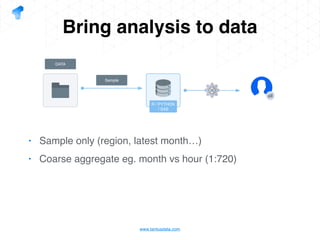
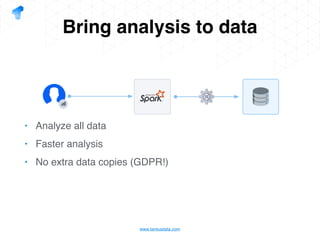
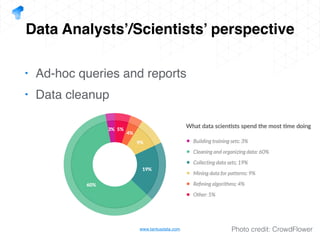
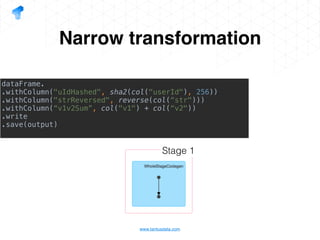
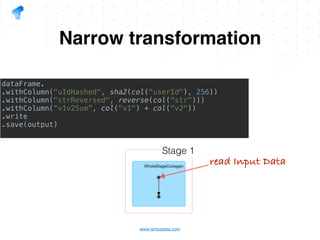
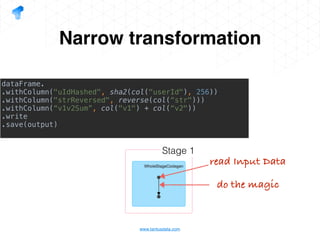
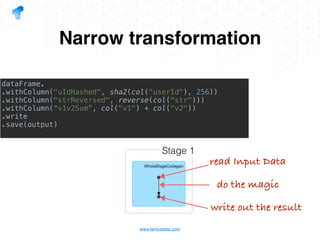
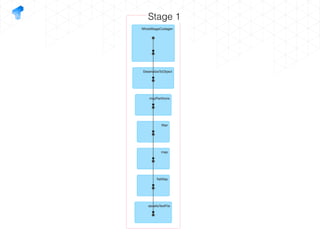
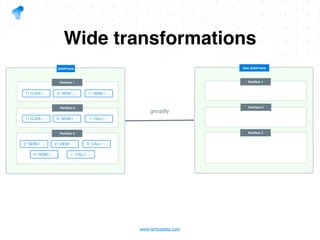
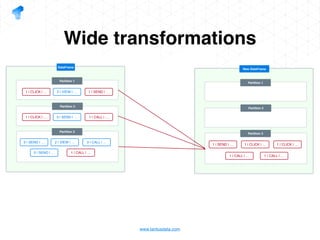
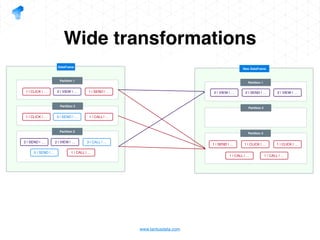
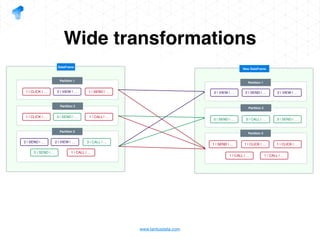
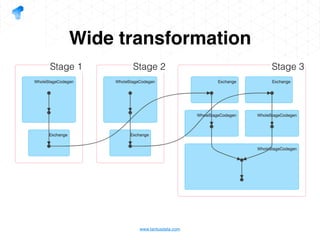
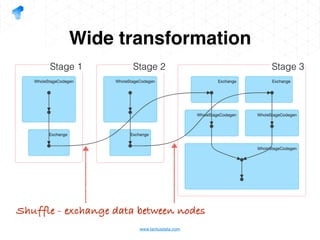
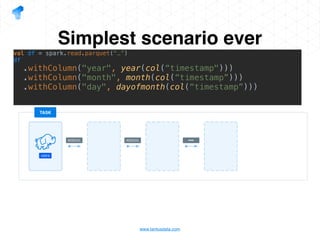
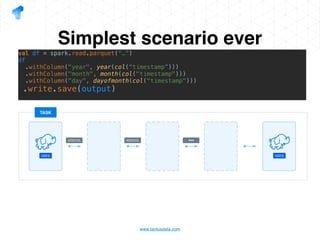
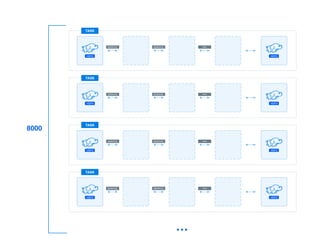
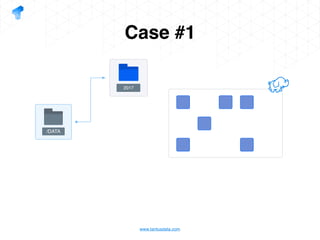
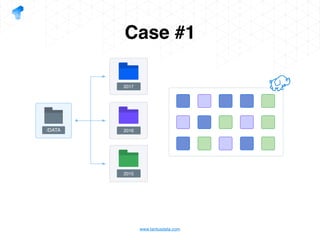
