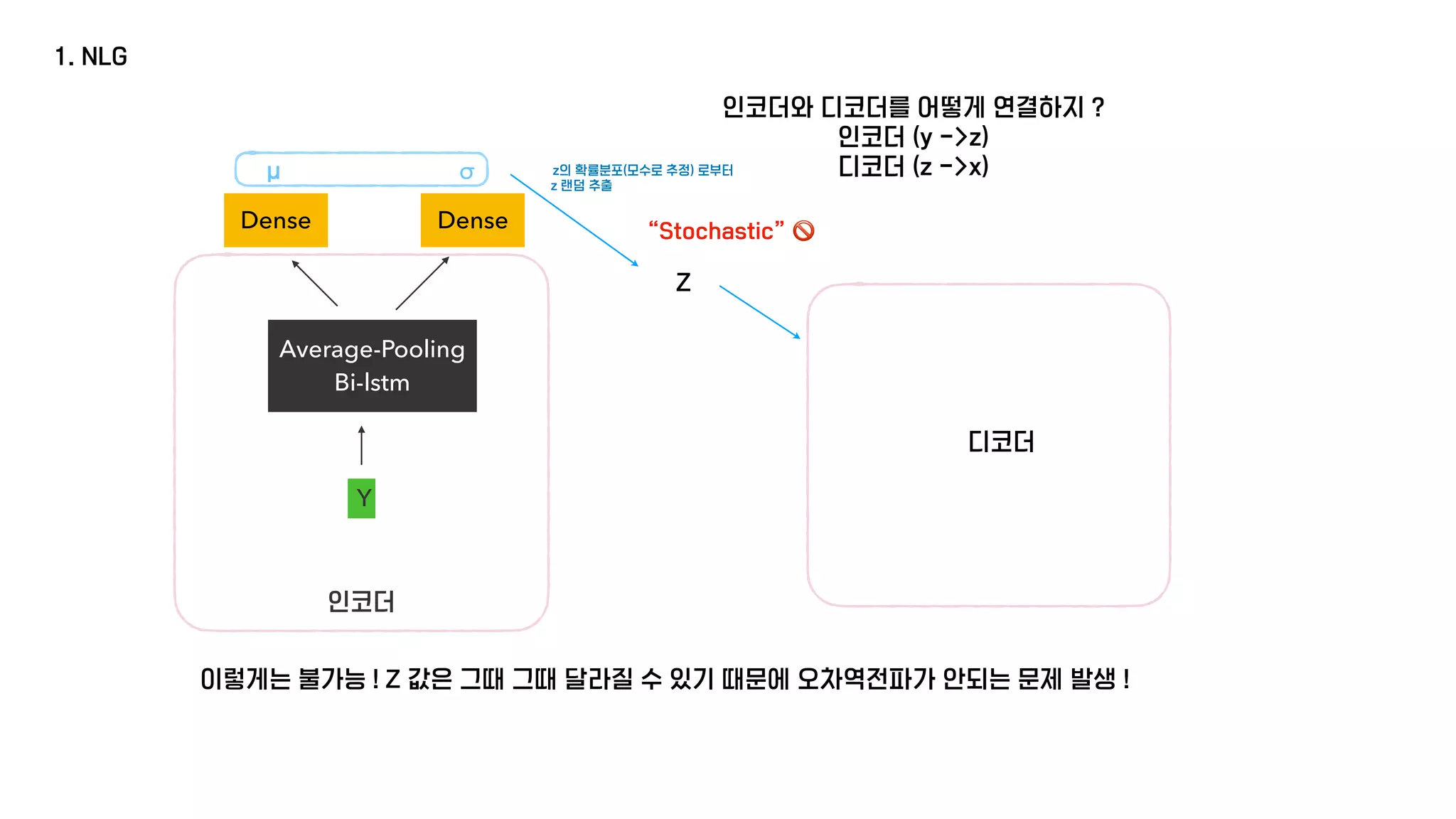
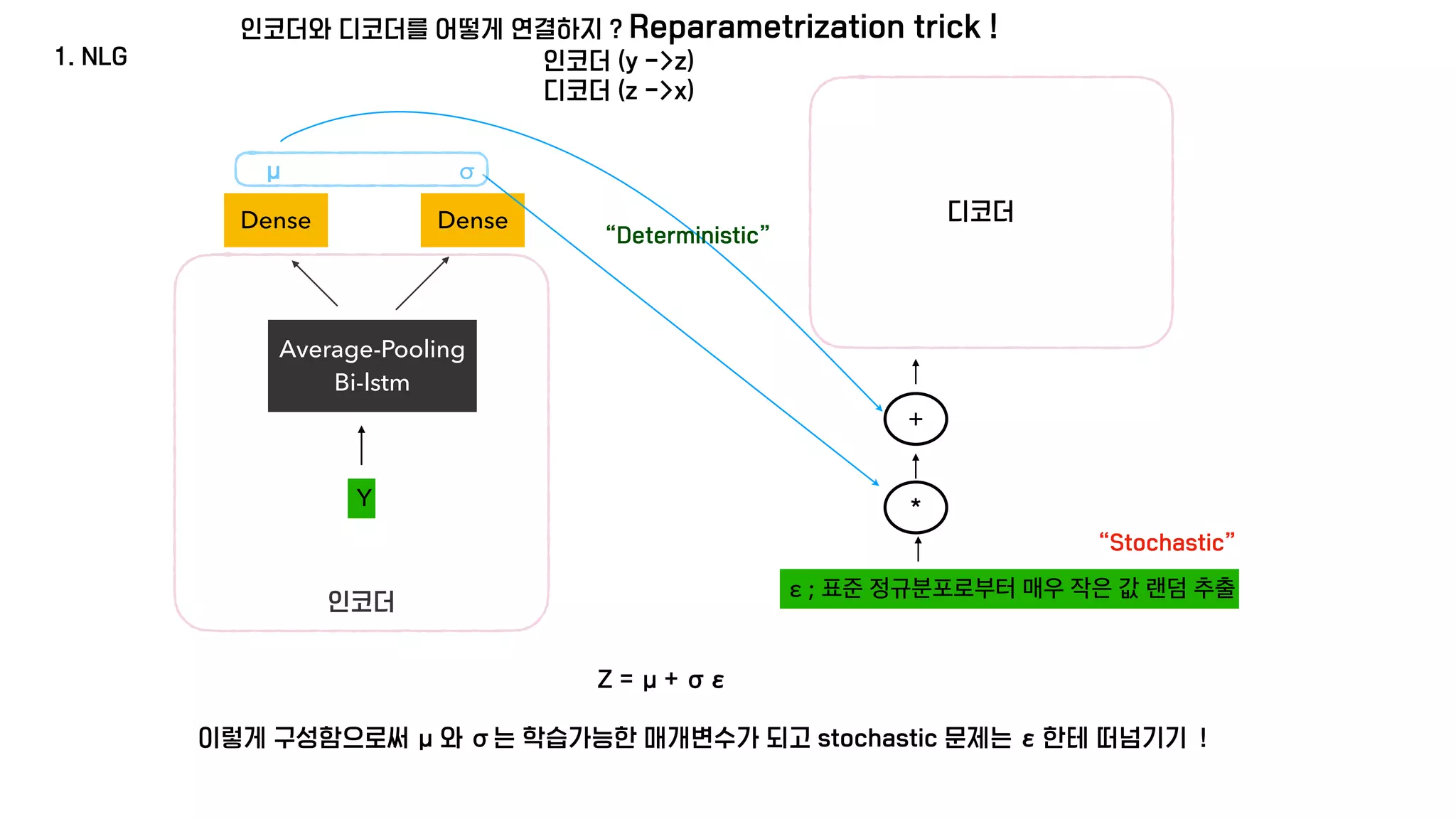
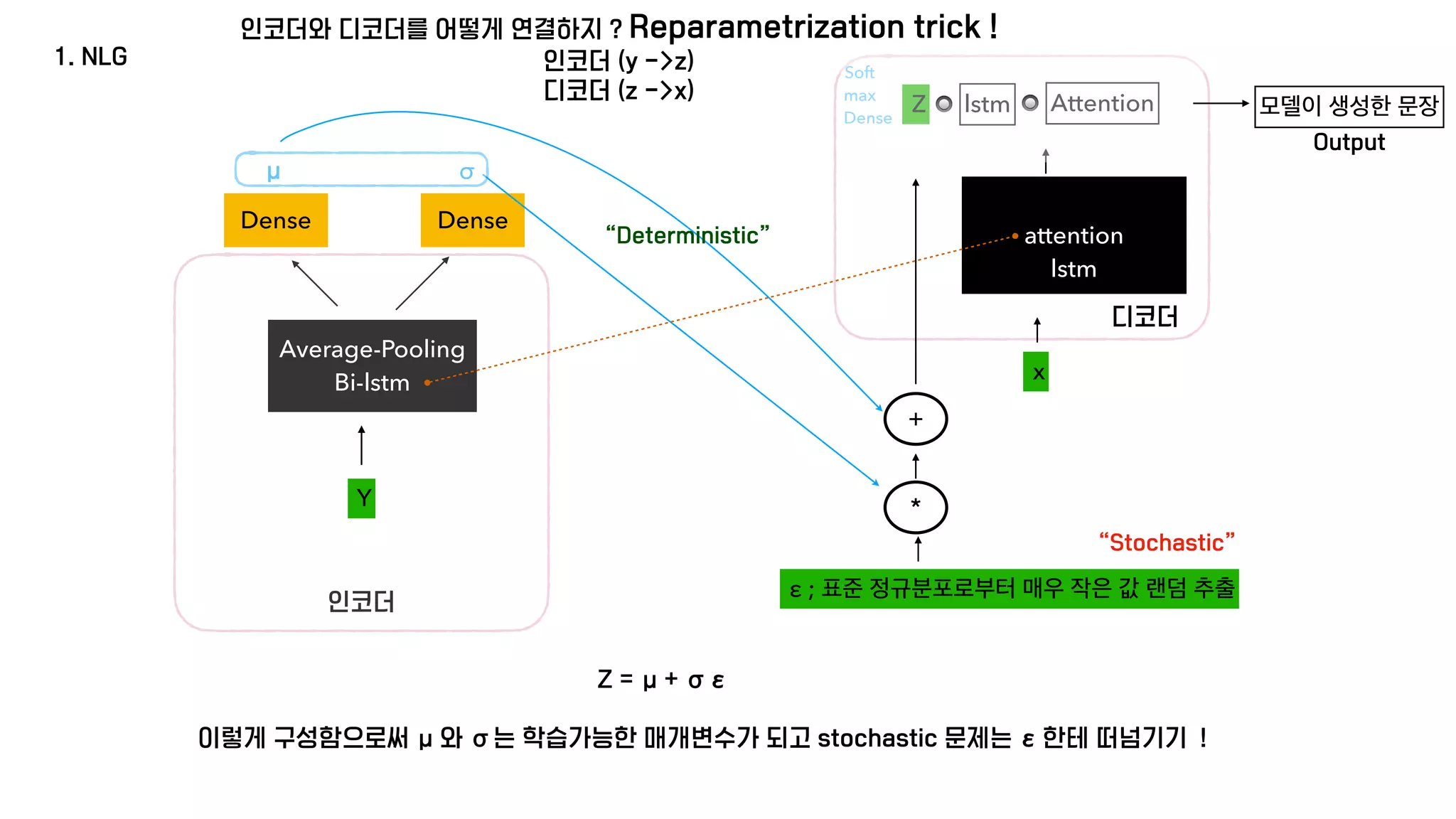
