
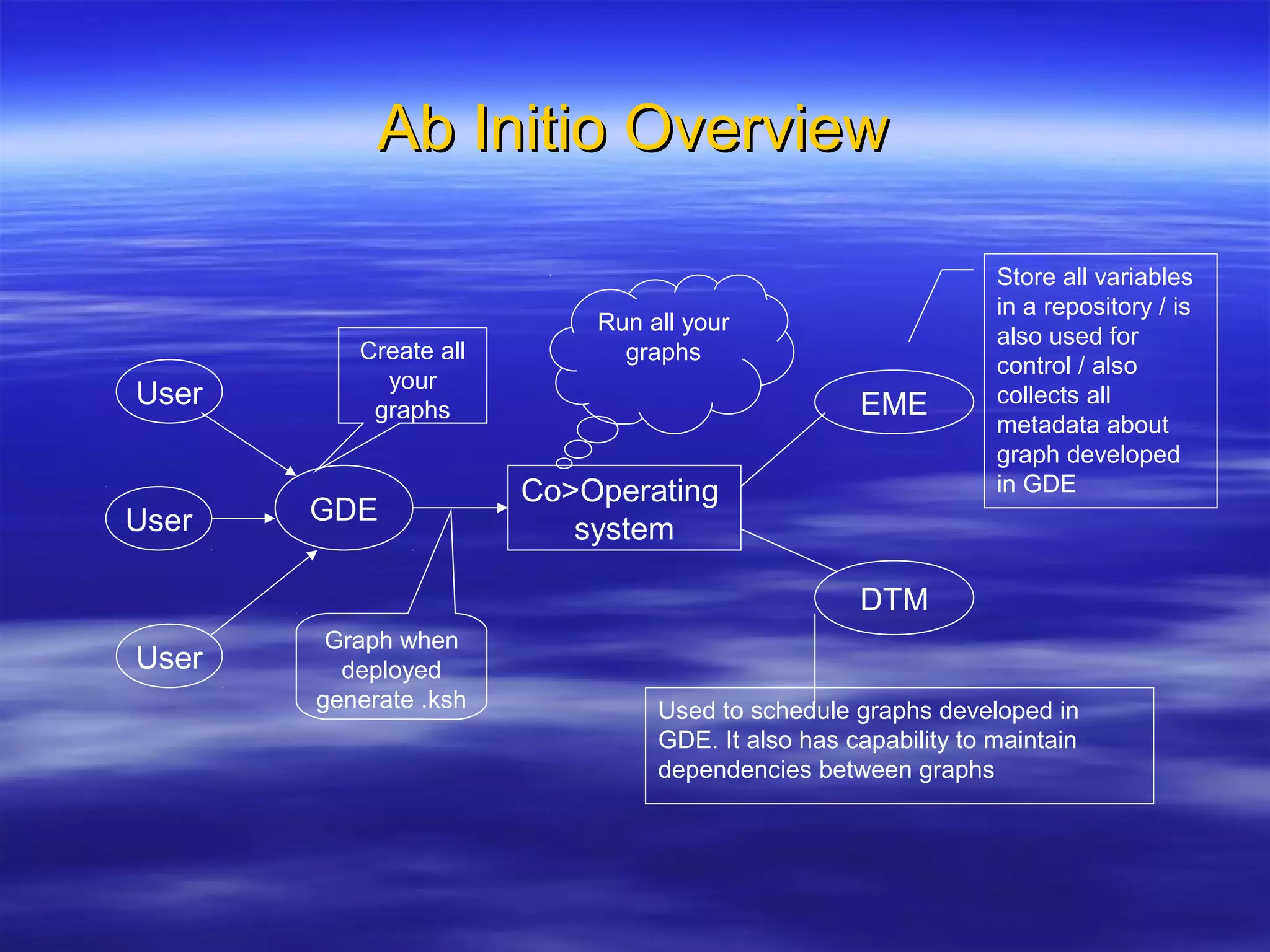


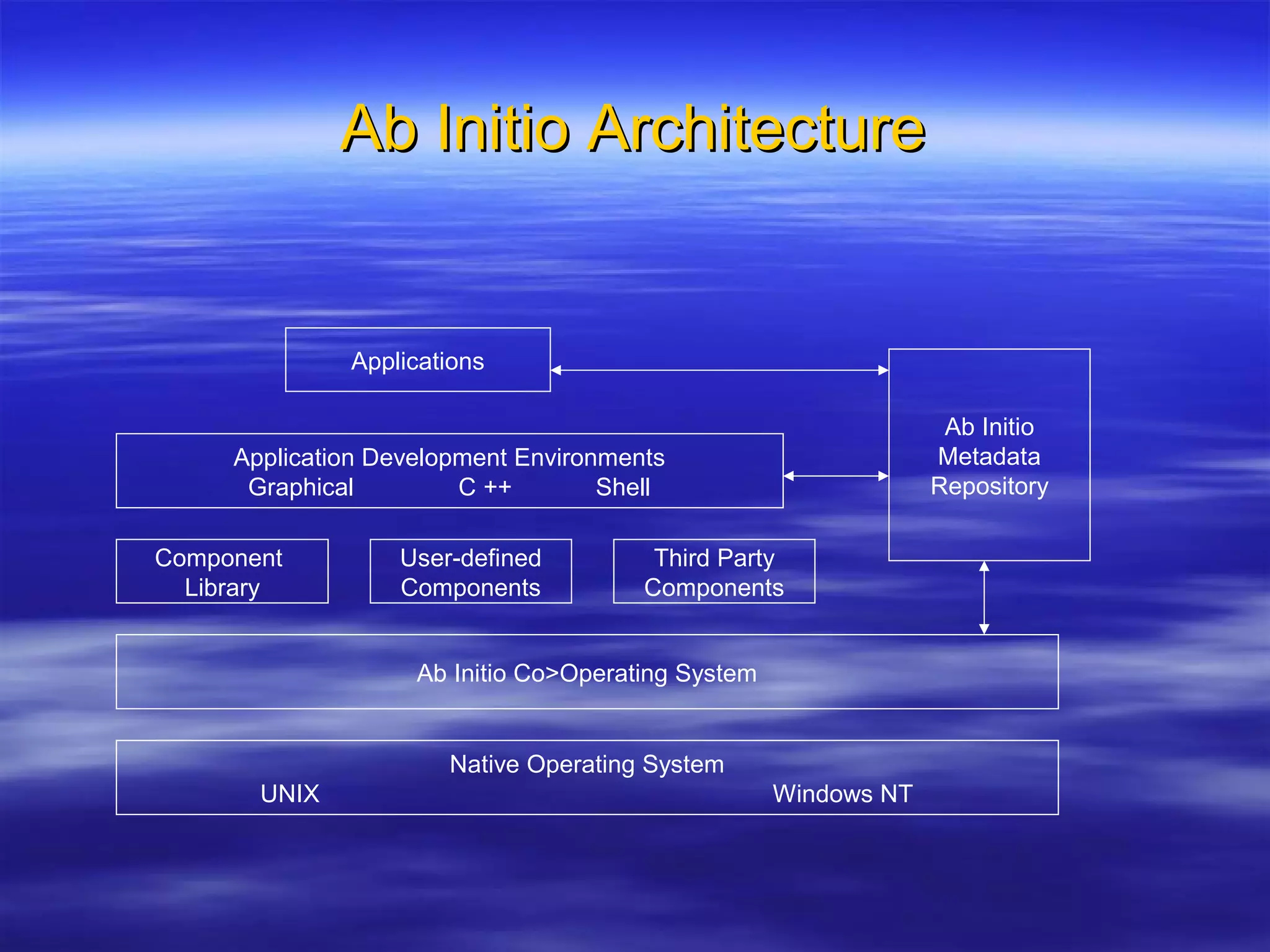






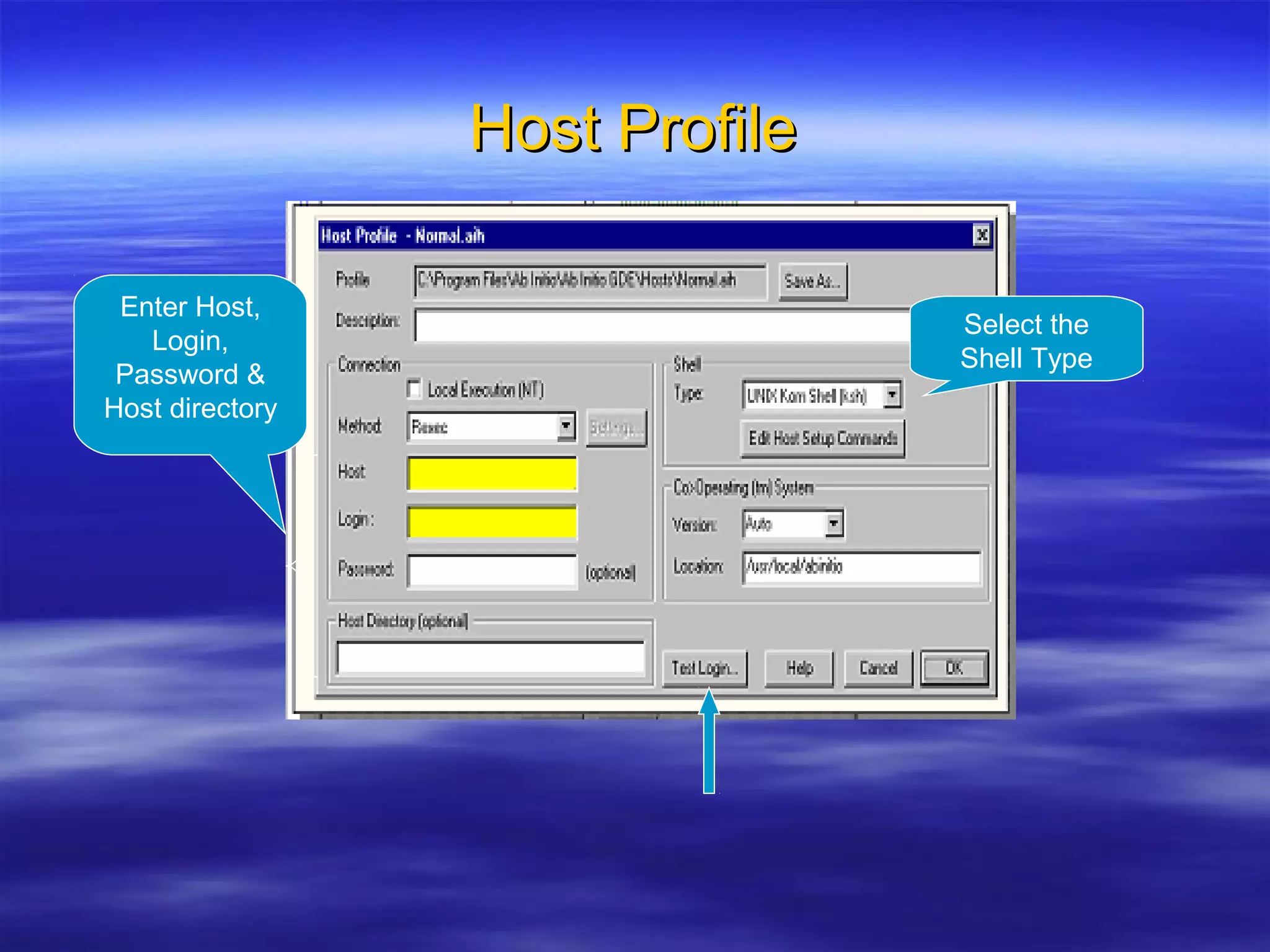
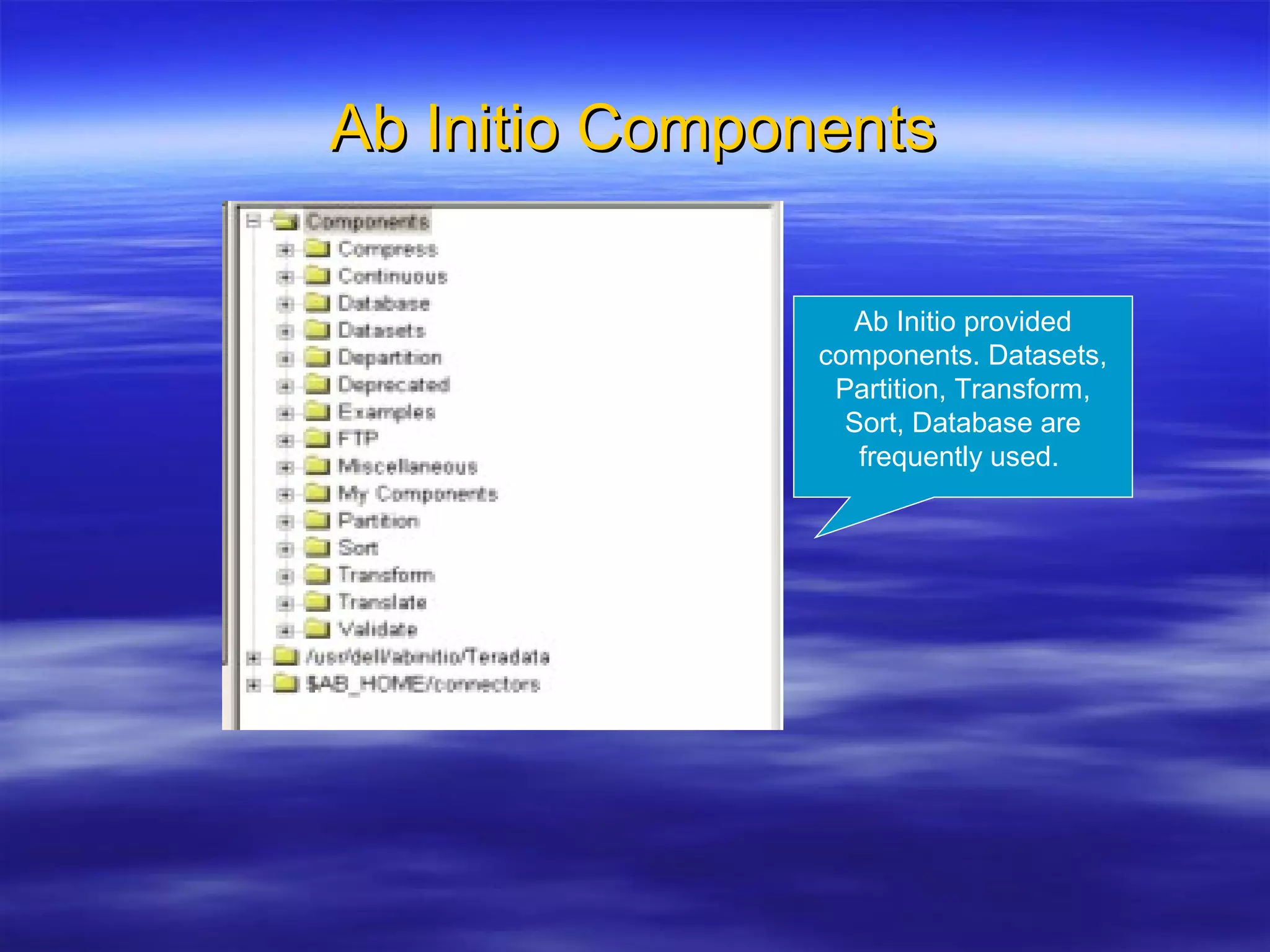
