Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takeshi Yamamuro
2,826 views
Sparkのクエリ処理系と周辺の話題
20161222のBDI研究会での発表資料
Engineering
◦
Read more
10
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 25
2
/ 25
3
/ 25
4
/ 25
5
/ 25
6
/ 25
7
/ 25
8
/ 25
9
/ 25
10
/ 25
11
/ 25
12
/ 25
13
/ 25
14
/ 25
15
/ 25
16
/ 25
17
/ 25
18
/ 25
19
/ 25
20
/ 25
21
/ 25
22
/ 25
23
/ 25
24
/ 25
25
/ 25
More Related Content
PDF
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Sparkを用いたビッグデータ解析 〜 前編 〜
by
x1 ichi
PDF
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PDF
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Sparkを用いたビッグデータ解析 〜 前編 〜
by
x1 ichi
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
What's hot
PDF
ゼロから始めるSparkSQL徹底活用!
by
Nagato Kasaki
PDF
Apache Sparkについて
by
BrainPad Inc.
PPTX
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise
by
YusukeKuramata
PPTX
Apache Spark チュートリアル
by
K Yamaguchi
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
PDF
Sparkをノートブックにまとめちゃおう。Zeppelinでね!(Hadoopソースコードリーディング 第19回 発表資料)
by
NTT DATA OSS Professional Services
PDF
SparkとCassandraの美味しい関係
by
datastaxjp
PDF
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
PDF
Apache Sparkの紹介
by
Ryuji Tamagawa
PDF
ストリームデータ分散処理基盤Storm
by
NTT DATA OSS Professional Services
PDF
本当にあったApache Spark障害の話
by
x1 ichi
PDF
Hadoop2.6の最新機能+
by
NTT DATA OSS Professional Services
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
PPTX
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
PDF
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」
by
Kazuki Taniguchi
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
ゼロから始めるSparkSQL徹底活用!
by
Nagato Kasaki
Apache Sparkについて
by
BrainPad Inc.
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise
by
YusukeKuramata
Apache Spark チュートリアル
by
K Yamaguchi
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
Sparkをノートブックにまとめちゃおう。Zeppelinでね!(Hadoopソースコードリーディング 第19回 発表資料)
by
NTT DATA OSS Professional Services
SparkとCassandraの美味しい関係
by
datastaxjp
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
Apache Sparkの紹介
by
Ryuji Tamagawa
ストリームデータ分散処理基盤Storm
by
NTT DATA OSS Professional Services
本当にあったApache Spark障害の話
by
x1 ichi
Hadoop2.6の最新機能+
by
NTT DATA OSS Professional Services
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」
by
Kazuki Taniguchi
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
Similar to Sparkのクエリ処理系と周辺の話題
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka...
by
NTT DATA Technology & Innovation
PPTX
Apache Sparkを使った感情極性分析
by
Tanaka Yuichi
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PPTX
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
by
Recruit Lifestyle Co., Ltd.
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PDF
Configureing analytics system with apache spark and object storage service of...
by
Kenichi Sonoda
PDF
DAIS2024参加報告 ~Spark中心にしらべてみた~ (JEDAI DAIS Recap 講演資料)
by
NTT DATA Technology & Innovation
PDF
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
PPTX
Bluemixを使ったTwitter分析
by
Tanaka Yuichi
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
[Oracle big data jam session #1] Apache Spark ことはじめ
by
Kenichi Sonoda
PDF
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
PDF
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PDF
The Future of Apache Spark
by
Hadoop / Spark Conference Japan
PDF
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料
by
Atsushi Tsuchiya
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka...
by
NTT DATA Technology & Innovation
Apache Sparkを使った感情極性分析
by
Tanaka Yuichi
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
データサイエンティストが力を発揮できるアジャイルデータ活用基盤
by
Recruit Lifestyle Co., Ltd.
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
Configureing analytics system with apache spark and object storage service of...
by
Kenichi Sonoda
DAIS2024参加報告 ~Spark中心にしらべてみた~ (JEDAI DAIS Recap 講演資料)
by
NTT DATA Technology & Innovation
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016
by
Nagato Kasaki
Bluemixを使ったTwitter分析
by
Tanaka Yuichi
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
[Oracle big data jam session #1] Apache Spark ことはじめ
by
Kenichi Sonoda
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
The Future of Apache Spark
by
Hadoop / Spark Conference Japan
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料
by
Atsushi Tsuchiya
More from Takeshi Yamamuro
PDF
20160908 hivemall meetup
by
Takeshi Yamamuro
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
PDF
VLDB’11勉強会 -Session 9-
by
Takeshi Yamamuro
PPTX
LLJVM: LLVM bitcode to JVM bytecode
by
Takeshi Yamamuro
PDF
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
PDF
MLflowによる機械学習モデルのライフサイクルの管理
by
Takeshi Yamamuro
PDF
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
PDF
Apache Spark + Arrow
by
Takeshi Yamamuro
PDF
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
PDF
An Experimental Study of Bitmap Compression vs. Inverted List Compression
by
Takeshi Yamamuro
PDF
Introduction to Modern Analytical DB
by
Takeshi Yamamuro
PDF
20180417 hivemall meetup#4
by
Takeshi Yamamuro
PPT
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
PDF
Taming Distributed/Parallel Query Execution Engine of Apache Spark
by
Takeshi Yamamuro
PDF
20150513 legobease
by
Takeshi Yamamuro
PDF
VLDB2013 R1 Emerging Hardware
by
Takeshi Yamamuro
PDF
VAST-Tree, EDBT'12
by
Takeshi Yamamuro
PDF
20150516 icde2015 r19-4
by
Takeshi Yamamuro
PDF
A x86-optimized rank&select dictionary for bit sequences
by
Takeshi Yamamuro
PDF
LT: Spark 3.1 Feature Expectation
by
Takeshi Yamamuro
20160908 hivemall meetup
by
Takeshi Yamamuro
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
VLDB’11勉強会 -Session 9-
by
Takeshi Yamamuro
LLJVM: LLVM bitcode to JVM bytecode
by
Takeshi Yamamuro
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
MLflowによる機械学習モデルのライフサイクルの管理
by
Takeshi Yamamuro
SIGMOD’12勉強会 -Session 7-
by
Takeshi Yamamuro
Apache Spark + Arrow
by
Takeshi Yamamuro
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
by
Takeshi Yamamuro
An Experimental Study of Bitmap Compression vs. Inverted List Compression
by
Takeshi Yamamuro
Introduction to Modern Analytical DB
by
Takeshi Yamamuro
20180417 hivemall meetup#4
by
Takeshi Yamamuro
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
Taming Distributed/Parallel Query Execution Engine of Apache Spark
by
Takeshi Yamamuro
20150513 legobease
by
Takeshi Yamamuro
VLDB2013 R1 Emerging Hardware
by
Takeshi Yamamuro
VAST-Tree, EDBT'12
by
Takeshi Yamamuro
20150516 icde2015 r19-4
by
Takeshi Yamamuro
A x86-optimized rank&select dictionary for bit sequences
by
Takeshi Yamamuro
LT: Spark 3.1 Feature Expectation
by
Takeshi Yamamuro
Recently uploaded
PPTX
【ASW22-01】STAMP:STPAロスシナリオの発想・整理支援ツールの開発 ~astah* System Safetyによる構造化・階層化機能の実装...
by
csgy24013
PDF
0.0001秒の攻防!?快適な運転を支えるリアルタイム制御と組み込みエンジニアの実践知【DENSO Tech Night 第四夜】
by
dots.
PDF
サーバーサイド Kotlin を社内で普及させてみた - Server-Side Kotlin Night 2025
by
Hirotaka Kawata
PDF
Kubernetes Release Team Release Signal Role について ~Kubernetes Meetup Tokyo #72~
by
Keisuke Ishigami
PPTX
「グローバルワン全員経営」の実践を通じて進化し続けるファーストリテイリングのアーキテクチャ
by
Fast Retailing Co., Ltd.
PDF
Nanami Doikawa_寄り道の誘発を目的とした旅行写真からのスポット印象語彙の推定に関する基礎検討_EC2025
by
Matsushita Laboratory
PDF
Rin Ukai_即興旅行の誘発を目的とした口コミ情報に基づく雰囲気キーワード_EC2025.pdf
by
Matsushita Laboratory
【ASW22-01】STAMP:STPAロスシナリオの発想・整理支援ツールの開発 ~astah* System Safetyによる構造化・階層化機能の実装...
by
csgy24013
0.0001秒の攻防!?快適な運転を支えるリアルタイム制御と組み込みエンジニアの実践知【DENSO Tech Night 第四夜】
by
dots.
サーバーサイド Kotlin を社内で普及させてみた - Server-Side Kotlin Night 2025
by
Hirotaka Kawata
Kubernetes Release Team Release Signal Role について ~Kubernetes Meetup Tokyo #72~
by
Keisuke Ishigami
「グローバルワン全員経営」の実践を通じて進化し続けるファーストリテイリングのアーキテクチャ
by
Fast Retailing Co., Ltd.
