Download as PDF, PPTX





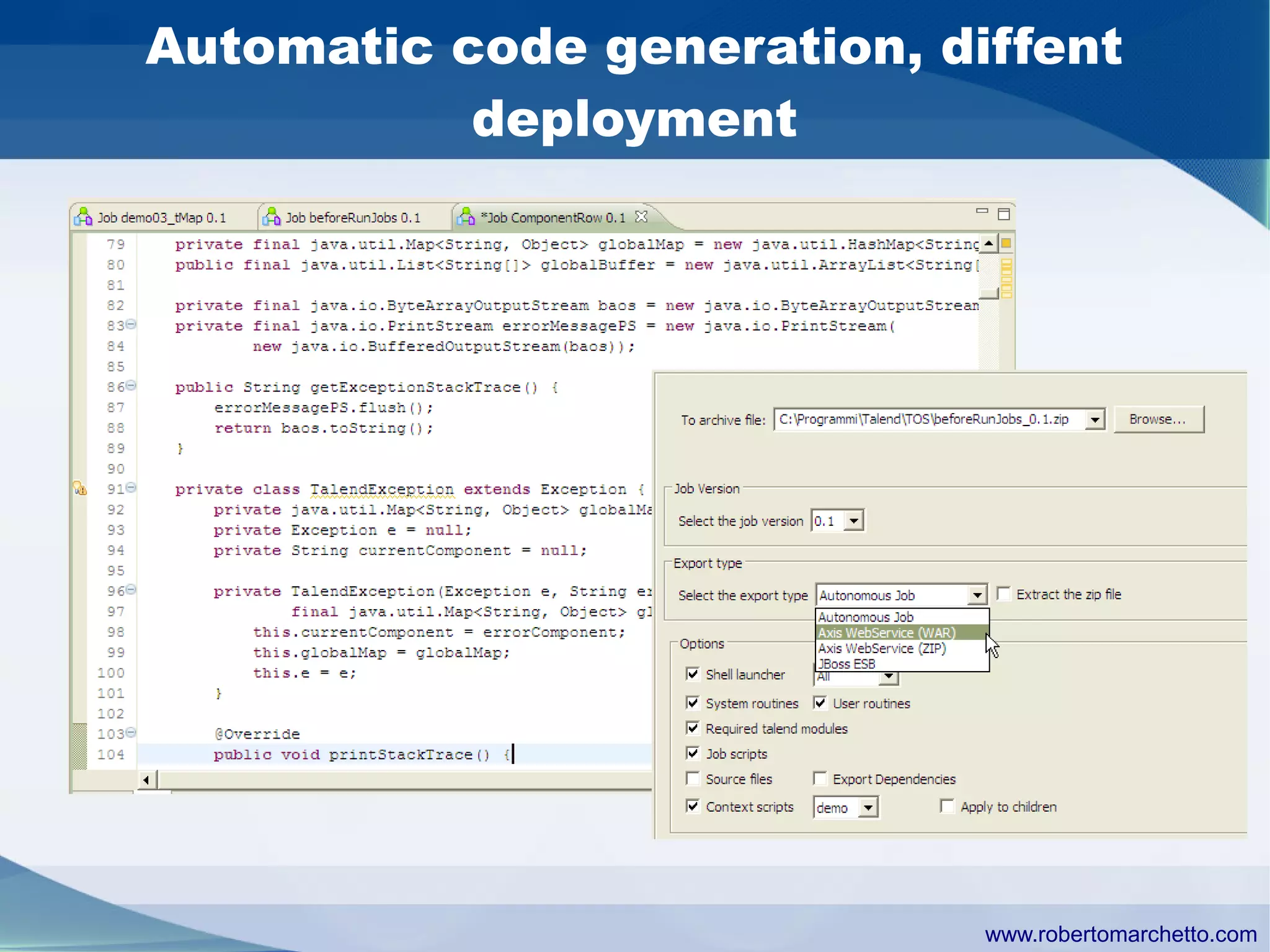

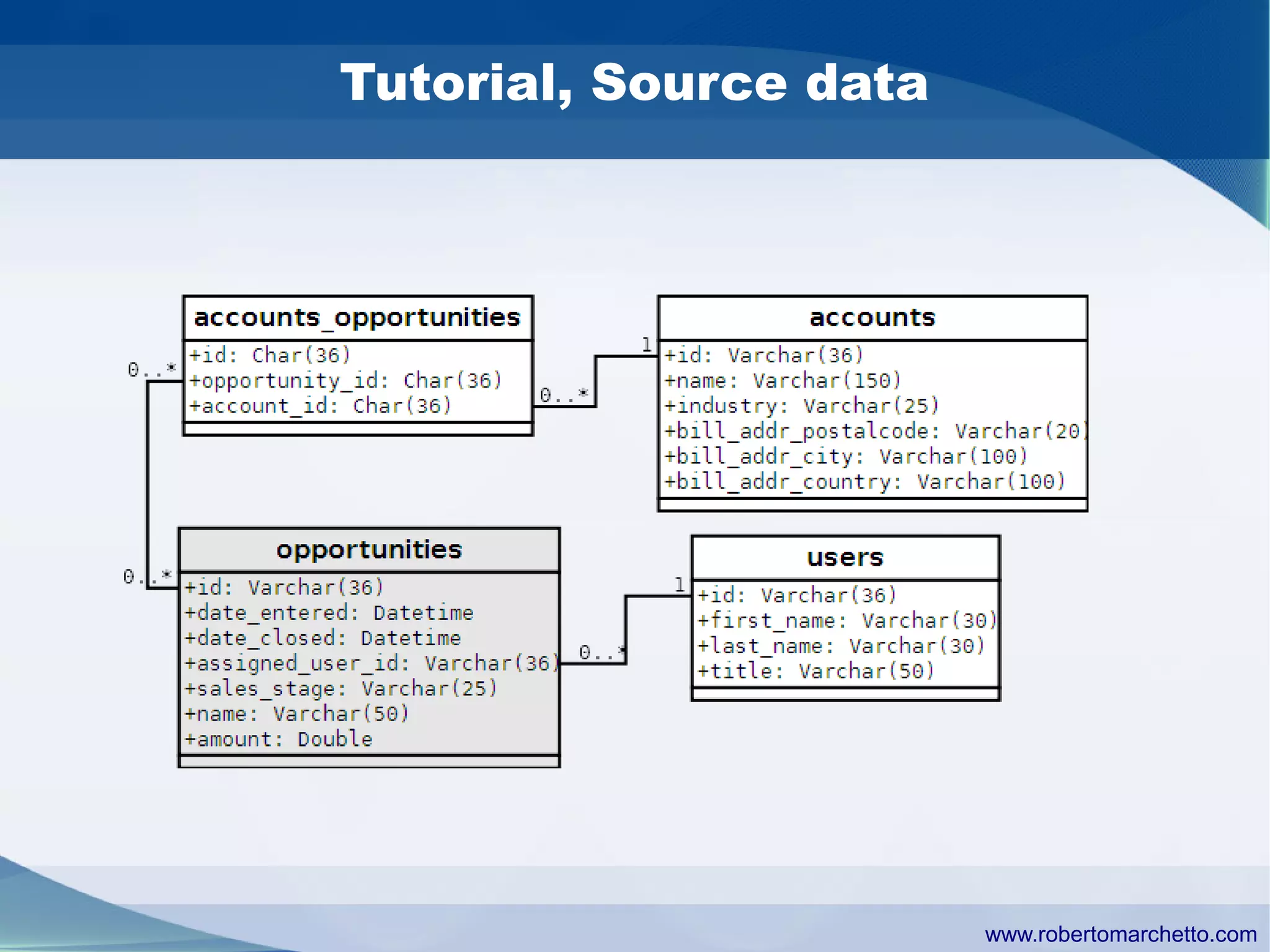
