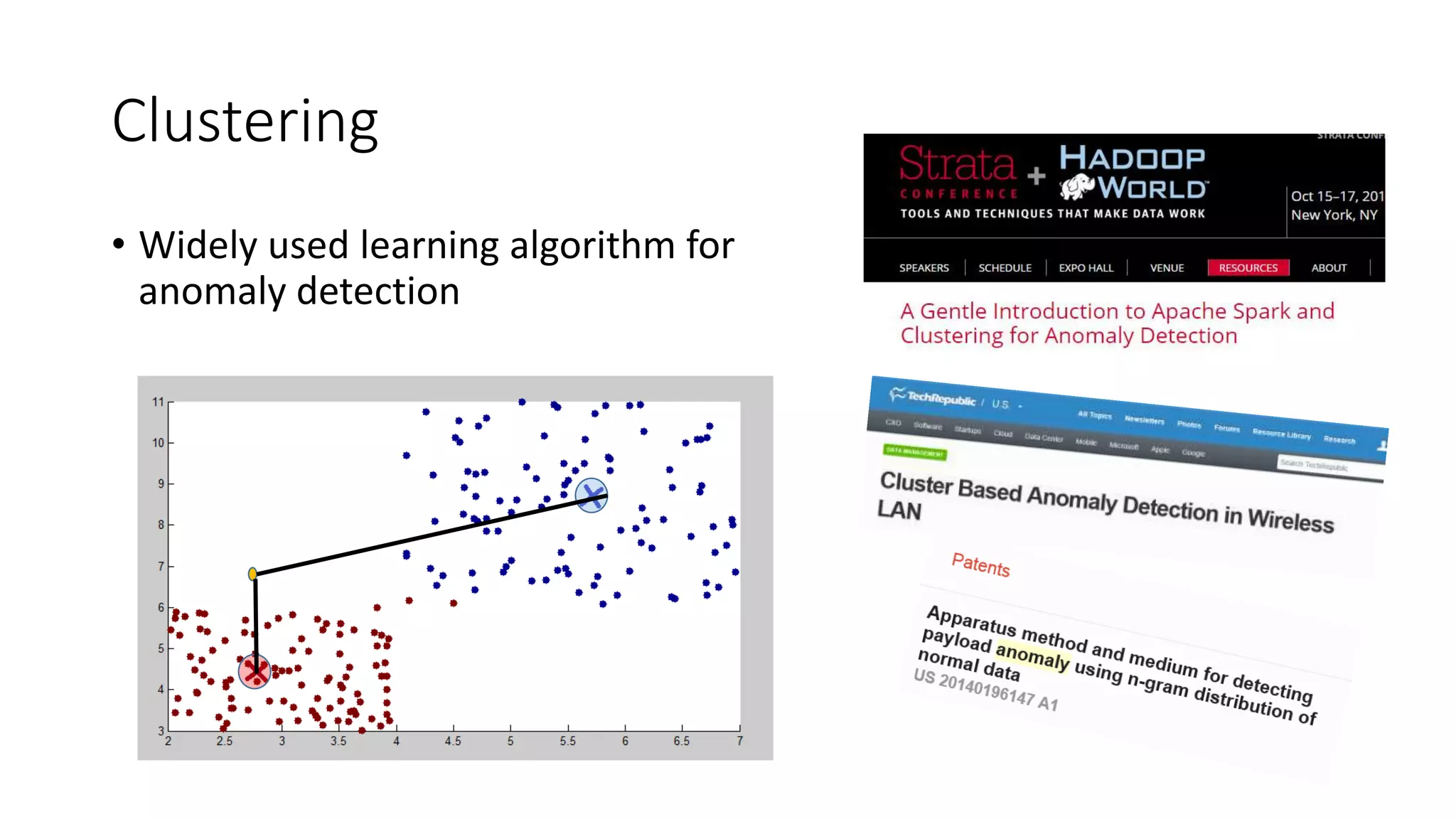
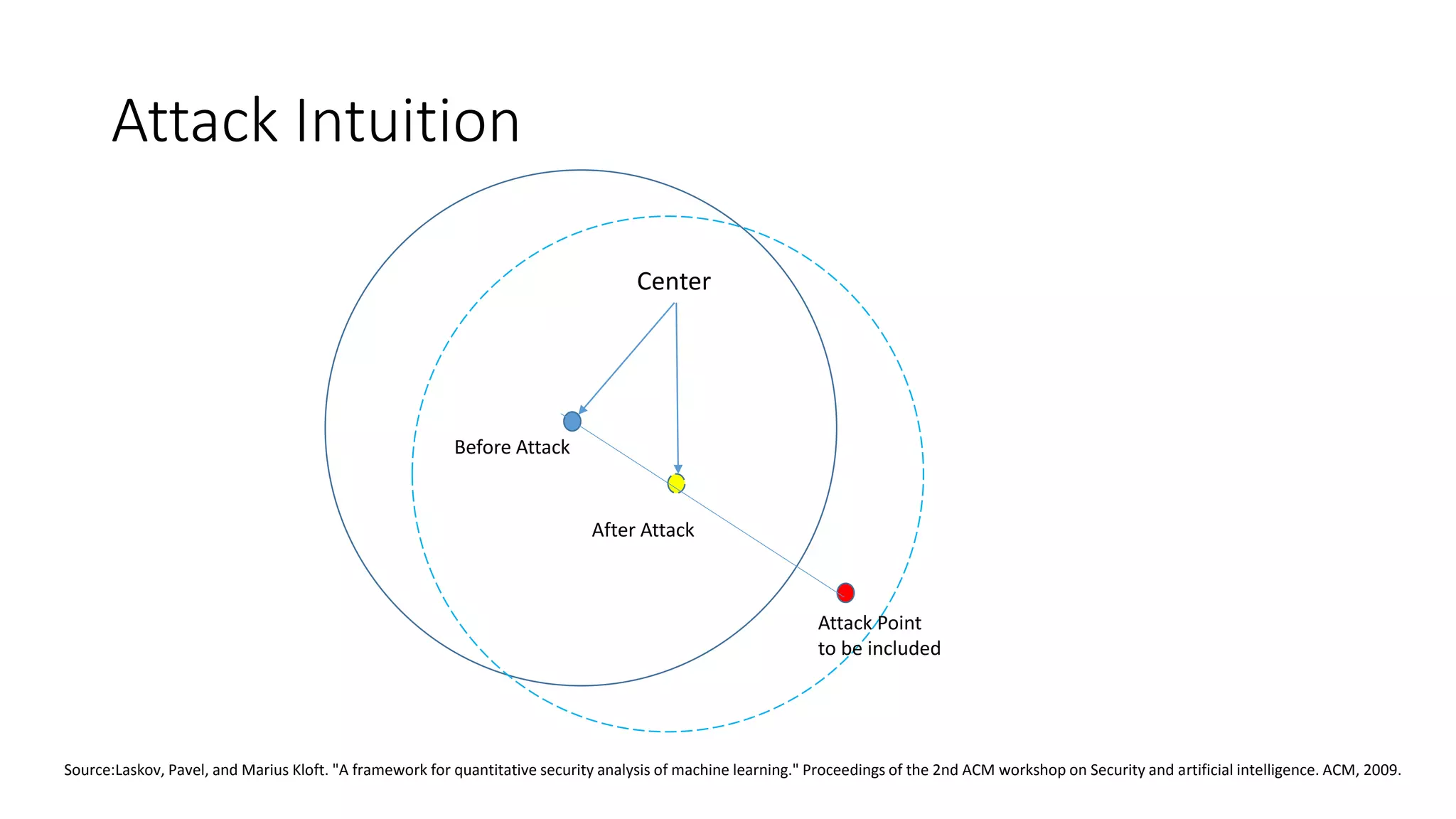
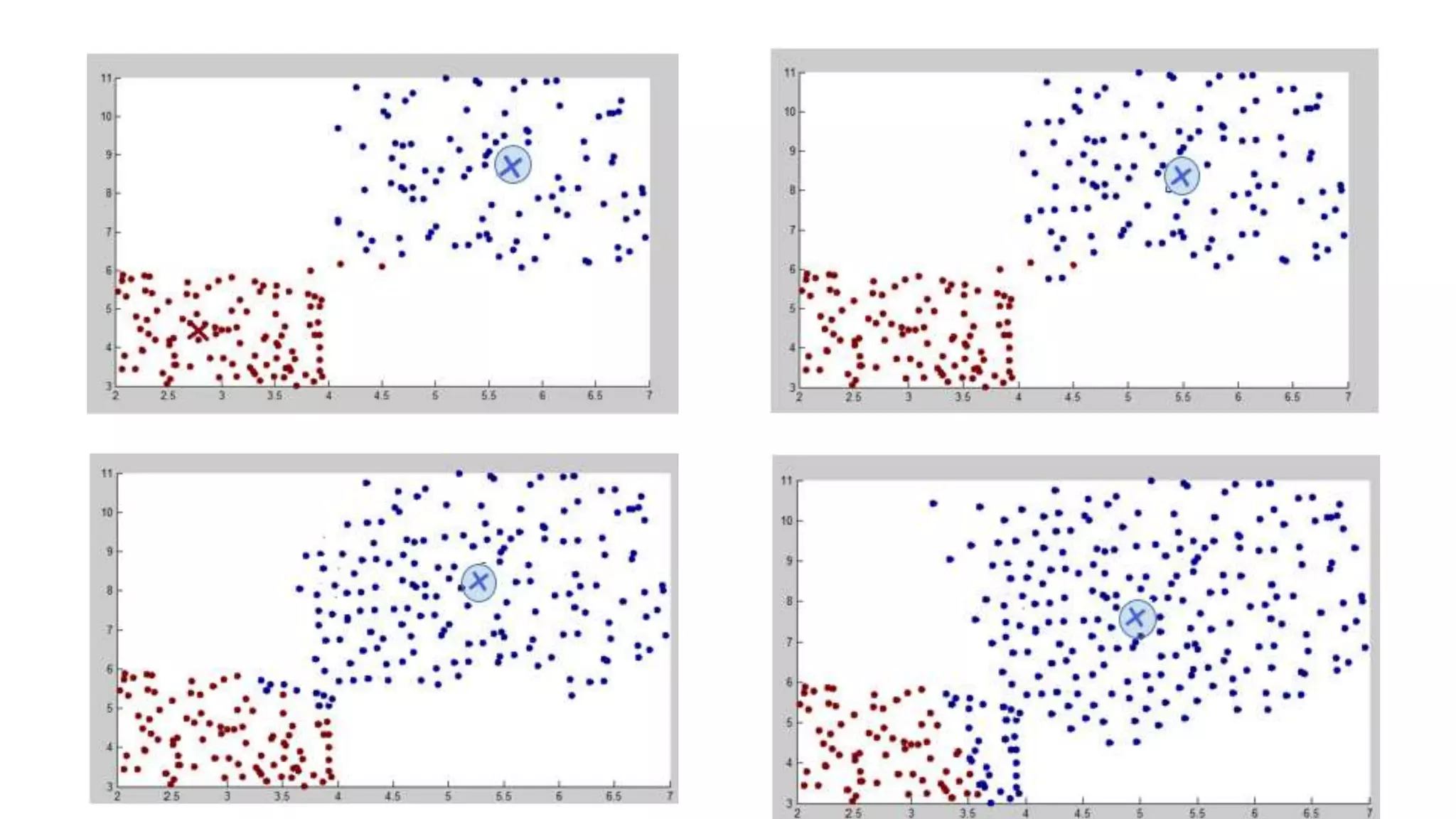



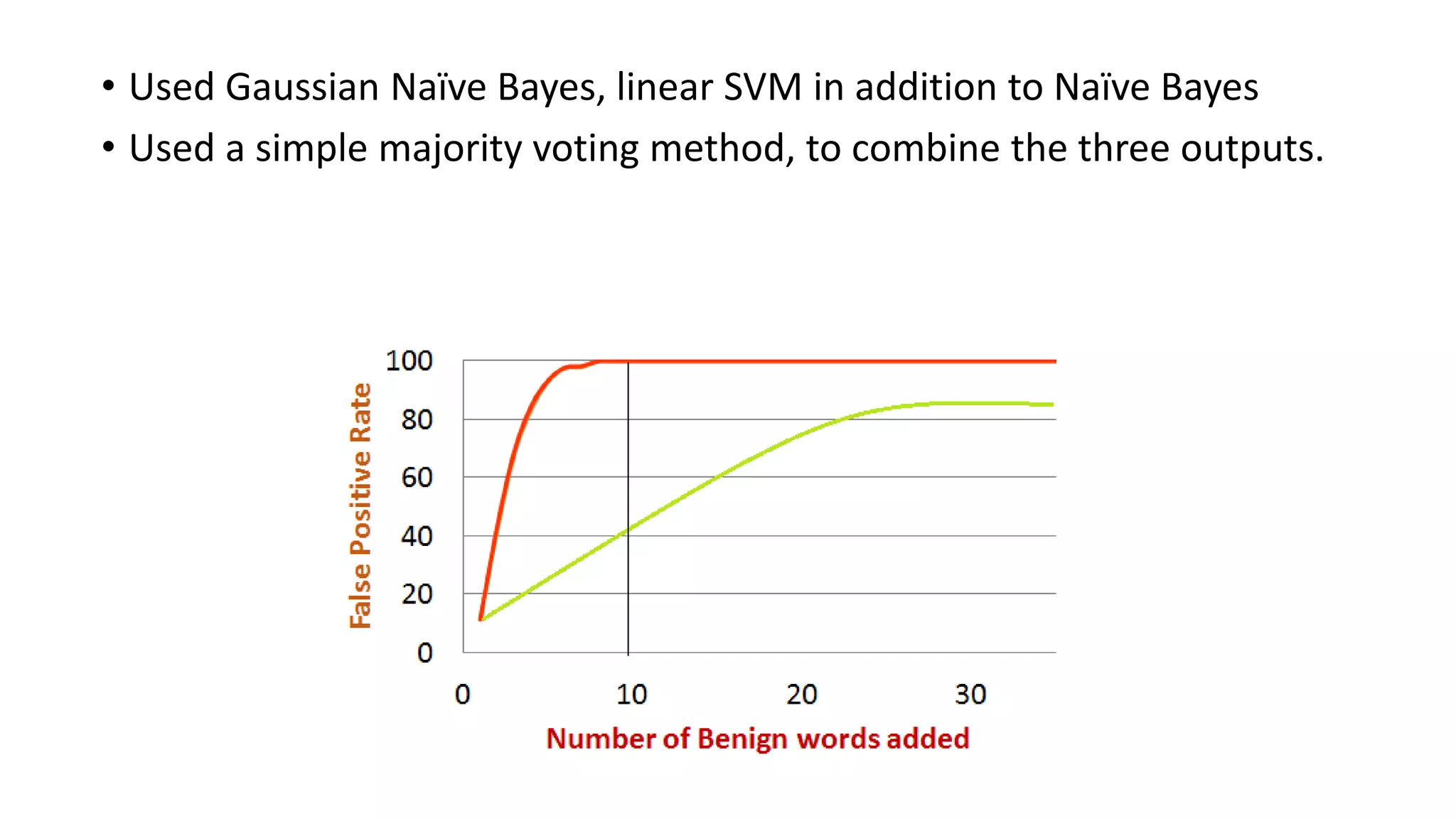