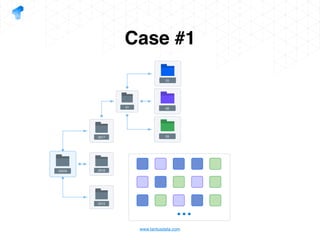
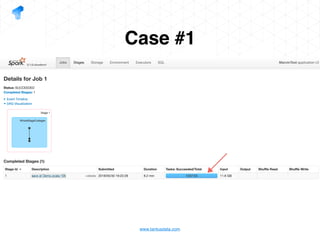
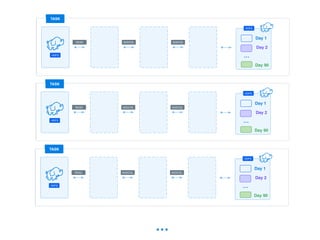
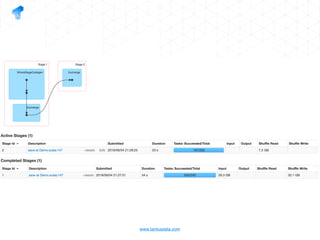
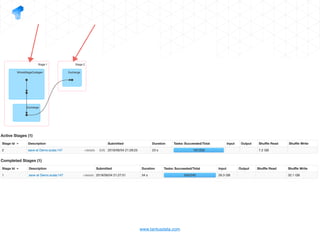
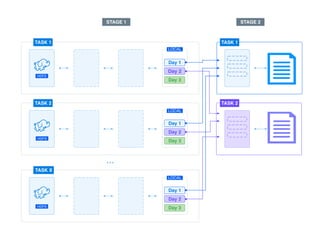
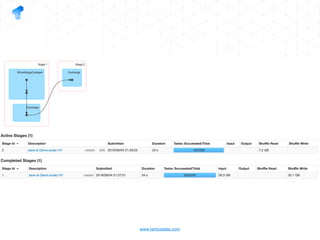
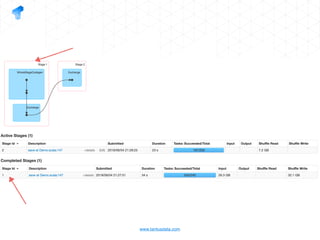
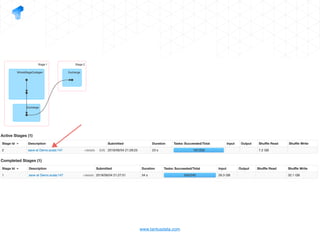
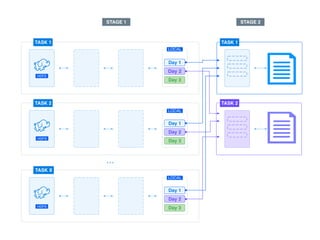
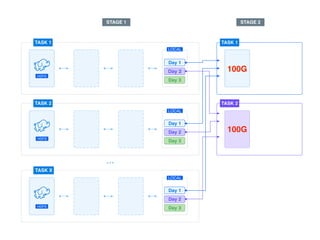
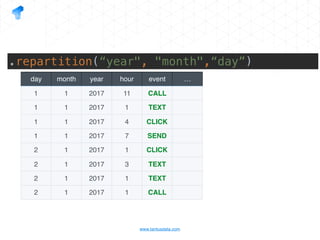
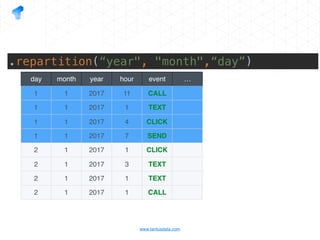
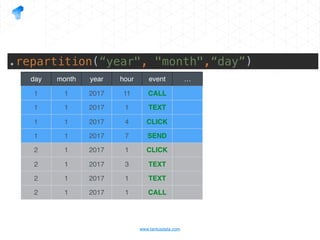
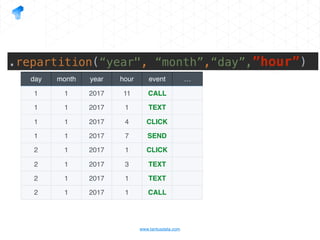
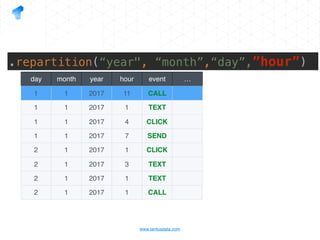
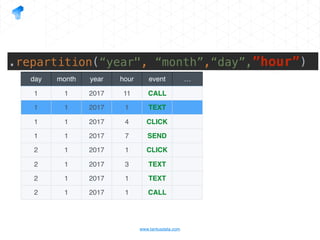
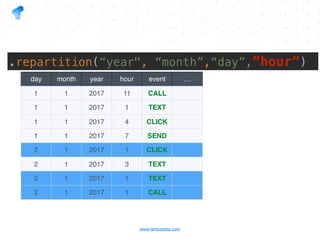
