リクルートテクノロジーズの立位置
Infrastructure
/Security
Big Data Solutions
TechnologyR&D
Systems
Development
Recruit
Holdings
Recruit Career
Recruit Sumai Company
Recruit Lifestyle
Recruit Jobs
Recruit Staffing
Recruit Marketing Partners
Staff service Holdings
Recruit Administration
Recruit Communications
Business/
Service
Function/
Support
Project
Management
UXD/SEO
Internet Marketing
Recruit Technologies












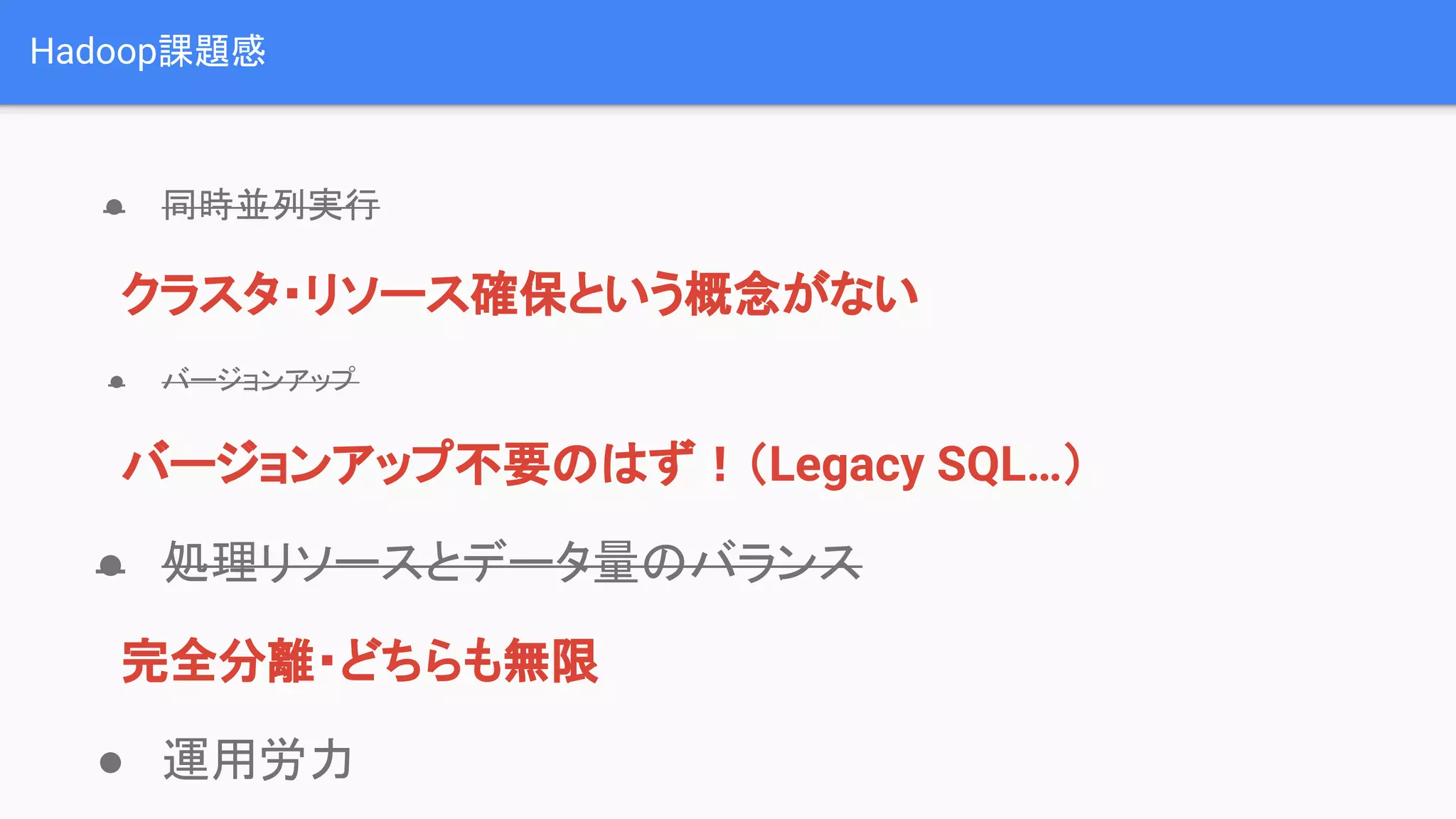

























![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)


