Download to read offline




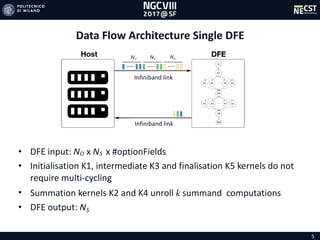
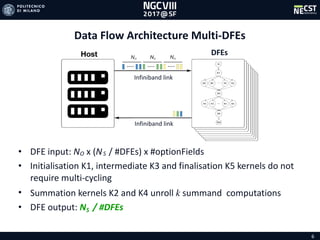

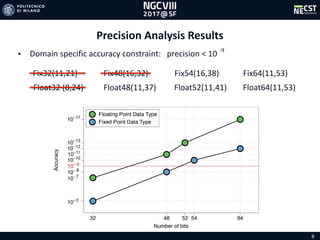
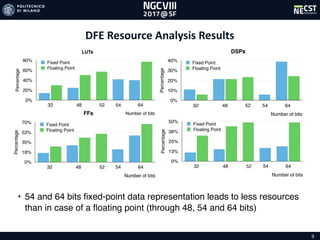






![16
Speedups and Energy Efficiencies
s CPU 48 Cores Single DFE
DataSet30
DataSet780
Tabella 1-1
DataSet30 DataSet780
PU 1 Core 21 400
PU 24 Cores 7 36
PU 48 Cores 8 27
ingle DFE 5 6
s CPU 48 Cores Single DFE
DataSet30
DataSet780
Tabella 1-1-1
DataSet30 DataSet780
PU 1 Core 11 30
PU 24 Cores 7 36
PU 48 Cores 8 27
ingle DFE 11 12
RunTime[s]
1
100
10000
CPU 1 Core CPU 24 Cores CPU 48 Cores Single DFE 8 DFEs
2,181
11,99
238,564240,017
3789,277
1,461,25
10,3310,49
158,81
DataSet30
DataSet780
SocketEnergy[Wh]
1
10
100
CPU 1 Core CPU 24 Cores CPU 48 Cores Single DFE 8 DFEs
8
6
27
36
400
55
87
21
DataSet30
DataSet780](https://image.slidesharecdn.com/asianoption5minpdf-170713144233/85/A-Scalable-Dataflow-Implementation-of-Curran-s-Approximation-Algorithm-16-320.jpg)


This document describes a dataflow implementation of Curran's approximation algorithm for pricing Asian options. The implementation computes the value at risk of a portfolio containing Asian options. It supports an arbitrary number of averaging points and achieves high precision using fixed-point arithmetic. Experimental results show that a single Maxeler dataflow engine can price portfolios over 10 times faster than a 48-core CPU. Further optimization including multi-DFE processing and porting to newer FPGA hardware could improve energy efficiency and performance.























![[Seminar] hyunwook 0624](https://cdn.slidesharecdn.com/ss_thumbnails/seminarhyunwook0624-200725001151-thumbnail.jpg?width=640&height=640&fit=bounds)























































