Учебное пособие посвящено математическому моделированию стохастических систем, включая классификацию моделей, методы их построения и применения. Рассматриваются аналитические и имитационные модели, а также принципы их валидации и верификации. Рекомендуется студентам технических специальностей и утверждено редакционно-издательским советом Сибирского государственного университета путей сообщения.
















![17
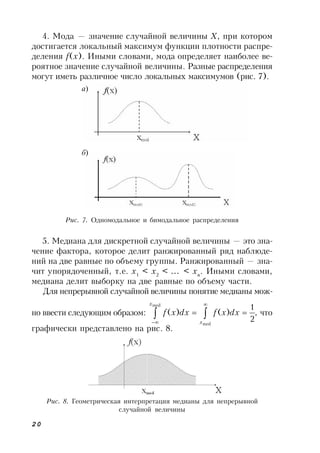
Функция плотности распределения вероятности определя-
ет плотность вероятности в этой точке. Геометрическая интер-
претация связи функции плотности вероятности и функции
распределения приведена на рис. 4.
Рис. 4. Геометрическая интерпретация связи функции плотности
вероятности и функции распределения
Рис. 5. Геометрическая интерпретация вероятности попадания в интервал
Свойства функции плотности распределения:
1. f(x) 0;
2. .1)(
dxxf
Вероятность попадания случайной величины в интервал
(a, b] можно вычислить по формуле
).()()()( aFbFdxxfbxaP
b
a
Геометрическая интерпретация вероятности попадания в
интервал (a, b] — это площадь криволинейной трапеции, огра-
ниченной функцией плотности распределения в заданном ин-
тервале (рис. 5).
X
X](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-17-320.jpg)

![19
2. Дисперсия определяет среднеожидаемый квадрат раз-
броса значений случайной величины X относительно матема-
тического ожидания M(X). Дисперсию можно вычислить по
формуле D(X) = M[(X – M(X))2
] = M(X2
) – [M(X)]2
.
Дисперсия дискретной случайной величины вычисляется по
формуле ,)()(
1
22
1
22
n
i
ii
n
i
ii pxpxXD а для не-
прерывной случайной величины —
.)()()()( 2222
dxxfxdxxfxXD
Свойства дисперсии: D(C) = 0; D(CX) = C2
D(X); D(X+Y)=
= D(X) + D(Y), если X иY независимы; D(C+X) = D(X);
D(X+Y) = D(X)+D(Y), если X иY независимы.
3. Среднеквадратическое отклонение вычисляется по фор-
муле .)(XD
Имеет место равенство ,)()()( YDXDYX если X и
Y независимы.
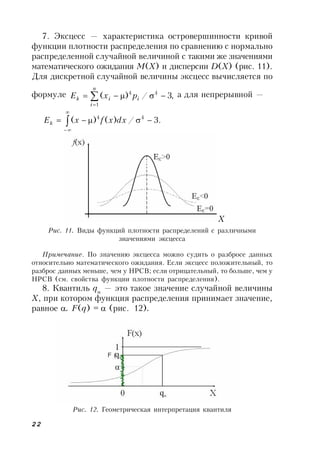
Дисперсия D(Х) и среднеквадратичное отклонение ха-
рактеризуют степень рассеивания случайной величины отно-
сительно ее математического ожидания. Чем меньше D(Х),
тем меньше степень рассеивания случайной величины. Это ут-
верждение наглядно представлено на рис. 6.
Рис. 6. Рассеивание данных с различными значениями
среднеквадратичных отклонений
x
f(x)
M(x)
Примечание. Глядя лишь на одно значение дисперсии, нельзя сказать,
большое рассеивание данных относительно математического ожидания или
нет. Ведь при вычислении значения дисперсии большое значение имеет,
например, масштабирование данного фактора (можно измерять в тоннах
или граммах), значение математического ожидания, минимальное и макси-
мальное значения, которые может принимать фактор.](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-19-320.jpg)



