RDS(Relational Database Service)
•클라우드에서 관계형 데이터베이스를
더 쉽게 설치, 운영 및 확장할 수 있는 웹 서비스
• 산업 표준 관계형 데이터베이스를 위한
경제적이고 크기 조절이 가능한 용량을 제공하고
공통 데이터베이스 관리 작업을 관리함
• Aurora != RDS
6.
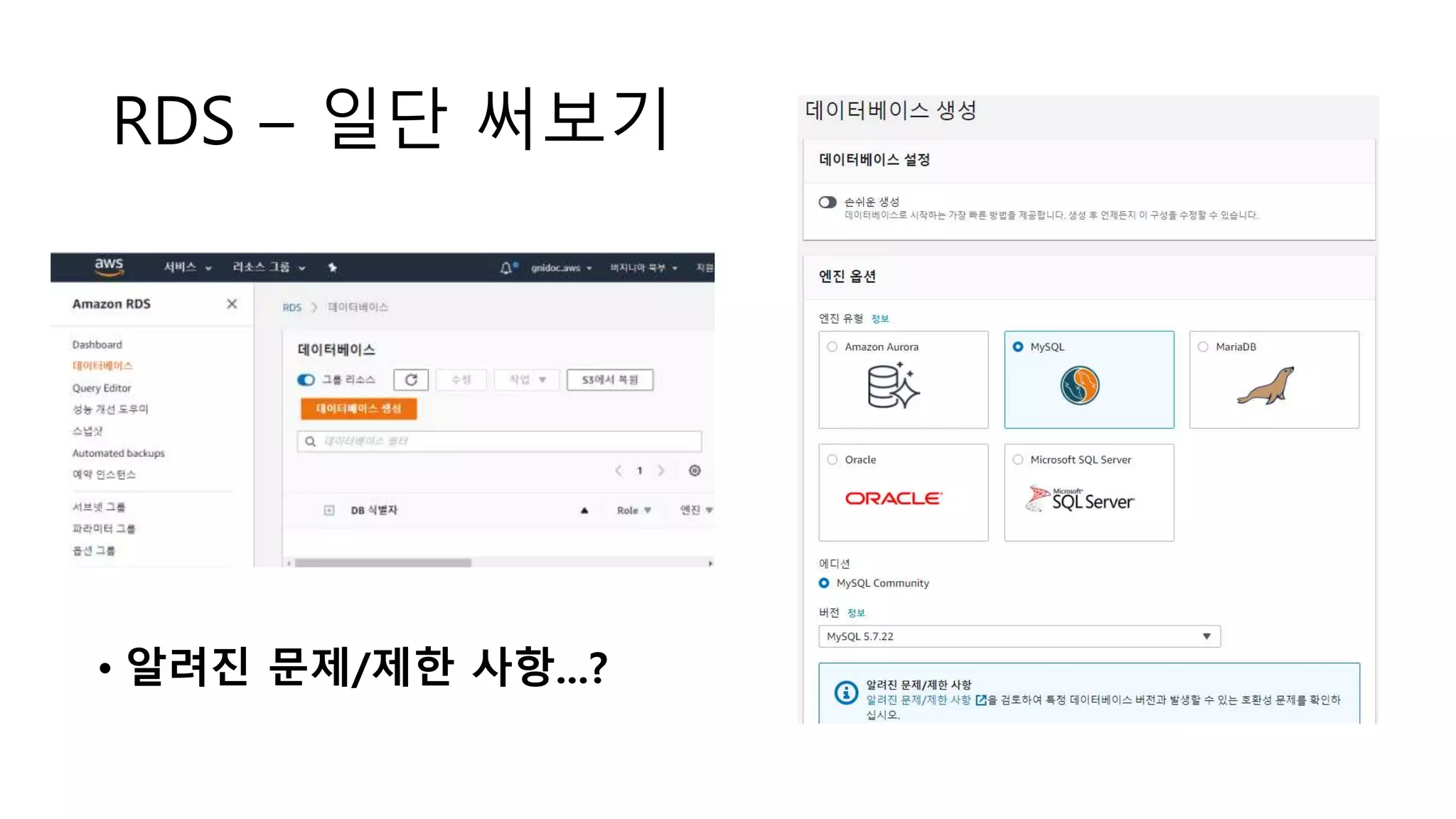
RDS – 지원하는DB엔진
• MySQL : 5.5~5.7, 8.0
• MariaDB : 10.0~10.3
• Oracle : Enterprise, Standard, Standard One/Two
• MS SQL Server : Express, Web, Standard, Enterprise
• Aurora : MySQL 5.6~5.7, PostqreSQL 9.6~10.7
7.
RDS vs EC2
•EC2에 Mysql 설치해서 쓰기 vs RDS에서 Mysql쓰기
• EC2
• CPU, 메모리, 스토리지, IOPS가 묶여서 제공(저비용)
• RDS
• 독립적으로 확장 가능(고비용)
• AWS서비스 확장 지원 – S3 Import, DMS....
• 완전 관리 – Auro Scaling, Multi AZ/Region 등등
RDS – 엔진/버전별로문제/제한 제공
• EX) MySQL 5.5 버그
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/MySQL.KnownIssuesAndLimitations.html
10.
RDS - Aurora
•MySQL 및 PostgreSQL과 호환되는
완전 관리형 관계형 데이터베이스 엔진
• 일부 워크로드의 경우,
MySQL의 처리량을 최대 5배,
PostgreSQL의 처리량을 최대 3배 제공
• 단, I/O 비용이 별도로 청구
11.
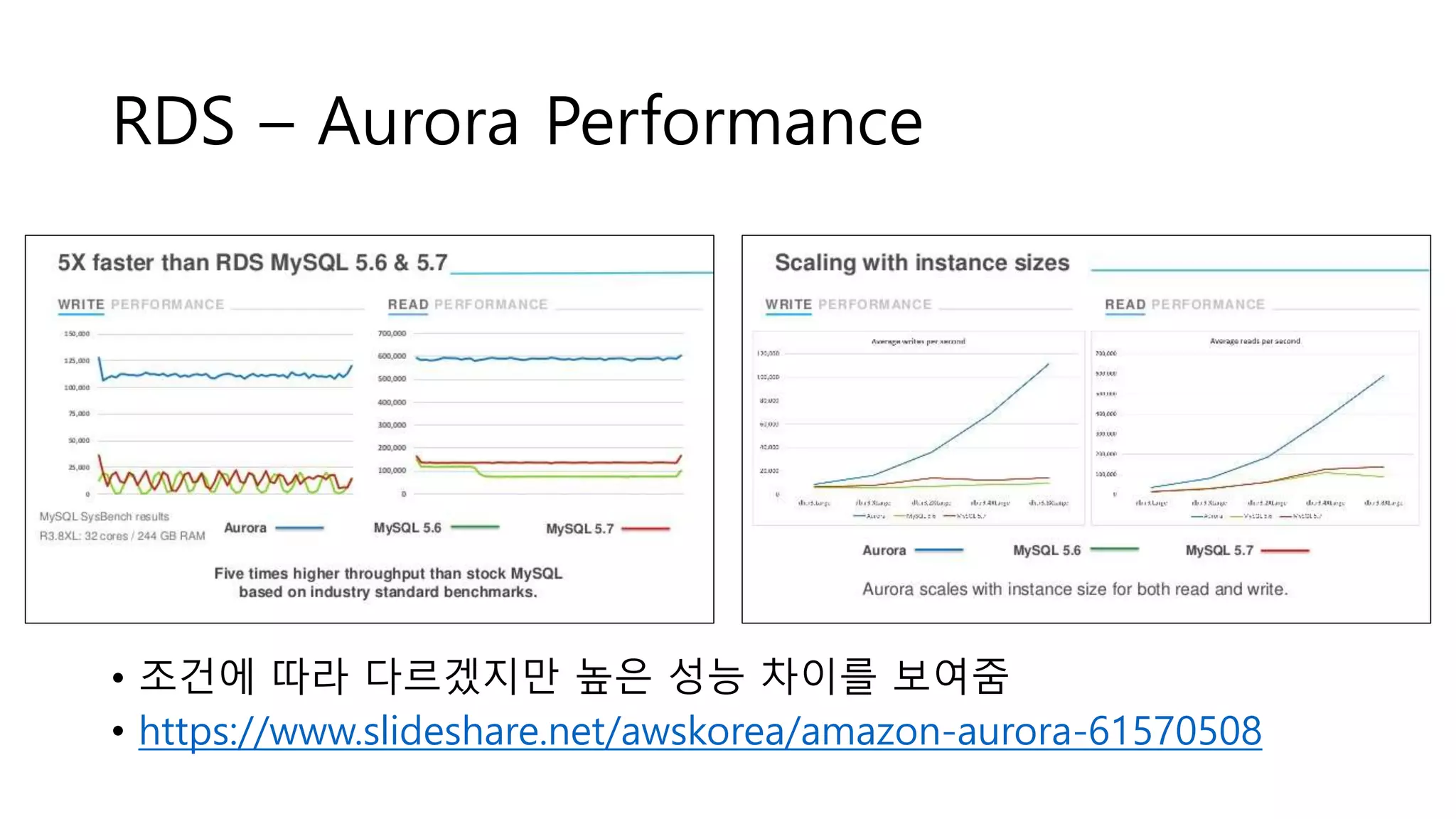
RDS – AuroraPerformance
• 조건에 따라 다르겠지만 높은 성능 차이를 보여줌
• https://www.slideshare.net/awskorea/amazon-aurora-61570508
12.
RDS – Aurora구조1
• Aurora 스토리지 엔진은
한 리전의 여러 AWS 가용 영역에 걸친 분산된 SAN 입니다.
• 스토리지 할당 = 최대 64TB(MySQL기준 테이블 1개)
13.
RDS – Aurora구조2
• 빠르게 쓸 수 있는 이유?
• 데이터를 쓰면 6개 스토리지 노드로 병렬 전송
• 중복 로그 레코드는 폐기
• 비동기식으로 S3에 백업
• https://aws.amazon.com/ko/blogs/korea/databaseintroducing-the-
aurora-storage-engine/
14.