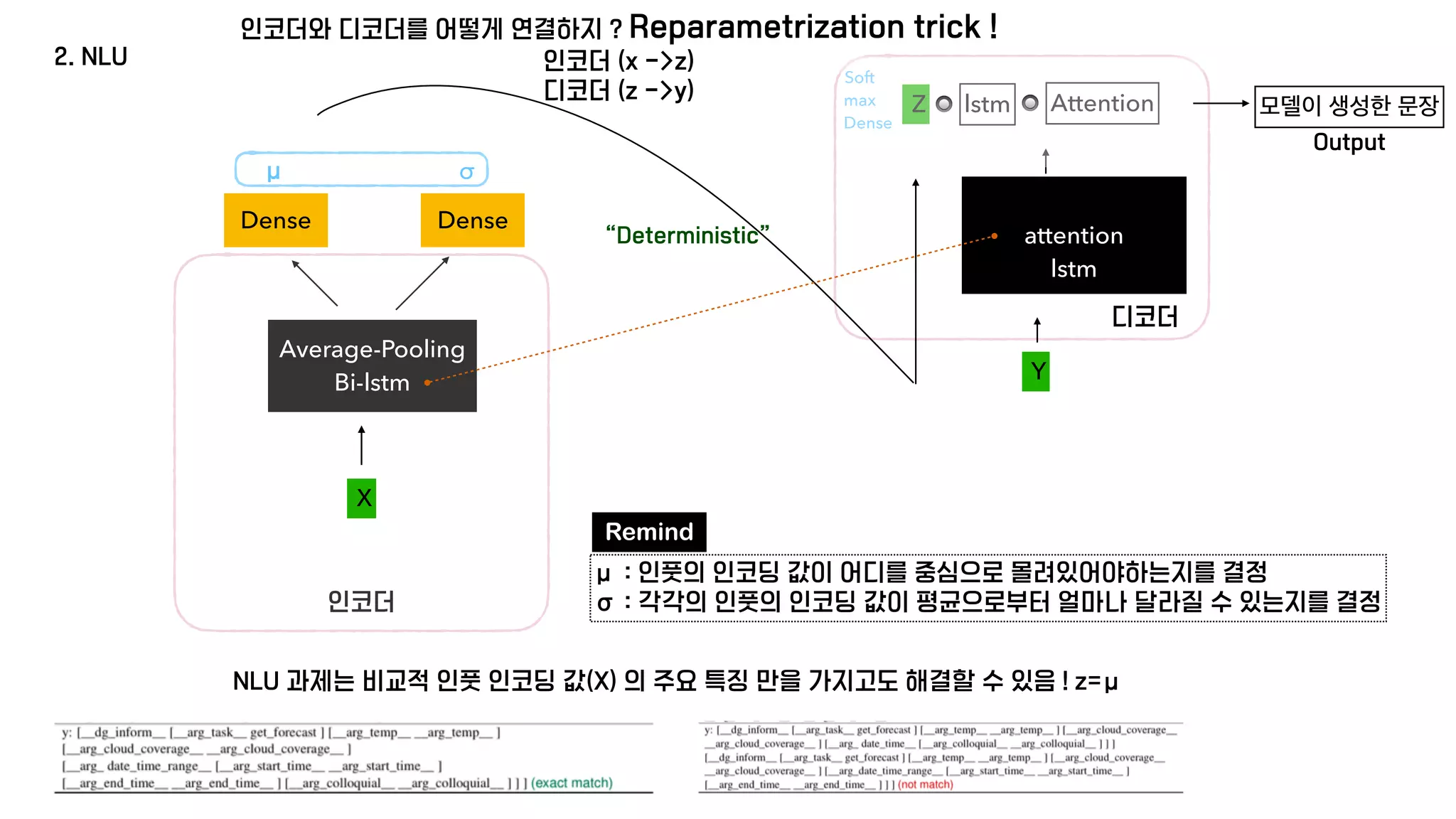
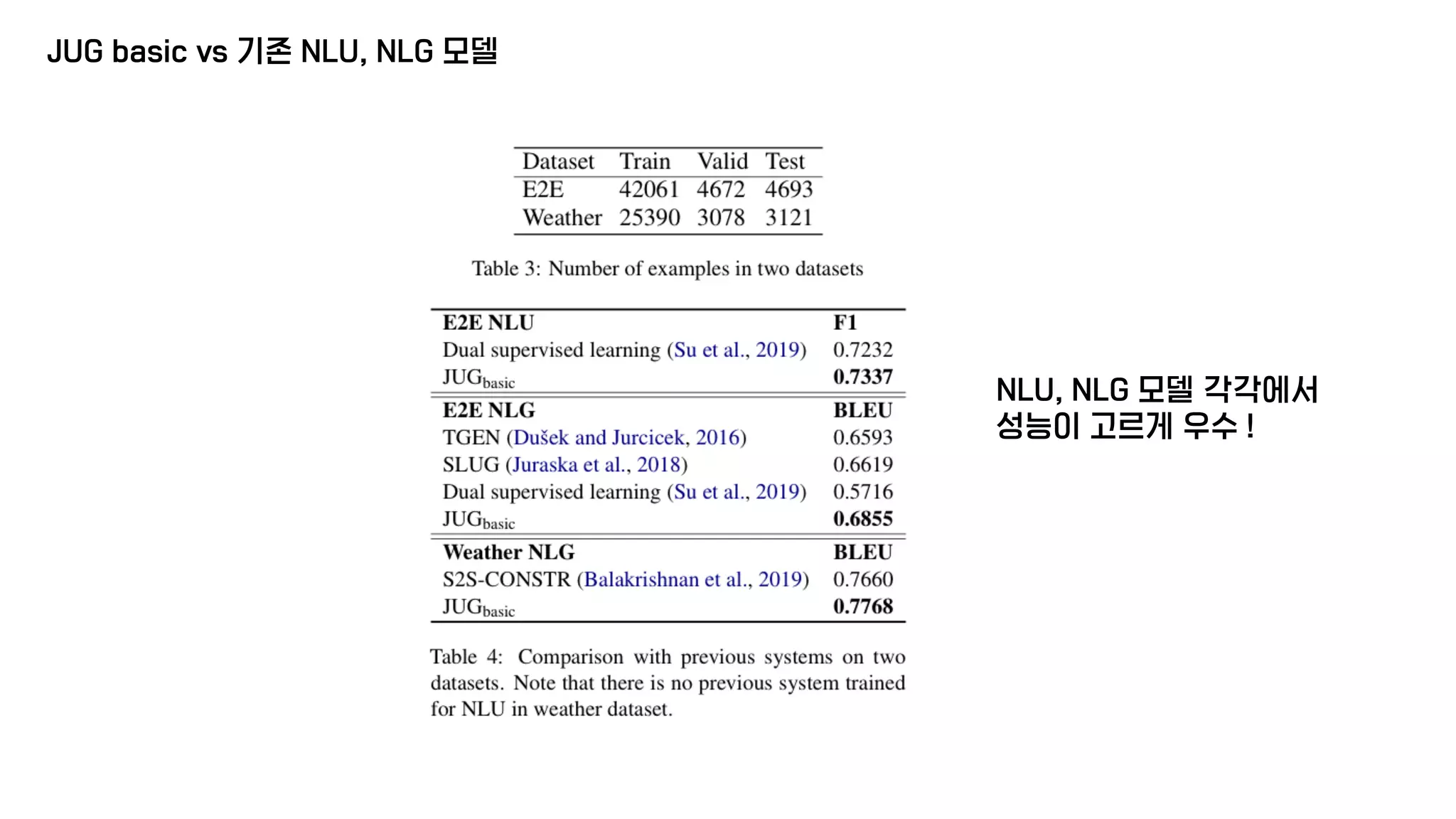
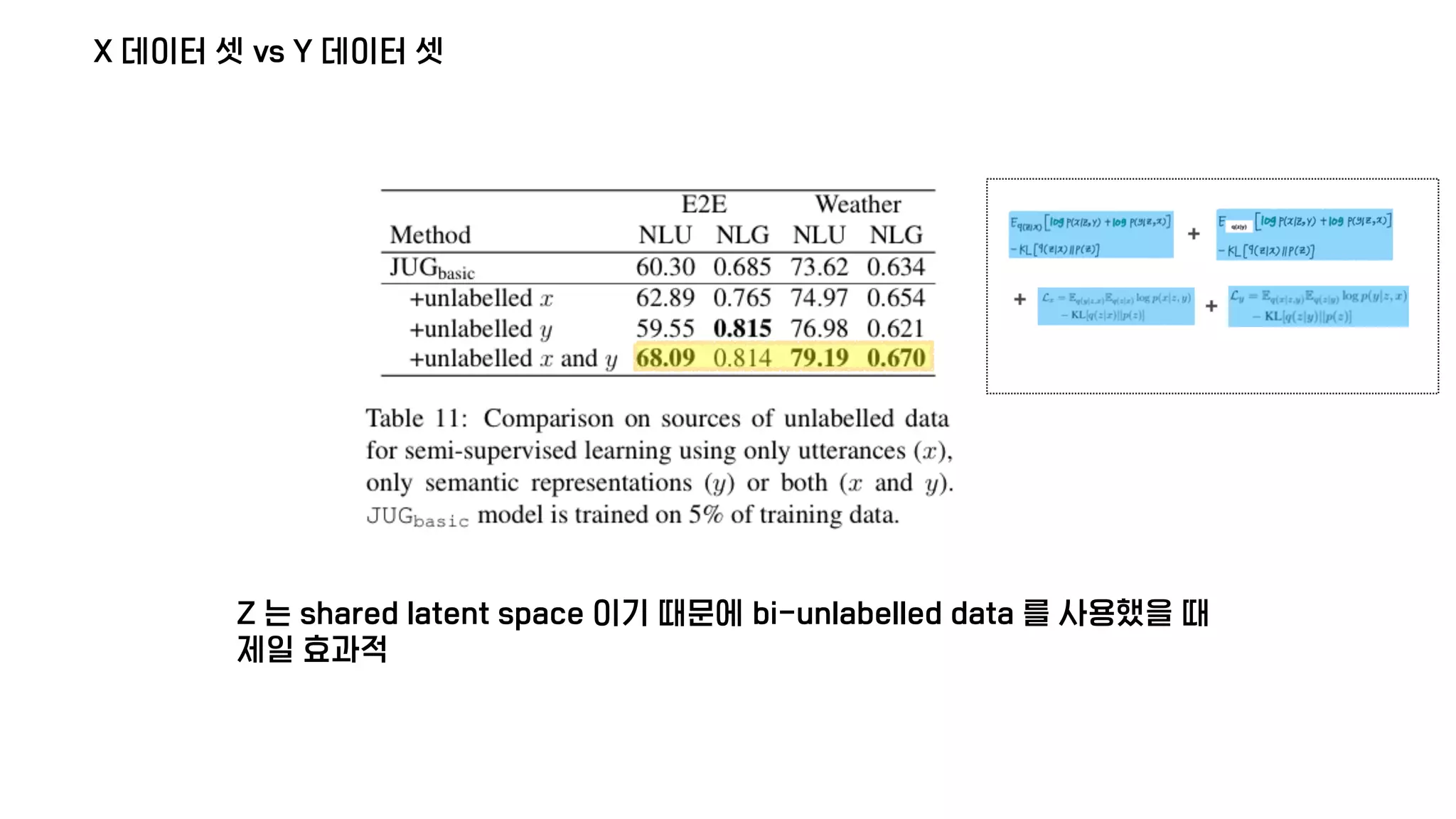