Nanami Doikawa_寄り道の誘発を目的とした旅行写真からのスポット印象語彙の推定に関する基礎検討_EC2025
by
Matsushita Laboratory
Rin Ukai_即興旅行の誘発を目的とした口コミ情報に基づく雰囲気キーワード_EC2025.pdf
by
Matsushita Laboratory
Sparkのクエリ処理系と周辺の話題
1.
Copyright©2016 NTT corp.
All Rights Reserved. 2016.12.22 Takeshi Yamamuro@ NTT SIC Sparkのクエリ処理理系と周辺の話題
2.
2Copyright©2016 NTT corp.
All Rights Reserved. ⾃自⼰己紹介
3.
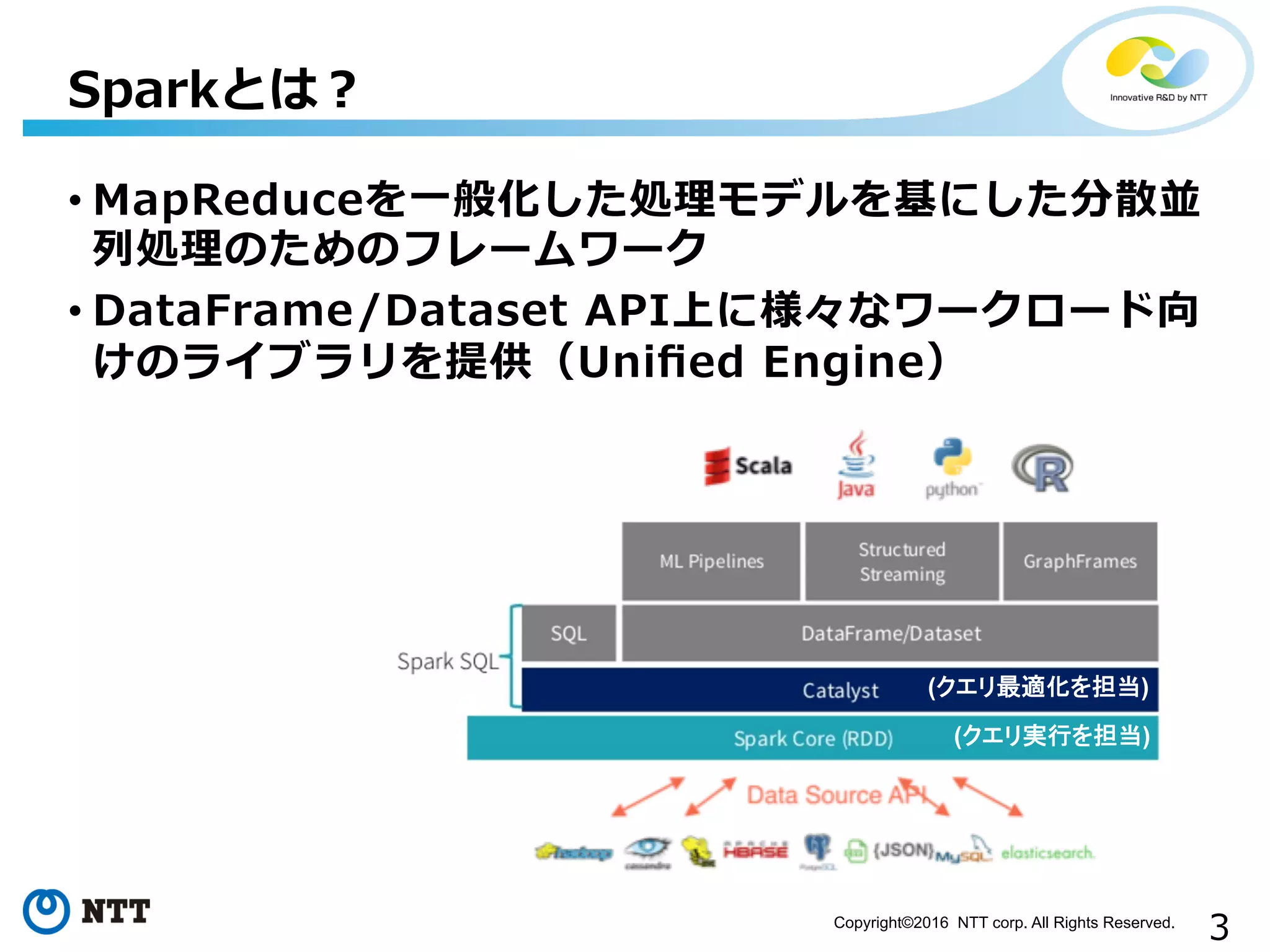
3Copyright©2016 NTT corp.
All Rights Reserved. • MapReduceを⼀一般化した処理理モデルを基にした分散並 列列処理理のためのフレームワーク • DataFrame/Dataset API上に様々なワークロード向 けのライブラリを提供(Unified Engine) Sparkとは? (クエリ最適化を担当) (クエリ実行を担当)
4.
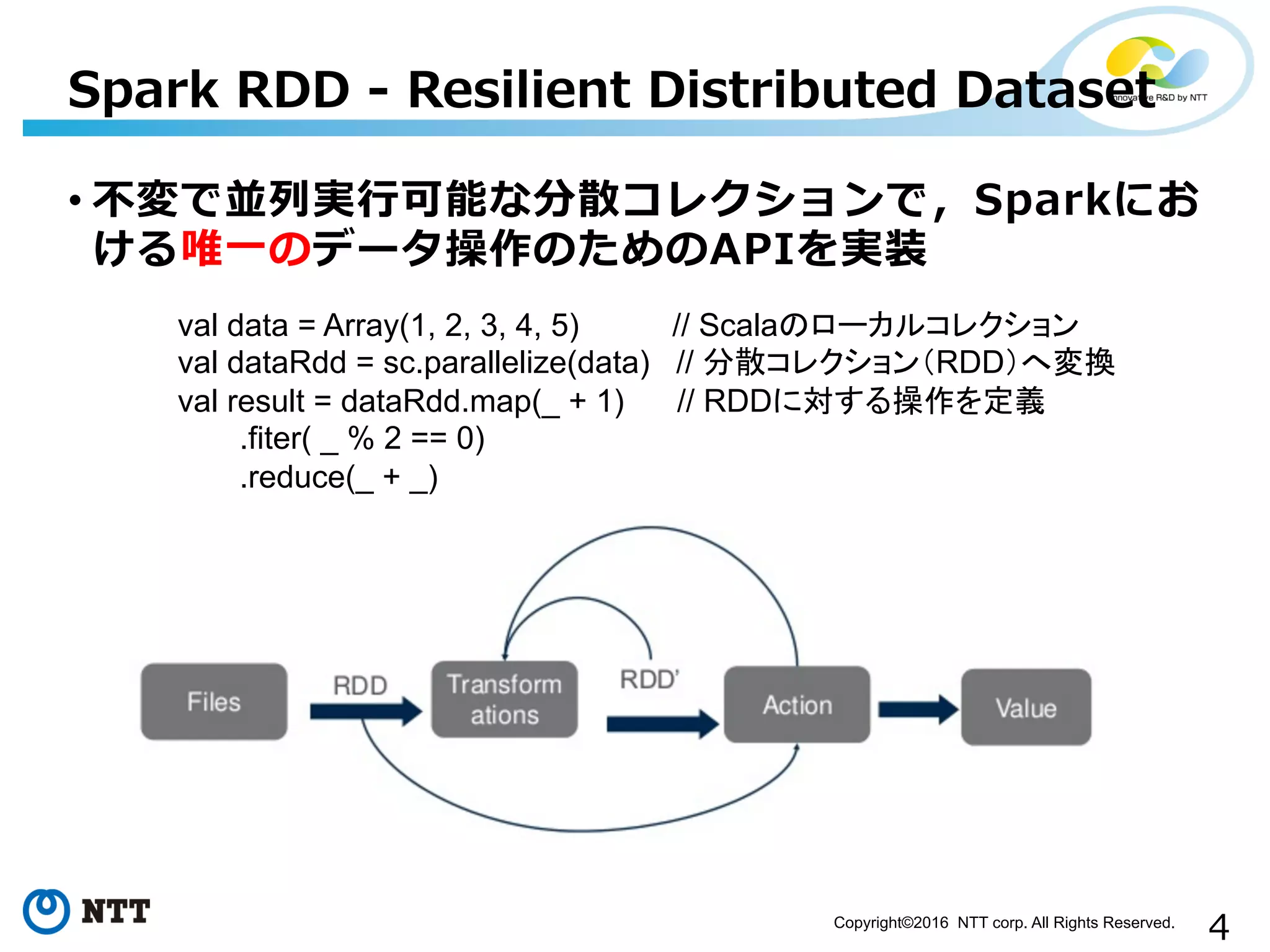
4Copyright©2016 NTT corp.
