Download as PDF, PPTX








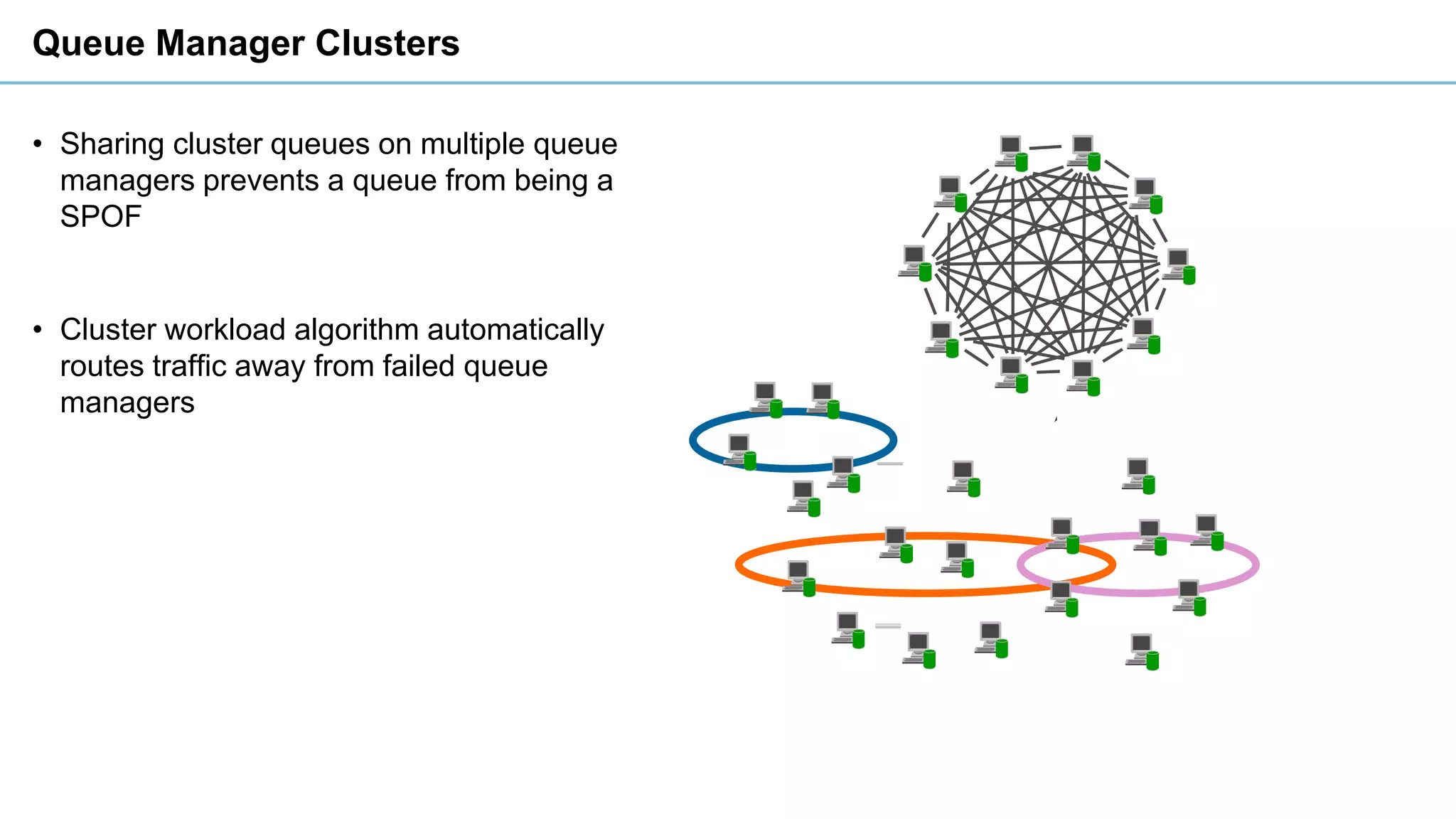
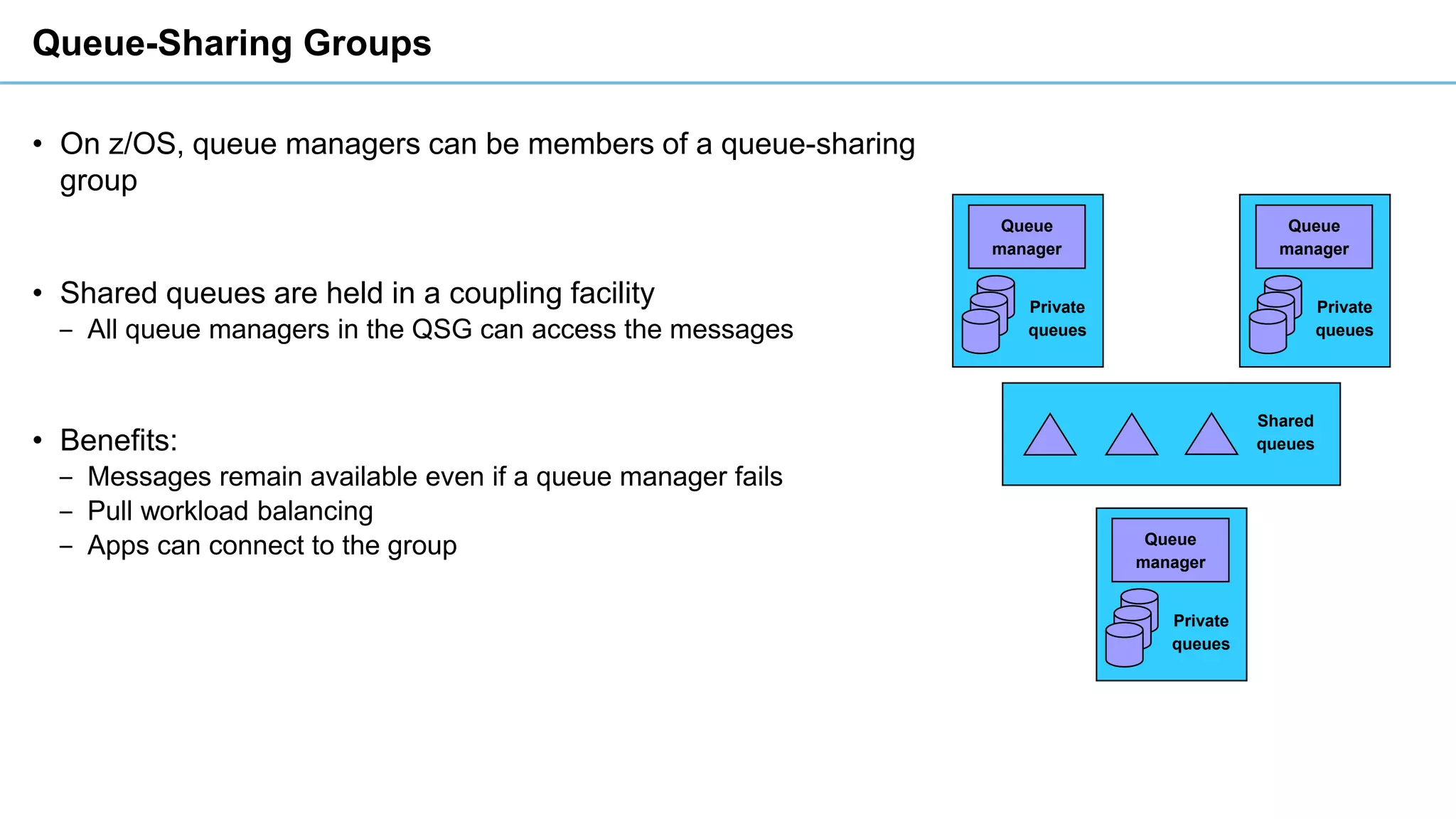




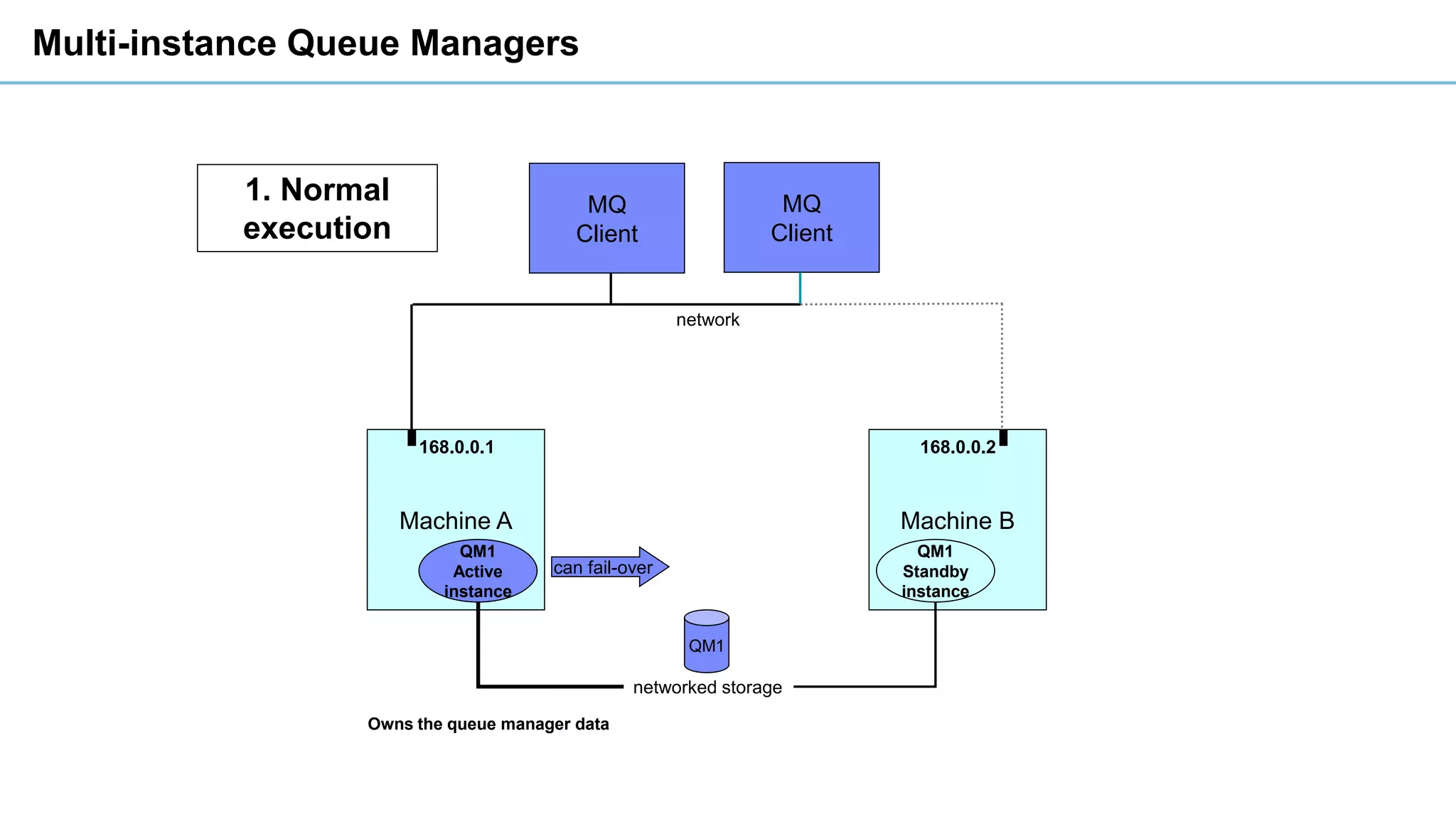
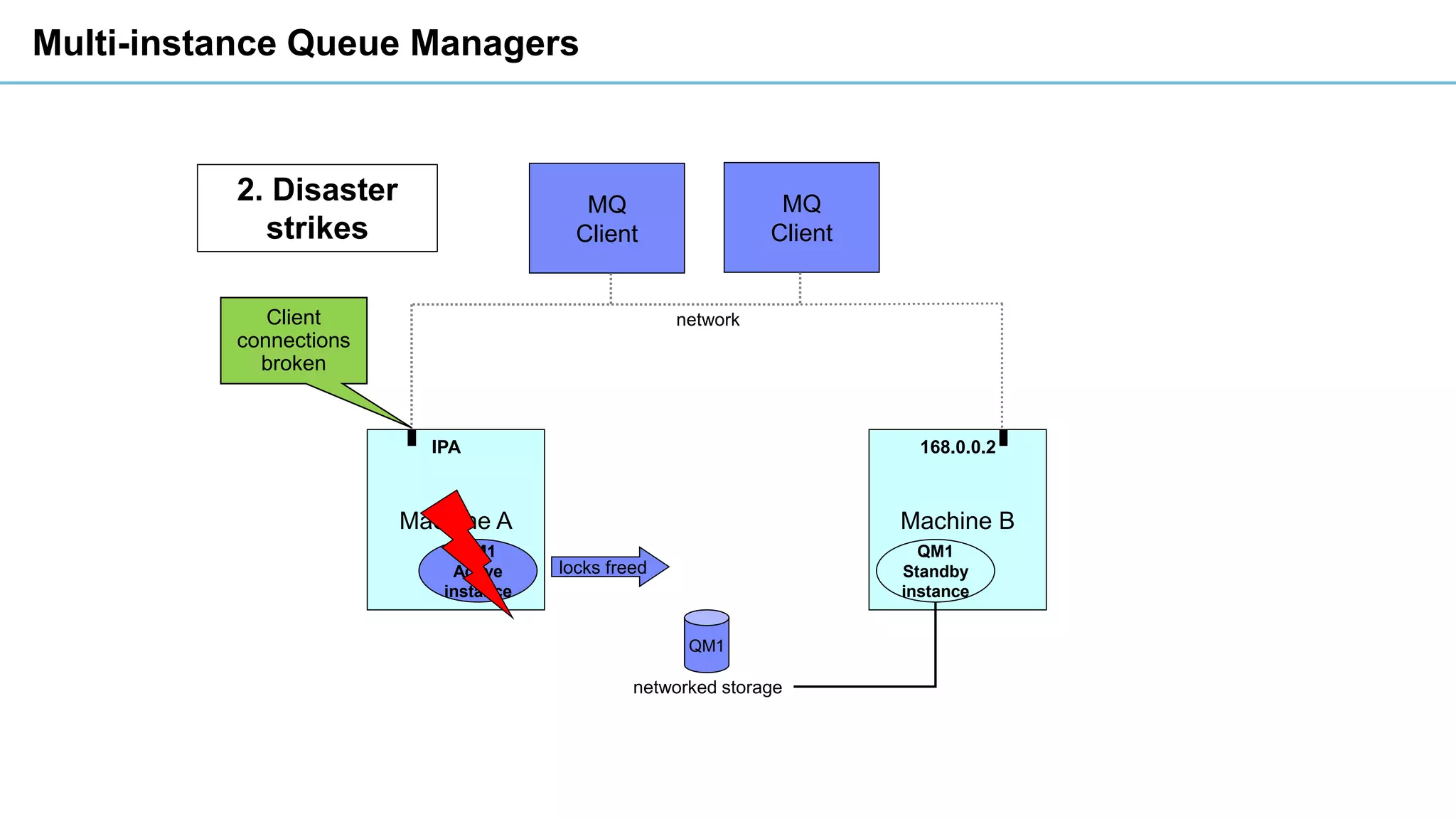