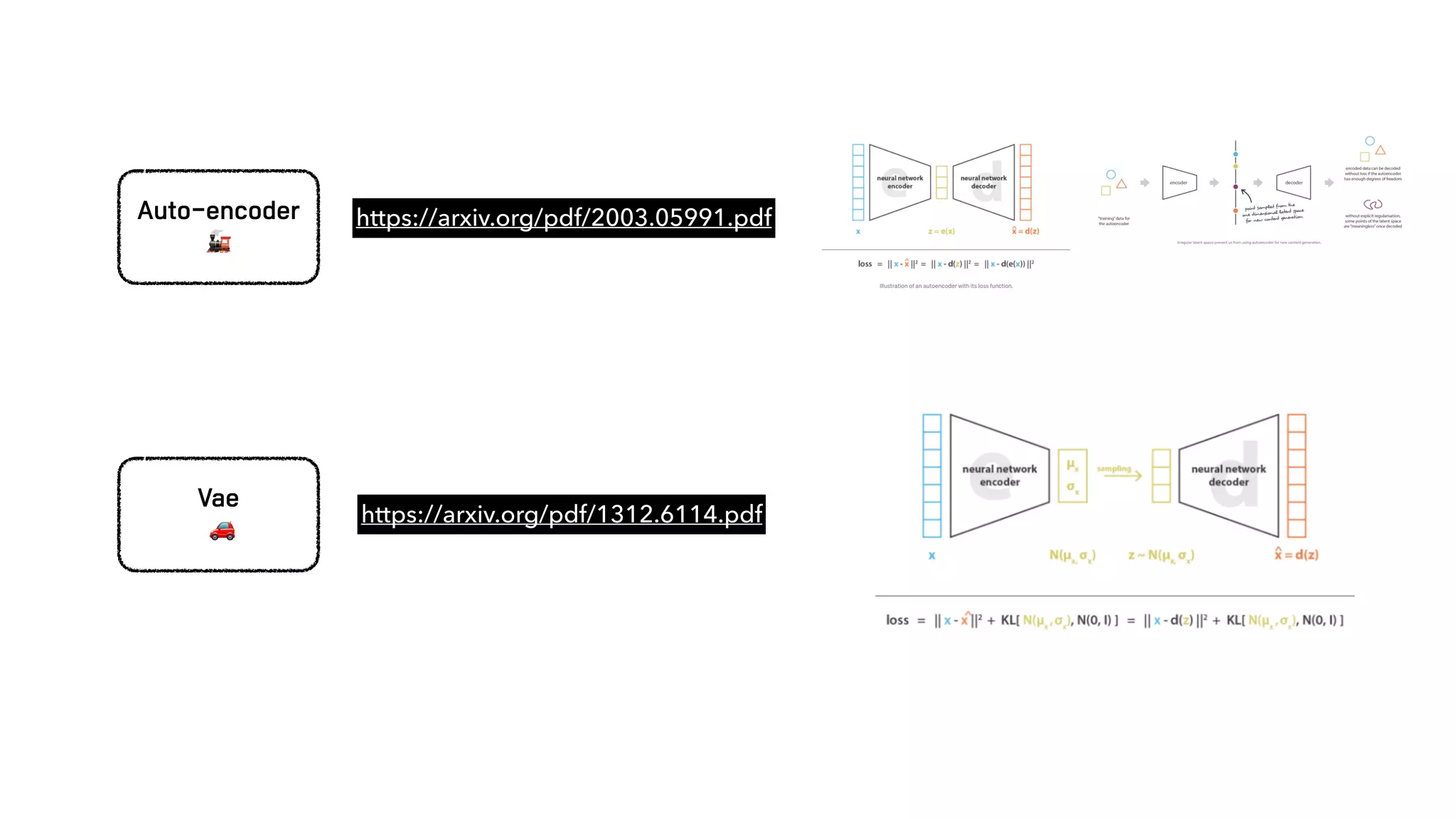
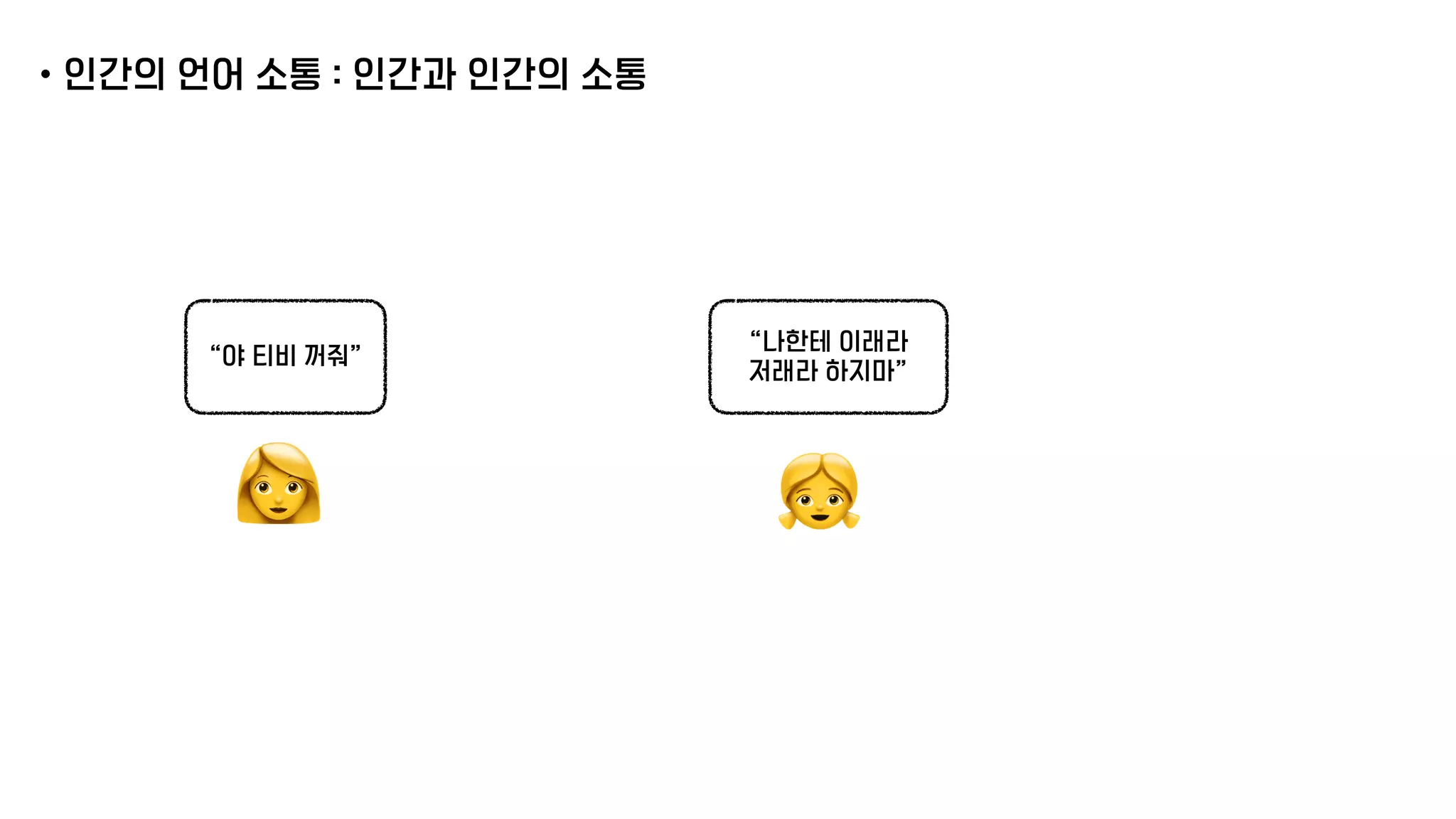
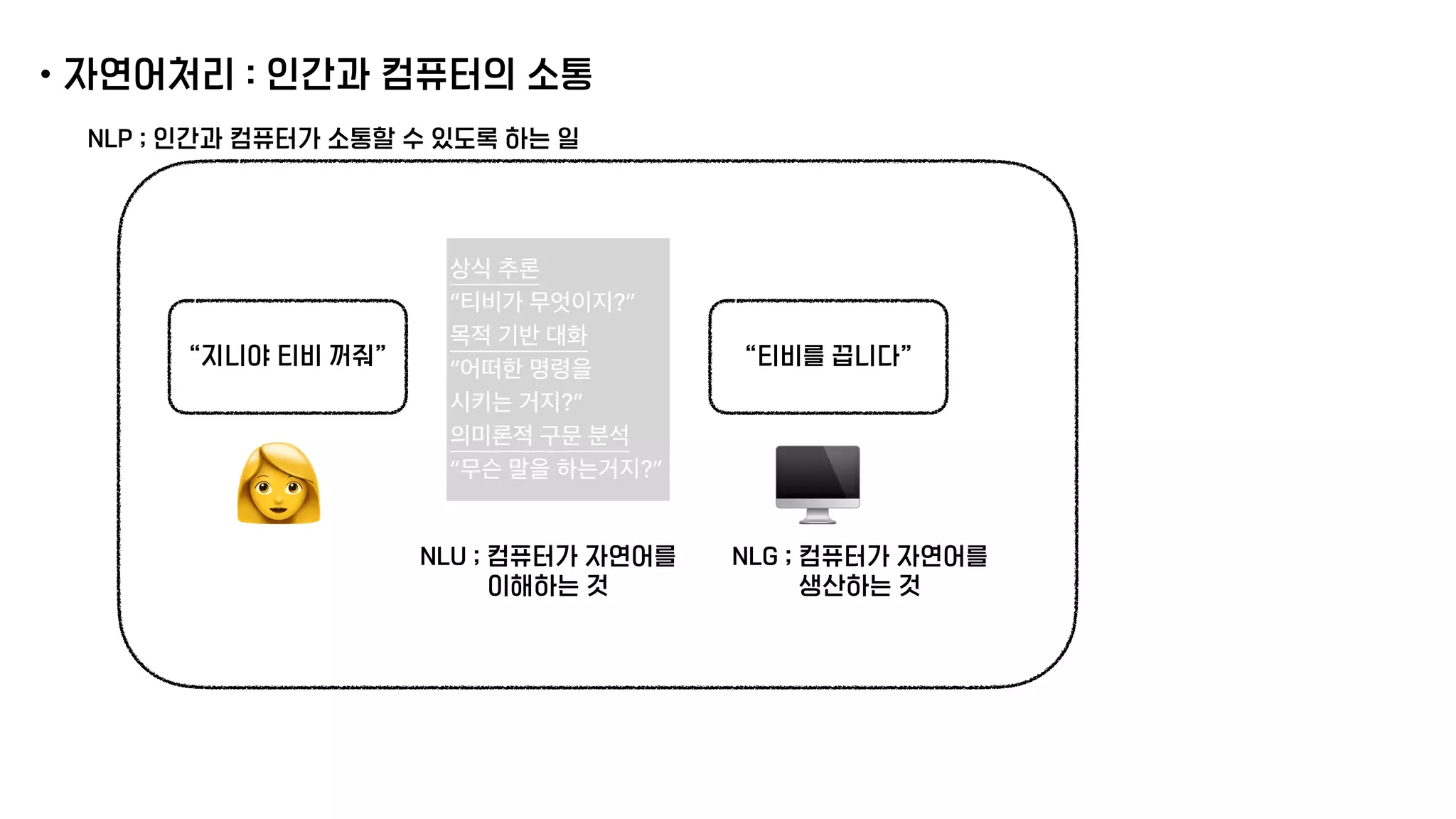
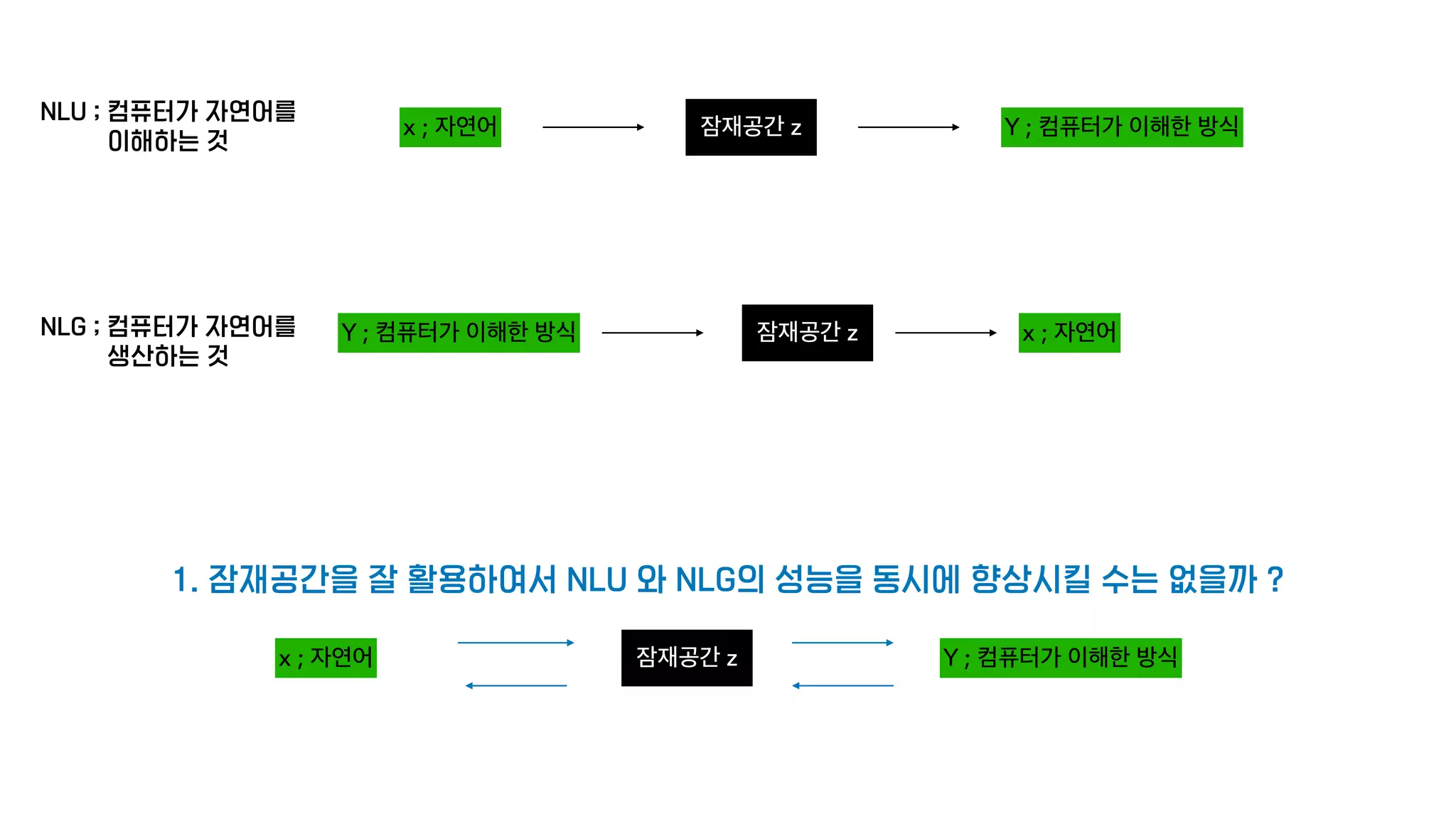
The document presents a generative model for joint natural language understanding (NLU) and natural language generation (NLG), aimed at improving communication between humans and computers. It outlines the model's structure, optimization methods, experimental results, and related research, highlighting the use of latent spaces for efficient information exchange across tasks. The findings indicate that the proposed 'jug model' outperforms existing NLU and NLG models, especially when labeled data is limited.