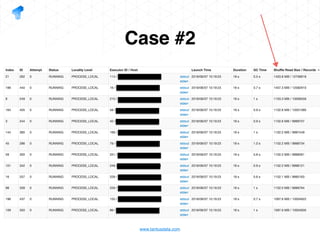
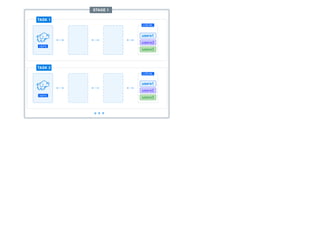
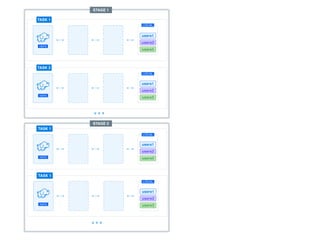
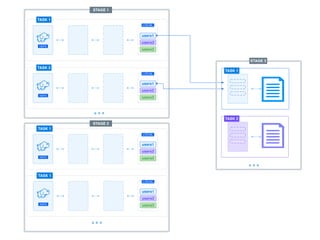
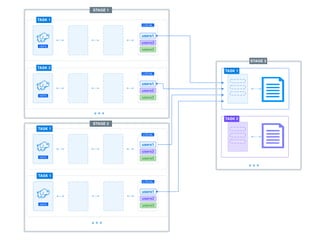
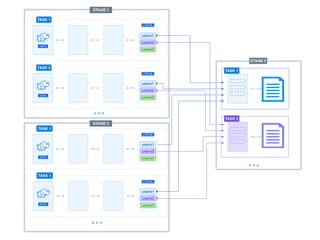
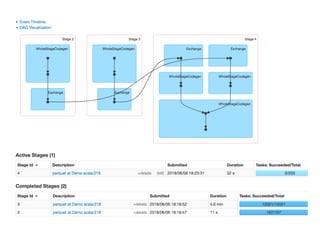
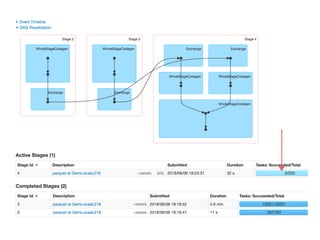
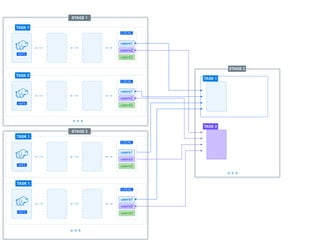
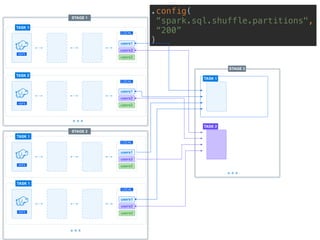
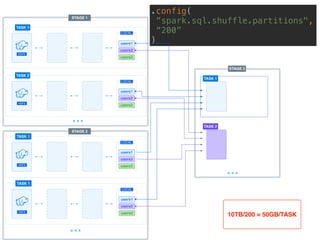
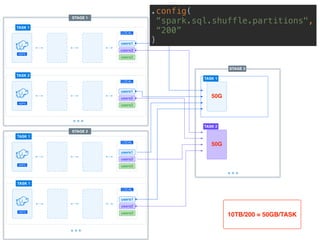
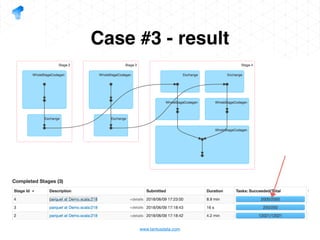
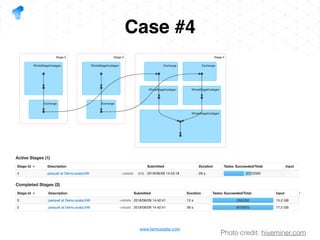
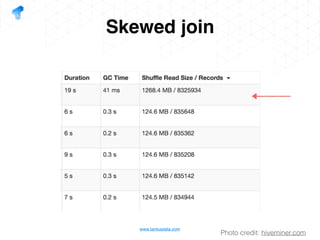
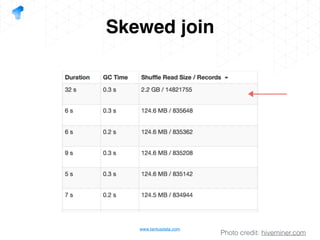
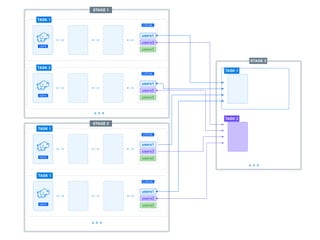
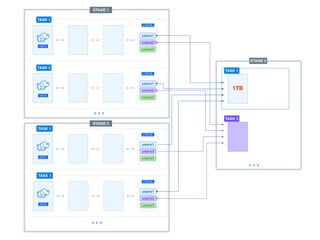
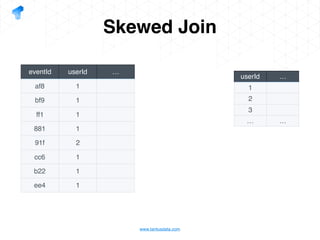
