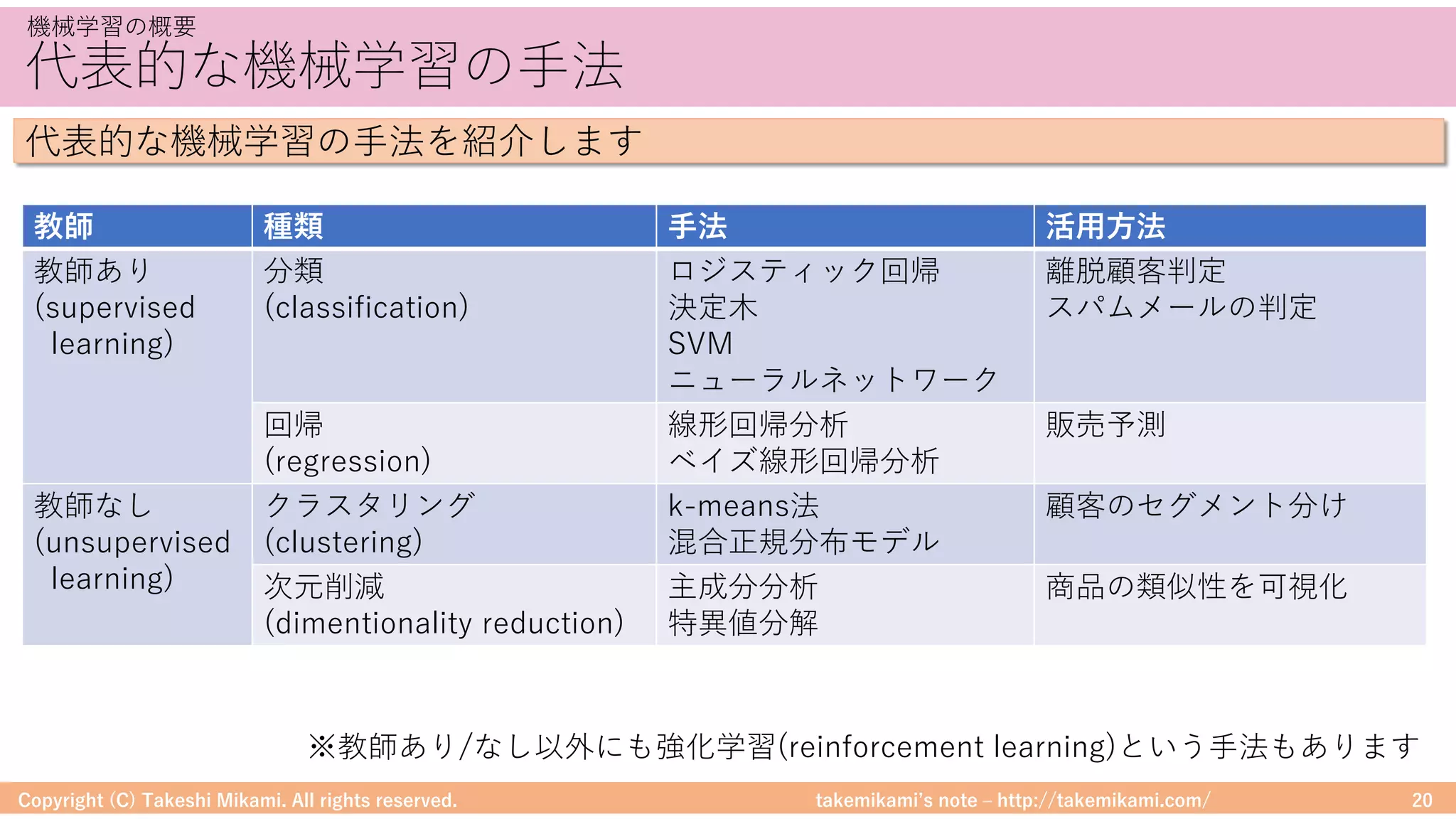
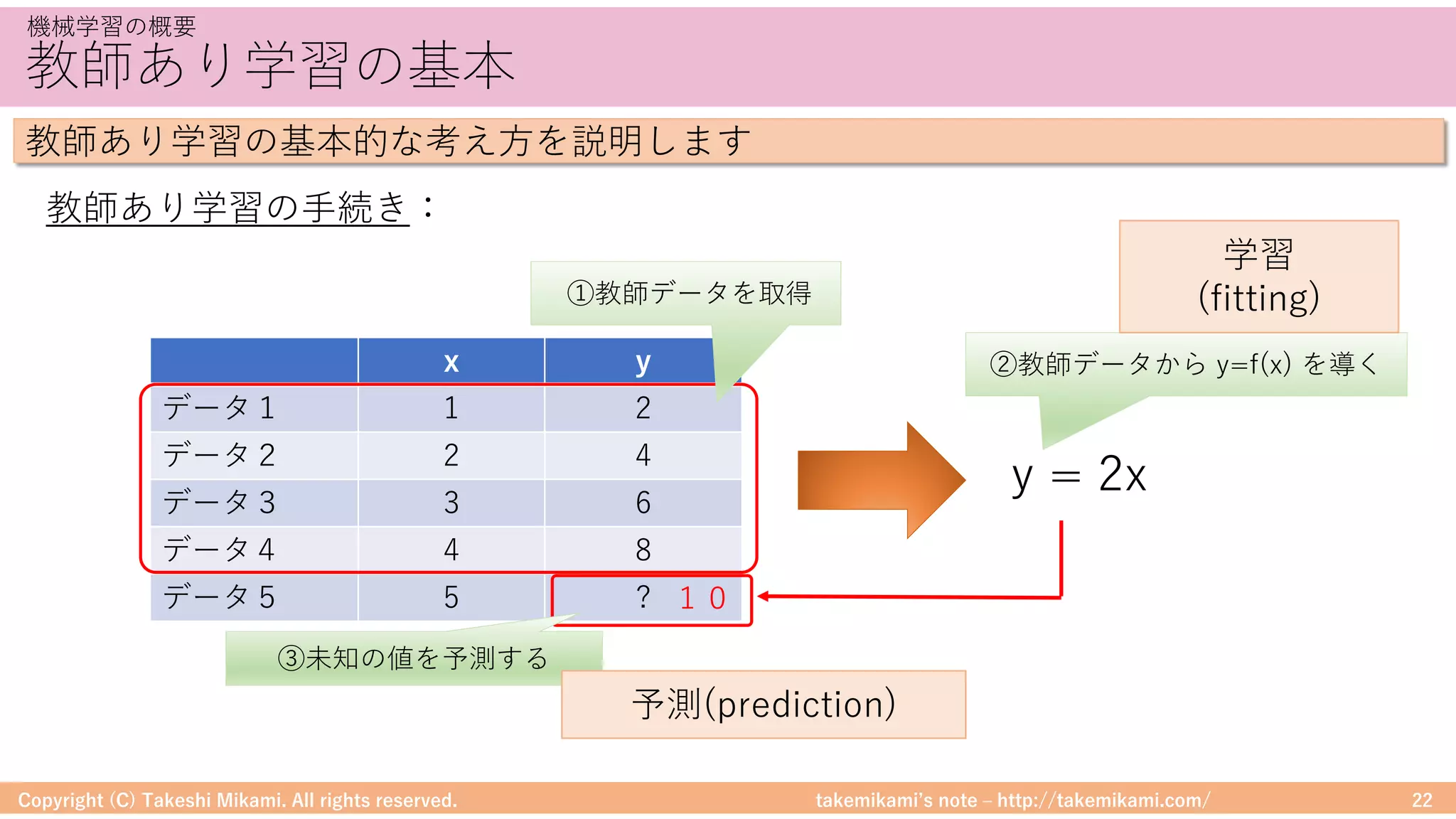
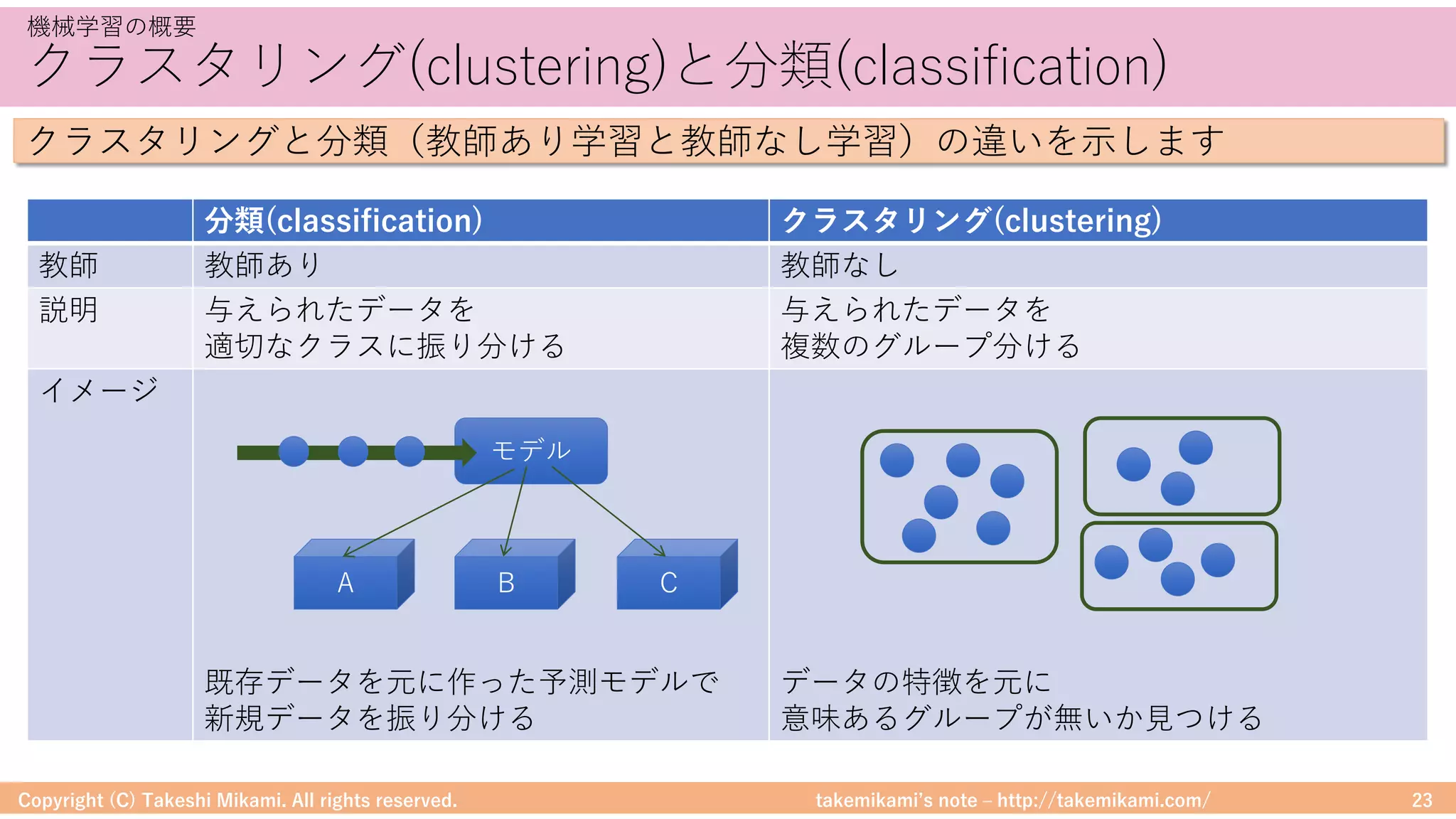
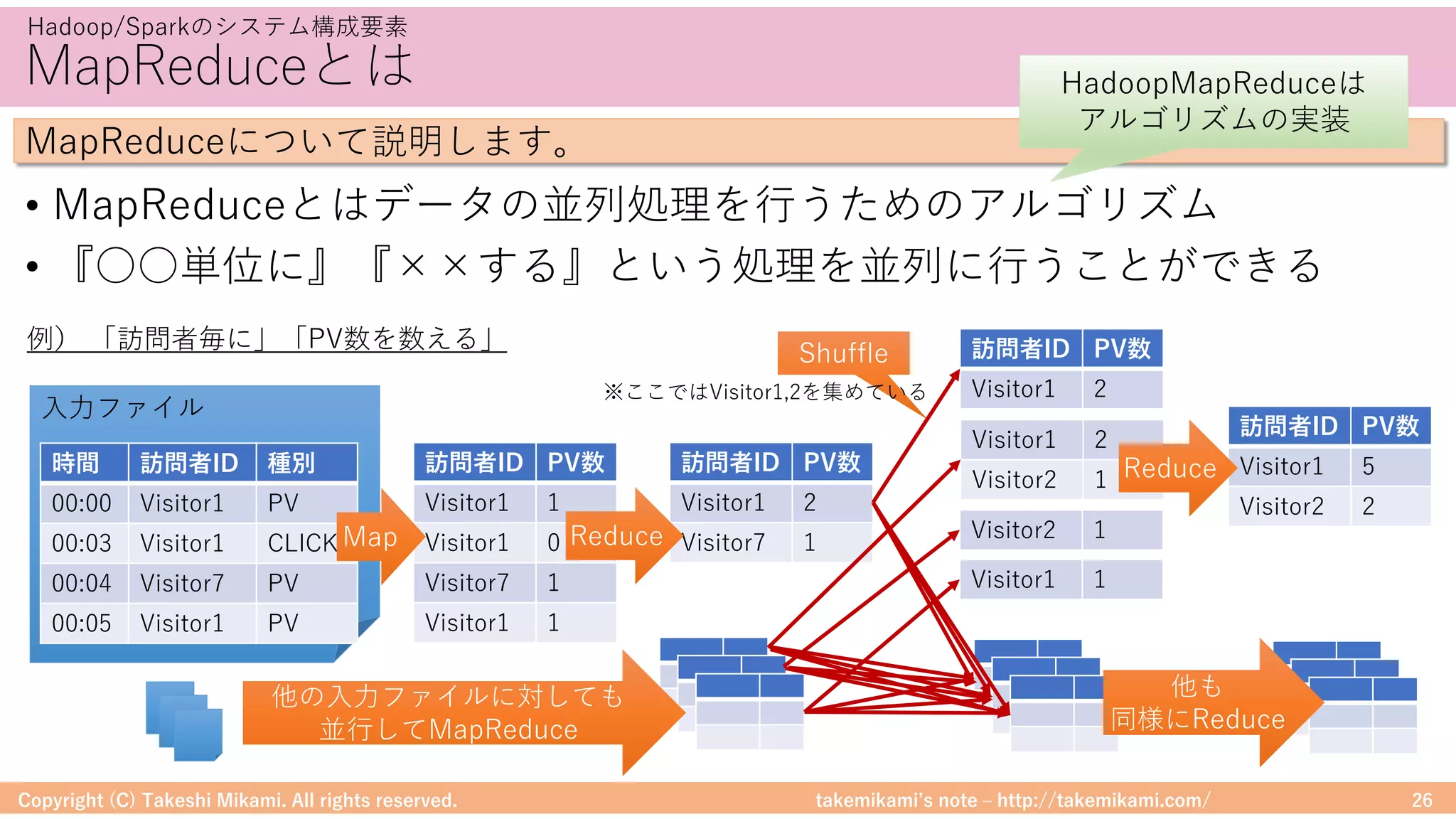
Download as PDF, PPTX



















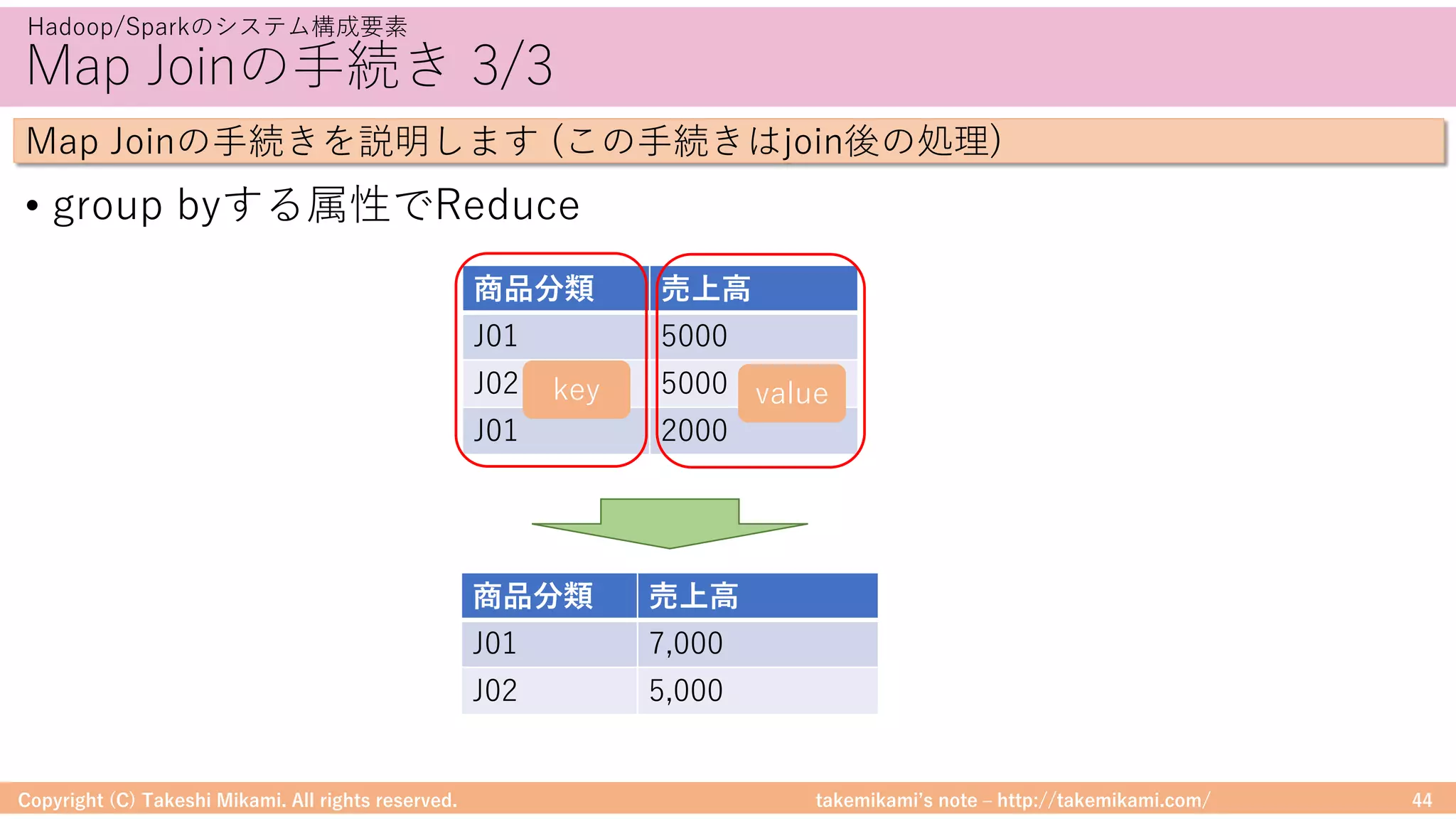
![takemikamiʼs note ‒ http://takemikami.com/
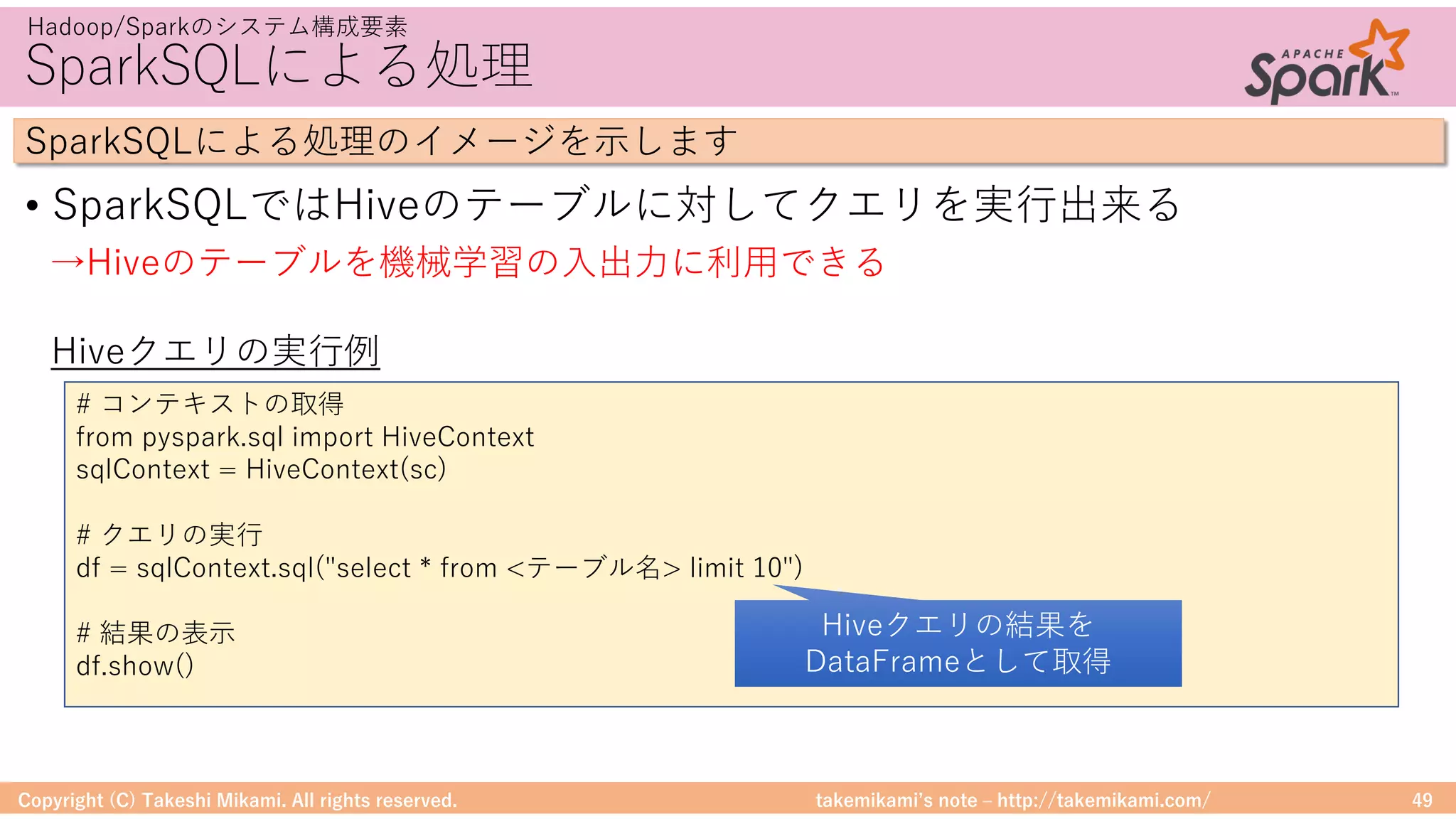
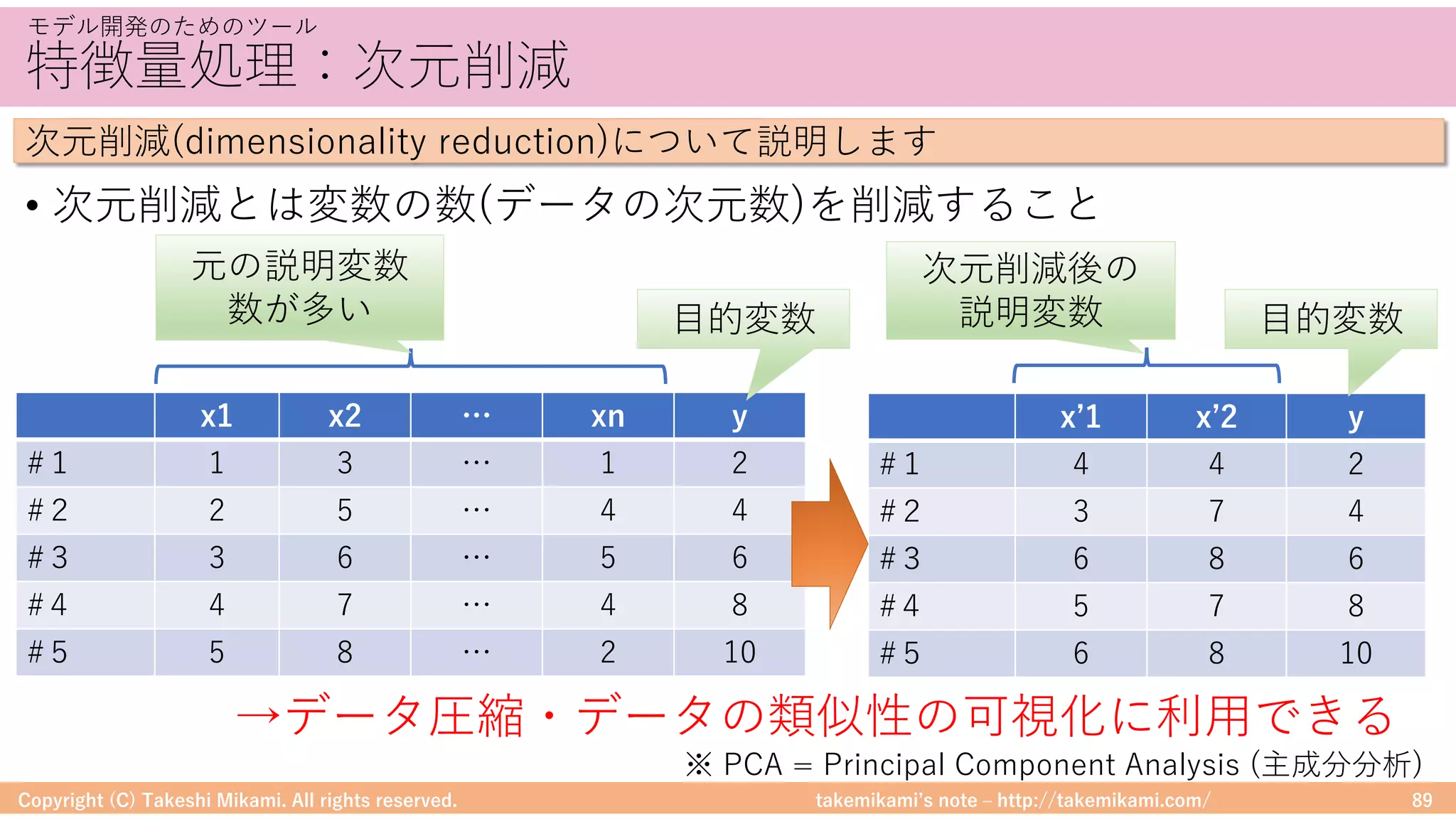