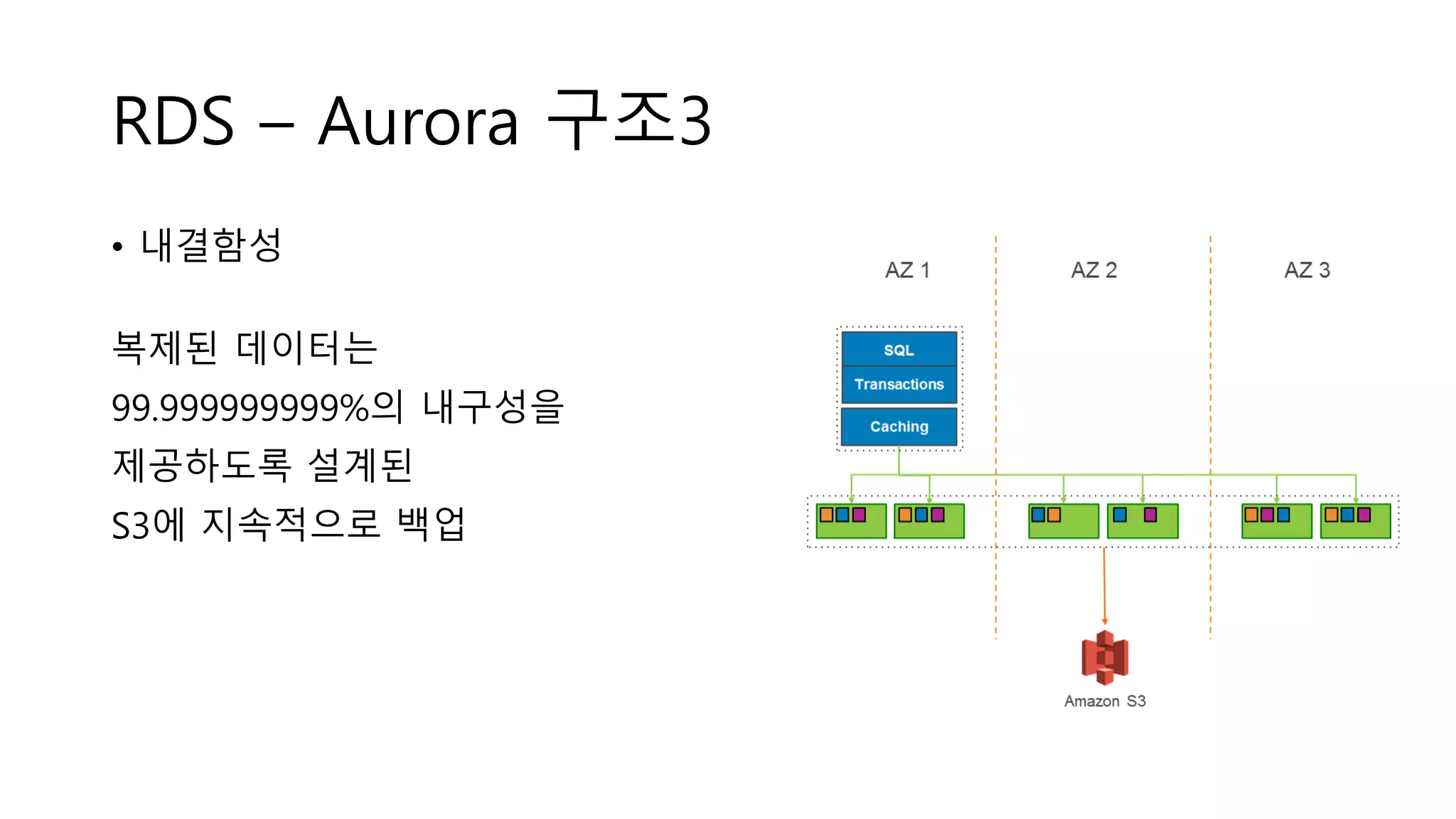
RDS – Aurora구조3
• 내결함성
복제된 데이터는
99.999999999%의 내구성을
제공하도록 설계된
S3에 지속적으로 백업
15.
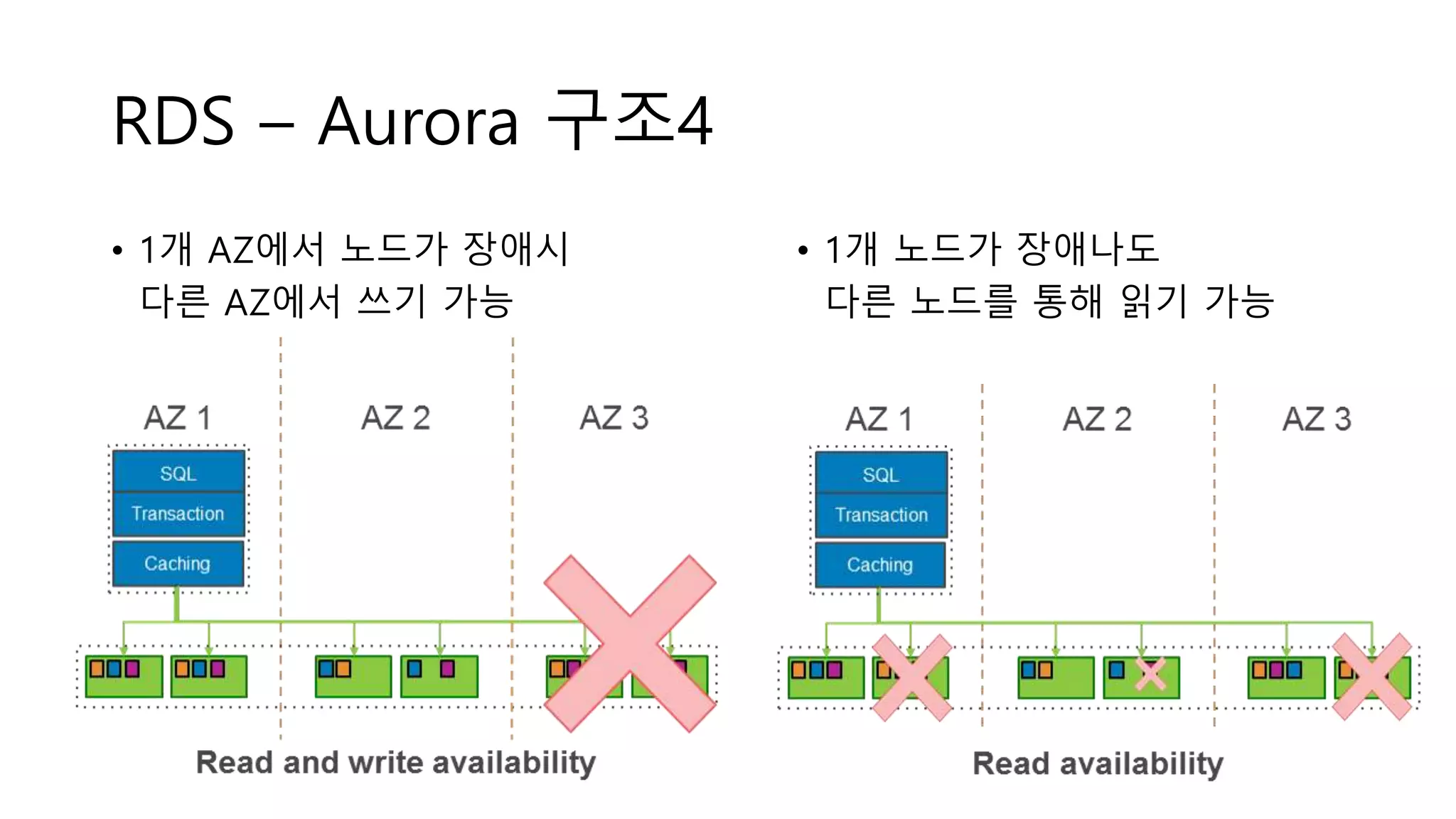
RDS – Aurora구조4
• 1개 AZ에서 노드가 장애시
다른 AZ에서 쓰기 가능
• 1개 노드가 장애나도
다른 노드를 통해 읽기 가능
16.
RDS - Aurora생성1
• Master user = 유사 Root
• 인터스턴스 클래스(타입)은 r4/5, t2/3 시리즈 지원
17.
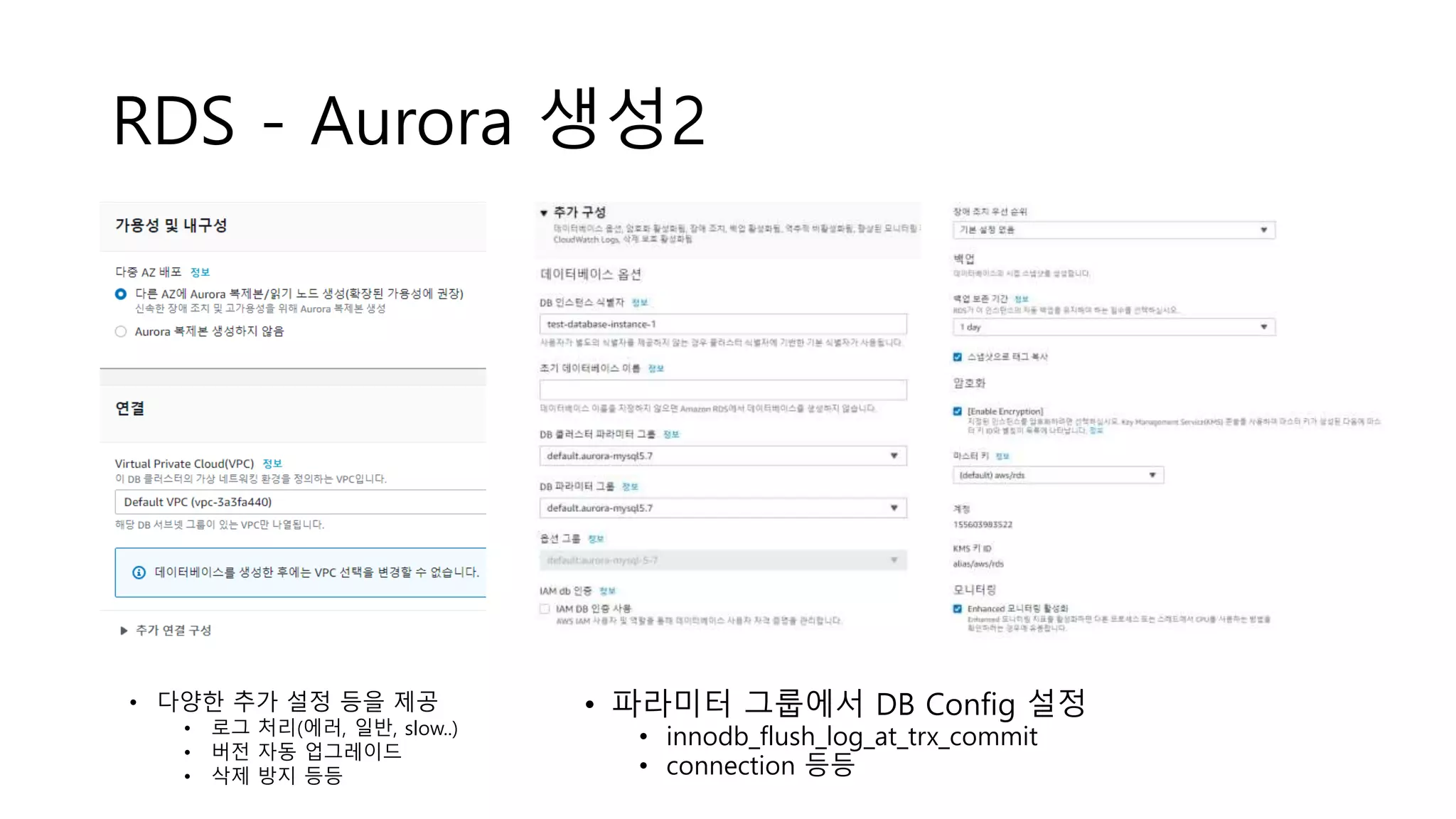
RDS - Aurora생성2
• 파라미터 그룹에서 DB Config 설정
• innodb_flush_log_at_trx_commit
• connection 등등
• 다양한 추가 설정 등을 제공
• 로그 처리(에러, 일반, slow..)
