Downloaded 31 times






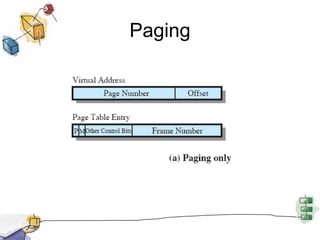

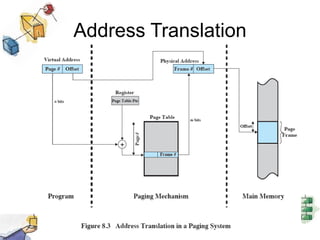
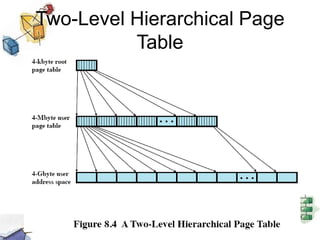
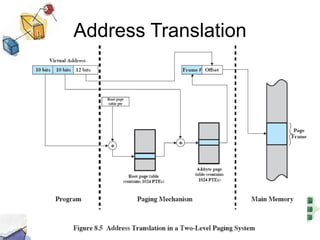

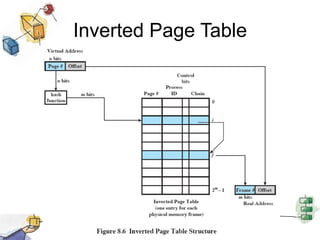



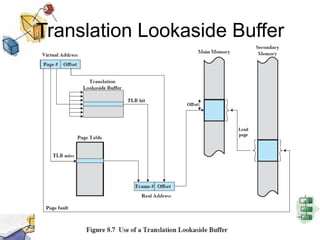
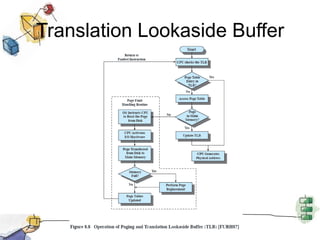
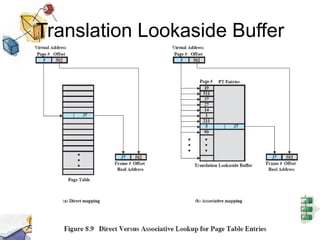
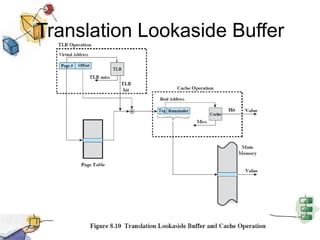



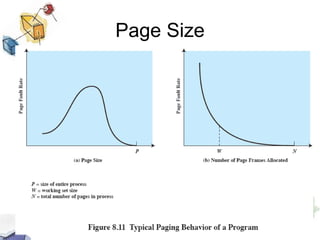

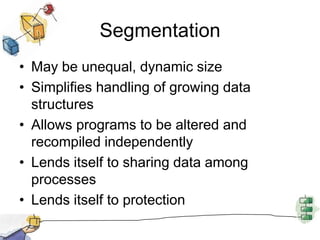

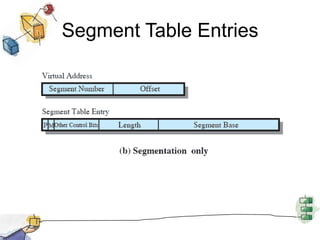
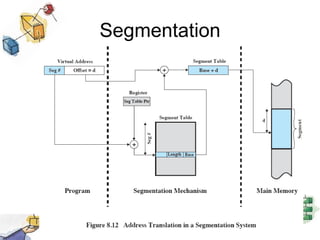

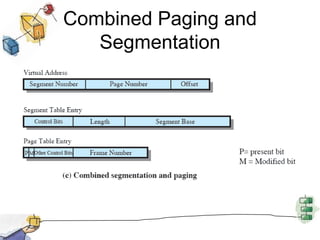
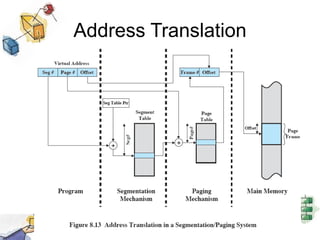
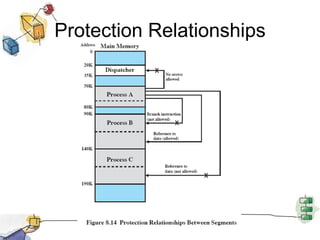







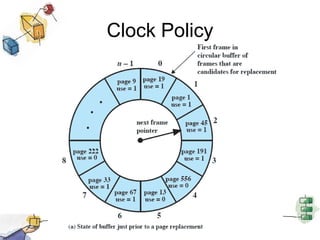
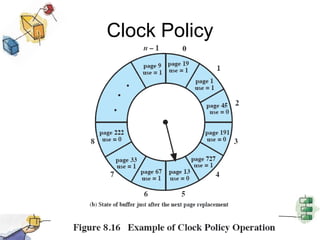












Virtual memory allows processes to be larger than physical memory by storing portions of processes that don't fit in RAM on disk. When a process attempts to access memory not currently in RAM, a page fault occurs, swapping the needed page in from disk while another process runs. Hardware and software mechanisms like page tables, TLBs, and replacement algorithms efficiently manage mapping virtual addresses to physical locations and swapping pages between disk and RAM. This improves system utilization by allowing many processes to reside partially in memory simultaneously.



































