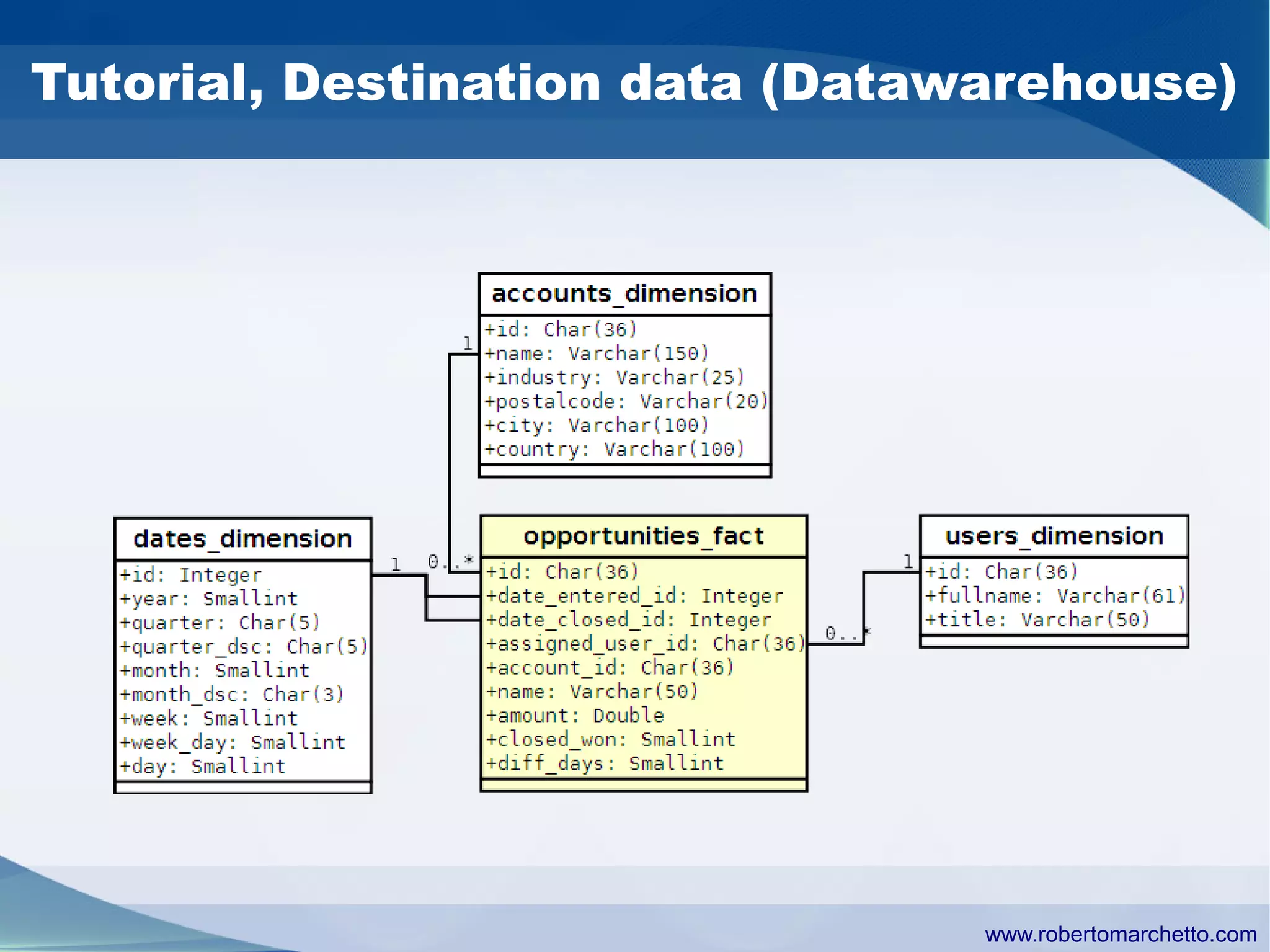


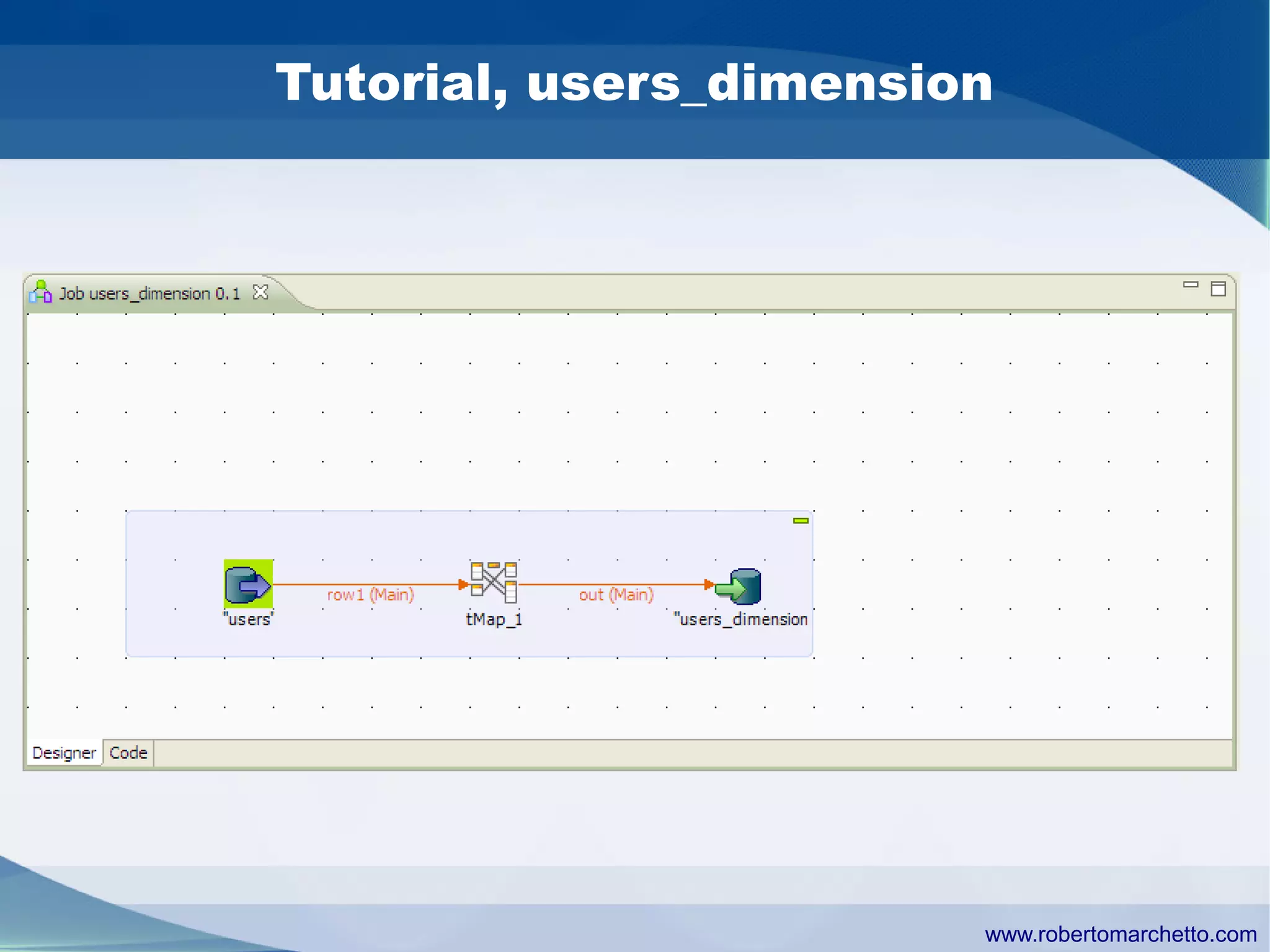
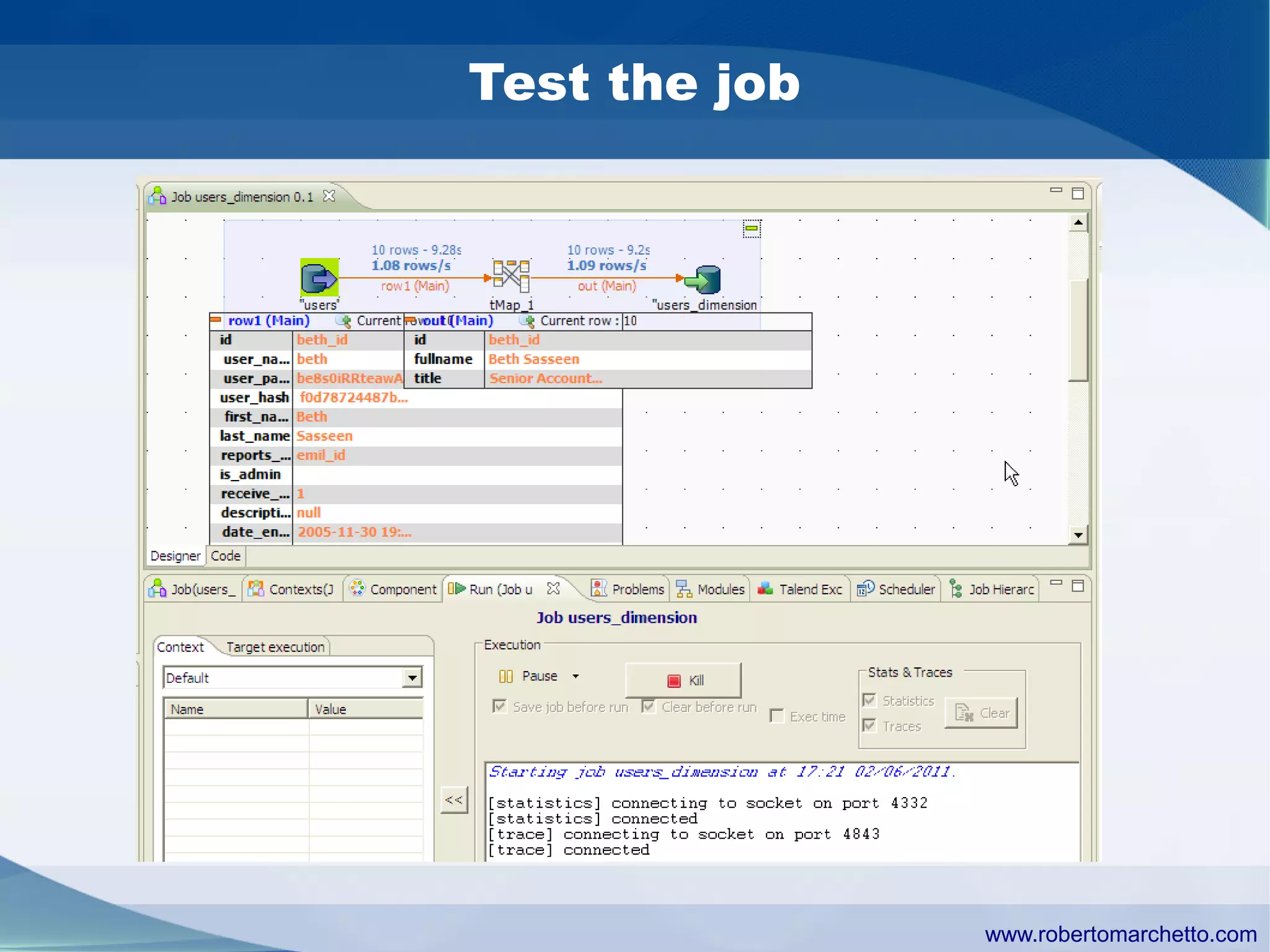