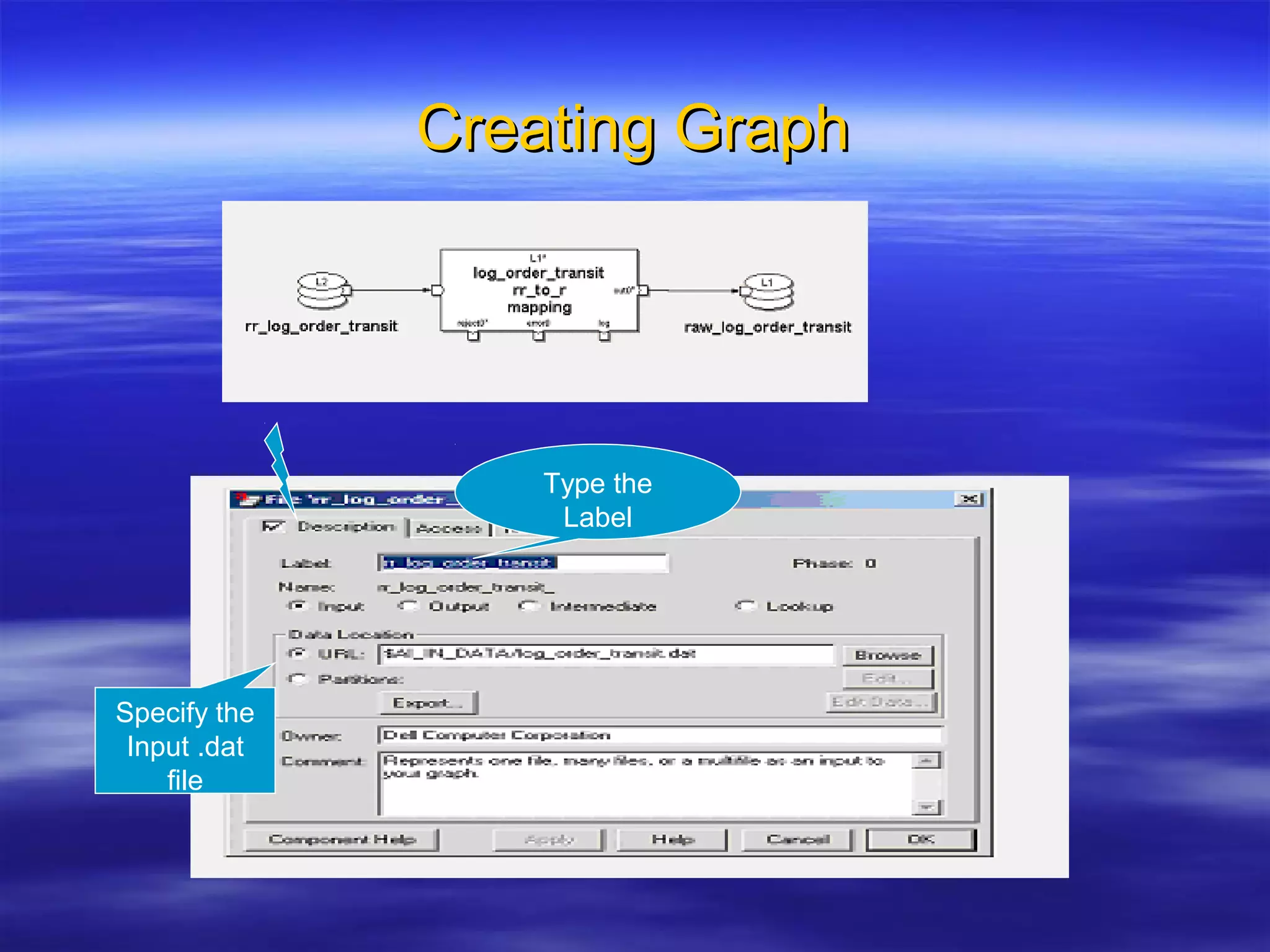
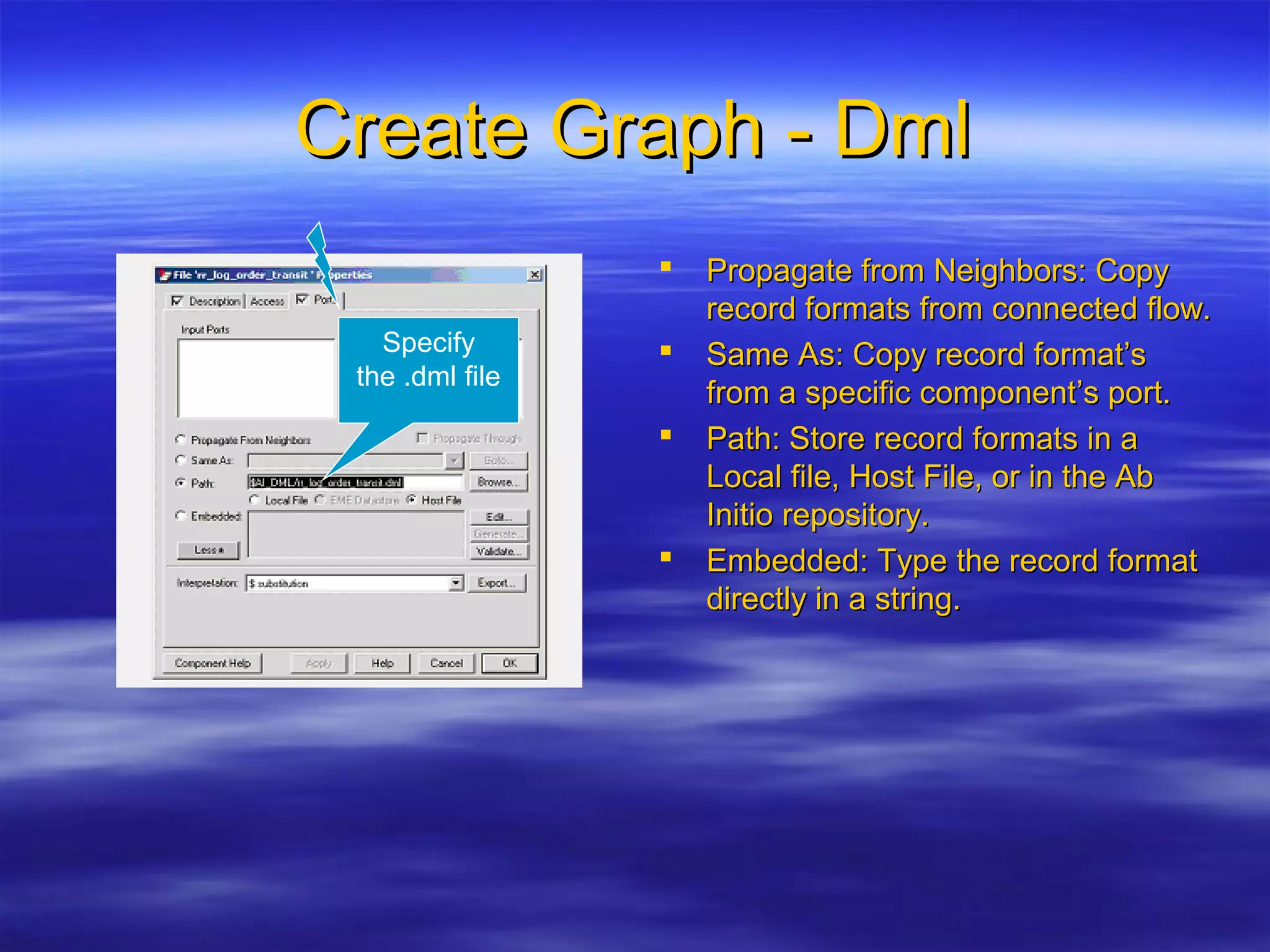
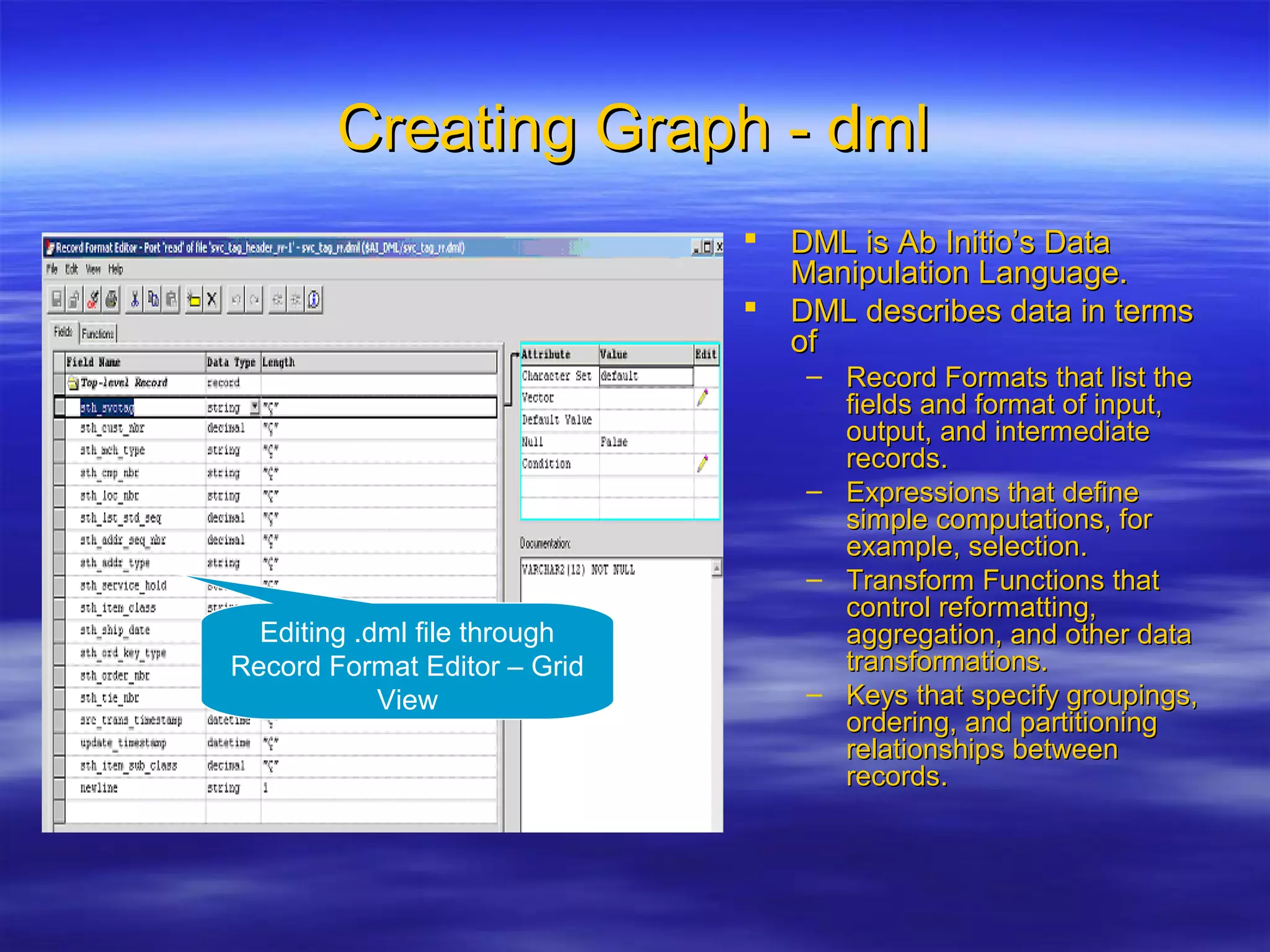
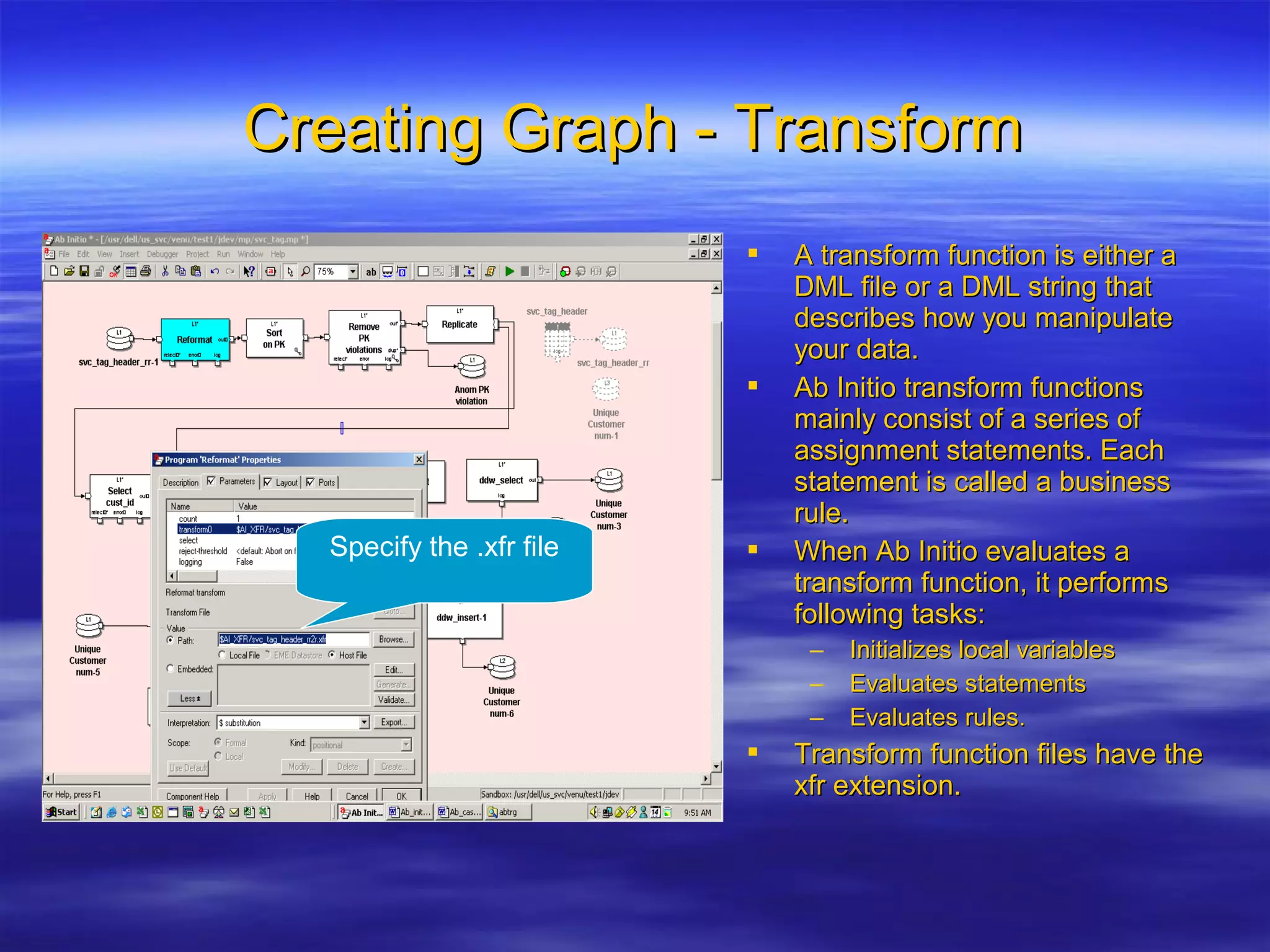
