Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
TY
Uploaded by
Tanaka Yuichi
PPTX, PDF
2,756 views
Apache Sparkを使った感情極性分析
Sparkの概要とSparkを使った感情極性分析のサンプルの紹介です。
Technology
◦
Related topics:
Apache Spark
•
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 85 times
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PPTX
SparkとJupyterNotebookを使った分析処理 [Html5 conference]
by
Tanaka Yuichi
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
PPTX
Bluemixを使ったTwitter分析
by
Tanaka Yuichi
PPTX
Watson summit 2016_j2_5
by
Tanaka Yuichi
PPTX
Big datauniversity
by
Tanaka Yuichi
PPTX
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ
by
Tanaka Yuichi
PPTX
PythonでDeepLearningを始めるよ
by
Tanaka Yuichi
PPTX
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
SparkとJupyterNotebookを使った分析処理 [Html5 conference]
by
Tanaka Yuichi
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
Bluemixを使ったTwitter分析
by
Tanaka Yuichi
Watson summit 2016_j2_5
by
Tanaka Yuichi
Big datauniversity
by
Tanaka Yuichi
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ
by
Tanaka Yuichi
PythonでDeepLearningを始めるよ
by
Tanaka Yuichi
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
What's hot
PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
PPTX
Pysparkで始めるデータ分析
by
Tanaka Yuichi
PPTX
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
PPTX
Jjug ccc
by
Tanaka Yuichi
PDF
Apache Sparkの紹介
by
Ryuji Tamagawa
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
by
Kazutaka Tomita
PDF
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
PPTX
Spark GraphX で始めるグラフ解析
by
Yosuke Mizutani
PDF
本当にあったApache Spark障害の話
by
x1 ichi
PDF
データ分析に必要なスキルをつけるためのツール~Jupyter notebook、r連携、機械学習からsparkまで~
by
The Japan DataScientist Society
PDF
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
PDF
Spark Summit 2015 参加報告
by
Katsunori Kanda
PDF
SparkとCassandraの美味しい関係
by
datastaxjp
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
PDF
SparkやBigQueryなどを用いた モバイルゲーム分析環境
by
yuichi_komatsu
PDF
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」
by
Kazuki Taniguchi
PDF
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
Pysparkで始めるデータ分析
by
Tanaka Yuichi
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
Jjug ccc
by
Tanaka Yuichi
Apache Sparkの紹介
by
Ryuji Tamagawa
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
by
Kazutaka Tomita
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
Spark GraphX で始めるグラフ解析
by
Yosuke Mizutani
本当にあったApache Spark障害の話
by
x1 ichi
データ分析に必要なスキルをつけるためのツール~Jupyter notebook、r連携、機械学習からsparkまで~
by
The Japan DataScientist Society
15.05.21_ビッグデータ分析基盤Sparkの最新動向とその活用-Spark SUMMIT EAST 2015-
by
LINE Corp.
Spark Summit 2015 参加報告
by
Katsunori Kanda
SparkとCassandraの美味しい関係
by
datastaxjp
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
SparkやBigQueryなどを用いた モバイルゲーム分析環境
by
yuichi_komatsu
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」
by
Kazuki Taniguchi
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Viewers also liked
PPTX
ジャンク解析入門
by
Akira Kaneda
PPTX
Akkaを使った スケーラブルなLINE BOT
by
Takashi Sugimoto
PPTX
「Python 機械学習プログラミング」 の挫折しない読み方
by
Hiroki Yamamoto
PPTX
アメーバブログを支えるデータセンターとインフラ技術
by
Hiroki NAKASHIMA
PDF
マイクロブログを用いた英語圏ユーザの日本食に対する印象の分析
by
恵佑 三富
PDF
[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...
by
Insight Technology, Inc.
PDF
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
PPTX
Prefer Cloud Platform - ビジョン、アーキテクチャ
by
Tomoharu ASAMI
PDF
Sparkストリーミング検証
by
BrainPad Inc.