DataFrameに対する処理
• DataFrameは、RやPandasのように操作ができる
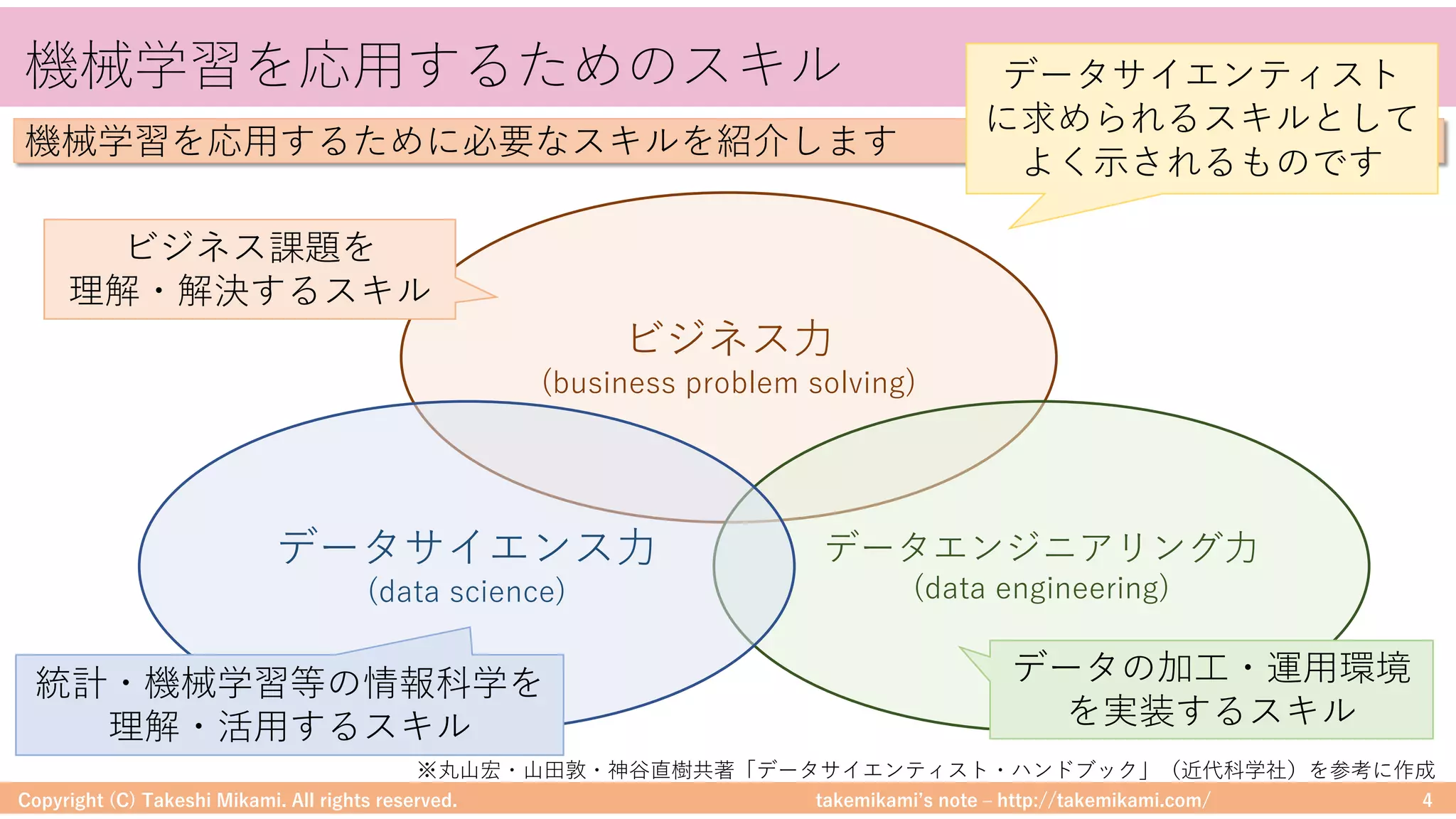
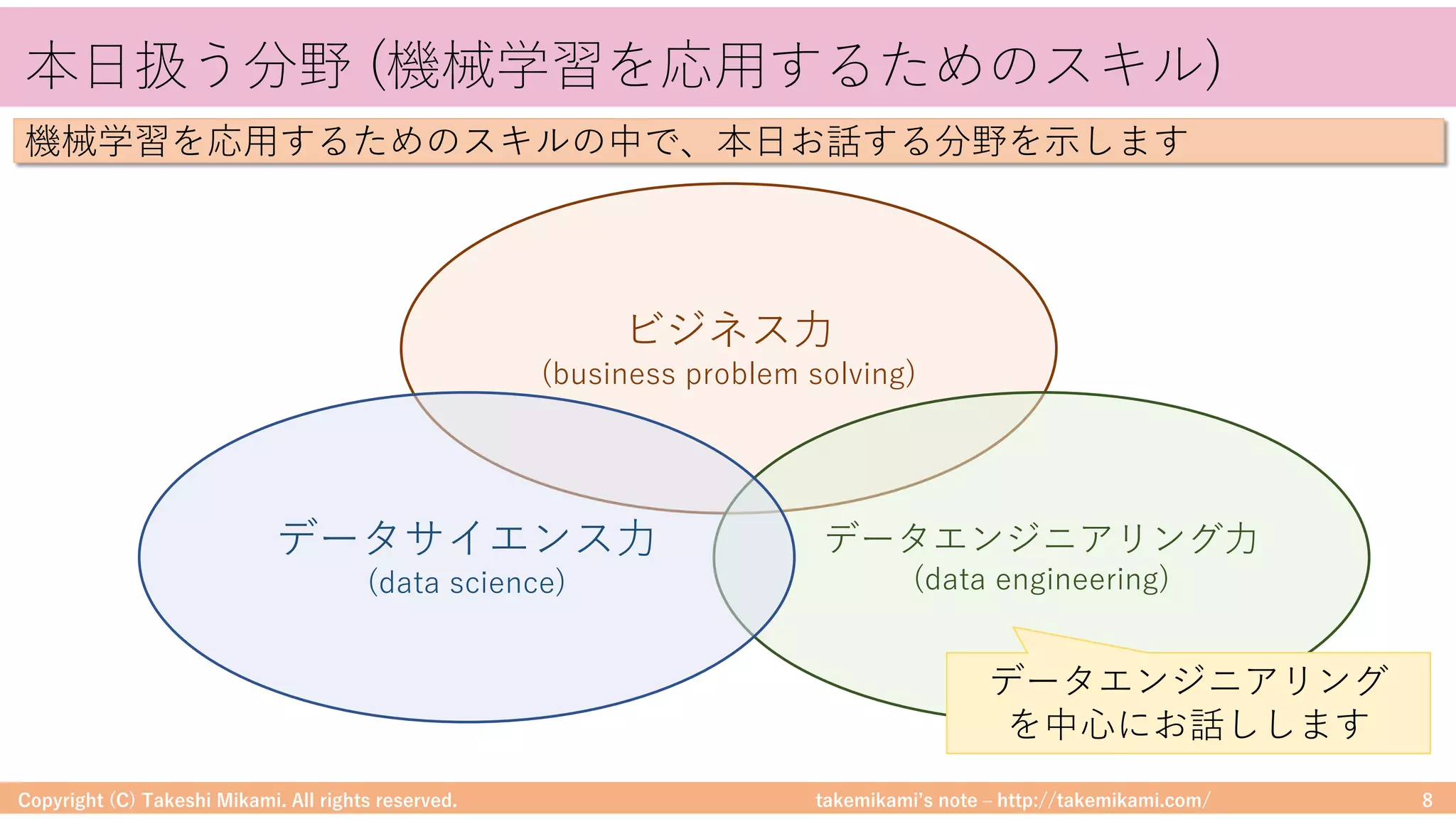
Copyright (C) Takeshi Mikami. All rights reserved. 48
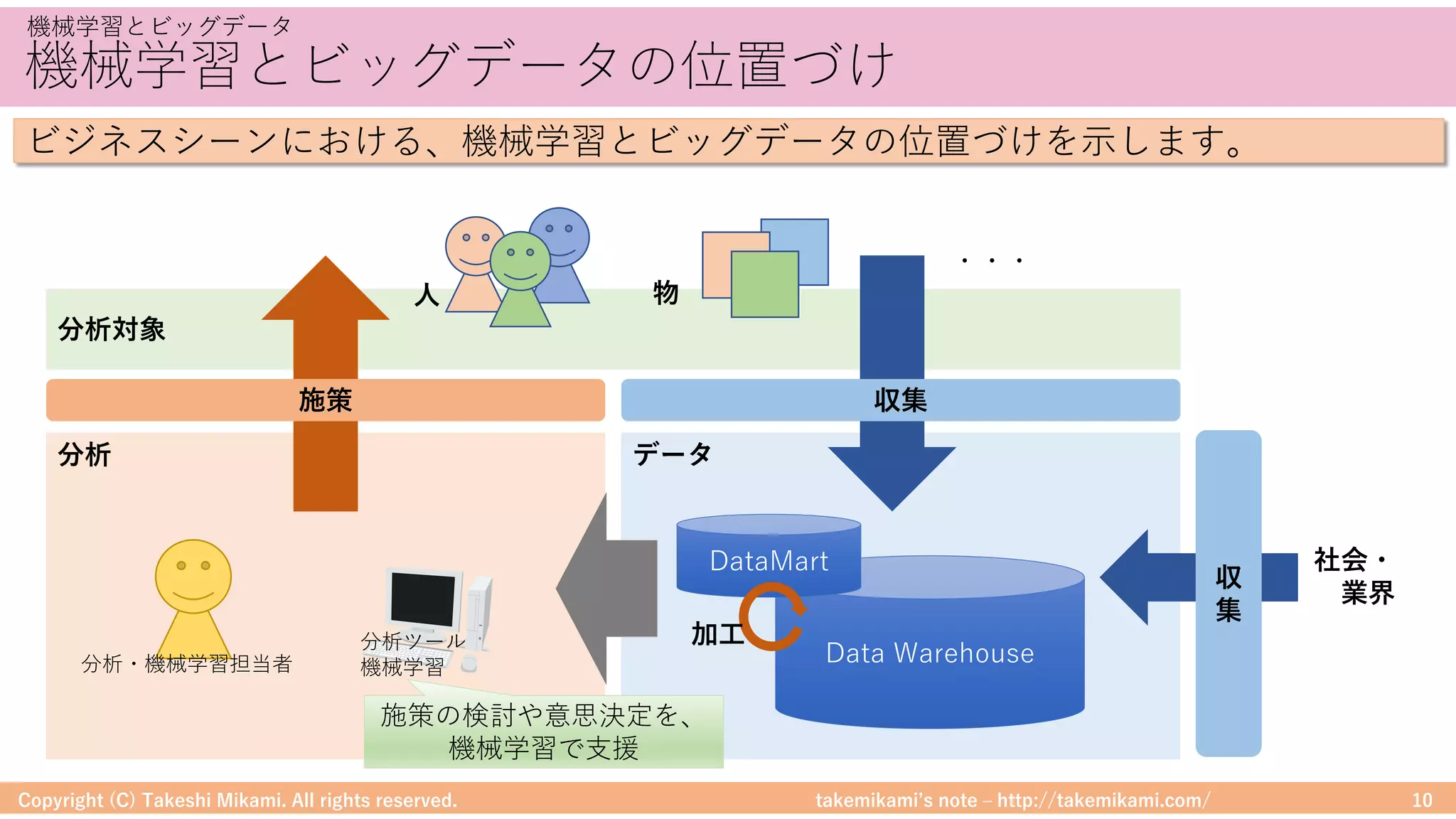
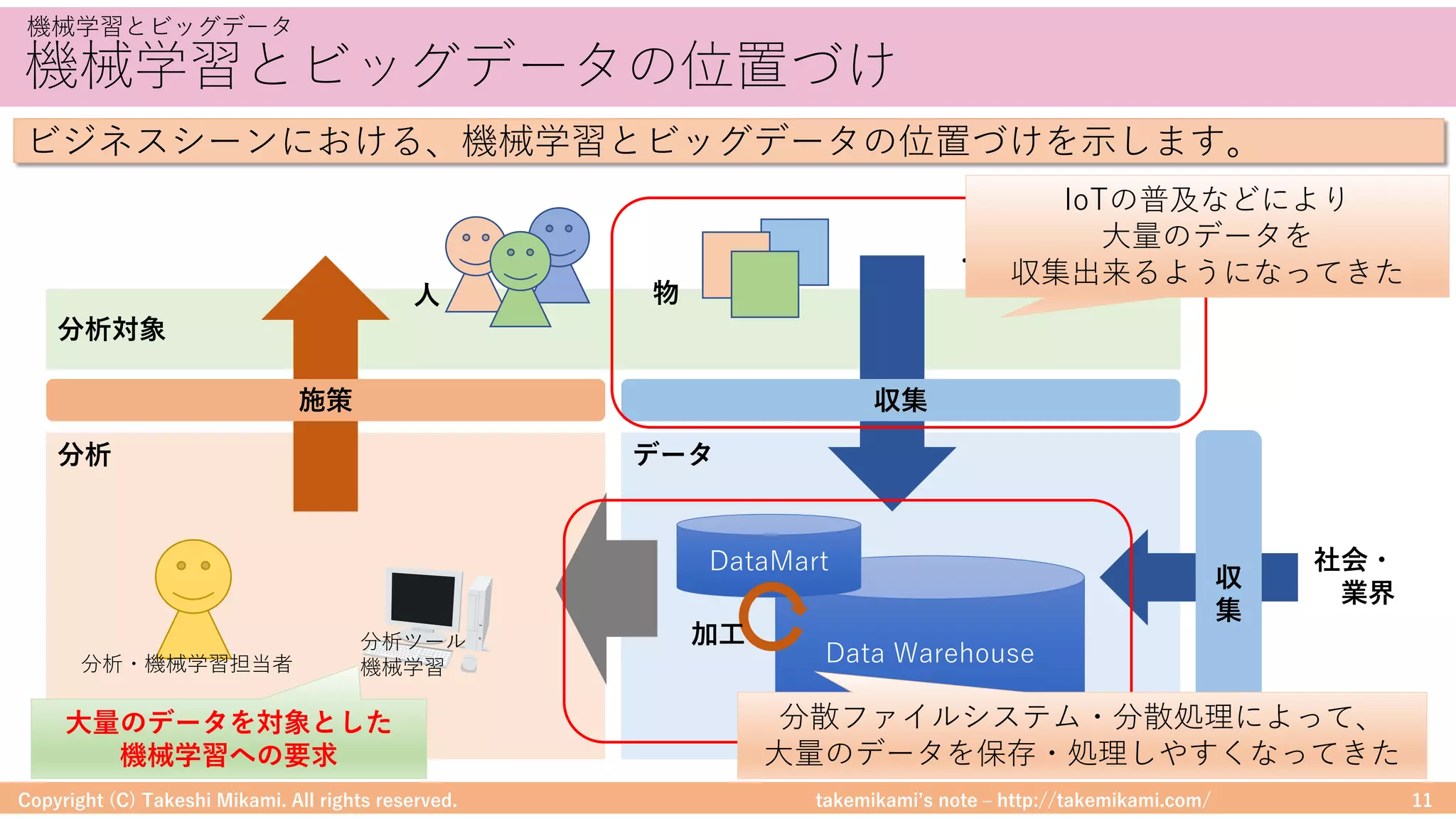
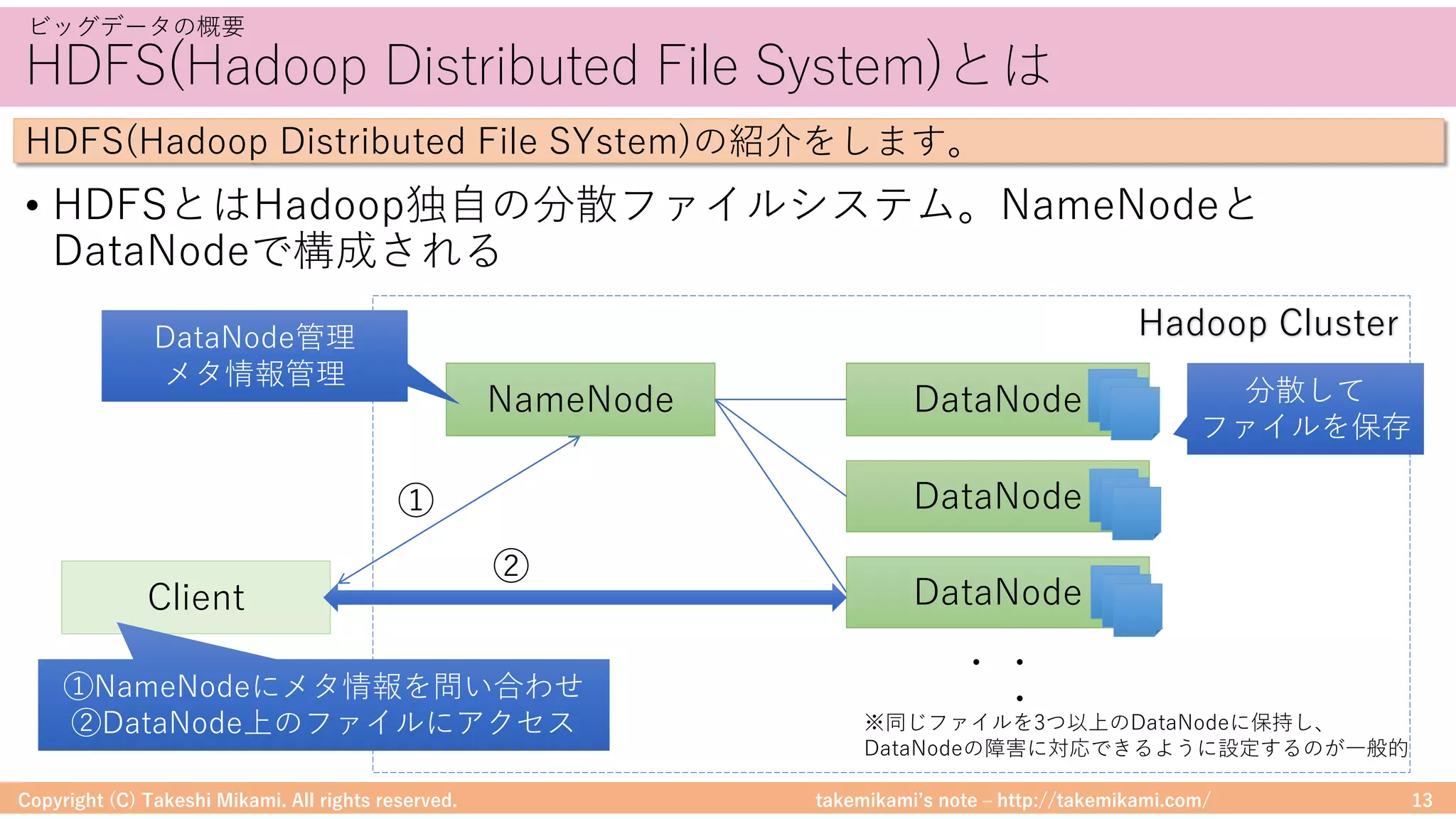
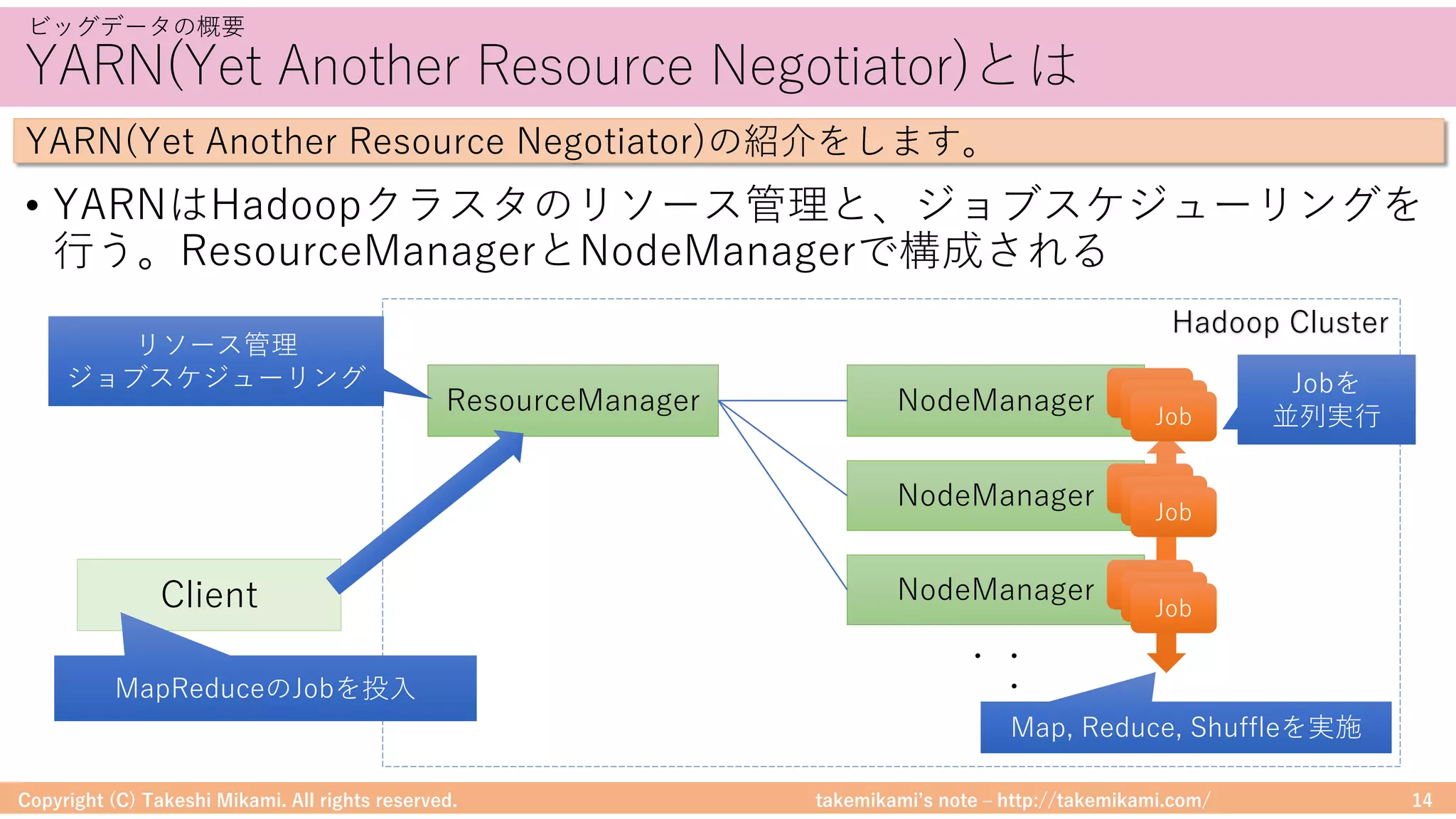
