Downloaded 11 times
































![Solution
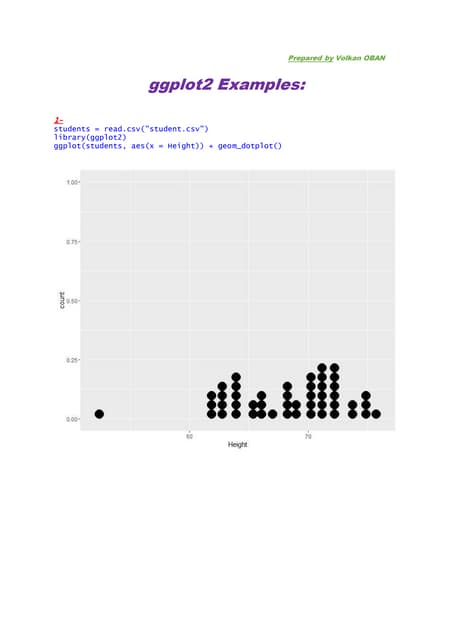
val topKeys = data2
.mapValues(x => 1L)
.reduceByKey(_ + _)
.takeOrdered(10)(Ordering[(String, Long)].on(_._2).reverse)
.toMap
.keys
val topData1 = sc.broadcast(
data1.filter(r => topKeys.contains(r._1)).collect.toMap
)
