Download as PDF, PPTX















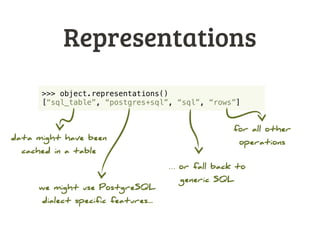
![Representations
>>> object.representations()
[“sql_table”, “postgres+sql”, “sql”, “rows”]
data might have been
cached in a table
we might use PostgreSQL
dialect specific features...
… or fall back to
generic SQL
for all other
operations](https://image.slidesharecdn.com/databrewery2-dataobjects-130605022102-phpapp01/85/Bubbles-Virtual-Data-Objects-17-320.jpg)





![List of Objects
@operation(“sql[]”)
def append(context, objects):
...
@operation(“rows[]”)
def append(context, objects):
...
matches one of common representations
of all objects in the list](https://image.slidesharecdn.com/databrewery2-dataobjects-130605022102-phpapp01/85/Bubbles-Virtual-Data-Objects-24-320.jpg)







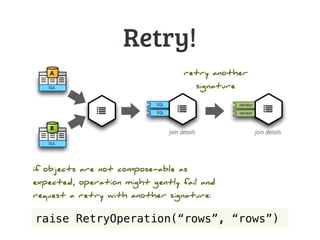













![Filtering
■ row filters
filter_by_value, filter_by_set, filter_by_range
■ field_filter(ctx, obj, keep=[], drop=[], rename={})
keep, drop, rename fields
■ sample(ctx, obj, value, mode)
first N, every Nth, random, …](https://image.slidesharecdn.com/databrewery2-dataobjects-130605022102-phpapp01/85/Bubbles-Virtual-Data-Objects-47-320.jpg)











This document describes Bubbles, a Python framework for data processing and quality probing. Bubbles focuses on representing data objects and defining operations that can be performed on those objects. Key aspects include: - Data objects define the structure and representations of data without enforcing a specific storage format. - Operations can be performed on data objects and are dispatched dynamically based on the objects' representations. - A context stores available operations and handles dispatching. - Stores provide interfaces to load and save objects from formats like SQL, CSV, etc. - Pipelines allow sequencing operations to transform and process objects from source to target stores. - The framework includes common operations for filtering, joining, aggreg

































































