What is Function?
Which takes some input and munch on it and
generate some output
relates an input to an output
f(x) =
f(q) = 1 - q + q2
h(A) = 1 - A + A2
w(θ) = 1 - θ + θ2
Function
3.
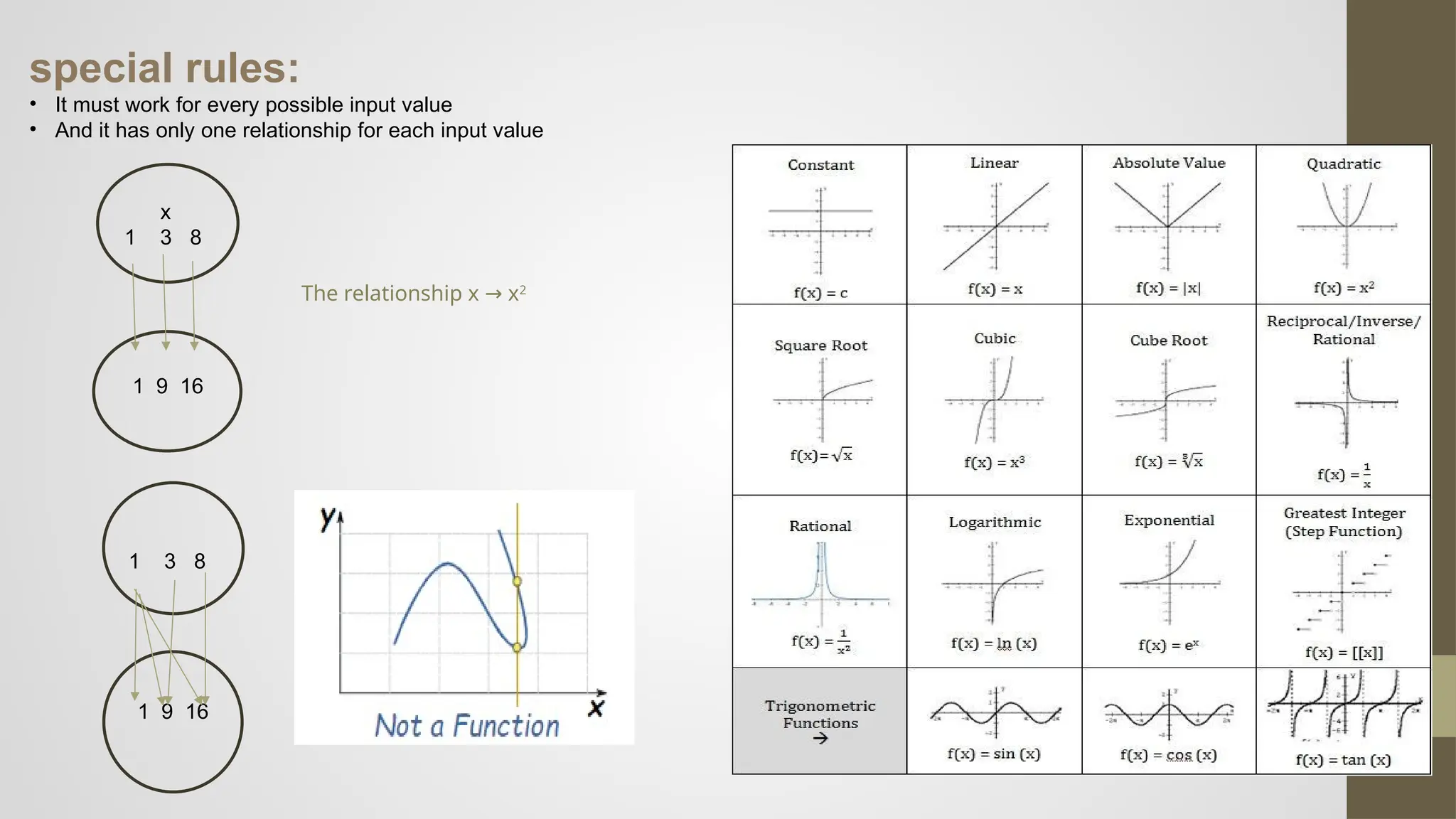
special rules:
• Itmust work for every possible input value
• And it has only one relationship for each input value
x
1 3 8
1 9 16
1 3 8
1 9 16
The relationship x x
→ 2
4.
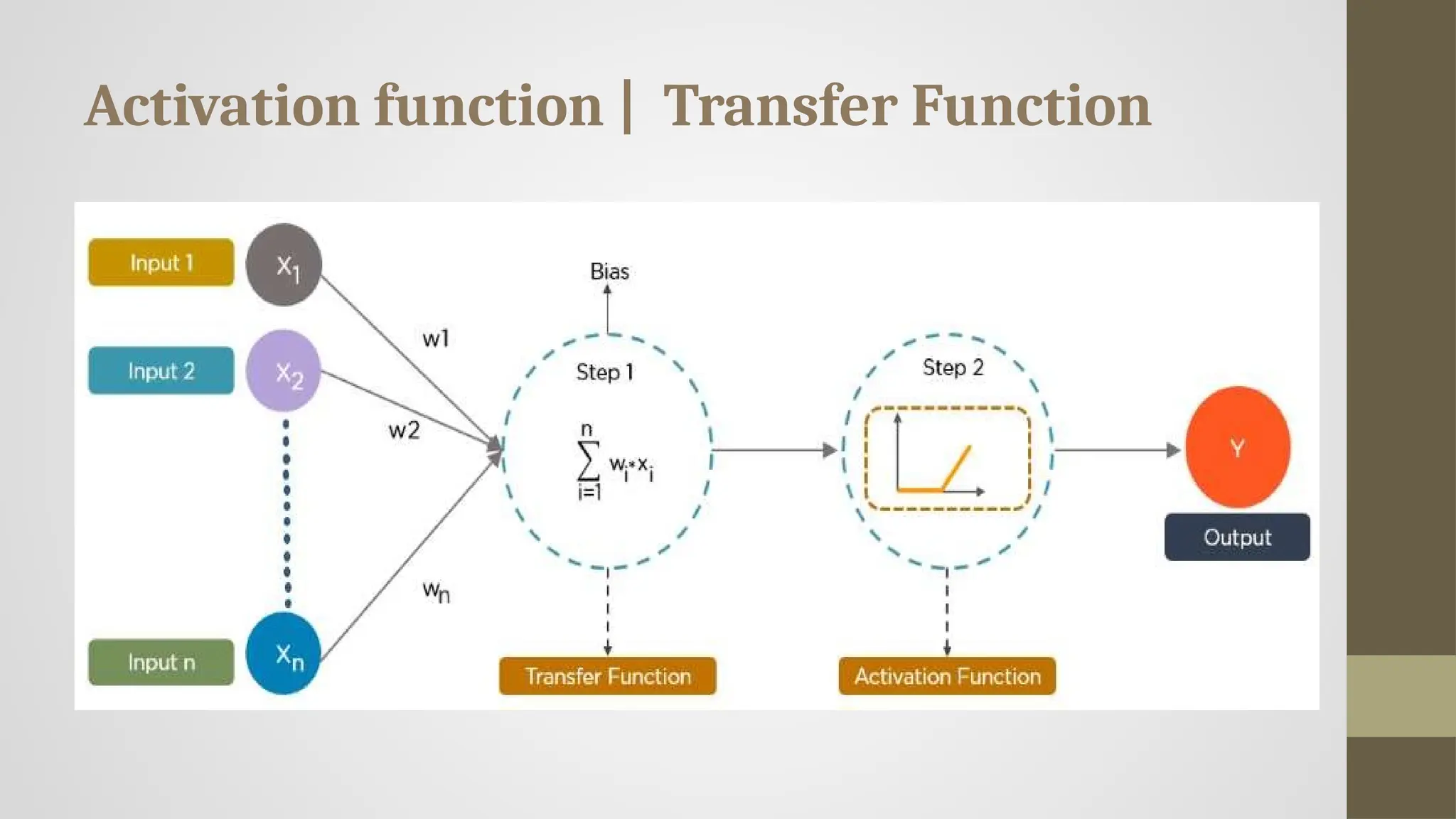
Activation Function
• AnActivation Function is a mathematical function that is applied to the output of a
neuron in a neural network to introduce non-linearity into the output of the neuron,
allowing the neural network to learn more complex and nuanced relationships between
inputs and outputs.
• An Activation Function decides whether a neuron should be activated or not.
• The primary role of the Activation Function is to transform the summed weighted input
from the node into an output value to be fed to the next hidden layer or as output.
Why do NNsNeed an Activation Function?
• The purpose of an activation function is to add non-linearity to the neural network.
• Activation functions introduce an additional step at each layer during the forward propagation, but its computation is worth
it.
WHY
A NN working without the activation functions
In that case, every neuron will only be performing a linear transformation on the inputs using the weights and biases. It’s because it doesn’t
matter how many hidden layers we attach in the neural network; all layers will behave in the same way because the composition of two linear
functions is a linear function itself.
• The neural network becomes simpler Without Activation Function
BUT
• Learning any complex task is impossible, and our model would be just a linear regression model.
7.