![26
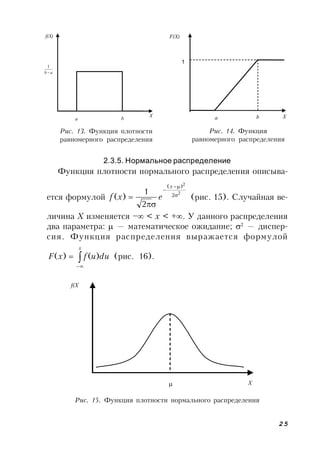
У нормально распределенной случайной величины M(X) =
= xmed
= xmod
; D(X) = 2
. Справедливы следующие правила:
;68,0)( xP ;95,0)22( xP
97,0)33( xP (правило «трех сигм»).
Двухмерный закон распределения нормальной случайной
величины (X, Y) можно описать функцией распределения
))(),((),( yYxXPyxF или функцией плотности распре-
деления .
),(
),(
yx
yxF
yxf
Причем выполняются следующие соотношения: M(X,Y) =
(MX),M(Y)); ,
)(),cov(
),cov()(
),(
YDYX
YXxD
YXD здесь кова-
риация ;),cov(),cov( xyXYYX
))]())(([( YMYXMXMxy
.)],())())(([(
dxdyyxfYMyXMx
Коэффициент корреляции между X и Y может быть опре-
делен по формуле .11
yx
xy
xy
Рис. 16. Функция нормального распределения
F(X)
X
1](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-26-320.jpg)
![27
Контрольные вопросы к разделу 2
1. Понятие случайного события. Дискретные и непрерыв-
ные случайные величины.
2. Свойства и геометрический смысл функции распределе-
ния и функции плотности распределения.
3. Как вычислить вероятность попадания случайной вели-
чины в интервал ( a, b]?
4. Основные числовые характеристики.
5. Специальные законы распределения.
3. ТОЧЕЧНЫЕ И ИНТЕРВАЛЬНЫЕ ОЦЕНКИ СЛУЧАЙНЫХ
ВЕЛИЧИН. СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
Знания законов распределения случайных величин доста-
точно для проведения полных вероятностных расчетов.
Однако при решении прикладных задач обычно ни законы
распределения, ни значение их числовых характеристик не
известны. Поэтому исследователь обращается к обработке
опытных данных, которые получены в результате проведенно-
го эксперимента.
Основные задачи в этом случае следующие:
— указать способы сбора и группировки опытных (эмпи-
рических) данных;
— разработать методы анализа статистических данных в за-
висимости от целей исследования.
Введем понятия генеральной совокупности и выборки.
Под генеральной совокупностью будем понимать совокуп-
ность всех мыслимых наблюдений, которые могли бы быть
сделаны при данном комплексе условий.
Но на практике исследование всей генеральной совокупно-
сти либо слишком трудоемко, либо принципиально невозмож-
но. Например, определить продолжительность работы лампоч-
ки. Если мы будем проводить исследование всей генеральной
совокупности, то нечем будет освещать комнаты. Приходится
ограничиваться анализом лишь некоторой выборки из анали-
зируемой генеральной совокупности.
Наблюдения выборки получены с помощью случайного ме-
ханизма из генеральной совокупности, причем каждое из на-
блюдений имеет одинаковый шанс попасть в выборку.](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-27-320.jpg)