![Z 의 차원과 모수에 대한 직관적인 이해
Vary Z1 :
Degree of smile
Vary Z2 :
Head pose
[ [μ 1 ,σ1],
[μ 2 ,σ2]]
[ [z1],
[z2]]
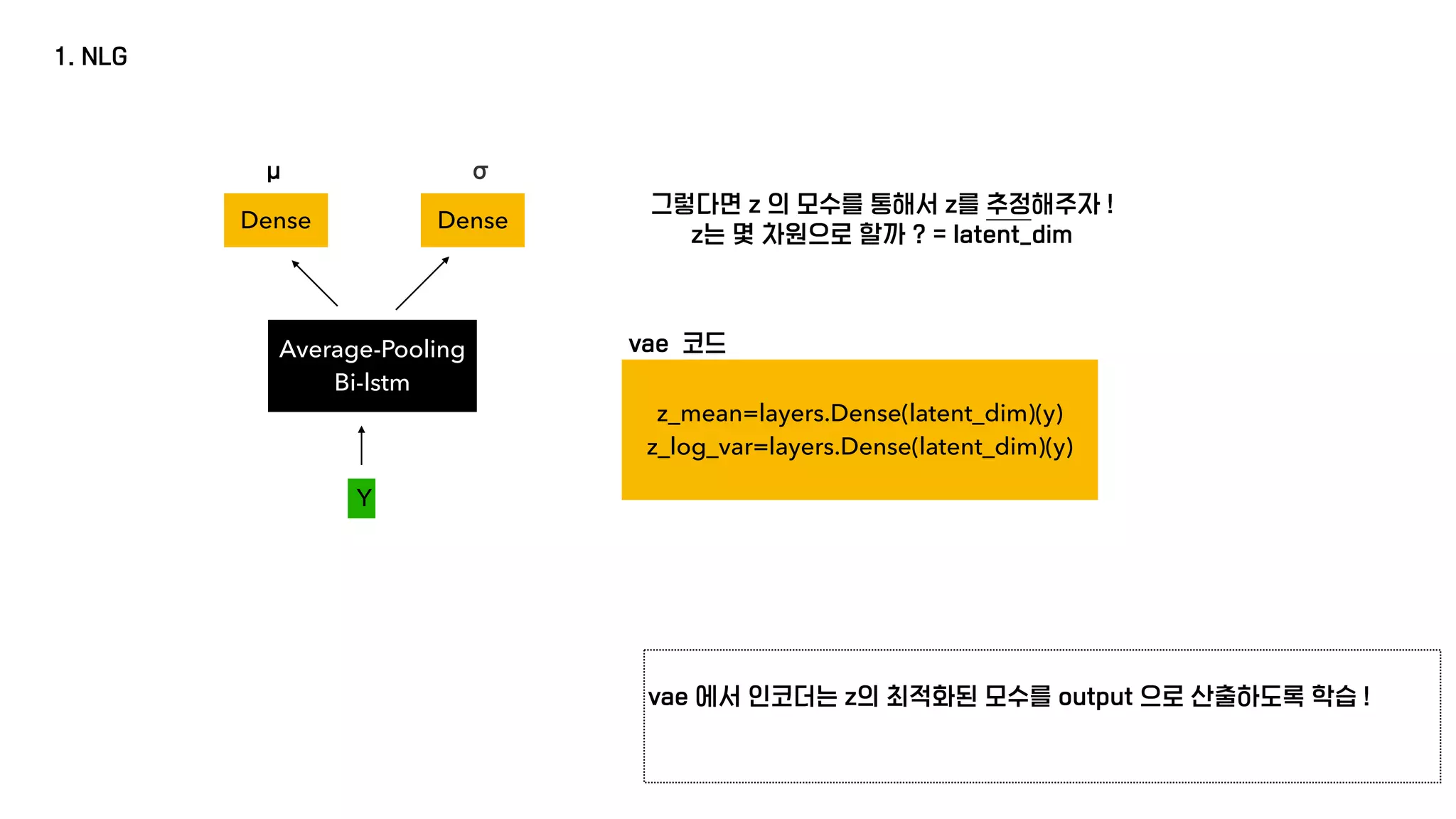
μ : 인풋의 인코딩 값이 어디를 중심으로 몰려있어야하는지를 결정
σ : 각각의 인풋의 인코딩 값이 평균으로부터 얼마나 달라질 수 있는지를 결정](https://image.slidesharecdn.com/jug-210128032605/75/A-Generative-Model-for-Joint-Natural-Language-Understanding-and-Generation-11-2048.jpg)