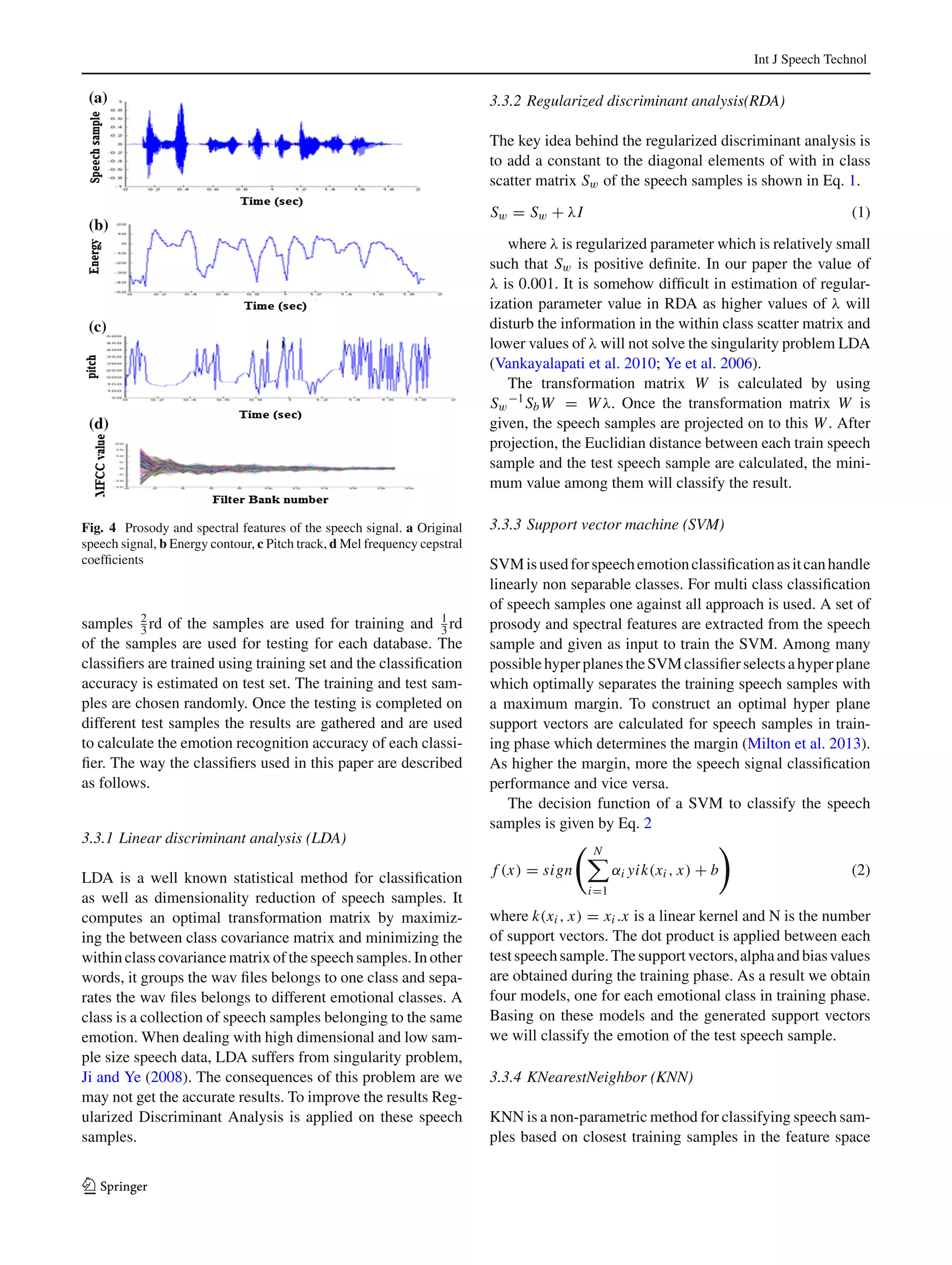
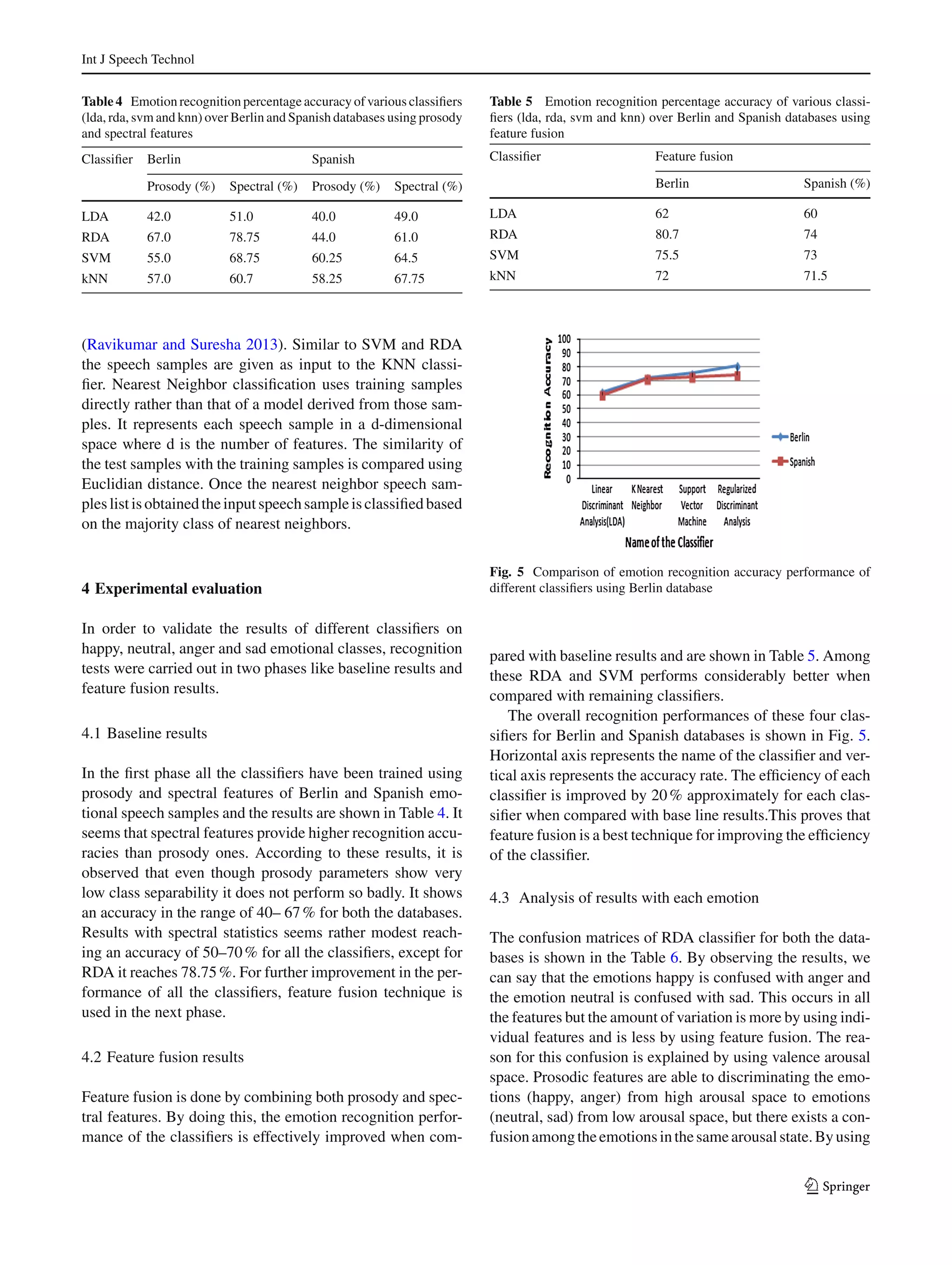
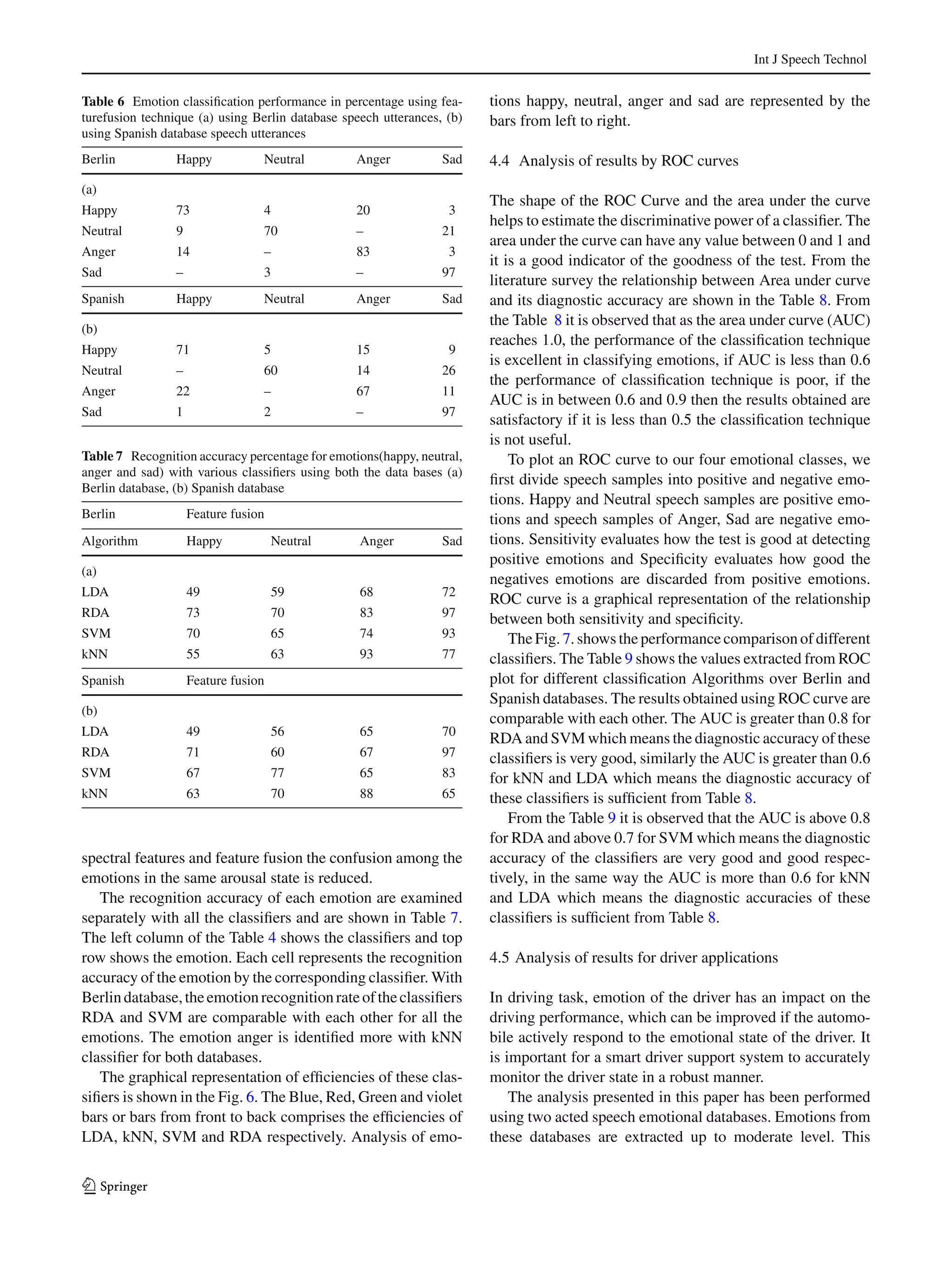
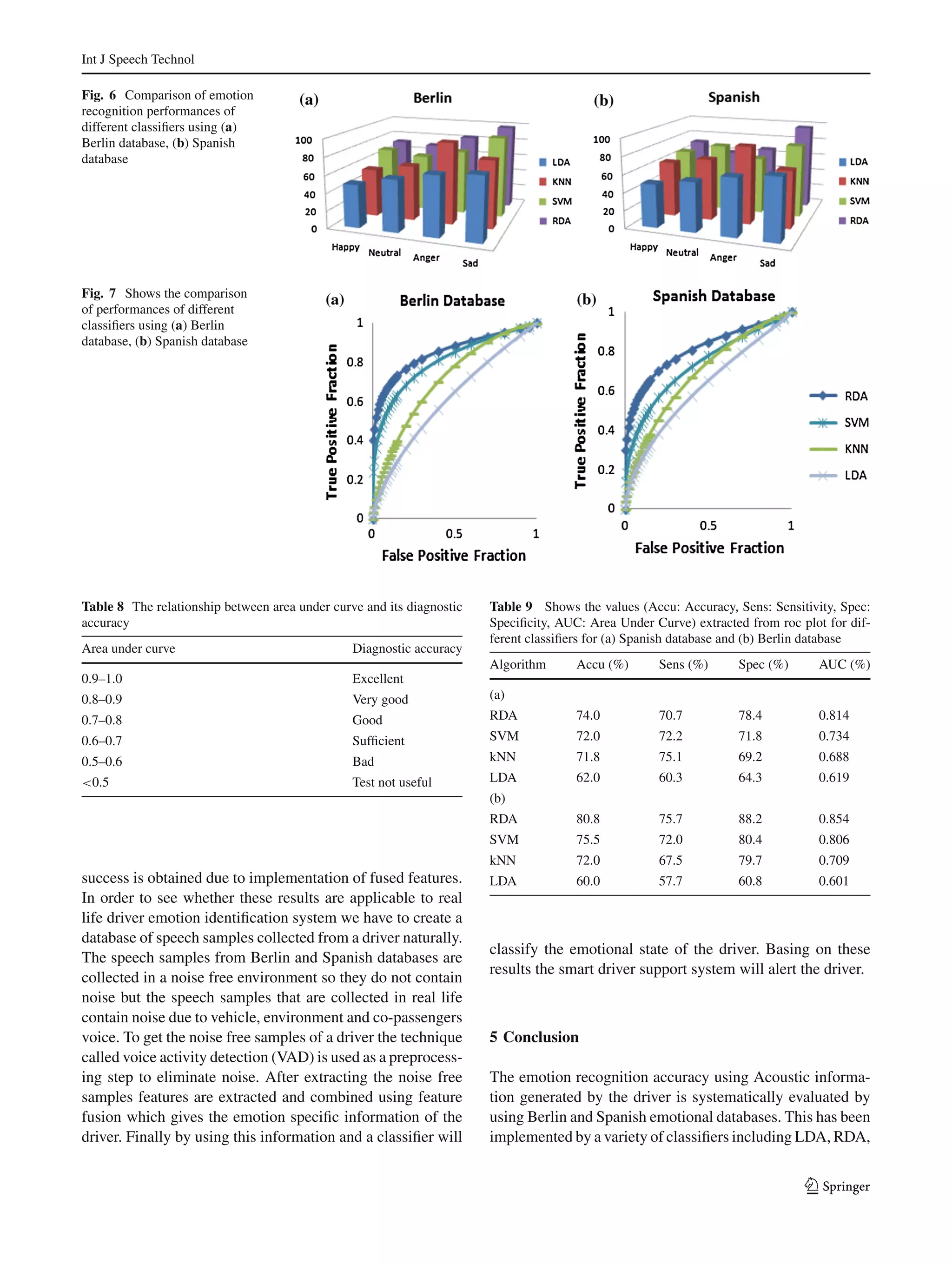
This document presents a comparative analysis of different classifiers for emotion recognition through acoustic features. It analyzes prosody features like energy and pitch as well as spectral features like MFCCs. Feature fusion, which combines prosody and spectral features, improves classification performance for LDA, RDA, SVM and kNN classifiers by around 20% compared to using features individually. Results on the Berlin and Spanish emotional speech databases show that RDA performs best as it avoids the singularity problem that affects LDA when dimensionality is high relative to the number of training samples.