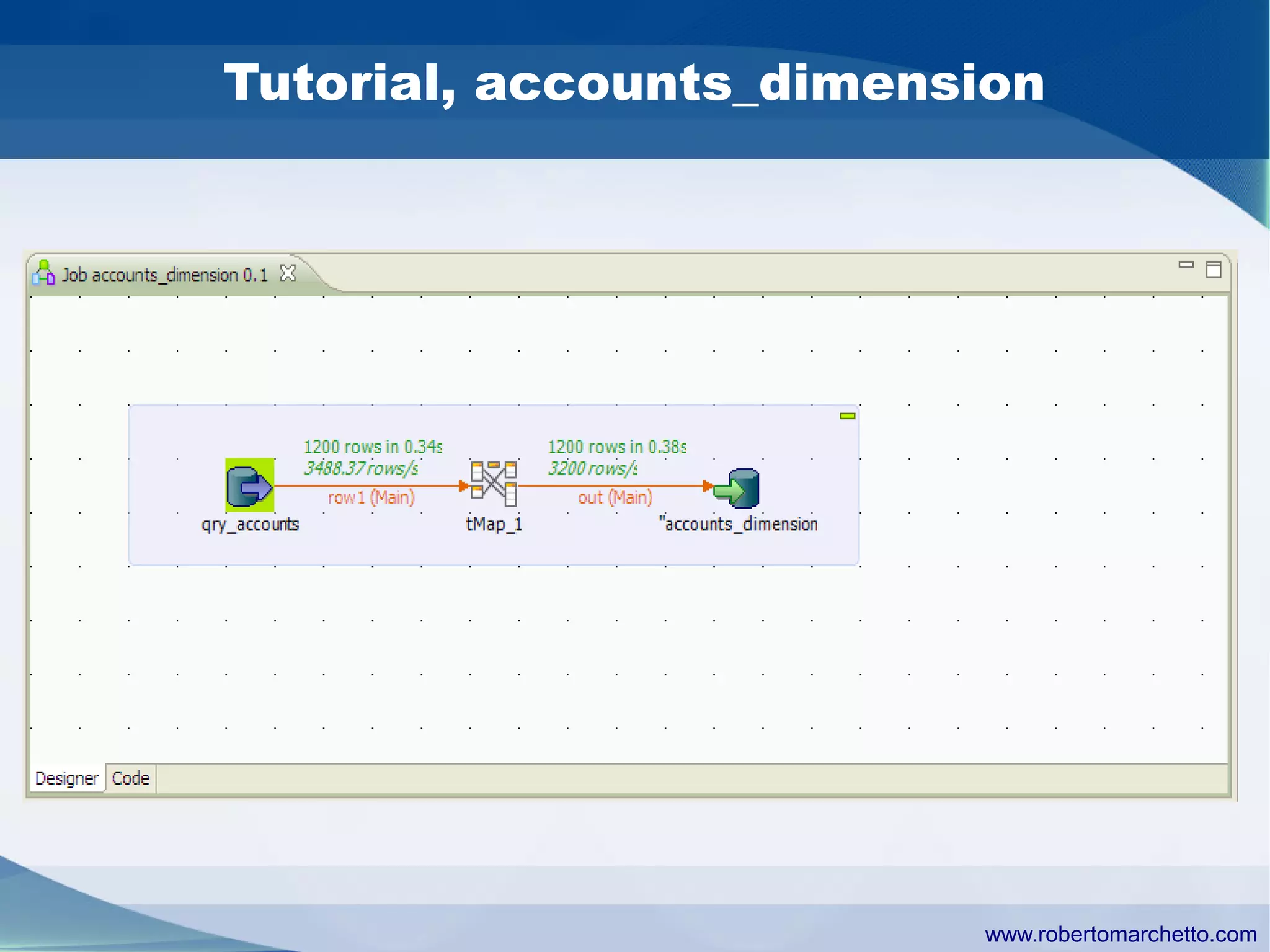

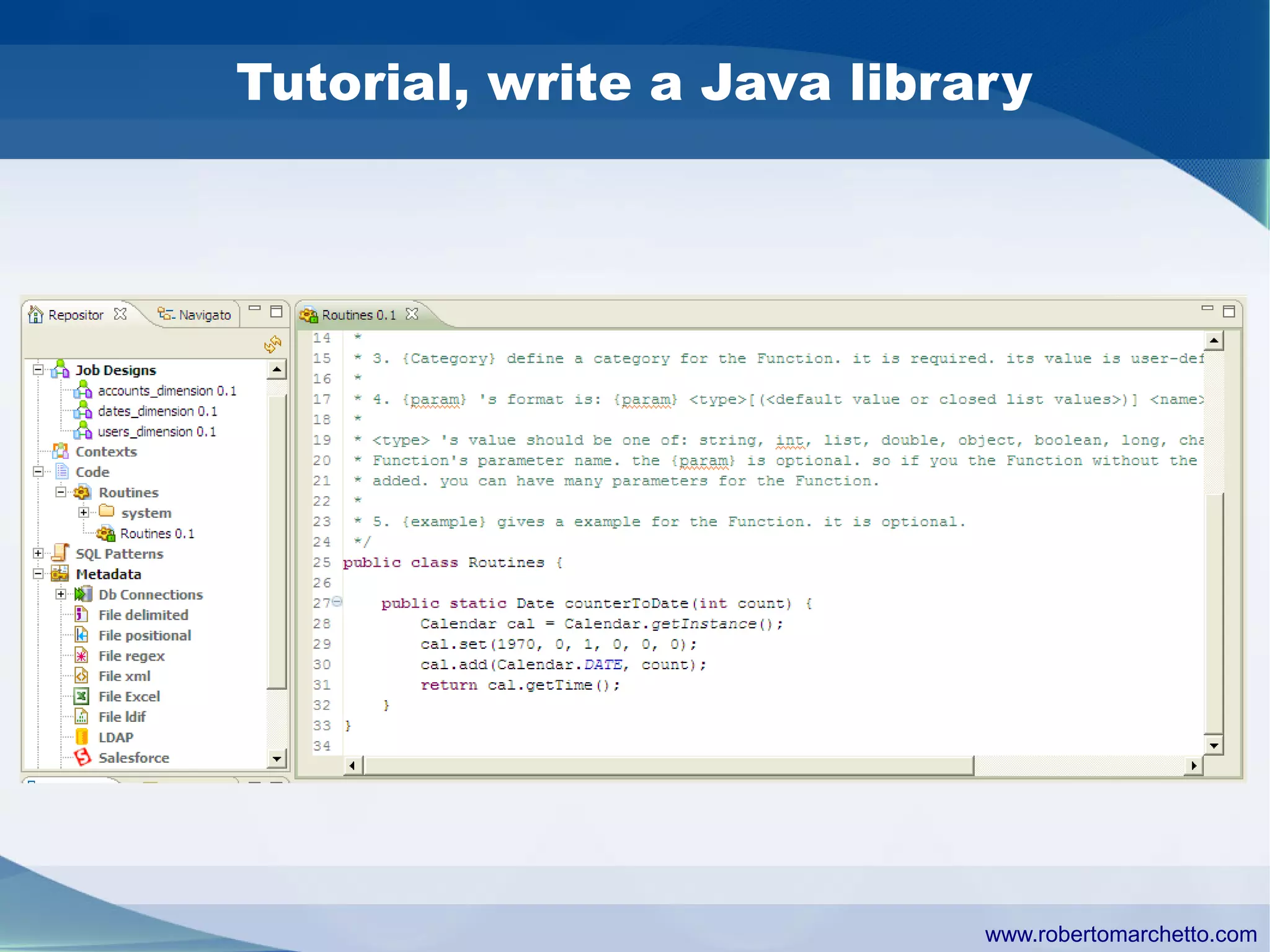
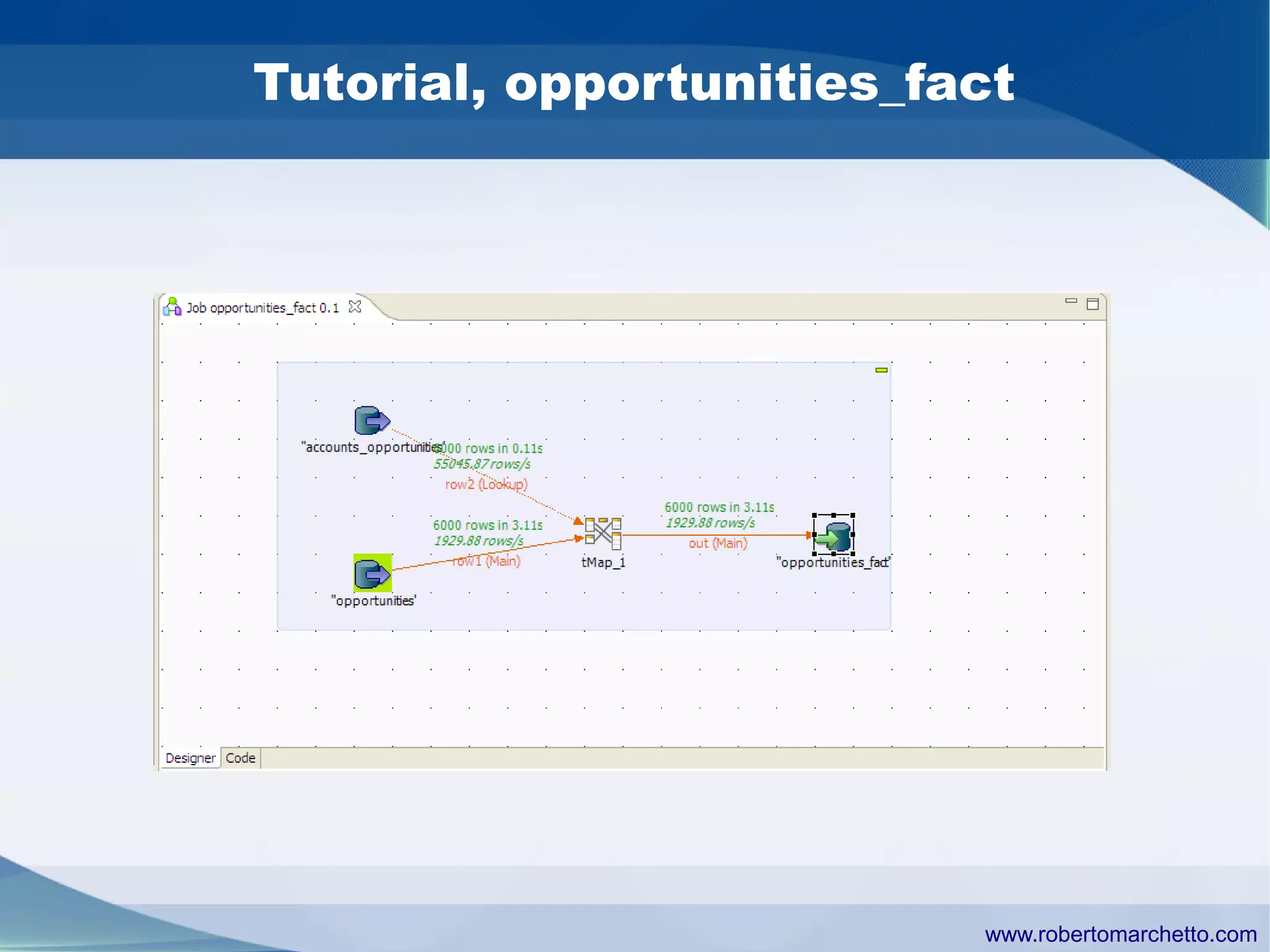







