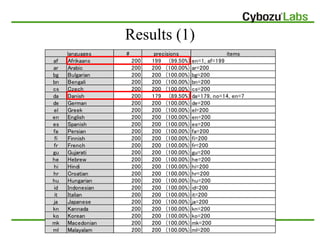
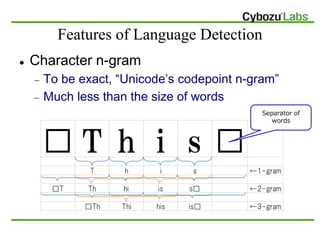
The document describes a language detection library that can detect the language of texts with over 99% precision for 49 languages. It uses a Naive Bayes algorithm and character n-grams as features to classify texts into language categories. The library is open source and available for Java. It was tested on over 9,000 news articles in 49 languages with an accuracy of 99.77%.


























![References
[Habash 2009] Introduction to Arabic Natual Language Processing
http://www.medar.info/conference_all/2009/Tutorial_1.pdf
[Dunning 1994] Statistical Identification of Language
[Sibun & Reynar 1996] Language identification: Examining the issues
[Martins+ 2005] Language Identification in Web Pages
千野栄一編「世界のことば100語辞典 ヨーロッパ編」
町田和彦編「図説 世界の文字とことば」
世界の文字研究会「世界の文字の図典」
町田和彦「ニューエクスプレス ヒンディー語」
中村公則「らくらくペルシャ語 文法から会話」
道広勇司「アラビア系文字の基礎知識」
http://moji.gr.jp/script/arabic/article01.html
北研二,辻井潤一「確率的言語モデル」](https://image.slidesharecdn.com/languagedetection-101203030754-phpapp01/85/Language-Detection-Library-for-Java-29-320.jpg)

































































![ACL2014 Reading: [Zhang+] "Kneser-Ney Smoothing on Expected Count" and [Pickh...](https://cdn.slidesharecdn.com/ss_thumbnails/kneser-neyacl2014-140711113350-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




