• 버전 자동 업그레이드
• 삭제 방지 등등
18.
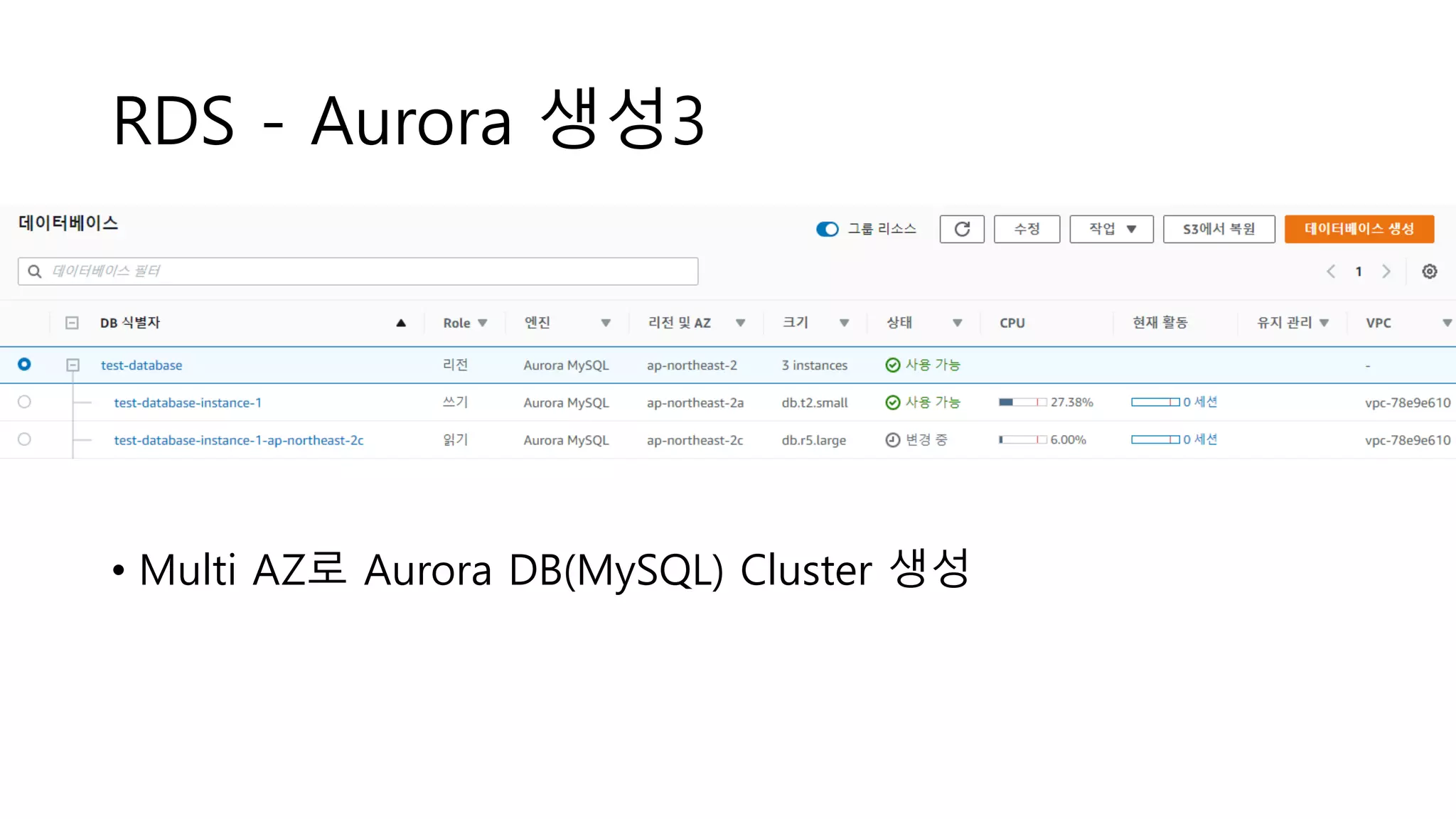
RDS - Aurora생성3
• Multi AZ로 Aurora DB(MySQL) Cluster 생성
19.
RDS - 역추적
•백업에서 데이터를 복구하지 않고 특정시간으로 이동
• Cluster 생성시 역추적 활성화 필수
• 제한
• 최대 72시간
• Cluster의 성능 영향
• 단일 테이블, 데이터만 선택적으로 추적X
• 역추적 작업 시작시 Instance가 일시 중단
• MySQL 5.6에서만 지원
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Managing.Backtrack.html
RDS – MultiAZ
• 쓰기 = northeast-2a
• 읽기 = northeast-2c
• 복제본에 대한 지연시간은 설정마다 달라짐(설정이 추가될수록 느려짐)
22.
RDS - 추가작업
