Download as PDF, PPTX


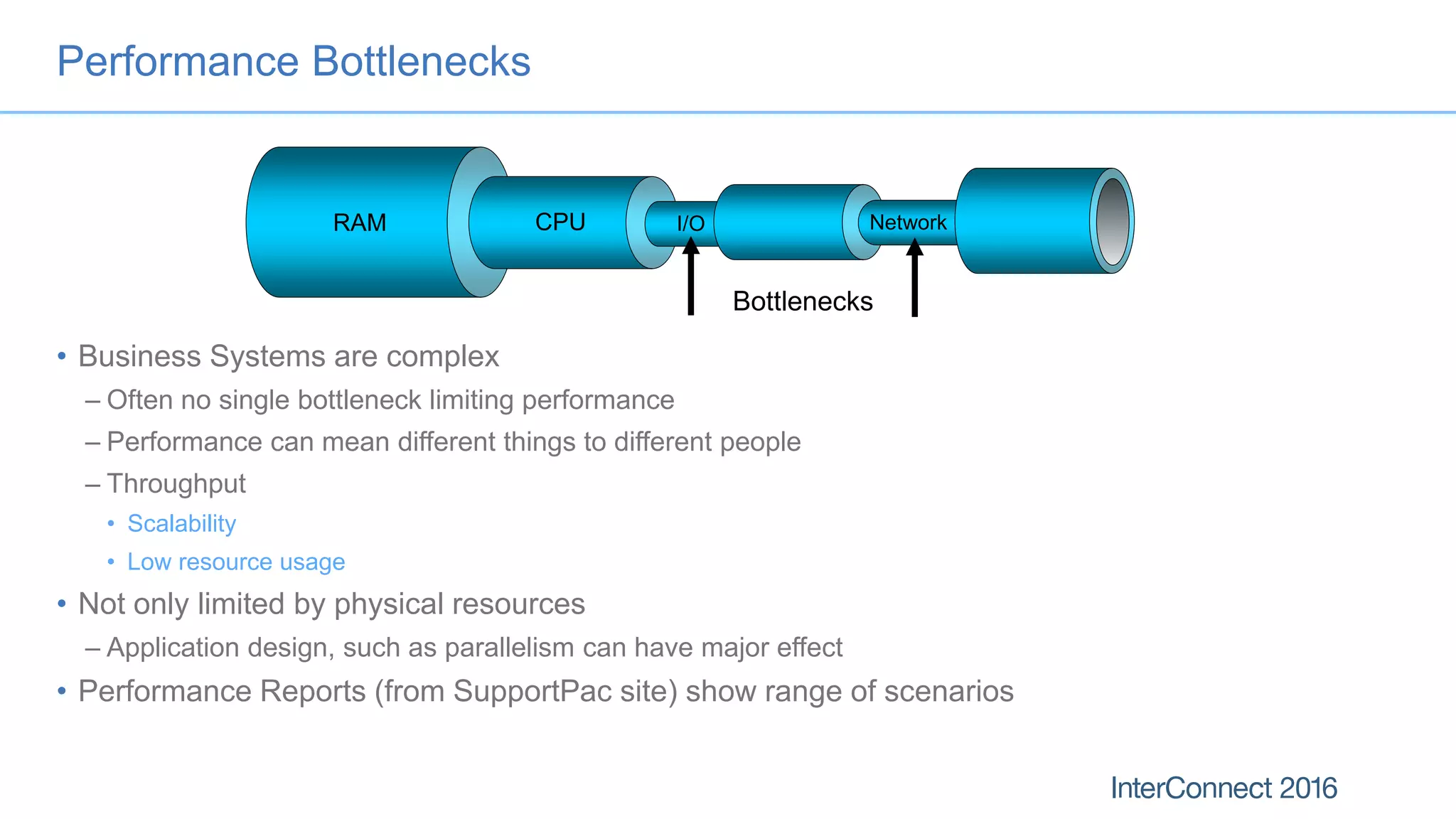
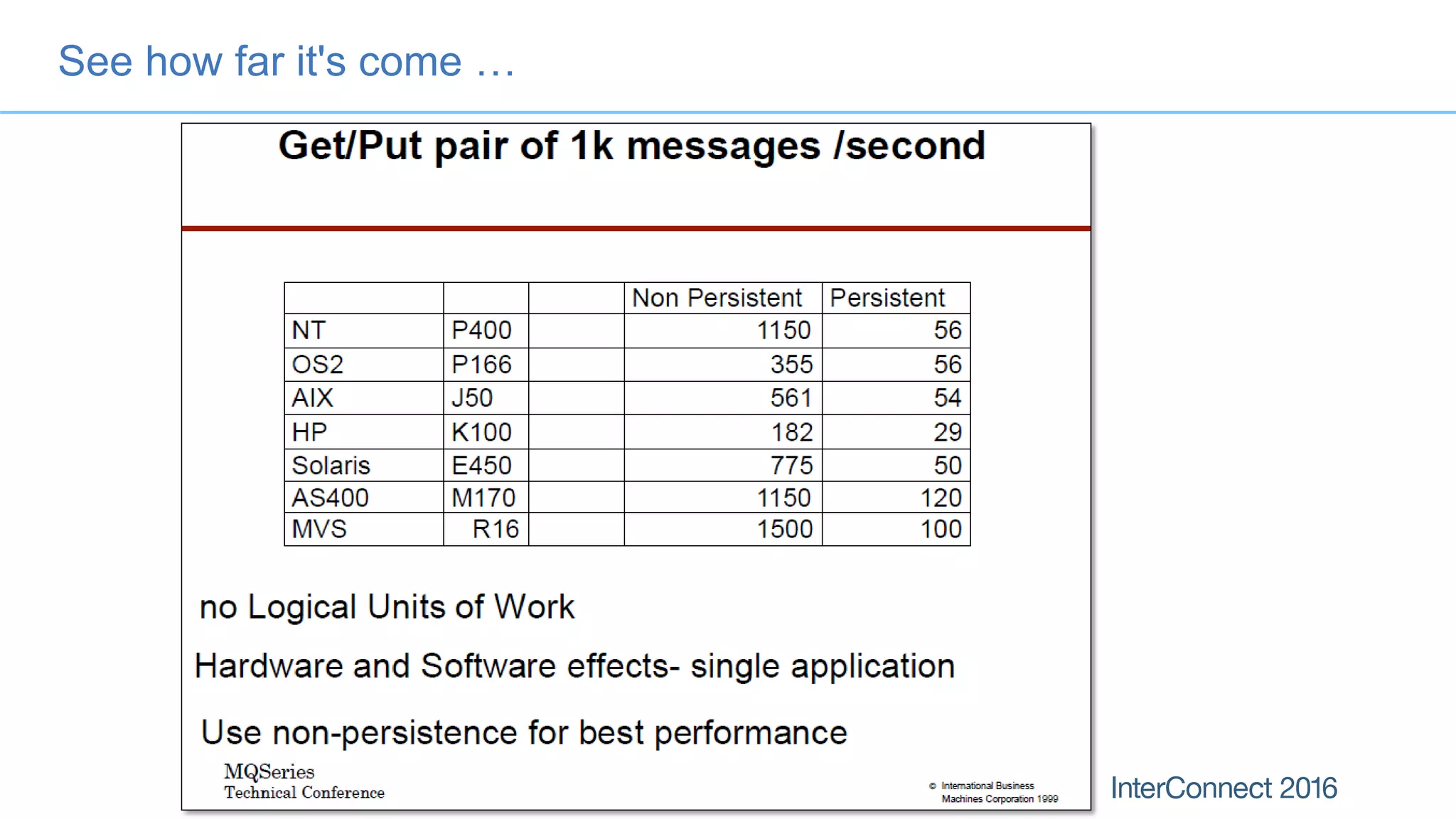
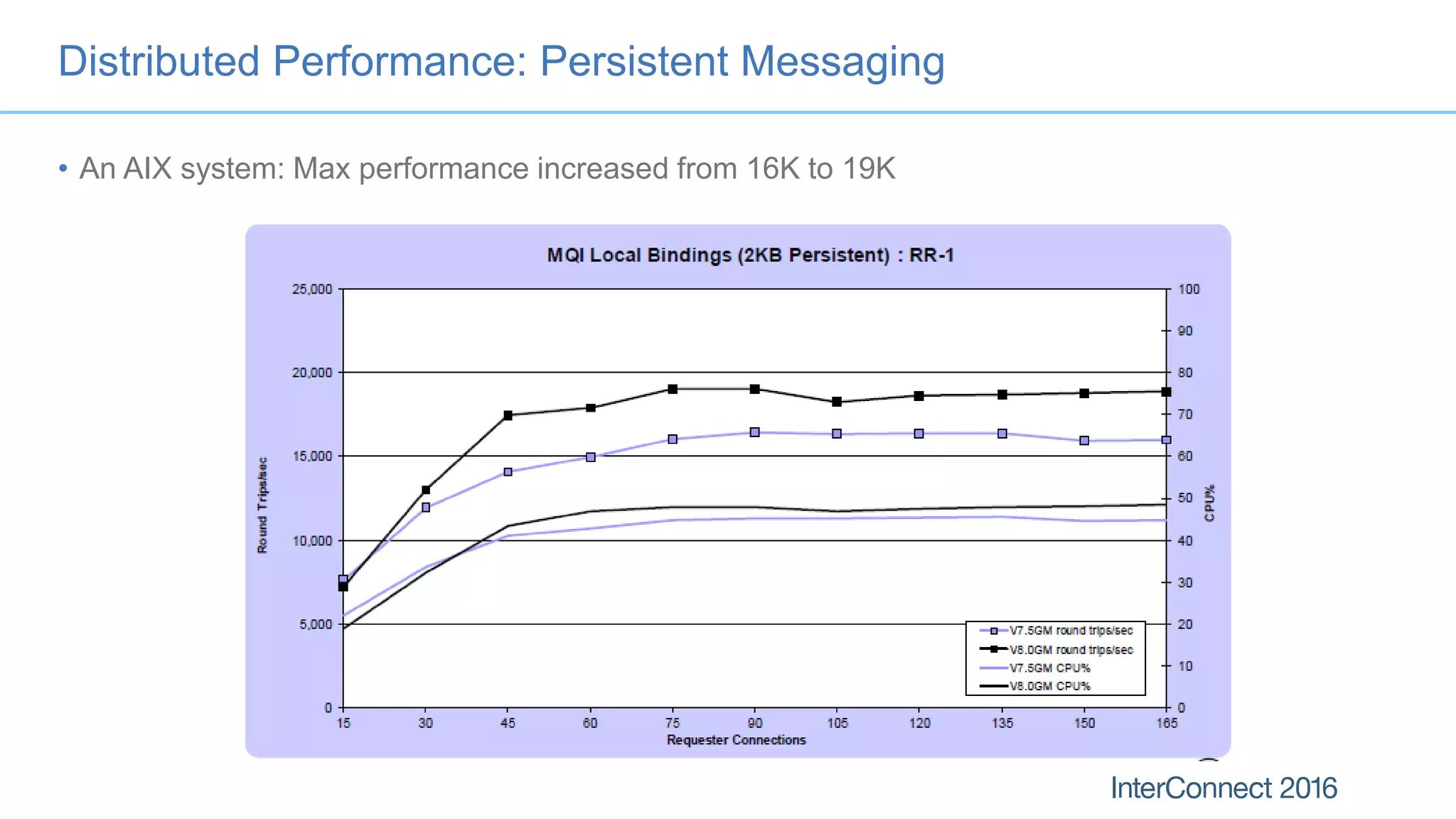
