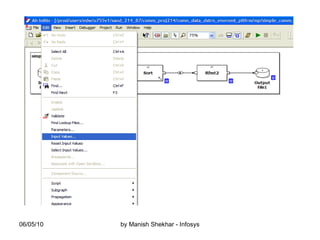
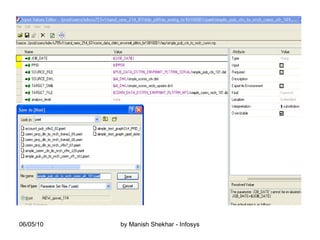
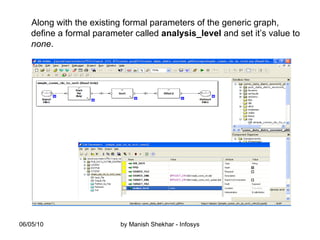
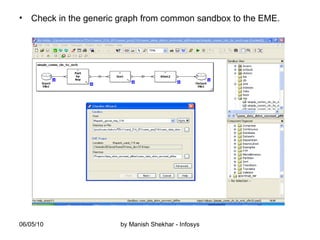
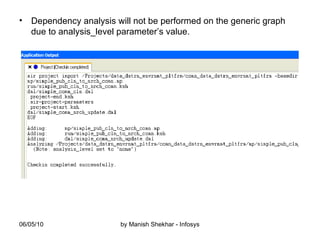
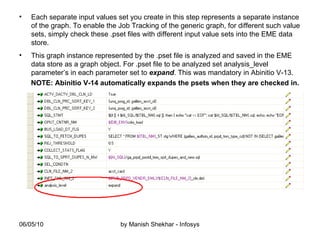
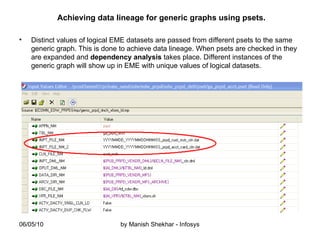
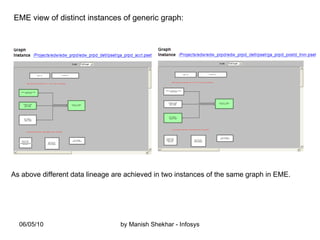
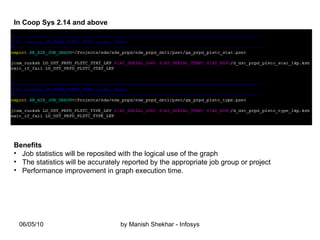
The document outlines the creation and management of parameter sets (psets) in Ab Initio for generic graphs, including how to define parameters, save psets, and achieve data lineage. It details the importance of setting the 'analysis_level' parameter and handling concurrent jobs through unique job identifiers. Additionally, it emphasizes capturing accurate job statistics in the Enterprise Metadata Environment (EME) associated with specific pset instances.