•DMS를 써서 S3에 올리거나
직접 S3에 Backup 파일을 올려서
복원처리 가능
• 삭제는
모든 Cluster instance 중지 후
삭제 가능
• 지금/다음에 업그레이드는
엔진 버전 업데이트나
수정 사항 업데이트
23.
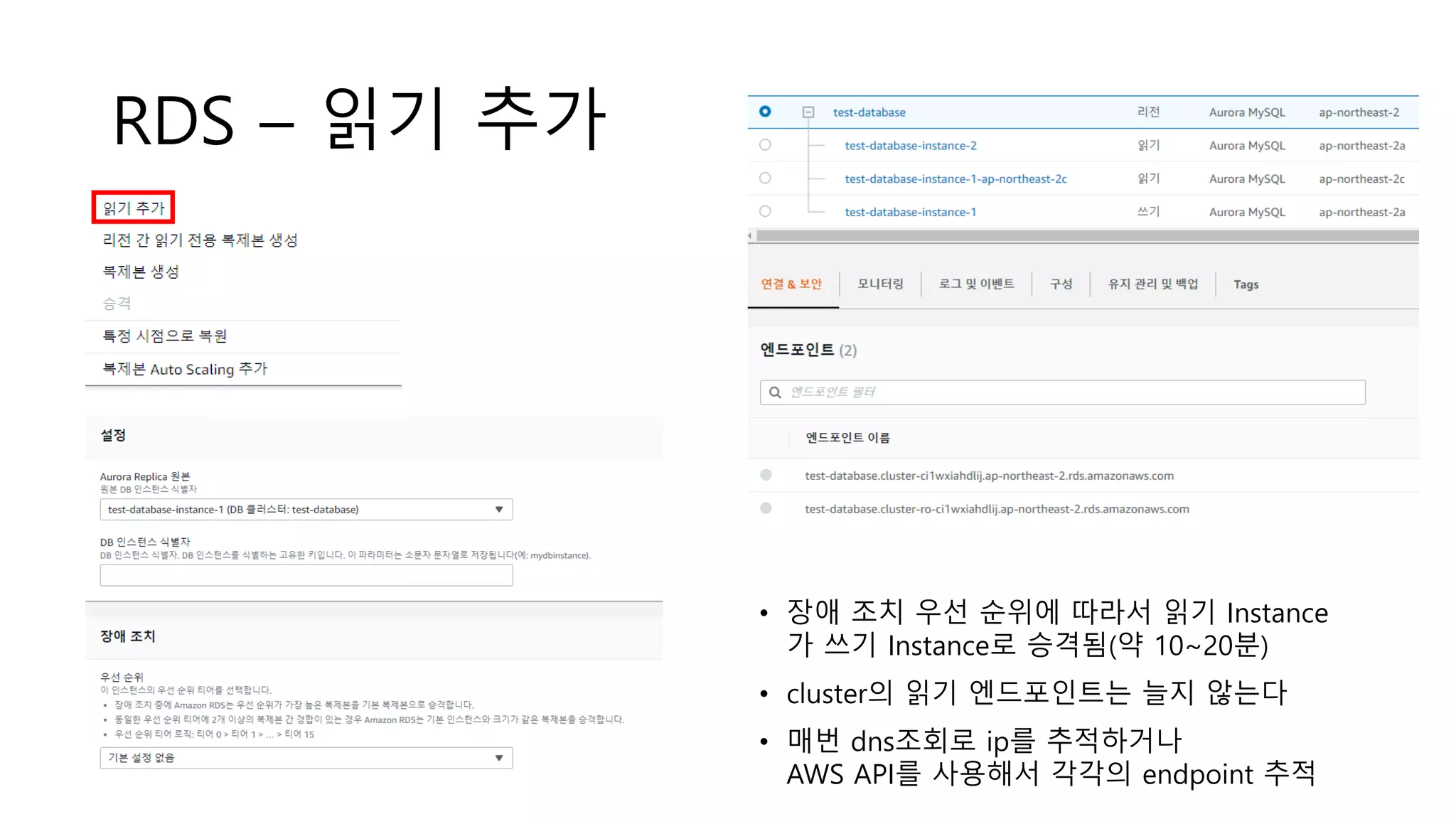
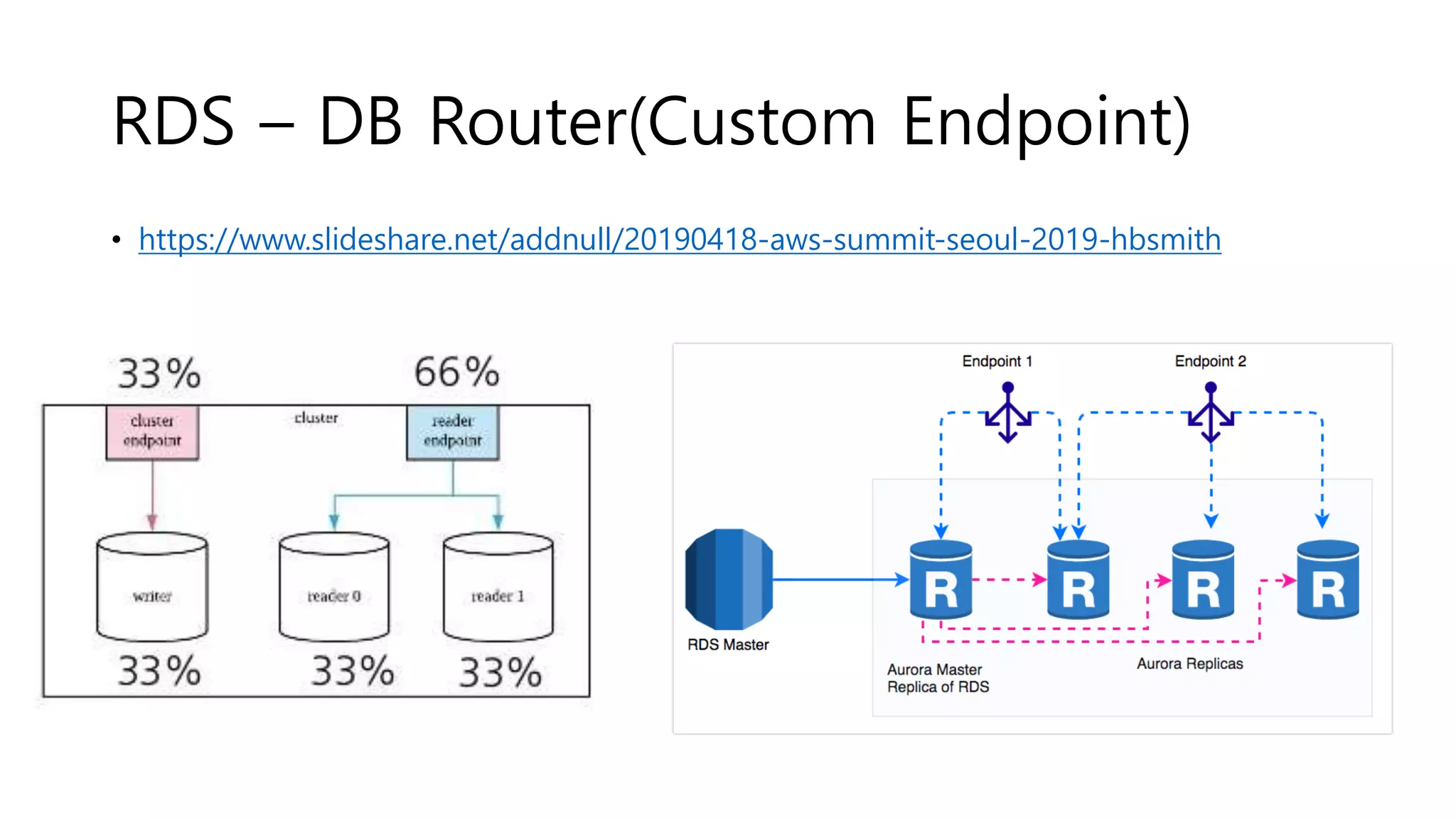
RDS – 읽기추가
• 장애 조치 우선 순위에 따라서 읽기 Instance
가 쓰기 Instance로 승격됨(약 10~20분)
• cluster의 읽기 엔드포인트는 늘지 않는다
• 매번 dns조회로 ip를 추적하거나
AWS API를 사용해서 각각의 endpoint 추적
24.
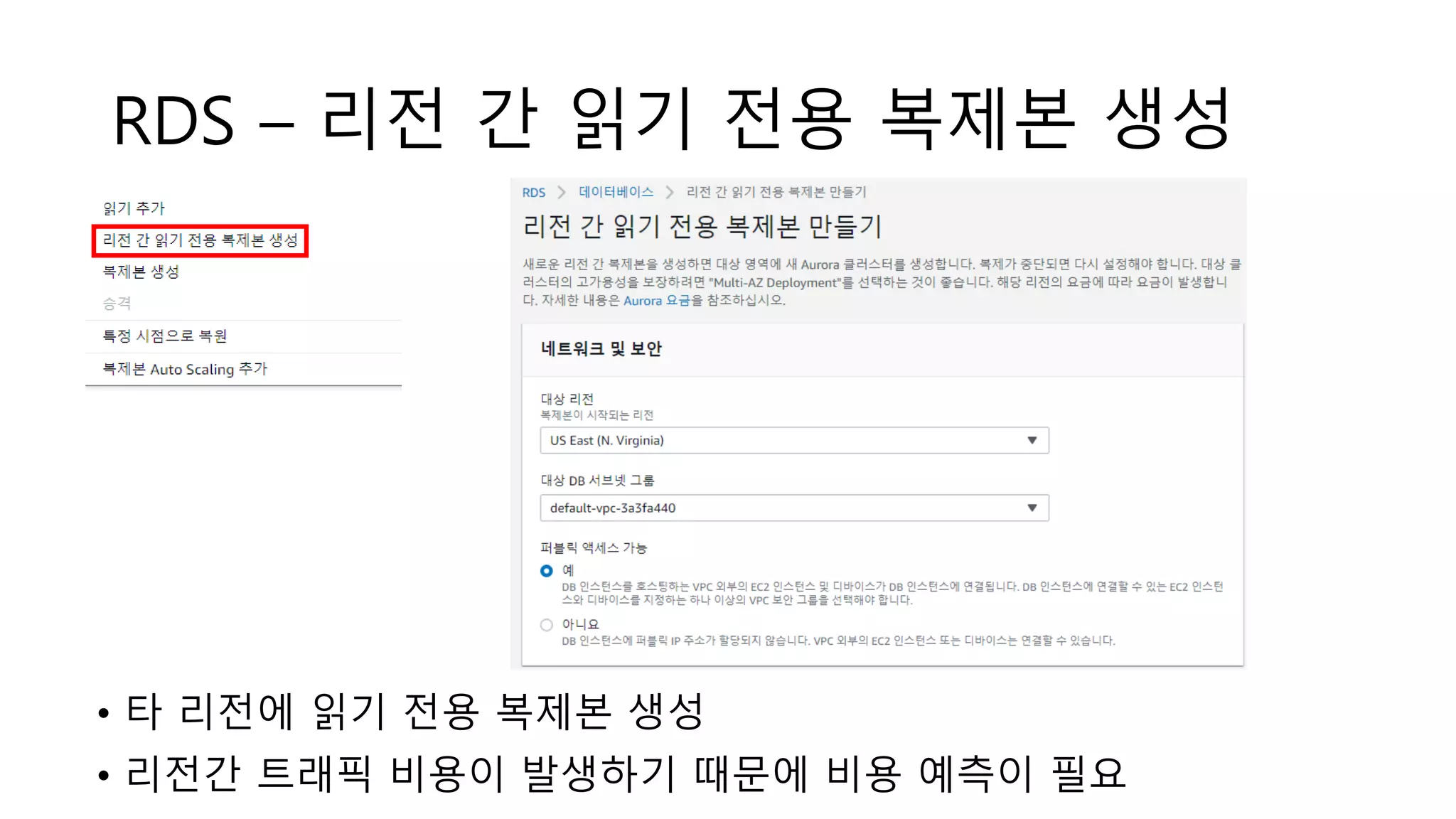
RDS – 리전간 읽기 전용 복제본 생성
• 타 리전에 읽기 전용 복제본 생성
• 리전간 트래픽 비용이 발생하기 때문에 비용 예측이 필요
25.
