Download to read offline





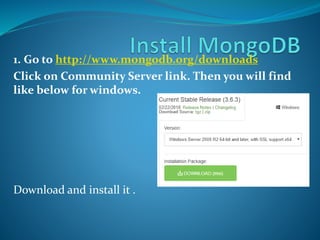




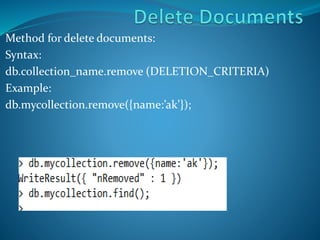

MongoDB is an open-source, document-oriented NoSQL database that allows for flexible document structures and easy installation. It supports dynamic queries and offers straightforward CRUD operations for managing data. Users can easily scale the database and execute commands via the command prompt after installation.



































