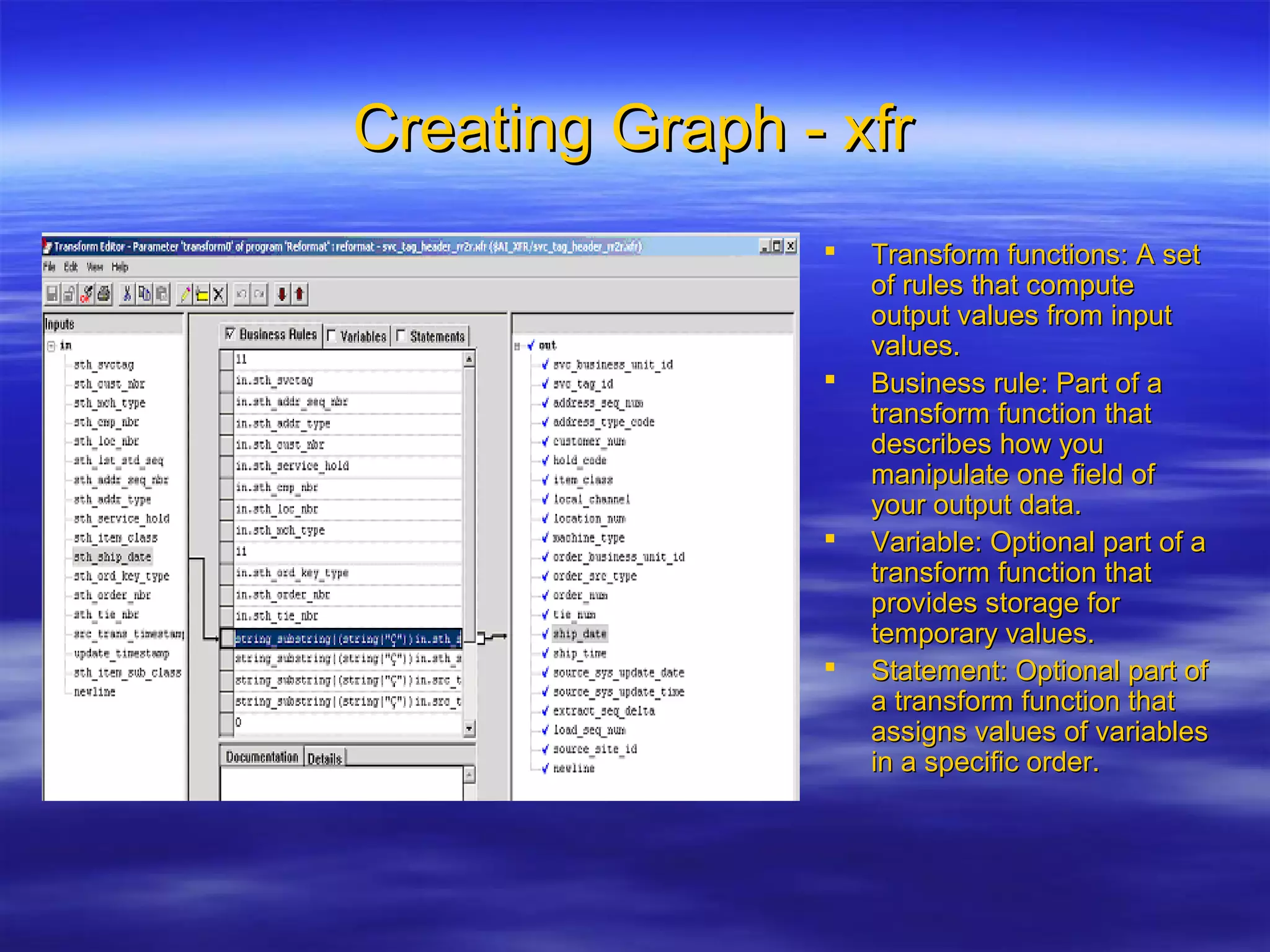

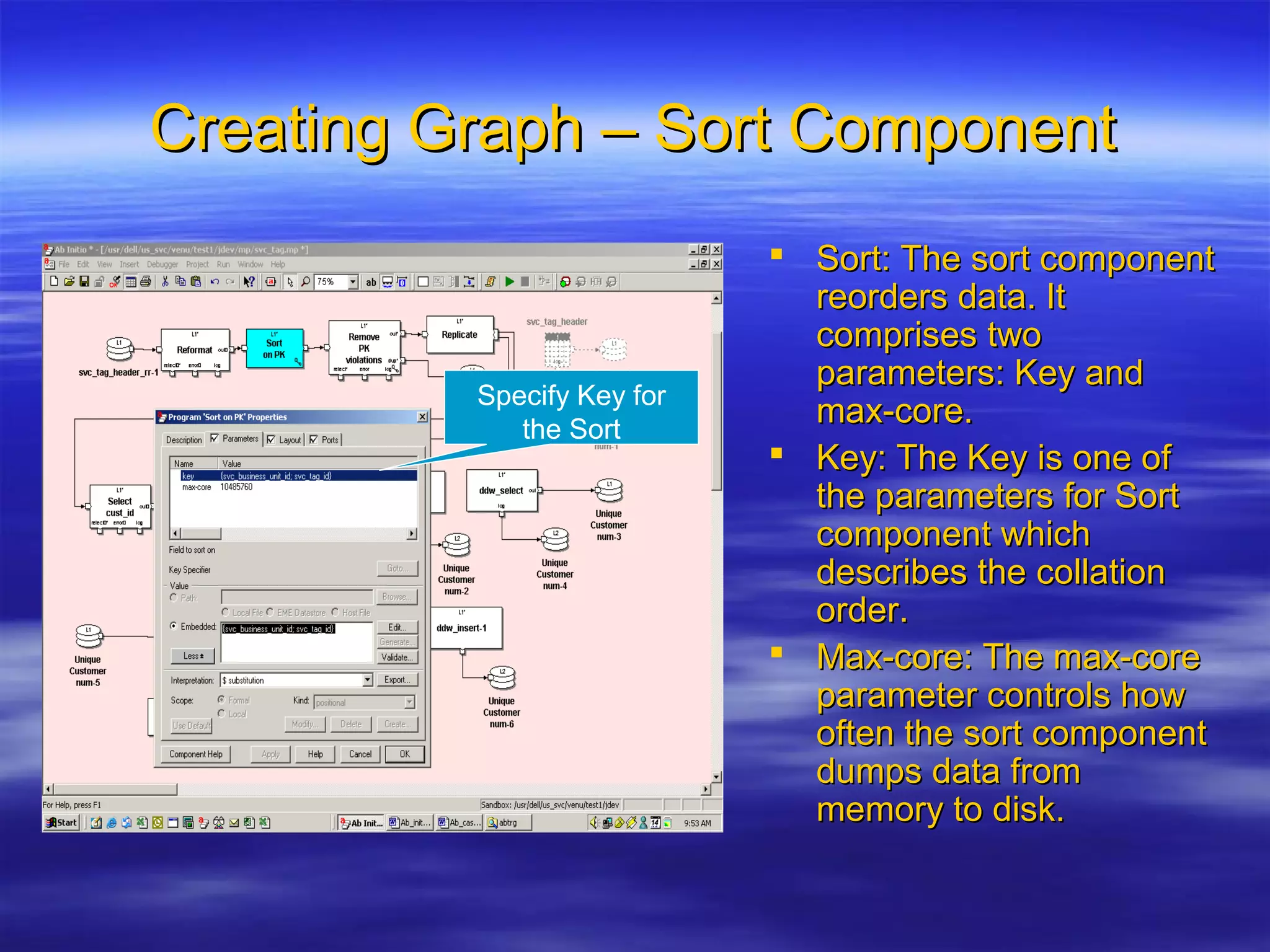
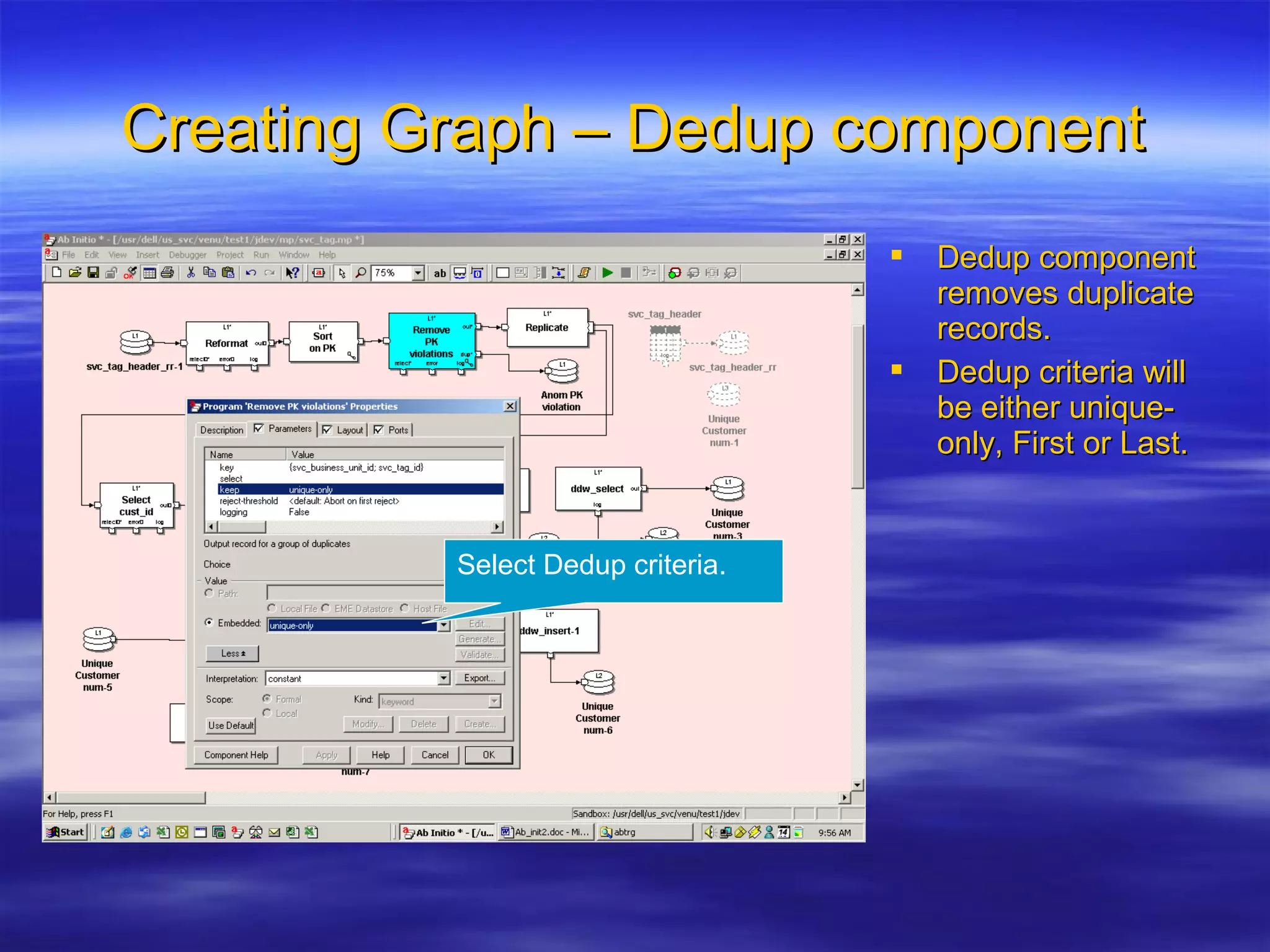
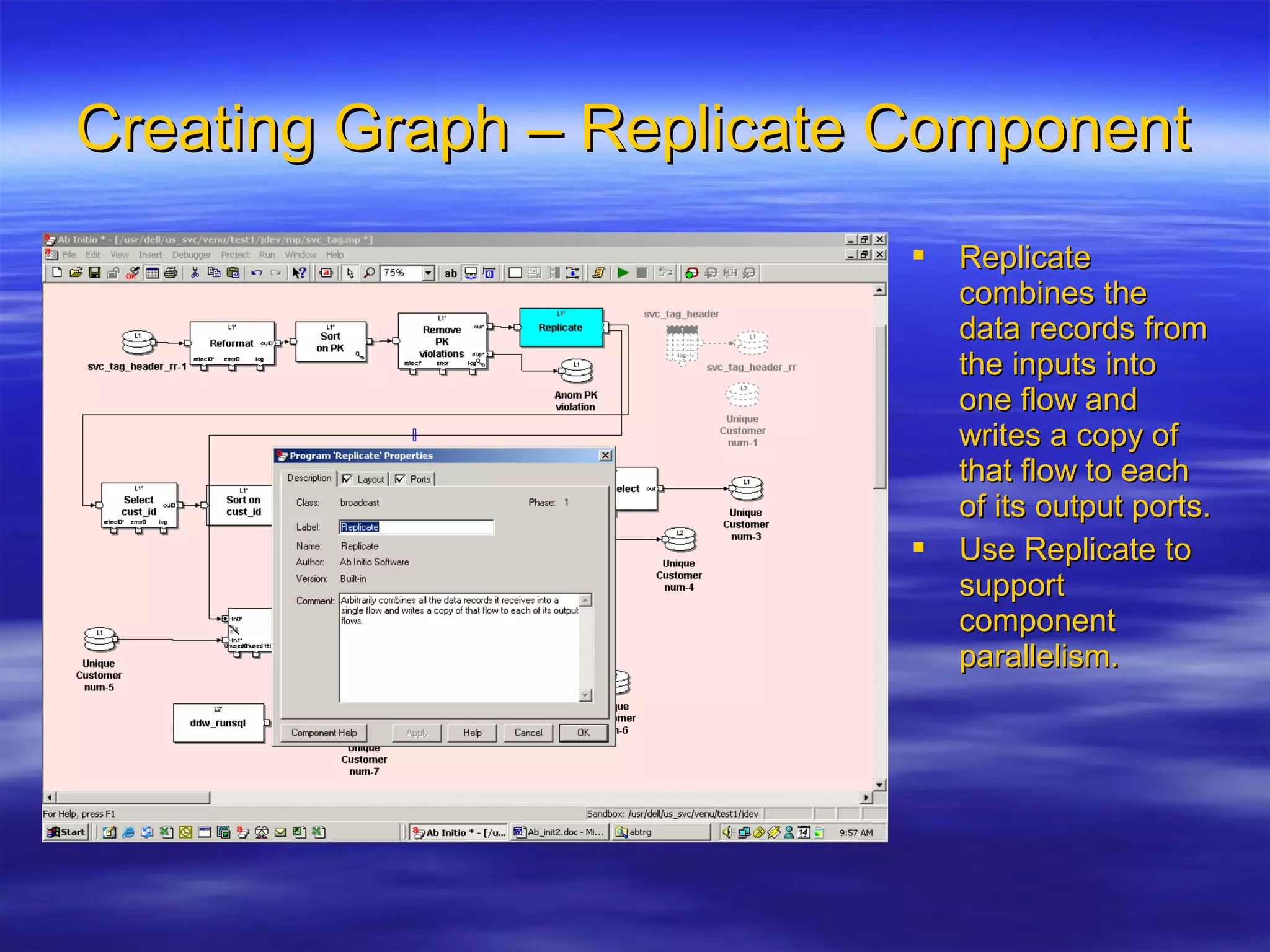
