Downloaded 17 times



![{
name : "Anant Srivastava",
company : "MongoDB",
title : "Senior Consulting Engineer",
location : "Plano, TX",
start_date: new Date("2016-02"),
Hats : [ "Troubleshooter", "Trainer",Developer
"Advisor" ],
email : "anant.srivastava@mongodb.com"
}](https://image.slidesharecdn.com/final-mongodblocalsf2018-advancedschemadesignpatterns1-190102191440/85/Advanced-Schema-Design-Patterns-3-320.jpg)


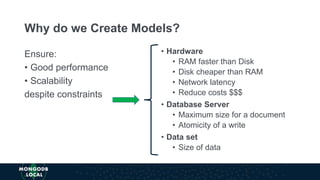
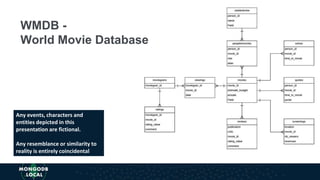
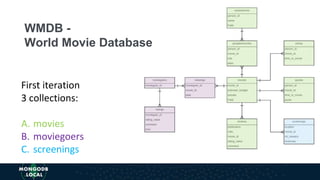

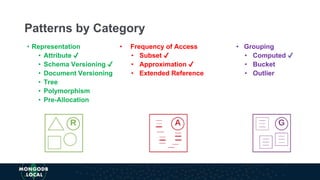





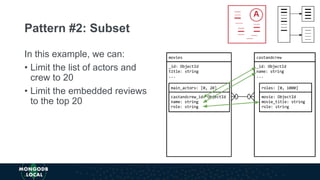



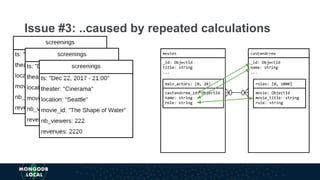
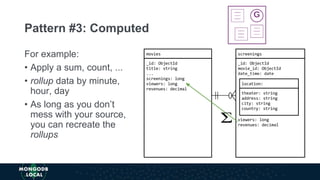


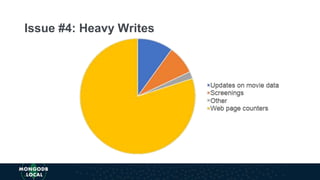










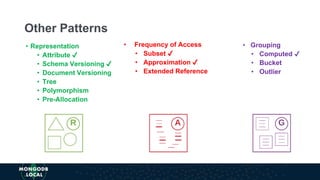





The document discusses schema design patterns for MongoDB databases. It introduces common patterns like attribute, subset, computed, and approximation to address issues like large documents, working set size, repeated calculations, and high write volumes. The patterns help optimize performance, scalability, and reduce costs. The document explains each pattern's problem, solution, and benefits through examples like storing movie release dates and computed values. It encourages applying these proven patterns as building blocks to design schemas for specific use cases like e-commerce or social networking applications.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