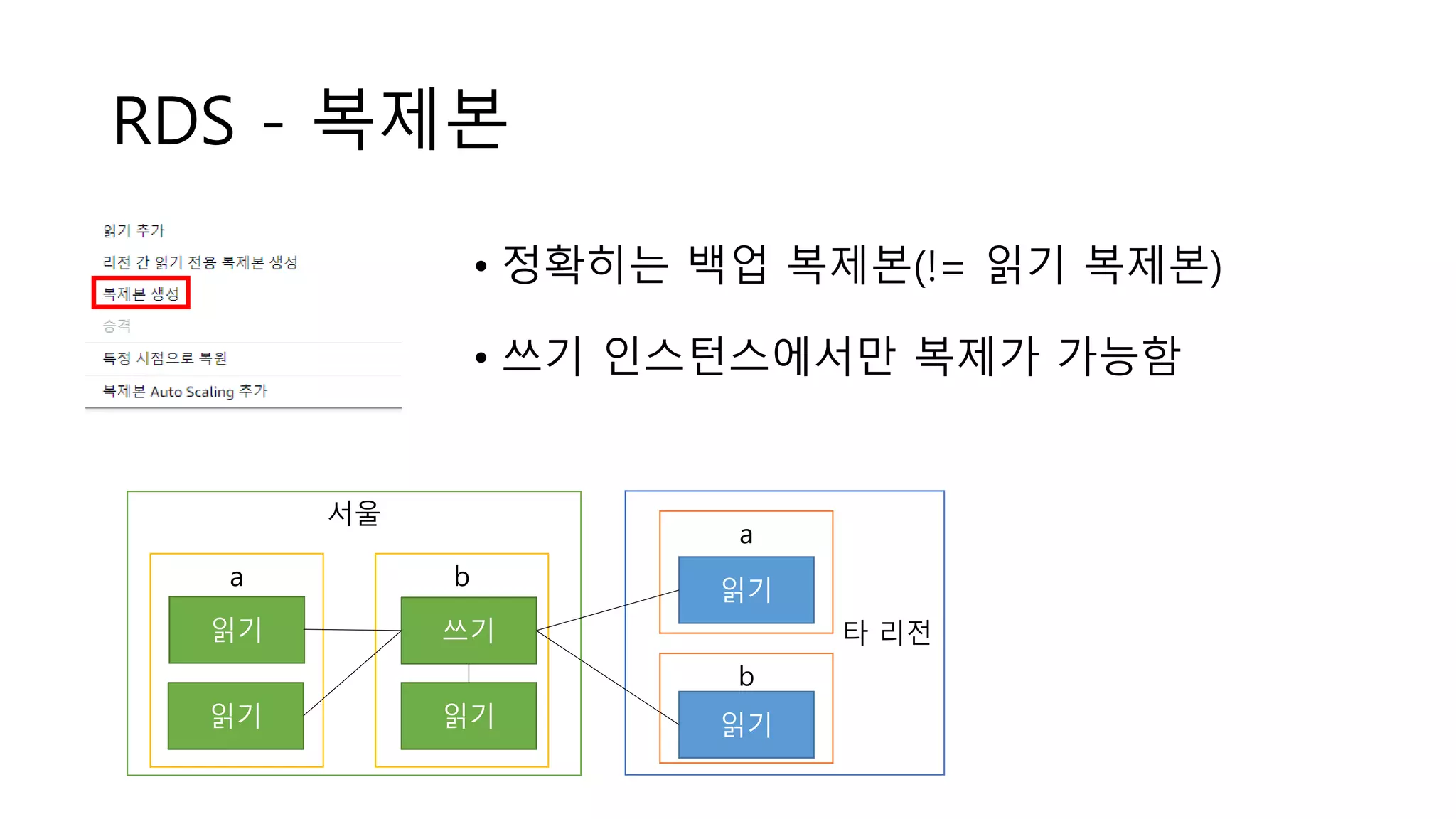
RDS - 복제본
•정확히는 백업 복제본(!= 읽기 복제본)
• 쓰기 인스턴스에서만 복제가 가능함
서울
타 리전쓰기
읽기읽기
읽기
읽기
읽기
a b
a
b
26.
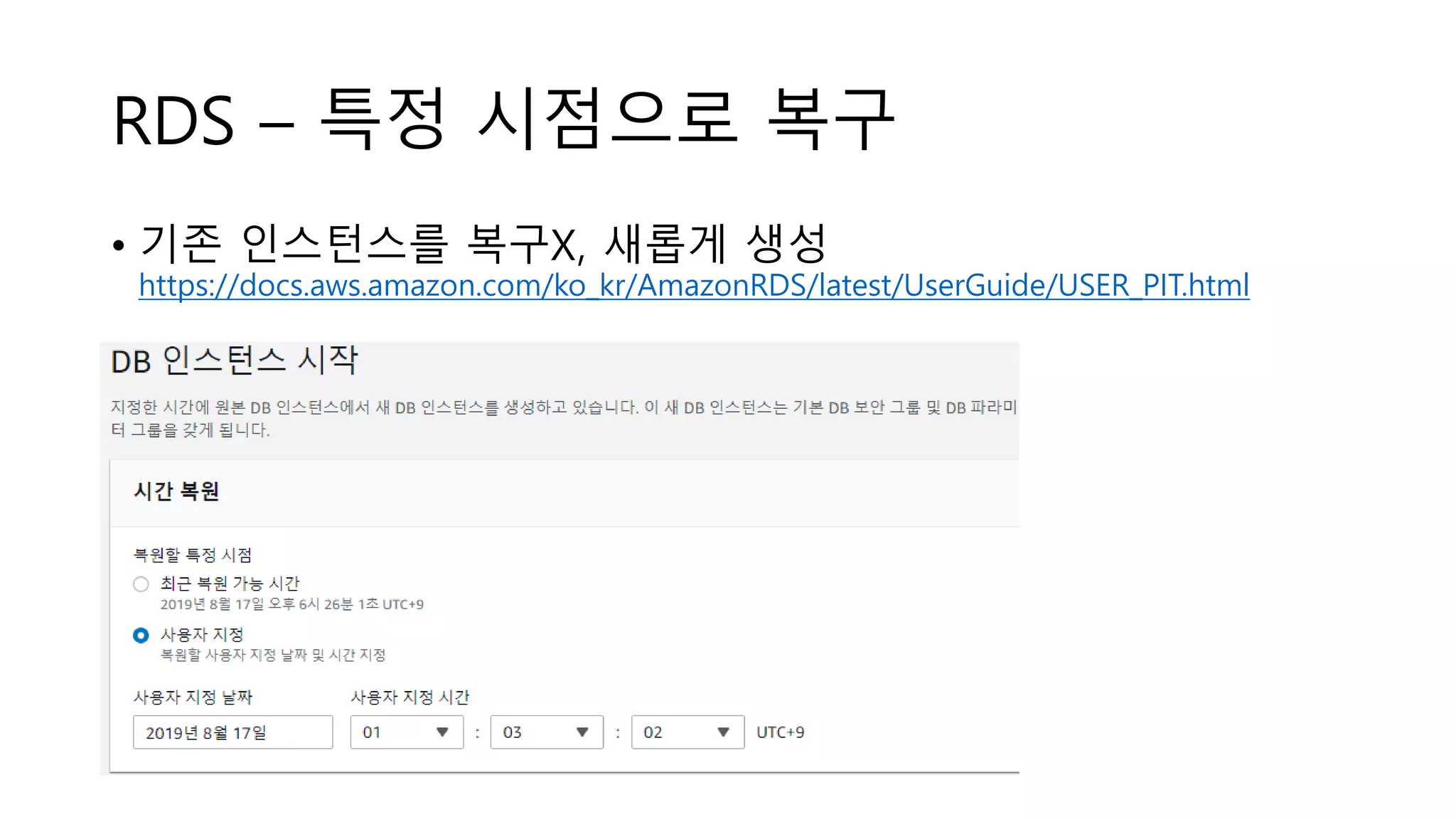
RDS – 특정시점으로 복구
• 기존 인스턴스를 복구X, 새롭게 생성
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/USER_PIT.html
27.
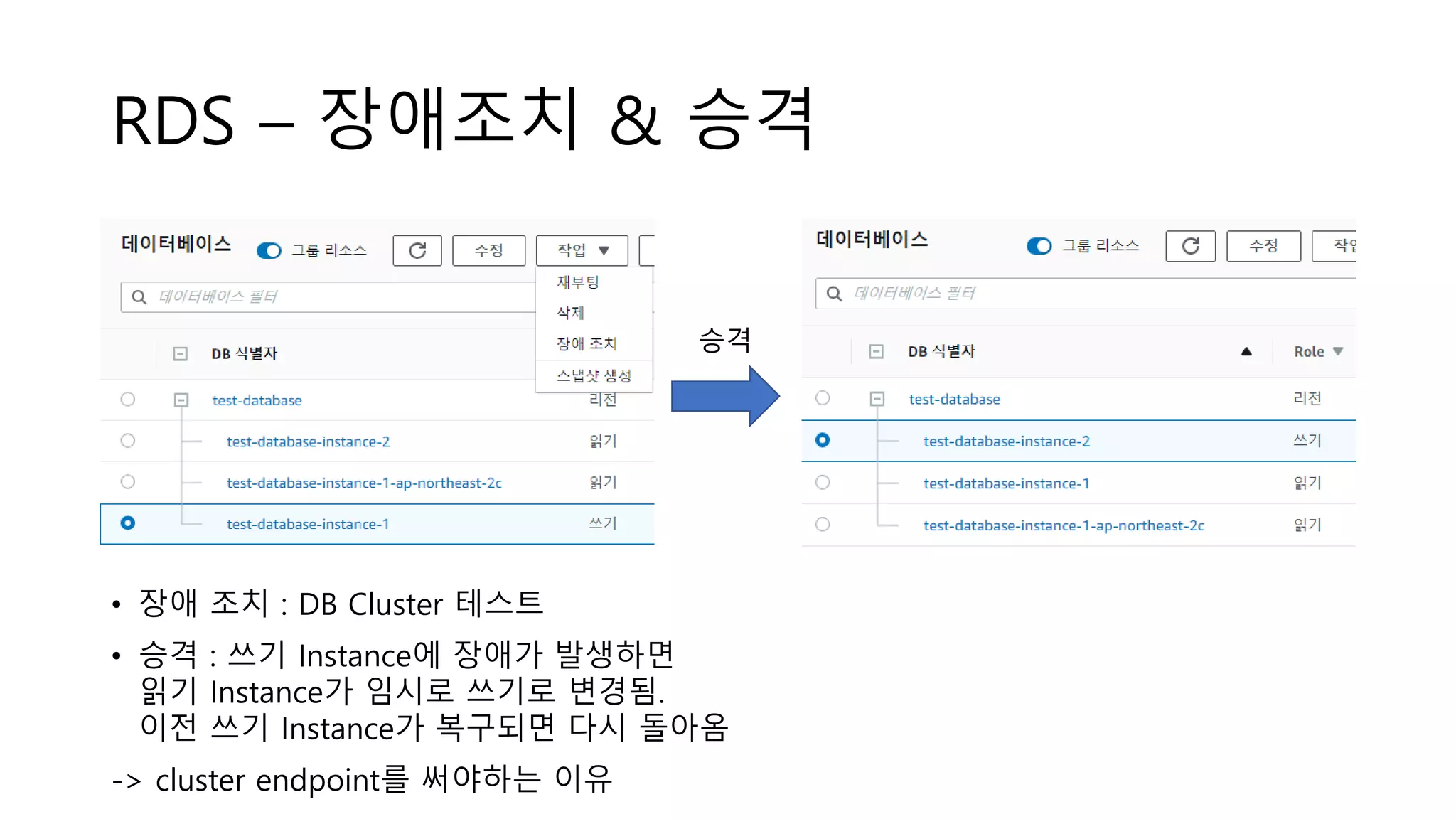
RDS – 장애조치& 승격
승격
• 장애 조치 : DB Cluster 테스트
• 승격 : 쓰기 Instance에 장애가 발생하면
읽기 Instance가 임시로 쓰기로 변경됨.