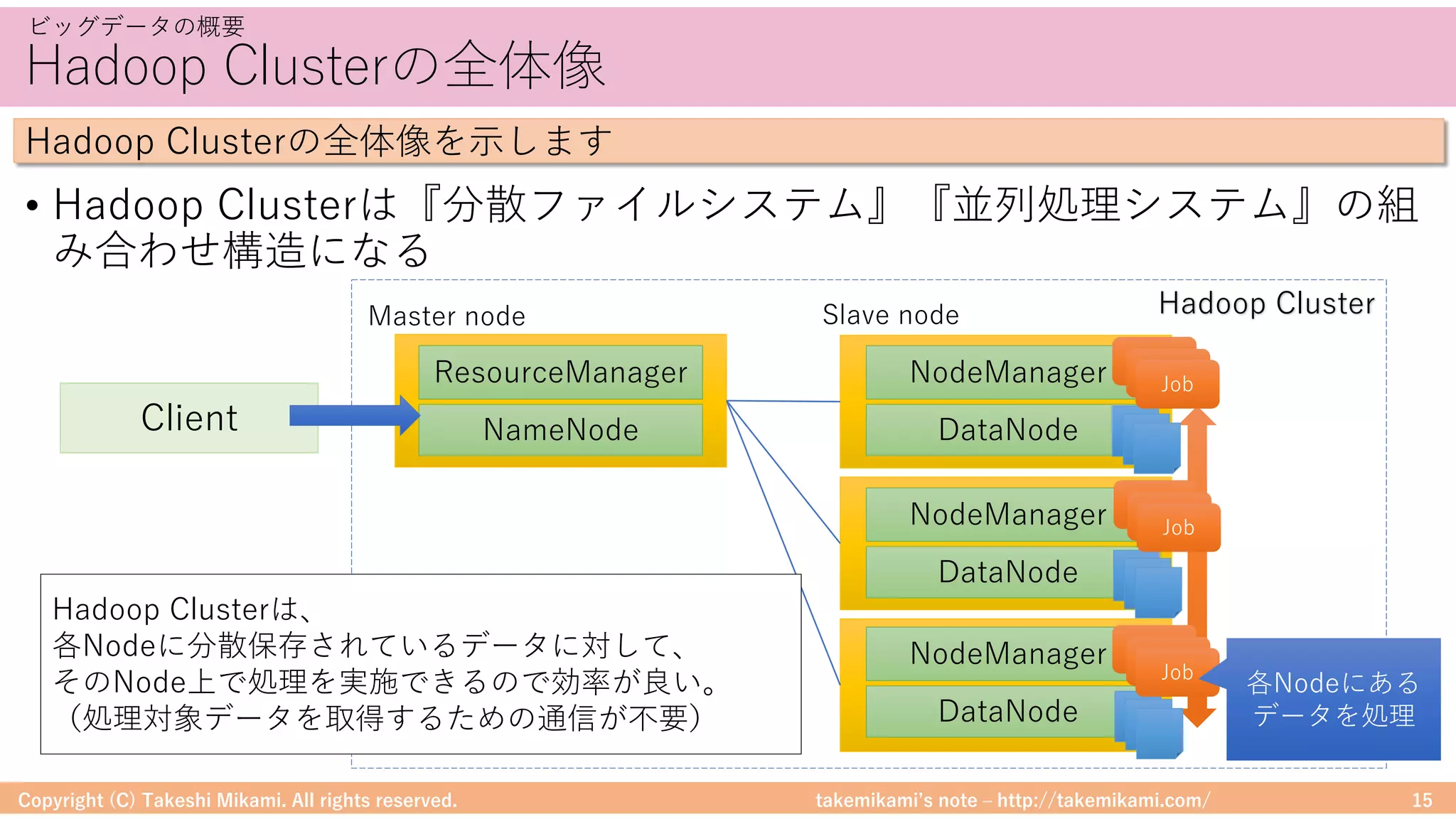
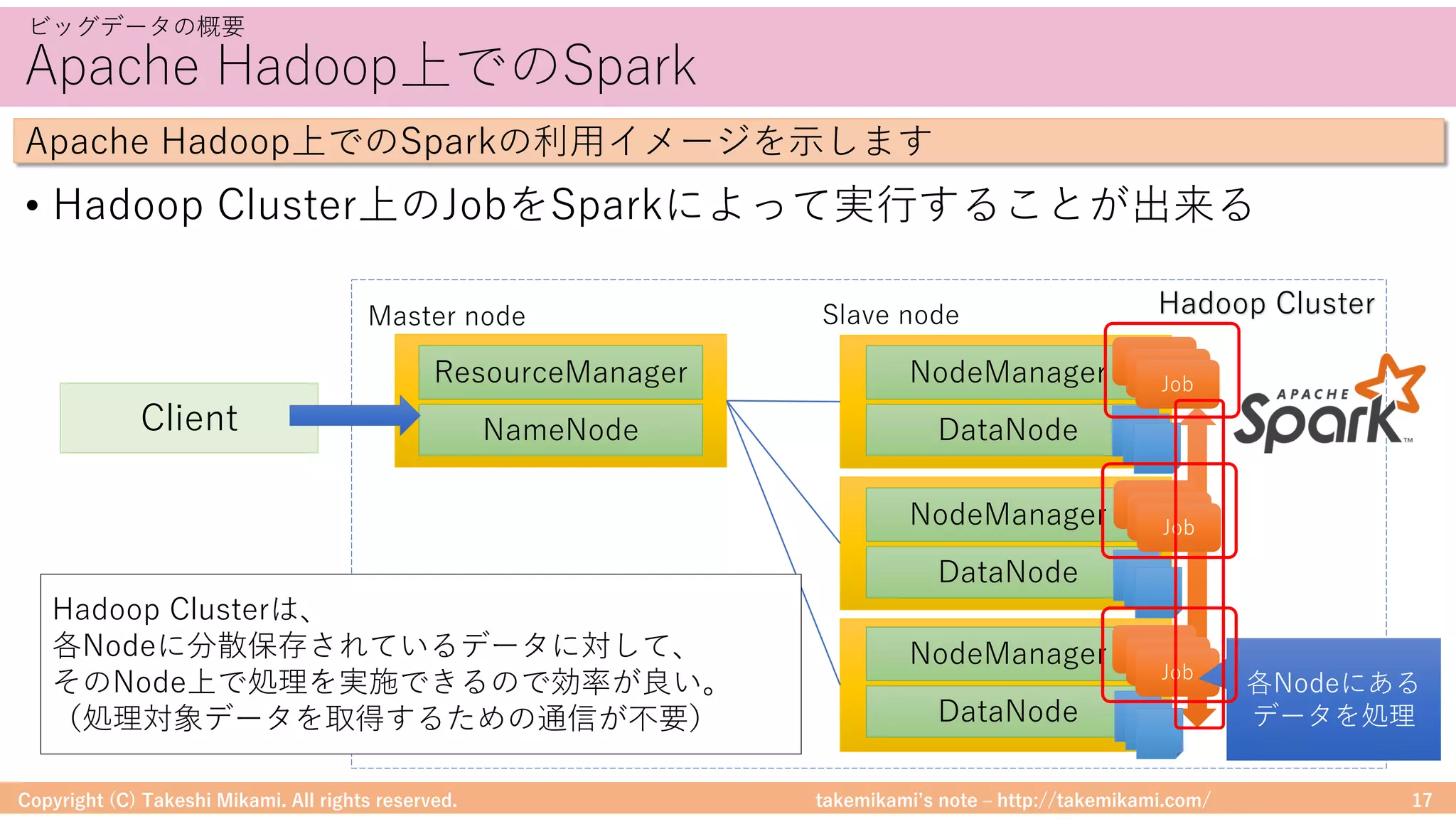
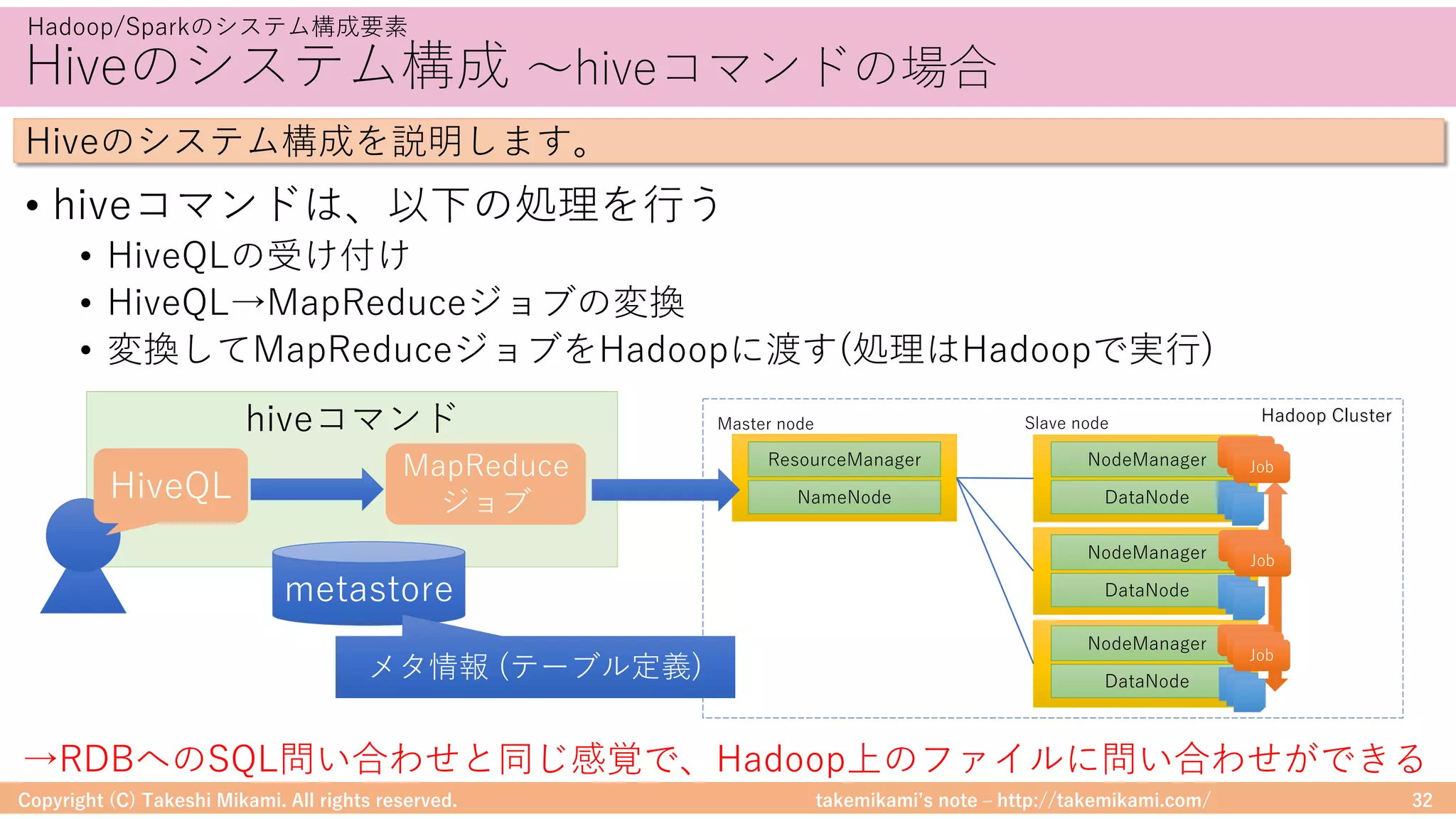
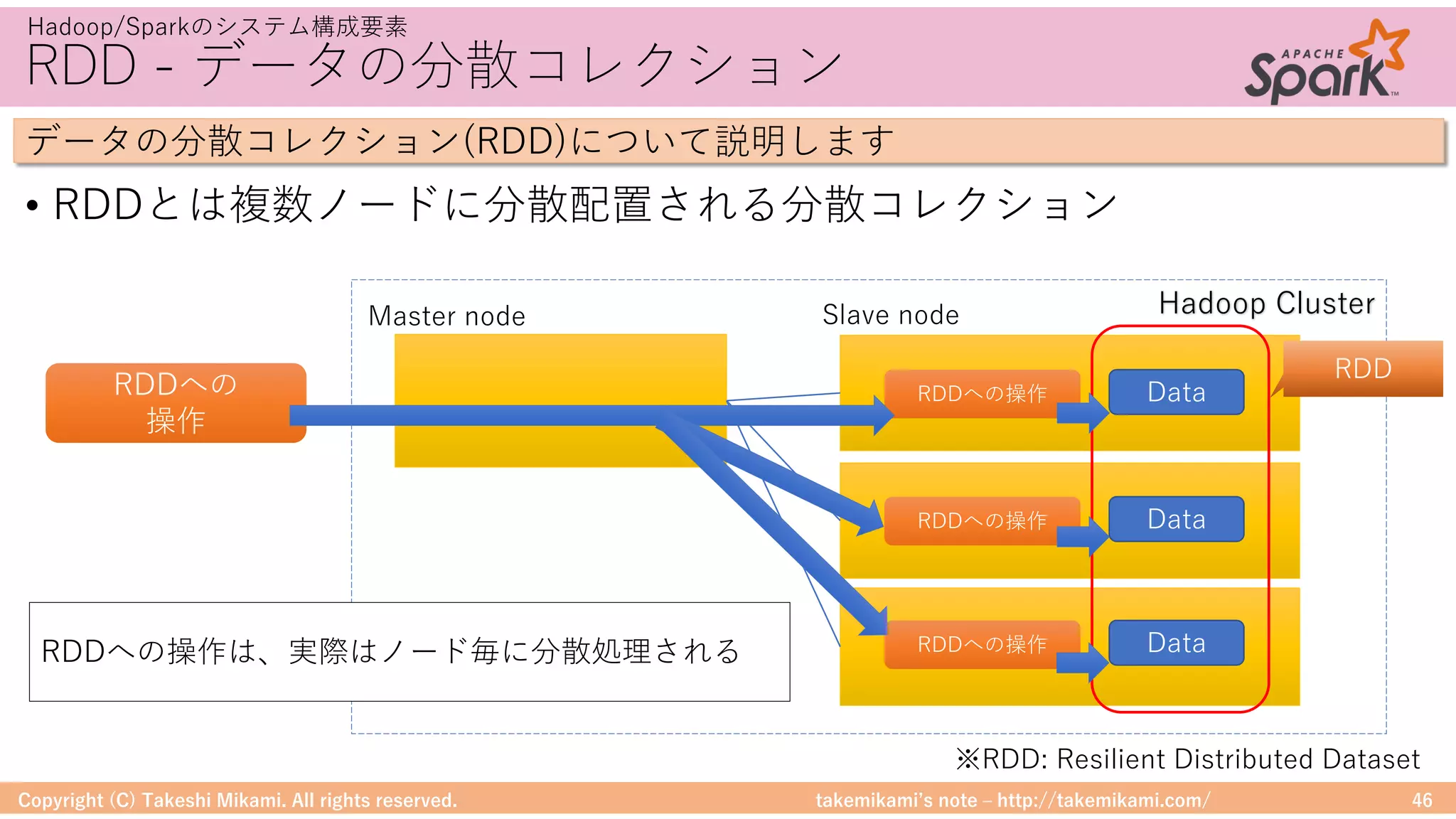
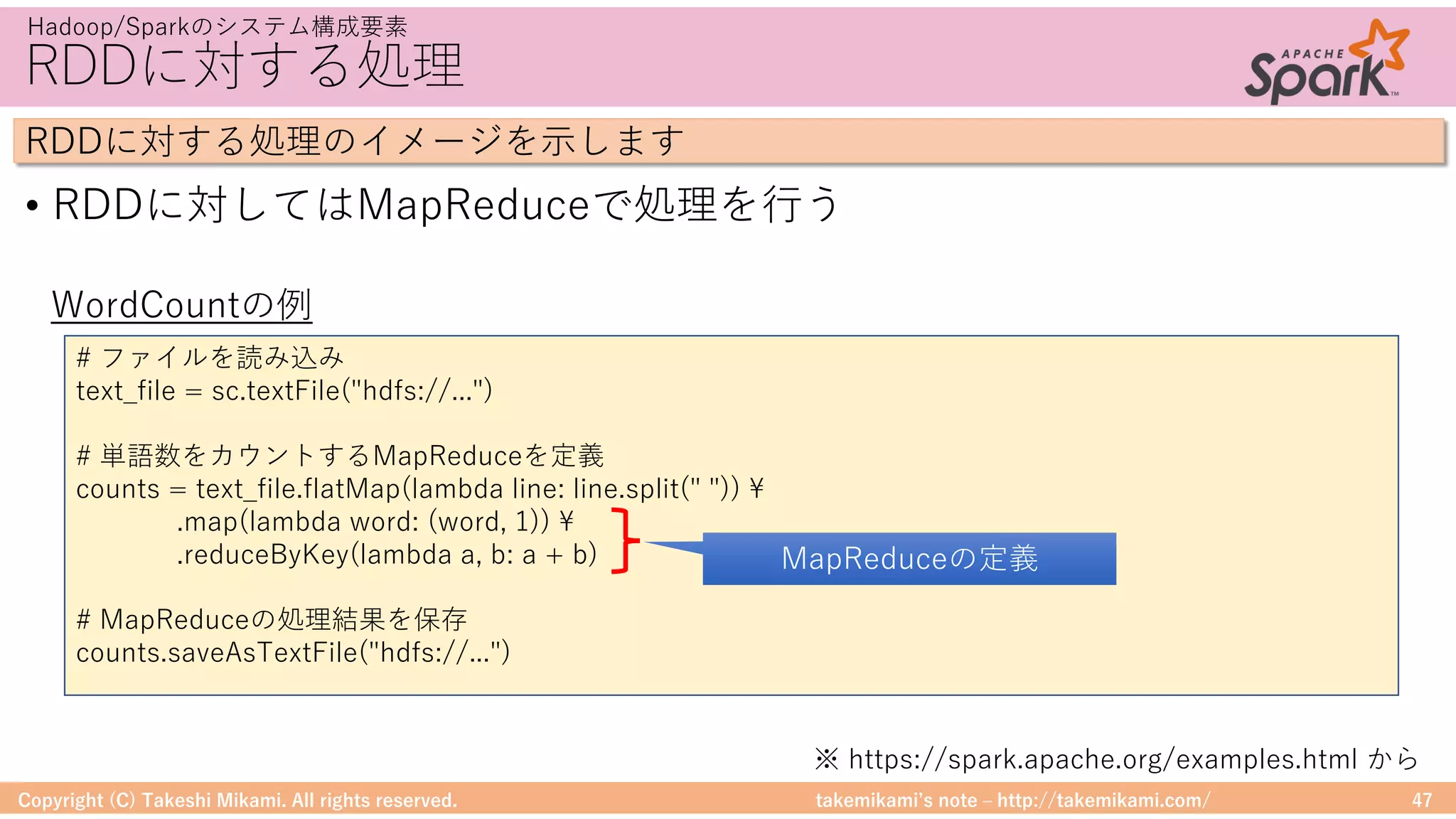
Hadoop/Sparkのシステム構成要素
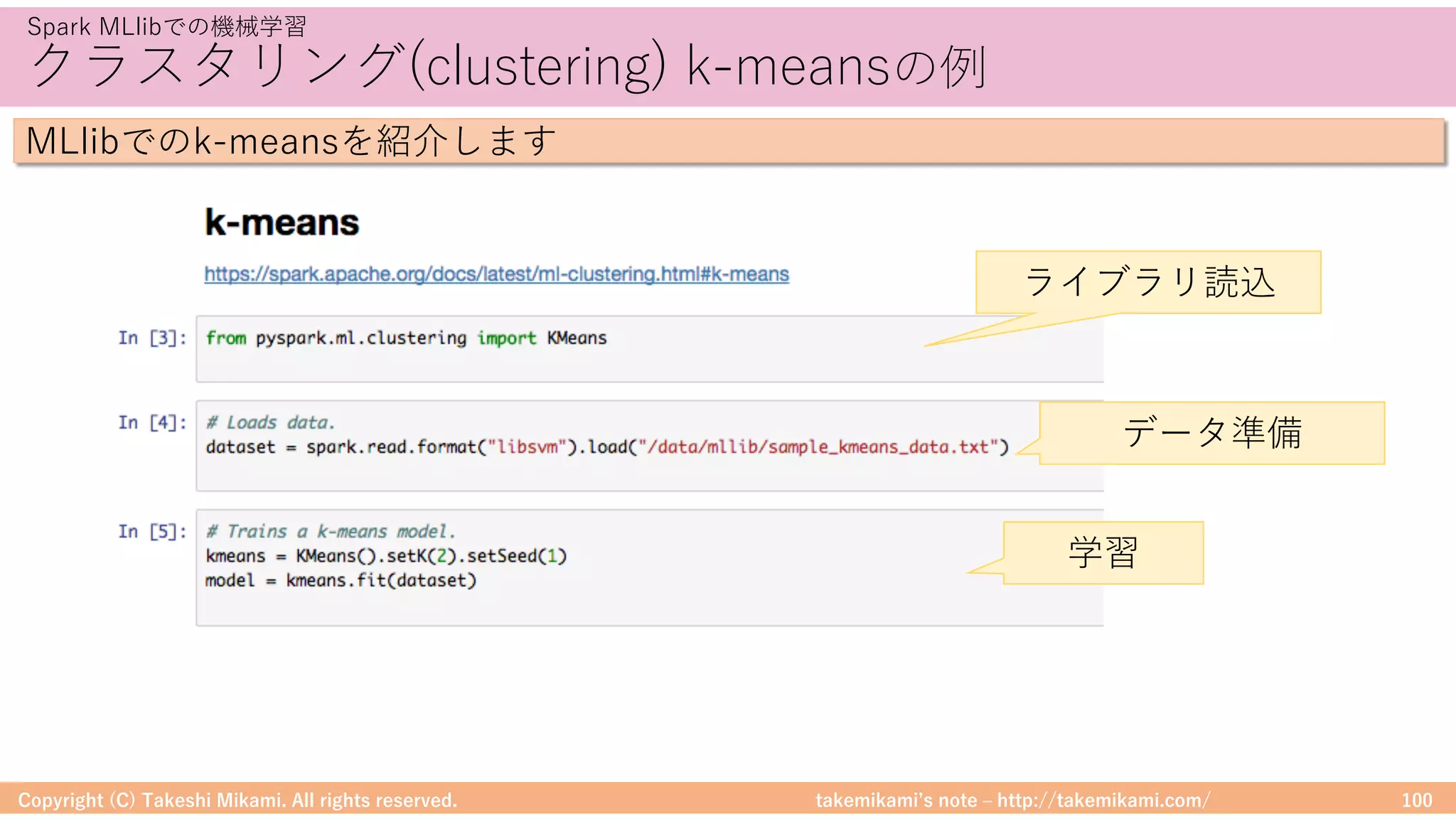
DataFrameに対する処理のイメージを⽰します
# ファイルを読み込んでDataFrameに変換
textFile = sc.textFile("hdfs://...")
