웹서비스 성능 향상을위한
오픈소스 Arcus 주요기능 및 활용사례
박준현 (junhyun.park@navercorp.com)
시스템스컴퓨팅G / NAVER LABS
2014-06-27
2.
2
NAVER에서 개발한Memory Cache Cloud
Memcached 기반의 extended key-value 모델 (collection 지원)
ZooKeeper 기반의 elastic cache cloud 구현
NAVER 서비스들의 여러 요구 사항들 반영
Open Source SW – Apache License 2.0
ARCUS [ɑ́ :rkəs] : 아커스
아치형 구름
http://en.wikipedia.org/wiki/Arcus_cloud
ARCUS
3.
3
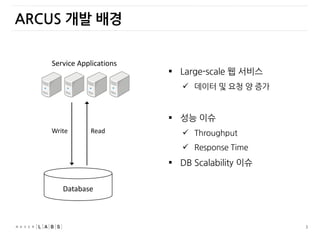
ARCUS 개발 배경
ServiceApplications
Write
Database
Read
Large-scale 웹 서비스
데이터 및 요청 양 증가
성능 이슈
Throughput
Response Time
DB Scalability 이슈
4.
4
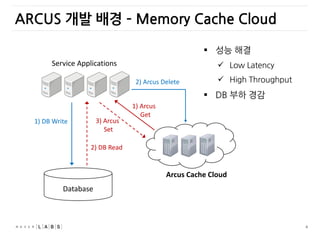
ARCUS 개발 배경– Memory Cache Cloud
Service Applications
1) DB Write
Database
Arcus Cache Cloud
2) DB Read
1) Arcus
Get
3) Arcus
Set
2) Arcus Delete
성능 해결
Low Latency
High Throughput
DB 부하 경감
8
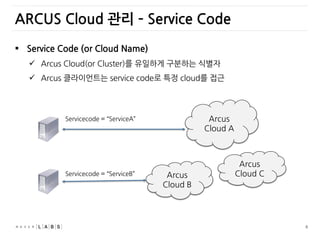
Service Code(or Cloud Name)
Arcus Cloud(or Cluster)를 유일하게 구분하는 식별자
Arcus 클라이언트는 service code로 특정 cloud를 접근
ARCUS Cloud 관리 – Service Code
Arcus
Cloud A
Arcus
Cloud B
Arcus
Cloud C
Servicecode = “ServiceA”
Servicecode = “ServiceB”
9.
9
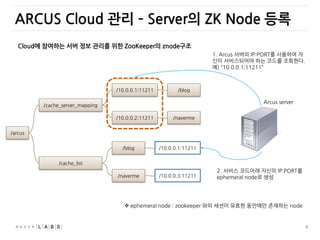
ARCUS Cloud 관리– Server의 ZK Node 등록
/cache_server_mapping
/cache_list
/arcus
/10.0.0.1:11211
/10.0.0.2:11211
/blog
/naverme
/blog
/naverme
/10.0.0.1:11211
/10.0.0.3:11211
1. Arcus 서버의 IP:PORT를 사용하여 자
싞이 서비스되어야 하는 코드를 조회한다.
예) “10.0.0.1:11211”
2. 서비스 코드아래 자싞의 IP:PORT를
ephemeral node로 생성
Arcus server
Cloud에 참여하는 서버 정보 관리를 위한 ZooKeeper의 znode구조
ephemeral node : zookeeper 와의 세션이 유효한 동안에만 존재하는 node
10.
10
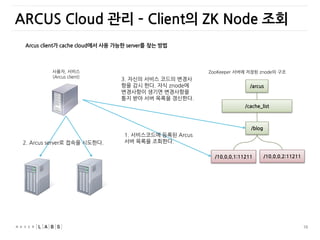
ARCUS Cloud 관리– Client의 ZK Node 조회
/cache_list
/arcus
/blog
/10.0.0.1:11211
ZooKeeper 서버에 저장된 znode의 구조
3. 자싞의 서비스 코드의 변경사
항을 감시 한다. 자식 znode에
변경사항이 생기면 변경사항을
통지 받아 서버 목록을 갱싞한다.
2. Arcus server로 접속을 시도한다.
1. 서비스코드에 등록된 Arcus
서버 목록을 조회한다.
/10.0.0.2:11211
Arcus client가 cache cloud에서 사용 가능한 server를 찾는 방법
사용자, 서비스
(Arcus client)
11.
11
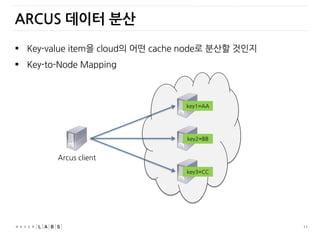
ARCUS 데이터 분산
Key-value item을 cloud의 어떤 cache node로 분산할 것인지
Key-to-Node Mapping
Arcus client
key1=AA
key2=BB
key3=CC
12.
12
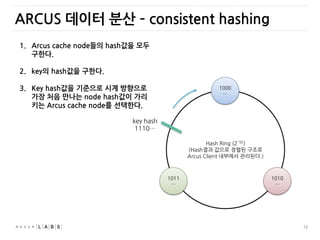
ARCUS 데이터 분산– consistent hashing
Hash Ring (2^32)
(Hash결과 값으로 정렬된 구조로
Arcus Client 내부에서 관리된다.)