이전 쓰기 Instance가 복구되면 다시 돌아옴
-> cluster endpoint를 써야하는 이유
28.
RDS – AutoScaling
• CPU, Connection으로 Auto Scale Up/Down 가능
• 최소 1~15개의 복제본 생성 가능
• 아직은 Read만 Scaling 가능
29.
RDS – MultiMaster
• https://aws.amazon.com/ko/about-aws/whats-
new/2019/08/amazon-aurora-multimaster-now-generally-
available/
• 지원 리전
• 미국 동부(버지니아 북부)
• 미국 동부(오하이오)
• 미국 서부(오레곤)
• EU(아일랜드)
• 지원 버전 - Aurora MySQL 5.6에서 사용
RDS – AuroraServerless
• MySQL 5.6만 가능
• 사용 빈도가 낮거나 예측할 수 없는 workload에서 사용
• 인스턴스 및 용량 관리 불필요
• 컴퓨팅 & 메모리 확장시 클라이언트 연결 유지
• 1 ACU(Aurora Capacity Unit) = $0.1
• 1 ACU = 2 Gb RAM
32.
RDS – AuroraPrice
• 온디맨드 요금 = r5.12xlarge 기준 750시간 $6300
• 48 core, 384 RAM, EBS 7000Mbps, Net 10 Gbps
• MySQL = $5130
• 스토리지 요금 = 월 GB당 $0.12
• MySQL = 단일 $0.131, Multi AZ $0.276
• I/O 요금 = 요청 100만 건당 $0.24
• 백업 스토리지 = 월 GB당 $0.023
• 역추적 = 변경 레크도 100만 개당 $0.014
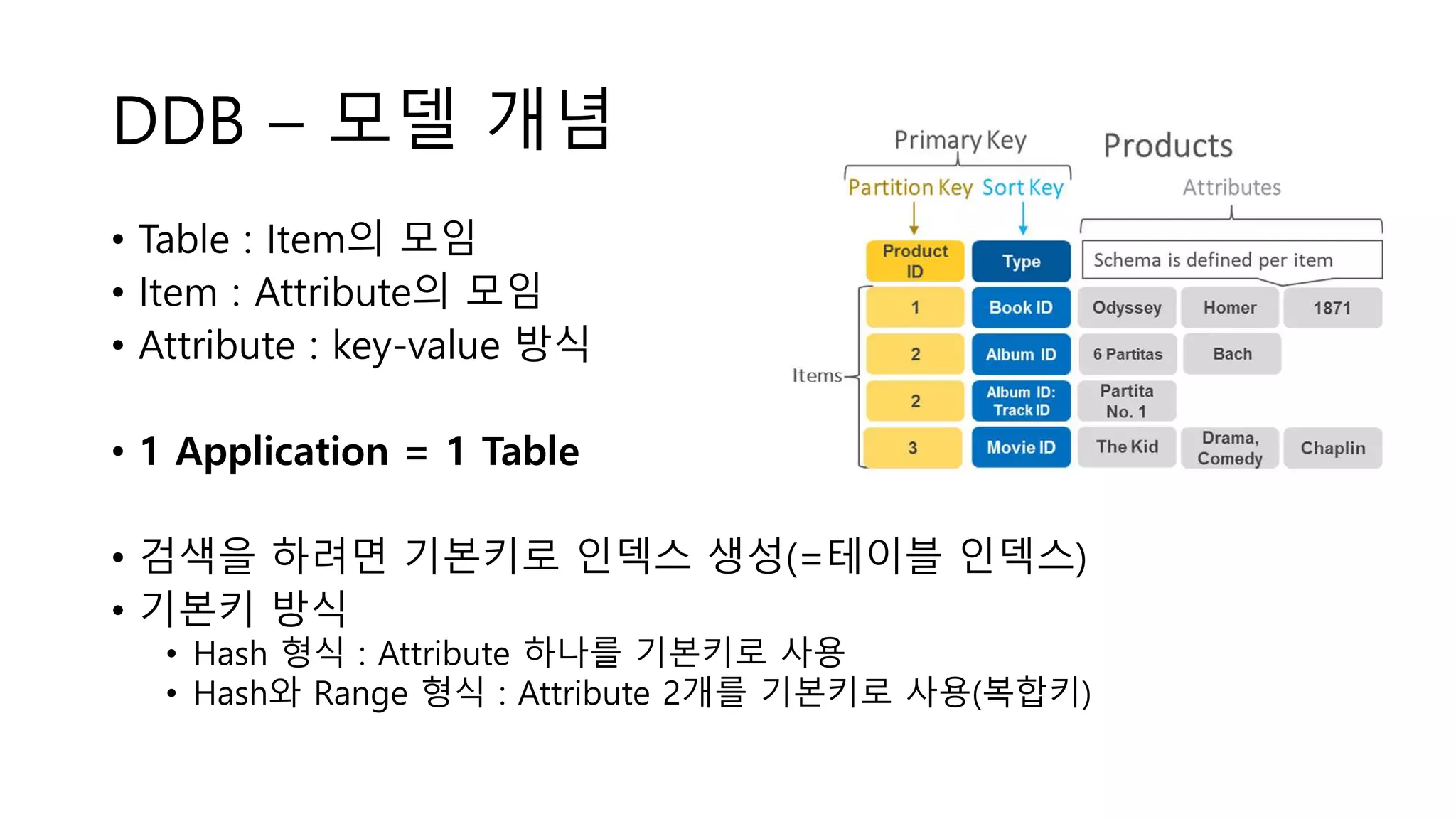
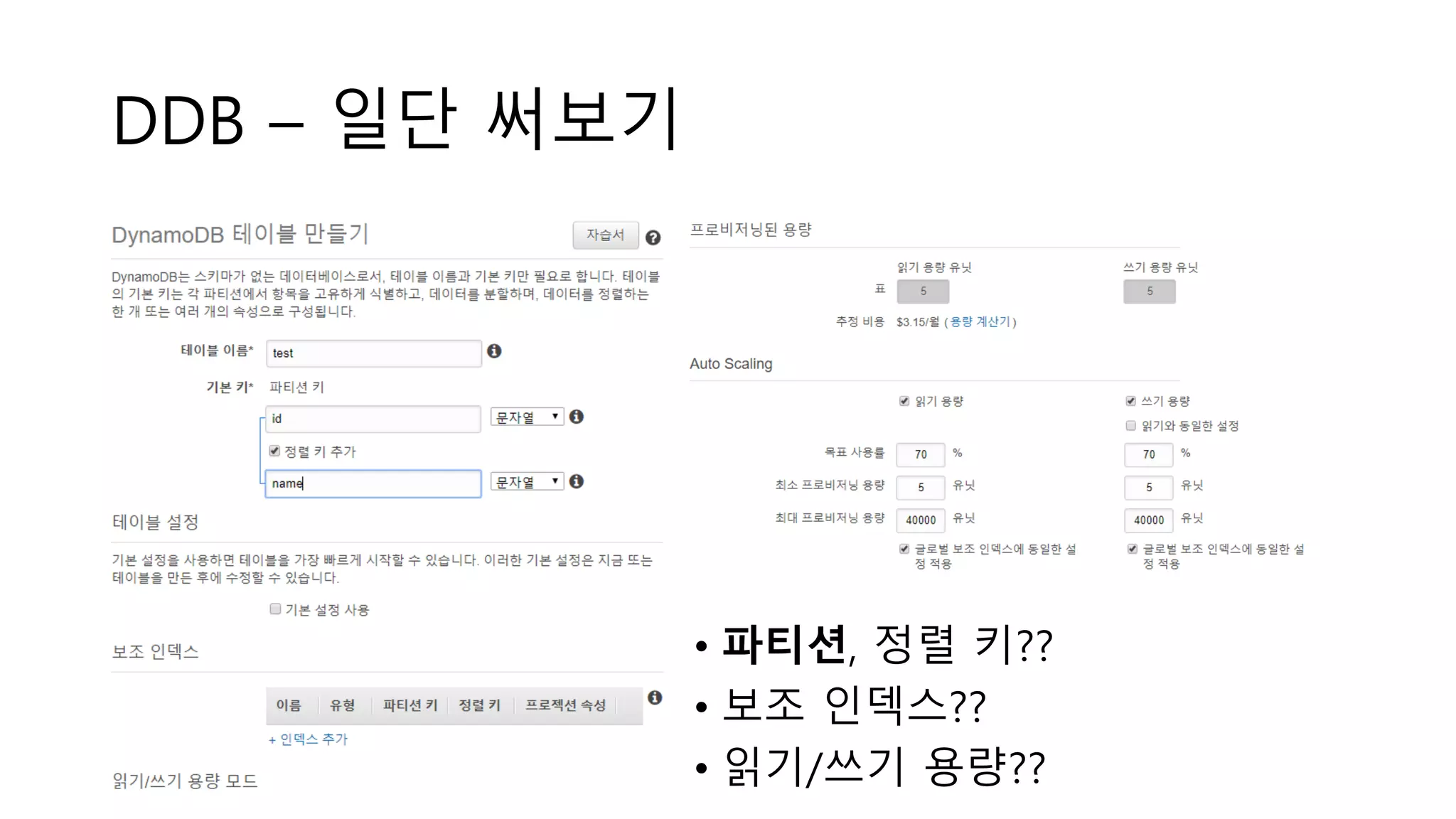
DDB - 함정
•파티션키
• 정렬키
• 보조 인덱스
• 읽기/쓰기 용량
• 용량 모드 – On-demand/Provisioned
• 지옥의 쿼리...
41.