PDF
5分でわかる静的解析入門
by
Kenta USAMI
PDF
Spark Streaming と Spark GraphX を使用したTwitter解析による レコメンドサービス例
by
Junichi Noda
PDF
Sparkで始めるお手軽グラフデータ分析
by
Nagato Kasaki
PPTX
Scalaで学ぶ関数型言語超入門
by
yujiro_t
PDF
線形?非線形?
by
nishio
PDF
DeNAのAIとは #denatechcon
by
DeNA
PDF
Phantom Type in Scala
by
Yasuyuki Maeda
PDF
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
PDF
Spark MLlibではじめるスケーラブルな機械学習
by
NTT DATA OSS Professional Services
PDF
(旧版) オープンソースライセンスの基礎と実務
by
Yutaka Kachi
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
ジャンク解析入門
by
Akira Kaneda
Akkaを使った スケーラブルなLINE BOT
by
Takashi Sugimoto
「Python 機械学習プログラミング」 の挫折しない読み方
by
Hiroki Yamamoto
アメーバブログを支えるデータセンターとインフラ技術
by
Hiroki NAKASHIMA
マイクロブログを用いた英語圏ユーザの日本食に対する印象の分析
by
恵佑 三富
[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...
by
Insight Technology, Inc.
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
Prefer Cloud Platform - ビジョン、アーキテクチャ
by
Tomoharu ASAMI
Sparkストリーミング検証
by
BrainPad Inc.
5分でわかる静的解析入門
by
Kenta USAMI
Spark Streaming と Spark GraphX を使用したTwitter解析による レコメンドサービス例
by
Junichi Noda
Sparkで始めるお手軽グラフデータ分析
by
Nagato Kasaki
Scalaで学ぶ関数型言語超入門
by
yujiro_t
線形?非線形?
by
nishio
DeNAのAIとは #denatechcon
by
DeNA
Phantom Type in Scala
by
Yasuyuki Maeda
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
Spark MLlibではじめるスケーラブルな機械学習
by
NTT DATA OSS Professional Services
(旧版) オープンソースライセンスの基礎と実務
by
Yutaka Kachi
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Similar to Apache Sparkを使った感情極性分析
PDF
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料
by
Atsushi Tsuchiya
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Sparkについて
by
BrainPad Inc.
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PDF
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PPTX
2014 11-20 Machine Learning with Apache Spark 勉強会資料
by
Recruit Technologies
PDF
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
PDF
Apache Sparkやってみたところ
by
Tatsunori Nishikori
PDF
HivemallとSpark MLlibの比較
by
Makoto Yui
PDF
Apache spark 2.3 and beyond
by
NTT DATA Technology & Innovation
PPTX
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ
by
Holden Karau
PDF
SparkMLlibで始めるビッグデータを対象とした機械学習入門
by
Takeshi Mikami
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PPTX
2015 03-12 道玄坂LT祭り第2回 Spark DataFrame Introduction
by
Yu Ishikawa
Big Data University Tokyo Meetup #6 (mlwith_spark) 配布資料
by
Atsushi Tsuchiya
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Sparkについて
by
BrainPad Inc.
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Yifeng spark-final-public
by
Yifeng Jiang
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
2014 11-20 Machine Learning with Apache Spark 勉強会資料
by
Recruit Technologies
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
Apache Sparkやってみたところ
by
Tatsunori Nishikori
HivemallとSpark MLlibの比較
by
Makoto Yui
Apache spark 2.3 and beyond
by
NTT DATA Technology & Innovation
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ
by
Holden Karau
SparkMLlibで始めるビッグデータを対象とした機械学習入門
by
Takeshi Mikami
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
2015 03-12 道玄坂LT祭り第2回 Spark DataFrame Introduction
by
Yu Ishikawa
Apache Sparkを使った感情極性分析
1.
© 2016 IBM
Corporation Apache Spark入門 Tanaka Y.P 2016-08-26
2.
© 2016 IBM
Corporation2 自己紹介 田中裕一(yuichi tanaka) 主にアーキテクチャとサーバーサイドプログラムを担当 することが多い。Hadoop/Spark周りをよく触ります。 Node.js、Python、最近はSpark周りの仕事でScalaを書く ことが多い気がします。 休日はOSS周りで遊んだり。 詳解 Apache Spark
3.
© 2016 IBM
Corporation3 アジェンダ Sparkの概要 Sparkのテクノロジースタック SparkとHadoop Sparkコンポーネント Spark Core SparkSQL DataFrame SparkStreaming MLlib GraphX DataSets 本日のサンプル(感情極性分析) Notebook
4.
© 2016 IBM
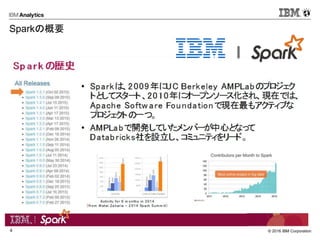
Corporation4 Sparkの概要
5.