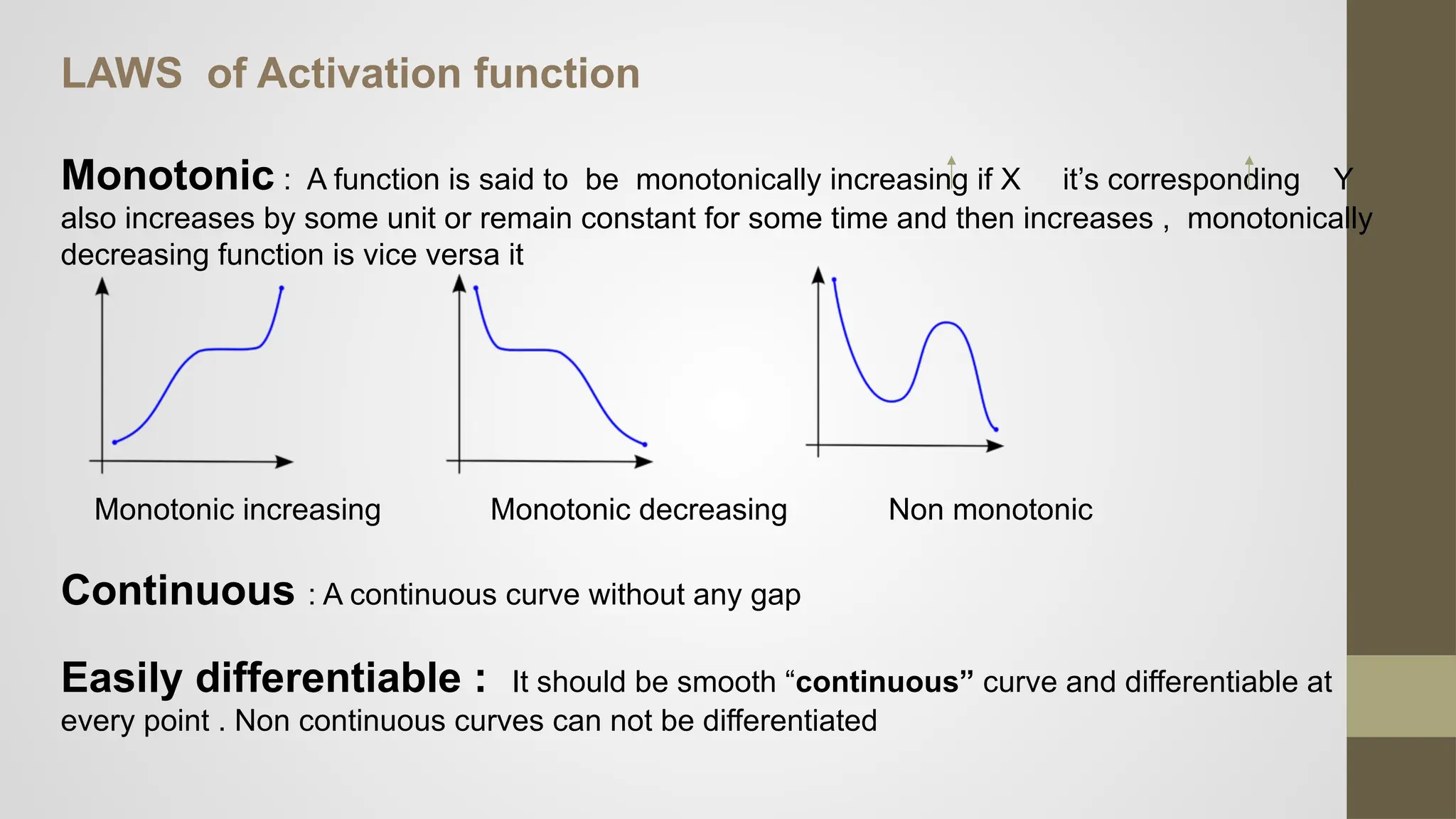
LAWS of Activationfunction
Monotonic : A function is said to be monotonically increasing if X it’s corresponding Y
also increases by some unit or remain constant for some time and then increases , monotonically
decreasing function is vice versa it
Monotonic increasing Monotonic decreasing Non monotonic
Continuous : A continuous curve without any gap
Easily differentiable : It should be smooth “continuous” curve and differentiable at
every point . Non continuous curves can not be differentiated
8.
Types of NNsActivation Functions
• Binary Step Function
• Linear Activation Function
• Non-Linear Activation Functions
9.
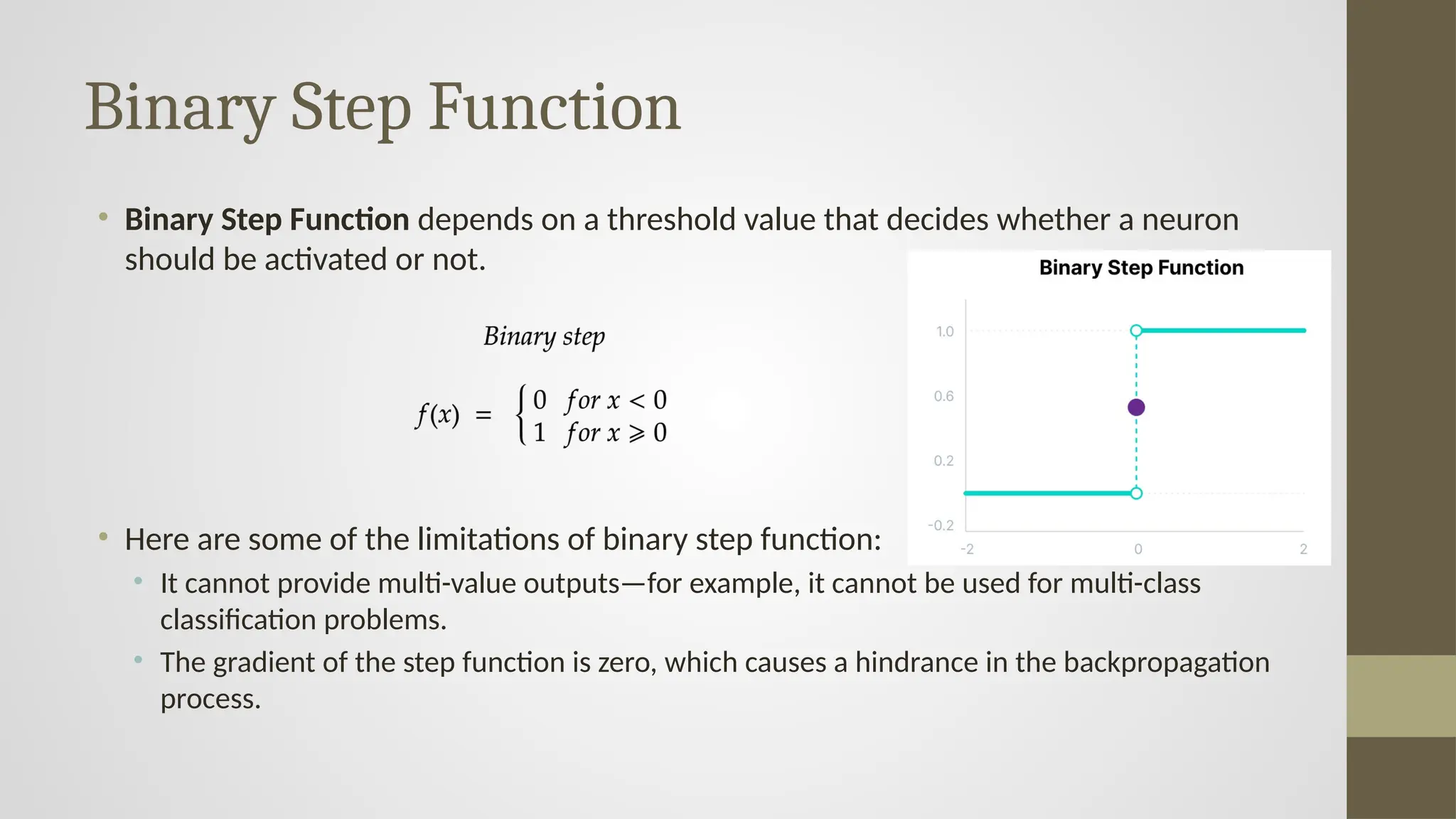
Binary Step Function
•Binary Step Function depends on a threshold value that decides whether a neuron
should be activated or not.
• Here are some of the limitations of binary step function:
• It cannot provide multi-value outputs—for example, it cannot be used for multi-class
classification problems.
• The gradient of the step function is zero, which causes a hindrance in the backpropagation
process.
10.