1000
…
1010
…
1011
…
key hash
1110…
1. Arcus cache node들의 hash값을 모두
구한다.
2. key의 hash값을 구한다.
3. Key hash값을 기준으로 시계 방향으로
가장 처음 만나는 node hash값이 가리
키는 Arcus cache node를 선택한다.
13.
13
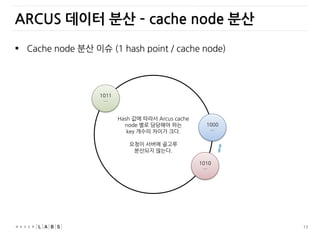
ARCUS 데이터 분산– cache node 분산
Hash 값에 따라서 Arcus cache
node 별로 담당해야 하는
key 개수의 차이가 크다.
요청이 서버에 골고루
분산되지 않는다.
1000
…
1010
…
1011
…
Cache node 분산 이슈 (1 hash point / cache node)
14.
14
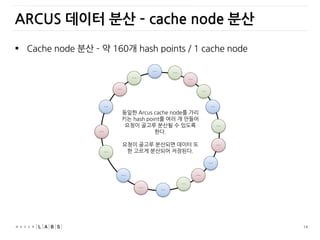
ARCUS 데이터 분산– cache node 분산
Cache node 분산 – 약 160개 hash points / 1 cache node
동일한 Arcus cache node를 가리
키는 hash point를 여러 개 만들어
요청이 골고루 분산될 수 있도록
한다.
요청이 골고루 분산되면 데이터 또
한 고르게 분산되어 저장된다.
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
15.
15
Key –key-value item 식별자
Format: <prefix>:<subkey> (max 250 characters)
<prefix> 단위로 key들을 그룹화하여 관리 (ex, delete, stats)
<subkey>로 prefix 내의 특정 item을 식별
Value – key-value item에서 value 부분
Single value (max 1MB)
A collection of values : List, Set, B+Tree
max 50000 elements
max 4KB value in each element
ARCUS Key-Value 모델
16.
16
ARCUS Collections
유형 구조및 특징
List Double linked list 구조
Set An unordered set of unique data
Membership checking (예, 친구 정보, 구독 정보, …)
B+Tree An ordered data set based on b+tree key
Element 구조: < bkey, [eflag,] value >
bkey(b+tree key): 8 bytes integer or 1~31 bytes array
eflag(element flag): 1~31 bytes array
주요 연산
Bkey 기반 range scan & eflag filter & offset, count
여러 b+tree들에 대한 smget(sort-merge get)
B+tree position 조회 / position 기반 element 조회
17.
17
대표 성능이슈 – 친구 글 또는 구독 글 모아보기
IN 리스트 커질수록, 질의 응답이 급격히 느림.
SNS 사용자 증가 및 활성화 => DB 성능 튜닝만으롞 해결이 어려움
관계(relationship) 증가
데이터 규모와 조회 요청 량 증가
ARCUS Collection - SNS
SELECT *
FROM posts
WHERE user IN (friend-1, friend-2, … friend-N)
AND create_time < sysdate()
ORDER BY create_time DESC
LIMIT 20;
18.
18
Arcus B+Tree- <bkey: create_time, value: postid>
ARCUS Collection - SNS
Push 방식 Pull 방식
Cache • 사용자 별 inbox cache 유지 • 사용자 별 outbox cache 유지
Post
작성
• 모든 친구의 inbox cache에
post 정보를 push delivery
• 친구 수만큼 write 발생
• 작성자의 outbox cache에만
post 정보를 보관
• 1회 write 발생
Post
모아보기
• 자싞의 inbox cache만 조회
• B+tree get 연산 사용
• 모든 친구의 outbox cache를
조회하여 sort-merge 수행
• B+tree smget 연산 사용
19.
19
B+tree smget(sort-mergeget) 연산