All Rights Reserved. • 不不変で並列列実⾏行行可能な分散コレクションで,Sparkにお ける唯⼀一のデータ操作のためのAPIを実装 Spark RDD -‐‑‒ Resilient Distributed Dataset val data = Array(1, 2, 3, 4, 5) // Scalaのローカルコレクション val dataRdd = sc.parallelize(data) // 分散コレクション(RDD)へ変換 val result = dataRdd.map(_ + 1) // RDDに対する操作を定義 .fiter( _ % 2 == 0) .reduce(_ + _)
5.
5Copyright©2016 NTT corp.
All Rights Reserved. • DataFrameはスキーマありの不不変な分散コレクション • 実際はDataFrame=Dataset[Row] Spark DataFrame/Dataset 引用: https://databricks.com/blog/ 2016/07/14/a-tale-of-three-apache- spark-apis-rdds-dataframes-and- datasets.html
6.
6Copyright©2016 NTT corp.
All Rights Reserved. Sparkの最近の基本⽅方針 引用: http://www.slideshare.net/databricks/structuring- spark-dataframes-datasets-and-streaming
7.
7Copyright©2016 NTT corp.
All Rights Reserved. Sparkの最近の基本⽅方針 引用: http://www.slideshare.net/databricks/structuring- spark-dataframes-datasets-and-streaming
8.
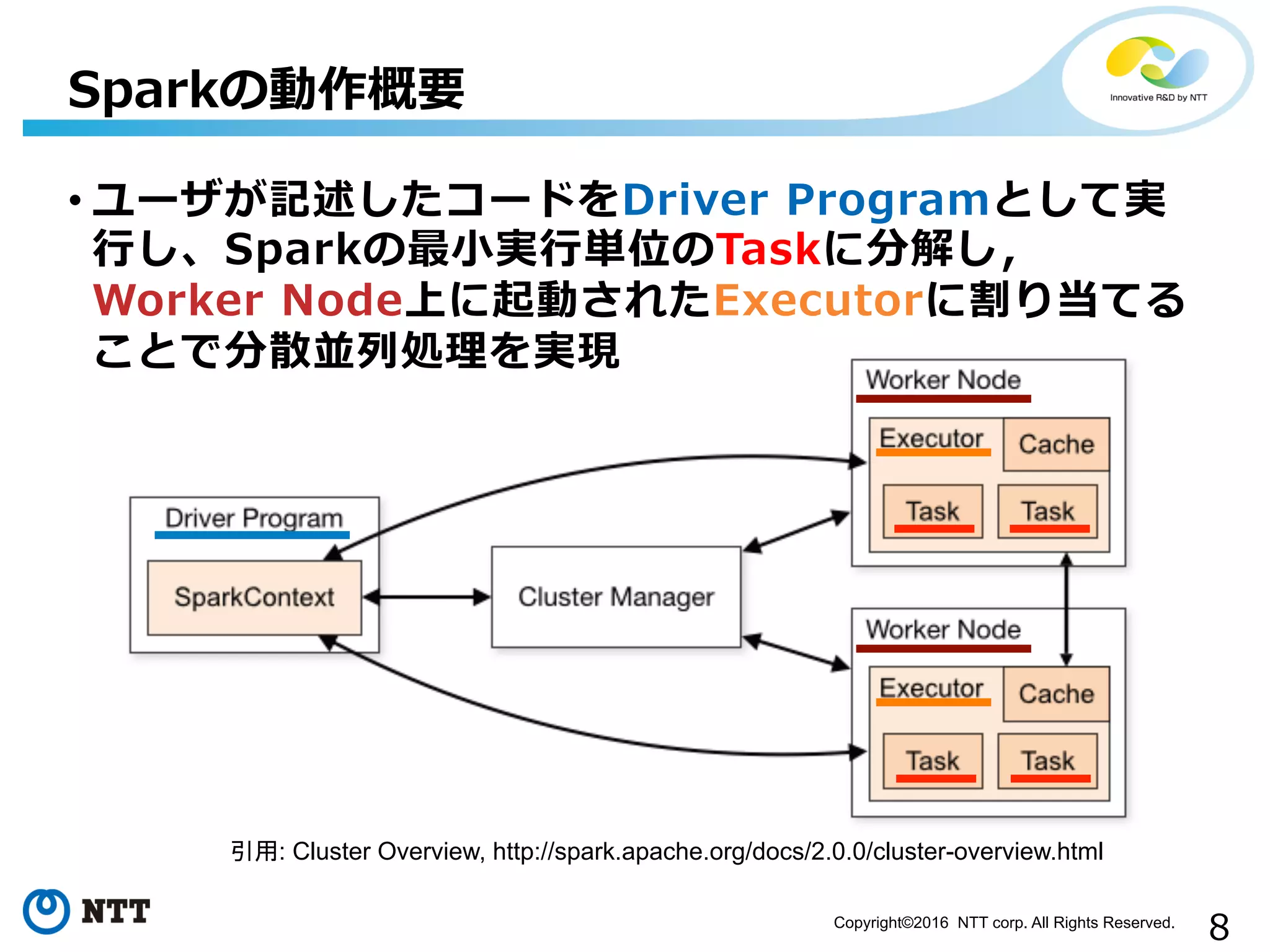
8Copyright©2016 NTT corp.
All Rights Reserved. Sparkの動作概要 • ユーザが記述したコードをDriver Programとして実 ⾏行行し、Sparkの最⼩小実⾏行行単位のTaskに分解し, Worker Node上に起動されたExecutorに割り当てる ことで分散並列列処理理を実現 引用: Cluster Overview, http://spark.apache.org/docs/2.0.0/cluster-overview.html
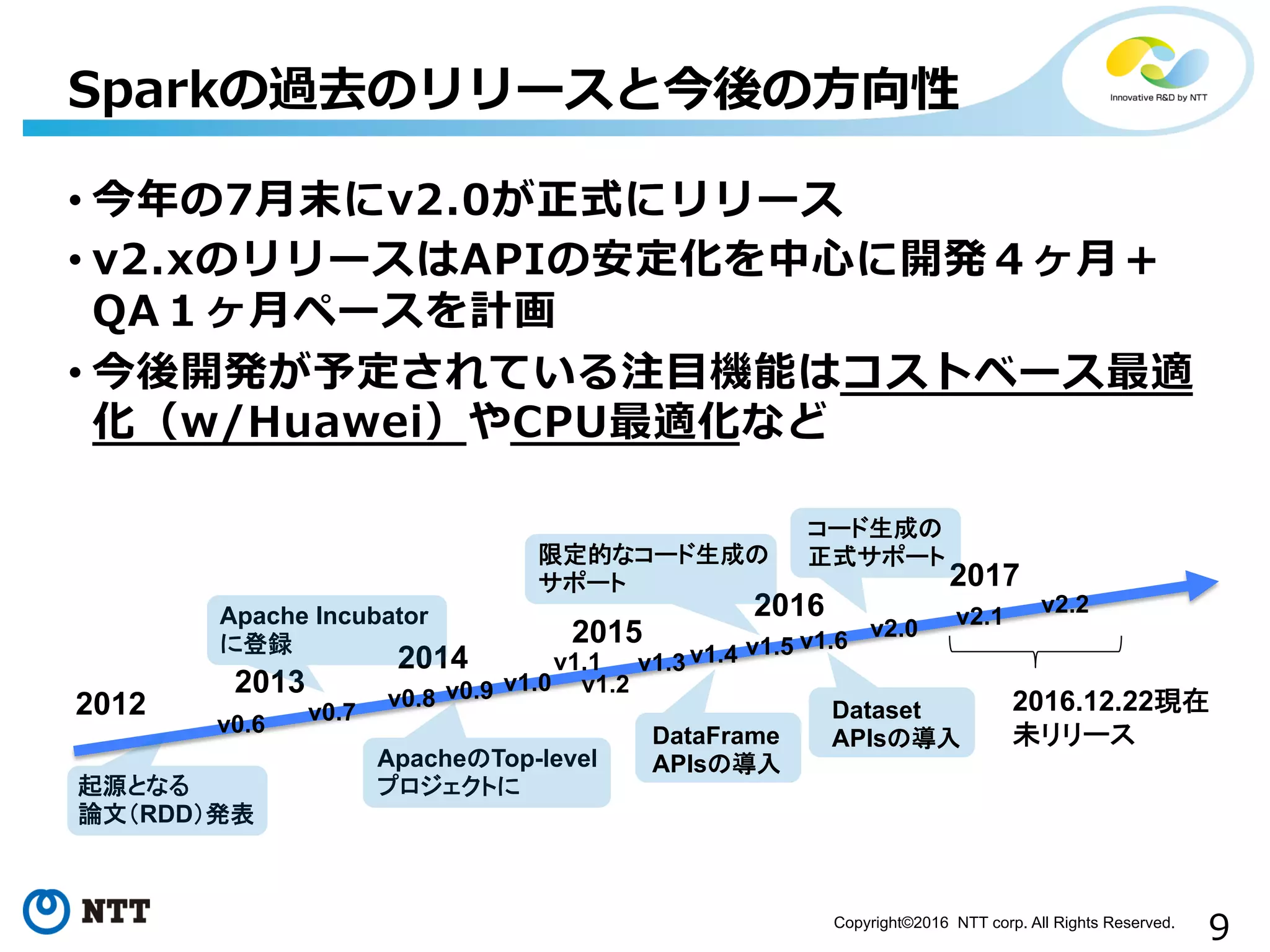
9.
