

![# M D B l o c a l
{ "name": "Daniel Coupal",
"jobs_at_MongoDB": [
{ "job": "Senior Curriculum Engineer",
"from": new Date("2016-11") },
{ "job": "Senior Technical Service Engineer",
"from": new Date("2013-11") }
],
"previous_jobs": [
"Consultant",
"Developer",
"Manager Quality & Tools Team",
"Manager Software Team",
"Tools Developer"
],
"likes": [ "food", "beers", "movies", "MongoDB" ]
}
Who Am I?](https://image.slidesharecdn.com/edited-advanced-schema-design-51d306dd-a2d6-4716-ba41-08e9c1c0f62e-322959707-171018133322/85/Advanced-Schema-Design-Patterns-2-320.jpg)


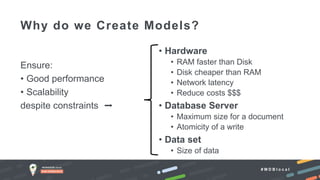


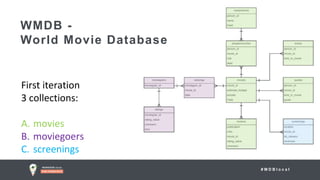

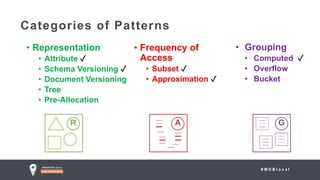
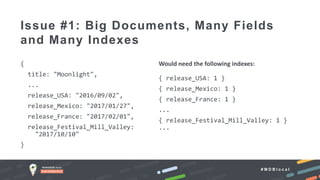
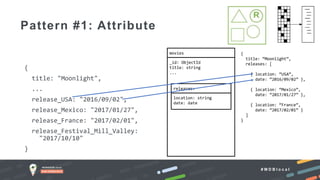



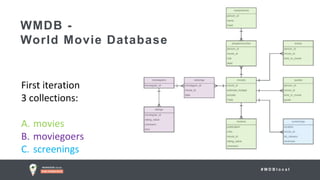
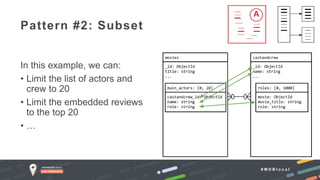






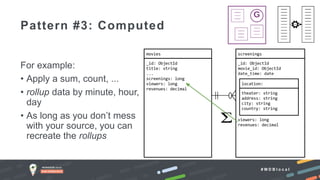


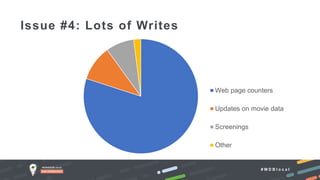

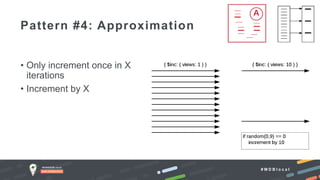












The document outlines advanced schema design patterns for MongoDB, emphasizing the importance of a common methodology and vocabulary for effective schema modeling. It discusses various issues such as performance, scalability, and simplicity, providing solutions through design patterns like attribute, subset, computed, approximation, and schema versioning. The presentation encourages utilizing these patterns to enhance database performance and reduce costs, while introducing case studies for practical application.













































![[MongoDB.local Bengaluru 2018] Keynote](https://cdn.slidesharecdn.com/ss_thumbnails/keynote-mongodb-180425154328-thumbnail.jpg?width=640&height=640&fit=bounds)









![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