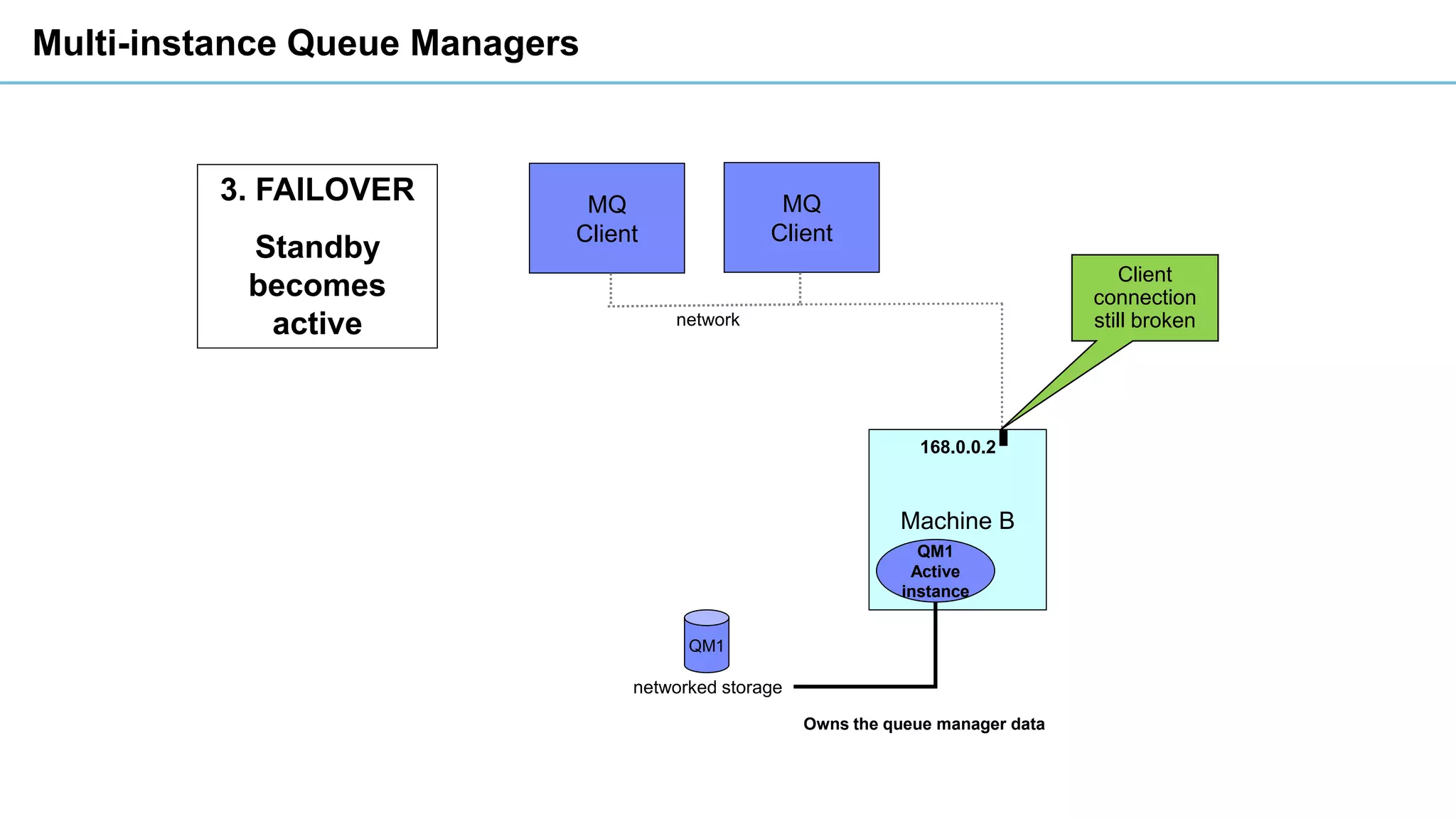
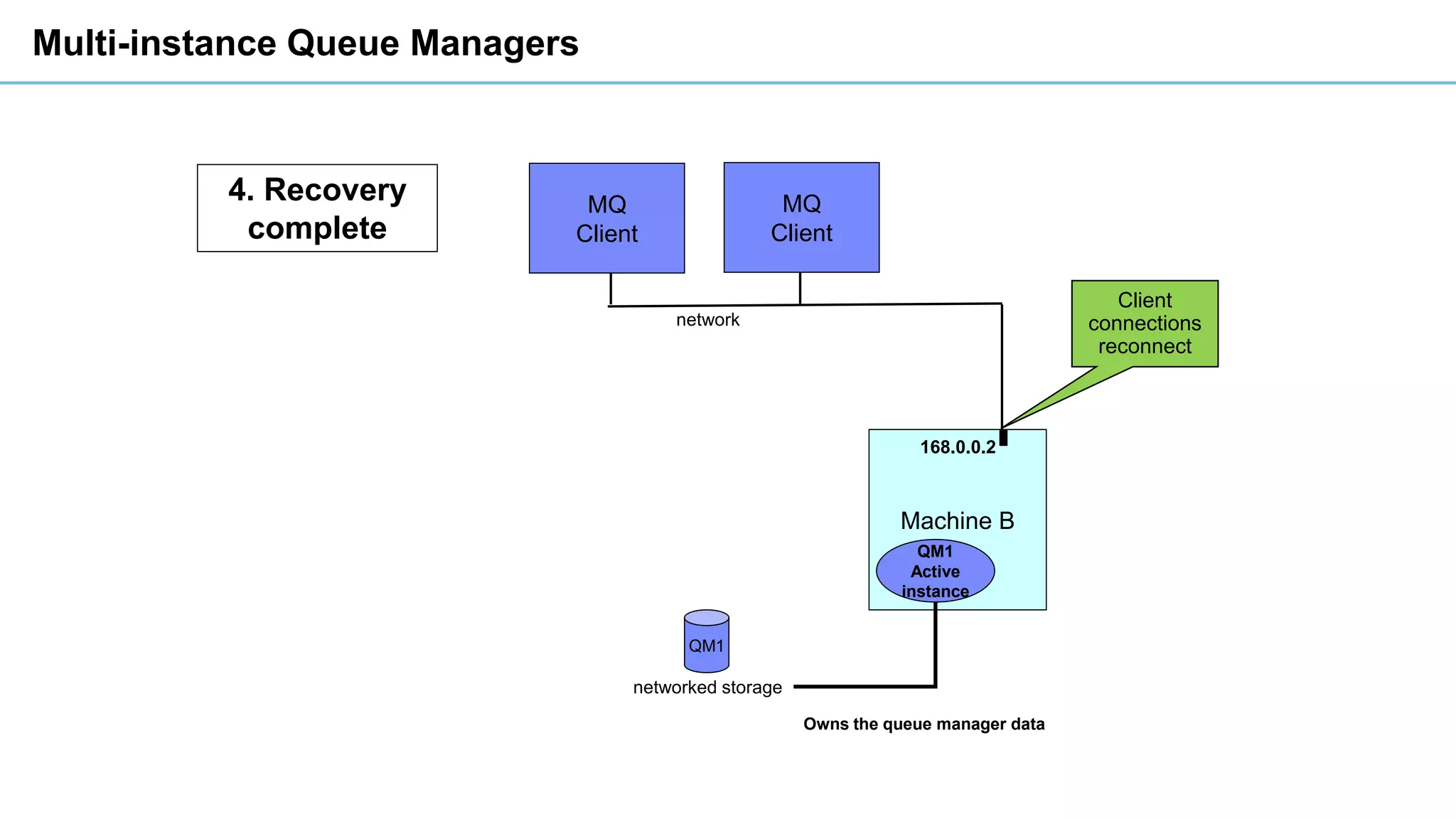




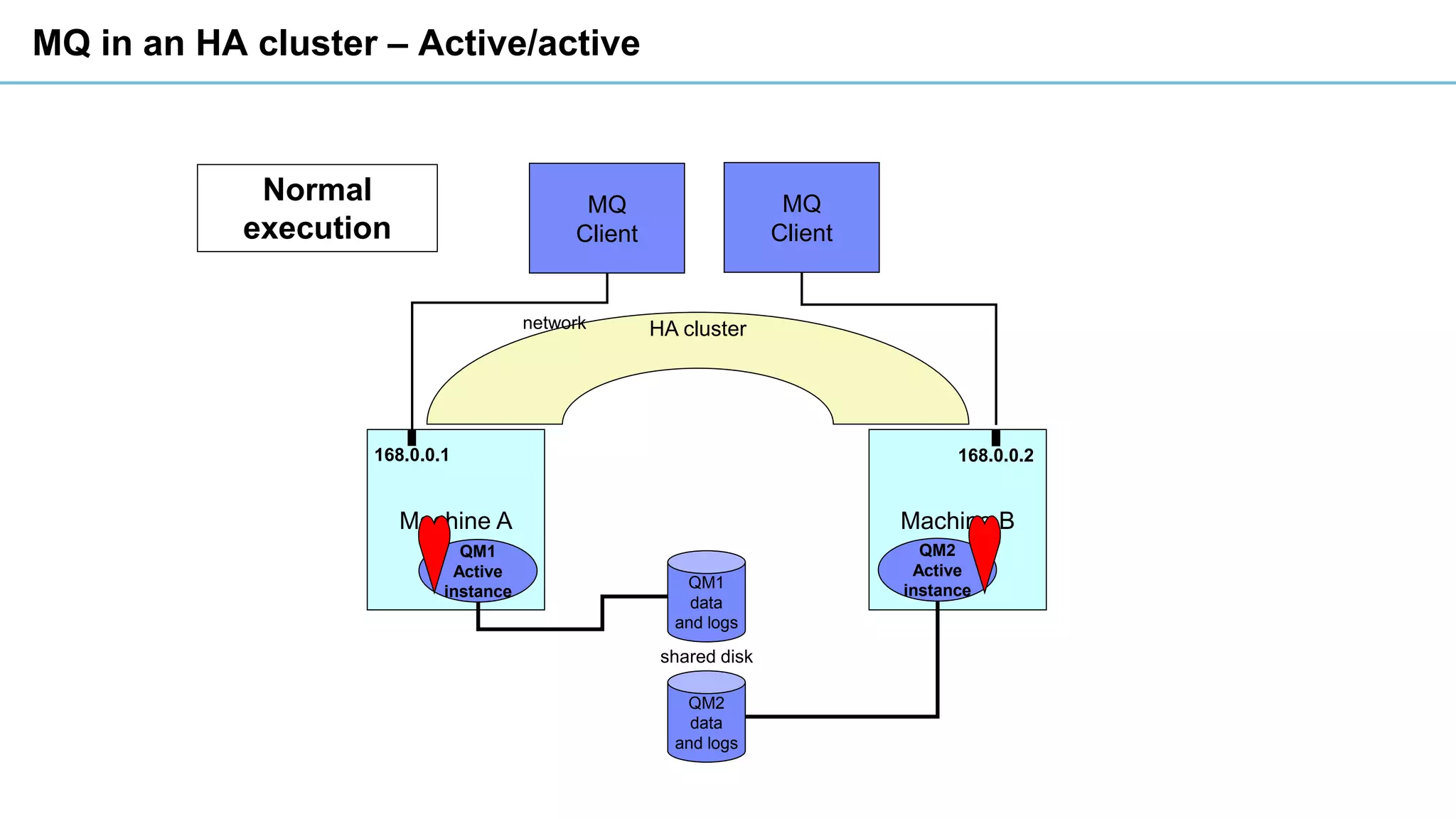
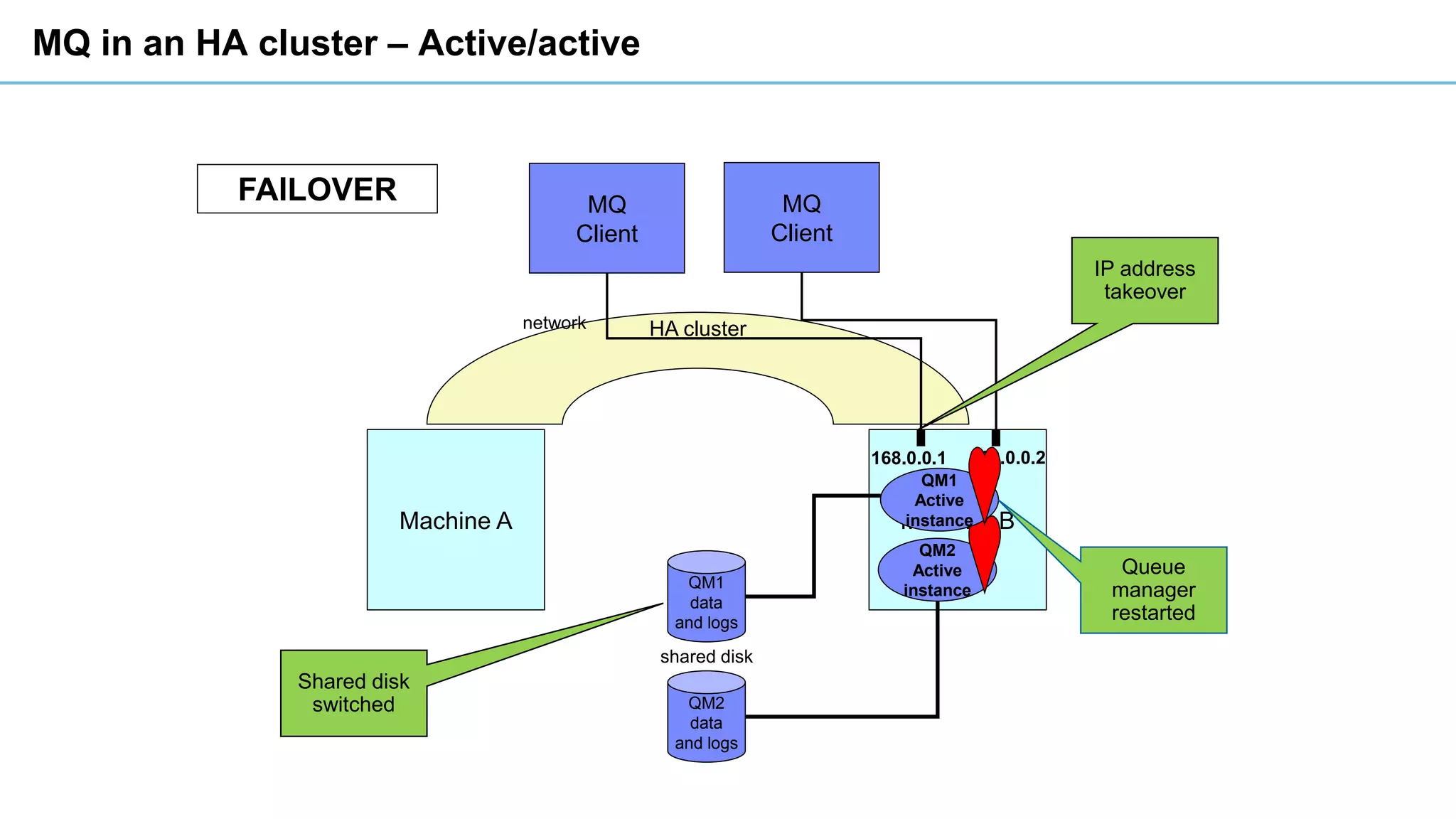





