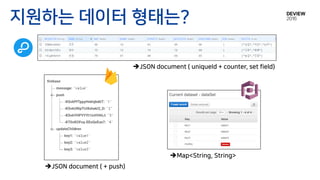
시작은 Mobile DB
LevelDB,
Couchbase,
CloudantSync-android,
JasDB,
RocksDB,
LMDB,
OrientDB,
MapDB,
TSDocDB,
waspdb,
BananaDB,
SynchronizedDB
…
“이미 잘나가고 있는 제품을
쫓아갈 필요가 있을까?”
차별화가 필요해!
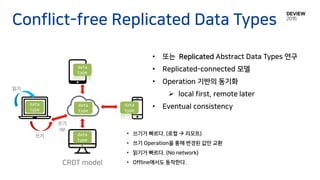
Conflict-free Replicated DataTypes
CRDT model
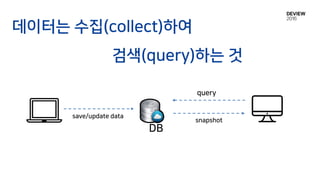
읽기
쓰기
쓰기
op
• 쓰기가 빠르다. (로컬 리모트)
• 쓰기 Operation을 통해 변경된 값만 교환
• 읽기가 빠르다. (No network)
• Offline에서도 동작한다.
• 또는 Replicated Abstract Data Types 연구
• Replicated-connected 모델
• Operation 기반의 동기화
local first, remote later
• Eventual consistencydata
type
data
type
data
type
data
type
data
type
• 유한한 element들의array
• Element에 대한 iteration 지원
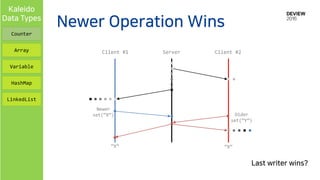
• Newer Operation Wins on each element
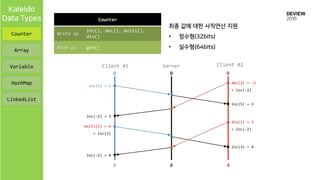
Counter
Array
Variable
HashMap
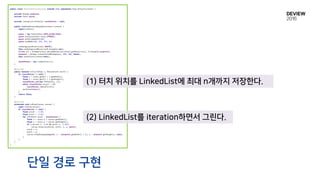
LinkedList
Array<E>
Write op set(int i, E e)
Read op get(int i)
HashMap<K,V>
Write op put(K k, V v), remove(K k)
Read op get(K k)
• Key에 대해 Value를 mapping
• Key, value set에 대한 iteration 지원
• Newer Operation Wins on each key
Variable<V>
Write op set(V v)
Read op get()
• 하나의 value를 저장
• Newer Operation Wins
• V, E : boolean, integer, long, double, String, byte[], Date, JSON
• K: boolean, integer, long, double, String, byte[], Date, JSON
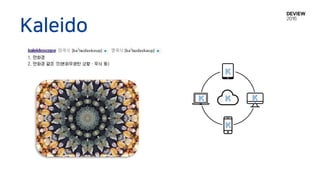
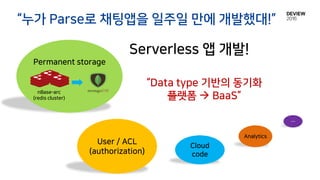
Kaleido
Data Types
• 2011. 06출시
• 2013. 04 Facebook 인수
• 2016. 01 parse.com 종료 발표(`17. 01)
open-source 전환
Amazon Cognito
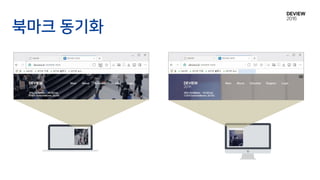
디바이스 간의 계정 정보 동기화
• 2014. 07 공개
출처: Google I/O 2016 https://www.youtube.com/watch?v=tb2GZ3Bh4p8
• 2016. 05 renewal @ google I/O
• 2011. 09 출시
• 2014. 10 Google 인수
비교 대상
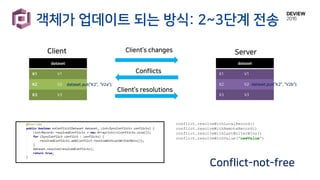
객체가 업데이트 되는방식: 단방향 전송
character
uniqueId S50WnnG6k
name 조조
war 96
power 72
intelli 91
politics 94
charisma 96
exp 1
skills
[“상업”, “치안“,
“논파”]
character.put(“power”, 82);
character.inc(“exp”);
character
uniqueId S50WnnG6k
name 조조
war 96
power 72
intelli 91
politics 94
charisma 96
exp 1
skills
[“상업”, “치안“,
“논파”]
character.put(“war”, 62);
character.inc(“exp”);
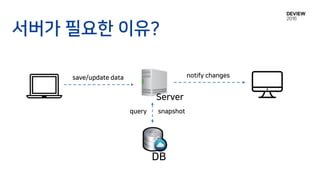
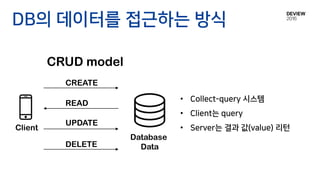
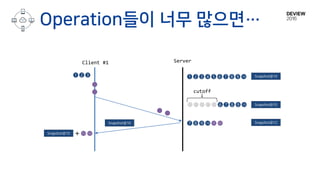
Client Server
변경 사항만 전송 or 전체 값 전송?
동기화를 위한 세가지선택 사항?
Stateless
or
Stateful objects
Unidirectional snapshot
or
Bidirectional changes
Conflict-not-free
or
Conflict-free
52.
• Attach: 데이터타입의생성 및 Push-Pull 을 등록
• Push-Pull: client / server 간에 operation들을
교환
• Detach: 데이터타입을 Push-Pull을 해제
Connect replicated objects
APPD model
Kaleido
Data Type
Client
ATTACH
DETACH
PUSH-PULL
53.
COUNTER
VARIABLE
ARRAY
HASH MAP
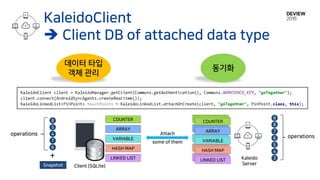
LINKED LISTKaleido
Server
COUNTER
VARIABLE
ARRAY
HASH MAP
LINKED LIST
COUNTER
VARIABLE
ARRAY
HASH MAP
LINKED LIST
COUNTER
VARIABLE
ARRAY
HASH MAP
LINKED LIST
Client (SQLite)
Attach
some of them
3
4
5
6
7
8
9
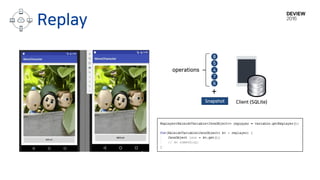
Snapshot
4
5
6
7
8
operations
+
operations
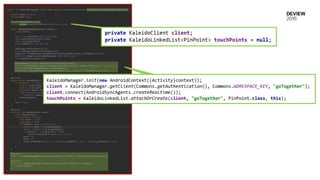
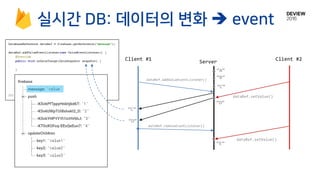
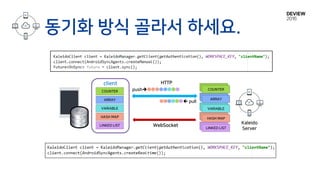
KaleidoClient
Client DB of attached data type
데이터 타입
객체 관리
동기화
54.
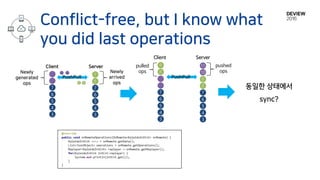
Conflict-free, but Iknow what
you did last operations
3
4
5
6
7
8
9
3
4
5
6
7
pulled
ops
pushed
ops8
9
10
11
Client Server
3
4
5
6
7
8
9
3
4
5
6
7
Client Server
Newly
generated
ops
Newly
arrived
ops
PushPull
8 9
PushPull
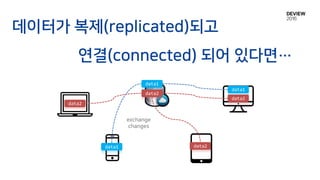
동일한 상태에서
sync?

















