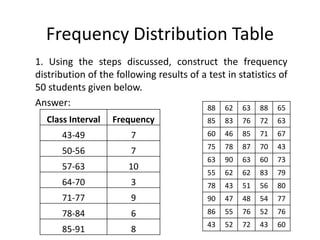
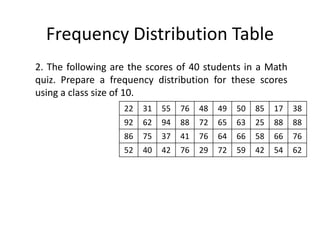
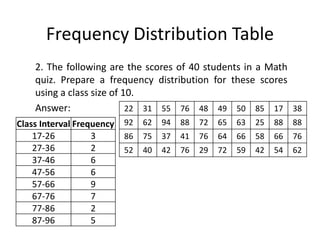
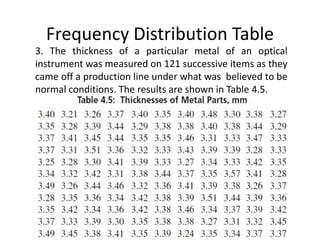
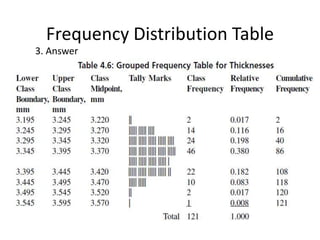
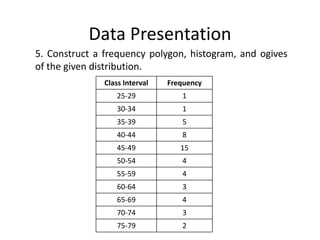
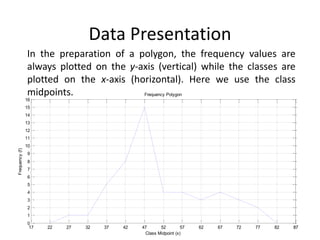
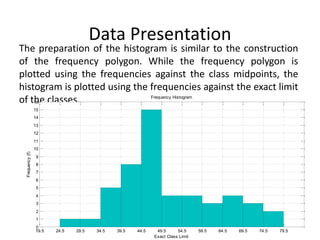
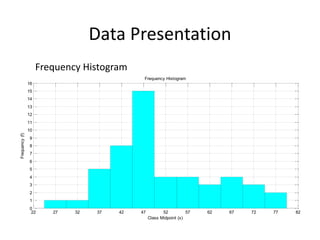
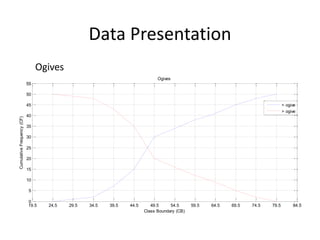
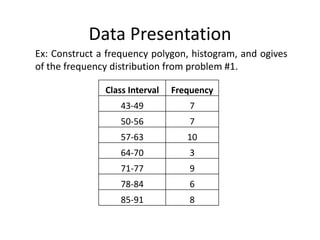
The document discusses frequency distribution tables, including how to construct them from raw data by grouping data into classes of equal intervals and determining the frequency of observations within each class. Key aspects covered include determining class limits, boundaries, frequencies, widths, and cumulative frequencies. Examples are provided to demonstrate how to build a frequency distribution table and corresponding graphical representations like histograms, frequency polygons, and ogives from sets of data.