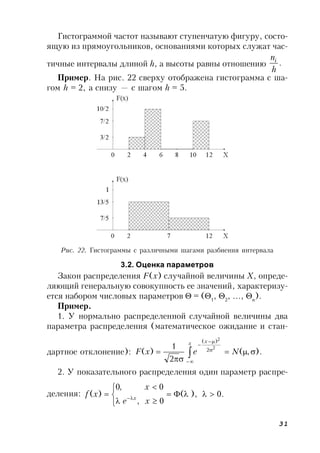















![47
чет изменение среднего значения другой, то такая зависимость
называется корреляционной ),(xfyx где xy — среднеариф-
метическое значение Y, соответствующее значению Х = х.
Уравнение )(xfyx — это уравнение регрессии Y на Х;
f(x) — функция регрессии Y на Х. График f(x) — линия
регрессии Y на Х.
Рассмотрим частный случай. Зависимость между Х и Y —
линейная: Y*
= bx + a = M[Y/X], где Х и Y — количествен-
ные признаки (рис. 28). Для отыскания коэффициентов урав-
нения необходимо провести n независимых испытаний: (x1
, y1
);
(x2
, y2
); … (xn
, yn
). Поскольку наблюдаемые пары чисел мож-
но рассматривать как случайную выборку из генеральной со-
вокупности всех возможных значений случайной величины
(X,Y), то уравнение прямой линии Y = by/x
x + a называют
выборочным уравнением регрессии Y на X, где by/x
— выбо-
рочный коэффициент регрессии Y на X (тангенс угла накло-
на линии регрессии).
Рис. 28. Выборочное уравнение регрессии
Для отыскания коэффициентов используют метод наимень-
ших квадратов (МНК). Для этого составляют следующий
функционал: ,)(),(
1
2*
n
i
ii yyabФ где ;*
abxy ii yi
—
наблюдаемое значение фактора Y; xi
— наблюдаемое значе-
ние фактора X. Необходимо минимизировать функционал
Ф(b, a) min. Из курса математического анализа известно,
что для этого необходимо найти частные производные и при-
равнять их к нулю:](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-47-320.jpg)



























![75
рассматривать случайную функцию одного аргумента. Чаще
всего этим аргументом является время. Обозначают случай-
ную функцию X(t), Y(t)…
Рассмотрим случайную функцию X(t). Произведем m не-
зависимых опытов и получим реализации x1
(t), x2
(t), …, xm
(t).
Каждая реализация — это обычная неслучайная функция
(рис. 32).
Рис. 32. Реализации случайной функции X(t)
Зафиксируем некоторое значение аргумента t = tk
и найдем
значения n реализаций для tk
: x1
(tk
), x2
(tk
), …, xm
(tk
) Эти реа-
лизации называют сечением m реализации случайной функ-
ции при t = tk
.
Причем математическое ожидание случайной функции
M[X(t)] — это не случайная функция.
Часто мы имеем данные для одной случайной функции по
одной реализации, когда аргумент функции t [0,T]. Разобь-
ем интервал [0,T] на n равных частей длинной t (рис. 33).
Получим n значений для реализации x(t1
), x(t2
), …, x(tn
)
или временной ряд, т. е. совокупность значений за несколько
последовательных значений времени.
В общем случае каждый уровень временного ряда форми-
руется из трендовой X*
(ti
), циклической S(ti
) и случайной i
компонент. Модели, в которых временной ряд представлен как
сумма перечисленных компонент, — аддитивная модель, как
произведение — мультипликативная модель. При построении
модели устраняется сезонная компонента из исходных уров-
ней ряда.
X(t)
0](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-75-320.jpg)
![76
Рассмотрим аддитивную модель без сезонной компоненты.
Этот временной ряд можно представить как функциональную
X*
(ti
) и случайную составляющие i
: .,1,)()( *
nitXtx iii
Под трендом (сигналом) временного ряда понимают состав-
ляющую X*
(t), которая является неслучайной функцией. Слу-
чайная составляющая i
называется шумом или ошибкой. Для
случайной составляющей верно утверждение M(i
) = 0. Ина-
че это была бы неслучайная составляющая и ее можно учесть
в X*
(t).
8.1. Трендовые модели временного ряда
Виды тренда:
1. Линейный тренд X*
(t) = a + bt.
2. Квадратичный тренд X*
(t) = a + bt + ct2
.
3. Экспоненциальный тренд X*
(t) = ea+bt
.
4. S-кривая X*
(t) = ea+b/t
.
5. Гипербола X*
(t) = a + b/t.
6. Степенной тренд X*
(t) = atb
.
7. Параболический тренд X*
(t) = a + b1
t + b2
t2
+ … .
Для построения модели линейного тренда используется
МНК минимизации функционала ,][),(
1
2*
n
i
ii xxbaФ где
).();(**
iiii txxtxx
Аналогично регрессионному анализу для минимизации
функционала находят частные производные и приравнивают
их к нулю:
Рис. 33. Одна реализация случайной функции](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-76-320.jpg)