© 2016 IBM
Corporation5 DataFrames Sparkのテクノロジースタック Spark Core SparkSQL Spark Streaming GraphX MLlib HDFS Cassandra HBase ・・・ Packages
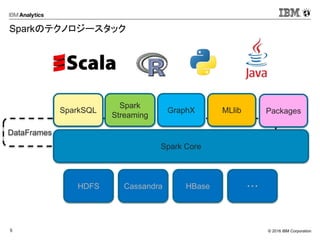
6.
© 2016 IBM
Corporation6 Apache SparkとHadoop HadoopでのMapReduceの処理例
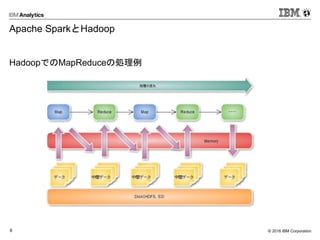
7.
© 2016 IBM
Corporation7 Apache Sparkの処理概要 SparkでのRDD&DAGの処理例
8.
© 2016 IBM
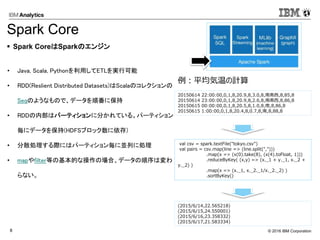
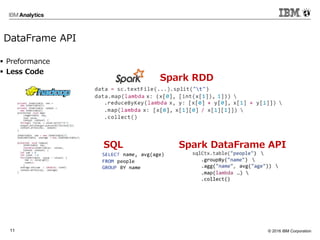
Corporation8 • Java, Scala, Pythonを利用してETLを実行可能 • RDD(Reslient Distributed Datasets)はScalaのコレクションの Seqのようなもので、データを順番に保持 • RDDの内部はパーティションに分かれている。パーティション 毎にデータを保持(HDFSブロック数に依存) • 分散処理する際にはパーティション毎に並列に処理 • mapやfilter等の基本的な操作の場合、データの順序は変わ らない。 val csv = spark.textFile("tokyo.csv") val pairs = csv.map(line => (line.split(","))) .map(x => (x(0).take(8), (x(4).toFloat, 1))) .reduceByKey( (x,y) => (x._1 + y._1, x._2 + y._2) ) .map(x => (x._1, x._2._1/x._2._2) ) .sortByKey() Spark CoreはSparkのエンジン Spark Core 20150614 22:00:00,0,1,8,20.9,8,3.0,8,南南西,8,85,8 20150614 23:00:00,0,1,8,20.9,8,2.6,8,南南西,8,86,8 20150615 00:00:00,0,1,8,20.5,8,1.0,8,南,8,86,8 20150615 1:00:00,0,1,8,20.4,8,0.7,8,南,8,88,8 (2015/6/14,22.565218) (2015/6/15,24.550001) (2015/6/16,23.358332) (2015/6/17,21.583334) 例:平均気温の計算
9.
© 2016 IBM
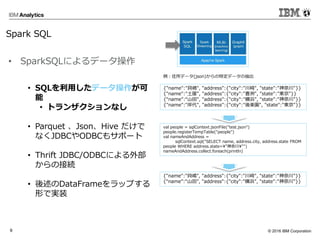
Corporation9 • SQLを利用したデータ操作が可 能 • トランザクションなし • Parquet 、Json、Hive だけで なくJDBCやODBCもサポート • Thrift JDBC/ODBCによる外部 からの接続 • 後述のDataFrameをラップする 形で実装 {"name":"貝嶋", "address":{"city":"川崎", "state":"神奈川"}} {"name":"土屋", "address":{"city":"豊洲", "state":"東京"}} {“name”:“山田", "address":{"city":"横浜", "state":"神奈川"}} {"name":"岸代", "address":{"city":"後楽園", "state":"東京"}} val people = sqlContext.jsonFile("test.json") people.registerTempTable("people") val nameAndAddress = sqlContext.sql("SELECT name, address.city, address.state FROM people WHERE address.state="神奈川"") nameAndAddress.collect.foreach(println) {"name":"貝嶋", "address":{"city":"川崎", "state":"神奈川"}} {“name”:“山田", "address":{"city":"横浜", "state":"神奈川"}} 例:住所データ(json)からの特定データの抽出 • SparkSQLによるデータ操作 Spark SQL
10.
© 2016 IBM
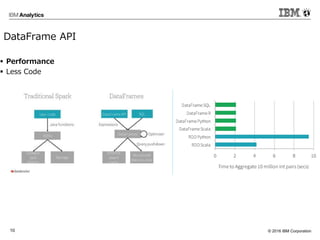
Corporation10 DataFrame API Performance Less Code
11.
