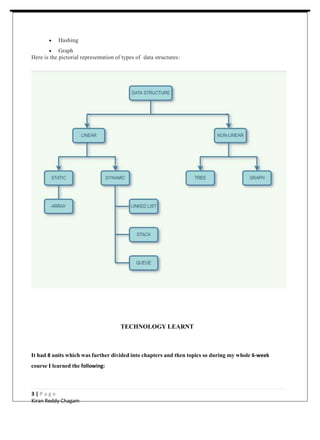
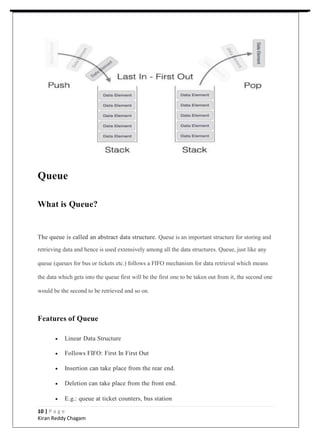
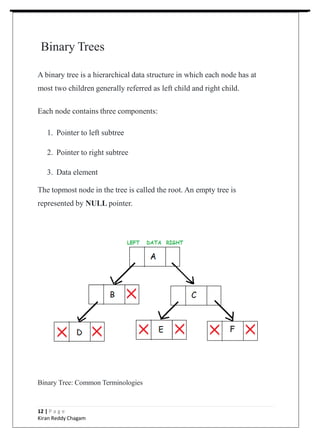
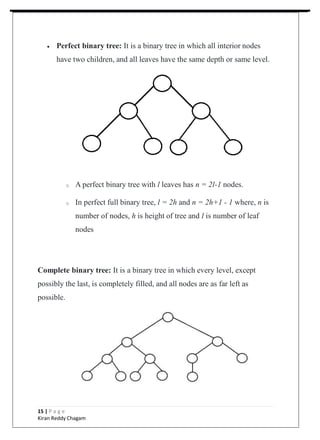
1. The document outlines the key topics and concepts covered in a 6-week data structures and algorithms course, including common data structures like arrays, linked lists, stacks, queues, binary trees, and graphs.
2. It provides details on different types of data structures, operations, advantages and disadvantages of each structure. Example applications are also discussed.
3. The reasons for choosing to learn data structures and algorithms are given as preparing for other programming languages and computer science topics, learning algorithm design, and gaining practical knowledge through live video lectures.