![78
Пример. Рассмотрим в качестве случайного процесса вес
кролика и, в частности, отдельную реализацию данного слу-
чайного процесса. В начале исследований кролик набрал вес,
затем заболел и похудел. С помощью построенных моделей
пытаемся предсказать значения фактора «вес кролика»
(рис. 34). Модель предсказания для большого периода пред-
сказания оказалась физически неверной (отрицательный вес).
Рис. 34. Тренд временного ряда
8.2. Числовые характеристики случайных процессов
Для характеристики поведения случайных процессов обычно
используется более широкий спектр характеристик. Важны-
ми характеристиками являются математическое ожидание
(t) = M[x(t)] и дисперсионная функция 2
(t) =
= M[(x(t) – (t))2
]. С дисперсионной функцией связана и
функция стандартного отклонения .)(2
t
Качественно новой характеристикой случайного процесса
x(t), в отличие от случайной величины X, является автокорре-
ляционная функция: ,
)()(
))()())(()([(
),(
ji
jjii
ji
tt
ttxttxM
ttr
где ti
> tj
. Величина r(ti
, tj
) может характеризоваться как ко-
эффициент корреляции r значений одного и того же фактора X в
различные моменты времени (ti
, tj
). Причем –1 r(ti
, tj
) +1.
Автокорреляция уровней ряда — корреляционная зависи-
мость между последовательными уровнями временного ряда —
определяется по формуле](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-78-320.jpg)















![94
Такой период реализуется, если x0
и m — взаимно простые
числа; a — первообразный элемент по модулю m. Как найти
первообразный элемент по модулю m?
Теорема. Число a есть первообразный элемент по модулю
ре
тогда и только тогда, когда:
1) ре
= 2, a — нечетно; или ре
= 4, a mod 4 = 3; или ре
= 8,
a mod 8 = 3, 5, 7; р = 2, е 4, a mod 8 = 3, 5;
2) р — нечетно (простое); е = 1; a 0 (mod p) и a(p–1)q
1
(mod p) для любого простого делителя q числа p – 1;
3) р — нечетно (простое); е > 1; a удовлетворяет 2) и
ap–1
1 (mod p2
) для любого простого делителя q числа p – 1.
Для важного случая m = 2е
при е 4 в качестве множителя
берут a = 3 или 5 (mod 8). В этом случае четвертая часть всех
возможных множителей дает максимальный период.
Второй распространенный случай m = 10е
; е 5; с = 0 и x, не
кратное 2 или 5, тогда в качестве a берут значения mod 200,
равные: 3,11, 13, 19, 21, 27, 29, 37, 53, 59, 61, 67, 69, 77, 83, 91, 109,
117, 123, 131, 133, 139, 141, 147, 163, 171, 173, 179, 181, 187, 189, 197.
Простой распространенный случай: c — нечетное и взаим-
но простое с m; a mod 4 = 1.
Еще один распространенный случай: a = 75
; c = 0; m = 231
– 1.
10.1.2. Метод серединных квадратов
Пусть имеется 2n-разрядное число, меньшее 1: хi
= 0,a1
a2
a2n
.
Возведем его в квадрат хi
2
= 0,b1
b2
b4n
, а затем отберем
средние 2n разрядов, которые и будут являться очередным чис-
лом псевдослучайной последовательности хi+1
= 0,bn+1
bn+2
b3n
.
Этому методу соответствует рекуррентное соотношение
хi+1
= {102n
[103n
хi
2
] }, где { } и [ ] означают соответственно
дробную и целую часть числа в скобках.
Недостаток метода — наличие корреляции между числами
последовательности, а в ряде случаев случайность вообще мо-
жет отсутствовать. Кроме того, при некоторых i*
может на-
блюдаться вырождение последовательности, т.е. хi
= 0 при
i i*
.](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-94-320.jpg)
![95
10.1.3. Метод середины произведения
Метод является модификацией метода серединных квадра-
тов и состоит в том, что два 2n-значных числа перемножаются,
и средние 2n цифр этого произведения принимаются в каче-
стве следующего числа последовательности. Таким образом,
если хi1
= 0,a1
a2
a2n
; хi
= 0,b1
b2
b2n
, то для получения числа
хi+1
необходимо перемножить хi1
и хi
, т.е. хi1
хi
= 0,c1
c2
c4n
, а
затем отобрать средние 2n цифр этого произведения
хi+1
= 0,cn+1
cn+2
c3n
.
Данному методу соответствует рекуррентное соотношение
при заданных двух начальных числах х0
и х1
:
хi+1
= {102n
[103n
хi
хi–1
]}.
Несмотря на то, что данный метод также имеет тенденцию к
вырождению, он обеспечивает лучшее качество псевдослучай-
ных чисел, чем у чисел, полученных с помощью метода сере-
динных квадратов.
10.1.4. Мультипликативный метод
Широкое применение для получения последовательностей
псевдослучайных равномерно распределенных чисел получи-
ли конгруэнтные процедуры генерации, которые могут быть
реализованы мультипликативным либо смешанным методом.
Конгруэнтные процедуры являются чисто детерминированны-
ми, так как описываются в виде рекуррентного соотношения,
когда функция имеет вид Хi
= aХi
+ c (mod m), где Хi
, a, c,
m — неотрицательные целые числа.
Преобразовав данную функцию, получим
Хi
= i
Х0
+ (i
– 1) /( – 1) (mod m).
Если задано начальное значение Х0
, множитель и адди-
тивная константа , то последняя формула однозначно опре-
деляет последовательность целых чисел Хi
, составленную из
остатков от деления на m, членов последовательности
i
Х0
+ (i
– 1)/( – 1).
Таким образом, для любого i 1 справедливо неравенство
Хi
m. По целым числам последовательности Хi
можно
построить последовательность {хi
} = {Хi
/m} рациональных
чисел из единичного интервала (0, 1).](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-95-320.jpg)