9Copyright©2016 NTT corp.
All Rights Reserved. • 今年年の7⽉月末にv2.0が正式にリリース • v2.xのリリースはAPIの安定化を中⼼心に開発4ヶ⽉月+ QA1ヶ⽉月ペースを計画 • 今後開発が予定されている注⽬目機能はコストベース最適 化(w/Huawei)やCPU最適化など Sparkの過去のリリースと今後の⽅方向性 2012 2013 2014 2015 2016 2017 起源となる 論文(RDD)発表 Apache Incubator に登録 ApacheのTop-level プロジェクトに v1.0 v1.1 v1.2 v1.3 v1.4 v1.5 v1.6 v2.0 v2.1 v2.2 2016.12.22現在 未リリースv0.6 v0.7 v0.8 v0.9 DataFrame APIsの導入 限定的なコード生成の サポート Dataset APIsの導入 コード生成の 正式サポート
10.
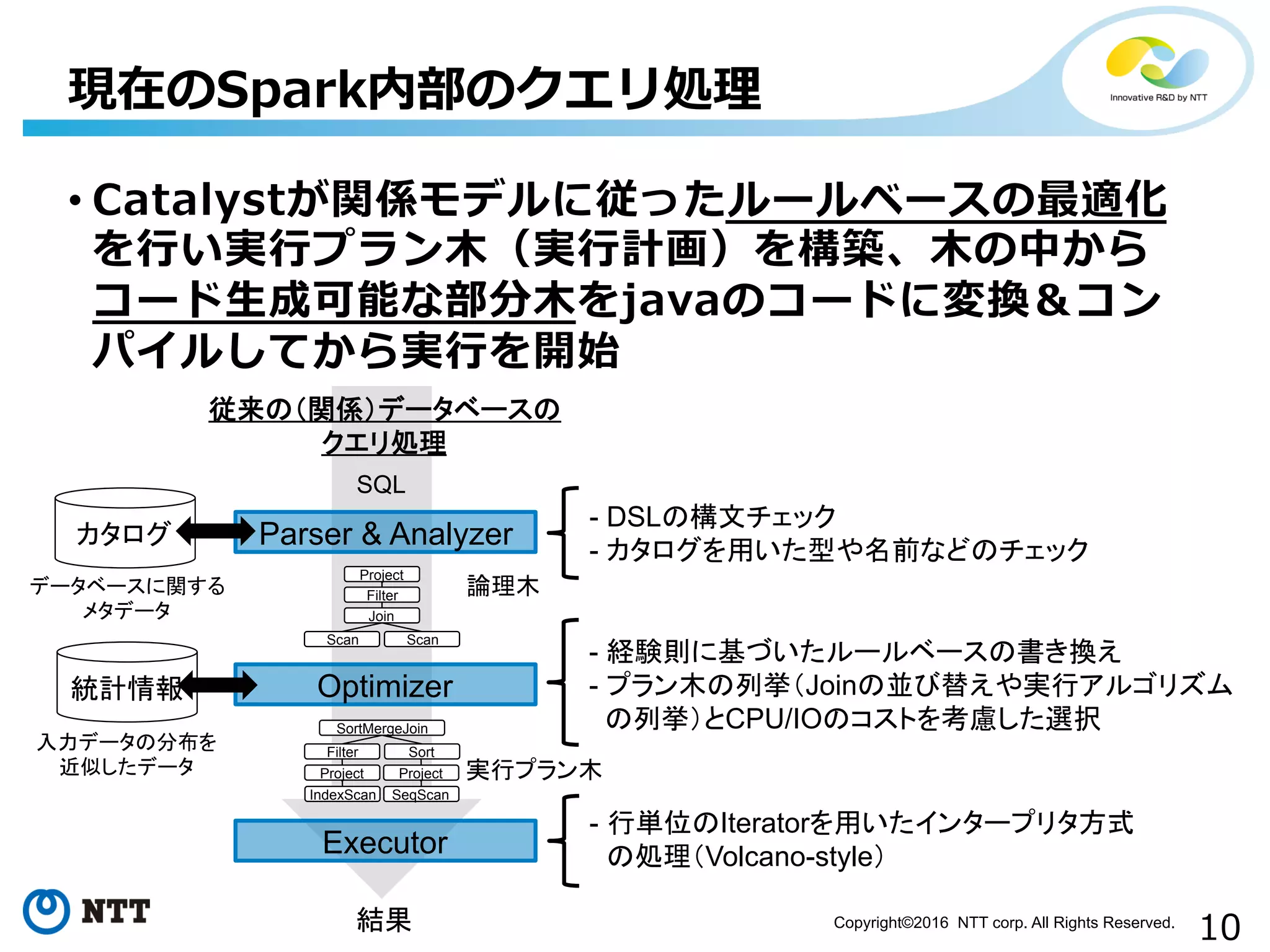
10Copyright©2016 NTT corp.
All Rights Reserved. • Catalystが関係モデルに従ったルールベースの最適化 を⾏行行い実⾏行行プラン⽊木(実⾏行行計画)を構築、⽊木の中から コード⽣生成可能な部分⽊木をjavaのコードに変換&コン パイルしてから実⾏行行を開始 現在のSpark内部のクエリ処理理 Parser & Analyzer Optimizer Executor 結果 従来の(関係)データベースの クエリ処理 統計情報 入力データの分布を 近似したデータ SQL Join Scan Filter Scan Project 論理木 SortMergeJoin Filter Sort 実行プラン木Project カタログ データベースに関する メタデータ - DSLの構文チェック - カタログを用いた型や名前などのチェック - 経験則に基づいたルールベースの書き換え - プラン木の列挙(Joinの並び替えや実行アルゴリズム の列挙)とCPU/IOのコストを考慮した選択 - 行単位のIteratorを用いたインタープリタ方式 の処理(Volcano-style) Project IndexScan SeqScan
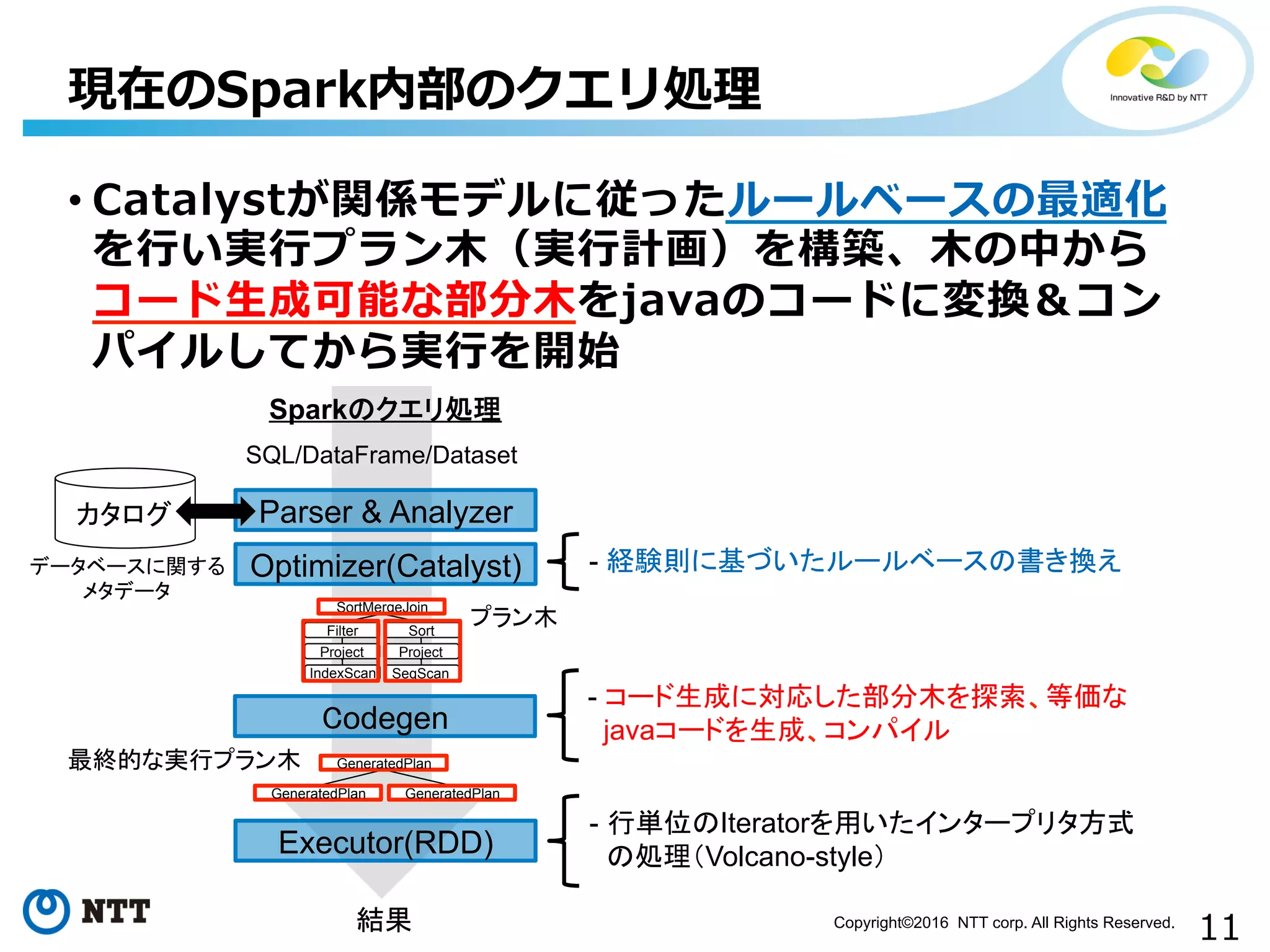
11.