df = textFile.map(lambda r: Row(r)).toDF(["line"])
# 「ERROR」を含む⾏を抽出
errors = df.filter(col("line").like("%ERROR%"))
# 該当⾏数をカウント
errors.count()
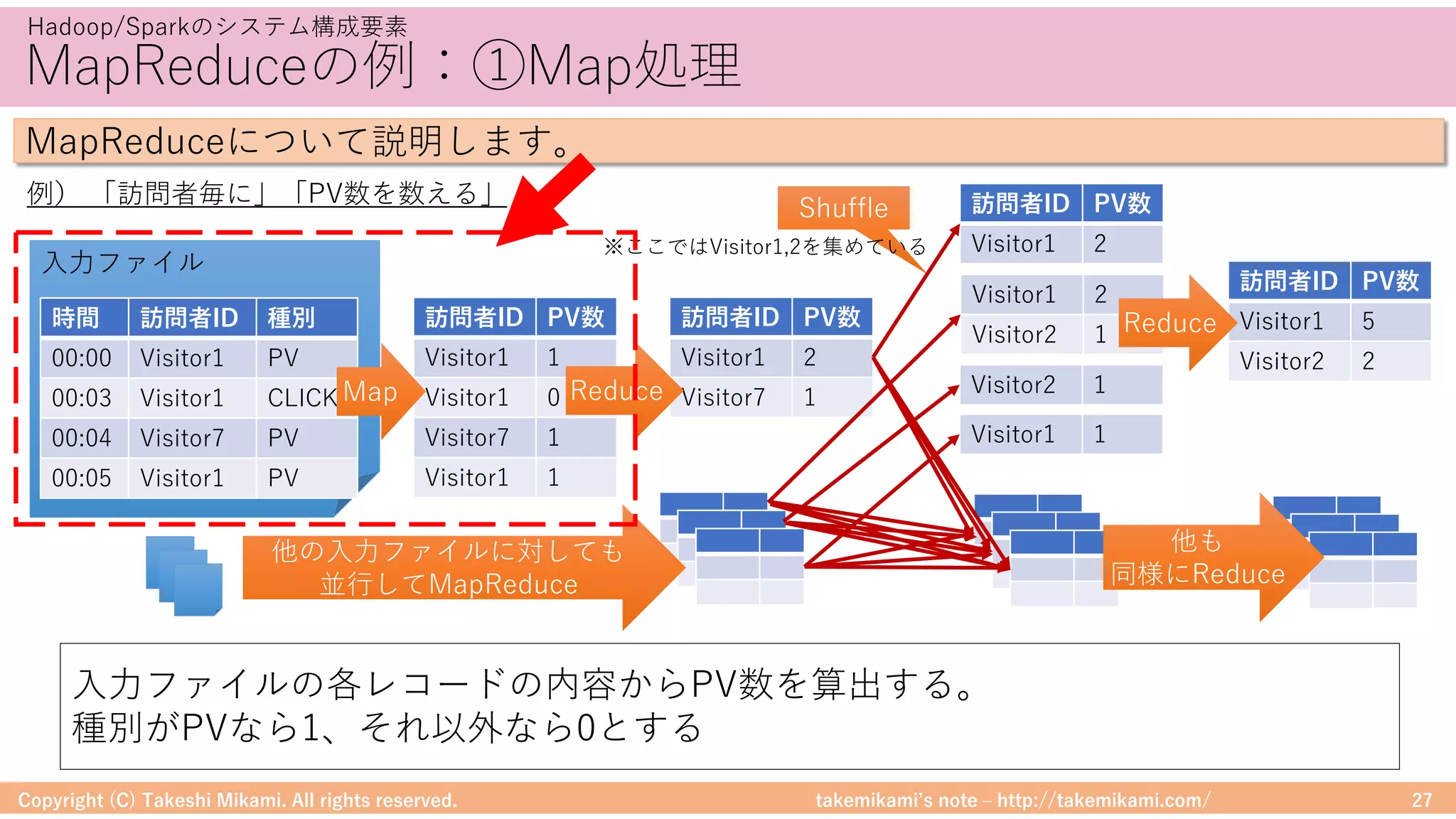
テキスト検索の例
→MapRecuceを意識しなくてよいので、プログラミングが苦⼿な⼈でも扱いやすい
filterのようなメソッドが使える
(MapReduceを意識しなくてよい)
※ https://spark.apache.org/examples.html から](https://image.slidesharecdn.com/sparkml-171028125811/75/SparkMLlib-48-2048.jpg)
![takemikamiʼs note ‒ http://takemikami.com/
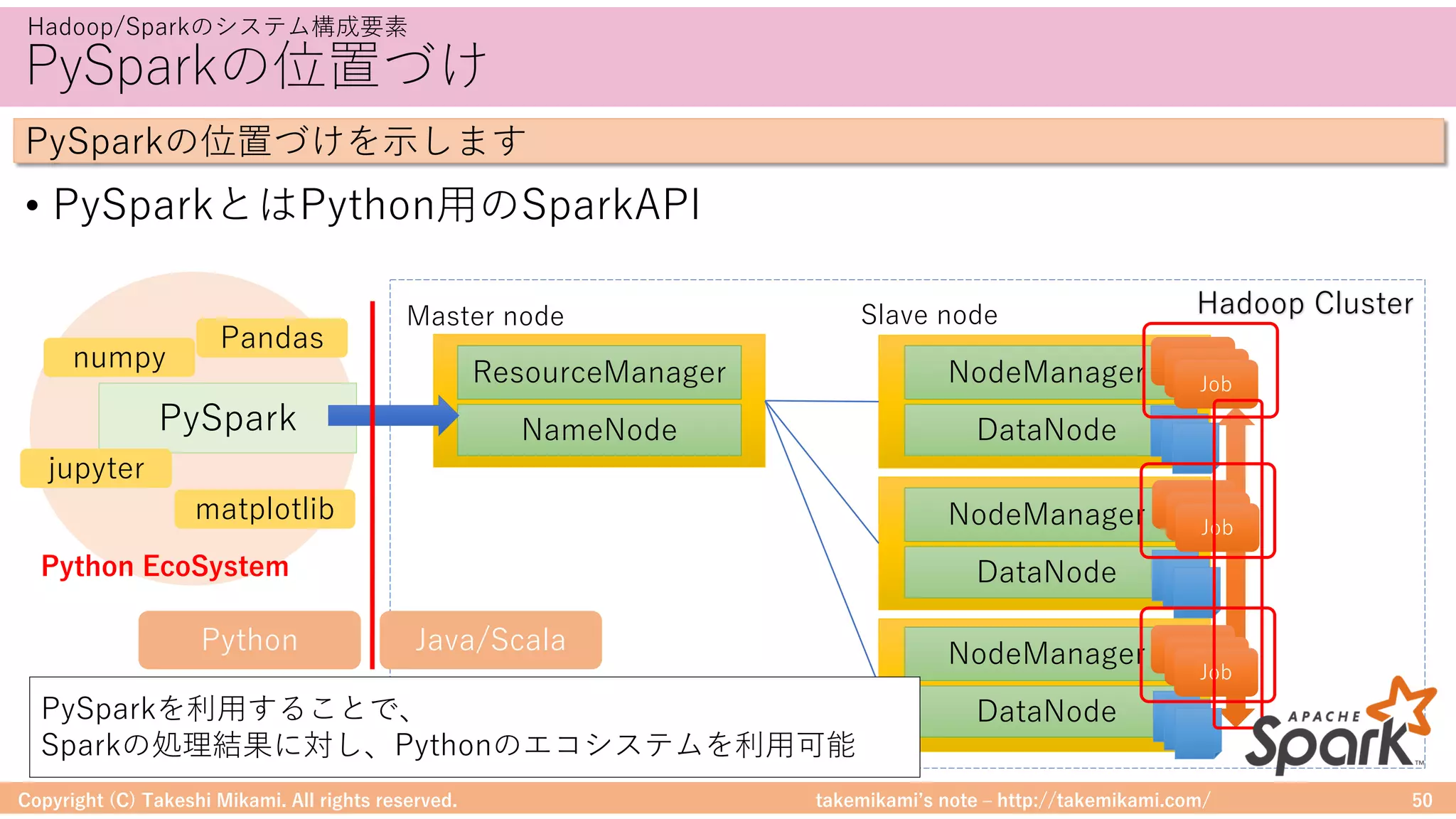
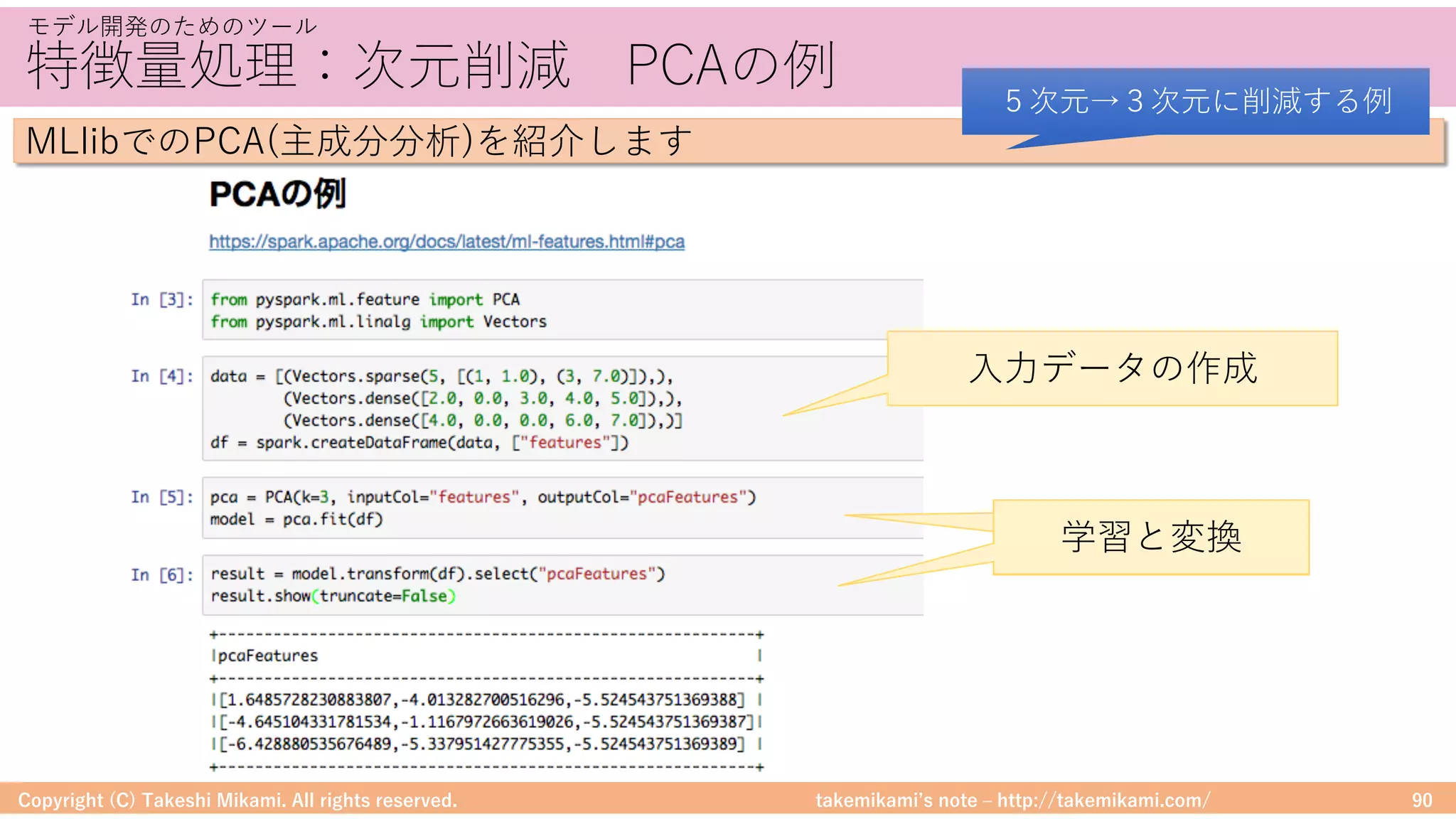
SparkとPandasのDataFrame
• SparkとPandasのDataFrameは相互に変換できます
Copyright (C) Takeshi Mikami. All rights reserved. 51
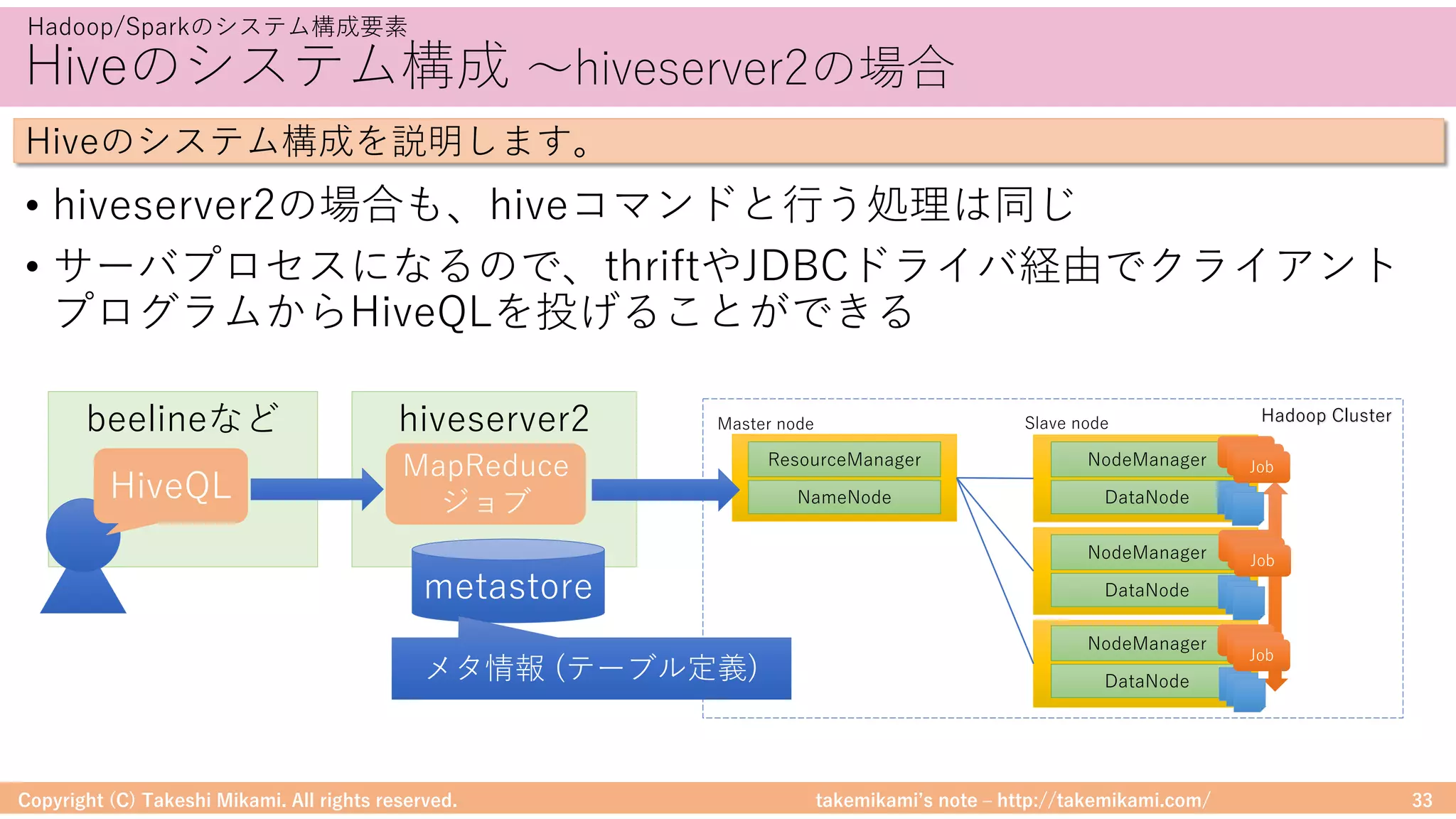
Hadoop/Sparkのシステム構成要素
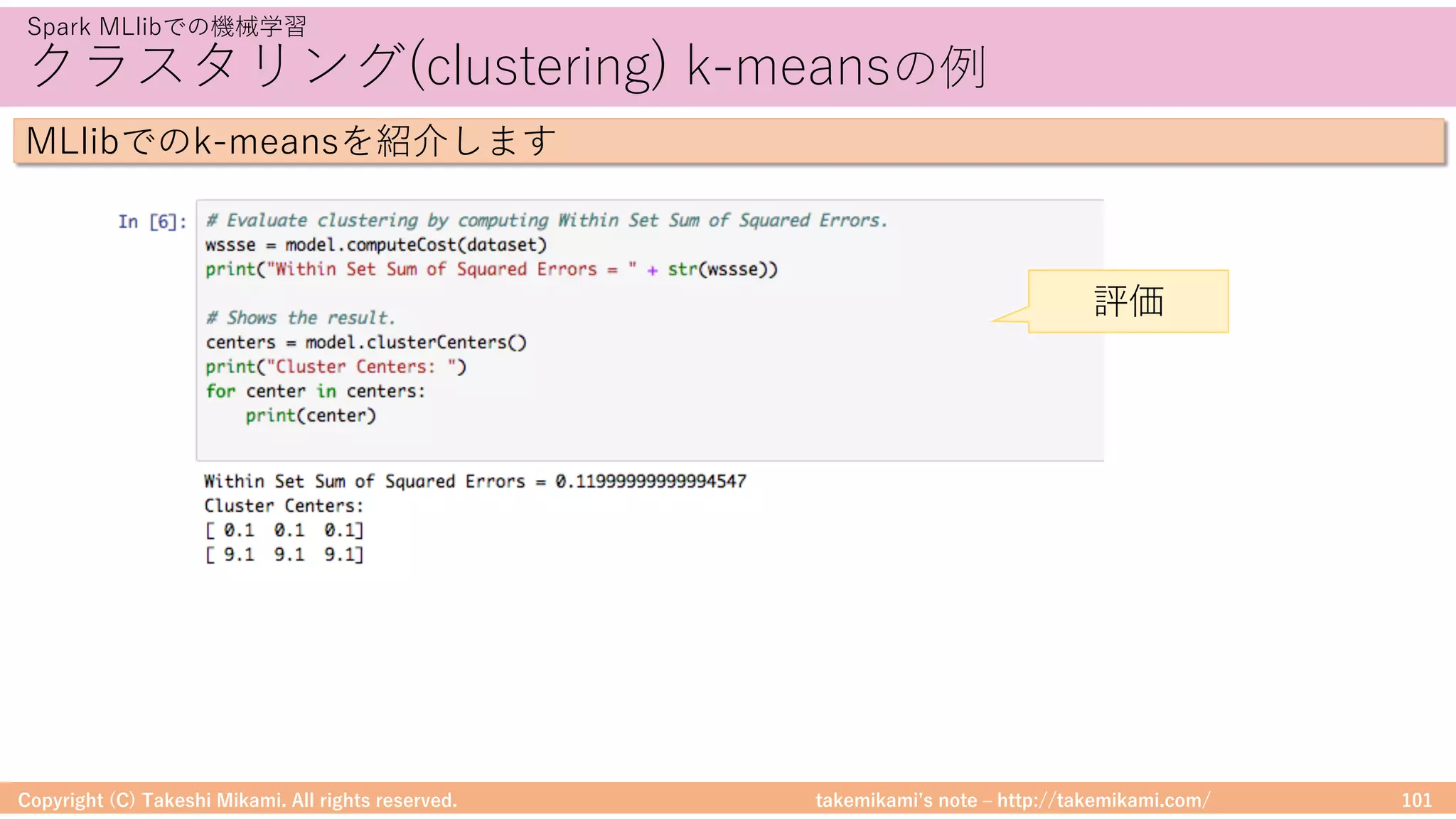
SparkとPandasのDataFrameの変換イメージを⽰します
# PandasのDataFrameを作成
import pandas as pd
import numpy as np
pandasDf = pd.DataFrame({ 'id' : np.array([1, 2]), 'name': np.array(["apple", "orange"])})
# PandasのDataFrame → SparkのDataFrame
sparkDf = spark.createDataFrame(pandasDf)
# SparkのDataFrame表⽰
sparkDf.show()
# SparkのDataFrame → PandasのDataFrame
sparkDf.toPandas()
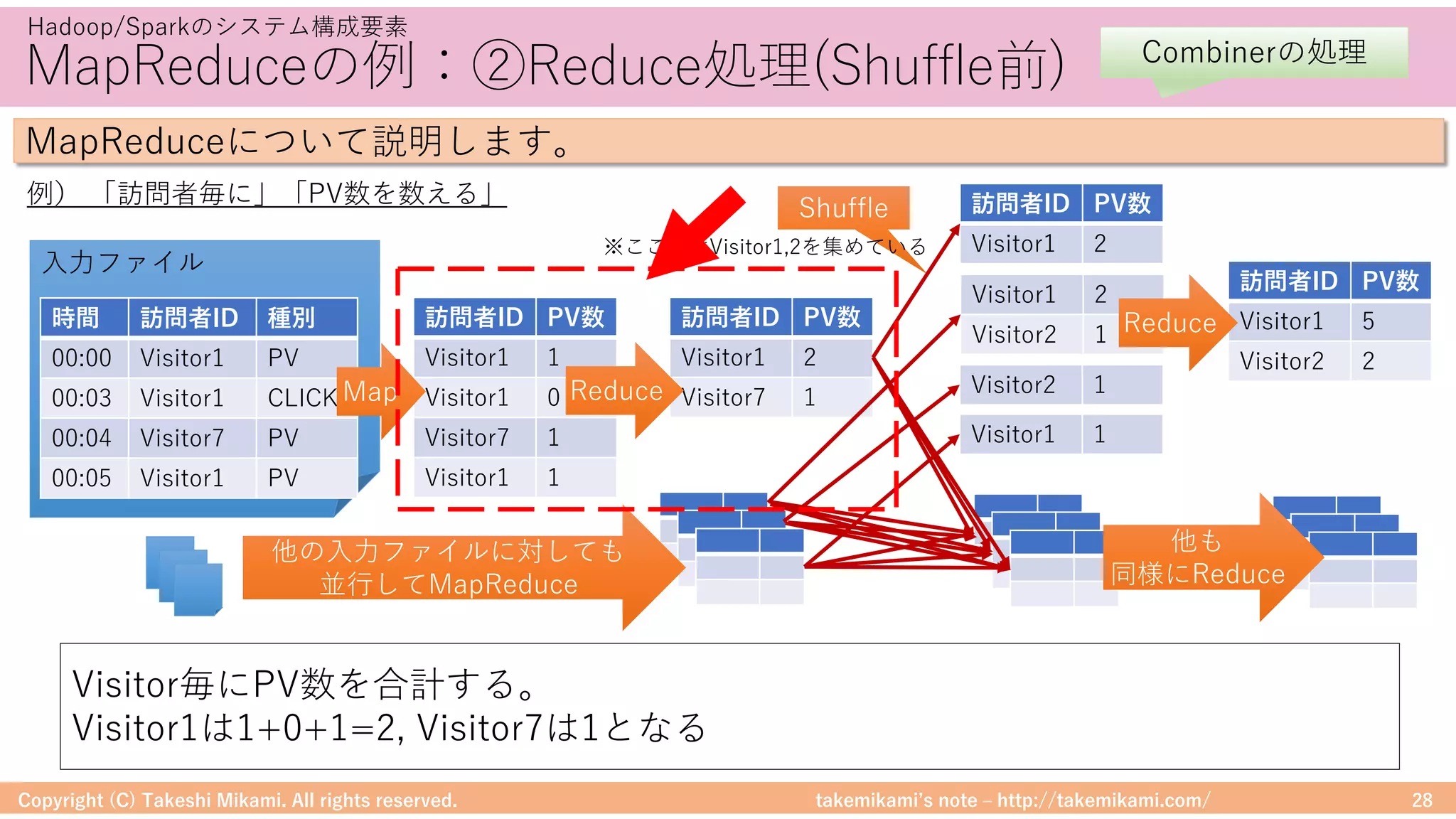
Spark/PandasのDataFrame変換の例
Spark→Pandas
Pandas→Spark](https://image.slidesharecdn.com/sparkml-171028125811/75/SparkMLlib-51-2048.jpg)