ARCUS Collection - SNS
0 7 14 21 28
A
1 5 10 15 20
B
3 6 9 12 16
C
A, B, C로 부터 bkey가 30 ~ 10인 element 조회
[ 28, 21, 20, 16, 15, 14, 12, 10 ]
10 1214 15 1620
20.
20
대표 조회요청
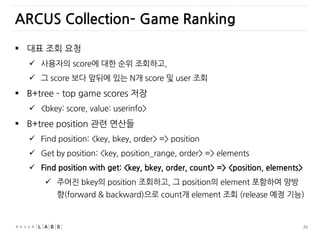
사용자의 score에 대한 순위 조회하고,
그 score 보다 앞뒤에 있는 N개 score 및 user 조회
B+tree – top game scores 저장
<bkey: score, value: userinfo>
B+tree position 관련 연산들
Find position: <key, bkey, order> => position
Get by position: <key, position_range, order> => elements
Find position with get: <key, bkey, order, count> => <position, elements>
주어진 bkey의 position 조회하고, 그 position의 element 포함하여 양방
향(forward & backward)으로 count개 element 조회 (release 예정 기능)
ARCUS Collection– Game Ranking
23
ARCUS – EagerItem Expiration
기존 Item Expiration
Search 범위
각 LRU 리스트의 tail에 위치한 N개 items만 검사
이슈
LRU 상위에 expired items이 존재하더라도 reclaim 되지 않고, LRU tail에
있는 valid item이 먼저 evict 됨.
Valid items의 memory 사용량 확인이 어려움
Eager Item Expiration
Search 범위
각 LRU 리스트의 tail에 위치한 N개 items 검사 외에도
LRU 리스트를 점진적 traverse하면서 N개 items 검사
효과 - Memory 효율성 증가
24.
24
Dynamic configuration변경
memlimit, maxconns, …
다양한 Item attributes 제공
Item attributes 조회 및 변경
Delete by prefix
Command pipelining for bulk operations
Sticky Items
stats 정보 확장
…
ARCUS – 그 외 특징들
25.
25
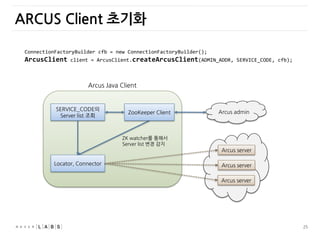
ARCUS Client 초기화
SERVICE_CODE의
Serverlist 조회
Arcus Java Client
Arcus admin
ZK watcher를 통해서
Server list 변경 감지
Arcus server
Arcus server
Arcus server
Locator, Connector
ZooKeeper Client
ConnectionFactoryBuilder cfb = new ConnectionFactoryBuilder();
ArcusClient client = ArcusClient.createArcusClient(ADMIN_ADDR, SERVICE_CODE, cfb);
26.
26
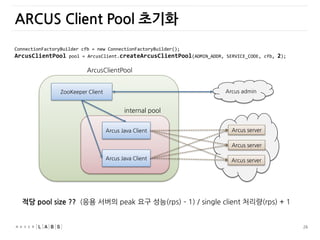
ARCUS Client Pool초기화
ArcusClientPool
Arcus admin
Arcus server
Arcus server
Arcus server
Arcus Java Client
ZooKeeper Client
Arcus Java Client
internal pool
ConnectionFactoryBuilder cfb = new ConnectionFactoryBuilder();
ArcusClientPool pool = ArcusClient.createArcusClientPool(ADMIN_ADDR, SERVICE_CODE, cfb, 2);
적당 pool size ?? (응용 서버의 peak 요구 성능(rps) – 1) / single client 처리량(rps) + 1
27.
27
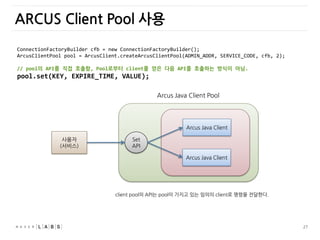
ARCUS Client Pool사용
Arcus Java Client Pool
Arcus Java Client
Arcus Java Client