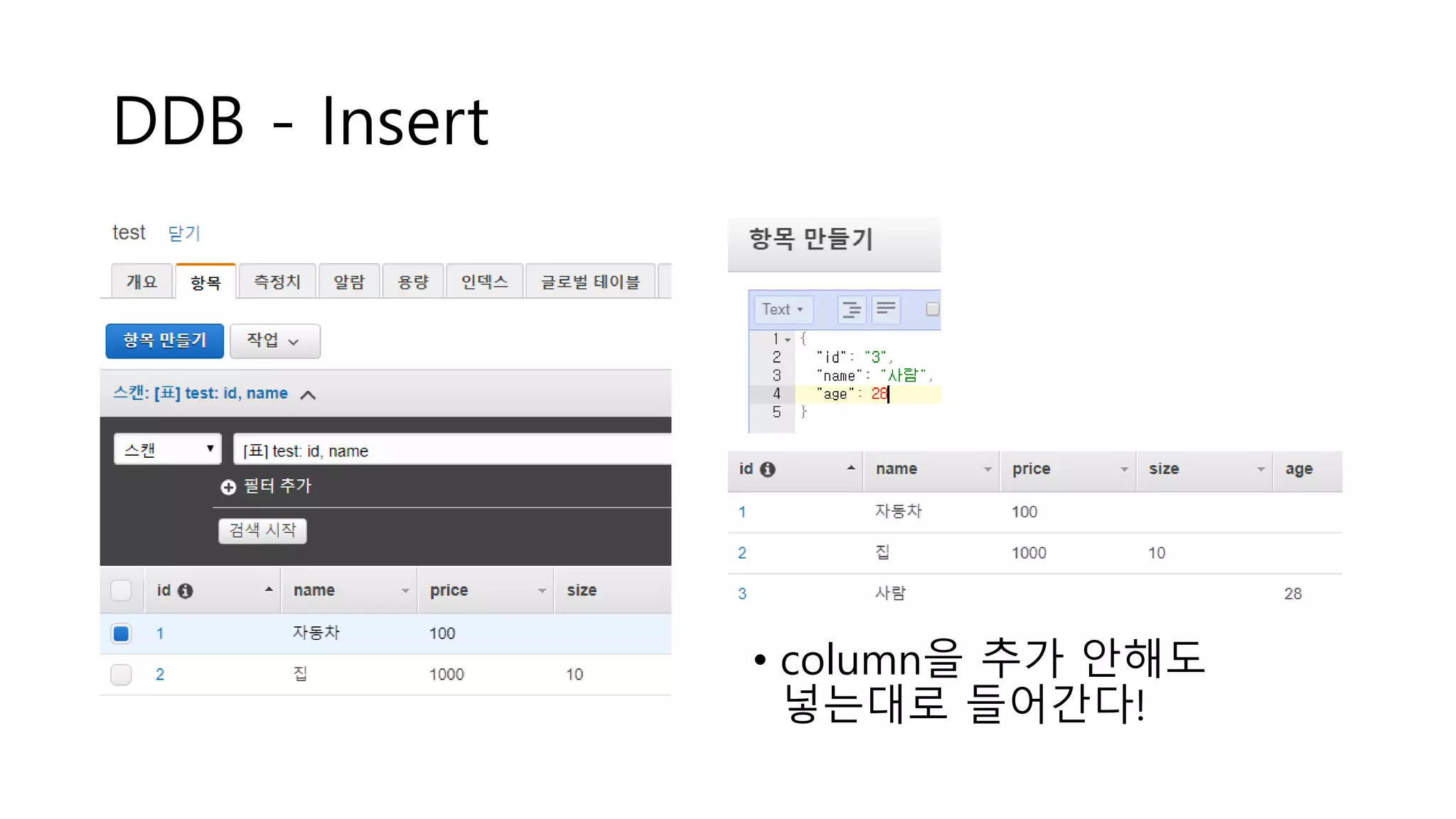
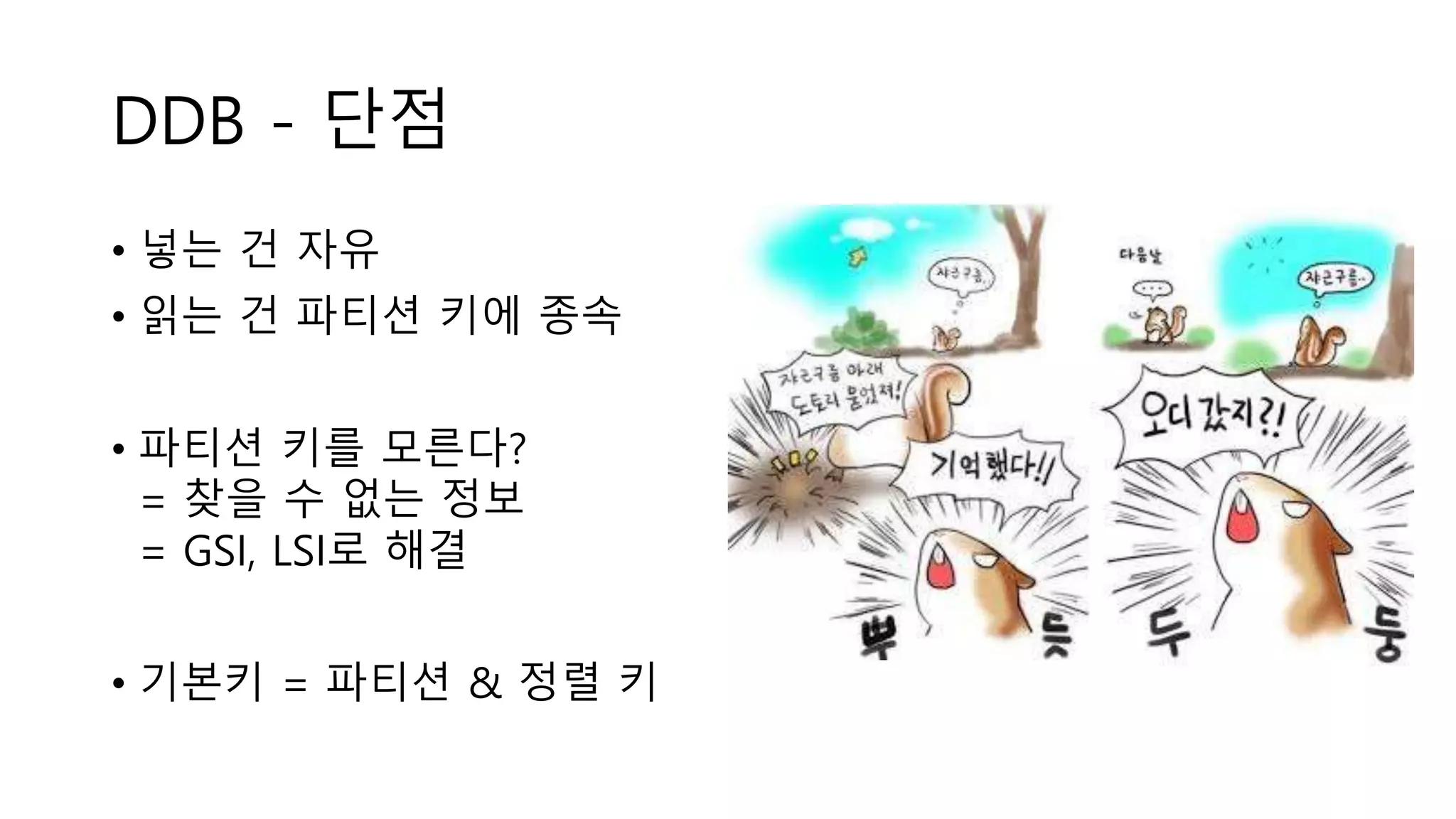
DDB - 단점
•넣는 건 자유
• 읽는 건 파티션 키에 종속
• 파티션 키를 모른다?
= 찾을 수 없는 정보
= GSI, LSI로 해결
• 기본키 = 파티션 & 정렬 키
42.
DDB – Queryvs Scan
• 파티션 키 = 필수
• 필터O, 정렬O
• 모든 항목을 읽어옴
• 필터O, 정렬X
43.
DDB – Query문제점?
• 최소 파티션 키를 알아야 조회가 가능함
• 파티션 & 정렬키가 아닌 값으로 Query를 쓰고 싶다?