11Copyright©2016 NTT corp.
All Rights Reserved. • Catalystが関係モデルに従ったルールベースの最適化 を⾏行行い実⾏行行プラン⽊木(実⾏行行計画)を構築、⽊木の中から コード⽣生成可能な部分⽊木をjavaのコードに変換&コン パイルしてから実⾏行行を開始 現在のSpark内部のクエリ処理理 Parser & Analyzer Optimizer(Catalyst) Executor(RDD) 結果 Sparkのクエリ処理 SQL/DataFrame/Dataset カタログ データベースに関する メタデータ - 経験則に基づいたルールベースの書き換え SortMergeJoin Filter Sort プラン木 Project Project IndexScan SeqScan Codegen GeneratedPlan GeneratedPlan GeneratedPlan 最終的な実行プラン木 - コード生成に対応した部分木を探索、等価な javaコードを生成、コンパイル - 行単位のIteratorを用いたインタープリタ方式 の処理(Volcano-style)
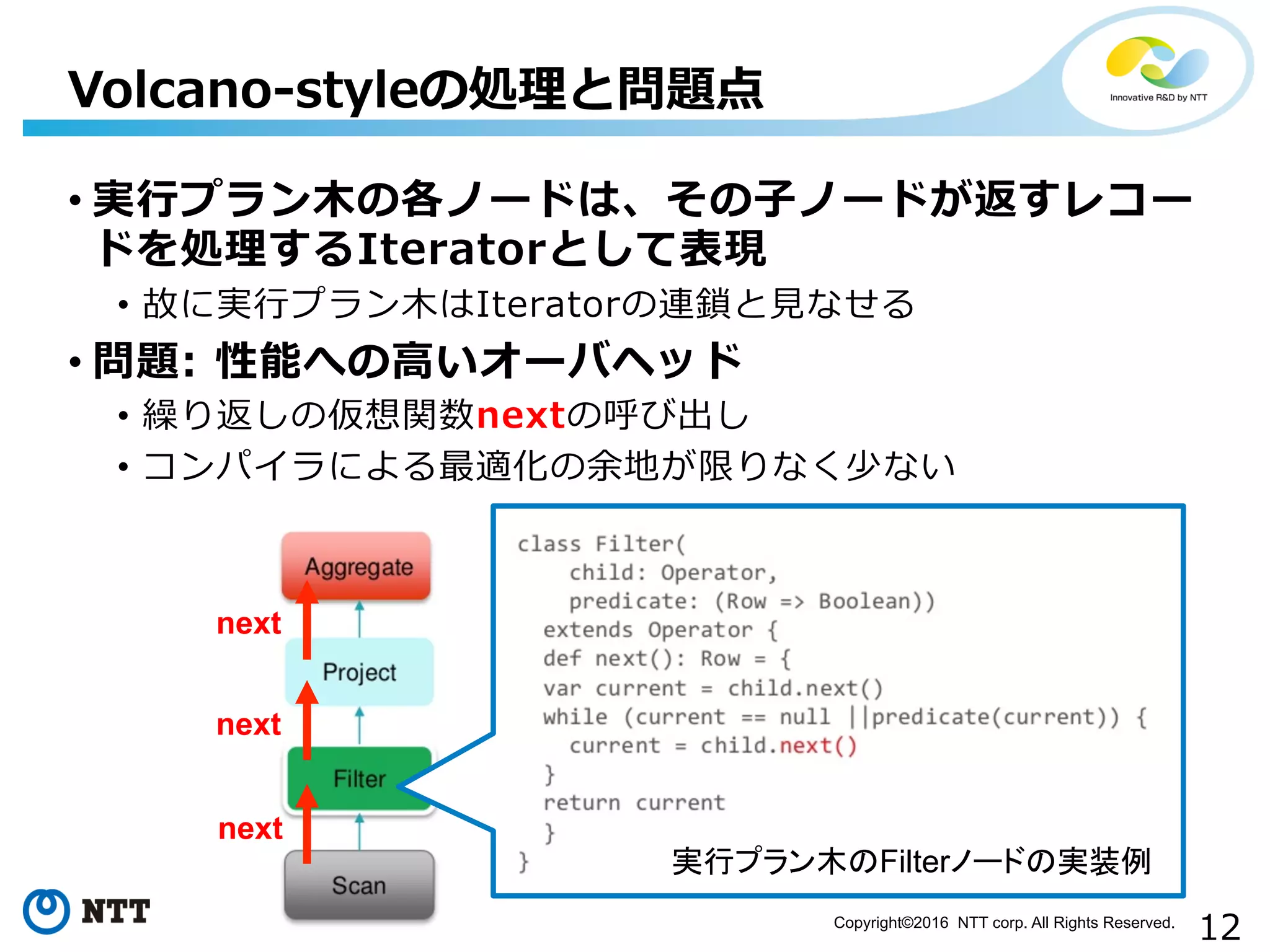
12.
12Copyright©2016 NTT corp.
All Rights Reserved. • 実⾏行行プラン⽊木の各ノードは、その⼦子ノードが返すレコー ドを処理理するIteratorとして表現 • 故に実⾏行行プラン⽊木はIteratorの連鎖と⾒見見なせる • 問題: 性能への⾼高いオーバヘッド • 繰り返しの仮想関数nextの呼び出し • コンパイラによる最適化の余地が限りなく少ない Volcano-‐‑‒styleの処理理と問題点 実行プラン木のFilterノードの実装例 next next next
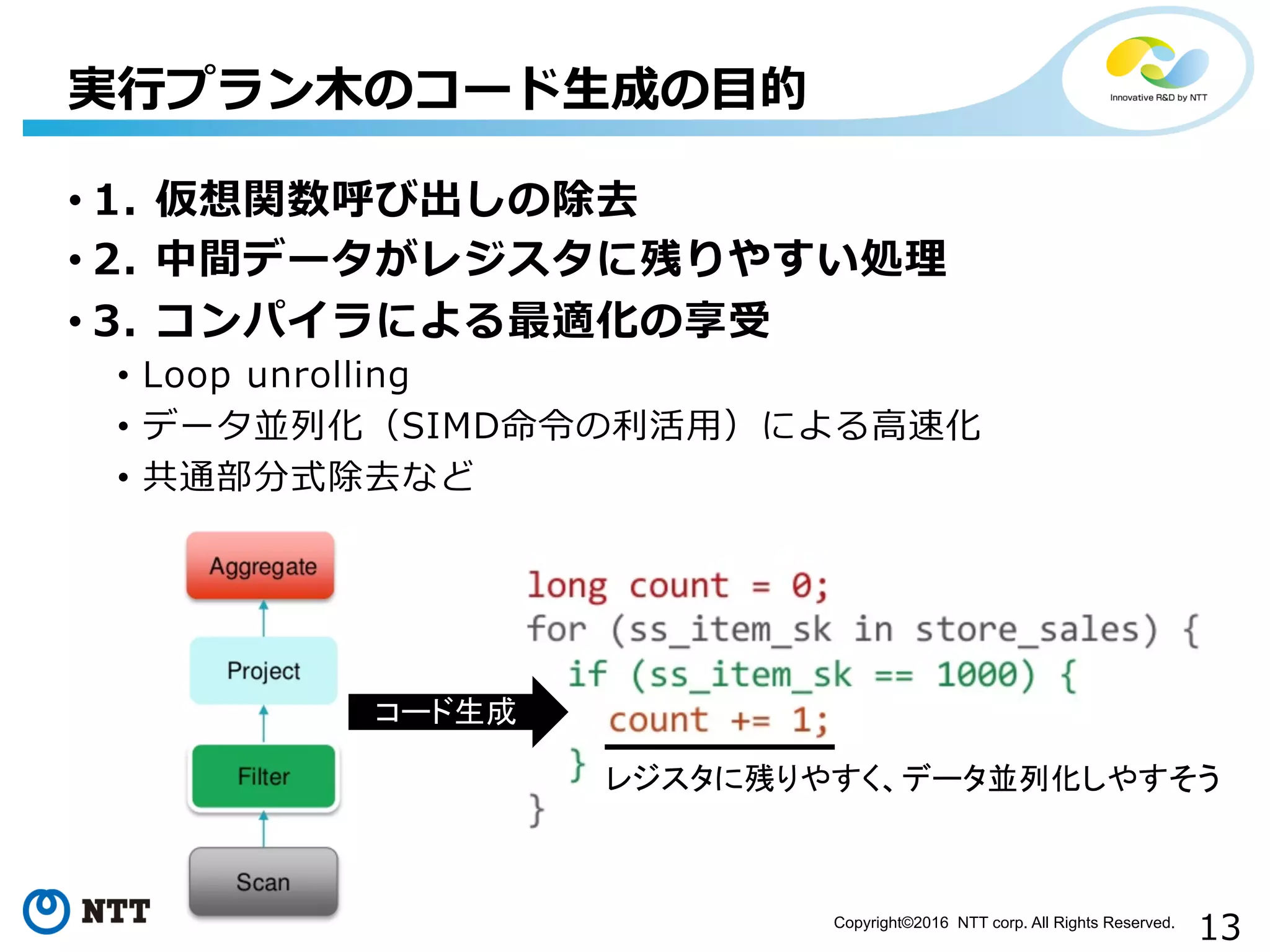
13.