![takemikamiʼs note ‒ http://takemikami.com/
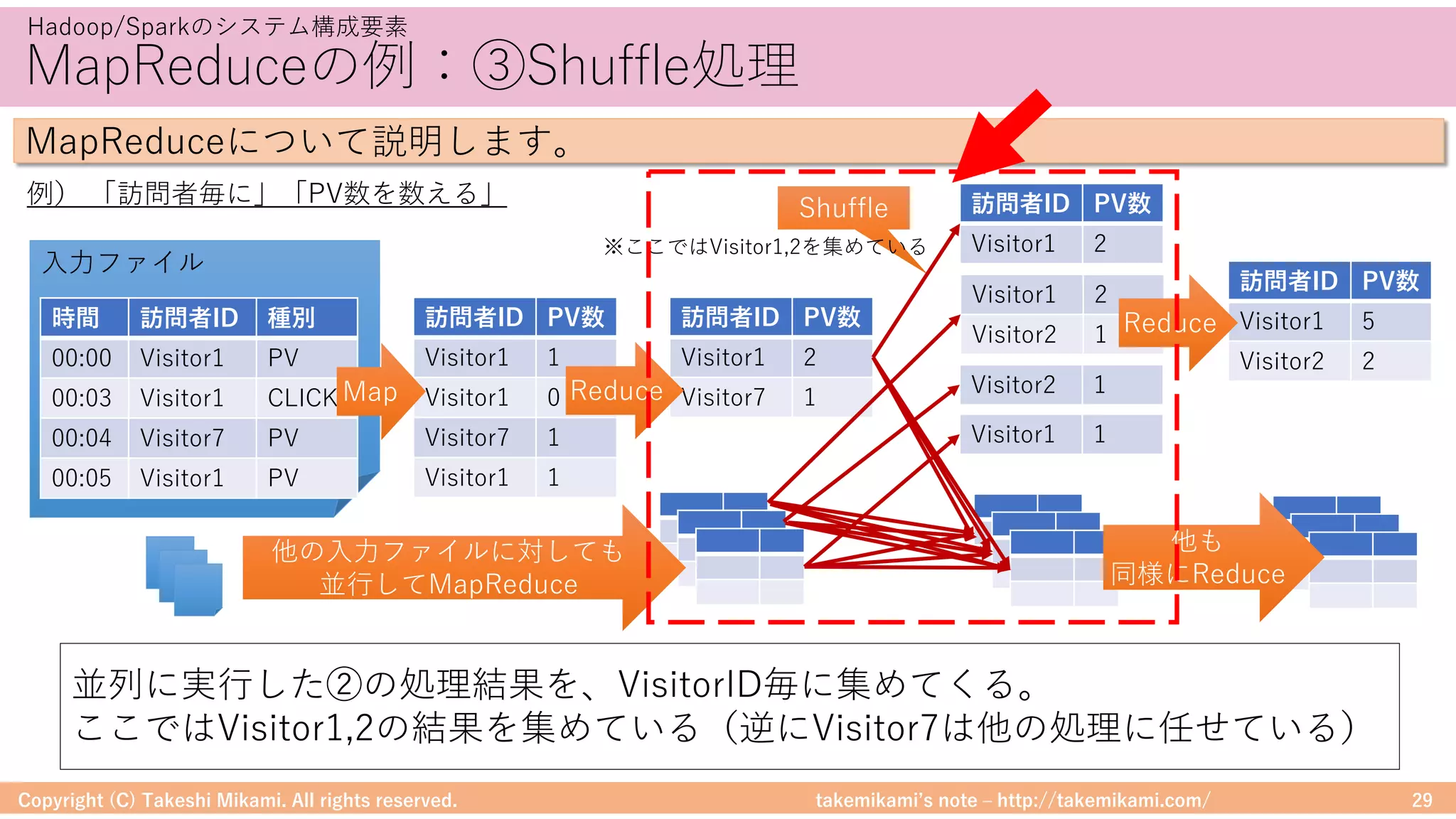
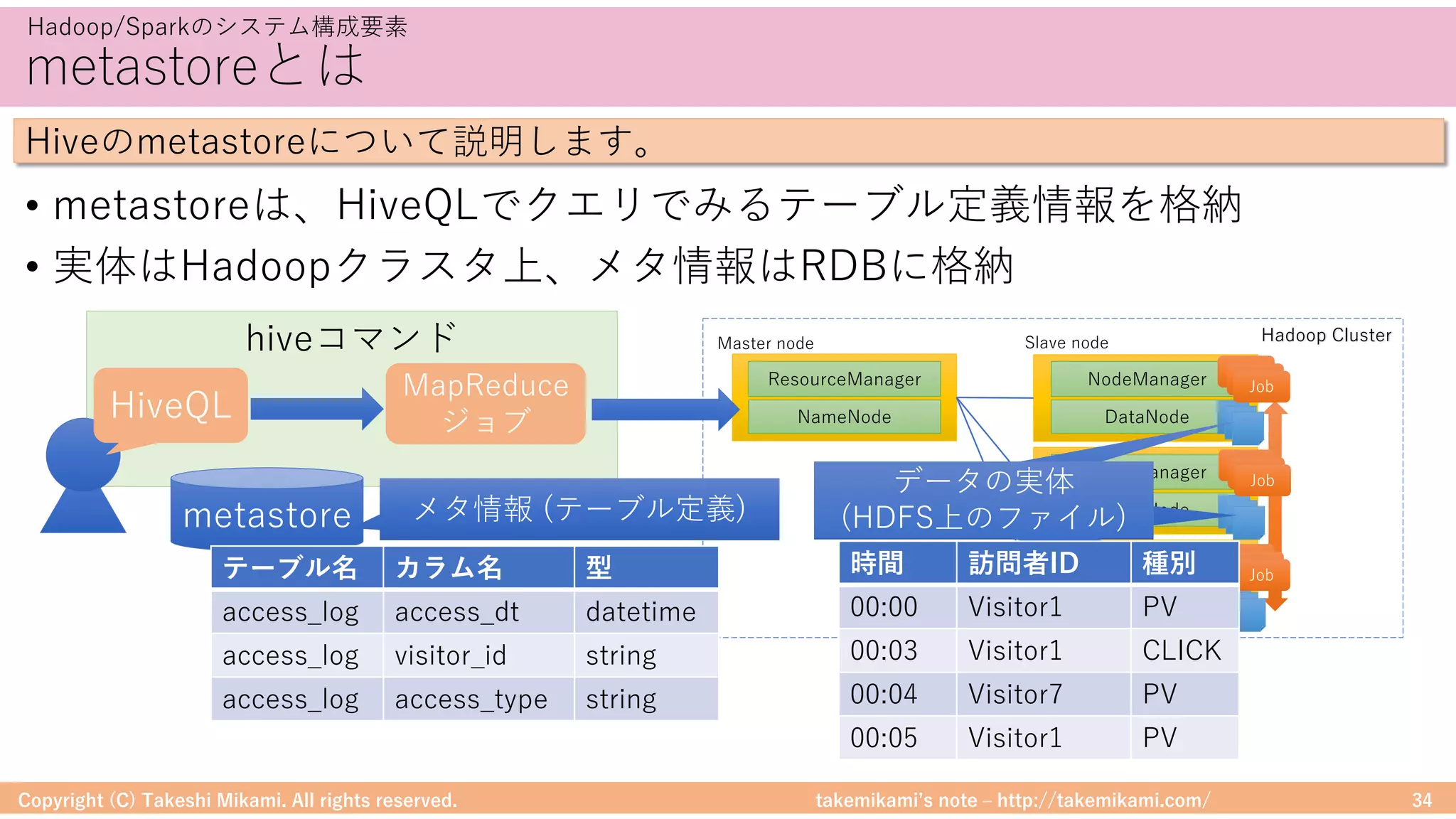
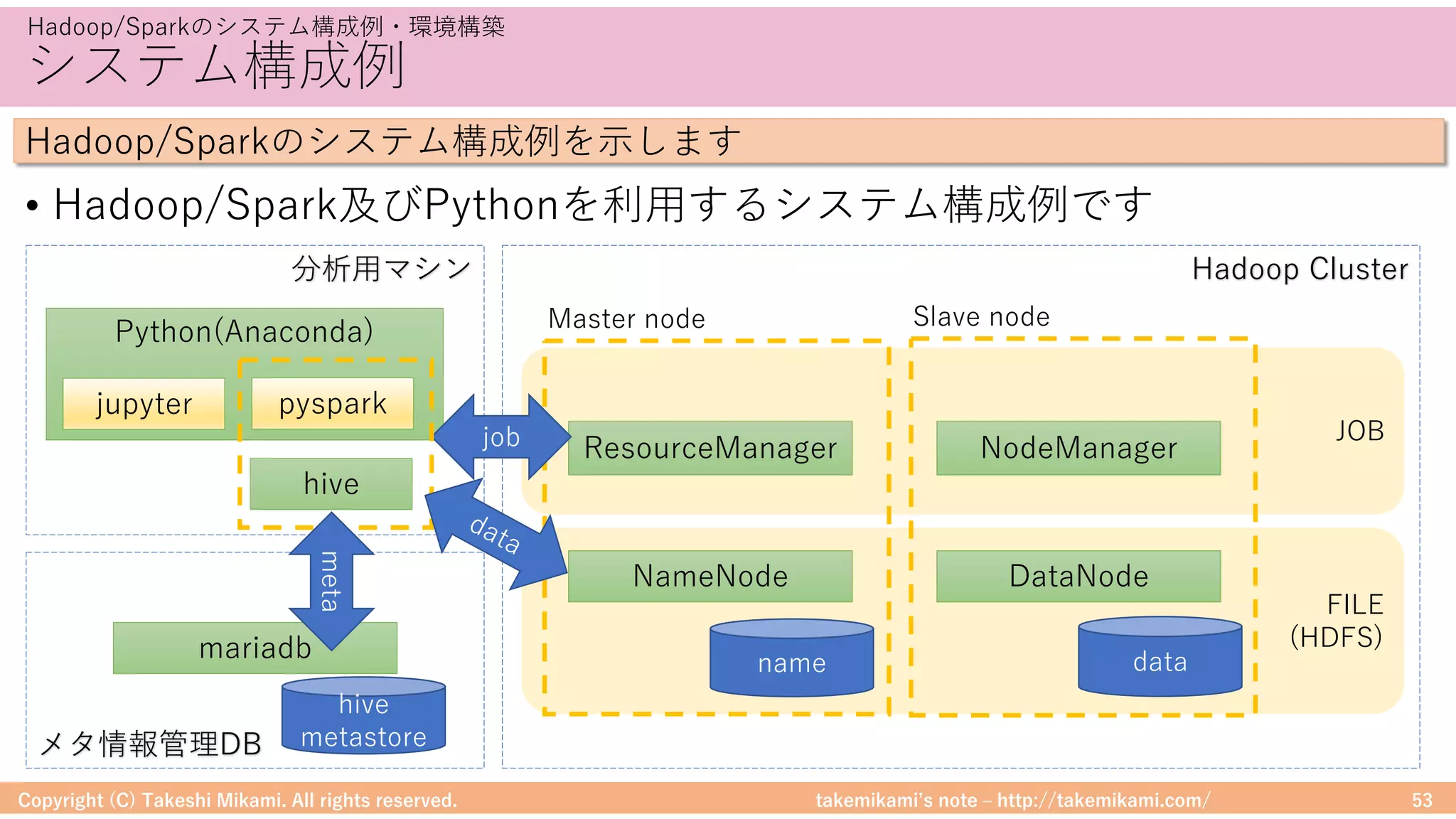
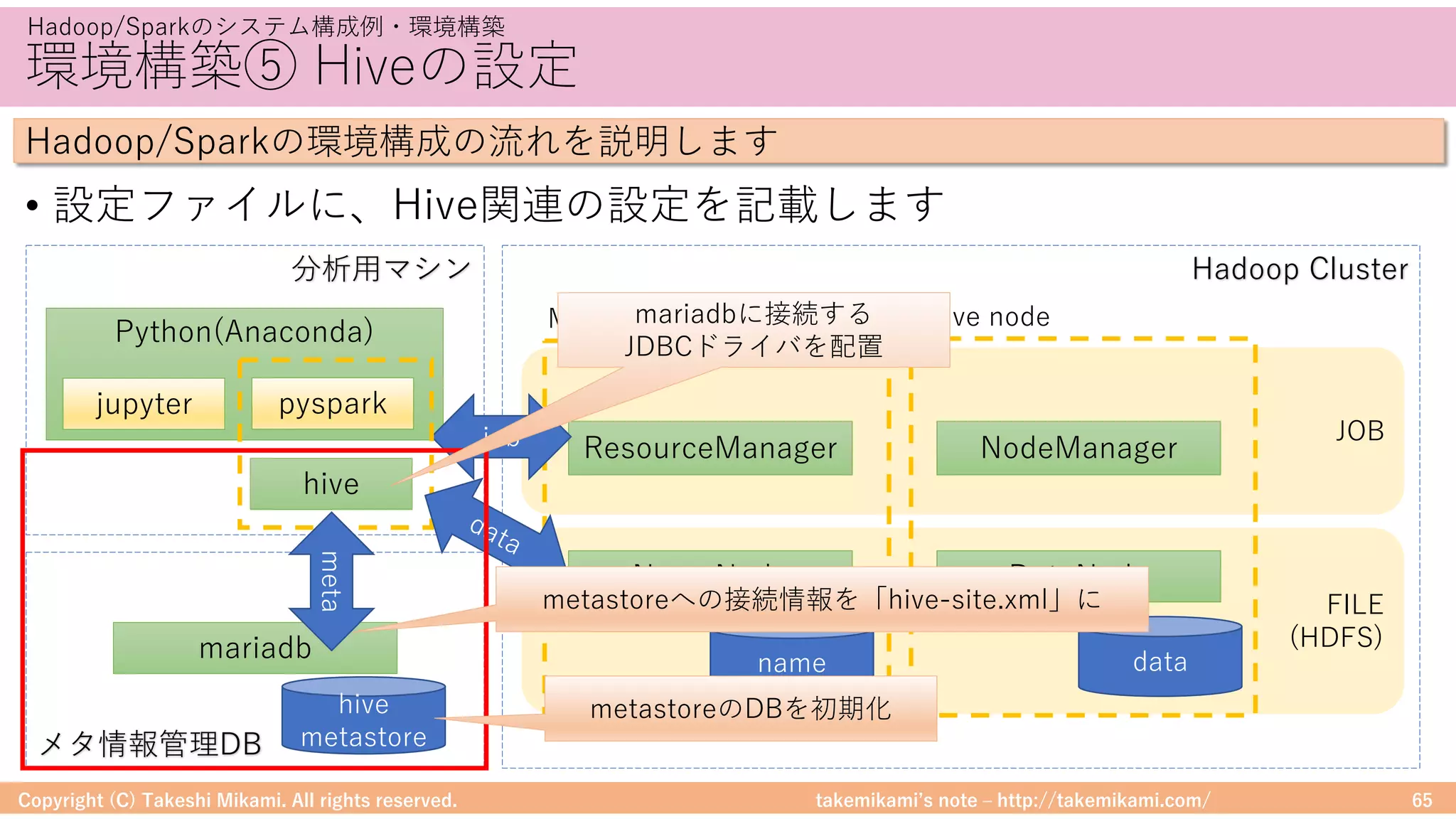
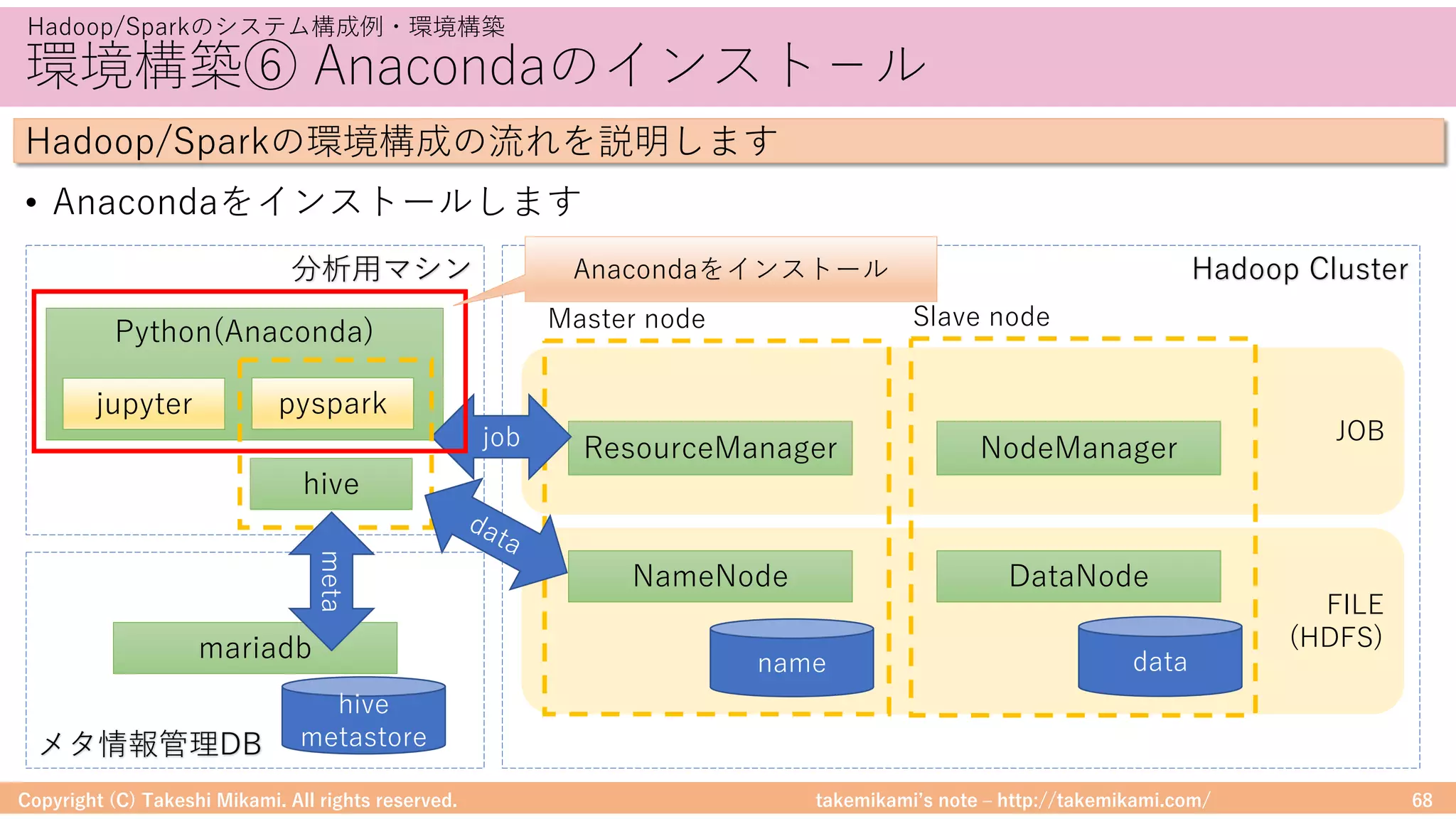
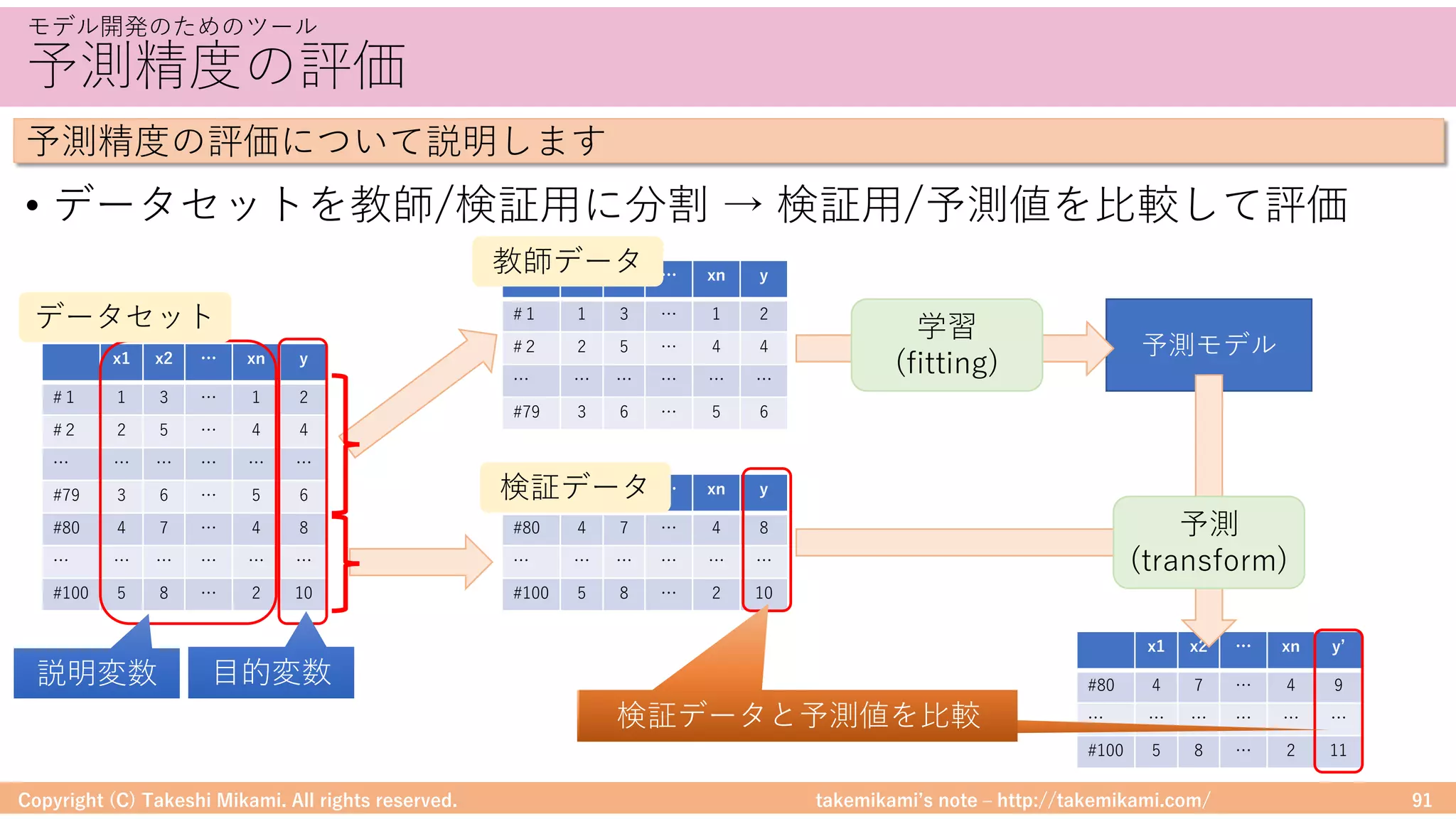
環境構築⑤ Hiveの設定
• 「https://dev.mysql.com/」からJDBCドライバ(mysql-connector-java-
x.x.xx.jarなど)をダウンロード、$HIVE_HOME/libに配置
• metastoreへの接続情報を記載 → $HIVE_HOME/conf/hive-site.xml
Copyright (C) Takeshi Mikami. All rights reserved. 66
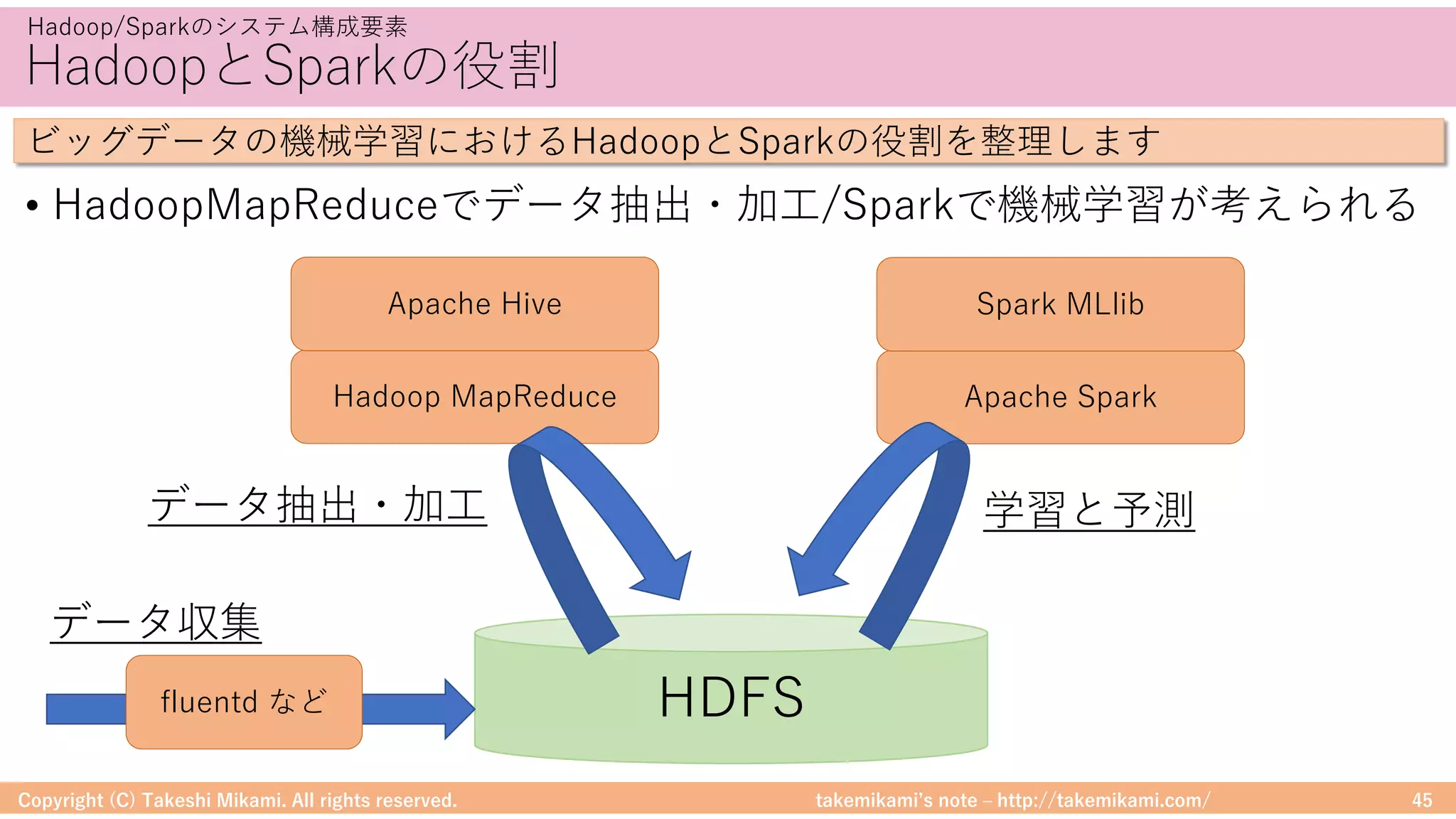
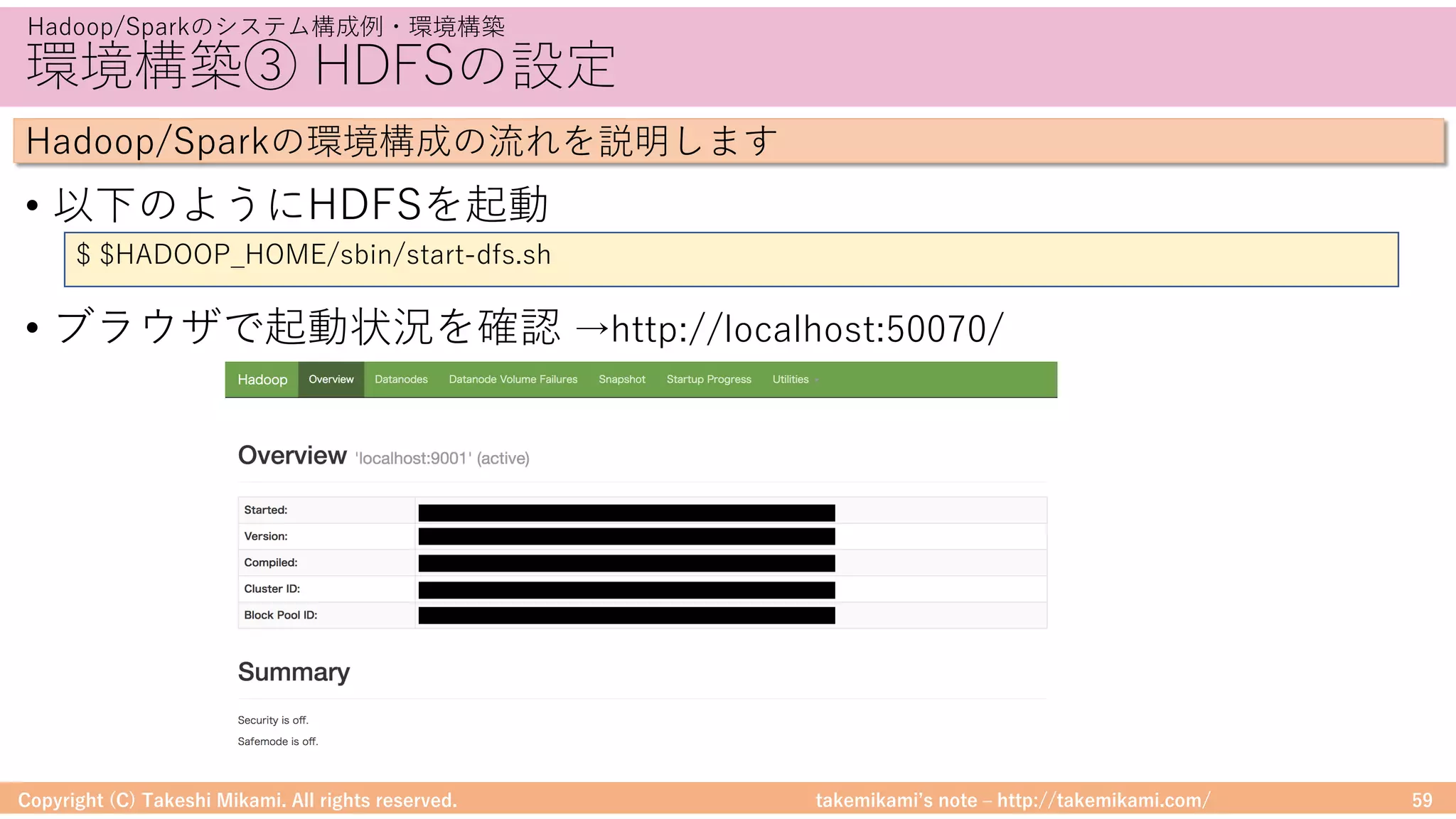
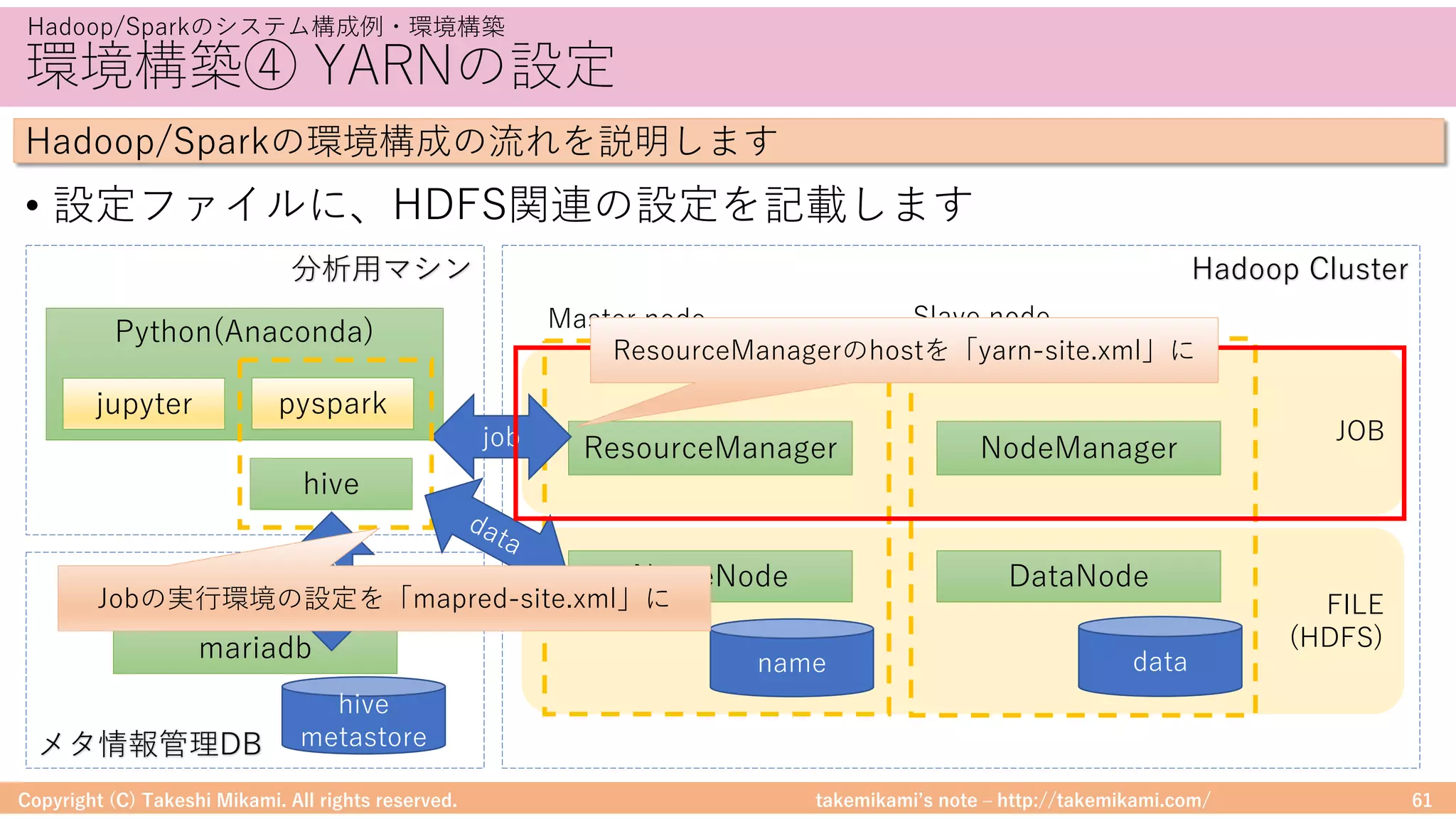
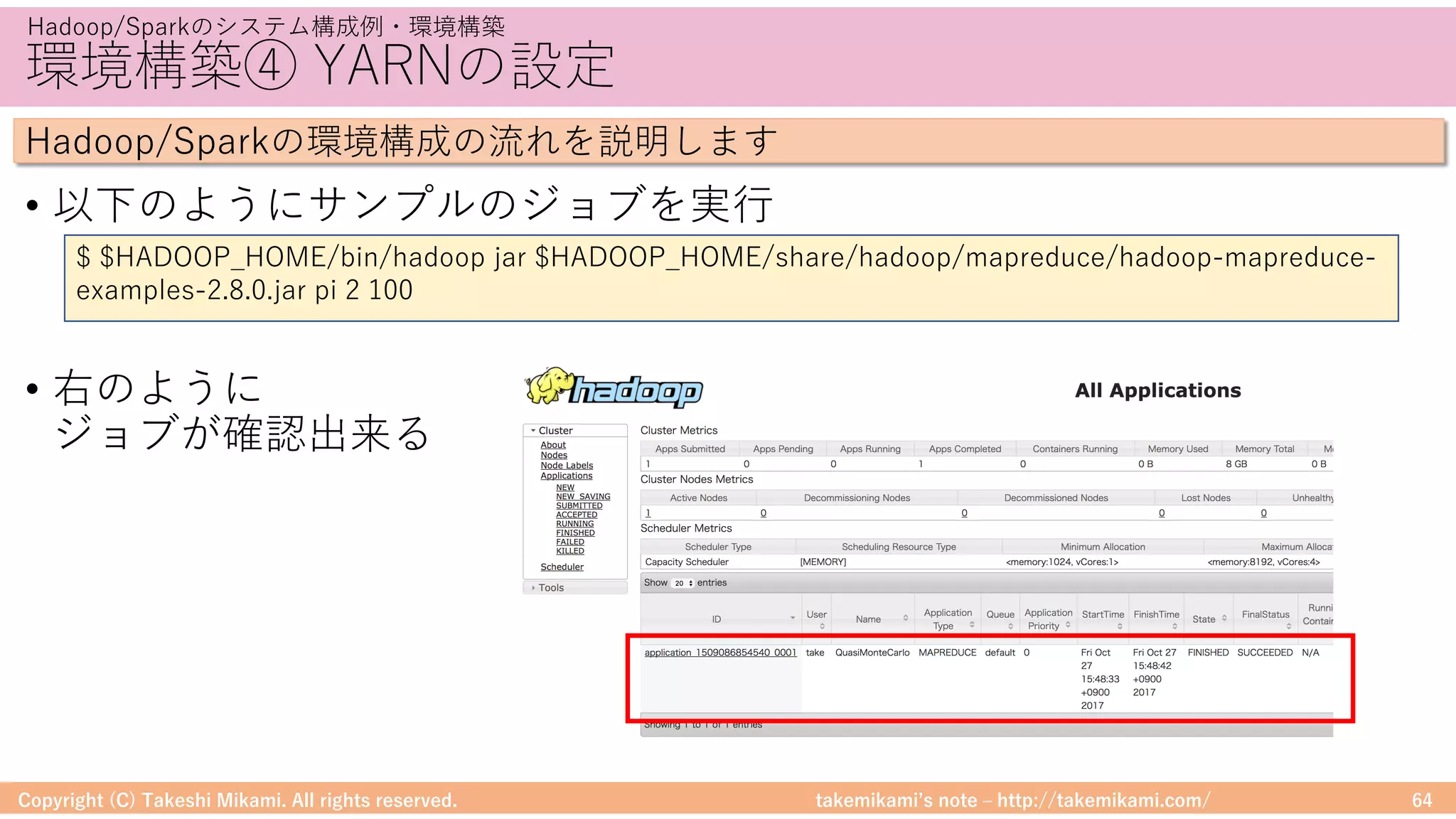
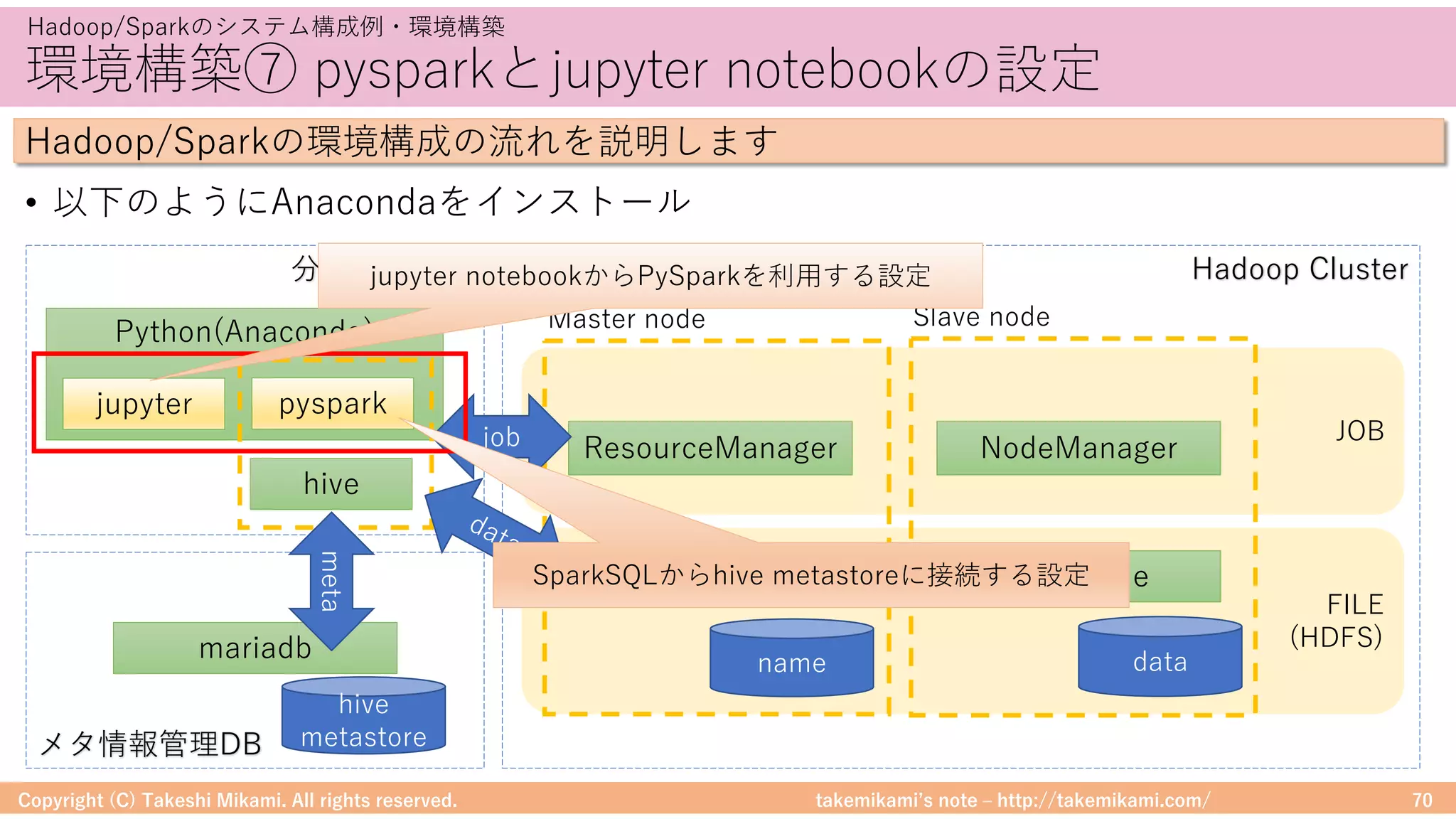
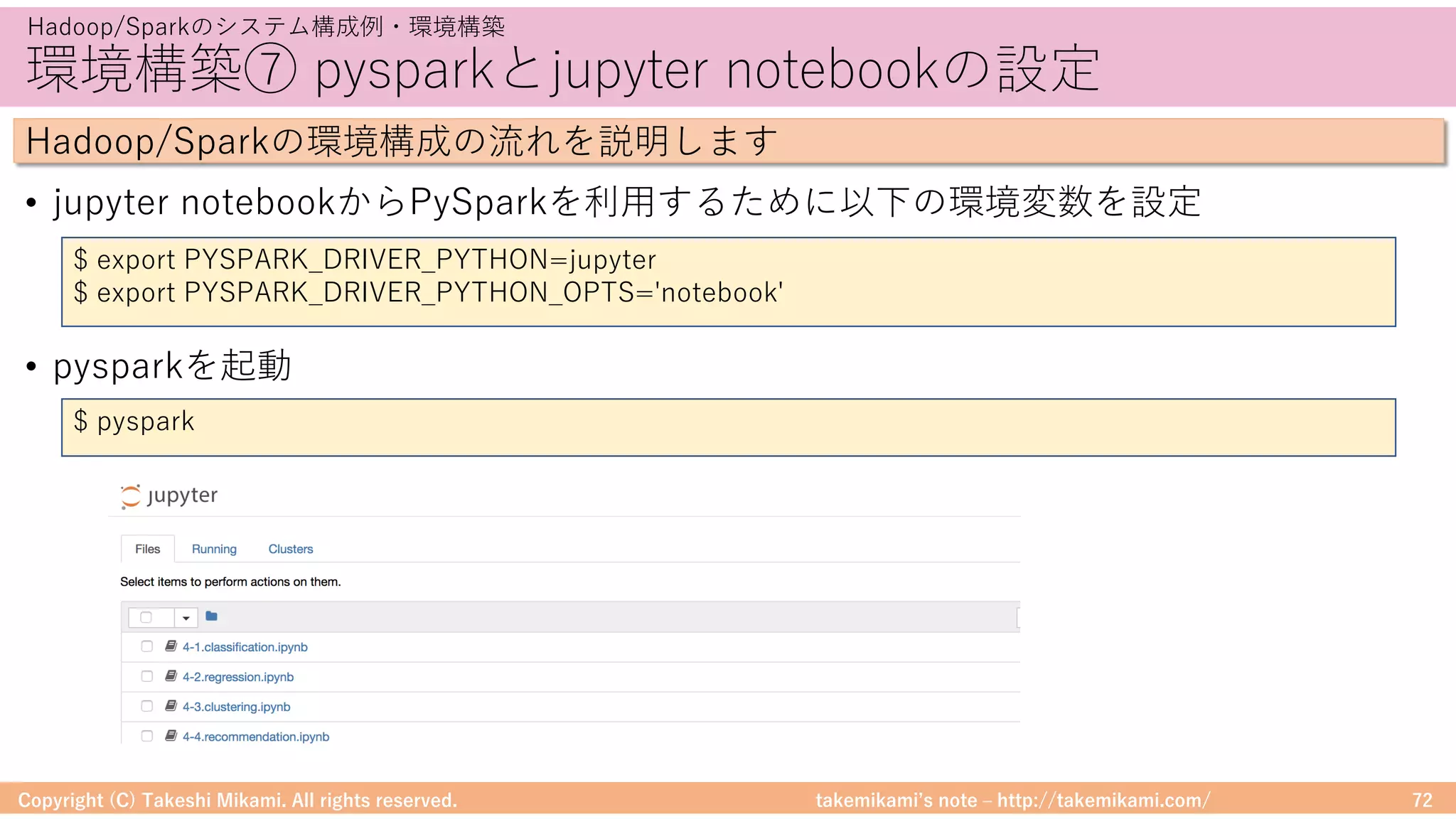
Hadoop/Sparkのシステム構成例・環境構築
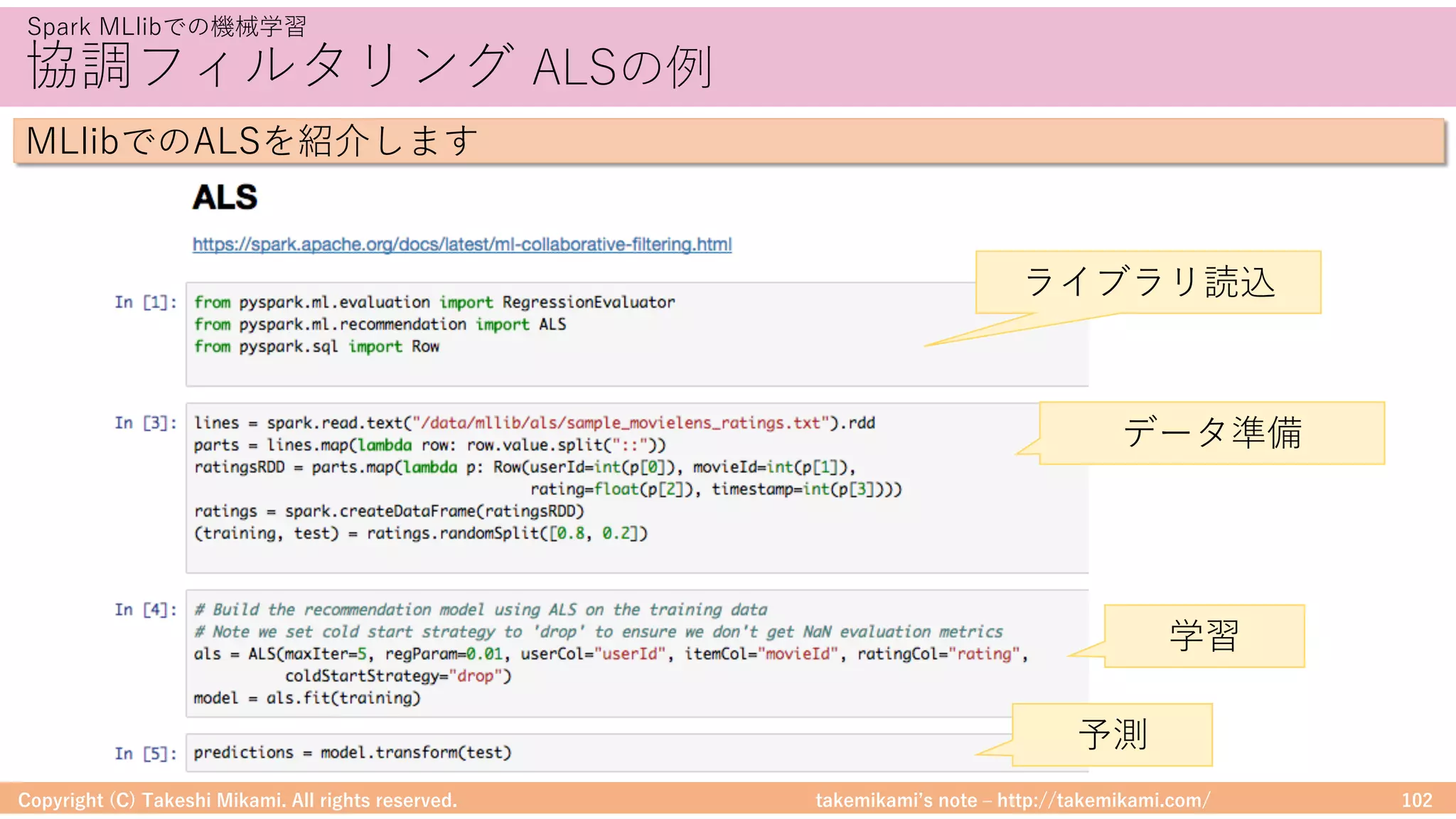
Hadoop/Sparkの環境構成の流れを説明します
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value><![CDATA[jdbc:mysql://localhost/(DB名)?autoReconnect=true&useSSL=false]]></value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property>
<property><name>javax.jdo.option.ConnectionUserName</name><value>(ユーザ)</value></property>
