Downloaded 398 times
![Unit 1
1.1 Overview of Database Management System:
Data - Data is meaningful known raw facts that can be processed and stored as
information.
Database - Database is a collection of interrelated and organized data.
In general, it is a collection of files (tables).
Entity: A person, place, thing or event about which information must be kept.
Attribute: Piece of information describing a particular entity. These are mainly the
characteristics about the individual entity. Individual attributes help to identify and
distinguish one entity from another.
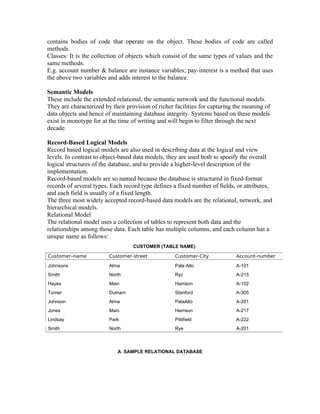
STUDENT (DATABASE NAME)
Entity Attributes
Personnel Name, Age, Address, Father’s Name
Academic Name, Roll No., Course, Dept. Name
E.g.
Student (Database Name)
Field name or attribute name
Personnel (Table Name) Academic (table name)
ROLL COURSE Dept. Name
Name Father Name Age Name
NO
John Albert 24 RECORD John 12 MSC Computer
Ramesh Suresh 18 Ramesh 15 BCA Computer
DBMS - Database Management System (DBMS) is a collection of interrelated data
[usually called database] and a set of programs to access, update and manage those data
[which form part of management system]
OR
It is a software package to facilitate creation and maintenance of computerized database.](https://image.slidesharecdn.com/23246406-dbms-unit-1-110307225733-phpapp02/85/23246406-dbms-unit-1-1-320.jpg)


![Enforces design criteria in relation to data
format and structure
1.2.2 Applications of DBMS:
1. Banking – For customer information, accounts, and loans, and banking transactions.
[all transactions]
2. Airlines – For reservation and schedule information. [reservations, schedules]
3. Universities – For student information, course registrations, and grades. [registration,
grades]
4. Credit Card Transactions – For purchases on credit card and generation of monthly
statements.
5. Telecommunication – For keeping records of calls made, generating monthly bills,
maintaining balances on prepaid calling cards, and storing information about
communication networks.
6. Finance – For storing information about holdings, sales, and purchases of financial
instruments such as stocks and bonds.
7. Sales – For customer, product, and purchase information. [customers, products,
purchases]
8. Manufacturing – For management of supply chain and for tracking production of
items in factories, inventories of items in warehouses/stores, and orders for items.
[production, inventory, orders, supply chain]
9. Human Resources – For information about employees, salaries, payroll taxes and
benefits, and generation of paychecks. [employee records, salaries, tax deductions]
1.3 Various views of Data
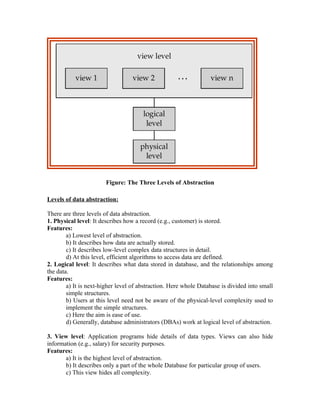
1.3.1 Data abstraction:
It can be summed up as follows.
1. When the DBMS hides certain details of how data is stored and maintained, it provides
what is called as the abstract view of data.
2. This is to simplify user-interaction with the system.
3. Complexity (of data and data structure) is hidden from users through several levels of
abstraction.
Data abstraction is used for following purposes:
1. To provide abstract view of data.
2. To hide complexity from user.
3. To simplify user interaction with DBMS.](https://image.slidesharecdn.com/23246406-dbms-unit-1-110307225733-phpapp02/85/23246406-dbms-unit-1-4-320.jpg)





















This document provides an overview of database management systems (DBMS). It defines key concepts like data, database, entity, attribute, and examples of DBMS like Oracle. It describes the goals and advantages of DBMS, including data independence, efficient data access, data integrity and security. Applications of DBMS discussed include banking, airlines, universities, and more. Finally, it introduces different views of data in a DBMS and various data models used to describe database structure, like the entity-relationship model.