![97
10.2.1. Критерий согласия 2
Пусть имеется — случайная величина, о законе распреде-
ления которой выдвигается некоторая гипотеза; Х — множе-
ство возможных значений . Разобьем Х на m попарно не-
пересекающихся множеств Х1
, Х2
, , Хm
, таких, что
PХj
pj
0 при ;,1 mj p1
+ p2
+ + pm
= PХ = 1.
Выберем n независимых значений 1
, 2
, ,n
и обозначим
через j
количество значений, попавших в j множество (Хj
).
Очевидно, что математическое ожидание j
равно npj
, т.е.
М[j
] = npj
.
В качестве меры отклонения всех от Npj
выбирается вели-
чина
.
1
2
2
набл
m
j j
jj
np
np
При достаточно большом n величина 2
n
хорошо подчиняет-
ся закону распределения 2
с (m – l – 1) степенями свободы
(l — число параметров распределения). Уравнение
,}{
0
1
2
x
lmn dxxkxP
где km–l–1
(x) — плотность распределения 2
с (m – l – 1) сте-
пенью свободы, позволяет найти критическую точку 2
кр
.
При малом объеме выборки лучше определять не крити-
ческую точку, а доверительный интервал принятия гипотезы.
При заданном уровне значимости или надежности (обыч-
но = 1 – = 0,95) можно определить нижнюю 2
н
и верхнюю
2
в
границы области возможного принятия гипотезы (довери-
тельного интервала). Для этого нужно решить соответственно
следующие уравнения:
,}{;}{
2
в
2
н
2
в
22
н
2
dxxkPdxxkP rnrn
где = 1 ; r = m – l – 1. Из данных уравнений следует, что
F(2
н
) = и F(2
в
) =., т. е. 2
н
— квантиль , а 2
в
— квантиль .
10.2.2. Тесты проверки «случайности»
На практике обычно применяют два теста проверки «слу-
чайности»: тест проверки серий и тест проверки частот и пар.](https://image.slidesharecdn.com/lujds88rucowhayzokgq-signature-7265c3e20b8e507ebe4bb1014784c684363c1b6eb97f77a9a34b9f01330933a1-poli-160712064535/85/569-97-320.jpg)


































































