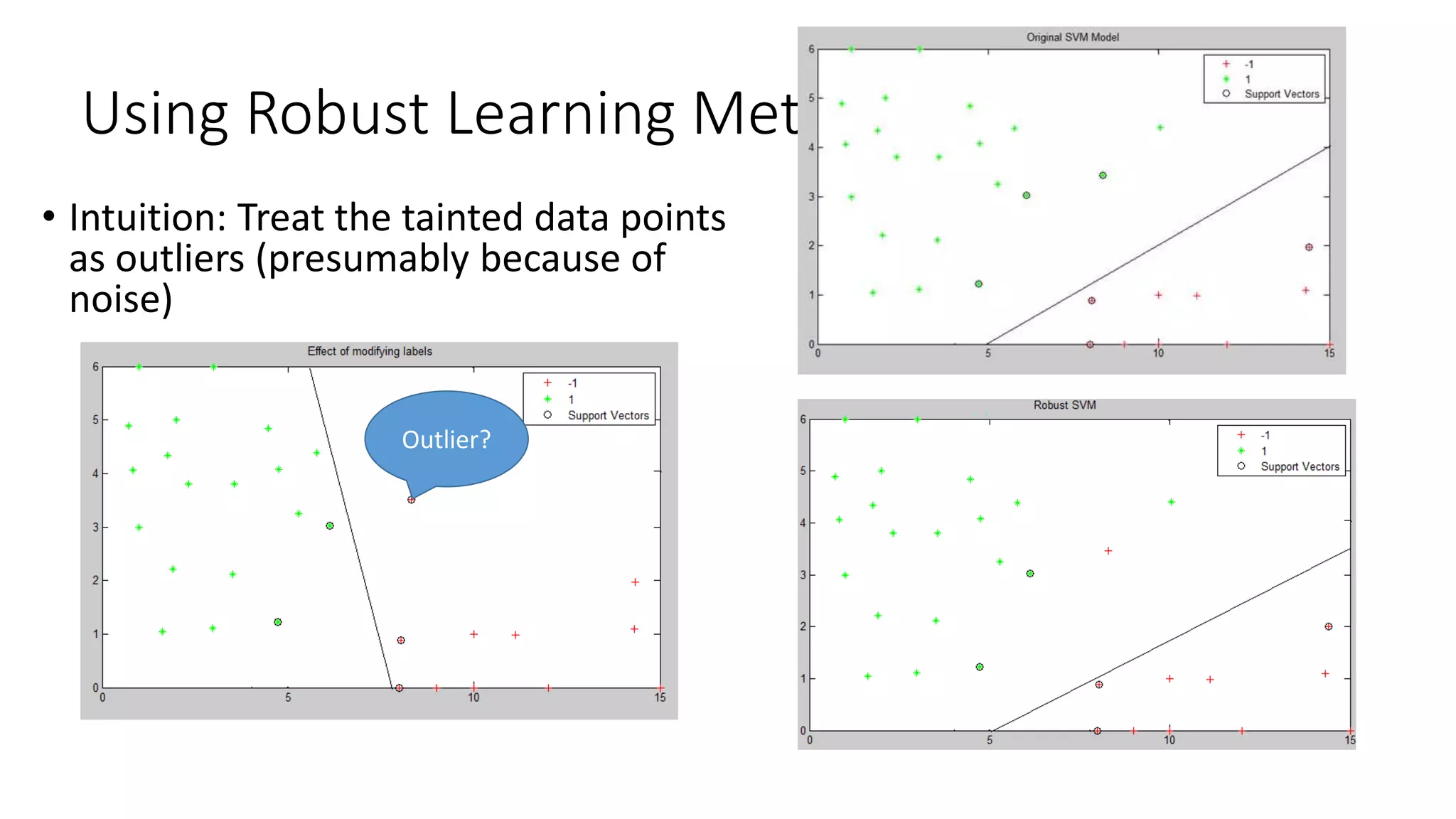
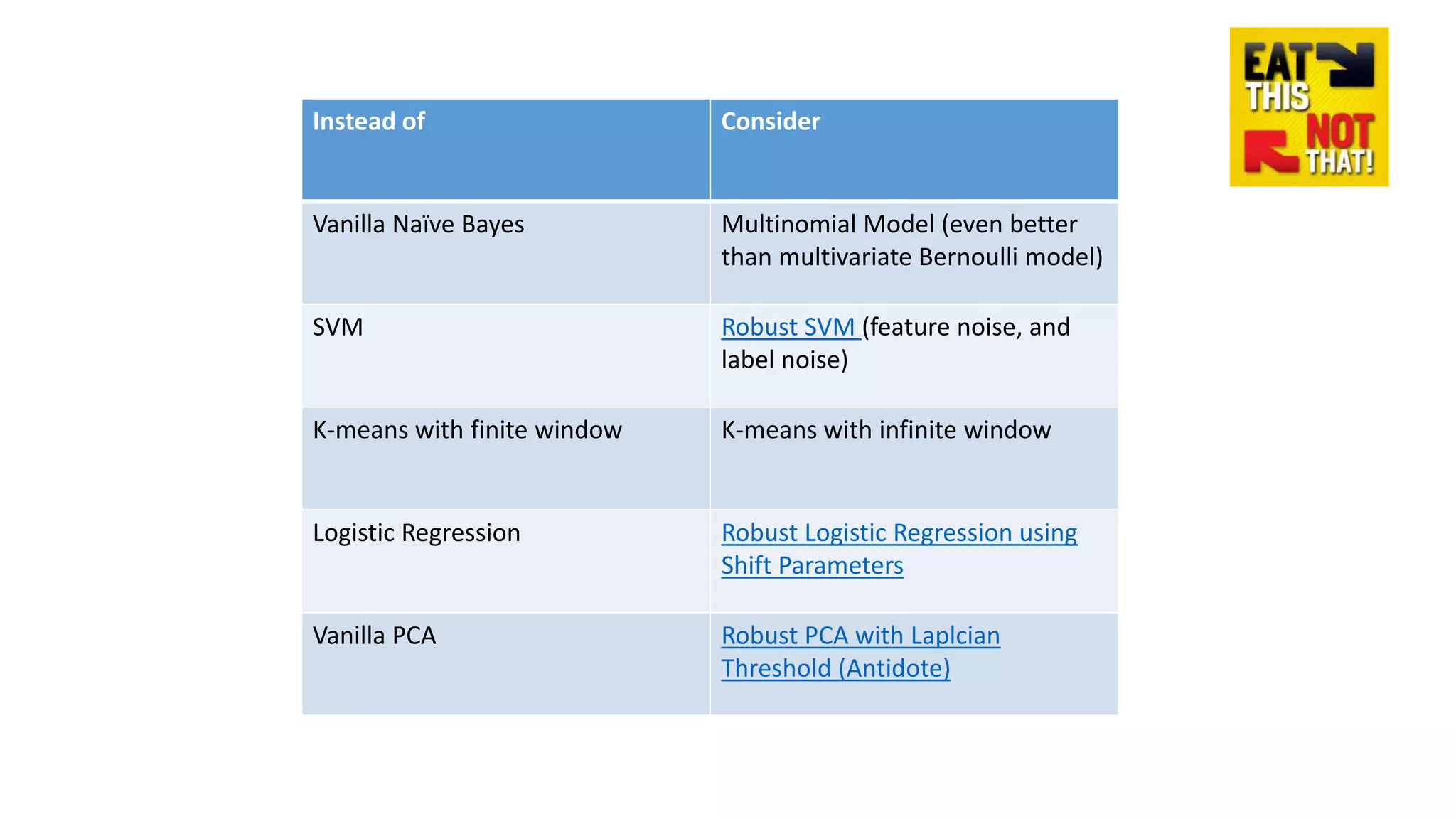







This document discusses adversarial machine learning and how to attack machine learning algorithms. It provides examples of how naive Bayes, k-means clustering, and SVM algorithms can be subverted by manipulating input data or model parameters. Specifically, the naive Bayes algorithm's accuracy can be decreased by introducing benign words to messages. The k-means clustering algorithm's false negative rate can be increased by adding outlier points. And the SVM algorithm's decision boundary and predictions can be controlled. The document advocates for defenses like ensembling multiple models and using robust learning methods.















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