13Copyright©2016 NTT corp.
All Rights Reserved. 実⾏行行プラン⽊木のコード⽣生成の⽬目的 • 1. 仮想関数呼び出しの除去 • 2. 中間データがレジスタに残りやすい処理理 • 3. コンパイラによる最適化の享受 • Loop unrolling • データ並列列化(SIMD命令令の利利活⽤用)による⾼高速化 • 共通部分式除去など レジスタに残りやすく、データ並列化しやすそう コード生成
14.
14Copyright©2016 NTT corp.
All Rights Reserved. • SparkはProduce-‐‑‒Consumeモデル*1に基づいて実装 されたCode Templateベースのコード⽣生成 • コード⽣生成をサポートするプラン⽊木の各ノードにproduceと consumeのIFを実装することでコード⽣生成を実現 • SortやFilterは各ノードが持つCode Templateを⽤用いて、等 価な処理理をjavaのコード(⽂文字列列)として返却 • 部分⽊木から⽣生成されたjavaのコードを軽量量な組み込み コンパイラjanino*2を⽤用いてコンパイル • BufferedRowIteratorというIteratorと同様のIFを持つ抽象ク ラスを派⽣生してコードが⽣生成されるため、コンパイルしてイン スタンス化した後はIteratorとして扱う Sparkにおけるコード⽣生成の実装 *1 Neumann先生の“Efficiently compiling efficient query plans for modern hardware”の論文内で提案(2011) *2 http://janino-compiler.github.io/janino/
15.
15Copyright©2016 NTT corp.
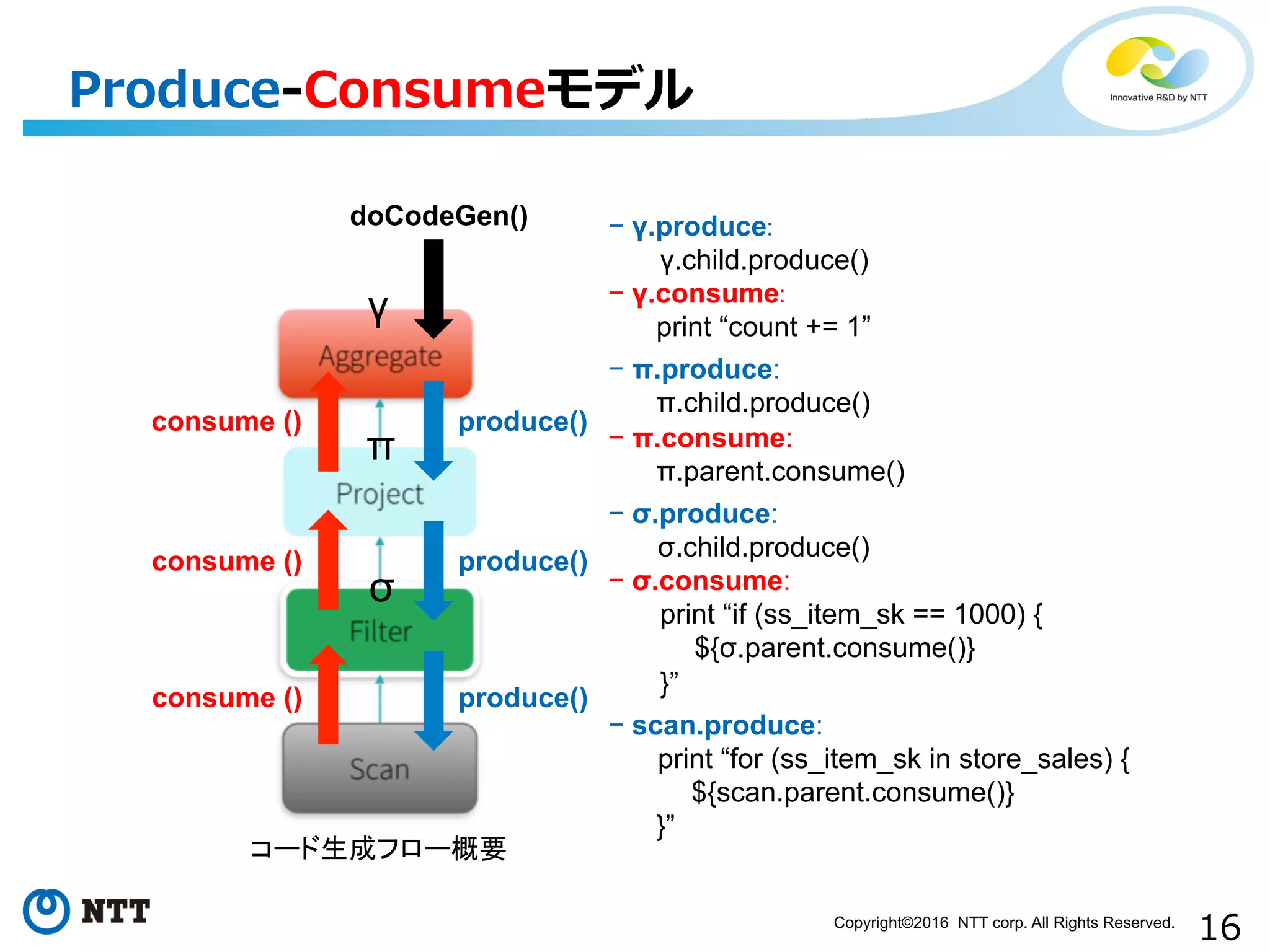
All Rights Reserved. • コード⽣生成をサポートする実⾏行行プラン⽊木の各ノードに以 下を満たすproduceとconsumeを実装 • produce: ⼊入⼒力力レコード⽣生成を依頼(⼦子のproduceを呼ぶ), 部分⽊木の葉葉であれば親のconsumeに⽣生成したレコードを渡す • consume:受け取ったレコードに各ノードの処理理を適⽤用して, 親のconsumeに渡す Produce-‐‑‒Consumeモデル
16.
16Copyright©2016 NTT corp.
All Rights Reserved. Produce-‐‑‒Consumeモデル consume () コード生成フロー概要 consume () consume () produce() produce() produce() doCodeGen() γ π σ - γ.produce: γ.child.produce() - γ.consume: print “count += 1” - π.produce: π.child.produce() - π.consume: π.parent.consume() - σ.produce: σ.child.produce() - σ.consume: print “if (ss_item_sk == 1000) { ${σ.parent.consume()} }” - scan.produce: print “for (ss_item_sk in store_sales) { ${scan.parent.consume()} }”
17.
17Copyright©2016 NTT corp.
All Rights Reserved. • doCodeGen()を呼ぶと以下のコードブロックを⽣生成 Produce-‐‑‒Consumeモデル
18.
18Copyright©2016 NTT corp.