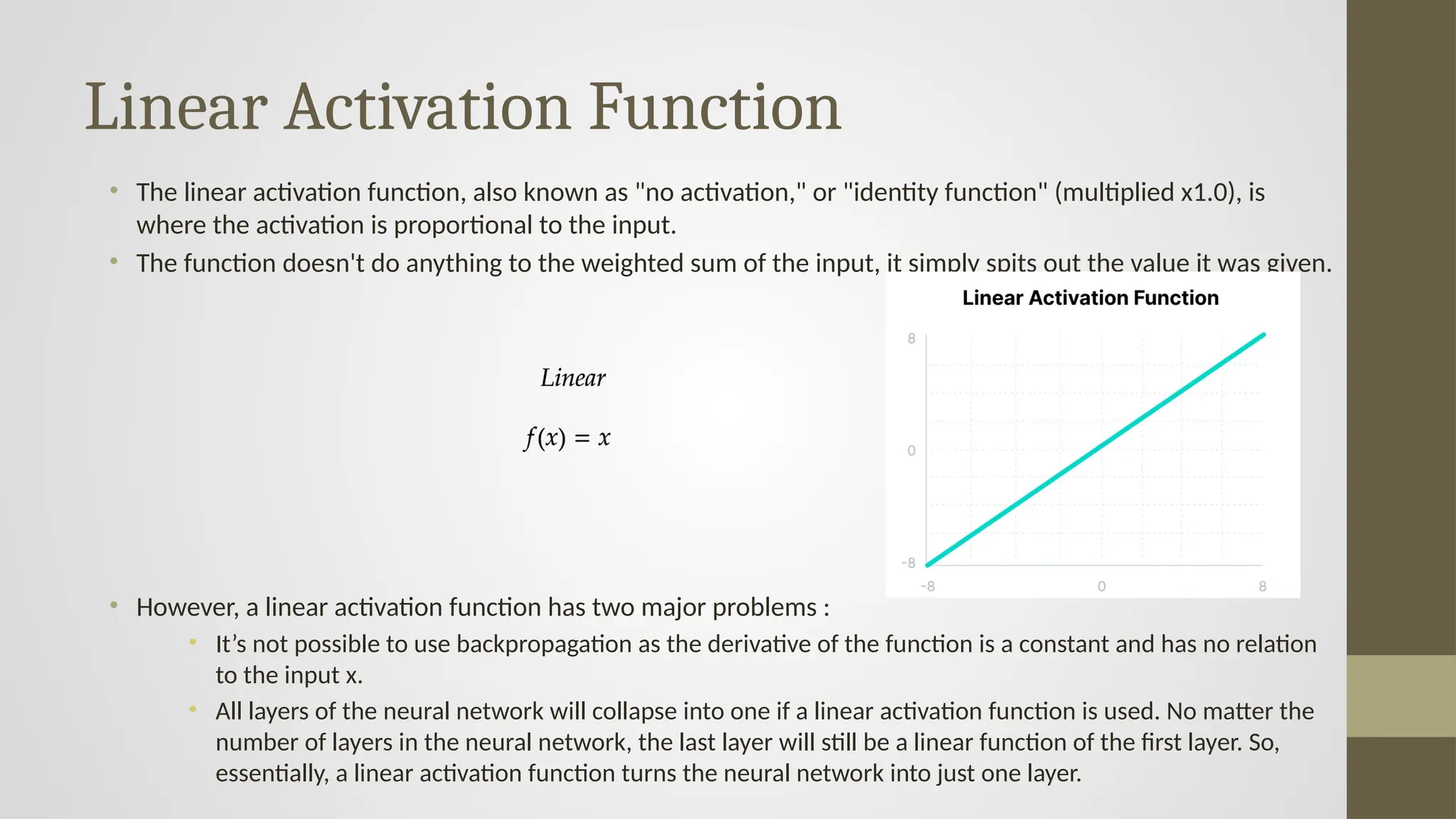
Linear Activation Function
•The linear activation function, also known as "no activation," or "identity function" (multiplied x1.0), is
where the activation is proportional to the input.
• The function doesn't do anything to the weighted sum of the input, it simply spits out the value it was given.
• However, a linear activation function has two major problems :
• It’s not possible to use backpropagation as the derivative of the function is a constant and has no relation
to the input x.
• All layers of the neural network will collapse into one if a linear activation function is used. No matter the
number of layers in the neural network, the last layer will still be a linear function of the first layer. So,
essentially, a linear activation function turns the neural network into just one layer.
11.
Linear Activation Function
•The linear activation function is simply a linear regression model.
• Because of its limited power, this does not allow the model to create complex
mappings between the network’s inputs and outputs.
12.
Non-Linear Activation Functions
Non-linearactivation functions solve the following limitations of linear activation
functions:
• Allow backpropagation because now the derivative function would be related to the input,
and it’s possible to go back and understand which weights in the input neurons can
provide a better prediction.
• They allow the stacking of multiple layers of neurons as the output would now be a non-
linear combination of input passed through multiple layers. Any output can be
represented as a functional computation in a neural network.
• There are various Non-Linear Activation Functions.
Lets Discuss
13.
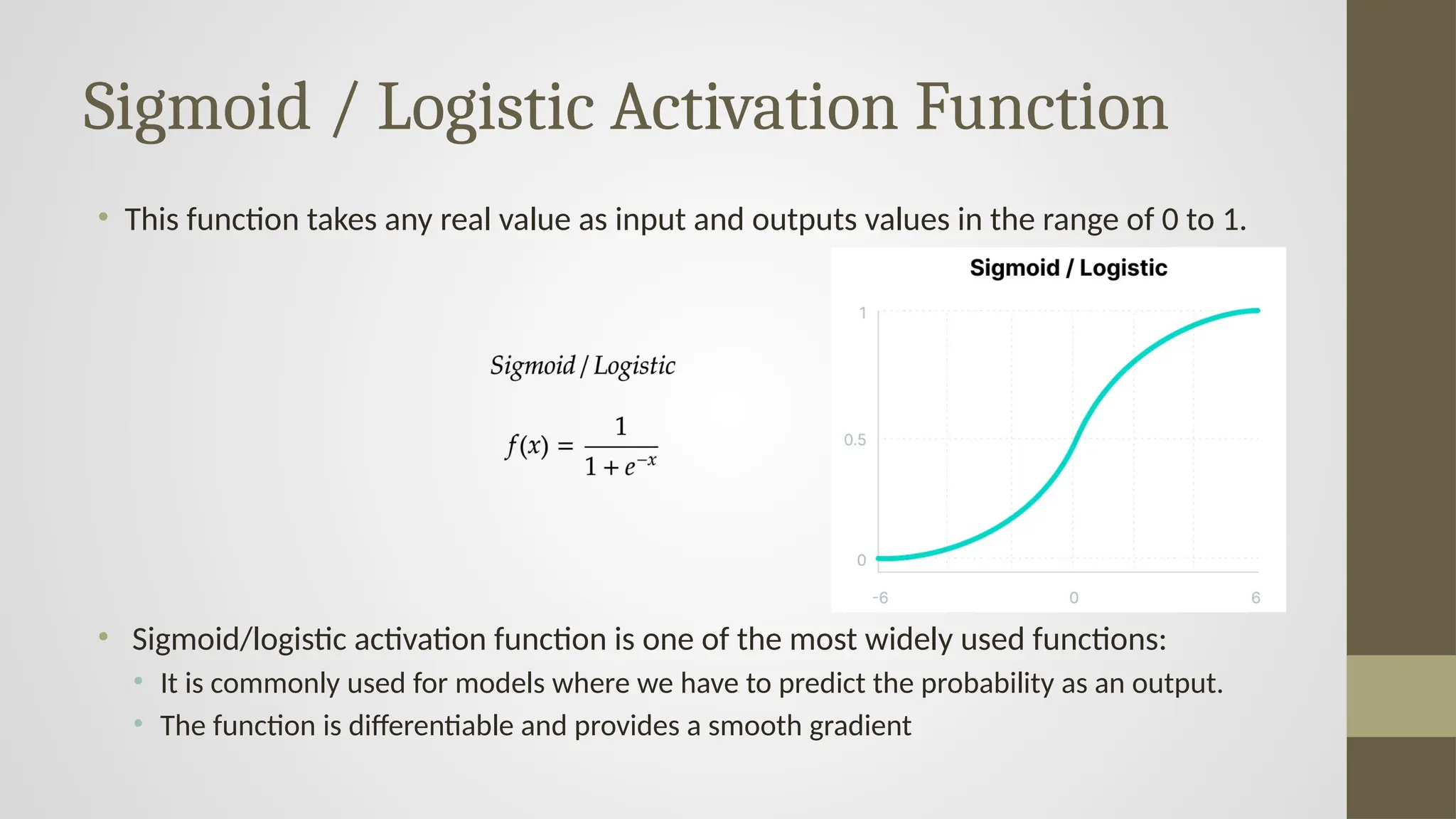
Sigmoid / LogisticActivation Function
• This function takes any real value as input and outputs values in the range of 0 to 1.
• Sigmoid/logistic activation function is one of the most widely used functions:
• It is commonly used for models where we have to predict the probability as an output.
• The function is differentiable and provides a smooth gradient
14.
Sigmoid / LogisticActivation Function
• The limitations of sigmoid function
• Figure shows, the gradient values are only significant for range -3 to 3, and the graph gets much
flatter in other regions.
• It implies that for values greater than 3 or less than -3, the function will have very small gradients. As
the gradient value approaches zero.
• The network ceases to learn and suffers from the Vanishing gradient problem.
15.