ConnectionFactoryBuilder cfb = new ConnectionFactoryBuilder();
ArcusClientPool pool = ArcusClient.createArcusClientPool(ADMIN_ADDR, SERVICE_CODE, cfb, 2);
// pool의 API를 직접 호출함, Pool로부터 client를 얻은 다음 API를 호출하는 방식이 아님.
pool.set(KEY, EXPIRE_TIME, VALUE);
사용자
(서비스)
Set
API
client pool의 API는 pool이 가지고 있는 임의의 client로 명령을 젂달한다.
28.
28
Arcus Client 설정
Connection Factory Builder 설정들
Transcoder, Key-Value 압축, Key-Value Local Cache (ehcache) 사용, …
Key-Value Local Cache 사용 설정
ConnectionFactoryBuilder cfb = new ConnectionFactoryBuilder();
// local cache의 expire time을 1초로 지정
cfb.setFrontCacheExpireTime(1000L);
// local cache에 저장 가능한 key의 개수를 1만개로 지정
cfb.setMaxFrontCacheElements(10000);
// 이제 client를 사용해서 저장/조회되는 key/value는 local cache를 거치게 된다.
ArcusClient client = ArcusClient.createArcusClient(ADMIN_ADDR, SERVICE_CODE, cfb);
// Key/Value local cache는 Arcus client / Arcus client pool별로 생성된다.
29.
29
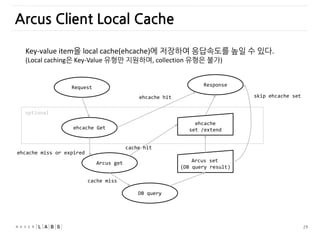
Arcus Client LocalCache
Request
Arcus get
DB query
Arcus set
(DB query result)
Response
cache hit
cache miss
ehcache Get
ehcache miss or expired
ehcache
set /extend
ehcache hit
optional
skip ehcache set
Key-value item을 local cache(ehcache)에 저장하여 응답속도를 높일 수 있다.
(Local caching은 Key-Value 유형만 지원하며, collection 유형은 불가)
30.
30
Arcus Open– 2014/05/15
http://naver.github.io/arcus/ (Apache License 2.0)
Linux : CentOS 6.x 64bit, Ubuntu 12.04 LTS 64bit
Arcus Code Repositories
arcus : arcus super project including setup tools
arcus-memcached : arcus memory cache server
arcus-java-client : arcus java client
arcus-c-client : arcus c client
arcus-zookeeper : zookeeper with arcus modifications
arcus-hubble : dashboard service to monitor arcus clusters
…
ARCUS Open Source
33
문의/질문 -openarcus 구글 그룹스
https://groups.google.com/d/forum/openarcus
openarcus@googlegroups.com
공지 – openarcus 구글 그룹스 (회원가입 필요)
버그/이슈
개별 code repository issues에 등록
Contribution
Github pull request 방식 선호
아주 갂단하면, patch 젂달 방식도 가능
ARCUS Open Source - Communication
34.
34
Replication
2Copy & Semi-Synchronous
Others
지원하는 Linux 플랫폼 확장
지원하는 Client 언어 확장
Slow Request Logging => 응용 Request 검증에 활용
Prefix 기능 확장
Arcus Monitoring 기능 확장
…
ARCUS Open Source – Future Dev



