Downloaded 14 times








![Gensim code
# import modules & set up logging
import gensim
sentences = [['first', 'sentence'], ['second', 'sentence']]
# train word2vec on the two sentences
model = gensim.models.Word2Vec(sentences, min_count=1)
indexes = model.wv.index2word
embedding = model.wv.vectors](https://image.slidesharecdn.com/jdqco3t6s2uuz0u8msbu-signature-1eb4670ba8de5929382cbea3a0fda75b827ea973be9dbede09affa09057f4996-poli-180924115412/85/Search2Vec-at-OLX-Group-Pydata-Meetup-Berlin-14-320.jpg)

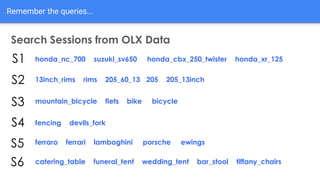
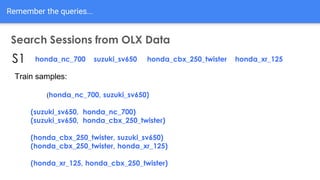




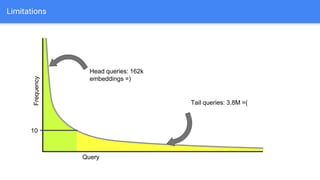

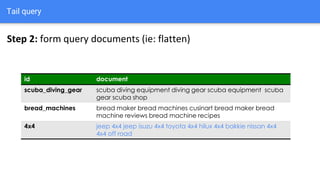
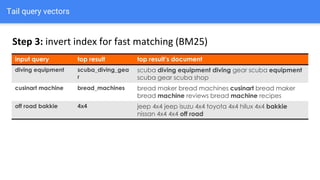
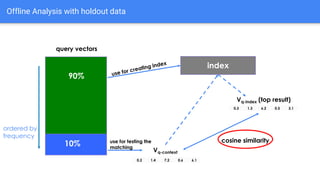
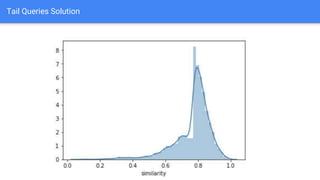





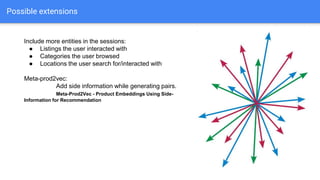

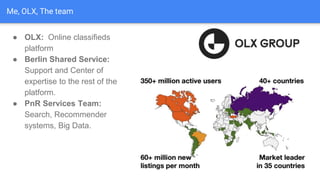
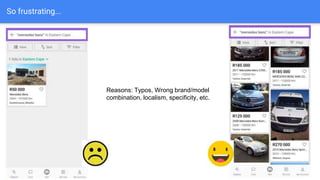
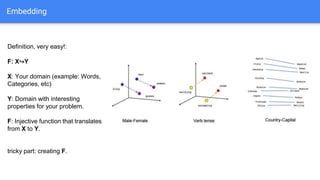
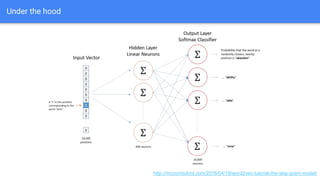
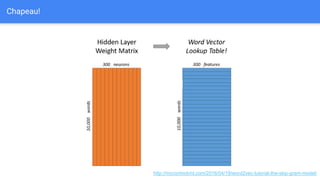
The document discusses the application of semantic query embeddings to enhance search capabilities on the OLX online classifieds platform, particularly focusing on query expansion to address issues like typos and localism. It outlines the process of using Word2Vec for word embeddings and describes the training of a model on search session data to improve query matching. The results indicate an increase in relevant search results and user engagement, with potential for further extensions to incorporate additional data elements.






























































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)




