Download to read offline





![©Microsoft Corporation
Azure
Shared under NDA
VM size changes:
o 2:1 (Dlv6), 4:1 (Dv6), 8:1 (Ev6) Mem:vCPU ratios
o Dv6 Sizes ranging from 2 to 128 vCPUs, up to 512GiB RAM (D192 size under evaluation)
o Ev6 sizes ranging from 2 to 192vCPU, up to 1,832GiB RAM
Expected improvement vs the previous v5 VMs (depending on a size):
o >15%-20% CPU performance on average measured by SPECInt; >3X L3 cache
o Max remote storage IOPS increase from 80k to 260k with Premium v1 SSDs and 400k with Premium v2 SSDs
o Max remote storage throughput increase from 2.6GB/s to 6.8GB/s (D128) or 12GB/s (E192i)
o 4X Faster local NVMe SSD in read IOPS, +50% local SSD capacity
o Up to 200Gbps network BW
Public Preview Plan (subject to change)
o Preview from July 2024 in US East & US West regions
o Attend preview by filling out this survey
o VM specifications
[Intel] Dlv6, Dv6, Ev6 VMs based on Intel Emerald Rapids CPU](https://image.slidesharecdn.com/acceleratingedaworkloadsonazurebestpracticeandbenchmarkonintelemrcpu-241125025129-d3fe6e6d/85/Accelerating-EDA-workloads-on-Azure-Best-Practice-and-benchmark-on-Intel-EMR-CPU-pdf-12-320.jpg)





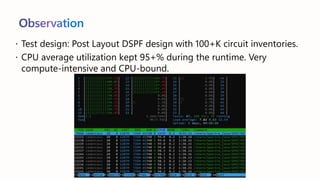
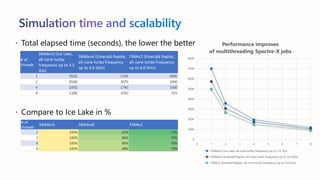
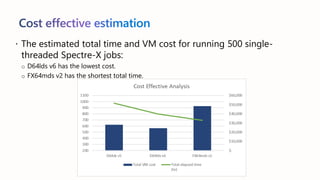



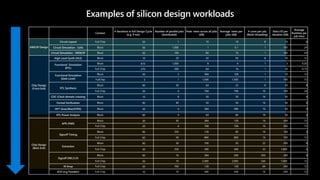
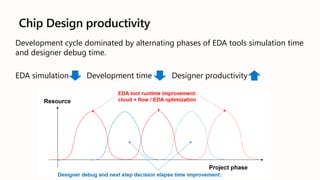
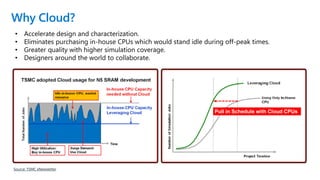
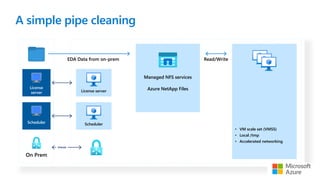
The document presents best practices for running electronic design automation (EDA) workloads on Azure using Intel's latest 5th generation Xeon processors, showcasing benchmark results for tools like Synopsys VCS and Cadence Spectre-X. It emphasizes the advantages of cloud computing in accelerating design processes, improving collaboration, and optimizing resource usage compared to in-house CPU setups. Key findings include improved performance metrics, particularly in CPU utilization and simulation speeds, and a detailed discussion on various EDA tools and their functionalities.


































































