Download as PDF, PPTX

















![Insert data
values = [
{'model': 'Ford Festiva',
'registration': 'HAX00R',
'odometer': 3141 },
{'model': 'Lotus Elise',
'registration': 'DELEG8',
'odometer': 31415 },
]
rows = engine.execute(
vehicles_table.insert(),
list(values)).rowcount](https://image.slidesharecdn.com/2013-data-flows-130707014042-phpapp01/85/Building-data-flows-with-Celery-and-SQLAlchemy-22-320.jpg)
![Query data
query = select(
[vehicles_table]
).where(
vehicles_table.c.odometer < 100
)
results = engine.execute(query)
for row in results:
print row](https://image.slidesharecdn.com/2013-data-flows-130707014042-phpapp01/85/Building-data-flows-with-Celery-and-SQLAlchemy-23-320.jpg)





![A Concrete Extract
class SalesHistoryExtract(CSVExtractMixin,
DatabaseProcessor):
target_table_name = 'SalesHistoryExtract'
input_file = SALES_FILENAME
def run(self):
target_table = Table(self.target_table_name,
self.metadata)
columns = self.reader.next()
[target_table.append_column(Column(column, ...))
for column in columns if column]
target_table.create()
insert = target_table.insert()
new_record_count = self.engine.execute(insert,
list(self.reader)).rowcount
return new_record_count](https://image.slidesharecdn.com/2013-data-flows-130707014042-phpapp01/85/Building-data-flows-with-Celery-and-SQLAlchemy-29-320.jpg)
![A Concrete Transform
from business_logic import derive_foo
class DeriveFooTransform(AbstractDeriveTransform):
table_name = 'SalesTransform'
key_columns = ['txn_id']
select_columns = ['location', 'username']
target_columns = [Column('foo', FOO_TYPE)]
def process_row(self, row):
foo = derive_foo(row.location, row.username)
return {'foo': foo}](https://image.slidesharecdn.com/2013-data-flows-130707014042-phpapp01/85/Building-data-flows-with-Celery-and-SQLAlchemy-31-320.jpg)


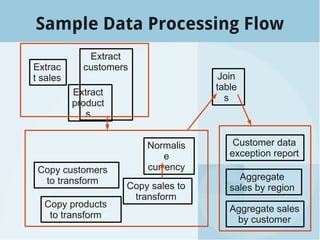

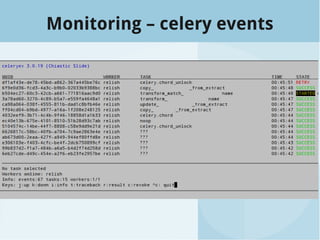
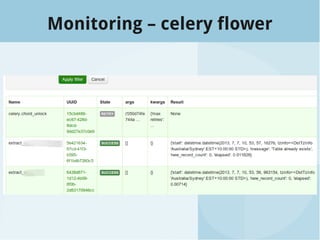





The document presents a talk by Roger Barnes on building data flows utilizing Celery and SQLAlchemy, highlighting their application in data warehousing. It covers the importance of timely and accurate reporting, introduces key concepts of SQLAlchemy and Celery for processing and managing data, and illustrates creating and managing data workflows. Additionally, it discusses how to structure and monitor tasks to enhance data processing efficiency.