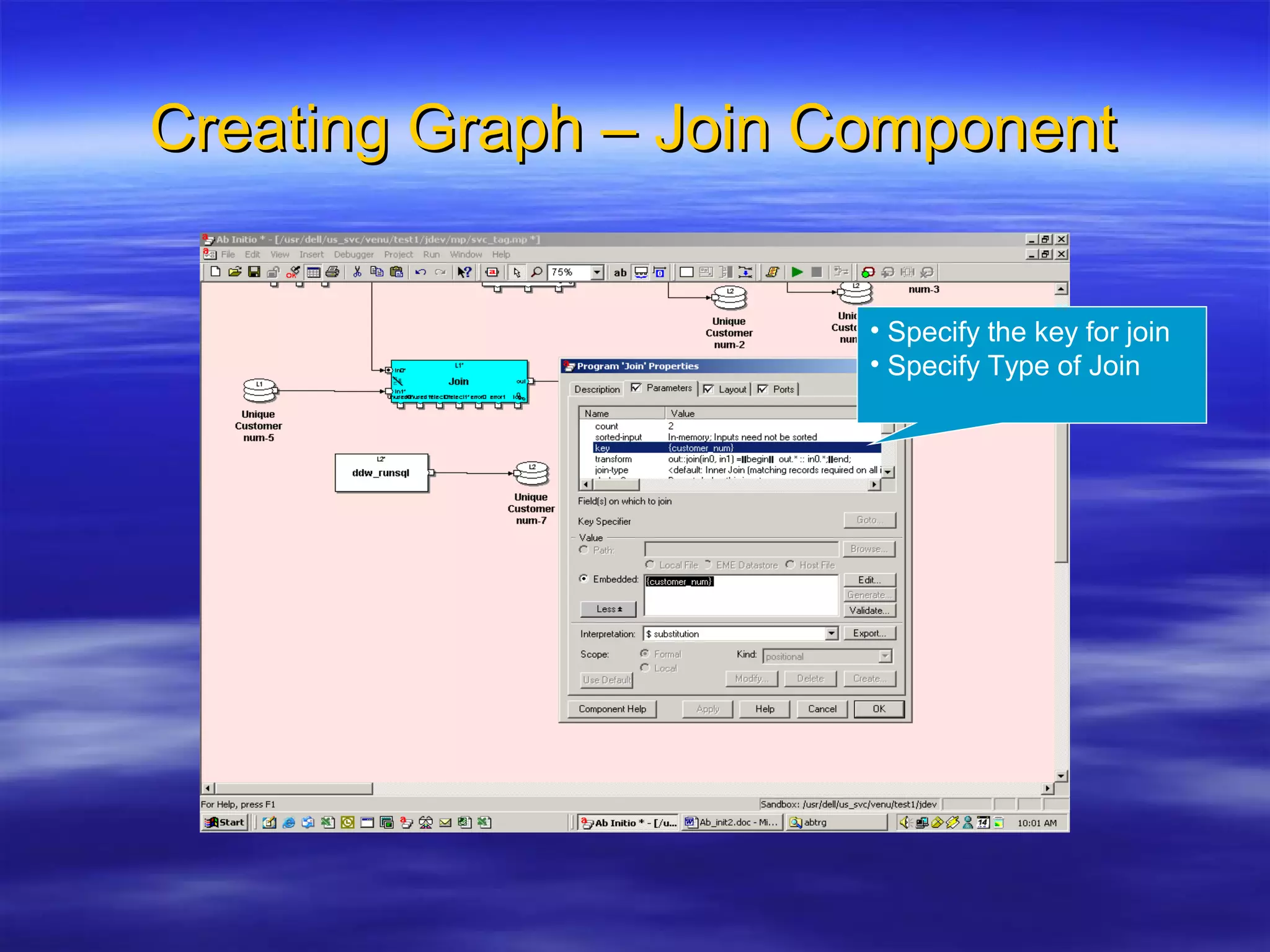





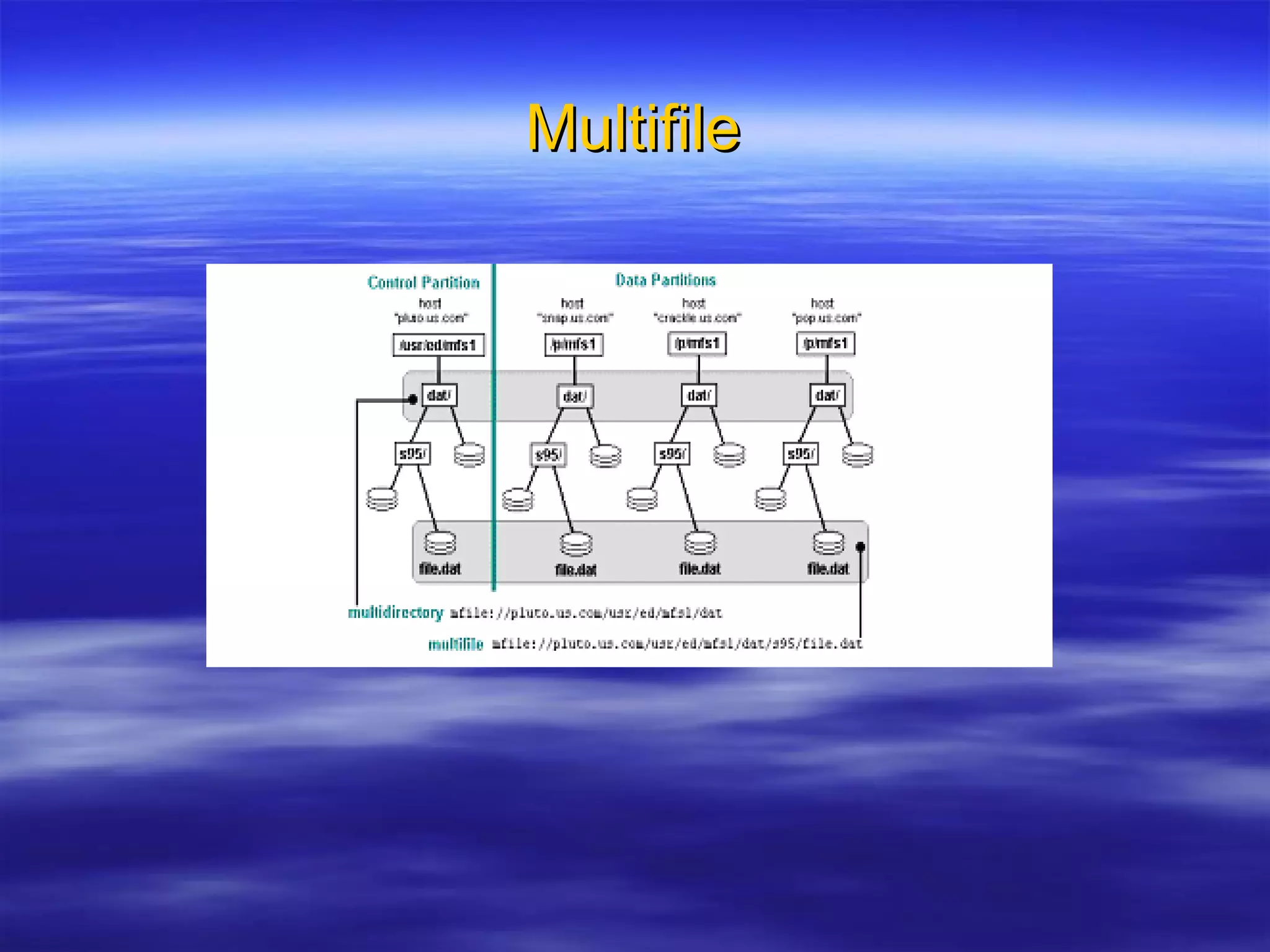


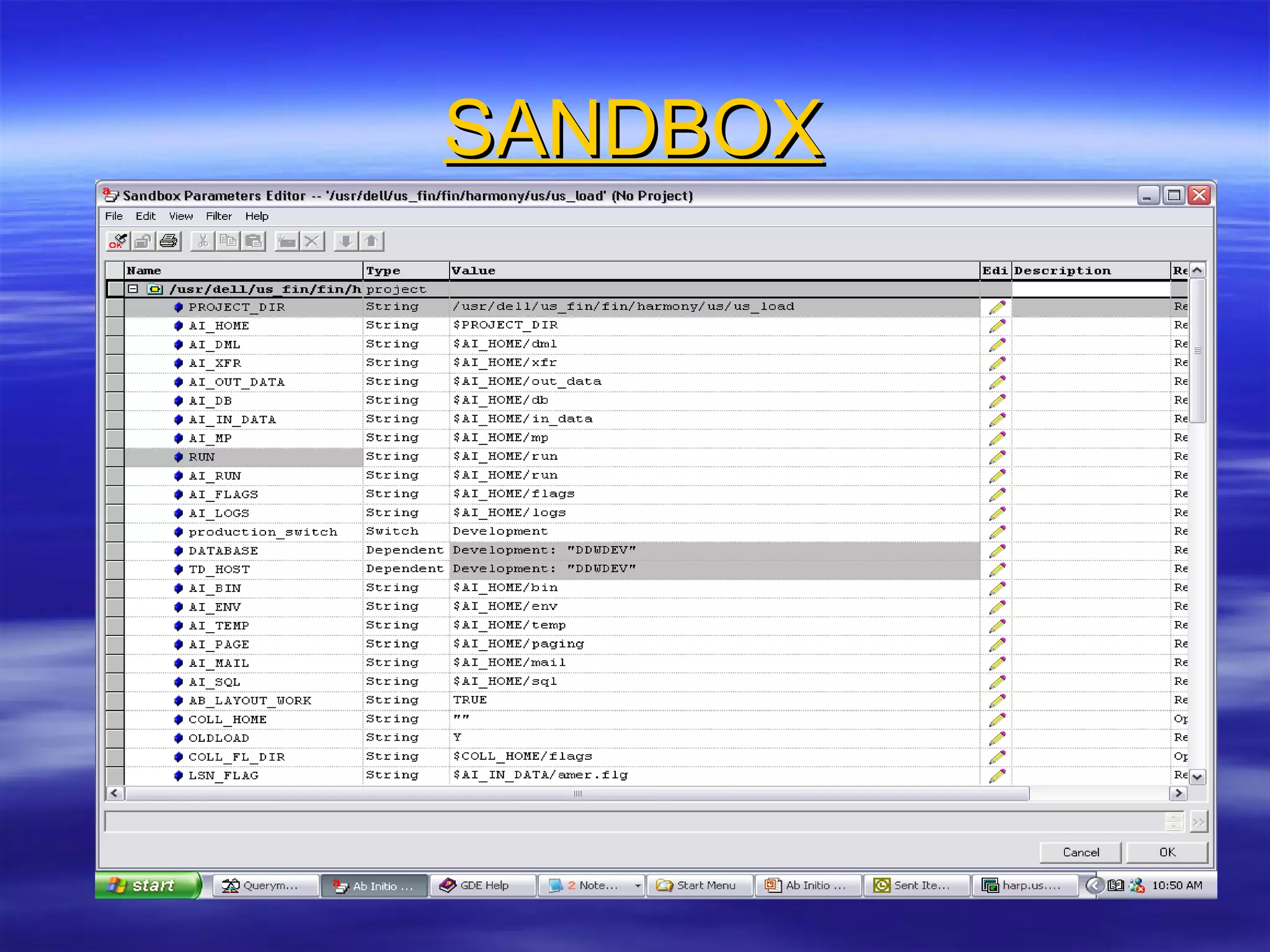


Ab Initio is a versatile data processing platform for enterprise applications that focuses on data warehousing, movement, and analytics, integrating various data sources while providing comprehensive metadata management. Its co>operating system offers scalable performance and reliability across multiple operating systems, facilitating parallel processing and a user-friendly graphical development environment for creating applications. Key functionalities include ETL processes, data transformation, and support for complex data workflows through customizable components and scripts.



















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