All Rights Reserved. • Sparkの実⾏行行プラン⽊木の各ノードはSparkPlanという 抽象クラスを派⽣生させて実装 • SparkPlanのexecute関数(前述のnext関数相当)の戻り値は RDD[InternalRow*1]で、RDDは各Workerノード上では Iteratorとして表現されている • コード⽣生成をサポートするノードはCodegenSupport というtrait*2をmixinする Sparkのコード⽣生成の実装概要 *1 レコードの内部表現 *2 ここではjava8のinterfaceに近い何かと思ってもらって良い trait CodegenSupport with SparkPlan { ... protected def doProduce(ctx: CodegenContext): String def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = { throw new UnsupportedOperationException } }
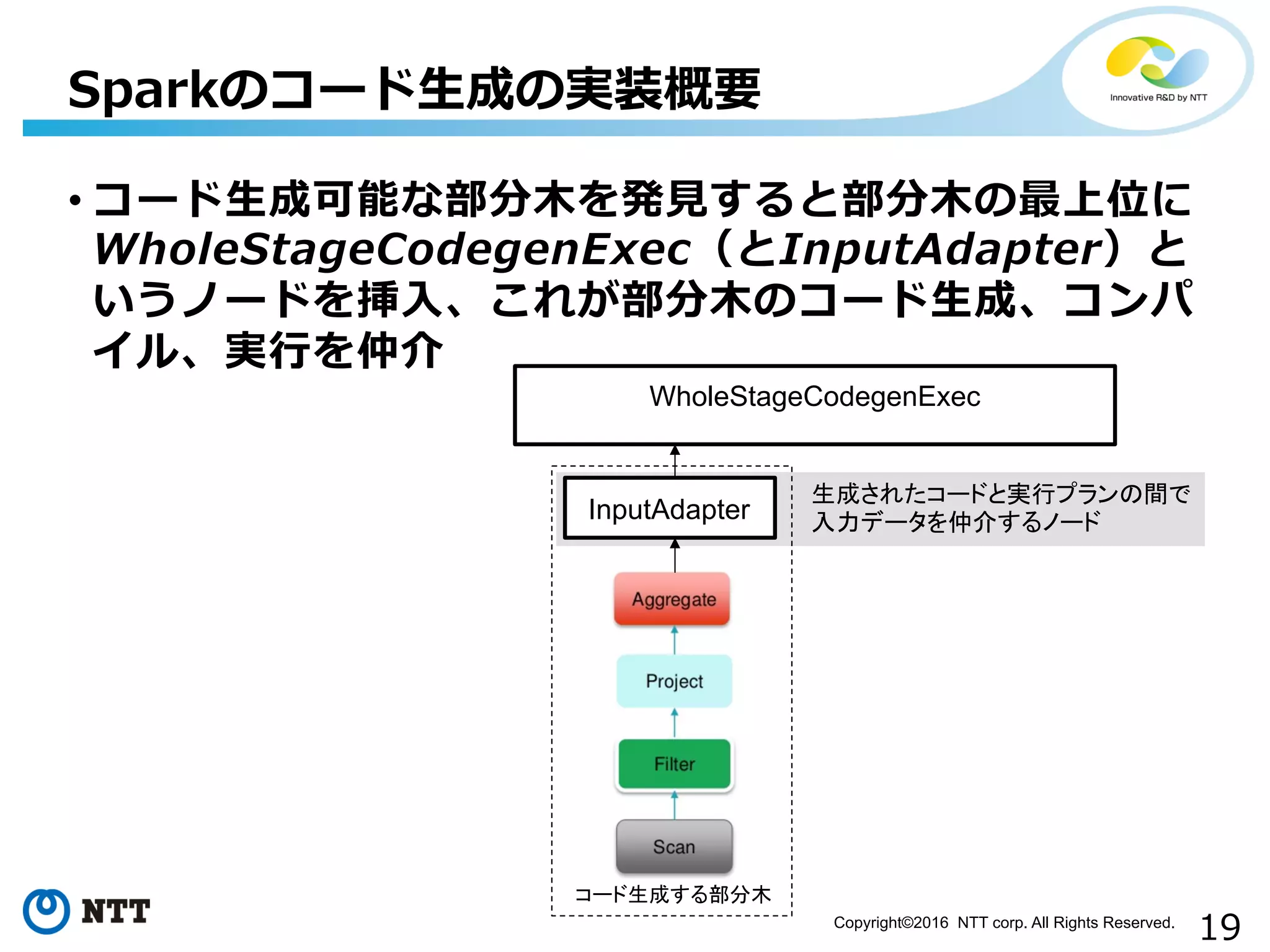
19.
19Copyright©2016 NTT corp.
All Rights Reserved. • コード⽣生成可能な部分⽊木を発⾒見見すると部分⽊木の最上位に WholeStageCodegenExec(とInputAdapter)と いうノードを挿⼊入、これが部分⽊木のコード⽣生成、コンパ イル、実⾏行行を仲介 Sparkのコード⽣生成の実装概要 WholeStageCodegenExec InputAdapter コード生成する部分木 生成されたコードと実行プランの間で 入力データを仲介するノード
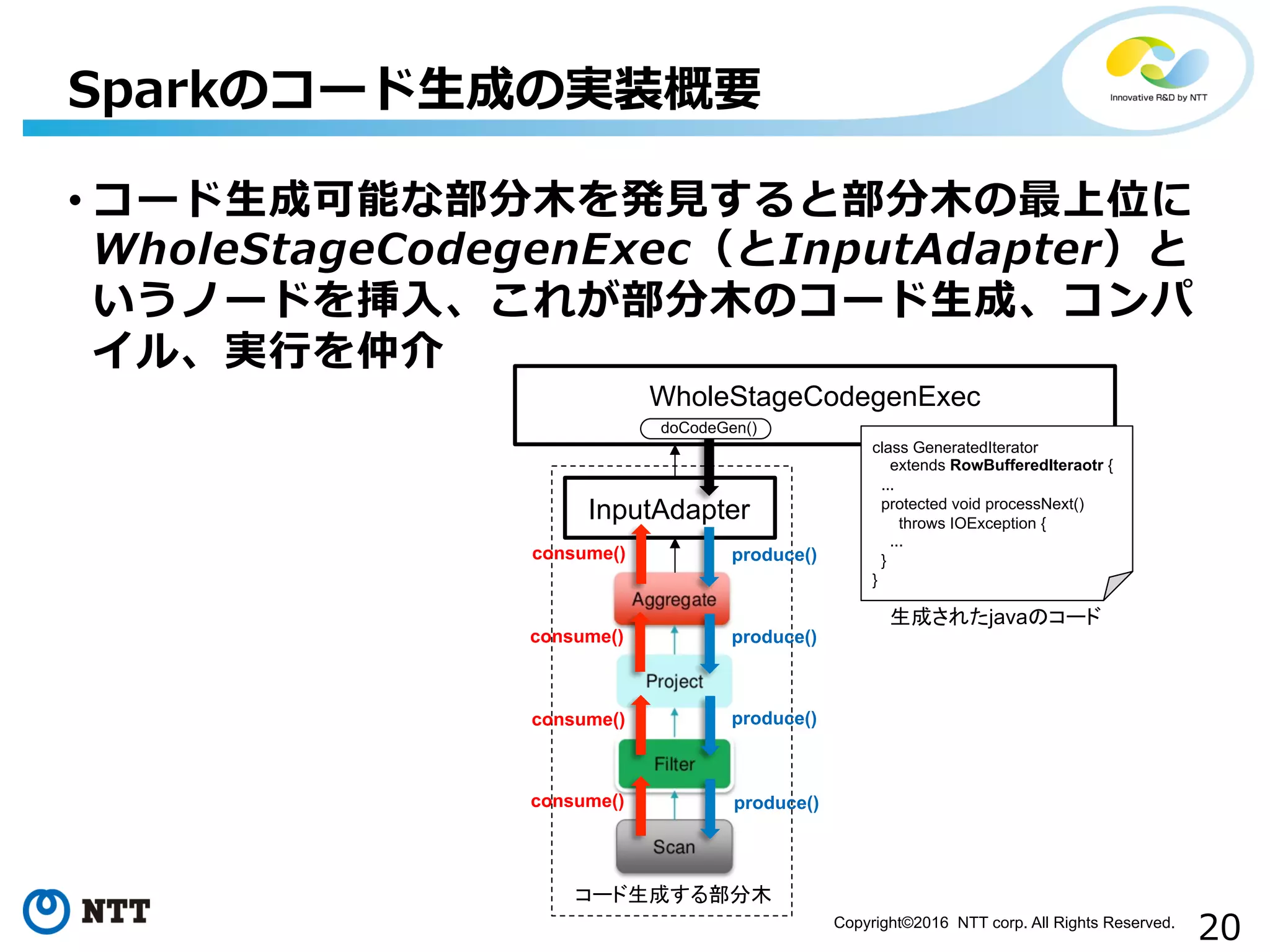
20.
20Copyright©2016 NTT corp.
All Rights Reserved. • コード⽣生成可能な部分⽊木を発⾒見見すると部分⽊木の最上位に WholeStageCodegenExec(とInputAdapter)と いうノードを挿⼊入、これが部分⽊木のコード⽣生成、コンパ イル、実⾏行行を仲介 Sparkのコード⽣生成の実装概要 WholeStageCodegenExec InputAdapter コード生成する部分木 doCodeGen() produce() produce() produce() produce() consume() consume() consume() consume() class GeneratedIterator extends RowBufferedIteraotr { ... protected void processNext() throws IOException { ... } } 生成されたjavaのコード
21.
21Copyright©2016 NTT corp.