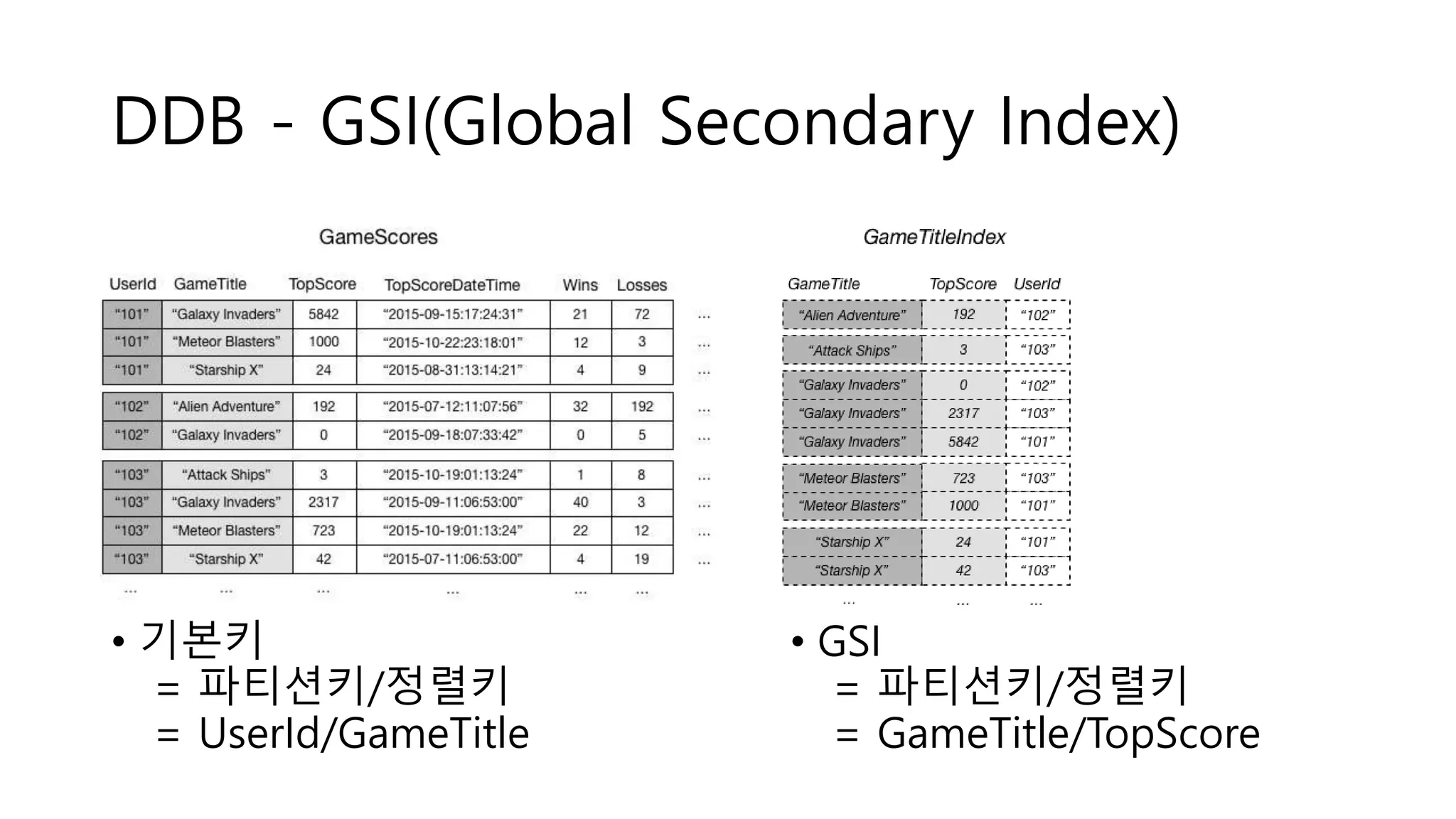
• GSI(Global Secondary Index)
• 파티션, 정렬키를 다르게 사용
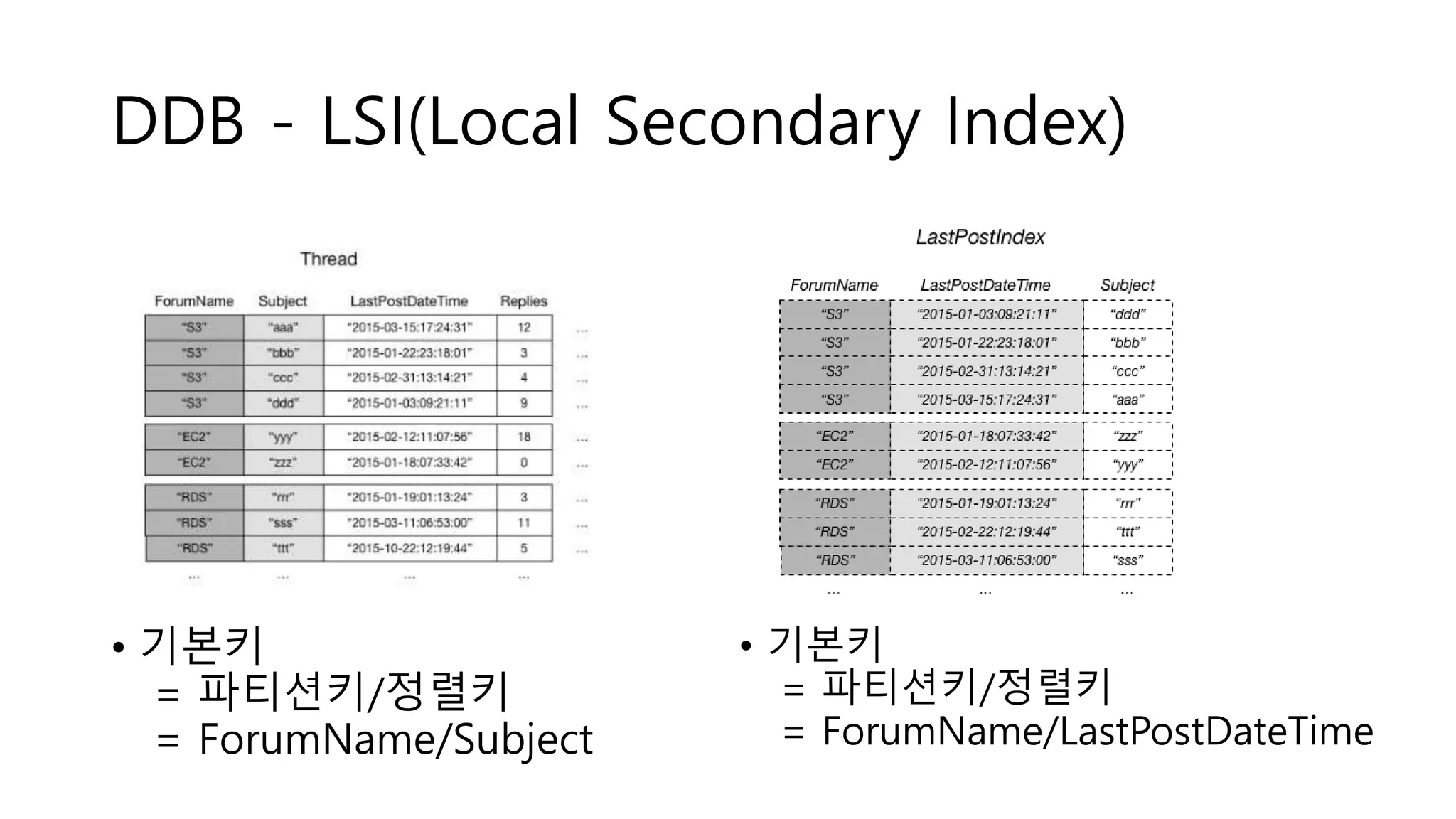
• LSI(Local Secondary Index)
• 정렬키만 다르게 사용
= 추가 스토리지 사용 = 당연히 추가요금 = 잘못된 테이블 설계
• 추가 속성을가져오려면 추가 읽기 작업을 수행해야함
= RCU 추가로 사용
• 쿼리하고 가져오기 작업을 회피하기 가장 효율적인 방법
= Projection
DDB - Projection
47.
DDB - Projection
•옵션
• KEY_ONLY : 파티션/정렬/인덱스 키
• INCLUDE : KEY_ONLY + a
• ALL : 모든 속성이 추가
GSI/LSI를 쓰는 성능 상의 이점이 크게 감소함
48.
DDB – Read/WriteUnit
• RCU(Read Capacity Unit) 1 = 최대 4 KB
• Eventually Consistent Read(2 Unit)
: 최근 쓰기 작업의 결과 반영이 안될 수 있음
• Strongly Consistent Read(1 Unit)
: 최근 완료된 쓰기 결과까지 반영
• WCU(Write Capacity Unit) 1 = 최대 1 KB
API 호출 수가 아닌 초당 읽은 아이템 수로 결정됨
49.
DDB – 항목크기(item)
• String
• UTF-8 이진 인코딩을 사용하는 유니코드
• 크기 = attribute name length + UTF-8 인코딩 Byte 수
• 숫자
• 앞과 끝의 0은 잘리는 38자까지 지원
• 크기 = attribute name length + 유효숫자 2자리당 1 Byte + 1 Byte
• Null/Boolean
• 크기 = attribute name length + 1 Byte
• List/Map
• 내용에 상관없이 오버헤드 3 Byte 필요
• 크기 = attribute name length + 합계(중첩된 요소의 크기) + 3 Byte
비어있다면 attribute name length + 3 Byte
https://zaccharles.github.io/dynamodb-calculator/
DDB - 한계
•Provisioned 모드에서 RCU/WCU 하향이
하루에 최대 4번(상향은 제한X)
• 테이블당 최대 GSI 20개, LSI 5개
• 파티션 키 길이 : 1 ~ 2048 Bytes
• 정렬 키 길이 : 1 ~ 1024 Bytes
• 문자열 최대 : 400KB(UTF-8)
• 숫자 : 최대 38자리 정밀도의 양, 음수, 0
• Item 크기 : 속성 이름, 값 모두 포함 400 KB
(400KB가 넘으면 S3에 넣고 해당 ARN을 DDB에 저장)
52.
DDB & ElasticSearch
• 쿼리의 유연성, 비용문제, 스케일링 문제를 해결
• DDB Stream으로 가공한 뒤에 ES에 Insert
• 검색은 ES에서 처리
• Mapping 문제
• 타입이 다르면 ES에서 입력X
• Glue, Athena도 비슷한 문제 존재
• Plugin 문제
• 플러그인이 10개 밖에 지원 안함
53.
DDB – OnDemand & Transaction
• 돈만 내라
• Provisioning/Auto Scale의 고통 해방...?
• 2018년 하반기에 생긴 기능
54.
DDB – OnDemand
• 하루에 1회 On-Demand/Provisioned 모드 변경 가능
• https://aws.amazon.com/ko/blogs/korea/amazon-dynamodb-on-demand-no-capacity-planning-and-pay-per-request-pricing/
55.
DDB - On-Demandvs Provisioned Price
• On-Demand(1회 요청당)
• 쓰기 요청 유닛 1 = $0.0000013556
• 읽기 요청 유닛 1 = $0.000000271
• Provisioned(1초당)
• 1 WCU = $0.0007049
• 1 RCU = $0.00014098
• 단위는 올림으로 계산
• 나머지 비용은 동일
56.
DDB – 트랜잭션지원
• NoSQL이지만
여러 Table을 묶어서 트랜젝션 처리 가능해짐
• 더 이상 AWSLabs SDK 사용 안해도 됨
• 비용은 일반 요청에 4배(4배만큼 유닛을 사용)
• https://github.com/awslabs/dynamodb-transactions
57.
DDB – 요즘은...
•Dynamo DB + API Gateway : Restful API
• Dynamo DB + AppSync : GraphQL API
• Dynamo DB + Elastic Search : Restful API, 검색엔진
• Dynamo DB + CloudWatch : 시계열









































































![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 데이터베이스 - 박주연 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/04gamesonawsawsdatabase-191014082829-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)
