<property><name>javax.jdo.option.ConnectionPassword</name><value>(パスワード)</value></property>
<property><name>datanucleus.fixedDatastore</name><value>false</value></property>
<property><name>hive.exec.local.scratchdir</name><value>/tmp/hive</value></property>
<property><name>hive.downloaded.resources.dir</name><value>/tmp/hive</value></property>
<property><name>hive.querylog.location</name><value>/tmp/hive</value></property>
<property><name>hive.execution.engine</name><value>mr</value></property>](https://image.slidesharecdn.com/sparkml-171028125811/75/SparkMLlib-66-2048.jpg)











![takemikamiʼs note ‒ http://takemikami.com/
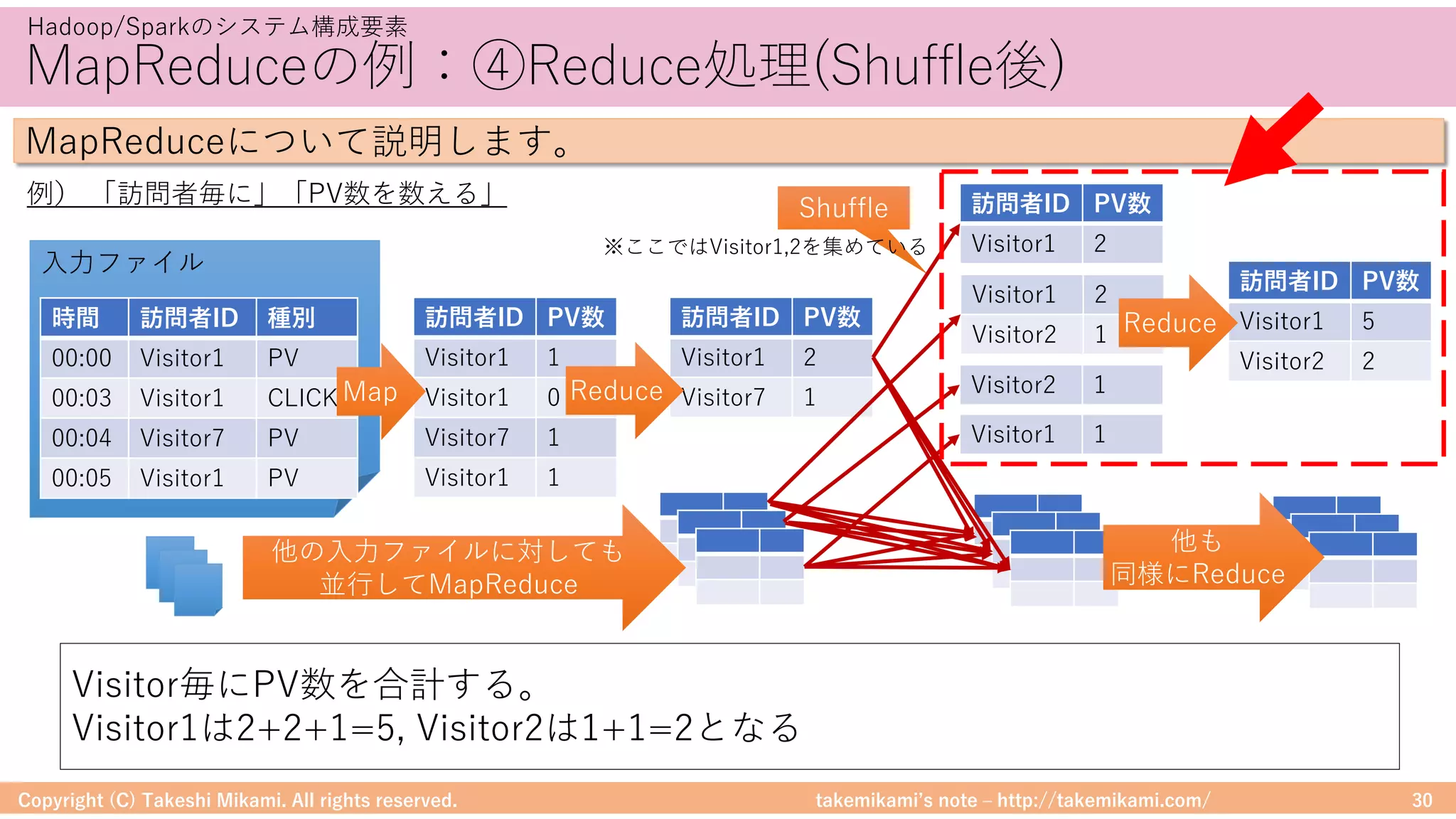
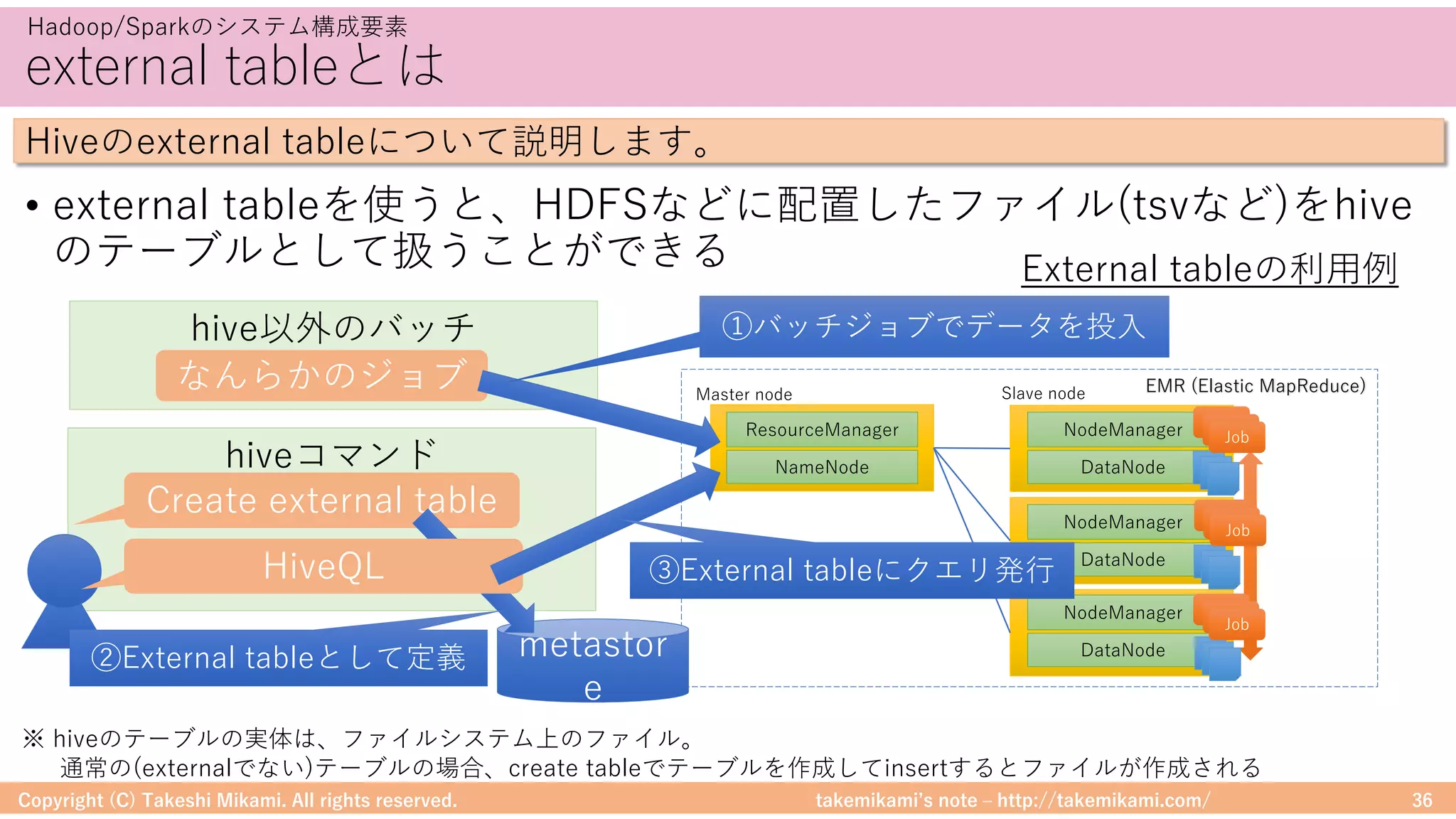
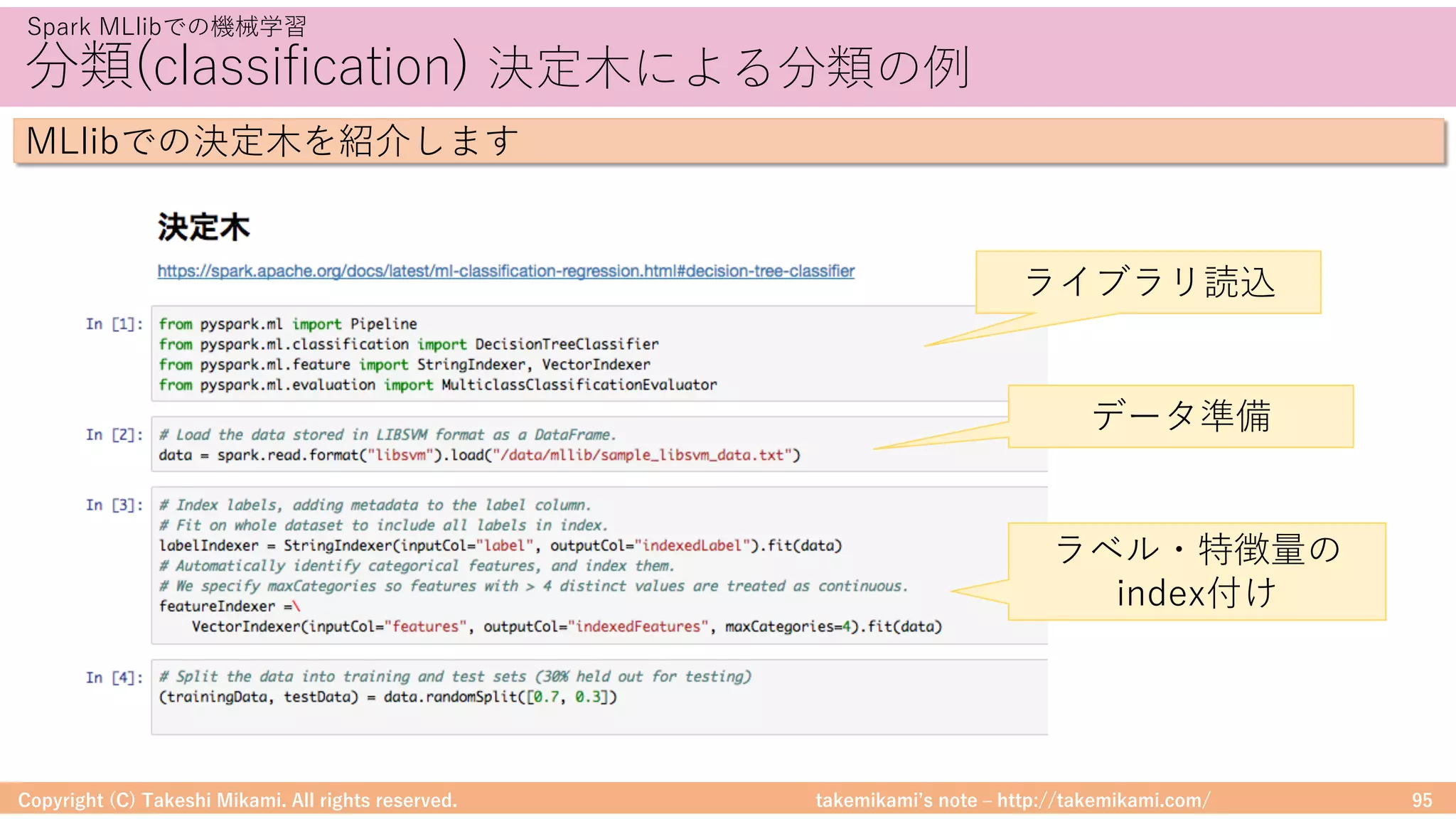
予測精度の評価 RMSEの計算例
Copyright (C) Takeshi Mikami. All rights reserved. 93
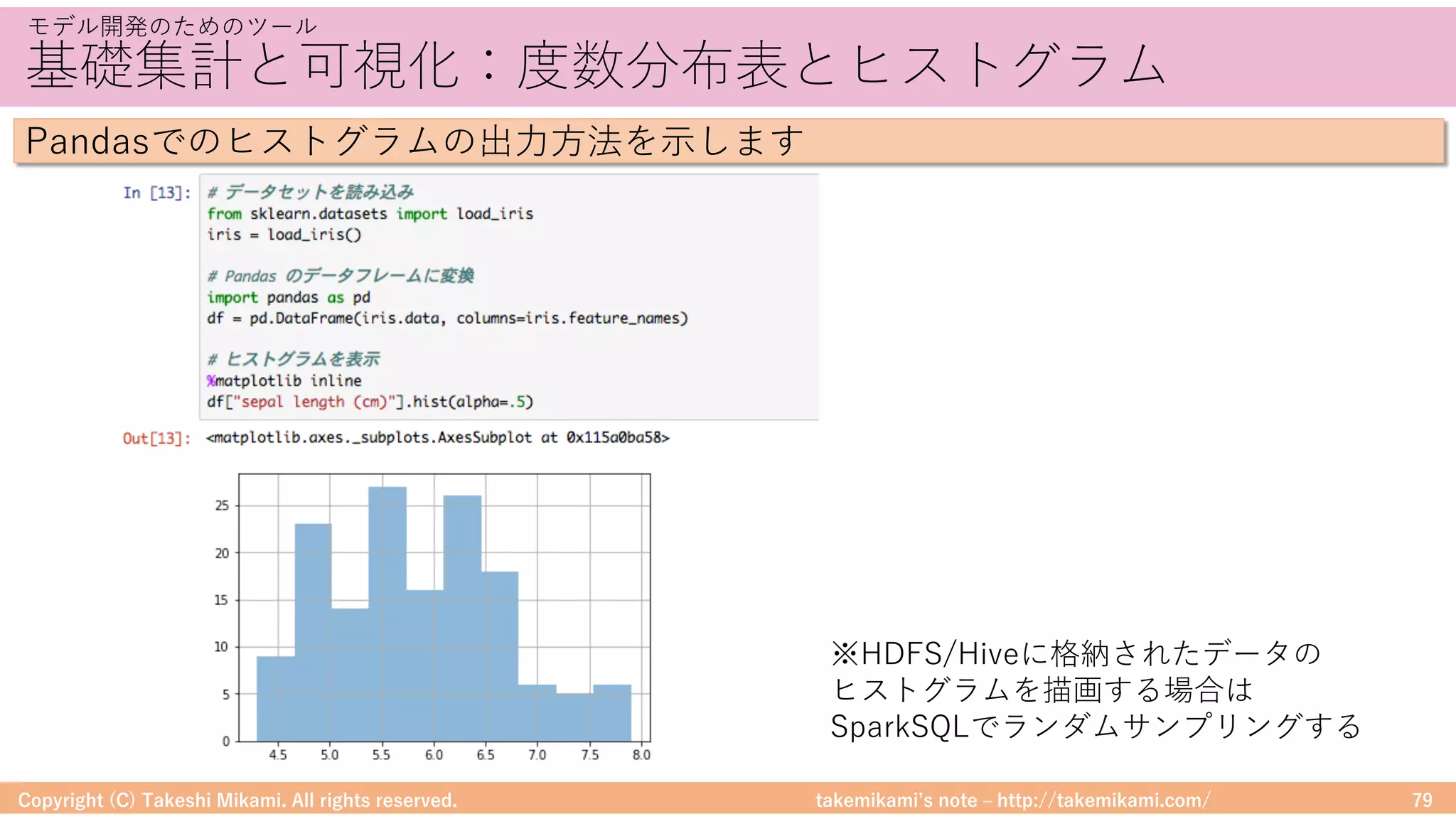
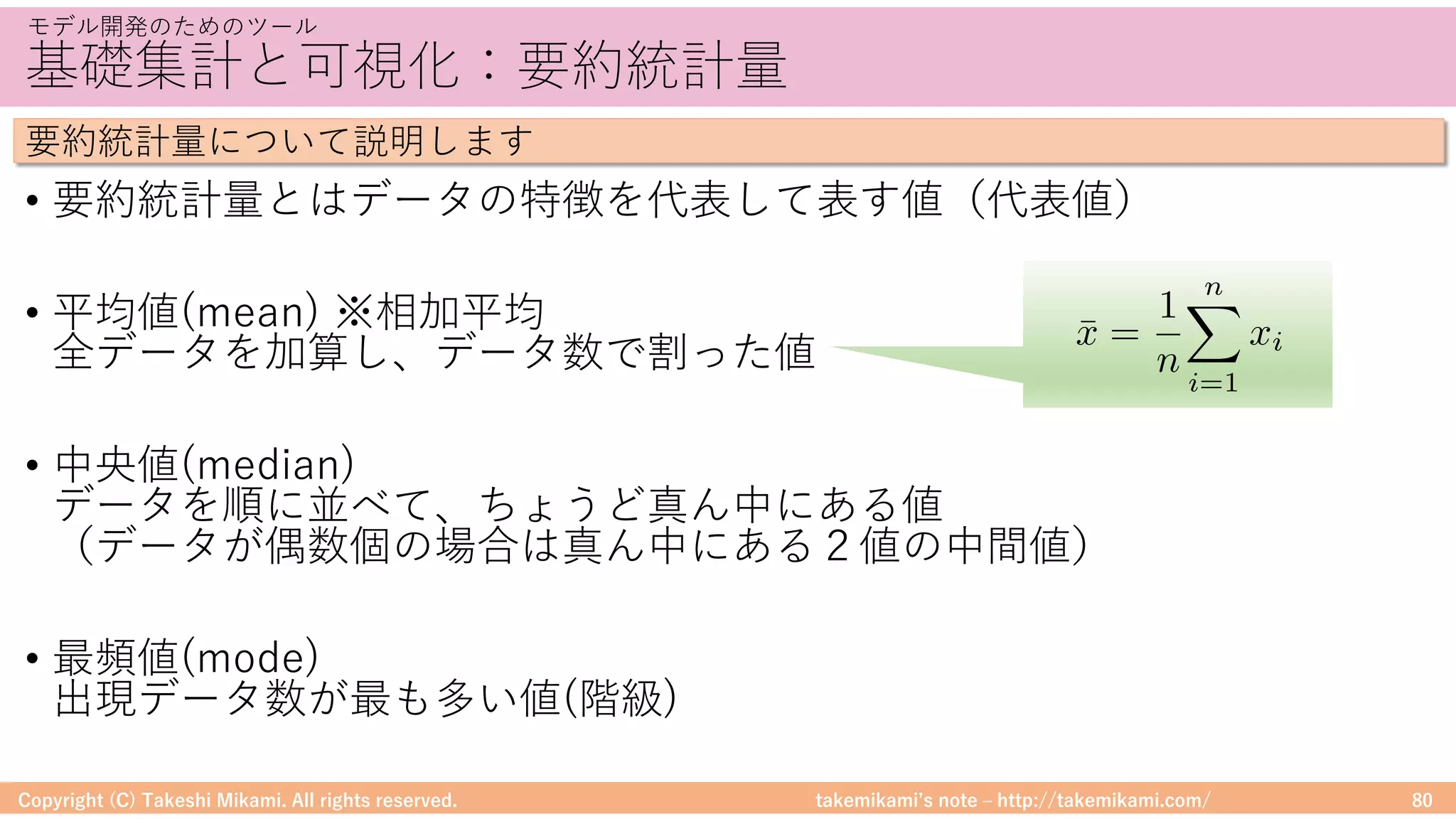
モデル開発のためのツール
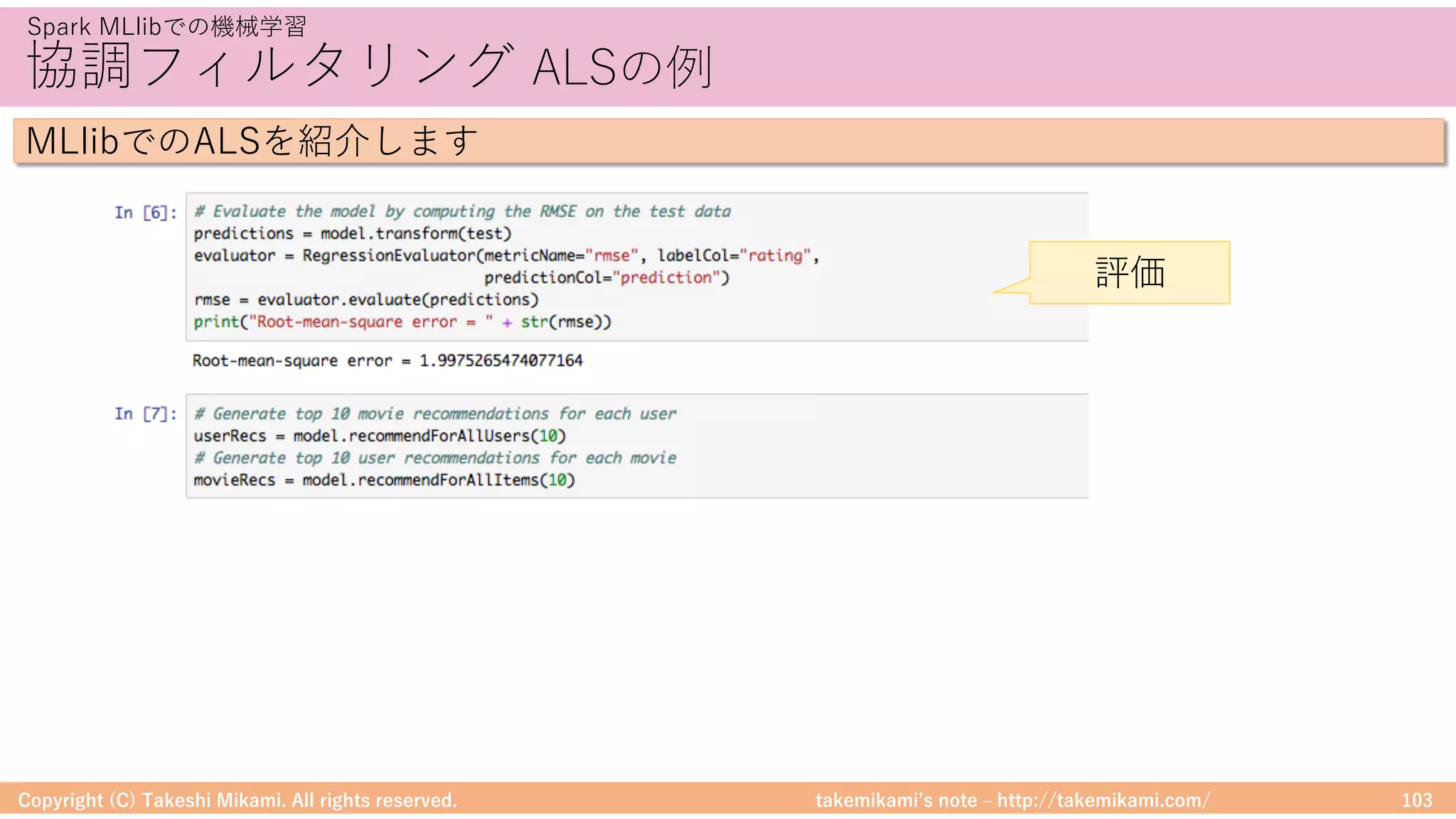
MLlibでの精度評価の例を紹介します
データセットを教師/検証⽤に分割 (8:2)
(training, test) = ratings.randomSplit([0.8, 0.2])
検証⽤/予測値を⽐較して評価 (RMSE)
evaluator = RegressionEvaluator(metricName="rmse",
labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)](https://image.slidesharecdn.com/sparkml-171028125811/75/SparkMLlib-93-2048.jpg)