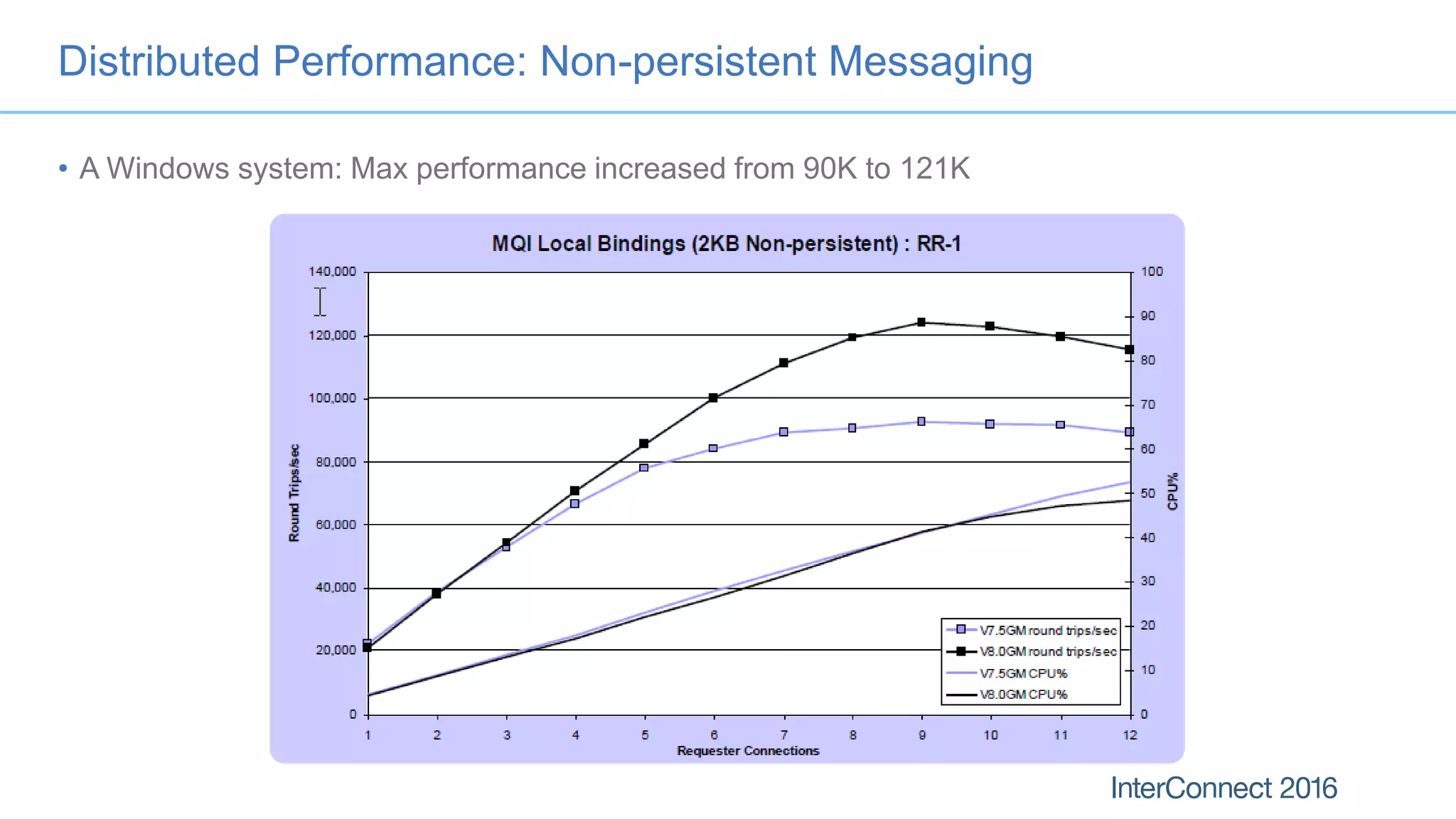


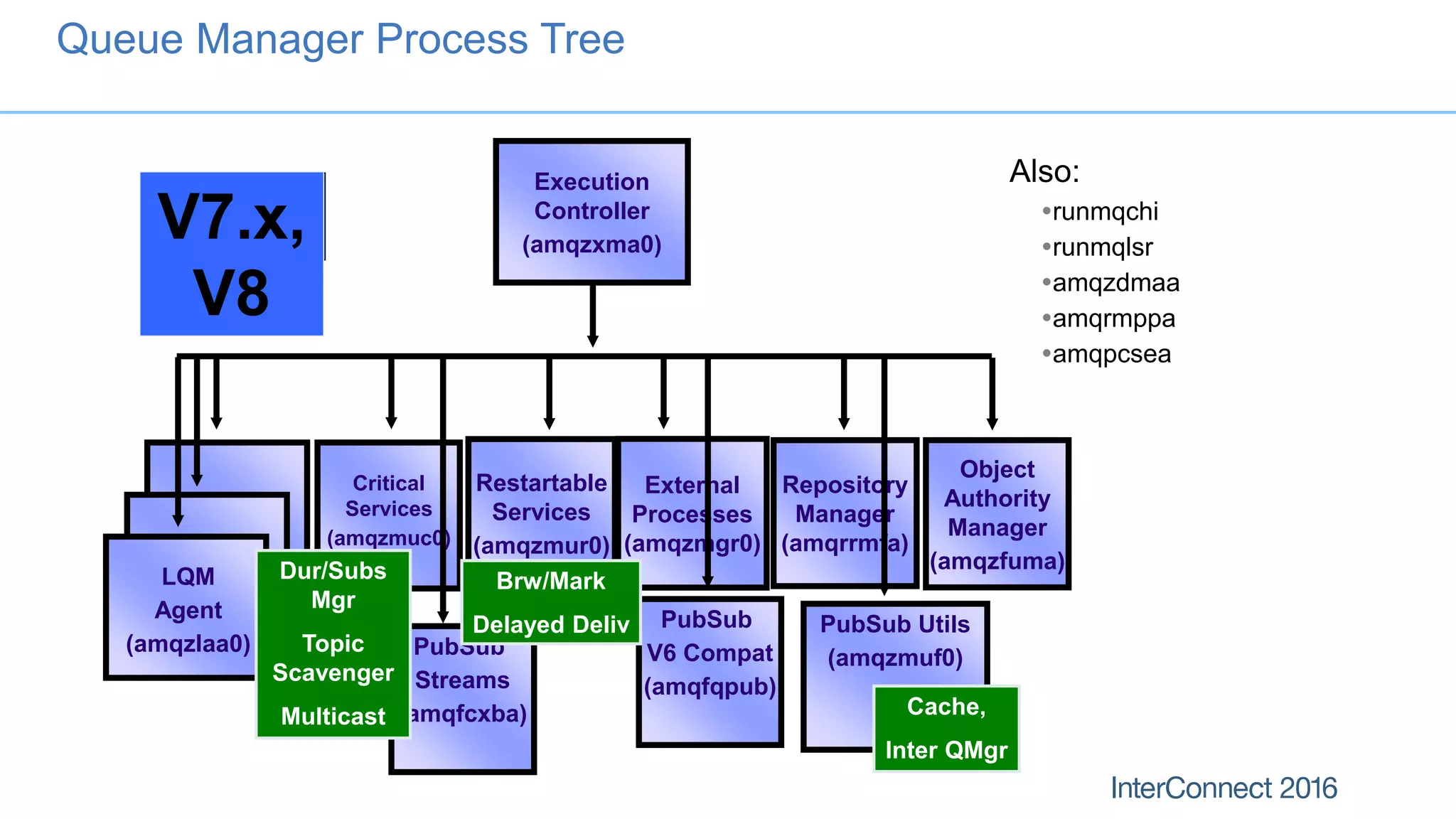
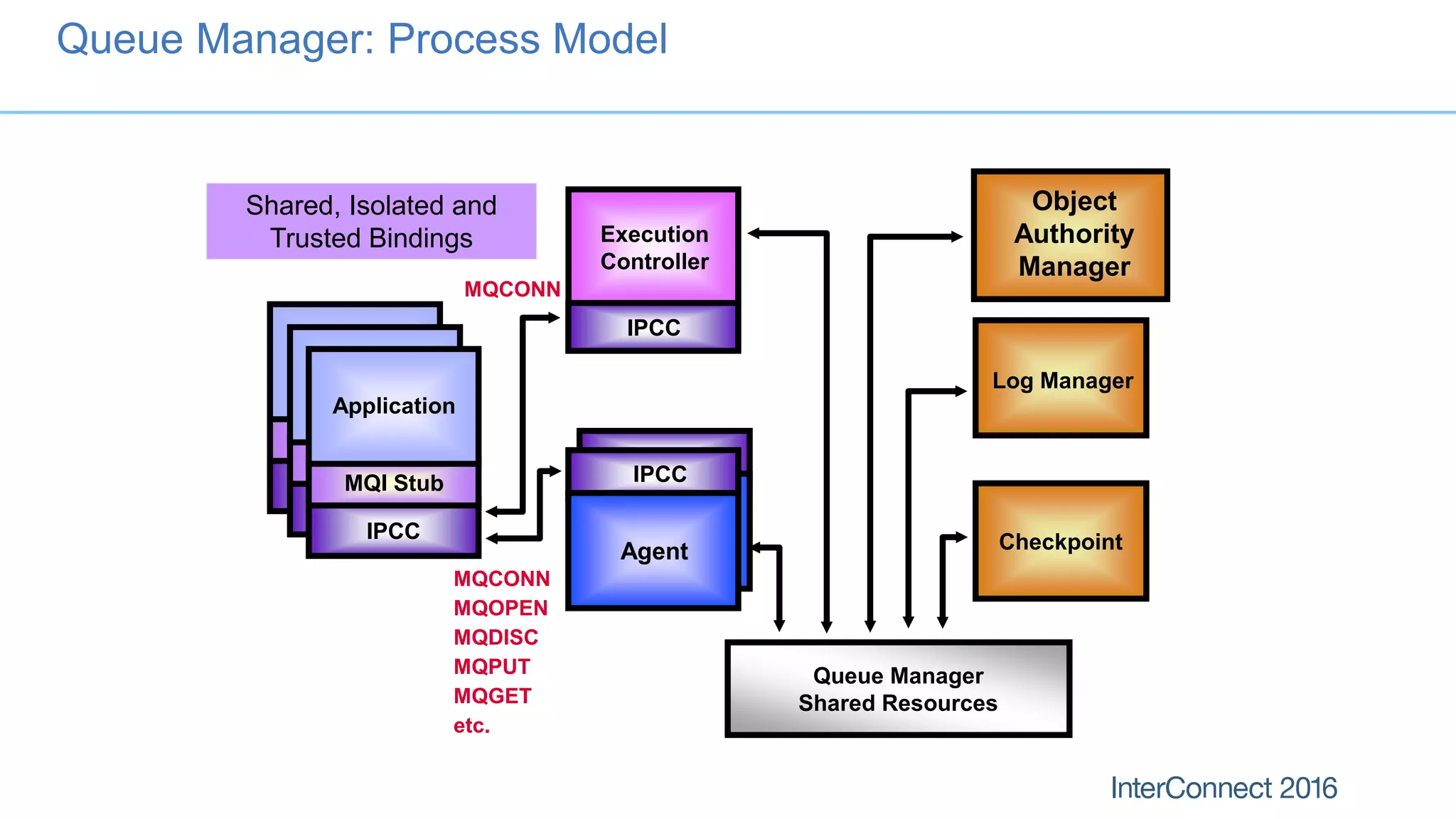

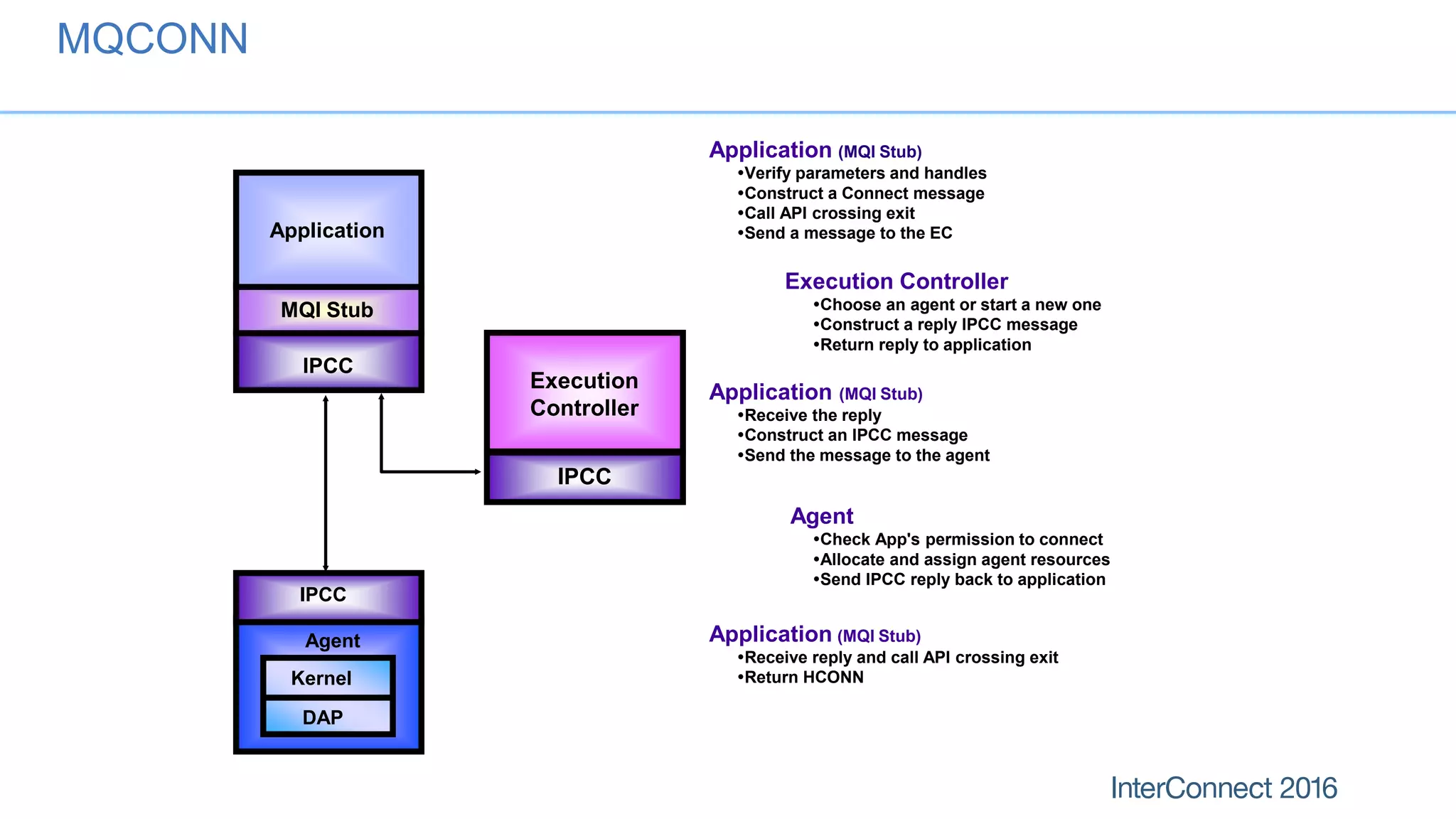
