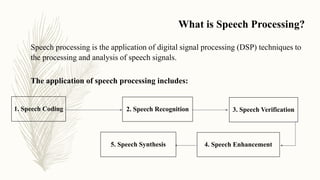
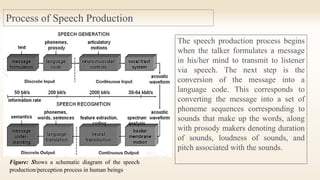
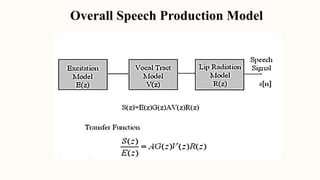
Speech processing is the application of digital signal processing techniques to analyze and process speech signals. It involves speech coding, recognition, verification, enhancement, and synthesis. The speech production process begins with formulating a message in the mind, converting it to a language code of phoneme sequences and prosody markers, and generating acoustic signals through vocal tract shaping and lip/nasal radiation. Speech sounds are classified as voiced produced with vocal cord vibration or unvoiced produced without. Formant frequencies and their magnitudes differ between voiced and unvoiced sounds. Developing an accurate model of speech production requires modeling the vocal tract operation, radiation process, voiced/unvoiced distinction, and short 10-20ms time frames.