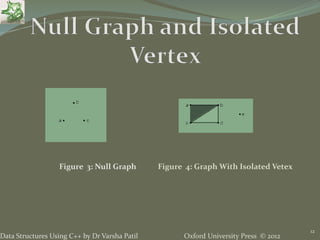
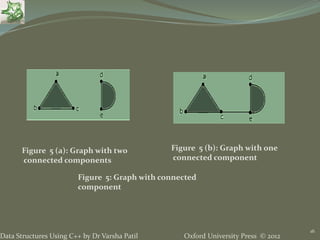
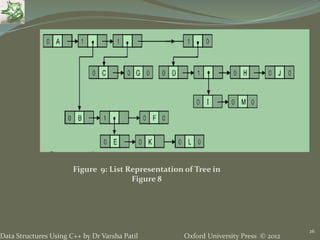
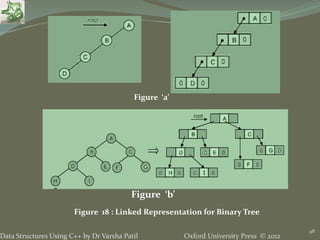
The document discusses different types of trees and graphs as data structures. It defines trees as hierarchical data structures that can represent information in a flexible manner. Binary search trees allow rapid retrieval of data based on keys. Different types of trees are discussed including binary trees, ordered trees, rooted trees, and complete trees. Graphs are also covered as structures that can represent relationships between data items and support applications like social networks. Common graph terms like nodes, edges, directed/undirected graphs, and connectivity are defined.






























































































































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