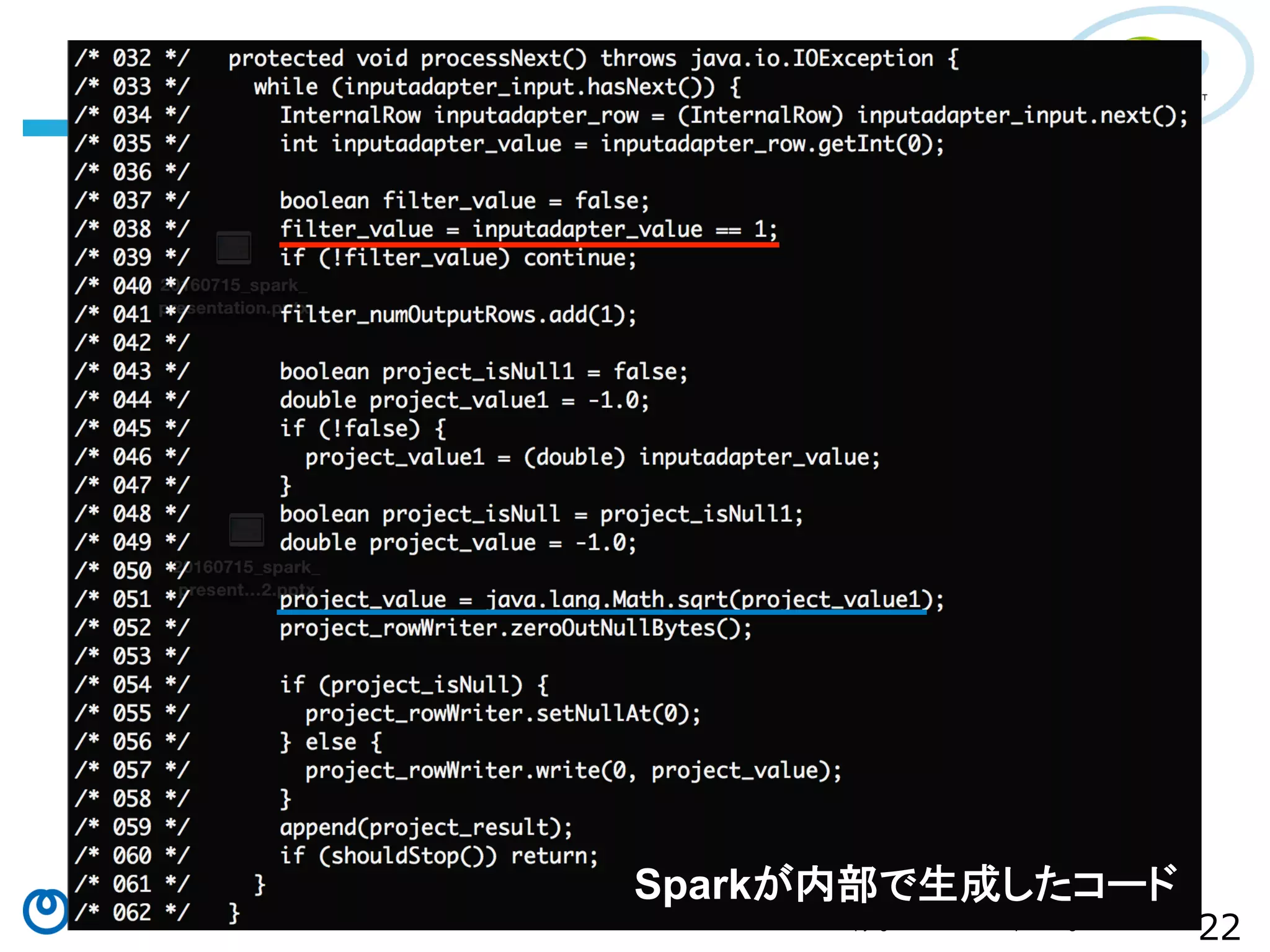
All Rights Reserved. • Sparkの⽣生成したコードを確認 • 各エントリの先頭にʼ’*ʼ’が付いている場合はコード⽣生成による最 適化が適⽤用されていることを⽰示している 具体例例)Sparkのコード⽣生成 scala> import org.apache.spark.sql.execution.debug._ scala> val df = sql("SELECT sqrt(a) FROM test WHERE b = 1”) scala> df.explain == Physical Plan == *Project [SQRT(cast(_1#2 as double)) AS SQRT(CAST(a AS DOUBLE))#18] +- *Filter (_2#3 = 1) +- LocalTableScan [_1#2, _2#3] scala> df.debugCodegen
22.
22Copyright©2016 NTT corp.
All Rights Reserved. Sparkが内部で生成したコード
23.
23Copyright©2016 NTT corp.
All Rights Reserved. • ノードを跨いだコード⽣生成の最適化が困難 • 例例えばAggregateノード→Joinノードという部分⽊木があった場 合に、JoinとAggregateを合成して最適なコードを⽣生成するこ とができれば冗⻑⾧長的な計算(実体化)を除去できる • メンテナンス性が低い • ⾔言わずもがな・・・ • 処理理系に含まれる他のデータ構造を含めたコード⽣生成 (⽊木構造やハッシュ表を含めた展開)が困難 • 現状のSparkでも、集約ノード⾃自体はコード⽣生成しているが集 約処理理に使うハッシュ表の操作はコード⽣生成できていない Code Templateベースのコード⽣生成の⾮非難
24.
24Copyright©2016 NTT corp.
All Rights Reserved. • ⾼高度度な組み込みコンパイラ基盤を活⽤用することでCode Templateベースのコード⽣生成での問題を解決 • Y. Klonatos et al., “Building Efficient Query Engines in a High-‐‑‒Level Language”, VLDB, 2014 • EPFL(スイス連邦⼯工科⼤大)とOracleの共同研究で、2014年年の VLDBのBest Paperの1つ • 実⾏行行プラン⽊木からコードを直接⽣生成するのではなく、よ り最適化できる中間表現を設計することで解決 • A. Shaikhha et al., “How to Architect a Query Compiler”, SIGMOD, 2016 • 上記のEPFLと同じ研究グループによる提案 コード⽣生成のNext Step – 研究動向 contʼ’d
25.
25Copyright©2016 NTT corp.
All Rights Reserved. • グラフ処理理、機械学習、SQLなどの異異なる処理理を統⼀一し て表現出来る中間表現を定め、ランタイム中に複数の異異 なる中間表現を結合&最適化して性能を改善 • S. Palkar et al., “Weld: A Common Runtime for High Performance Data Analytics”, CIDR, 2017 • AuthorのメンバにSpark RDDを提案したMatei⽒氏 コード⽣生成のNext Step – 研究動向
Download



![5Copyright©2016 NTT corp. All Rights Reserved.
• DataFrameはスキーマありの不不変な分散コレクション
• 実際はDataFrame=Dataset[Row]
Spark DataFrame/Dataset
引用: https://databricks.com/blog/
2016/07/14/a-tale-of-three-apache-
spark-apis-rdds-dataframes-and-
datasets.html](https://image.slidesharecdn.com/20161222bdiyamamuro-161223160723/75/Spark-5-2048.jpg)





![18Copyright©2016 NTT corp. All Rights Reserved.
• Sparkの実⾏行行プラン⽊木の各ノードはSparkPlanという
抽象クラスを派⽣生させて実装
• SparkPlanのexecute関数(前述のnext関数相当)の戻り値は
RDD[InternalRow*1]で、RDDは各Workerノード上では
Iteratorとして表現されている
• コード⽣生成をサポートするノードはCodegenSupport
というtrait*2をmixinする
Sparkのコード⽣生成の実装概要
*1 レコードの内部表現
*2 ここではjava8のinterfaceに近い何かと思ってもらって良い
trait CodegenSupport with SparkPlan {
...
protected def doProduce(ctx: CodegenContext): String
def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
throw new UnsupportedOperationException
}
}](https://image.slidesharecdn.com/20161222bdiyamamuro-161223160723/75/Spark-18-2048.jpg)
![21Copyright©2016 NTT corp. All Rights Reserved.
• Sparkの⽣生成したコードを確認
• 各エントリの先頭にʼ’*ʼ’が付いている場合はコード⽣生成による最
適化が適⽤用されていることを⽰示している
具体例例)Sparkのコード⽣生成
scala> import org.apache.spark.sql.execution.debug._
scala> val df = sql("SELECT sqrt(a) FROM test WHERE b = 1”)
scala> df.explain
== Physical Plan ==
*Project [SQRT(cast(_1#2 as double)) AS SQRT(CAST(a AS DOUBLE))#18]
+- *Filter (_2#3 = 1)
+- LocalTableScan [_1#2, _2#3]
scala> df.debugCodegen](https://image.slidesharecdn.com/20161222bdiyamamuro-161223160723/75/Spark-21-2048.jpg)











































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)
