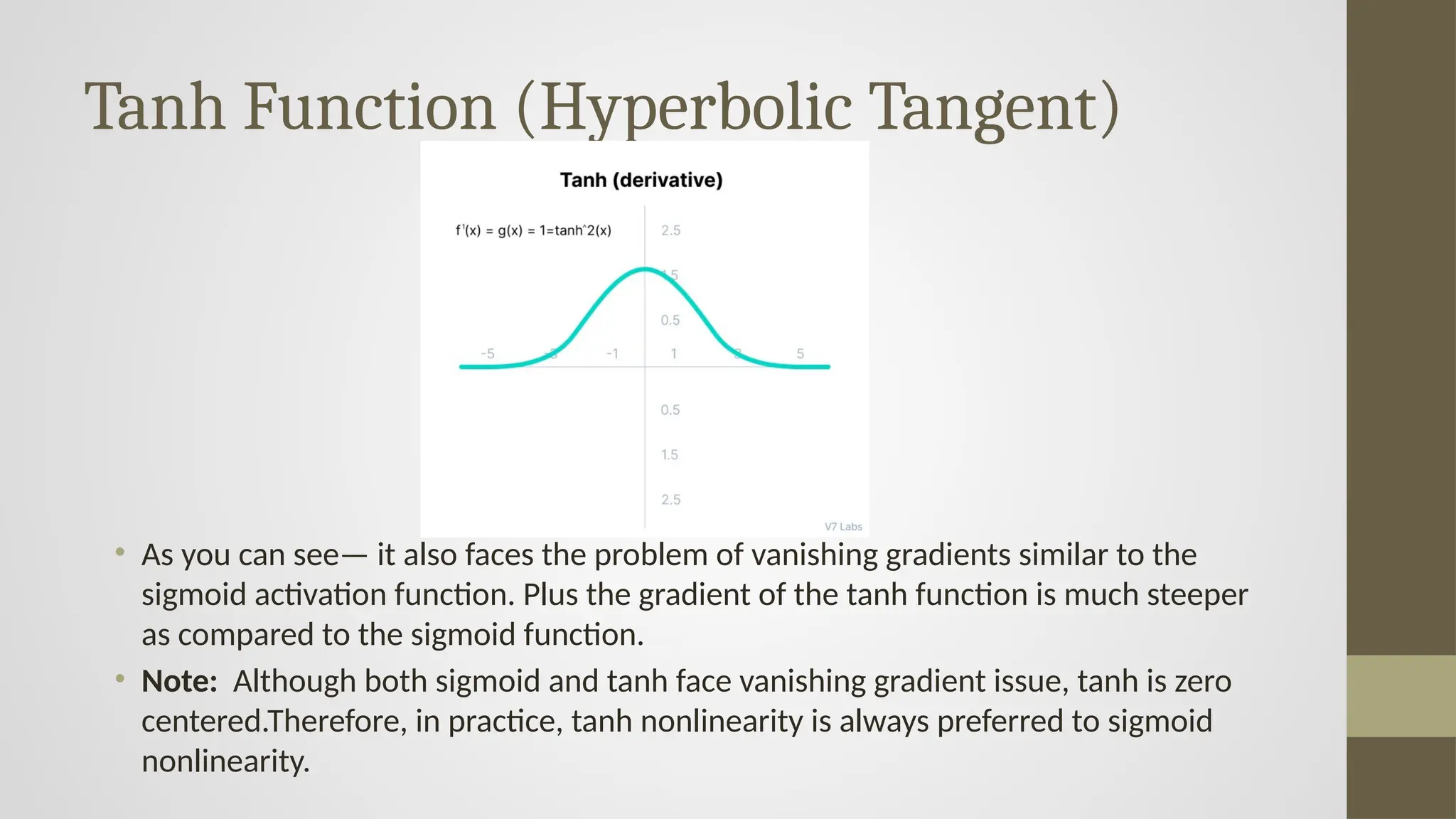
Tanh Function (HyperbolicTangent)
• Tanh function is very similar to the Sigmoid activation function, same S-shape with the
difference in output range of -1 to 1.
• Advantages of using this activation function are:
• The output of the tanh activation function is Zero centered; hence we can easily map the
output values as strongly negative, neutral, or strongly positive.
• Usually used in hidden layers of a neural network as its values lie between -1 to 1; therefore,
the mean for the hidden layer comes out to be 0 or very close to it. It helps in centering the
data and makes learning for the next layer much easier.
16.
Tanh Function (HyperbolicTangent)
• As you can see— it also faces the problem of vanishing gradients similar to the
sigmoid activation function. Plus the gradient of the tanh function is much steeper
as compared to the sigmoid function.
• Note: Although both sigmoid and tanh face vanishing gradient issue, tanh is zero
centered.Therefore, in practice, tanh nonlinearity is always preferred to sigmoid
nonlinearity.
17.
ReLU Function
• ReLUstands for Rectified Linear Unit.
• Although it gives an impression of a linear function, ReLU has a derivative function and allows
backpropagation while simultaneously making it computationally efficient.
• The main catch here is that the ReLU function does not activate all the neurons at the same
time.
• The neurons will only be deactivated if the output of the linear transformation is less than 0.
18.
ReLU Function
• Theadvantages of using ReLU as an activation function are as follows:
• Since only a certain number of neurons are activated, the ReLU function is far more
computationally efficient when compared to the sigmoid and tanh functions.
• ReLU accelerates the convergence of gradient descent towards the global minimum of the
loss function due to its linear, non-saturating property.
• The limitations faced by this function are:
• The Dying ReLU problem
19.
ReLU Function
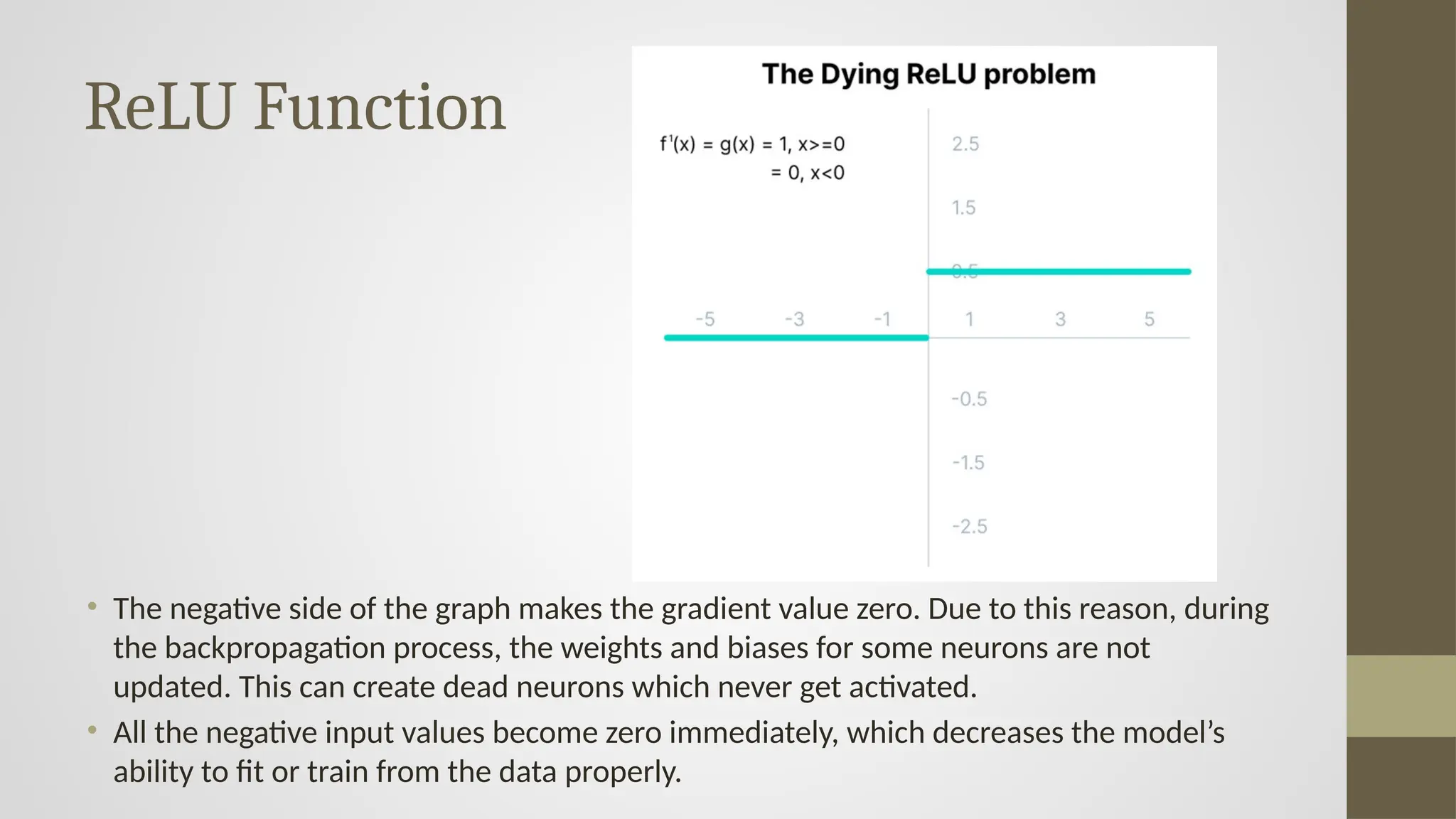
• Thenegative side of the graph makes the gradient value zero. Due to this reason, during
the backpropagation process, the weights and biases for some neurons are not
updated. This can create dead neurons which never get activated.
• All the negative input values become zero immediately, which decreases the model’s
ability to fit or train from the data properly.
20.
