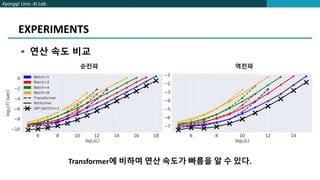
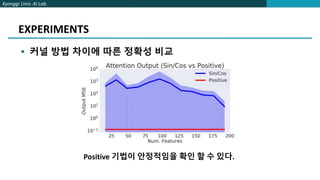
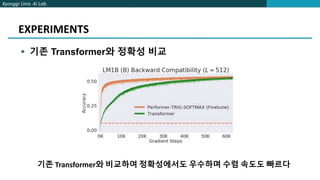
The document proposes FAVOR, a method to improve the efficiency of attention in Transformers. FAVOR reduces computational complexity of attention from O(L^2d) to O(Lr) by applying a mapping before attention to represent queries and keys with lower dimensionality r. It introduces a kernel function to replace softmax that is more stable during training. Experiments show FAVOR achieves faster inference speed and higher accuracy than baseline Transformers.





![Kyonggi Univ. AI Lab.
FAVOR - Attention의 개선
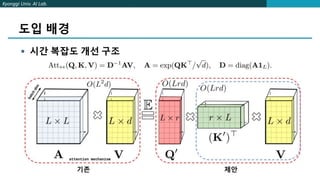
시간 복잡도 개선하기 – Trick!
일반적인 Attention -> 𝑨 = 𝒔𝒐𝒇𝒕𝒎𝒂𝒌(𝒒, 𝒌)
제안한 방법 -> 𝑨 = 𝑲𝒆𝒓𝒏𝒆𝒍(𝑸, 𝑲)
𝑲𝒆𝒓𝒏𝒆𝒍 𝑸, 𝑲 = 𝑬[∅ 𝑸 𝑻∅(𝑲)]
∅: mapping (d -> r)
Q → L X d
𝑄𝑇
→ d X L
∅(𝑄𝑇) → r X L
∅(𝑄𝑇)𝑇 → L X r
𝑸′ = ∅(𝑸𝑻)𝑻
Attention = Kernel(Q, K) V
= 𝑸′
(𝑲′
)𝑻
V
= 𝑸′ ((𝑲′)𝑻 V)](https://image.slidesharecdn.com/rethinkingattentionwithperformers-210819100700/85/Rethinking-attention-with-performers-8-320.jpg)






![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)





![[111]실내이동체정밀위치추정기술의세가지측면 도락주](https://cdn.slidesharecdn.com/ss_thumbnails/111-161023160508-thumbnail.jpg?width=640&height=640&fit=bounds)





























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)