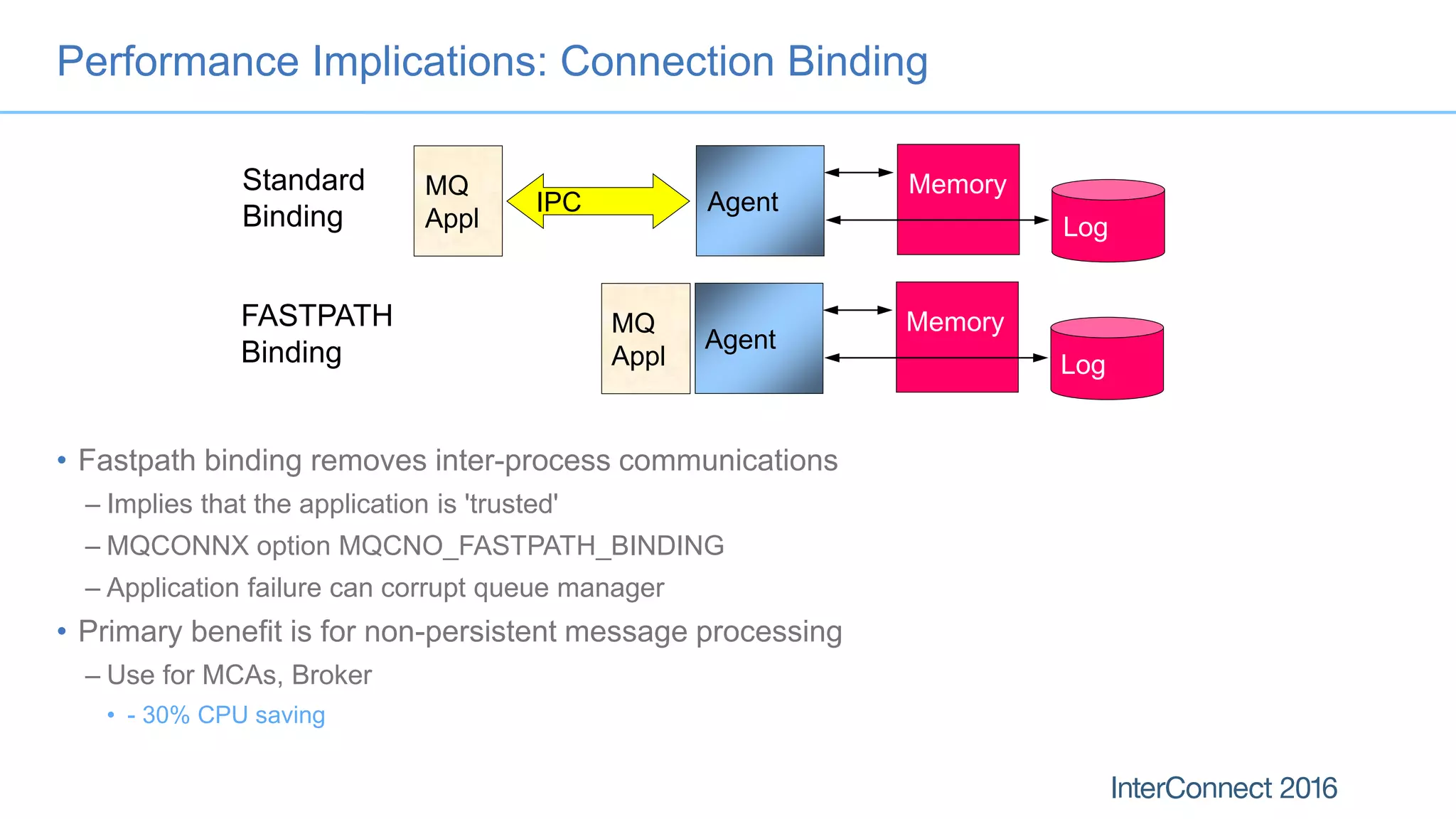

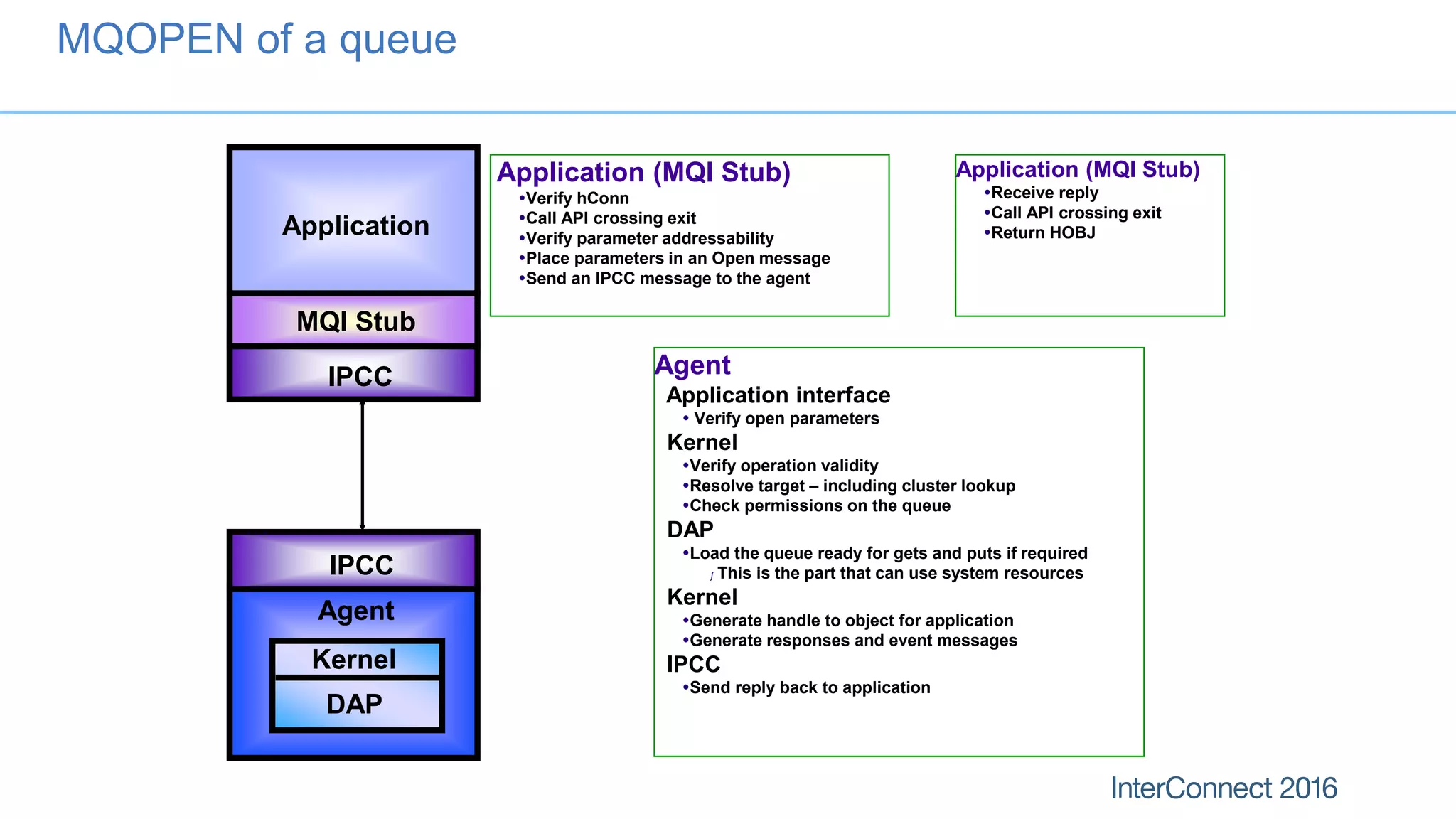


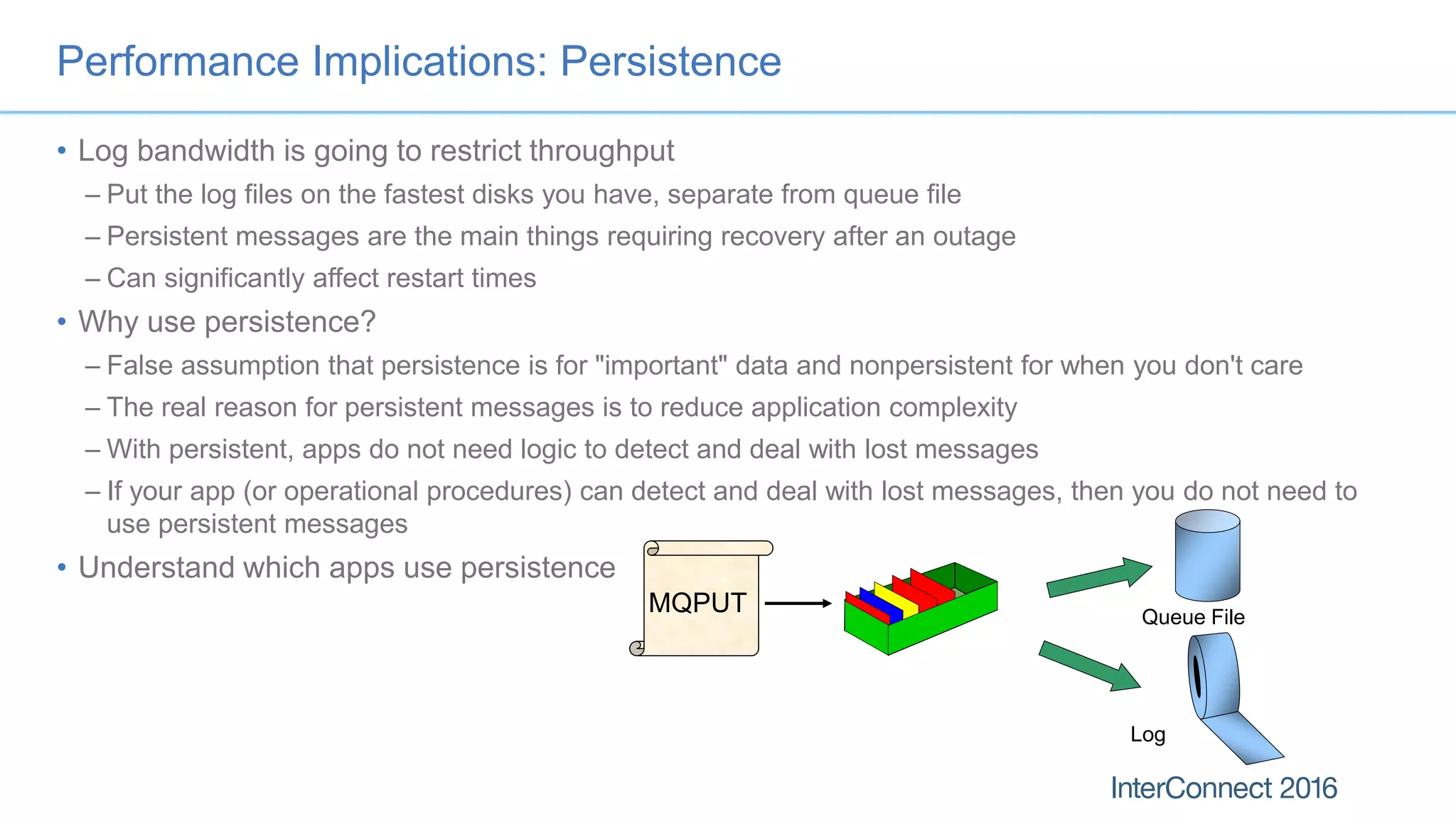