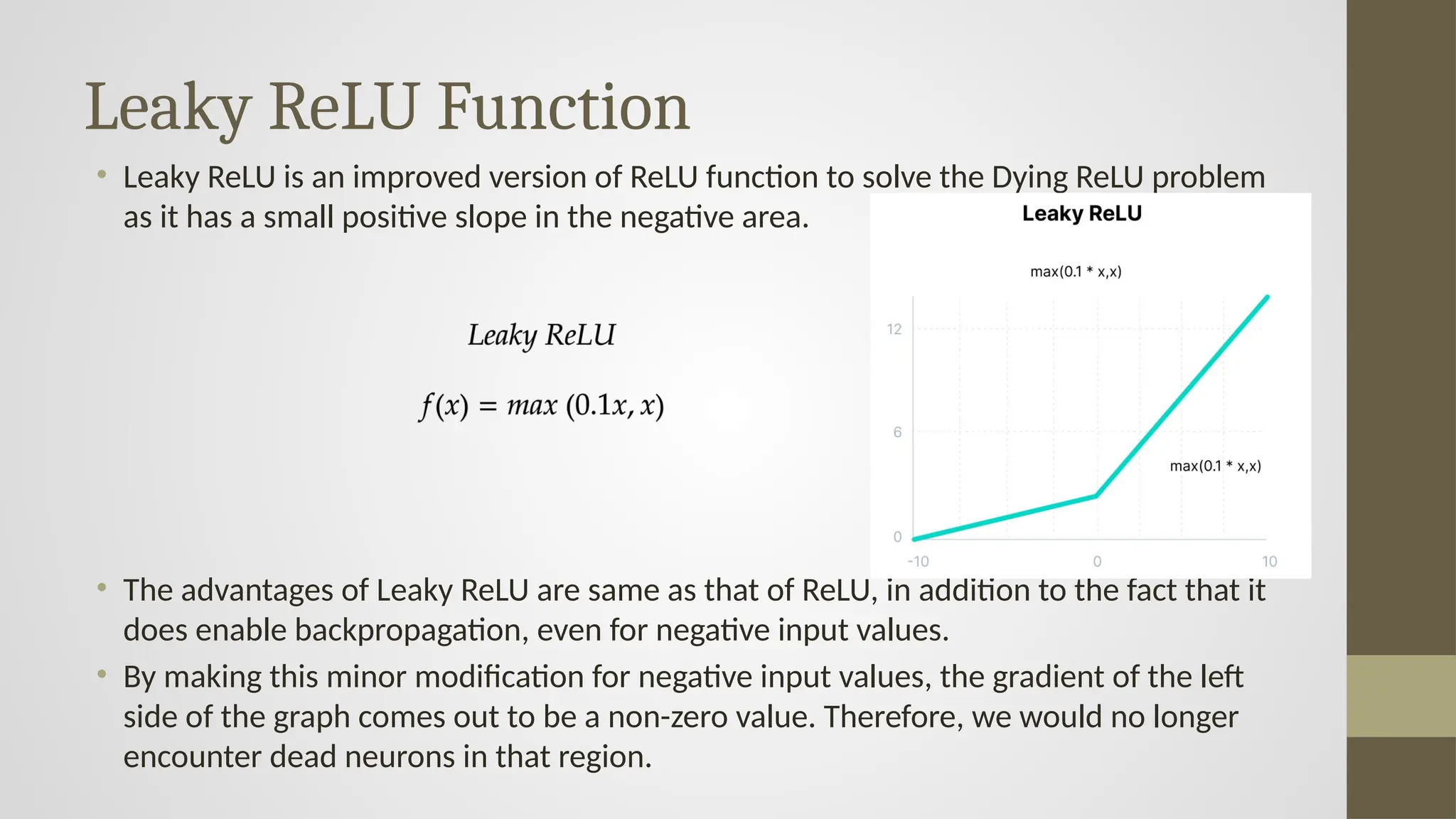
Leaky ReLU Function
•Leaky ReLU is an improved version of ReLU function to solve the Dying ReLU problem
as it has a small positive slope in the negative area.
• The advantages of Leaky ReLU are same as that of ReLU, in addition to the fact that it
does enable backpropagation, even for negative input values.
• By making this minor modification for negative input values, the gradient of the left
side of the graph comes out to be a non-zero value. Therefore, we would no longer
encounter dead neurons in that region.
21.
Leaky ReLU Function
•The limitations that this function faces include:
• The predictions may not be consistent for negative input values.
• The gradient for negative values is a small value that makes the learning of model
parameters time-consuming.
22.
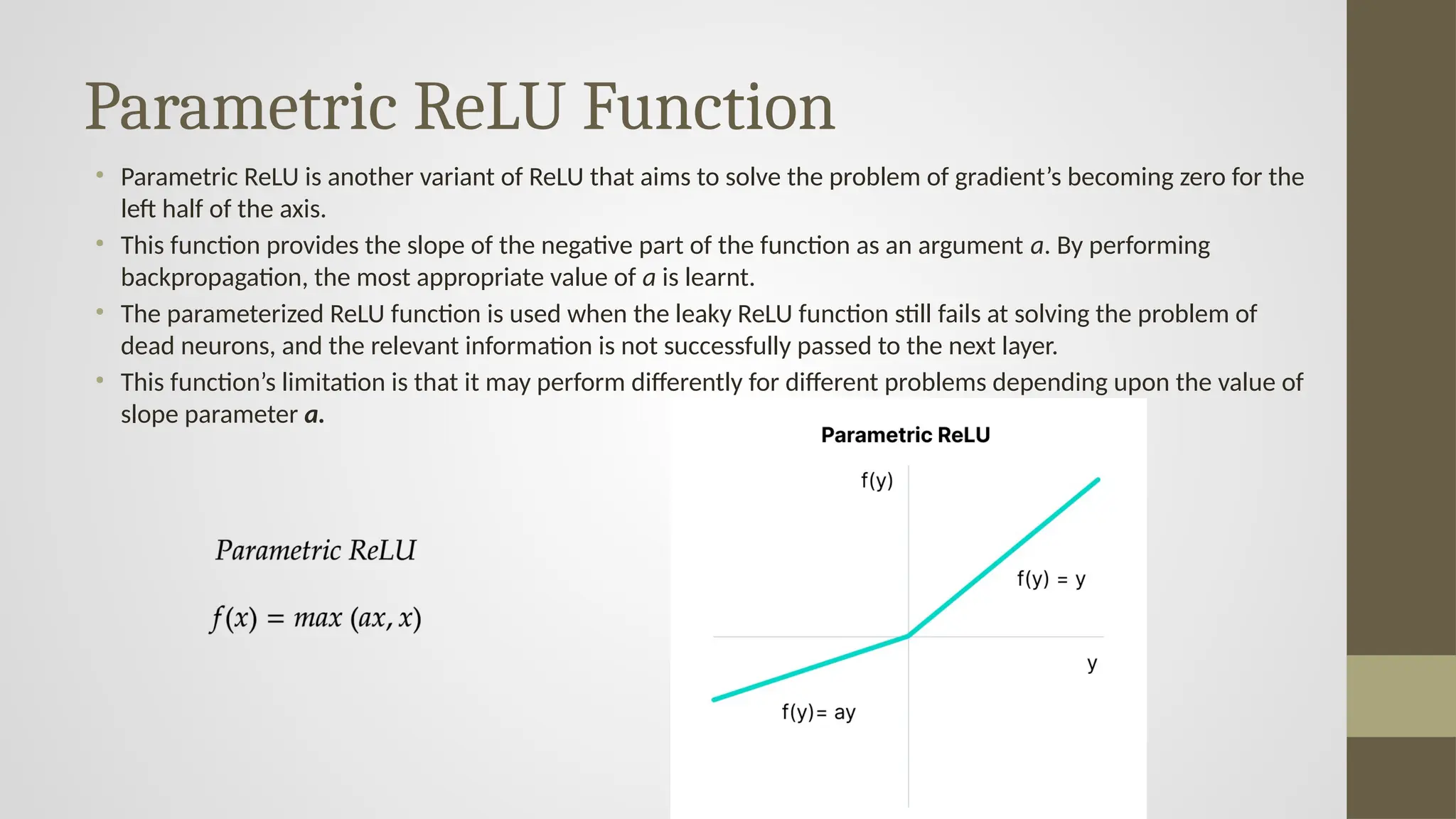
Parametric ReLU Function
•Parametric ReLU is another variant of ReLU that aims to solve the problem of gradient’s becoming zero for the
left half of the axis.
• This function provides the slope of the negative part of the function as an argument a. By performing
backpropagation, the most appropriate value of a is learnt.
• The parameterized ReLU function is used when the leaky ReLU function still fails at solving the problem of
dead neurons, and the relevant information is not successfully passed to the next layer.
• This function’s limitation is that it may perform differently for different problems depending upon the value of
slope parameter a.
23.
Exponential Linear Unit
•ReLU returns 0 for any negative input. This leads to the
"dying ReLU" problem where some neurons stop learning
entirely due to zero gradients.
• Leaky ReLU solves this by allowing a small, non-zero
gradient for negative values. However its slope is fixed
and may not be ideal in all situations.
• Both functions are non-differentiable at x = 0 which can
slightly affect optimization.
• To address these issues more effectively ELU function was
introduced.
ELU is a activation function used in neural networks which is an advanced version of
widely used relu activation function. Exponential Linear Unit modifies the negative
part of ReLU by applying an exponential curve. It allows small negative values
instead of zero which improves learning dynamics.
24.