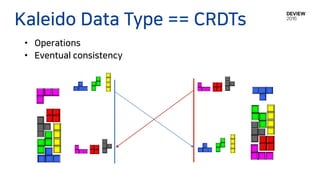
![• 유한한 element들의 array
• Element에 대한 iteration 지원
• Newer Operation Wins on each element
Counter
Array
Variable
HashMap
LinkedList
Array<E>
Write op set(int i, E e)
Read op get(int i)
HashMap<K,V>
Write op put(K k, V v), remove(K k)
Read op get(K k)
• Key에 대해 Value를 mapping
• Key, value set에 대한 iteration 지원
• Newer Operation Wins on each key
Variable<V>
Write op set(V v)
Read op get()
• 하나의 value를 저장
• Newer Operation Wins
• V, E : boolean, integer, long, double, String, byte[], Date, JSON
• K: boolean, integer, long, double, String, byte[], Date, JSON
Kaleido
Data Types](https://image.slidesharecdn.com/243kaleido-161025011559/85/243-kaleido-38-320.jpg)
![• element들의 list로 순서를 정하여 삽입/제거
할 수 있는 데이터 타입
• position은 다양한 방법으로 제공(iterator,
integer index 등)
Client #1 Client #2Server
[1,2] [1,2]
ins(next to “1”, “X”)
[1, X, 2]
ins(next to “2”, “Y”)
[1, 2, Y]
del(“2”)
[1, X]
ins(next to “1”, “Z”)
[1, Z, 2, Y]
ins(next to “2”, “Y”)
[1, X, Y]
ins(next to “1”, “Z”)
[1, X, Z, Y]
ins(next to “1”, “X”)
[1, X, Z, 2, Y]
del(“2”)
[1, X, Z, Y]
LinkedList<E>
Write op
ins(Pos p, E e),
del(Pos p), set(Pos p, E e)
Read op get(Pos p)
Counter
Array
Variable
HashMap
LinkedList
Kaleido
Data Types](https://image.slidesharecdn.com/243kaleido-161025011559/85/243-kaleido-40-320.jpg)




