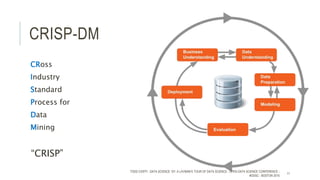
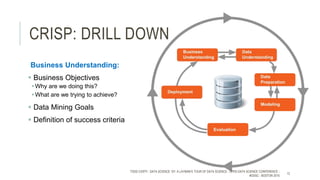
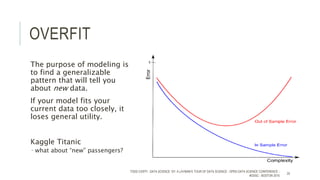
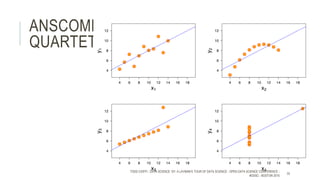
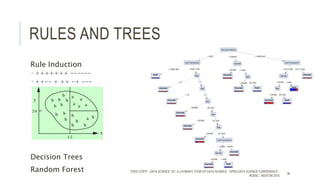
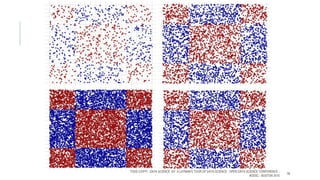
The document provides an introductory overview of data science and its key concepts, including terminology, analytics stages, and various tools used in the field. It emphasizes the importance of understanding data, modeling, and the methodologies involved in data analysis, particularly through a structured approach like CRISP-DM. Key topics include the types of analytics, data visualization, and the modeling process to derive insights for business decisions.




















































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























































