© 2016 IBM
Corporation11 DataFrame API Preformance Less Code SQL Spark DataFrame API Spark RDD
12.
© 2016 IBM
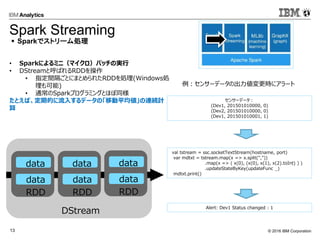
Corporation13 • Sparkによるミニ(マイクロ)バッチの実行 • DStreamと呼ばれるRDDを操作 • 指定間隔ごとにまとめられたRDDを処理(Windows処 理も可能) • 通常のSparkプログラミングとほぼ同様 たとえば、定期的に流入するデータの「移動平均値」の連続計 算 val tstream = ssc.socketTextStream(hostname, port) var mdtxt = tstream.map(x => x.split(",")) .map(x => ( x(0), (x(0), x(1), x(2).toInt) ) ) .updateStateByKey(updateFunc _) mdtxt.print() センサーデータ: (Dev1, 201501010000, 0) (Dev2, 201501010000, 0) (Dev1, 201501010001, 1) Alert: Dev1 Status changed : 1 Sparkでストリーム処理 Spark Streaming 例:センサーデータの出力値変更時にアラート DStream RDD data data RDD data data RDD data data
13.
© 2016 IBM
Corporation14 • MLlibとRが利用可能 MLlibはScalaで、SparkRはRで 記述可能 • アルゴリズム(MLlib) • SVM、ロジスティック回帰、決定木、K- means、ALSなど • IBMはSystemMLをSparkに提供 val data = spark.textFile("kdata.txt") val parsedData = data.map(x => Vectors.dense(x.split(',').map(_.toDouble))).cache() val numClusters = 3 val numIterations = 10 val clusters = KMeans.train(parsedData, numClusters, numIterations) Sparkで機械学習 SparkR, Mllib データ: ( 直近購買月[n日前], 期間内購買回数 ) (5,1),(4,2),(5,3),(1,2),(2,4),(2,5),(2,6),(1,4),(1,5),(1,2),(1,5),(5,5) クラスタ結果: ([中心], 人数) ([1.0, 2.0], 2), ([1.5, 4.833333333333333], 6), ([4.666666666666666, 2.0], 3), ([5.0, 5.0], 1) 例:顧客のクラスタ分け 0 2 4 6 0 2 4 6
14.
© 2016 IBM
Corporation15 • グラフデータを並列分散環境で処理するための フレームワーク • グラフ構造データを用いた解析を行う • 「点」と「辺」からなるデータ • SNSでのつながり、データ間の関連性 など • 表構造では扱うことが難しい関係を見つけ出す • データ間のつながりの抽出 • 輪の抽出 • 距離の計測 • 影響の計測 • グラフDBとの兼ね合い(これから) val graphWithDistance = Pregel( graph.mapVertices((id:VertexId, attr:Int) => List((id, 0))), List[(VertexId, Int)](), Int.MaxValue,EdgeDirection.Out)((id, attr, msg) => mergeVertexRoute(attr, msg.map(a=> (a._1, a._2 + 1))),edge => { val isCyclic = edge.srcAttr.filter(_._1 == edge.dstId).nonEmpty if(isCyclic) Iterator.empty else Iterator((edge.dstId, edge.srcAttr)) },(m1, m2) => m1 ++ m2 ) Sparkでグラフ処理を Spark GraphX つながりの検索 例: つながりと距離を見つけ出す 1,((1,0), (6,1), (9,1), (7,1), (4,2)) 1 2 3 4 5 6 7 89
15.
© 2016 IBM
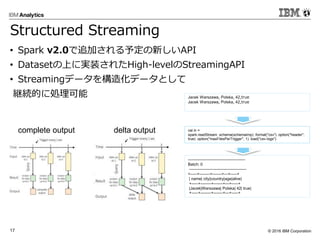
Corporation16 DataSet API • Spark v1.6で追加された新しいAPI • まだ実験的な実装であることに注意 • 登場背景 • RDDとDataFrameという二つの抽象概念ができてしまった。 • RDDとDataFrameにそれぞれ長所があること • 2つの抽象概念を行き来する為のコストがかかる • 二つの抽象概念をいいとこ取りしたDataSetAPIの登場 • DataFrameの速さはそのまま • オブジェクト・メソッドはコンパイル時のタイプセーフ提供 • DataFrameとのシームレス変換
16.