val bottomData1 = data1.filter(r => !topKeys.contains(r._1))
val topJoin = data2.flatMap { case (k, v2) =>
topData1.value.get(k).map(v1 => k -> (v1, v2))
}
topJoin ++ bottomData1.join(data2)](https://image.slidesharecdn.com/170606sparksummitkexinxieyacovsalomon-170623180903/75/Scaling-up-data-science-applications-36-2048.jpg)

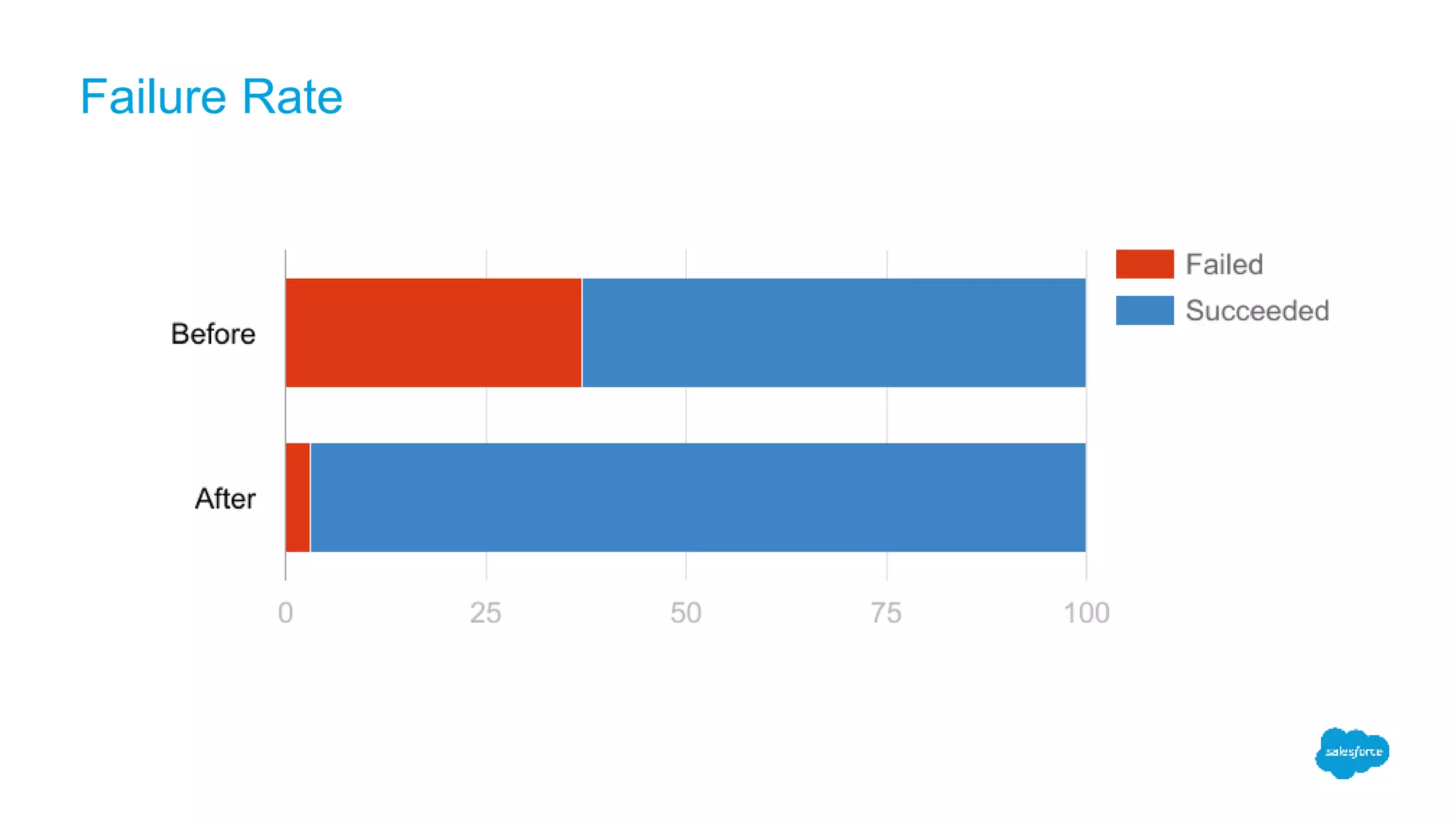




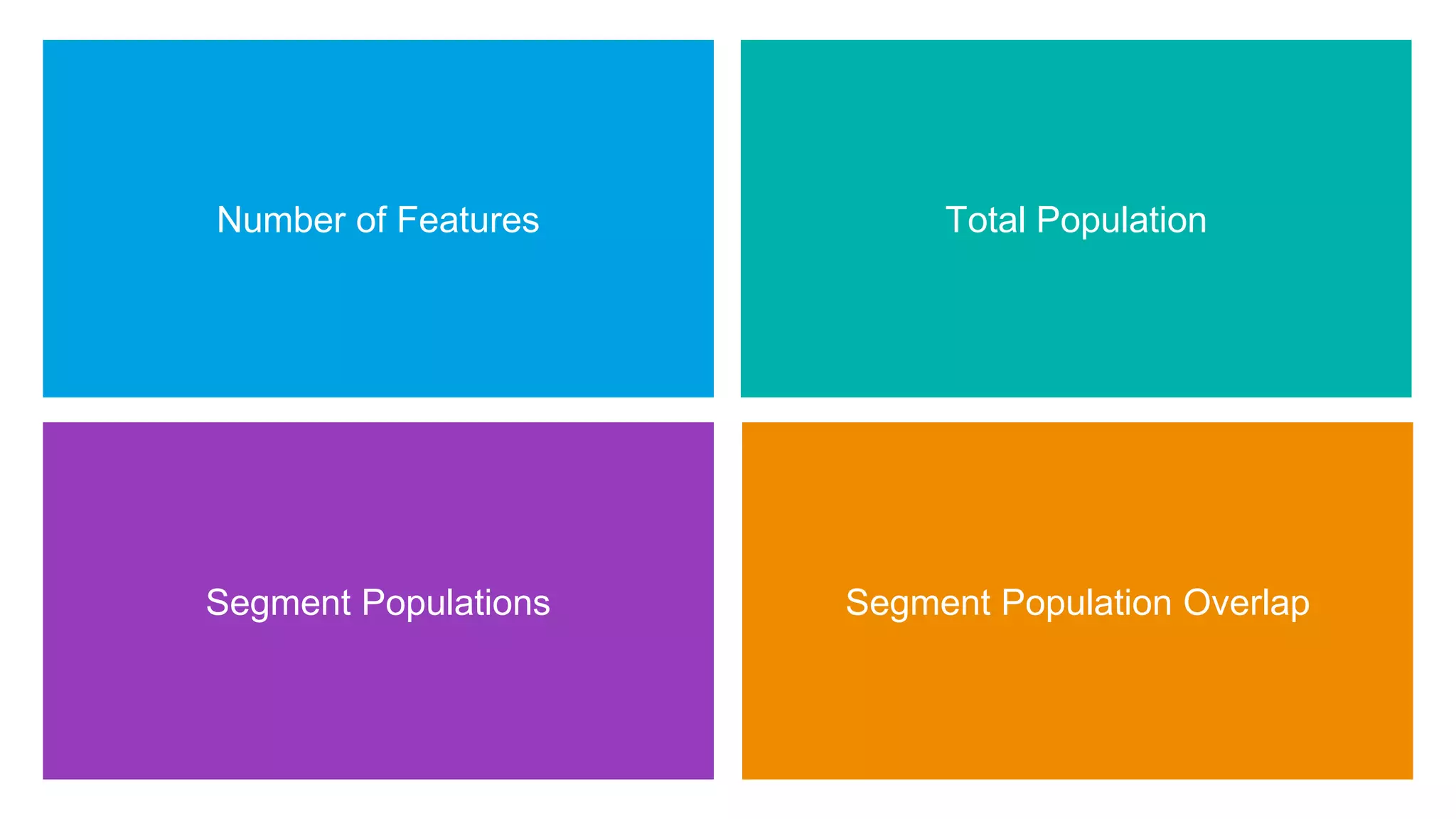
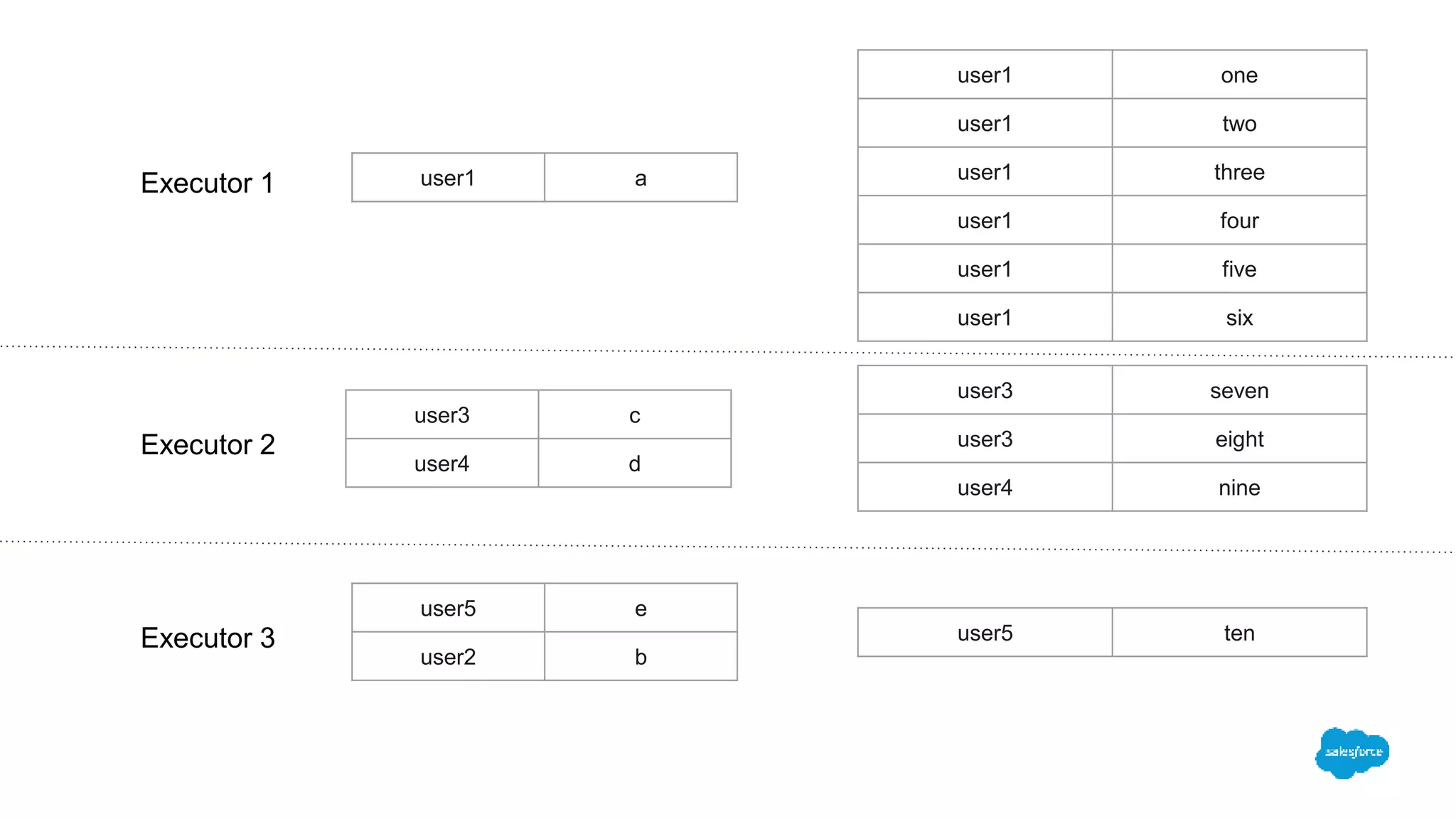
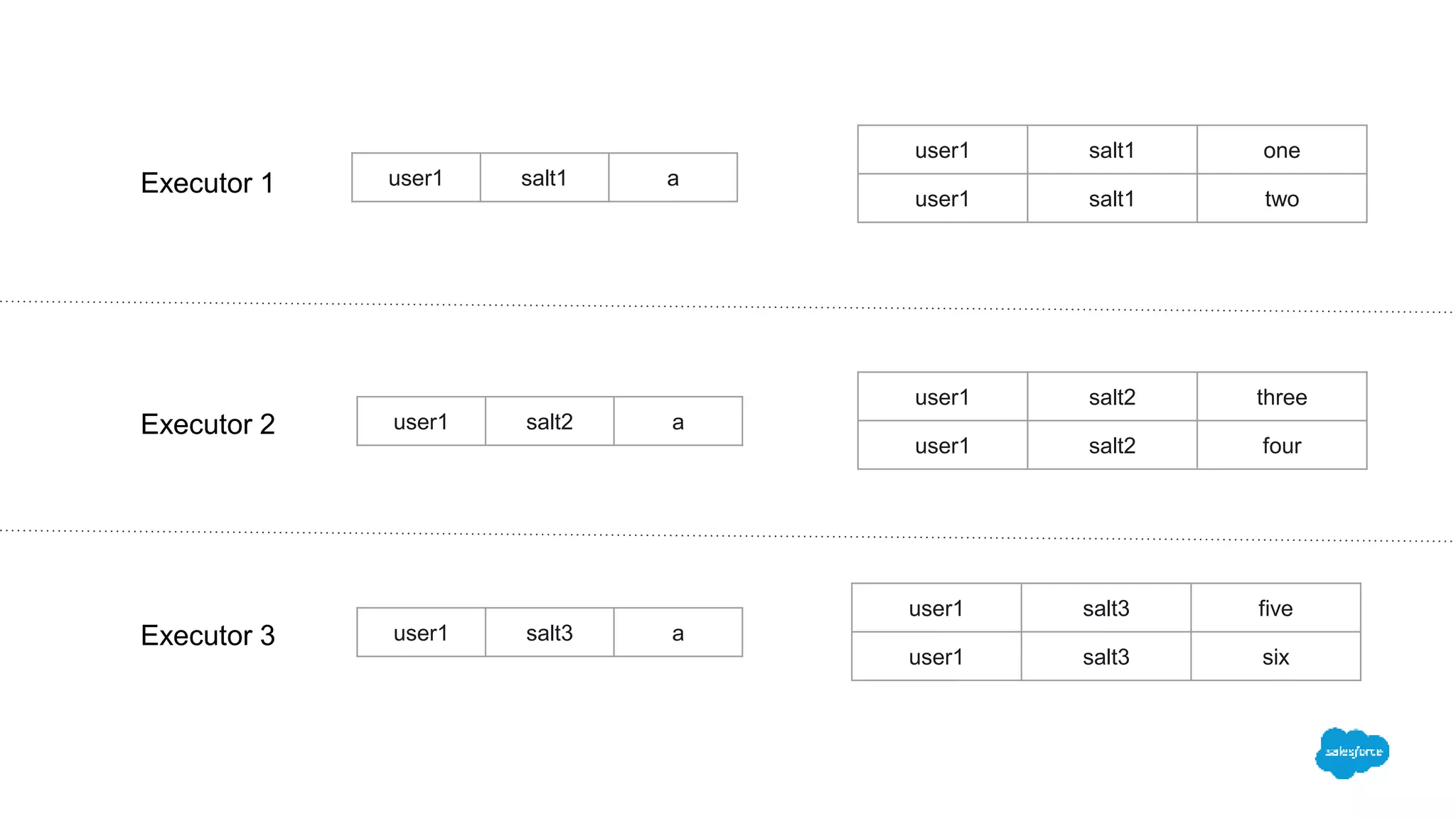
The document discusses how switching to Apache Spark enhanced the performance, reliability, and cost-efficiency of data science applications at Salesforce. It highlights the challenges of handling large datasets and user segment overlaps, while presenting solutions for optimizing data retrieval and processing. The transition resulted in significant reductions in processing time and data handling costs when managing complex data operations.

















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