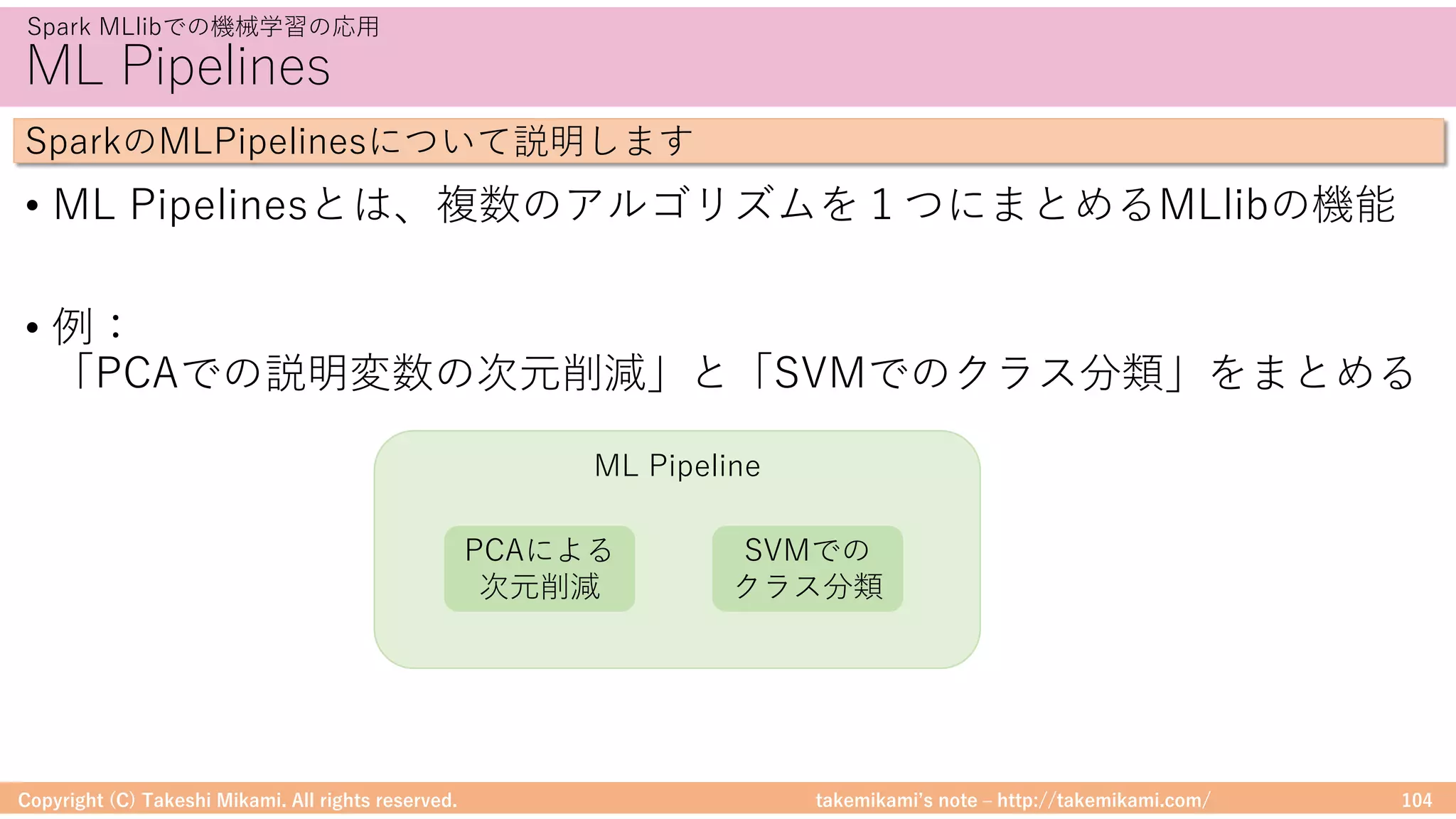


![takemikamiʼs note ‒ http://takemikami.com/
アルゴリズムの実装 Estimatorの実装
• Estimatorのfitに学習のロジックを実装します
Copyright (C) Takeshi Mikami. All rights reserved. 108
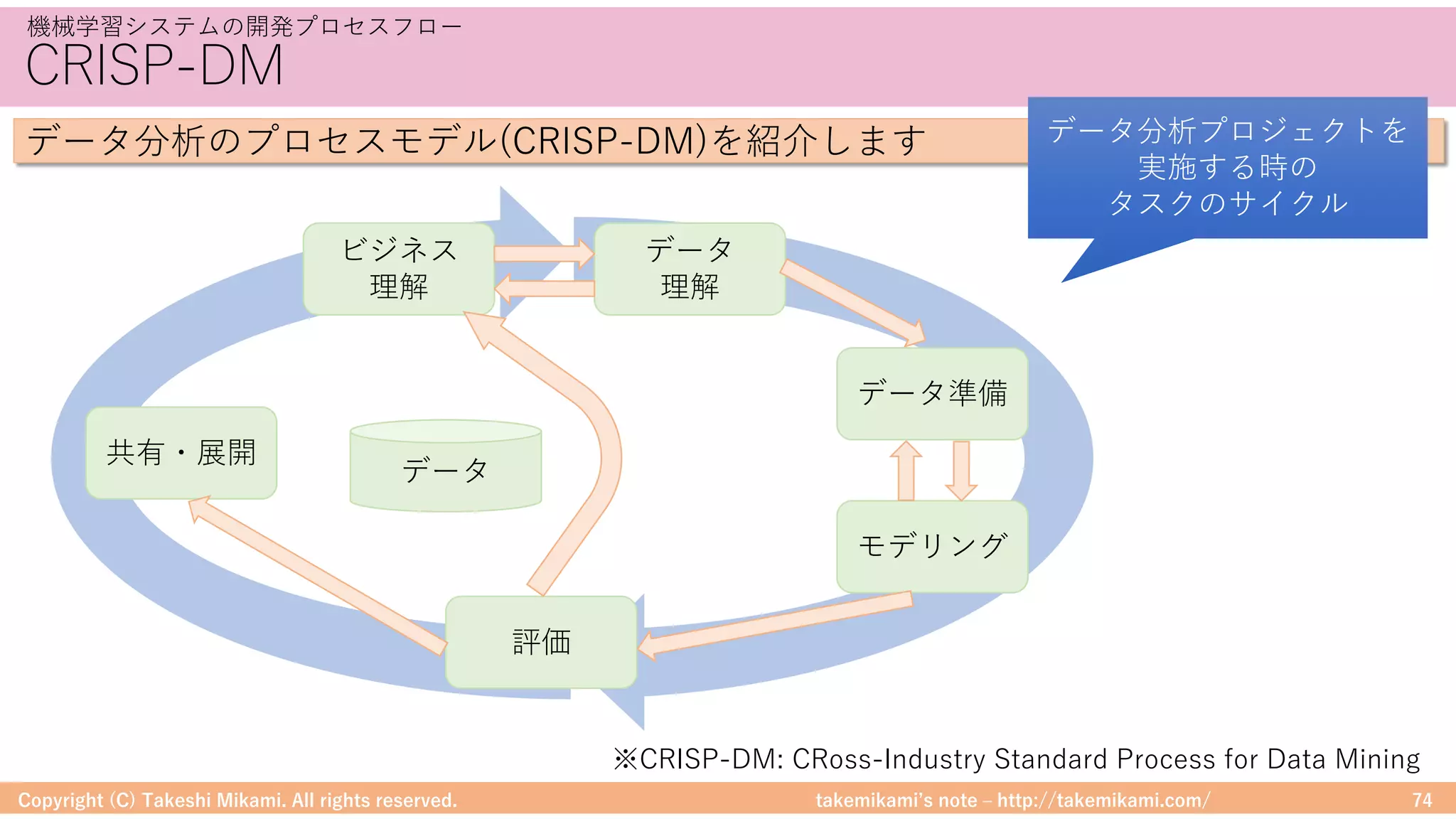
Spark MLlibでの機械学習の応⽤
SparkMLlibに独⾃のアルゴリズムを実装する⽅法を説明します
class MyAlgorithm (override val uid: String)
extends Estimator[MyAlgorithmModel] {
override def fit(dataset: Dataset[_]): MyAlgorithmModel = {
....
val model = new MyAlgorithmModel(....)
copyValues(model)
}
override def copy(extra: ParamMap):MyAlgorithm = defaultCopy(extra)
override def transformSchema(schema: StructType): StructType = {
....
}
}
学習のロジックを実装
IN: DataFrame
OUT: Model](https://image.slidesharecdn.com/sparkml-171028125811/75/SparkMLlib-108-2048.jpg)
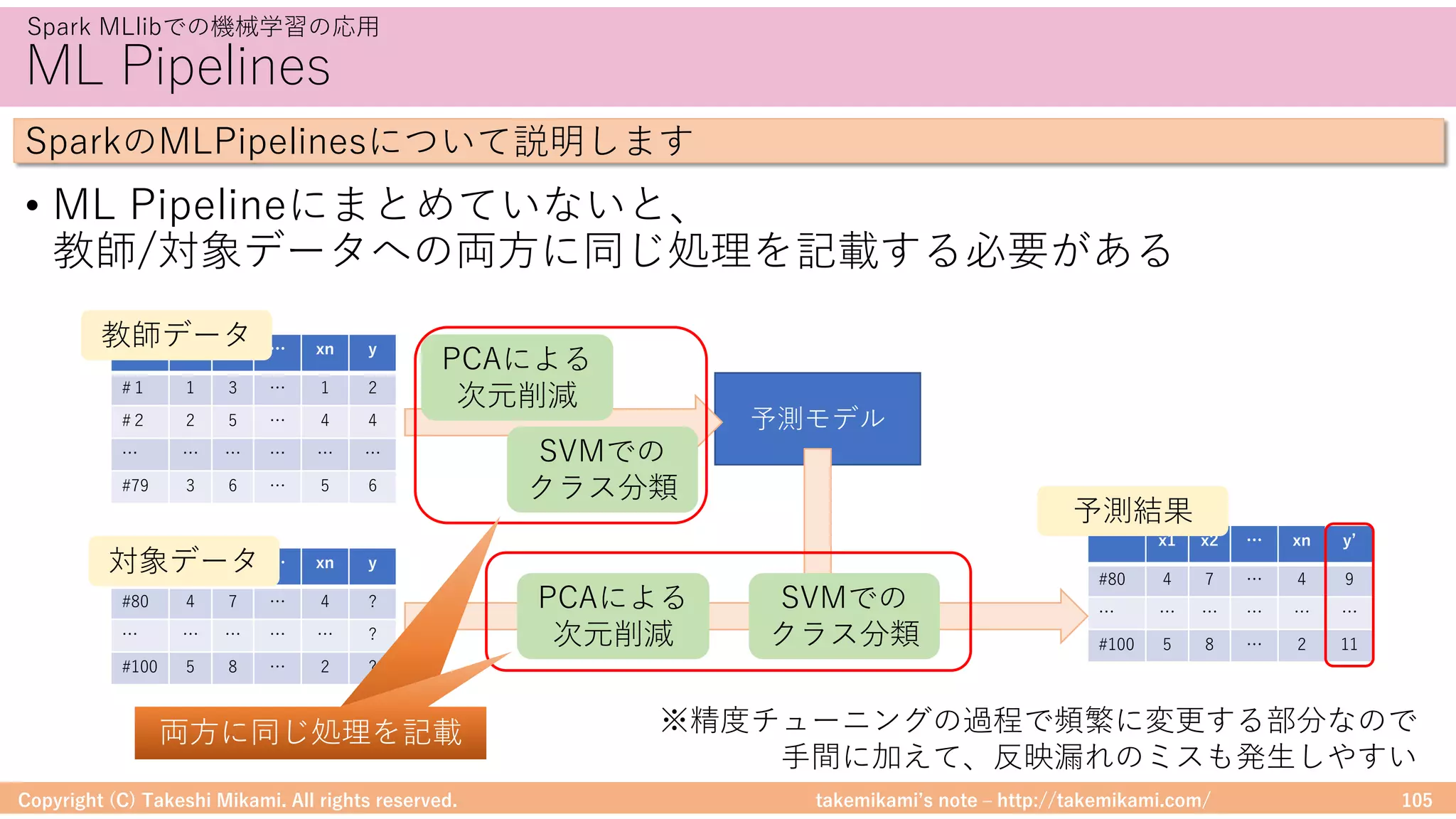
![takemikamiʼs note ‒ http://takemikami.com/
アルゴリズムの実装 Modelの実装
• Modelに予測のロジックを実装します
Copyright (C) Takeshi Mikami. All rights reserved. 109
Spark MLlibでの機械学習の応⽤
SparkMLlibに独⾃のアルゴリズムを実装する⽅法を説明します
class MyAlgorithmModel (override val uid: String, ...)
extends Model[MyAlgorithmModel] {
override def transform(dataset: Dataset[_]): DataFrame = {
....
}
override def copy(extra: ParamMap): MyAlgorithmModel = {
val copied = new MyAlgorithmModel(uid, ...)
