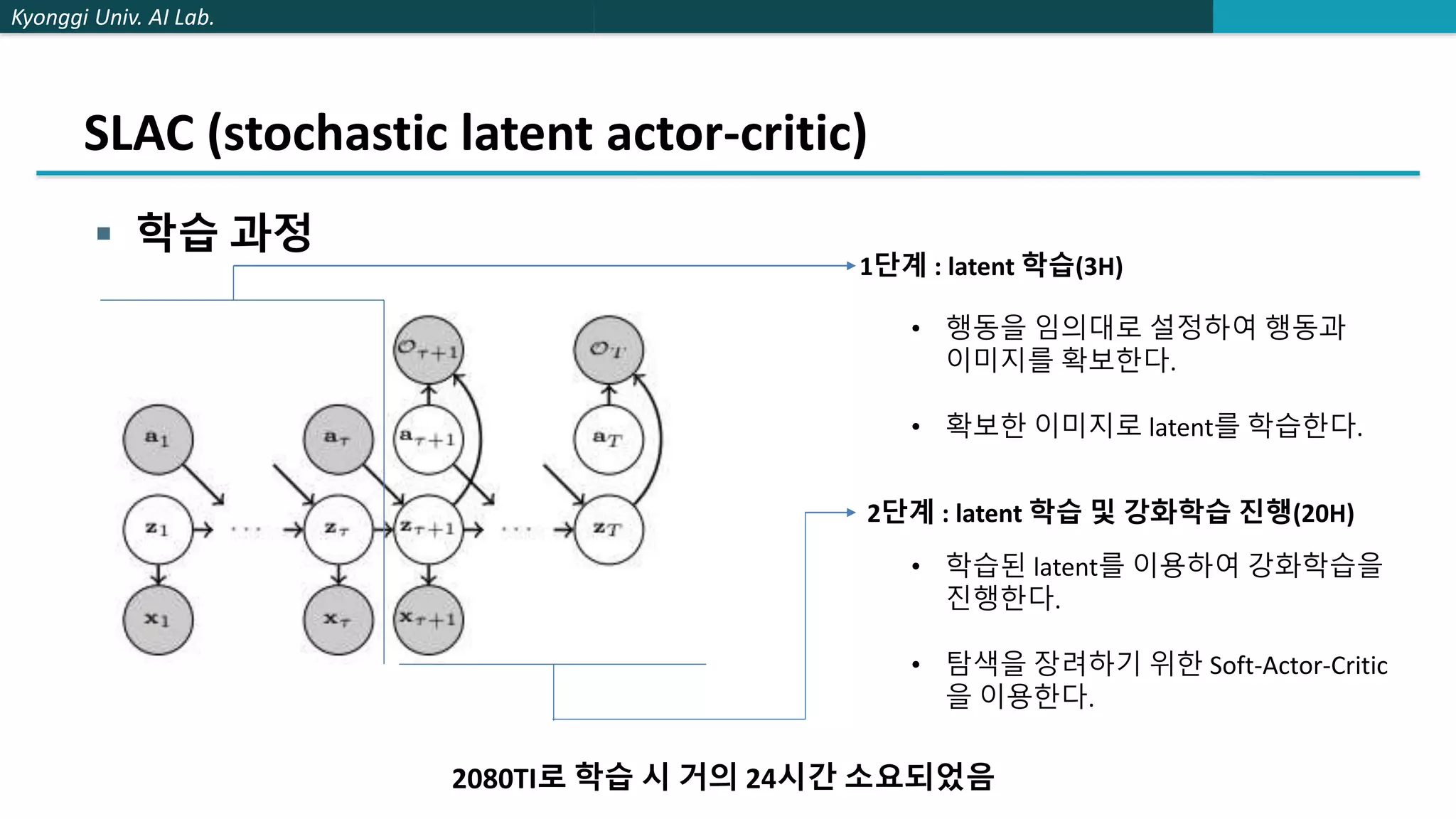
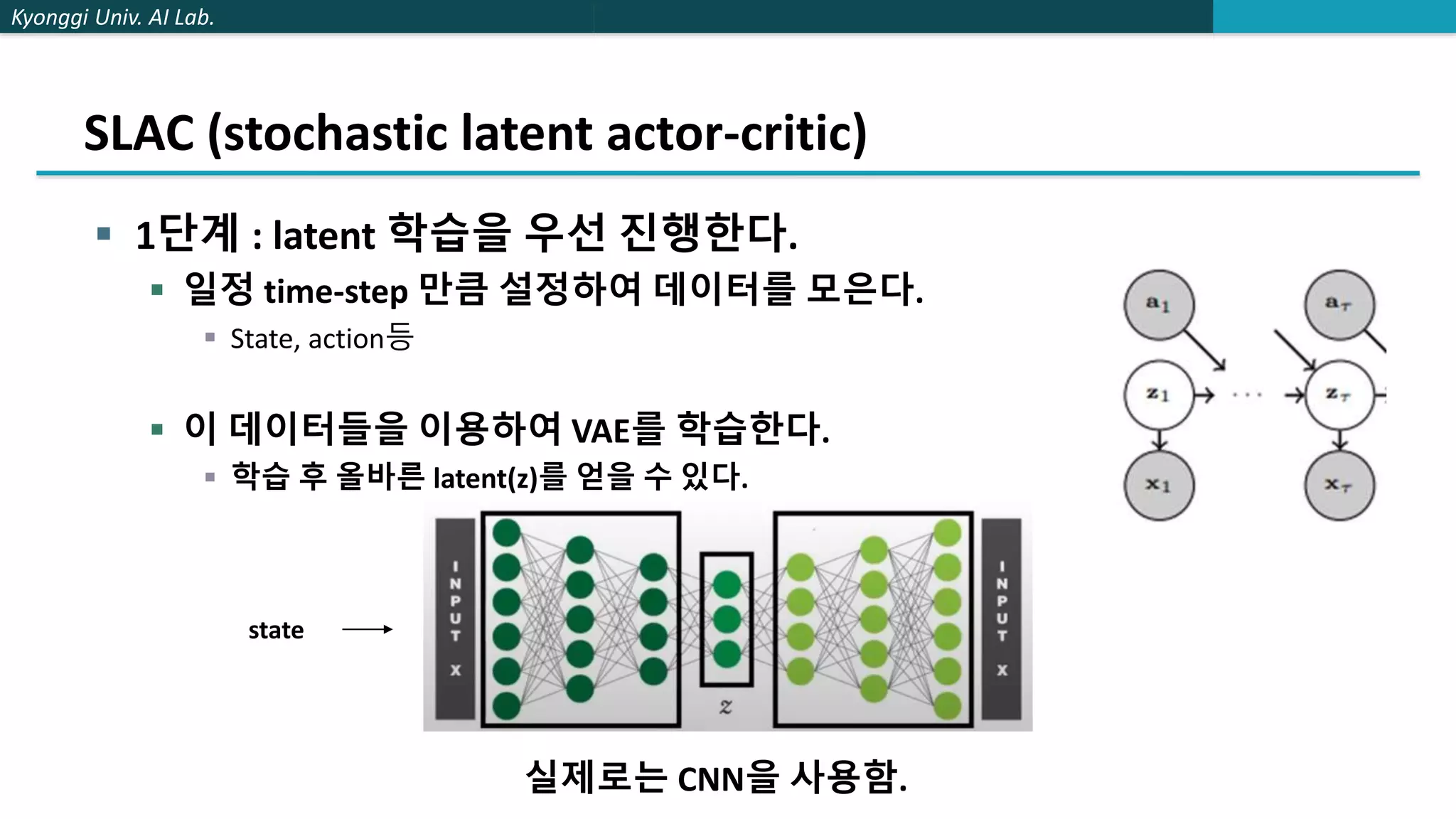
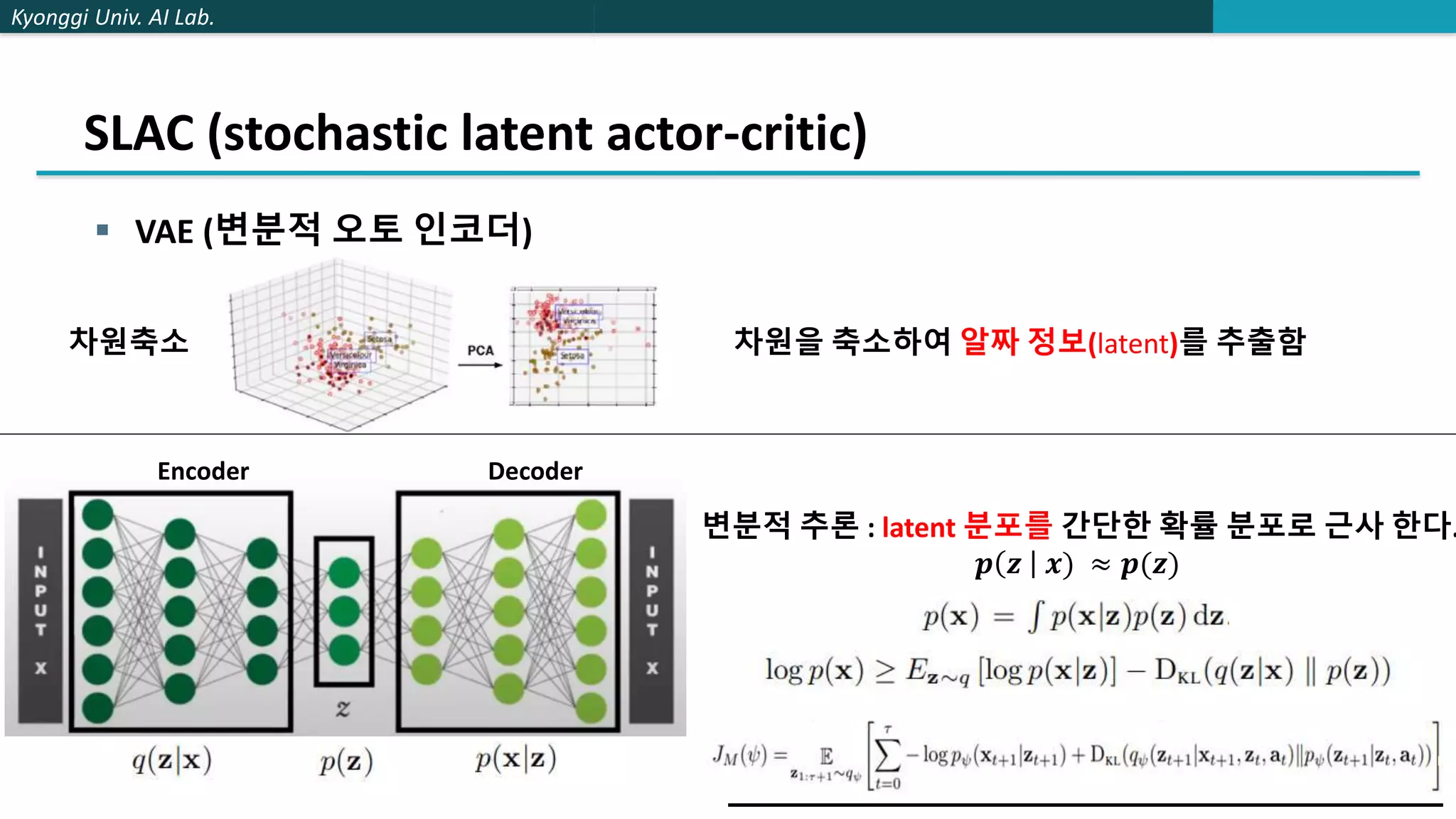
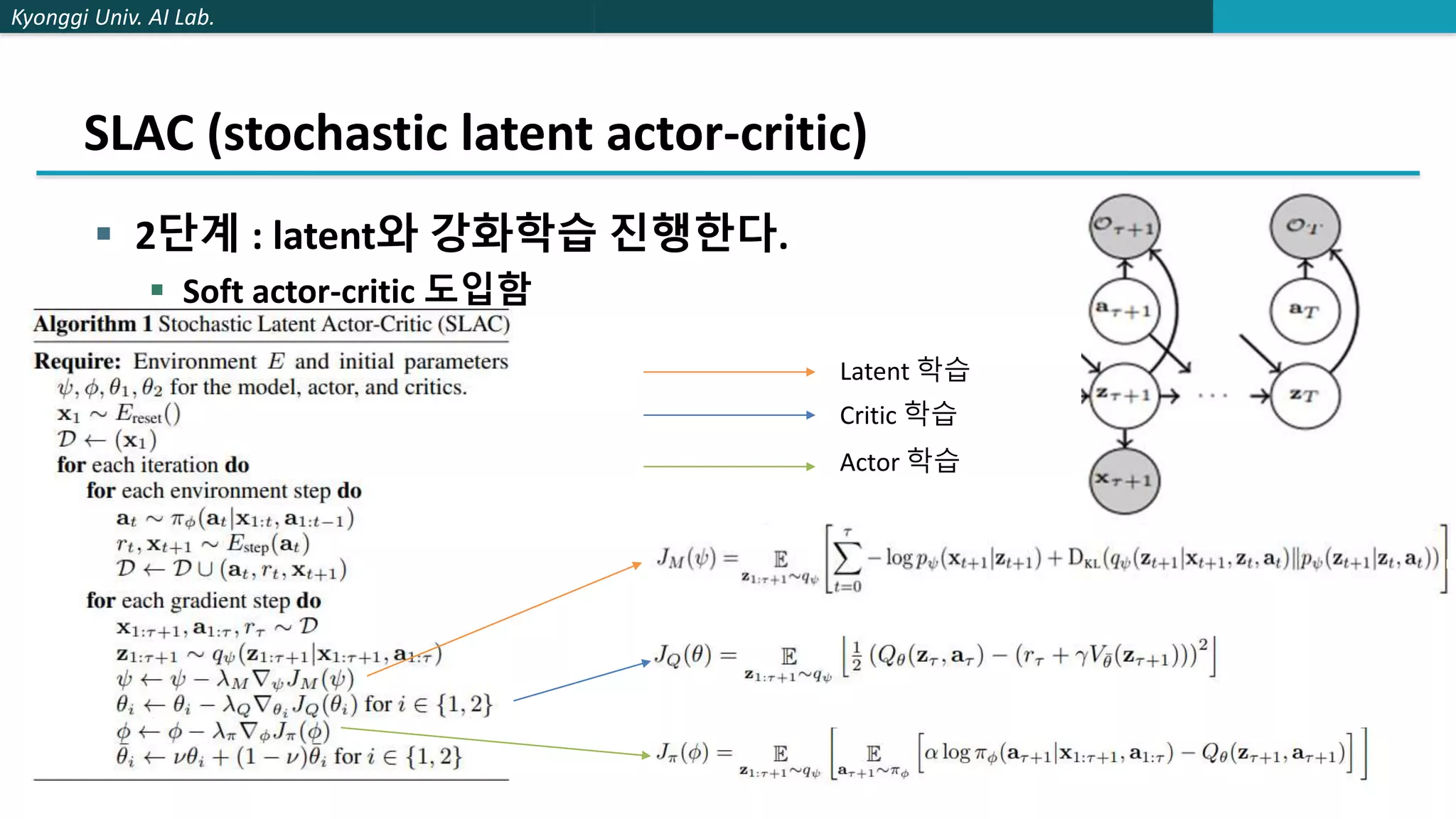
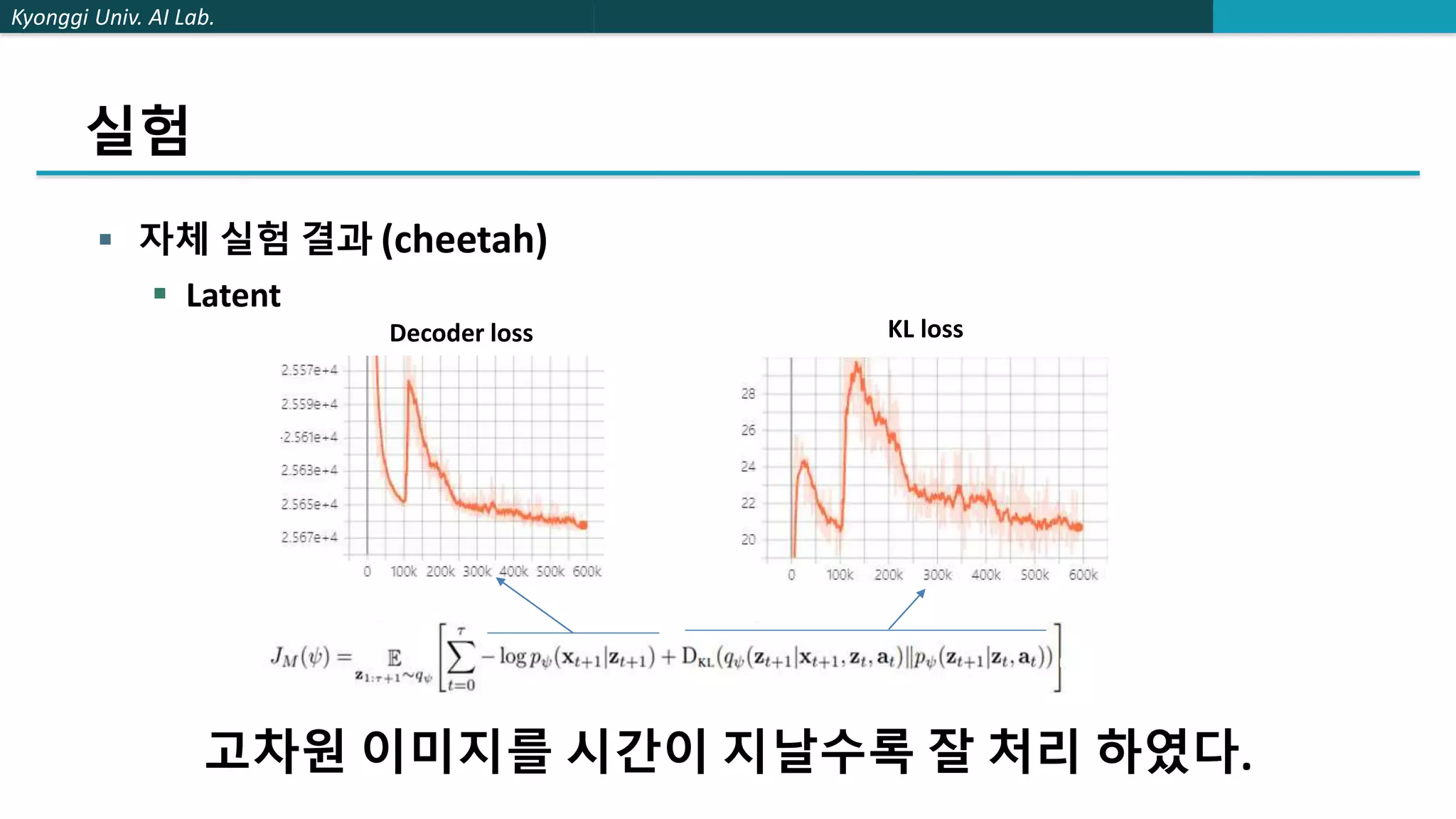
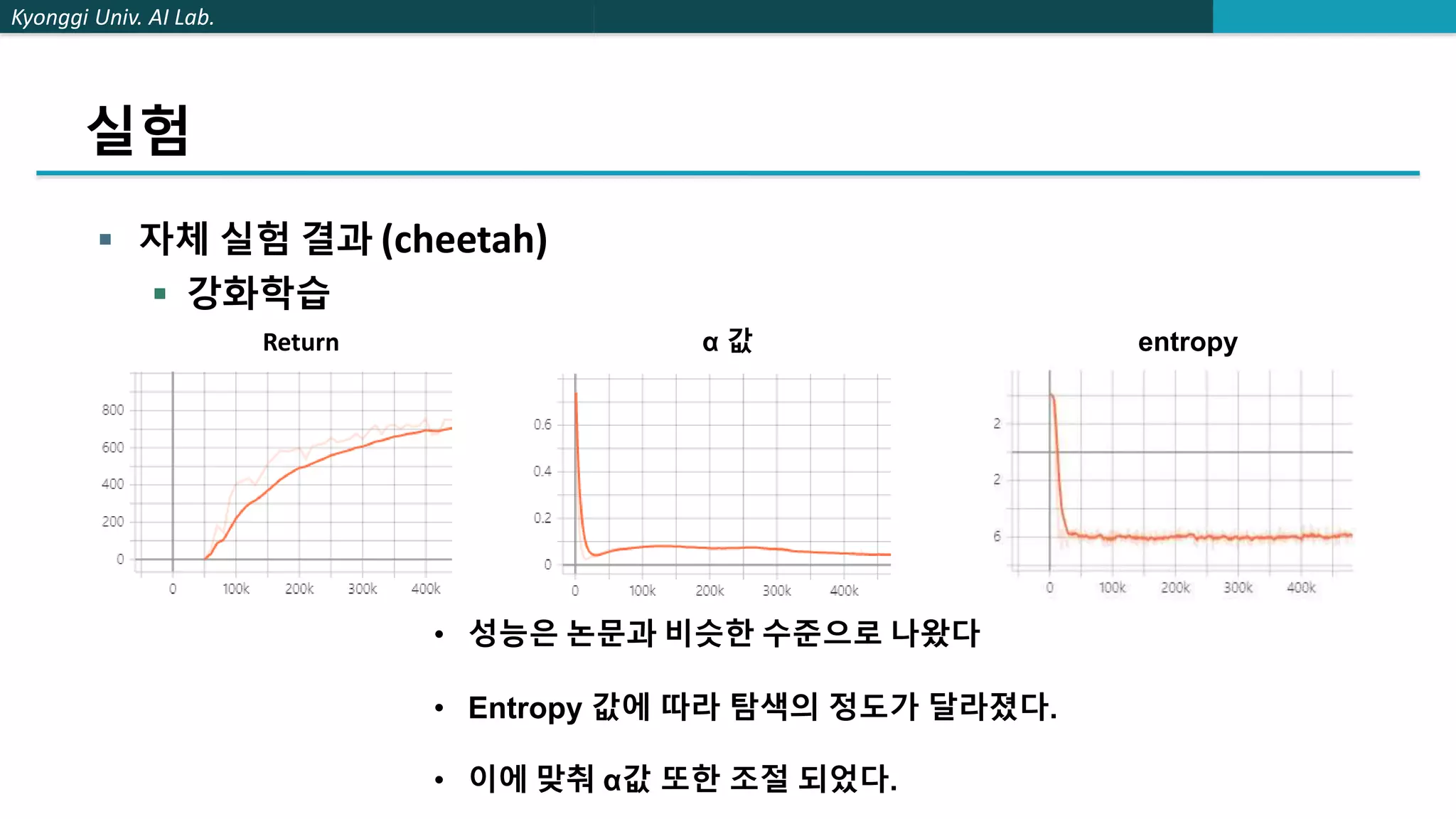
The document describes a method called stochastic latent actor-critic (SLAC) for deep reinforcement learning from high-dimensional images using a latent variable model. SLAC first learns a latent representation of images using a variational autoencoder, then performs reinforcement learning in the latent space using soft actor-critic. The method was tested on several control tasks from DeepMind and OpenAI and showed better performance than prior image-based deep RL methods. The author believes parallel training could improve the speed of SLAC, and that an adaptive entropy parameter may better balance exploration vs exploitation for complex tasks.











![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)











![[부스트캠프 Tech Talk] 김봉진_WandB로 Auto ML 뿌수기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkkimbongjin-210515042758-thumbnail.jpg?width=640&height=640&fit=bounds)


![[216]네이버 검색 사용자를 만족시켜라! 의도파악과 의미검색](https://cdn.slidesharecdn.com/ss_thumbnails/216-171017052320-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[NDC2017] 딥러닝으로 게임 콘텐츠 제작하기 - VAE를 이용한 콘텐츠 생성 기법 연구 사례](https://cdn.slidesharecdn.com/ss_thumbnails/v072-170426075401-thumbnail.jpg?width=640&height=640&fit=bounds)