![2
NAVER에서 개발한 Memory Cache Cloud
Memcached 기반의 extended key-value 모델 (collection 지원)
ZooKeeper 기반의 elastic cache cloud 구현
NAVER 서비스들의 여러 요구 사항들 반영
Open Source SW – Apache License 2.0
ARCUS [ɑ́ :rkəs] : 아커스
아치형 구름
http://en.wikipedia.org/wiki/Arcus_cloud
ARCUS](https://image.slidesharecdn.com/3-140627050358-phpapp01/85/Arcus-2-320.jpg)



![16
ARCUS Collections
유형 구조 및 특징
List Double linked list 구조
Set An unordered set of unique data
Membership checking (예, 친구 정보, 구독 정보, …)
B+Tree An ordered data set based on b+tree key
Element 구조: < bkey, [eflag,] value >
bkey(b+tree key): 8 bytes integer or 1~31 bytes array
eflag(element flag): 1~31 bytes array
주요 연산
Bkey 기반 range scan & eflag filter & offset, count
여러 b+tree들에 대한 smget(sort-merge get)
B+tree position 조회 / position 기반 element 조회](https://image.slidesharecdn.com/3-140627050358-phpapp01/85/Arcus-16-320.jpg)


![19
B+tree smget(sort-merge get) 연산
ARCUS Collection - SNS
0 7 14 21 28
A
1 5 10 15 20
B
3 6 9 12 16
C
A, B, C로 부터 bkey가 30 ~ 10인 element 조회
[ 28, 21, 20, 16, 15, 14, 12, 10 ]
10 1214 15 1620](https://image.slidesharecdn.com/3-140627050358-phpapp01/85/Arcus-19-320.jpg)
![21
ARCUS Collection– Game Ranking
B+tree find position with get 연산
69 70 10 15 20
B
B에서 bkey 78에 대해 descending 순서의 position과 양방향 3개씩 element 조회
[ 6, < 89, 84, 83, 78, 76, 70, 69 > ]
76 78 83 84 89 10 15 2090 93 9560 61 10 15 2062 63 68bkey:
position:
(desc)
14 13 12 11 10 9 8 7 6 5 4 3 2 1 0](https://image.slidesharecdn.com/3-140627050358-phpapp01/85/Arcus-21-320.jpg)









![[Hello world 오픈세미나]n grinder helloworld발표자료_저작권free](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldngrinderhelloworldfree-130717011906-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Hello world 오픈세미나]vertx&socket io](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldvertxsocketio-130717011923-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Hello world 오픈세미나]varnish로 웹서버성능 향상시키기](https://cdn.slidesharecdn.com/ss_thumbnails/helloworldvarnish-130717011909-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













![[2B5]nBase-ARC Redis Cluster](https://cdn.slidesharecdn.com/ss_thumbnails/2b5nbase-arcrediscluster-140930003743-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)


![[261] 실시간 추천엔진 머신한대에 구겨넣기](https://cdn.slidesharecdn.com/ss_thumbnails/216-150915054828-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[124]네이버에서 사용되는 여러가지 Data Platform, 그리고 MongoDB](https://cdn.slidesharecdn.com/ss_thumbnails/124mongodb-181011042943-thumbnail.jpg?width=640&height=640&fit=bounds)


![NDC 2016, [슈판워] 맨땅에서 데이터 분석 시스템 만들어나가기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=640&height=640&fit=bounds)


![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)


![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)