copyValues(copied, extra).setParent(parent)
}
override def transformSchema(schema: StructType): StructType = {
....
StructType(schema.fields :+ StructField($(predictionCol), FloatType, false))
}
}
学習のロジックを実装
IN: DataFrame
OUT: DataFrame
DataFrameに追加される
カラムの情報
(通常は予測値のカラム)](https://image.slidesharecdn.com/sparkml-171028125811/75/SparkMLlib-109-2048.jpg)



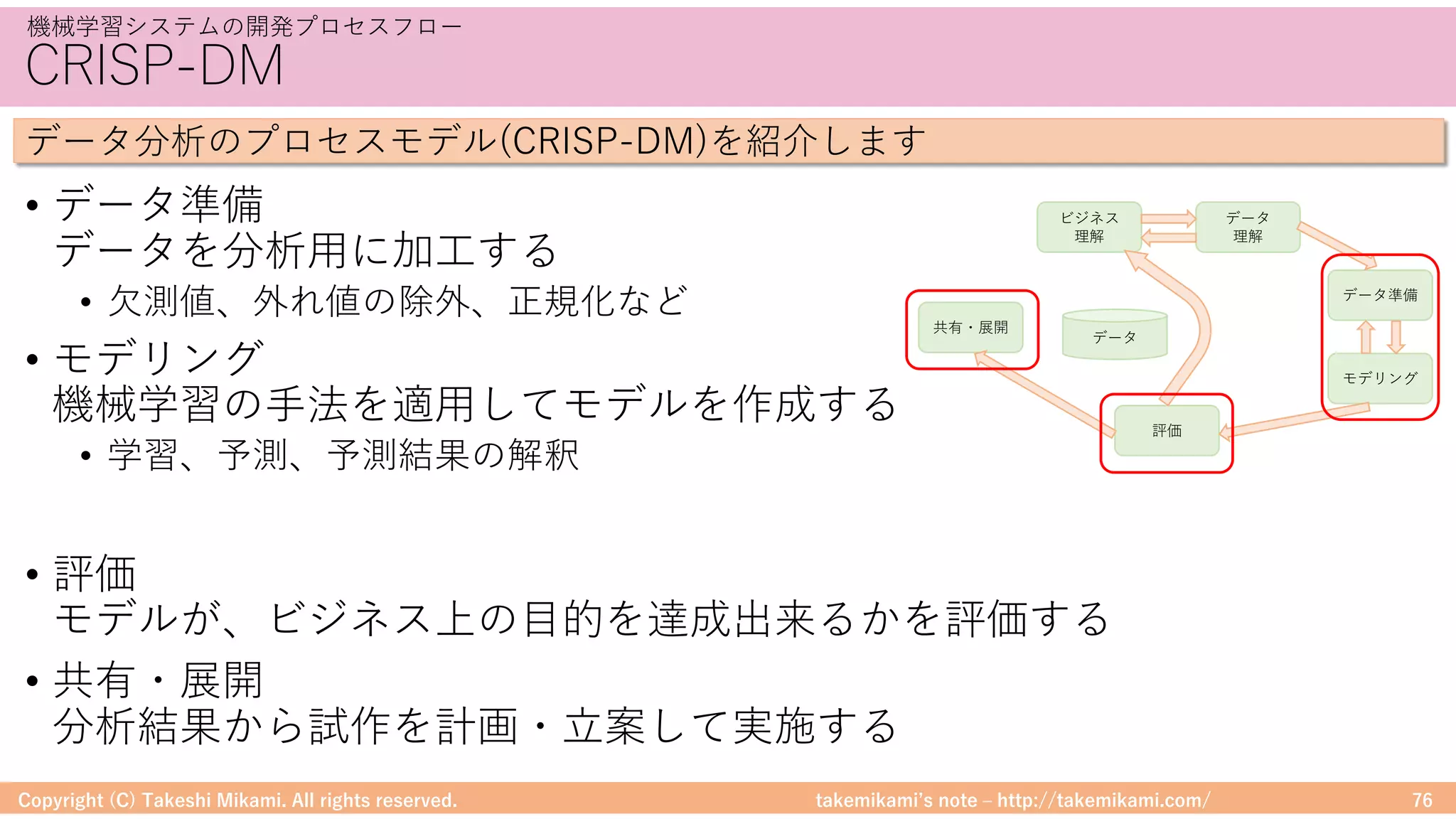
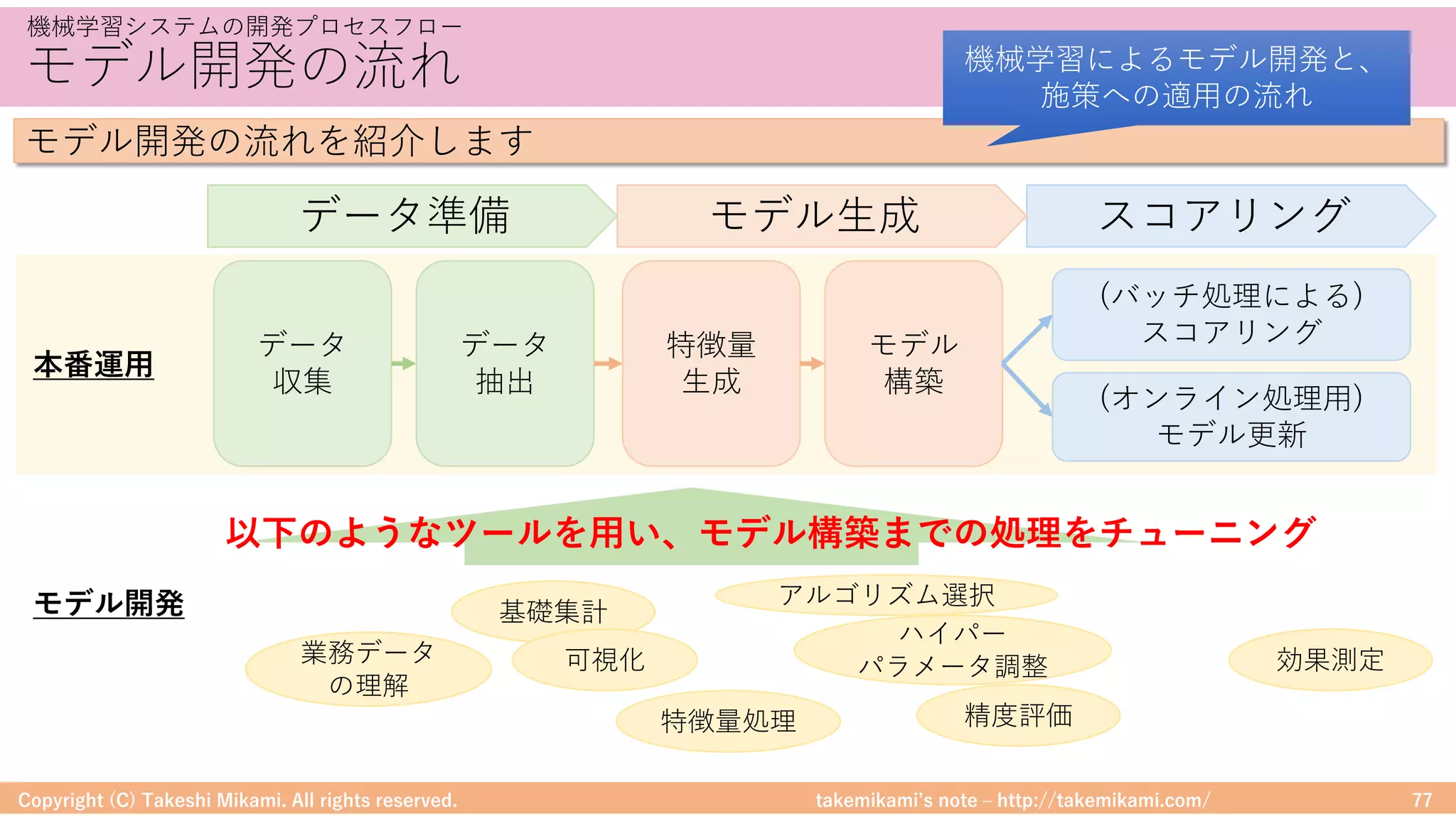
<機械学習及びビッグデータの概要> ・機械学習とビッグデータ ・ビッグデータの概要 Hadoop、Spark、SparkMLlib ・機械学習の概要 データ分析のアプローチ、機械学習の手法 <Hadoop及びSpark MLlibのシステム構成例> ・Hadoop/Sparkのシステム構成要素 Hadoop、Hive、Spark、PySpark、jupyter notebook ・Hadoop/Sparkのシステム構成例・環境構築 システム構成例、環境構築の流れ <機械学習システムの開発プロセス> ・機械学習システムの開発プロセスフロー CRISP-DM、モデル開発の流れ ・モデル開発のためのツール 基礎集計と可視化、特徴量処理、予測精度 <Spark MLlibを使った機械学習の紹介> ・Spark MLlibでの機械学習 分類と回帰、クラスタリング、協調フィルタリング ・Spark MLlibでの機械学習の応用 MLPipelines、アルゴリズムの実装
























![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[db tech showcase Tokyo 2017] AzureでOSS DB/データ処理基盤のPaaSサービスを使ってみよう (Azure Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/20170907dbtechshowcaseazureossdb-170907082746-thumbnail.jpg?width=640&height=640&fit=bounds)








