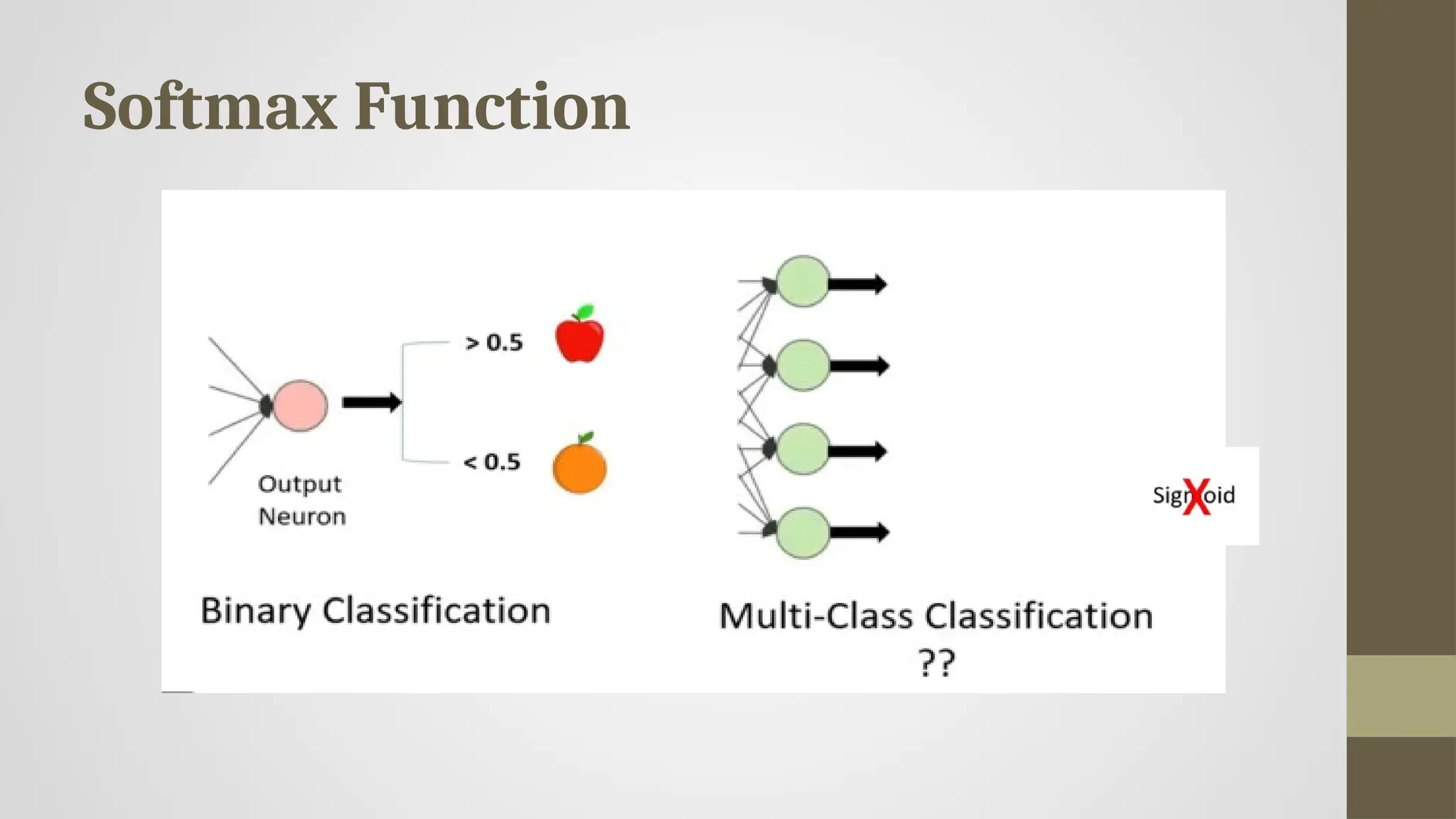
Softmax Function
• Itsbuilding block—the sigmoid/logistic activation function that works on calculating probability values.
• The output of the sigmoid function was in the range of 0 to 1, which can be thought of as probability.
• You see, the Softmax function is described as a combination of multiple sigmoids.
• It calculates the relative probabilities. Similar to the sigmoid/logistic activation function, the SoftMax
function returns the probability of each class.
• It is most commonly used as an activation function for the last layer of the neural network in the case of
multi-class classification.
Why are deepNNs hard to train?
• There are two challenges you might encounter when training your deep neural networks.
• Vanishing Gradients
• Like the sigmoid function, certain activation functions squish an ample input space into a small output space
between 0 and 1.
• Therefore, a large change in the input of the sigmoid function will cause a small change in the output. Hence,
the derivative becomes small. For shallow networks with only a few layers that use these activations, this
isn’t a big problem.
• However, when more layers are used, it can cause the gradient to be too small for training to work
effectively.
• Exploding Gradients
• Exploding gradients are problems where significant error gradients accumulate and result in very large
updates to neural network model weights during training.
• An unstable network can result when there are exploding gradients, and the learning cannot be completed.
• The values of the weights can also become so large as to overflow and result in something called NaN
values.
30.
How to choosethe right Activation Function?
• You need to match your activation function for your output layer based on the type of
prediction problem that you are solving.
• As a rule of thumb, you can begin with using the ReLU activation function and then move
over to other activation functions if ReLU doesn’t provide optimum results.
• ReLU activation function should only be used in the hidden layers.
• Sigmoid/Logistic and Tanh functions should not be used in hidden layers as they make
the model more susceptible to problems during training (due to vanishing gradients).
• Regression - Linear Activation Function
• Binary Classification—Sigmoid/Logistic Activation Function
• Multiclass Classification—Softmax
• Multilabel Classification—Sigmoid
• Convolutional Neural Network (CNN): ReLU activation function.
• Recurrent Neural Network(RNN): Tanh and/or Sigmoid activation function.
#7 Activation function decides whether a neuron should be activated by calculating the weighted sum of inputs and adding a bias term. This helps the model make complex decisions and predictions by introducing non-linearities to the output of each neuron.
Introducing Non-Linearity in Neural Network
Non-linearity means that the relationship between input and output is not a straight line. In simple terms the output does not change proportionally with the input.
Imagine you want to classify apples and bananas based on their shape and color.
If we use a linear function it can only separate them using a straight line.
But real-world data is often more complex like overlapping colors, different lighting, etc.
By adding a non-linear activation function like ReLU, Sigmoid or Tanh the network can create curved decision boundaries to separate them correctly.
Effect of Non-Linearity
The inclusion of the ReLU activation function
σ
σ allows
h
1
h
1
to introduce a non-linear decision boundary in the input space. This non-linearity enables the network to learn more complex patterns that are not possible with a purely linear model such as:
Modeling functions that are not linearly separable.
Increasing the capacity of the network to form multiple decision boundaries based on the combination of weights and biases.
Why is Non-Linearity Important in Neural Networks?
Neural networks consist of neurons that operate using weights, biases and activation functions.
In the learning process these weights and biases are updated based on the error produced at the output—a process known as backpropagation. Activation functions enable backpropagation by providing gradients that are essential for updating the weights and biases.
#8 three essential properties of activation functions used in machine learning: monotonicity, continuity, and differentiability. A function is monotonic if it consistently increases or decreases, helping models learn stable patterns.
A continuous function has no breaks or jumps, ensuring smooth transitions.
Lastly, being easily differentiable means the function has a smooth curve with a defined slope at every point, which is crucial for gradient-based optimization methods like backpropagation.
#10 The Binary Step Function is an activation function that outputs either 0 or 1 based on a threshold—typically, it outputs 1 if the input is positive and 0 otherwise. This function is simple and used to determine whether a neuron should fire. However, it has major limitations: it can't handle multi-class problems and its gradient is zero almost everywhere, which prevents learning through gradient-based optimization like backpropagation.
#11 The Linear Activation Function shown in the image is mathematically defined as:
𝑓
(
𝑥
)
=
𝑥
f(x)=x
This means that the output of the function is directly equal to the input — there is no transformation applied. Let's break down both the mathematical model and the graph:
🔢 Mathematical Model:
Function:
𝑓
(
𝑥
)
=
𝑥
f(x)=x
This is known as the identity function.
For any input value
𝑥
x, the output is exactly the same.
The derivative of this function is constant:
𝑓
′
(
𝑥
)
=
1
f
′
(x)=1
This constant derivative has no variation with respect to
𝑥
x, which poses a problem for gradient-based learning.
📈 Graph Explanation:
The graph shows a straight line passing through the origin (0,0) with a slope of 1.
This means that for every unit increase in input
𝑥
x, the output
𝑓
(
𝑥
)
f(x) increases by the same unit.
The line extends infinitely in both directions (shown from around -8 to 8 here), indicating that there's no non-linearity or saturation in this function.
🚫 Why It’s Problematic in Neural Networks:
No Hierarchical Learning: Using this activation in multiple layers means every layer just applies the same transformation, collapsing the entire network into a single linear transformation — losing the power of deep networks.
No Non-linearity = No Complexity: It cannot model complex functions or boundaries required in tasks like image recognition or natural language understanding.
Backpropagation Limitation: Because the derivative is constant, gradient-based learning does not adjust weights meaningfully based on the input.
In summary, while the linear activation function is simple and interpretable, it fails to introduce non-linearity, which is essential for deep learning models to learn and represent complex patterns.