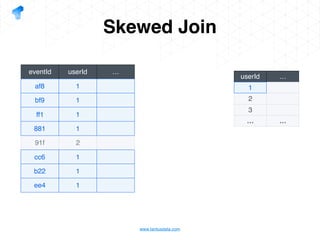
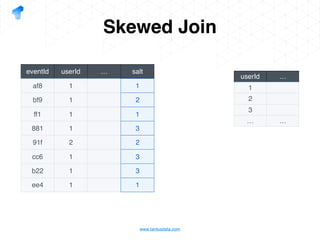
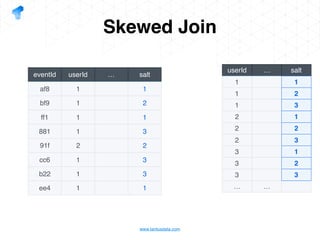
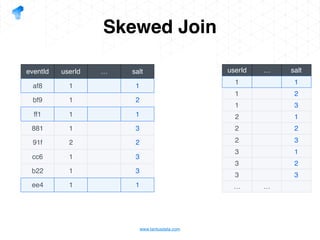
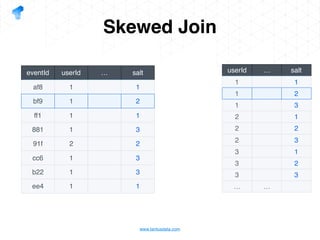
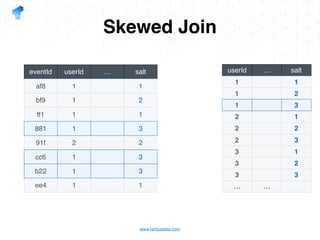
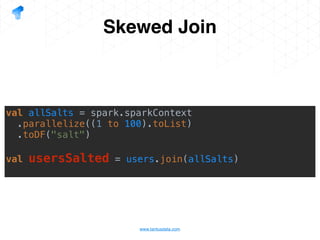
The document presents a detailed overview of using Spark DataFrames from a data analyst's perspective, covering aspects such as Spark execution models, data transformations, and query optimization techniques. It emphasizes the importance of efficient data handling to improve performance while ensuring compliance with data regulations. Additionally, the document provides practical examples and case studies demonstrating the application of Spark for data aggregation and processing.