![객체가 업데이트 되는 방식: 단방향 전송
character
uniqueId S50WnnG6k
name 조조
war 96
power 72
intelli 91
politics 94
charisma 96
exp 1
skills
[“상업”, “치안“,
“논파”]
character.put(“power”, 82);
character.inc(“exp”);
character
uniqueId S50WnnG6k
name 조조
war 96
power 72
intelli 91
politics 94
charisma 96
exp 1
skills
[“상업”, “치안“,
“논파”]
character.put(“war”, 62);
character.inc(“exp”);
Client Server
변경 사항만 전송 or 전체 값 전송?](https://image.slidesharecdn.com/243kaleido-161025011559/85/243-kaleido-48-320.jpg)

























![[오픈소스컨설팅]Java Performance Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/javaperformanetuning-150408192031-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Pgday.Seoul 2019] Citus를 이용한 분산 데이터베이스](https://cdn.slidesharecdn.com/ss_thumbnails/citus20191207studypgday-191218045308-thumbnail.jpg?width=640&height=640&fit=bounds)





![Egoless Programming [Mixit 2022]](https://cdn.slidesharecdn.com/ss_thumbnails/egolessmixit2022-220531062546-b9619493-thumbnail.jpg?width=640&height=640&fit=bounds)





![[135] 우리 팀에서도 코드리뷰를 할 수 있을까 안오균](https://cdn.slidesharecdn.com/ss_thumbnails/135-161023163934-thumbnail.jpg?width=640&height=640&fit=bounds)
![[145]5년간의네이버웹엔진개발삽질기그리고 김효](https://cdn.slidesharecdn.com/ss_thumbnails/1455-161023163929-thumbnail.jpg?width=640&height=640&fit=bounds)











![[221] docker orchestration](https://cdn.slidesharecdn.com/ss_thumbnails/212dockerorchestration-150915010646-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)








![[H3 2012] Cloud Database Service - Hulahoop를 소개합니다.](https://cdn.slidesharecdn.com/ss_thumbnails/c1-hulahoop-121105214317-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[110730/아꿈사발표자료] mongo db 완벽 가이드 : 7장 '고급기능'](https://cdn.slidesharecdn.com/ss_thumbnails/110730mongodb7-110729214130-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)