© 2016 IBM
Corporation17 Structured Streaming • Spark v2.0で追加される予定の新しいAPI • Datasetの上に実装されたHigh-levelのStreamingAPI • Streamingデータを構造化データとして 継続的に処理可能 val in = spark.readStream .schema(schemaImp) .format("csv") .option("header", true) .option("maxFilesPerTrigger", 1) .load("csv-logs") Jacek Warszawa, Polska, 42,true Jacek Warszawa, Polska, 42,true ------------------------------------------- Batch: 0 ------------------------------------------- +-----+--------+-------+---+-----+ | name| city|country|age|alive| +-----+--------+-------+---+-----+ |Jacek|Warszawa| Polska| 42| true| +-----+--------+-------+---+-----+ complete output delta output
17.
© 2016 IBM
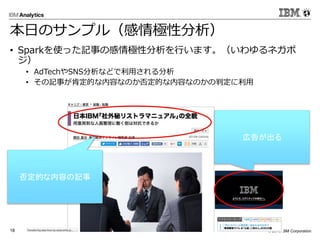
Corporation18 本日のサンプル(感情極性分析) • Sparkを使った記事の感情極性分析を行います。(いわゆるネガポ ジ) • AdTechやSNS分析などで利用される分析 • その記事が肯定的な内容なのか否定的な内容なのかの判定に利用 否定的な内容の記事 広告が出る
18.
© 2016 IBM
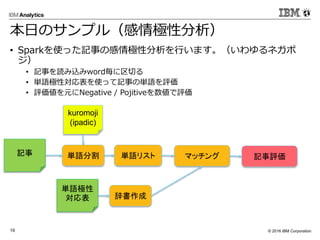
Corporation19 本日のサンプル(感情極性分析) • Sparkを使った記事の感情極性分析を行います。(いわゆるネガポ ジ) • 記事を読み込みword毎に区切る • 単語極性対応表を使って記事の単語を評価 • 評価値を元にNegative / Pojitiveを数値で評価 記事 単語極性 対応表 単語分割 kuromoji (ipadic) 辞書作成 マッチング 記事評価単語リスト
19.
© 2016 IBM
Corporation20 本日のサンプル(感情極性分析) • 記事 • 記事タイトル,本文,メディアのCSV • サンプル記事 • 飲酒運転、検挙数5分の1に減 「悪質」の割合は高まる • 領海侵入の沈静化要求=岸田氏「首脳会談の前提」―日中外相会談 • 国交省、休日のダム見学、ツアーを実施することを発表 内部の一般開放も推進 • 過去最多メダル獲得 リオ五輪日本選手団の解団式 • 辞書 • 単語¥t極性値t用法 • サンプルデータ • 貪欲 n 〜である・になる(評価・感情)主観 • 絆 p 〜がある・高まる(存在・性質) • 腕前 e 〜がある・高まる(存在・性質) • 腕利き p 〜である・になる(評価・感情)主観
20.
© 2016 IBM
Corporation21 参考 • 辞書 • 日本語評価極性辞書 • 東山昌彦, 乾健太郎, 松本裕治, 述語の選択選好性に着目した名詞評価極性の獲得, 言語処理学会第14 回年次大会論文集, pp.584-587, 2008. / Masahiko Higashiyama, Kentaro Inui, Yuji Matsumoto. Learning Sentiment of Nouns from Selectional Preferences of Verbs and Adjectives, Proceedings of the 14th Annual Meeting of the Association for Natural Language Processing, pp.584-587, 2008.