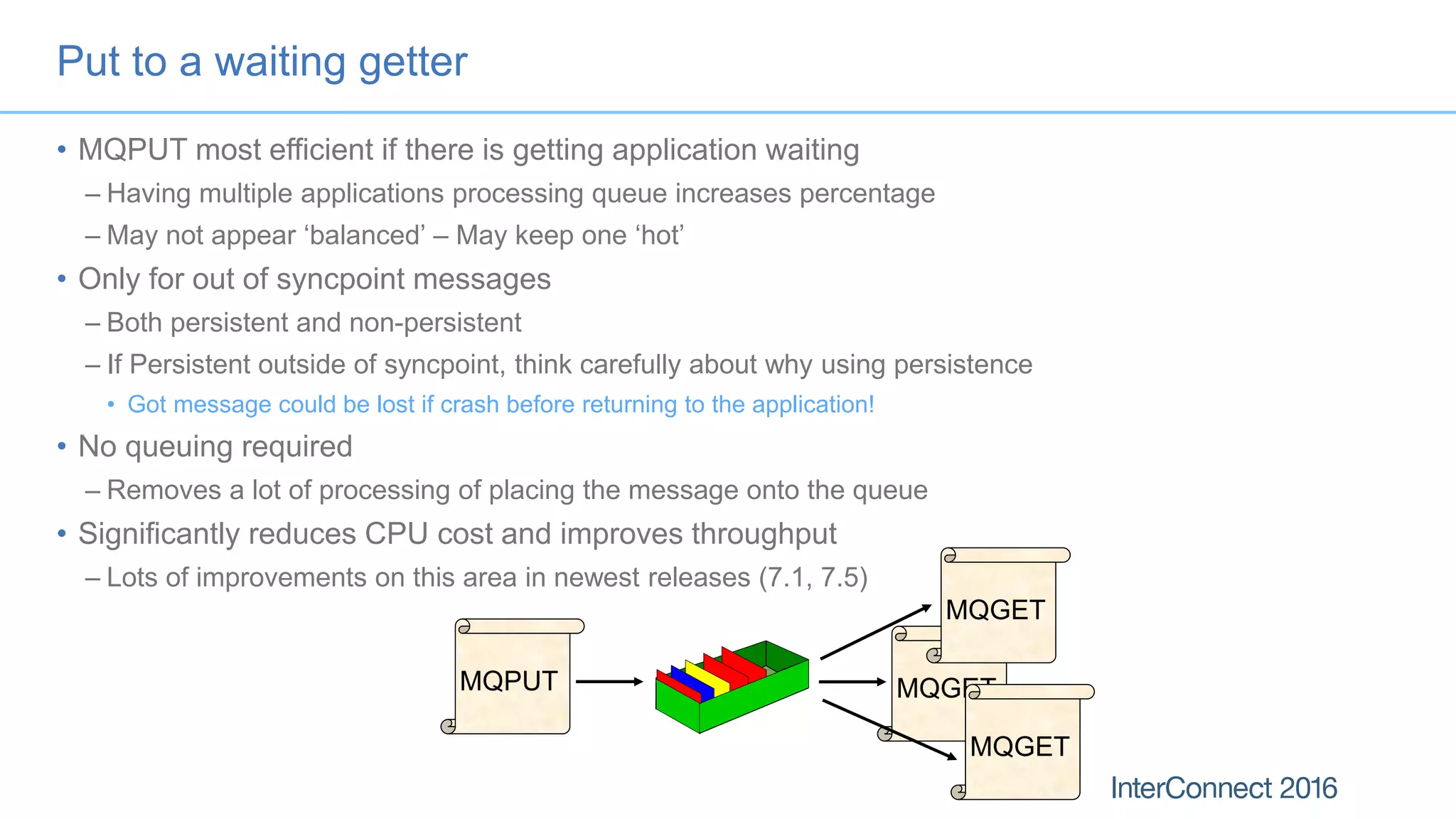






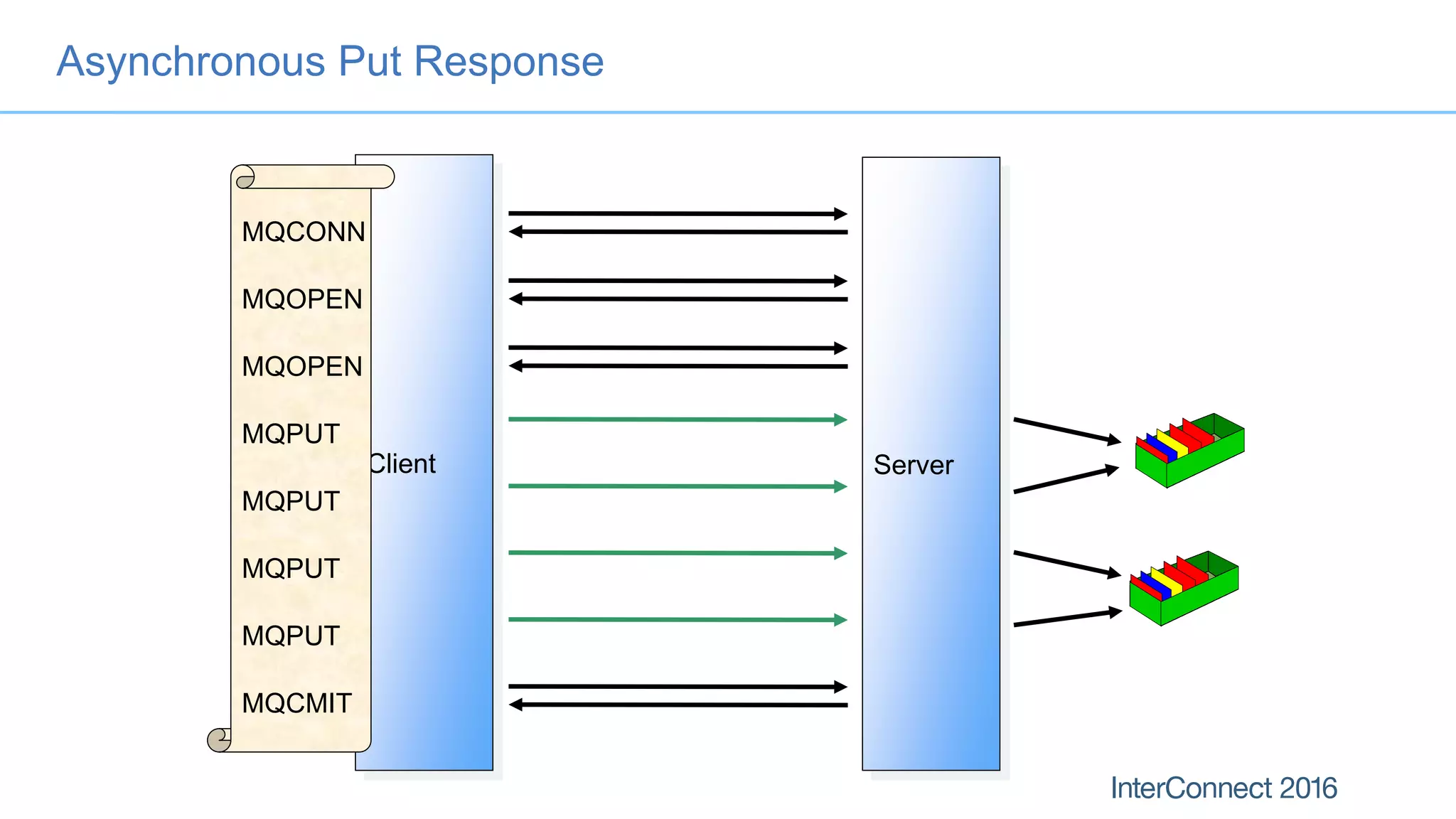
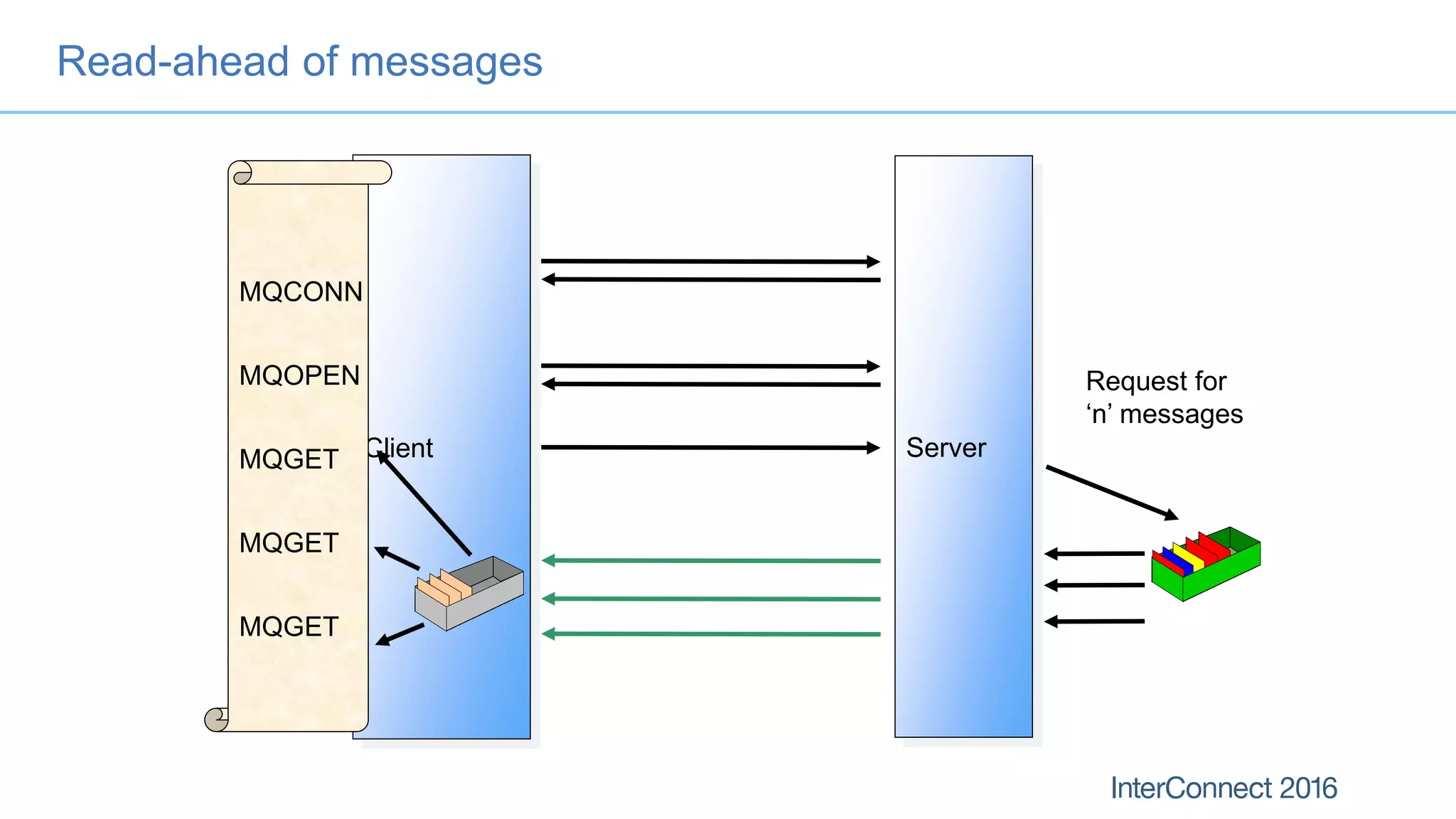











The document discusses performance optimization for IBM MQ messaging applications, detailing various performance bottlenecks, improvements in versions, and recommendations for application design. Key topics include the importance of message persistence, performance implications of connection binding, and enhancements in the queue manager's structure to improve scalability and efficiency. It also covers logging, recovery, and the significance of understanding application patterns to enhance throughput and reduce latency.















































