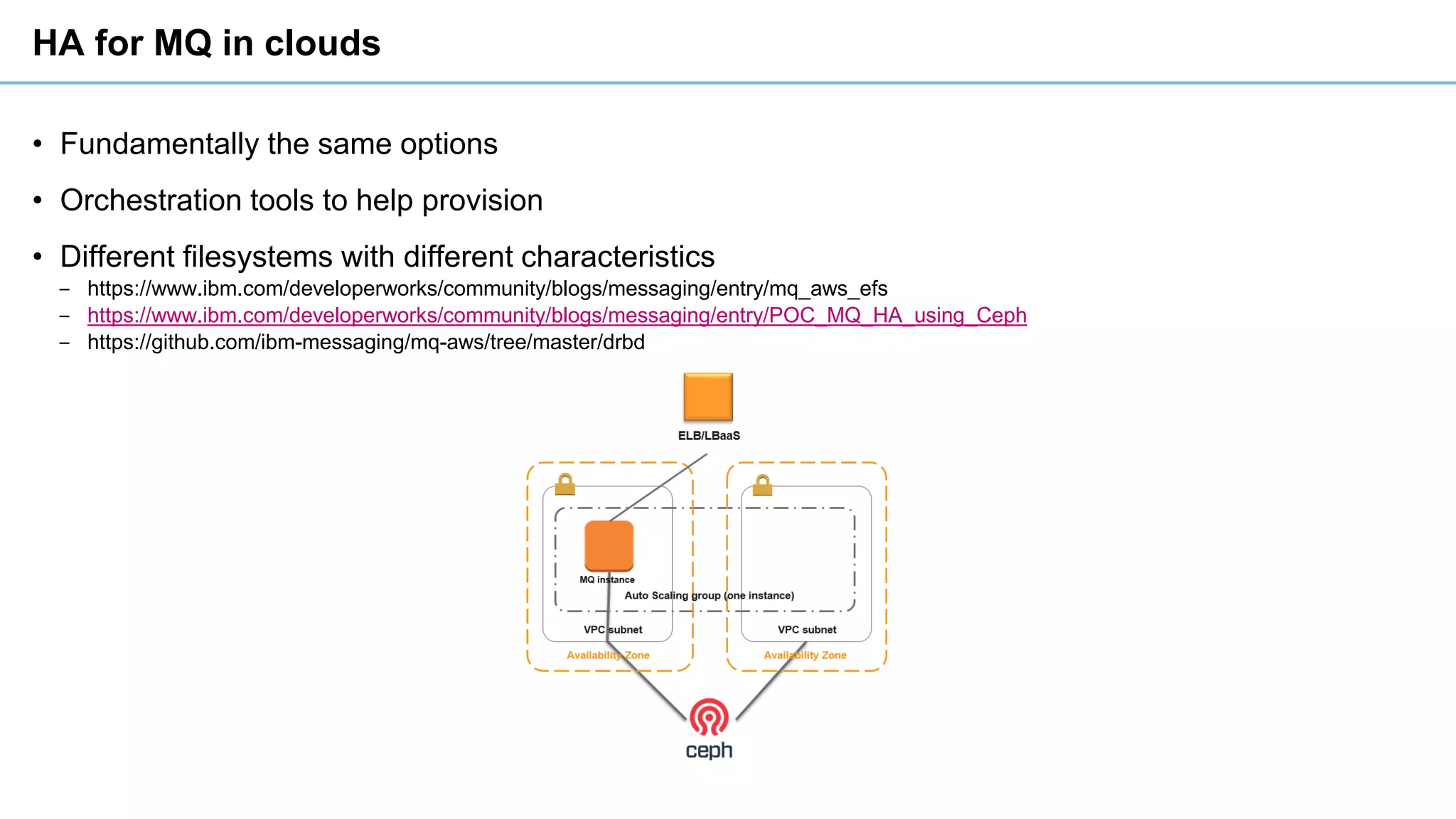
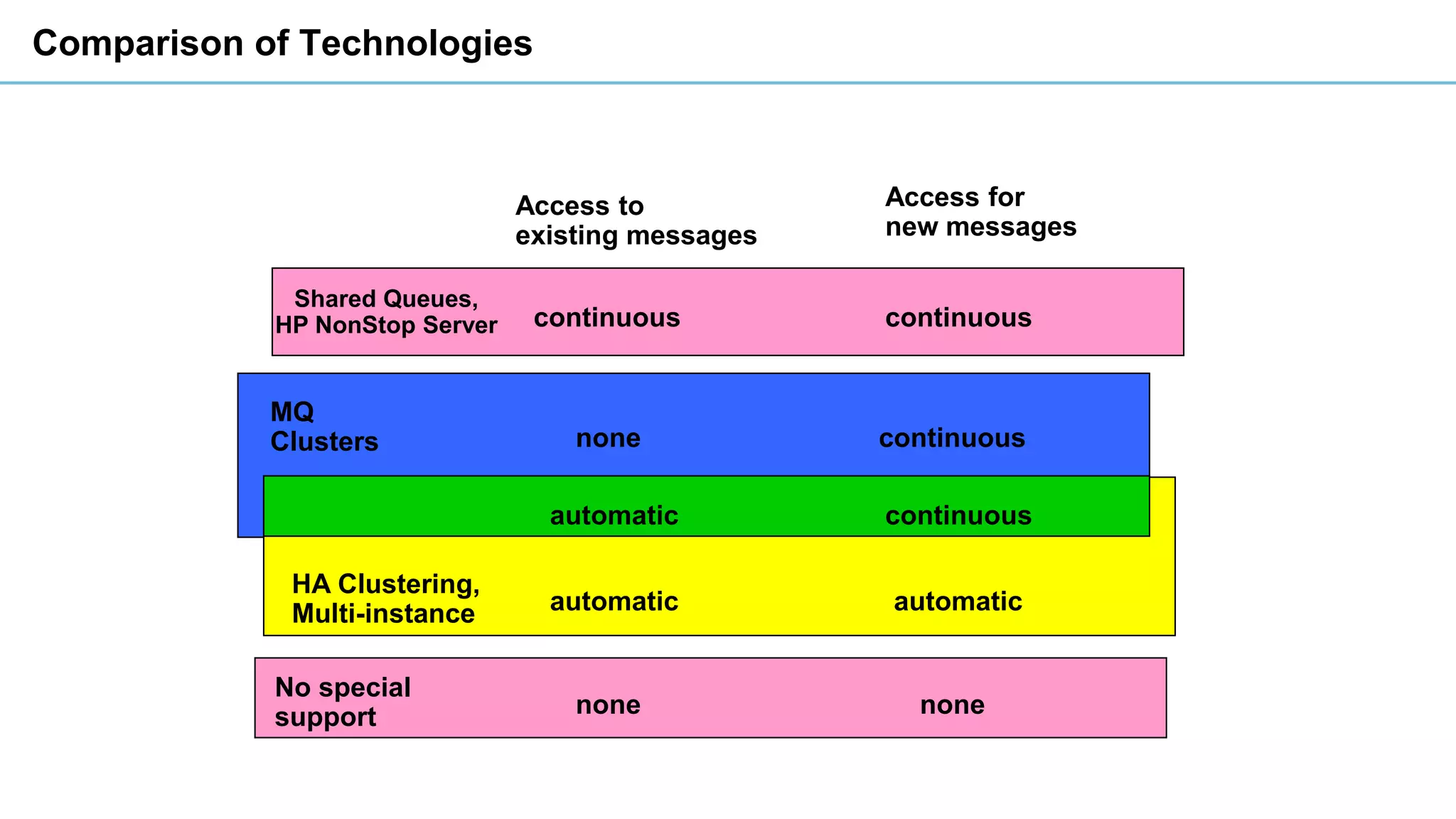






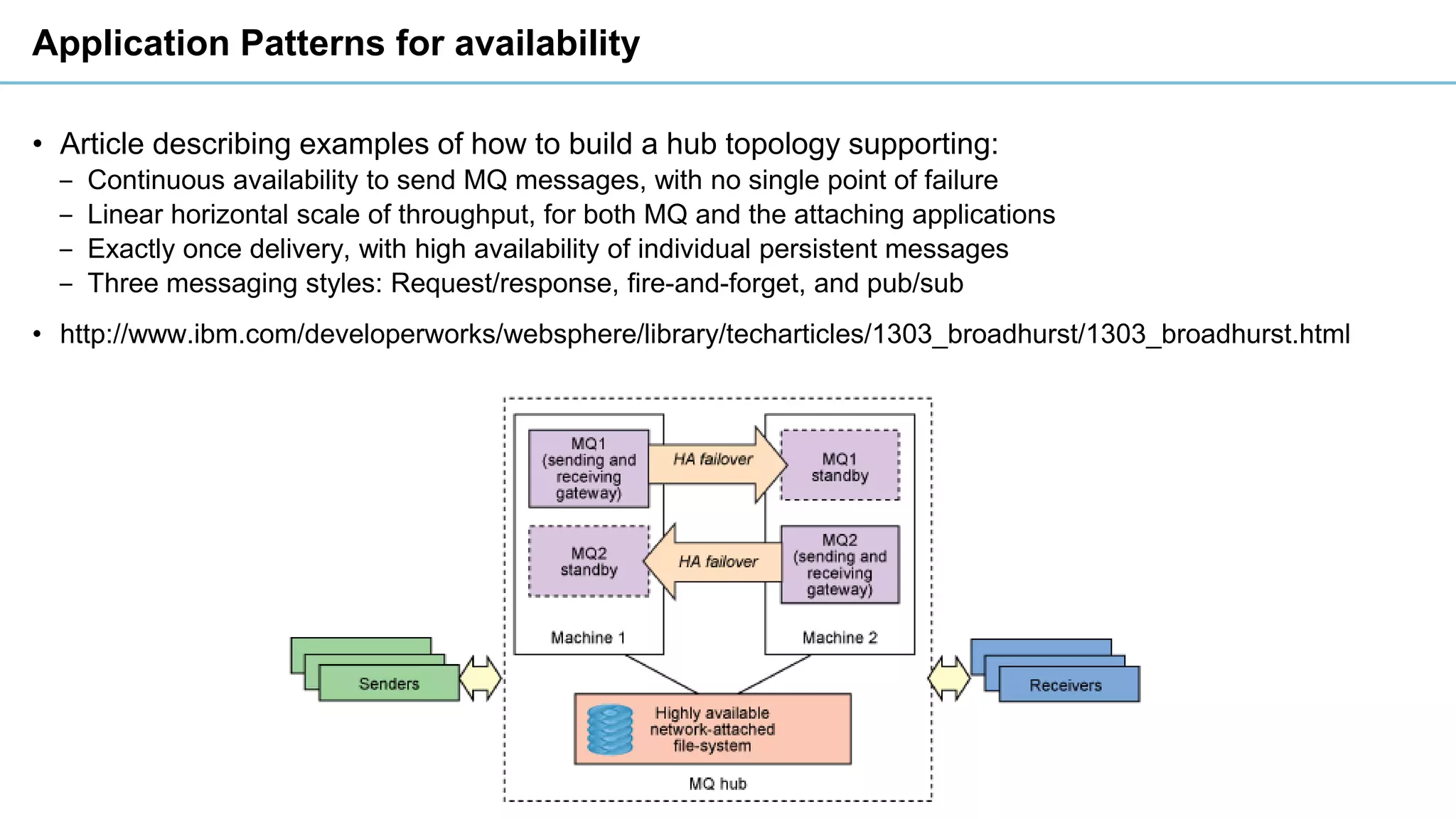

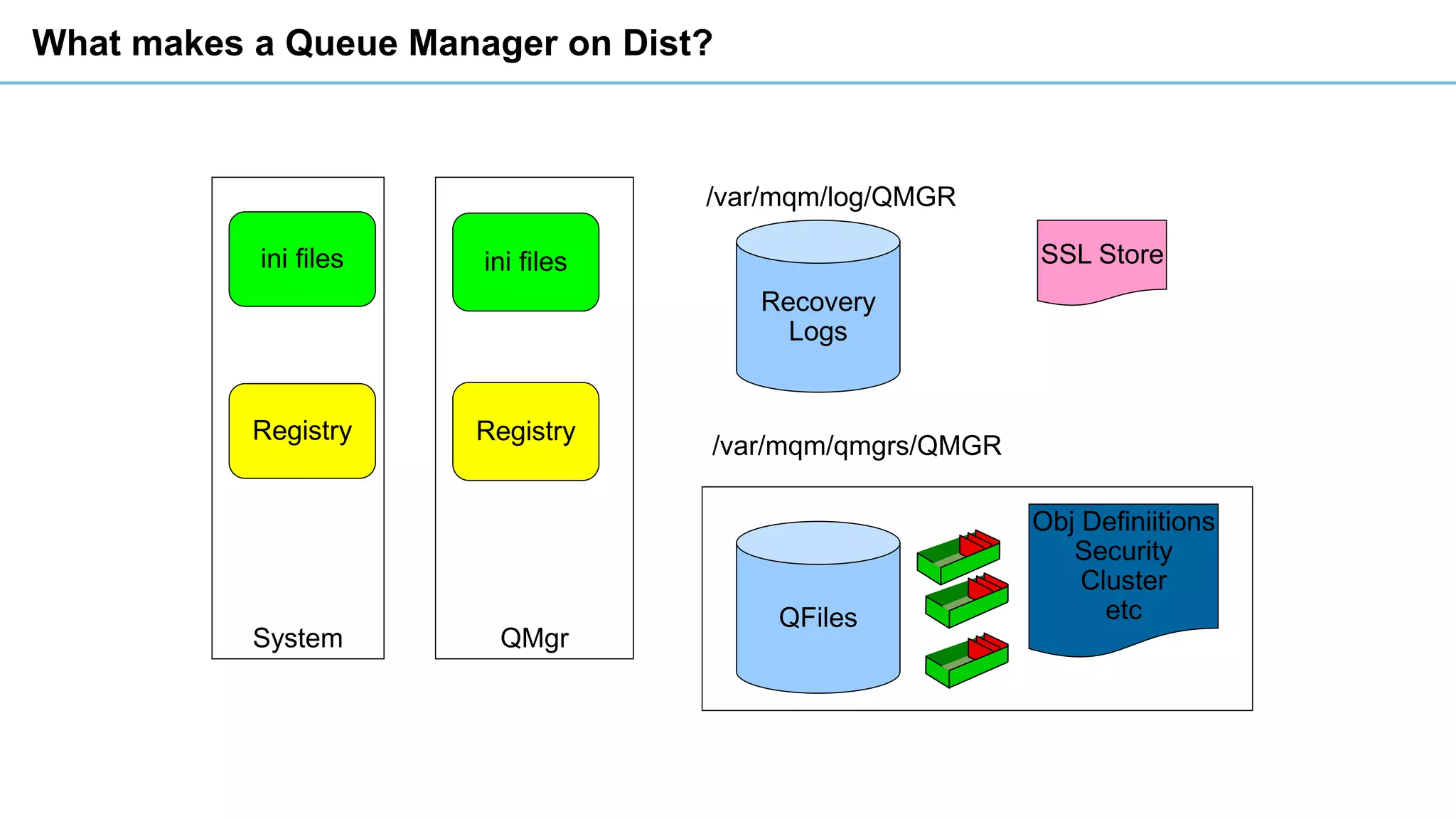