#13 Non-linear activation functions are essential in neural networks because they allow complex patterns to be learned by enabling backpropagation and the use of multiple layers. Unlike linear functions, they help model non-linear relationships, making it possible for the network to solve more complex problems. This allows the network to learn and represent almost any function. Let's discuss the different types of non-linear activation functions used in practice.
#14 The Sigmoid / Logistic Activation Function is a popular non-linear activation function used in neural networks, especially for binary classification tasks. Let’s break it down in detail:
The sigmoid function is defined as:
f(𝑥)=1/1+𝑒−𝑥
Here,
x is any real-valued input.
e−𝑥 is the exponential decay.Exponential decay refers to a process where a quantity decreases at a rate proportional to its current value. In simple terms, the larger the value, the faster it decreases—but the rate slows down over time
The output of this function lies in the range of 0 to 1, which makes it suitable for representing probabilities.
The graph shown in the slide is a classic S-shaped curve:
When 𝑥→−∞, 𝑓(𝑥)→0
When 𝑥=0, 𝑓(𝑥)=0.5
When 𝑥→+∞, 𝑓(𝑥)→1
This smooth curve allows the model to gradually activate neurons based on the input, unlike hard thresholding.
Use Case:
Binary Classification: Often used in the final layer of models where the output is the probability of a binary class (e.g., diseased vs. healthy).
Probability Output: Because the range is between 0 and 1, it's interpretable as a likelihood or confidence score.
Advantages:
Differentiable: Allows backpropagation to compute gradients.
Smooth gradient: Gradually changes output, allowing small updates in weights.
Range-bound: Always outputs values in (0, 1), preventing extreme outpu
#15 Limitations:
Vanishing Gradient Problem:
For large positive or negative
𝑥
x, the gradient (slope) becomes very small.
This slows down learning, especially in deeper networks, because the weights update very slowly.
Mathematically, the derivative
𝑓′(𝑥)=𝑓(𝑥)(1−𝑓(𝑥))f ′
(x)=f(x)(1−f(x)) approaches 0 as
f(x) nears 0 or 1.
Not Zero-Centered:
Outputs always positive (0 to 1), which can lead to zigzagging updates during optimization, making convergence slower.
Computational Cost:
Involves computing the exponential function
𝑒−𝑥
, which is more expensive than simple operations like max or ReLU’s thresholding.
Summary:
The sigmoid function is easy to understand and great for simple binary classification problems, but it's not always ideal for deep networks due to the vanishing gradient issue. It has mostly been replaced in hidden layers by ReLU or its variants in modern neural networks, but it still sees use in output layers where probabilities are needed.
#16 The Tanh (Hyperbolic Tangent) Activation Function is another widely used non-linear activation function in neural networks. It is closely related to the sigmoid function but has some advantages in practice.
Mathematical Model:
𝑓(𝑥)=𝑒𝑥−𝑒−𝑥/𝑒𝑥+e−𝑥
This function maps any real number input to a range between -1 and 1.
It's a scaled and shifted version of the sigmoid function.
Graph Explanation:
Like sigmoid, the tanh function has an S-shaped curve, but it is centered at zero.
For large negative inputs, the output approaches -1.
For large positive inputs, the output approaches 1.
At
x=0, the output is exactly 0.
The graph helps visualize how tanh gives both positive and negative activations, which helps in balancing the data passed to the next layer.
Advantages:
Zero-Centered Output:
Unlike sigmoid, tanh outputs values that are balanced around zero.
This helps gradients flow better during training and allows the model to converge faster.
Improved Performance in Hidden Layers:
Because outputs can be negative, tanh allows for more expressive representations in hidden layers.
This helps in centering the data, which improves the learning dynamics of deeper networks.
Use Cases:
Tanh is commonly used in hidden layers of neural networks, especially when a balanced output around zero is helpful.
It's often preferred over sigmoid in these cases because it provides stronger gradients and better optimization behavior.
#17 Limitations:
Vanishing Gradient Problem:
Like sigmoid, when the input is very large or very small, the derivative of tanh becomes very small.
This can lead to slow learning or stuck weights in deeper networks.
Computational Cost:
The exponential operations involved are computationally more expensive than simpler functions like ReLU.
Summary:
Tanh offers a zero-centered output and a smooth gradient, making it more effective than sigmoid for training deep networks. However, it still suffers from vanishing gradients and is often replaced by ReLU or other modern functions in deeper architectures.
#18 ReLU stands for Rectified Linear Unit. It is an activation function used in neural networks to introduce non-linearity, which is essential for the model to learn complex patterns.
🔹 Mathematical Definition
The ReLU function is defined as:
f(x)=max(0,x)
This means:
If 𝑥>0, then 𝑓(𝑥)=x
If 𝑥≤0 , then 𝑓(𝑥)=0
Graphically, this is a line that:
Is flat (zero) for all negative input values
Is linear (y = x) for all positive input values
This is shown in the graph on the right side of the slide.
🔹 Key Points
Backpropagation-Friendly
Although ReLU may look simple and piecewise linear, it has a derivative, which makes it suitable for backpropagation—a core part of training neural networks.
Computational Efficiency
ReLU is computationally efficient because it doesn't involve expensive operations like exponentials or divisions (as in sigmoid or tanh).
Selective Neuron Activation
One important feature of ReLU is that it deactivates neurons when their input is ≤ 0. This property is helpful because:
It introduces sparsity (i.e., fewer neurons firing at once)
It reduces the risk of overfitting
Deactivation Condition
Neurons using ReLU are only active if the output of the linear transformation is greater than 0. Otherwise, they output 0 and do not contribute to the network's output at that layer.
🔹 (From the Graph)
The x-axis represents the input values.
The y-axis shows the output of the ReLU function.
The curve is flat at y = 0 when
𝑥<0
The curve rises linearly when 𝑥>0
This behavior makes ReLU especially good at propagating gradients and training deep networks effectively.
🔹 Advantages of ReLU
Simple to implement
Faster computation
Solves the vanishing gradient problem to some extent (compared to sigmoid/tanh)
Promotes sparse activation (fewer neurons active at once)
#19 Potential Disadvantages
Dying ReLU problem: If many neurons output zero consistently, they may never activate again, effectively becoming useless.
#20 What is the Dying ReLU Problem?
When using the ReLU activation function, some neurons can become "dead" during training. This means:
For certain inputs, the output of the neuron is always 0.
These neurons never activate, no matter what input they receive.
They stop contributing to the learning process — their weights are never updated.
🔹 Graph Explanation
The graph illustrates the derivative of the ReLU function:
𝑓′(𝑥)={1} if 𝑥>0
f (x) = [0] if 𝑥<0
On the positive side, the derivative is 1 (so gradients flow normally).
On the negative side, the derivative is 0 — meaning the gradient is zero for all negative inputs.
🔹 Why Is This a Problem?
Zero Gradient on Negative Side
When inputs to a neuron are negative, the ReLU outputs 0 and its gradient is also 0.
During backpropagation, this zero gradient means no error signal is sent back.
As a result, the weights of that neuron are not updated.
Neuron Becomes Permanently Inactive
Once a neuron's output is 0 and its weights are not updated, it becomes stuck — it never activates again, regardless of input.
Model Capacity Decreases
If many neurons "die" like this, the network loses capacity — it cannot model complex functions well, which leads to:
Poor training performance
Underfitting
🔹 Summary
Gradient is zero for negative inputs, stopping learning for some neurons.
Weights and biases stop updating, leading to "dead neurons".
This harms training and reduces the model's effectiveness.
#21 the Leaky ReLU Function, an improved version of the standard ReLU designed to address the Dying ReLU Problem discussed earlier. Let’s go through it in detail:
🔹 What is Leaky ReLU?
Leaky ReLU introduces a small, non-zero slope for negative input values, instead of setting them strictly to 0 (as ReLU does).
Its function is defined as:
𝑓(𝑥)={𝑥if 𝑥≥0
𝛼𝑥if 𝑥<0
Where
α is a small constant, typically 0.01.
🔹 Derivative of Leaky ReLU (from the Slide)
𝑓′(𝑥)={1}
if 𝑥≥0
0.01 if 𝑥<0
For positive inputs, the derivative is 1.
For negative inputs, the derivative is 0.01 (small, but not zero).
🔹 Advantages Over ReLU
Prevents neurons from “dying,” as they still have a small gradient even when the input is negative.
Allows some learning to occur in the negative domain.
Makes the network more robust and resistant to neuron inactivation.
#22 Limitations of Leaky ReLU (As Mentioned in the Slide)
Inconsistent Predictions for Negative Inputs
The function behaves differently on the negative side with a fixed small slope (e.g., 0.01). This can cause:
Slight unpredictability in how the model responds to negative input values.
Instability if those small values influence predictions too much in certain architectures.
Slow Learning on Negative Side
Since the gradient in the negative region is very small (0.01), weight updates are minimal during backpropagation.
This slows down the learning for those neurons.
Optimization becomes more time-consuming, especially if many inputs fall in the negative range.
🔹 When to Use Leaky ReLU?
Leaky ReLU is generally a better default choice than standard ReLU when training deep networks, especially if you observe a significant number of inactive neurons.
#23 Parametric ReLU Function",is a variant of the ReLU (Rectified Linear Unit) activation function used in neural networks.Parametric ReLU is an advanced version of the ReLU and Leaky ReLU activation functions designed to improve learning in deep neural networks.
💡 Standard ReLU:
f(x)=max(0,x)
Outputs 0 for negative inputs.