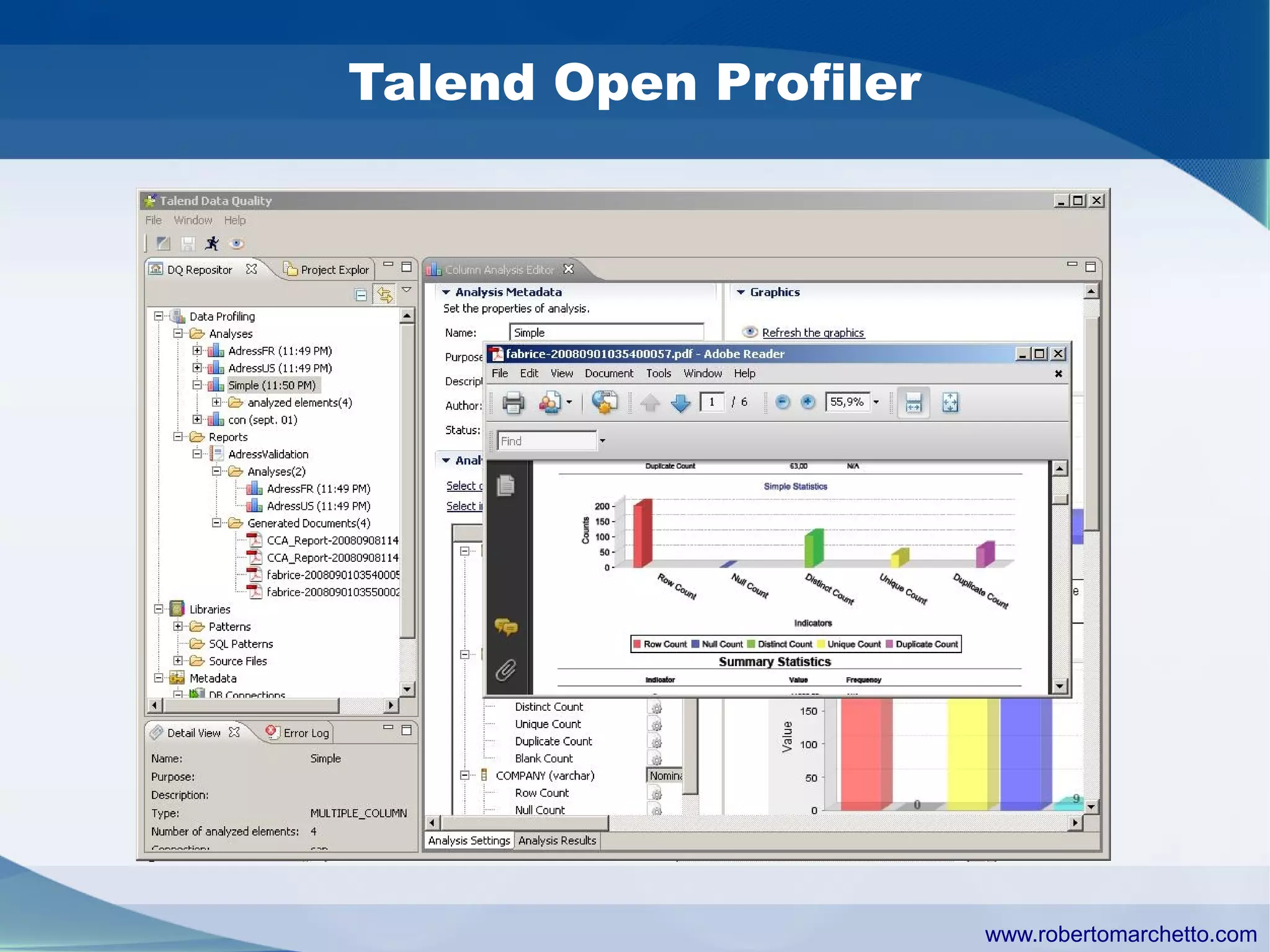


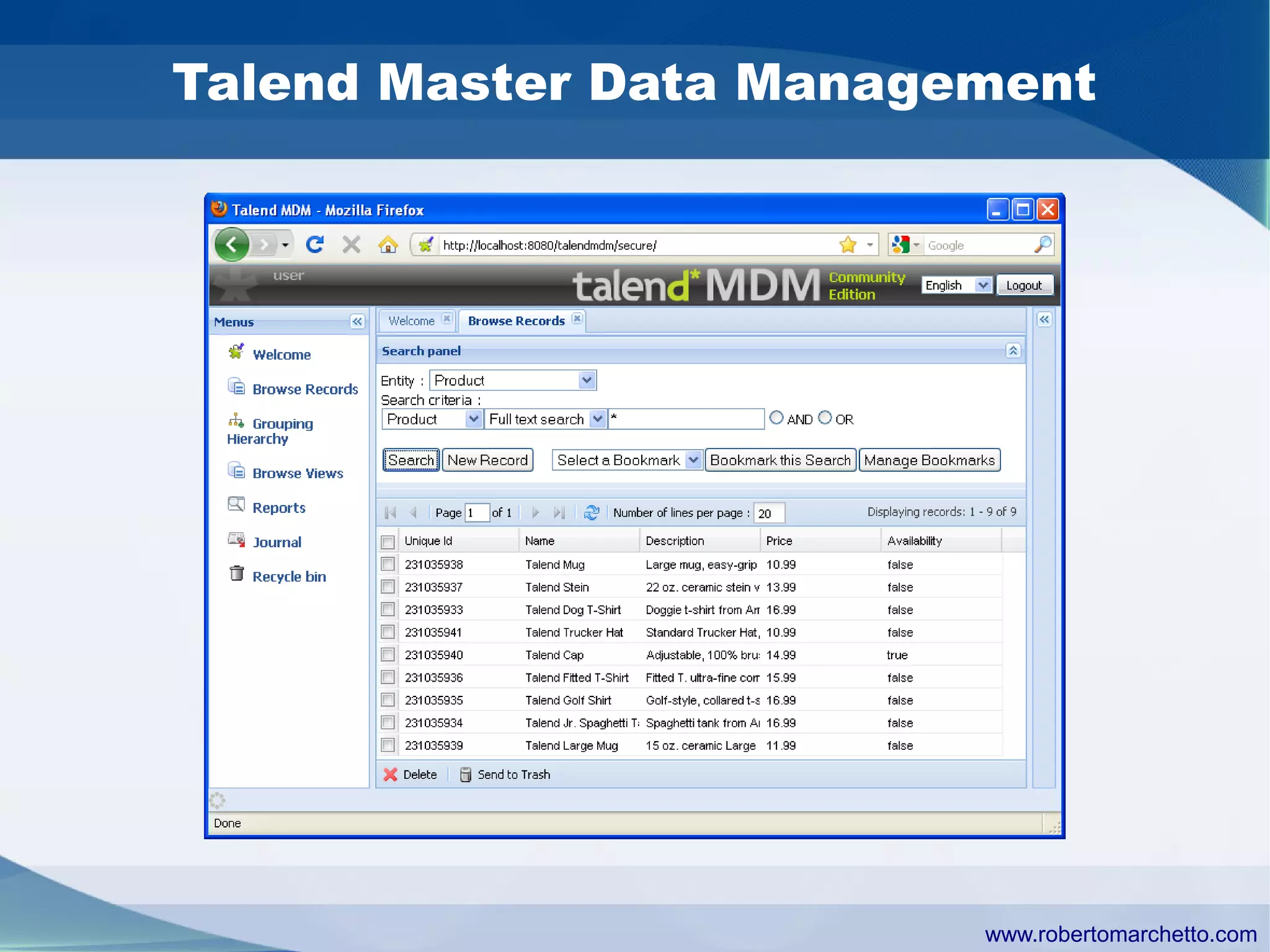

Talend provides data integration and management solutions. It focuses on combining data from different sources into a unified view for users. Talend offers an open source tool called Talend Open Studio that allows users to visually design procedures to extract, transform, and load data between various databases and file types. It also offers features for data quality, storage optimization, master data management, and reporting.













![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)





















