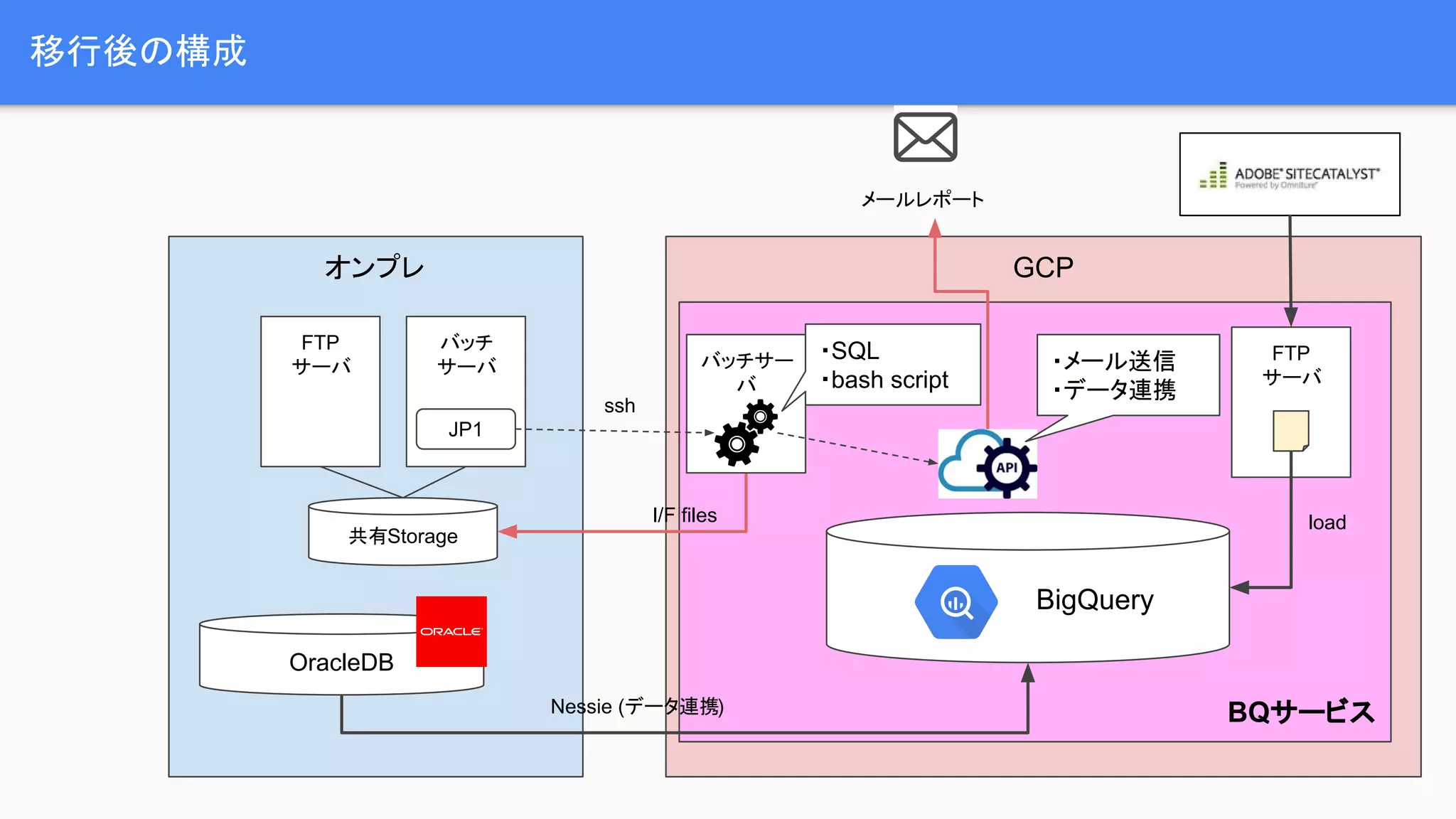
![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)
































