Can lead to "dead neurons" where the neuron never activates (i.e., always outputs 0).
💡 Leaky ReLU:
𝑓(𝑥)=max(𝑎𝑥,𝑥)
,
where
𝑎
is a small constant like 0.01
Allows a small, non-zero gradient when
𝑥<0
✅ Parametric ReLU (PReLU):
f(x)=max(ax,x)
Key Difference: Unlike Leaky ReLU where
a is fixed,
in PReLU
a is a learnable parameter.
The slope of the negative part
𝑎
a is learned during training through backpropagation.
🔷 Key Points
Gradient Issue Solution:
PReLU addresses the gradient becoming zero on the left (negative input) side by allowing a non-zero, learnable slope.
Learnable Parameter
a:The slope
𝑎
a is not hardcoded. Instead, it adapts as the network learns, allowing the model to optimize performance dynamically.
Use Case:
PReLU is especially helpful when Leaky ReLU does not solve the dead neuron issue adequately.
Dead neurons occur when neurons never activate during training, stalling learning.
Limitation:
Performance can vary depending on the problem and the learned value of
𝑎
a.
Improper learning of
𝑎
a may lead to suboptimal activation and performance.
🔷 Mathematical Expression:
f(x)=max(ax,x)
When
𝑥>0
f(x)=x
When 𝑥≤0
𝑓(𝑥)=𝑎𝑥 where
a is learned
The graph in the image shows two linear parts:
Positive x-axis:
f(𝑦)=𝑦
f(y)=y (standard ReLU behavior)
Negative x-axis:
f(y)=ay (slope of
𝑎
a, which is learnable)
This shows how the function transitions smoothly from a learned negative slope to a standard ReLU in the positive domain.
🔷 Benefits of PReLU:
Allows the model to learn optimal activation behavior.
Helps in avoiding dead neurons.
More adaptive and flexible than ReLU and Leaky ReLU.
🔷 Drawbacks:
Introduces additional parameters to learn (the slope
𝑎).
May lead to overfitting if not regularized properly.
Needs careful initialization and training to ensure stability.
#24 Exponential Linear Unit (ELU) is an advanced activation function designed to improve learning by addressing the limitations of ReLU (Rectified Linear Unit) and Leaky ReLU. It introduces an exponential component for negative values, which helps to push the mean activations closer to zero and maintain stronger gradients.
📘 Definition:
The ELU function is defined as:
𝑓(𝑥)={𝑥if 𝑥>0
x=𝛼(𝑒𝑥−1)
if 𝑥≤0
x: Input to the activation function.
α: A hyperparameter that controls the value to which an ELU saturates for negative net inputs. Commonly
𝛼=1
📊 Graph Characteristics:
For positive values, ELU behaves like the identity function (like ReLU).
For negative values, it smoothly curves toward
−α instead of going flat (like in ReLU) or being linear (as in Leaky ReLU).
The function is continuous and differentiable, making it suitable for gradient-based optimization.
✅ Advantages of ELU over ReLU and Leaky ReLU:
Feature ELU Benefit
Smooth curve Avoids sharp transitions, making training more stable
No dying neurons Unlike ReLU, negative inputs still have non-zero gradients
Mean closer to zero ELUs push the mean activation toward zero, improving learning efficiency
Better convergence Faster and more reliable training in deep networks
⚠️ Drawbacks of ELU:
Computationally expensive due to the exponential function (especially on hardware without acceleration).
Requires tuning of the
α parameter.
May still cause vanishing gradients if improperly used.
💡 When to Use ELU:
When you observe slow convergence or dead neurons with ReLU.
In deeper networks where zero-centered activations are beneficial.
When using batch normalization is not ideal or introduces extra complexity.
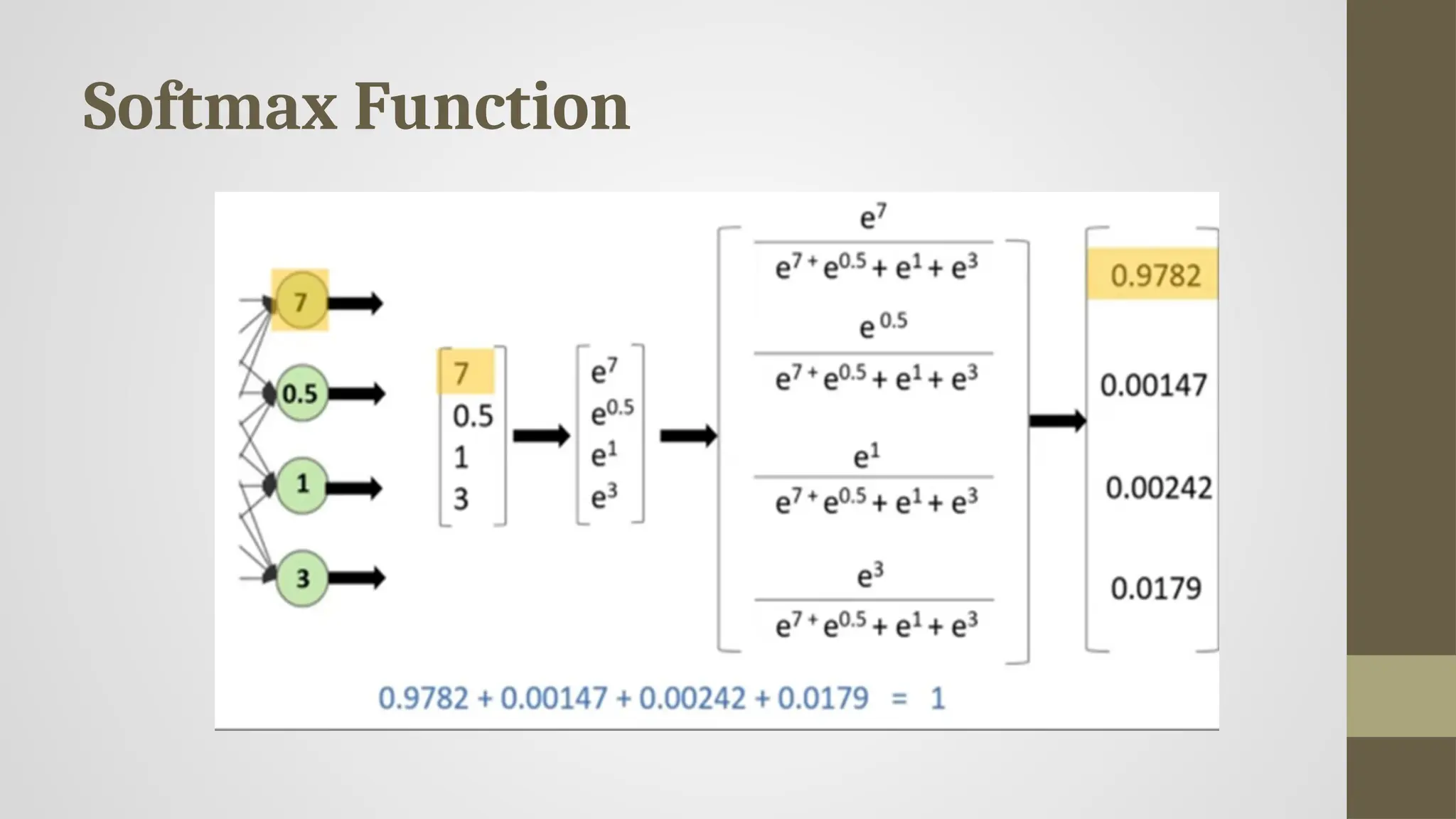
#25 The Softmax function is a mathematical function that converts a vector of raw scores (logits) into probabilities, which sum to 1. It's particularly useful when your neural network needs to classify inputs into multiple categories.
🔢 Softmax Formula:
softmax(𝑧𝑖)=𝑒𝑧𝑖∑𝑗𝑒𝑧𝑗
Where:
𝑧𝑖 is the raw score (logit) for class 𝑖
The denominator sums over all logits 𝑧𝑗
The result is a value between 0 and 1 that represents the probability of class 𝑖
✅ 1. Built on the Sigmoid Function:
The sigmoid function outputs a value between 0 and 1:
Sigmoid is useful for binary classification because it maps any real number to a probability.
The Softmax function uses sigmoid however to multiple classes or output.
✅ 2. Outputs Relative Probabilities:
Softmax doesn't just output probabilities; it compares logits and outputs relative probabilities.
Even if all logits are high, Softmax will normalize them to represent the likelihood of each class.
✅ 3. Common Use Case:
Used in the last layer of neural networks for multi-class classification tasks.
Example: In digit recognition (0–9), Softmax outputs the probabilities for each digit, and the class with the highest probability is chosen.
📊 Graph & Equation in Image:
The graph shows a sigmoid curve, which demonstrates how an input is mapped to a probability.
in the Softmax equation, it shows how it takes the exponent of each input and divides by the sum of all exponents.
This makes sure all outputs are positive and sum to 1, forming a probability distribution.
✅ Why Use Softmax?
Feature Benefit
Probabilistic Output Helps in interpreting the confidence of predictions
Multi-Class Support Suitable for problems with more than 2 classes
Differentiable Allows gradient-based training (backpropagation)
⚠️ Limitations:
Can be sensitive to large input values (can lead to numerical instability).
Outputs can be overconfident when predictions are wrong.
Assumes mutually exclusive classes.
Unlock more with Plus