Editor's Notes
#2
1
#3
会社ではSparkとHadoopのスペシャリストやってます。
#6
Apache Sparkの概要を簡単におさらいします。 SparkはSparkCoreモジュールとそれを利用したSparkSQL,GraphX,Streaming,Mllibからなります。 SparkCore:RDDを始めとる、メモリ管理やタスクスケジューリングなどの機能を提供するコンポーネント SparkSQL:構造化データを操作するため、SQLのインタフェースを提供するコンポーネント GraphX:グラフ演算処理を行い、グラフ操作するための機能を提供するコンポーネント Spark Streaming:ストリーミングデータの処理を提供するコンポーネント、RDDの拡張であるDStreamを用いてRDDと似た操作が可能 MLlib: 分類、推薦、クラスタリングなどの機械学習アルゴリズムを提供するコンポーネント
#7
MapReduceと比較してオンメモリでの分散処理に特化しています。 まずはMapReduceを用いてデータ処理を行った場合の処理例です。 MapReduceがスループットを重視し、バッチ処理に特化しているのに対して、 Sparkはレイテンシを重視し、インタラクティブにデータ分析が可能となっています。
#8
次にSparkのRDD&DAGの場合の処理例です。 後ほど出てきますが、SparkはSparkSQLを使うことでRDBの直接参照が可能です。 MapReduceがスループットを重視し、バッチ処理に特化しているのに対して、 Sparkはレイテンシを重視し、メモリ上で操作を行うことで、インタラクティブにデータ分析が可能となっています。
#10
そこでRDBMSと同様なSQLを用いてRDDの操作を行うのがSparkSQLです。
#11
DataFrameAPIを使うメリットとしては2つ Performance(catalystオプティマイザによる処理の最適化) Less Code(より簡素なコード)
#13
Catalystの主な役割は論理最適化と物理実行計画の最適化を行う Analysis:DataFrameの分析 Logical Optimization: 主に処理順序の最適化 Physical Planning: 幾つかの計画を実行コストで比較し、コストの低いものを選択 Code Generation: RDDの処理を生成
#17
RDDとDataFrameの相互変換は可能 RDDはJVMオブジェクトである為コンパイル時のタイプセーフ(DataFrameはタイプセーフにならない) RDDで書くほうが処理ロジックは容易 基本的に速い対してDataFrameは メモリアカウンティングをやってくれる などそれぞれメリットがある
Download




![© 2016 IBM Corporation14
• MLlibとRが利用可能
MLlibはScalaで、SparkRはRで
記述可能
• アルゴリズム(MLlib)
• SVM、ロジスティック回帰、決定木、K-
means、ALSなど
• IBMはSystemMLをSparkに提供
val data = spark.textFile("kdata.txt")
val parsedData = data.map(x =>
Vectors.dense(x.split(',').map(_.toDouble))).cache()
val numClusters = 3
val numIterations = 10
val clusters = KMeans.train(parsedData, numClusters, numIterations)
Sparkで機械学習
SparkR, Mllib
データ: ( 直近購買月[n日前], 期間内購買回数 )
(5,1),(4,2),(5,3),(1,2),(2,4),(2,5),(2,6),(1,4),(1,5),(1,2),(1,5),(5,5)
クラスタ結果: ([中心], 人数)
([1.0, 2.0], 2), ([1.5, 4.833333333333333], 6),
([4.666666666666666, 2.0], 3), ([5.0, 5.0], 1)
例:顧客のクラスタ分け
0
2
4
6
0 2 4 6](https://image.slidesharecdn.com/bigdatauniversity-160826083222/85/Apache-Spark-13-320.jpg)
![© 2016 IBM Corporation15
• グラフデータを並列分散環境で処理するための
フレームワーク
• グラフ構造データを用いた解析を行う
• 「点」と「辺」からなるデータ
• SNSでのつながり、データ間の関連性
など
• 表構造では扱うことが難しい関係を見つけ出す
• データ間のつながりの抽出
• 輪の抽出
• 距離の計測
• 影響の計測
• グラフDBとの兼ね合い(これから)
val graphWithDistance = Pregel(
graph.mapVertices((id:VertexId, attr:Int) => List((id, 0))),
List[(VertexId, Int)](),
Int.MaxValue,EdgeDirection.Out)((id, attr, msg) =>
mergeVertexRoute(attr, msg.map(a=> (a._1, a._2 + 1))),edge
=> {
val isCyclic = edge.srcAttr.filter(_._1 ==
edge.dstId).nonEmpty
if(isCyclic) Iterator.empty
else Iterator((edge.dstId, edge.srcAttr))
},(m1, m2) => m1 ++ m2
)
Sparkでグラフ処理を
Spark GraphX
つながりの検索
例: つながりと距離を見つけ出す
1,((1,0), (6,1), (9,1), (7,1), (4,2))
1
2 3
4
5
6
7
89](https://image.slidesharecdn.com/bigdatauniversity-160826083222/85/Apache-Spark-14-320.jpg)



![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[db tech showcase Tokyo 2016] D27: Next Generation Apache Cassandra by ヤフー株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/6g0l8lpr6eqa08bnwkta-signature-9b274dcdb85a5eaa42259455c2cec526dc34c97173e0294f27c0fdabde43af57-poli-160719060716-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)