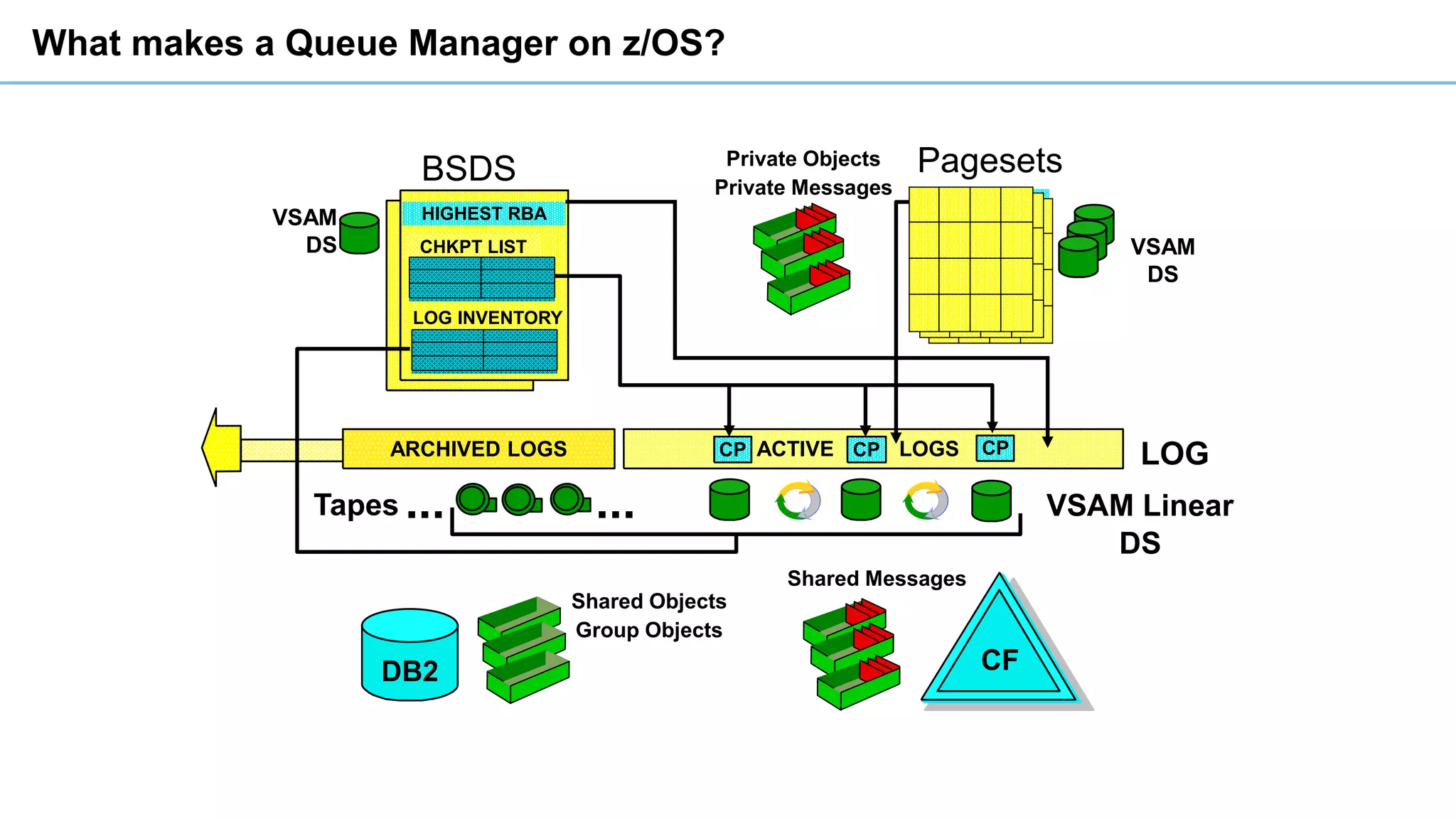






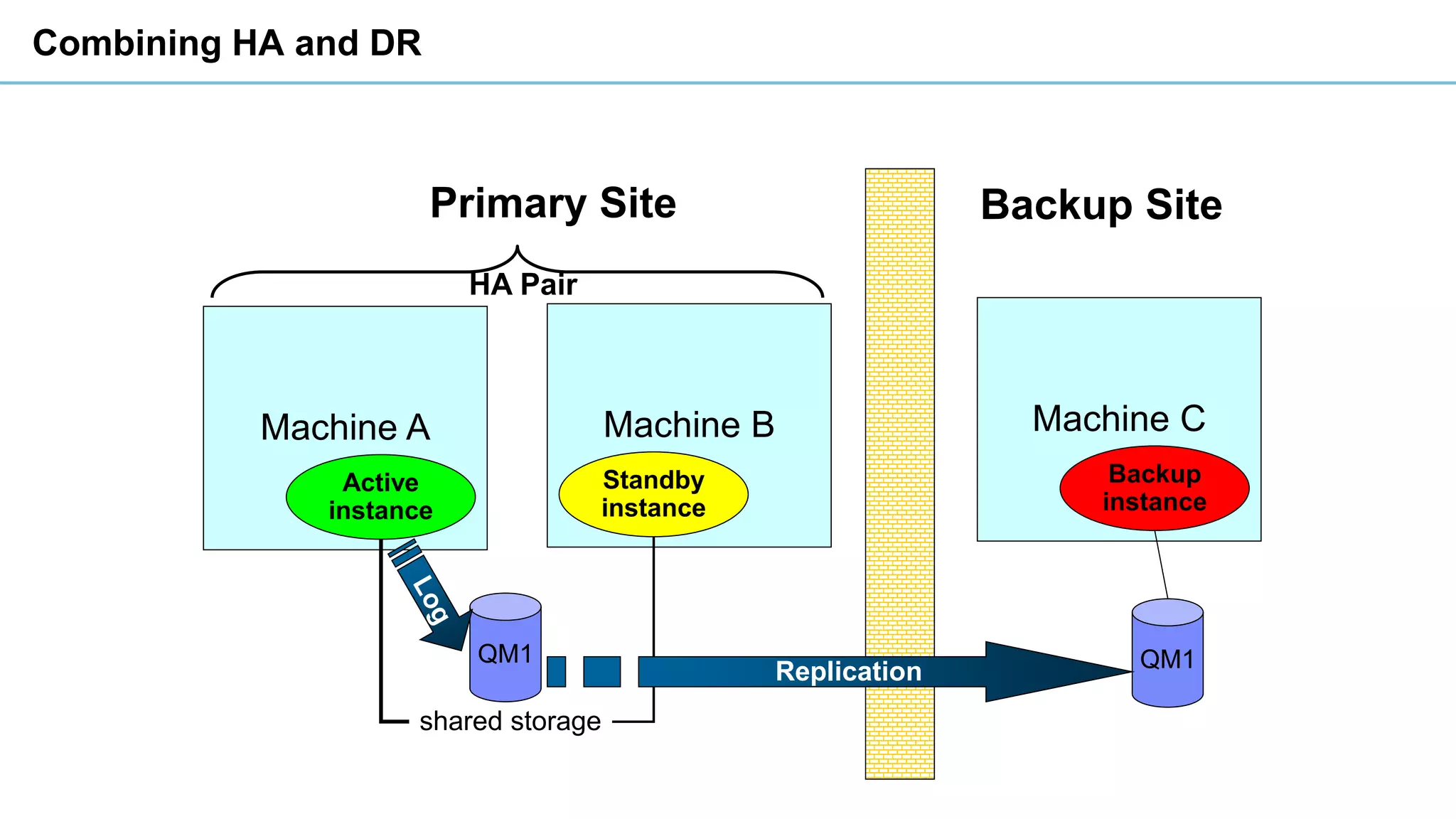
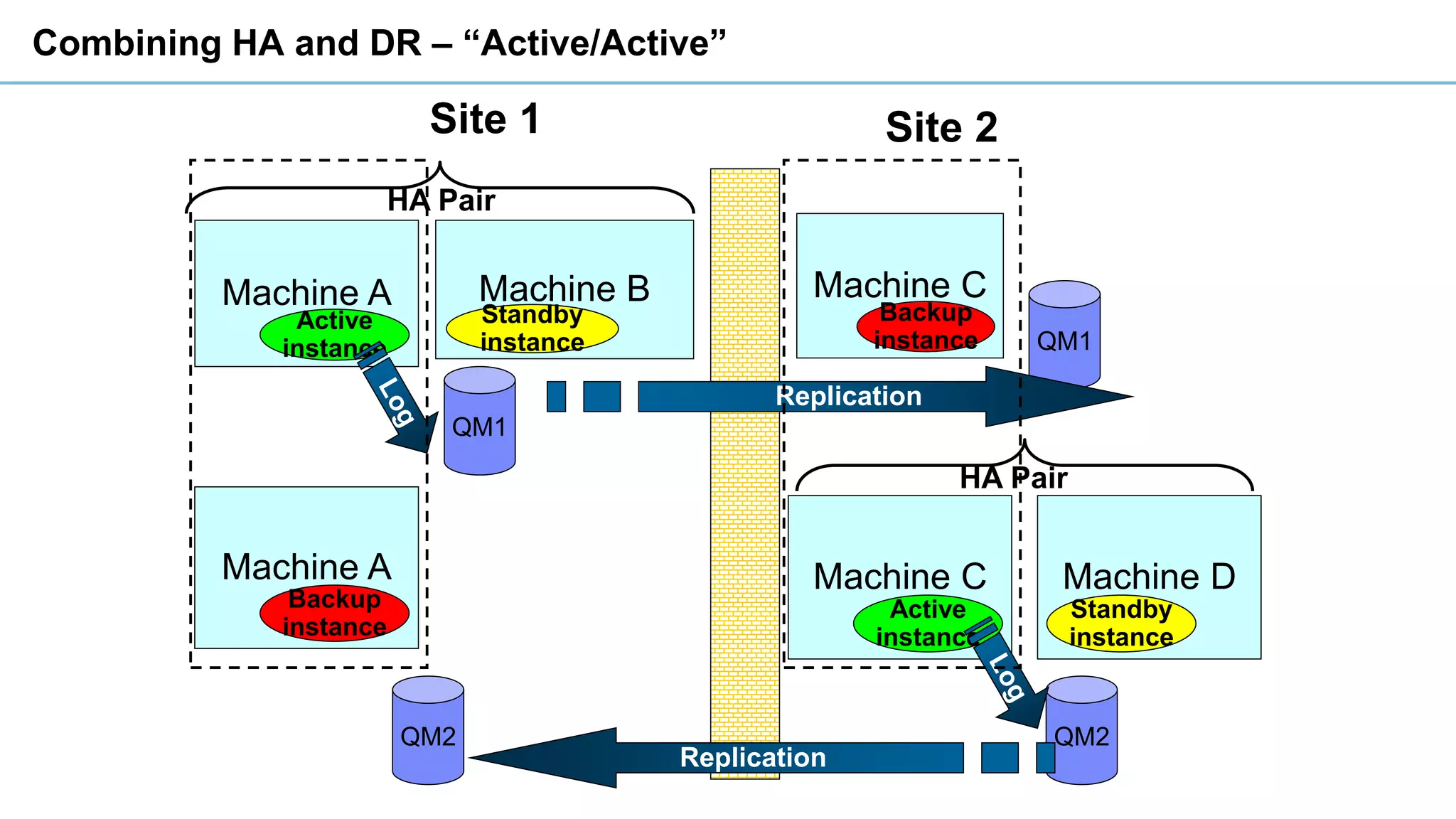


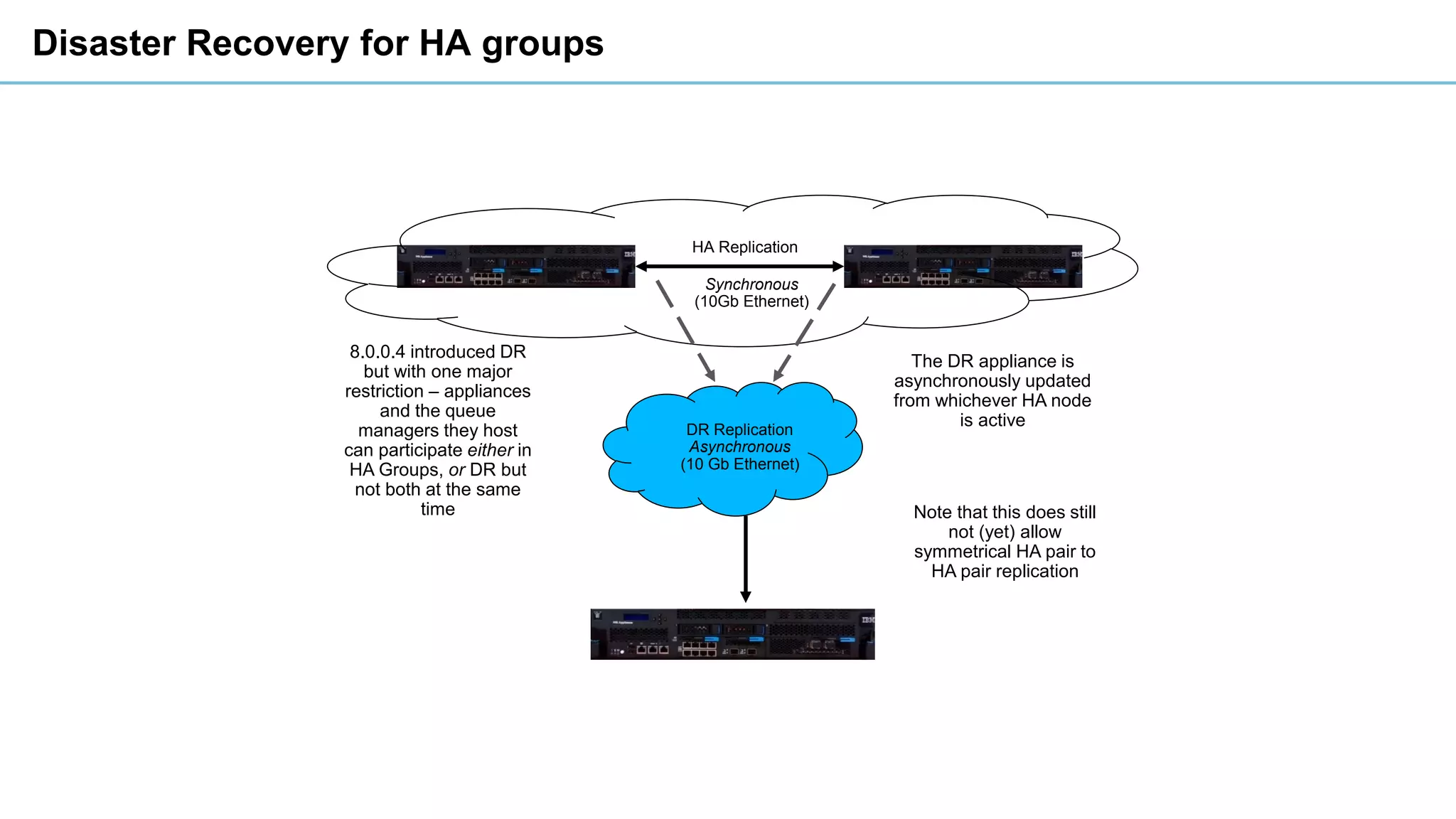













This document discusses high availability and disaster recovery strategies for IBM MQ. It describes technologies like queue manager clusters, multi-instance queue managers, and HA clusters that can be used to provide high availability when failures occur across datacenters and clouds. Multi-instance queue managers provide basic failover of a queue manager between two systems without an HA cluster. HA clusters coordinate failover of resources like the queue manager, shared storage, and IP address across multiple machines for increased reliability. The IBM MQ Appliance also supports high availability between two appliances.













































































