Download as PDF, PPTX

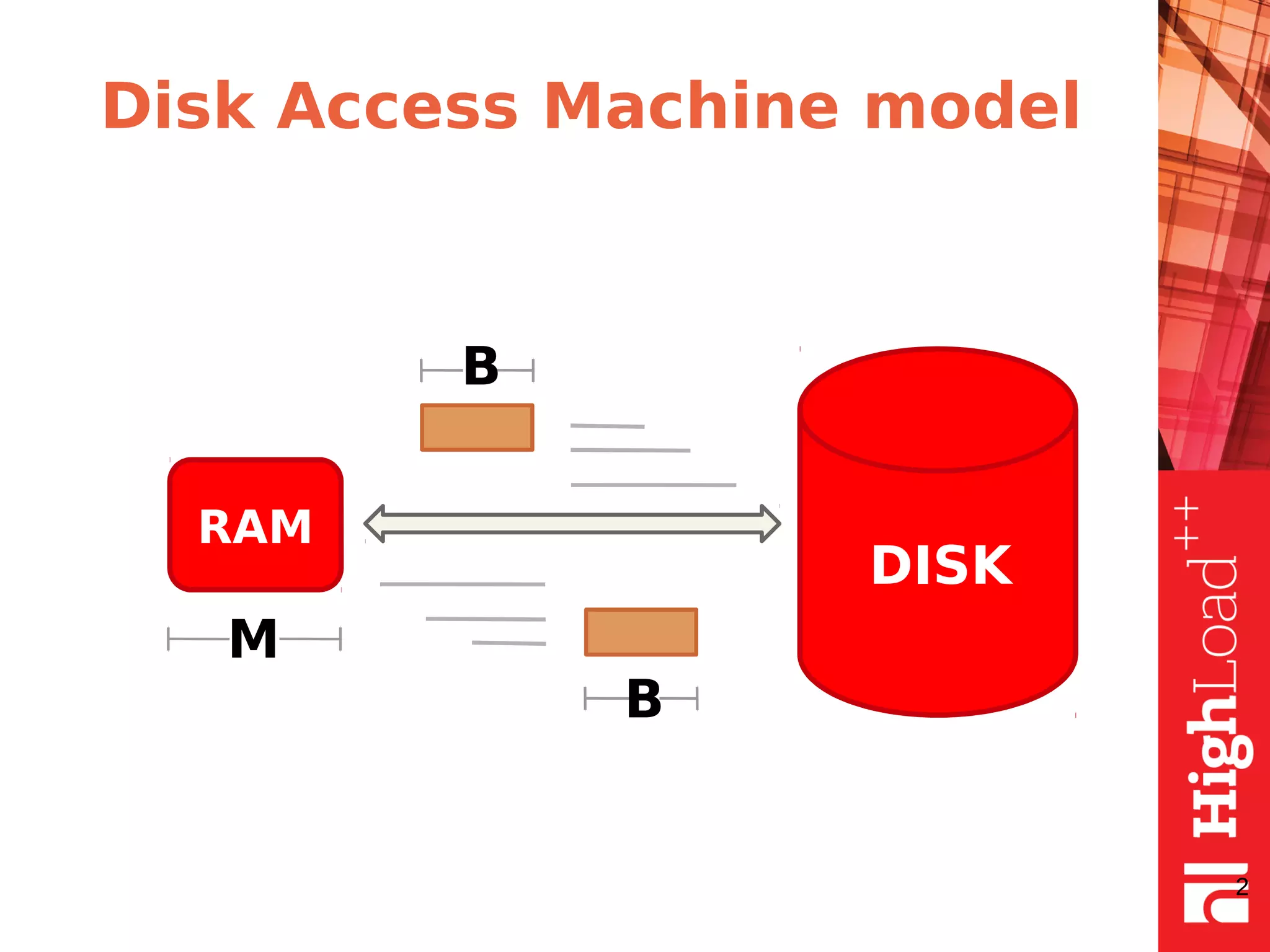
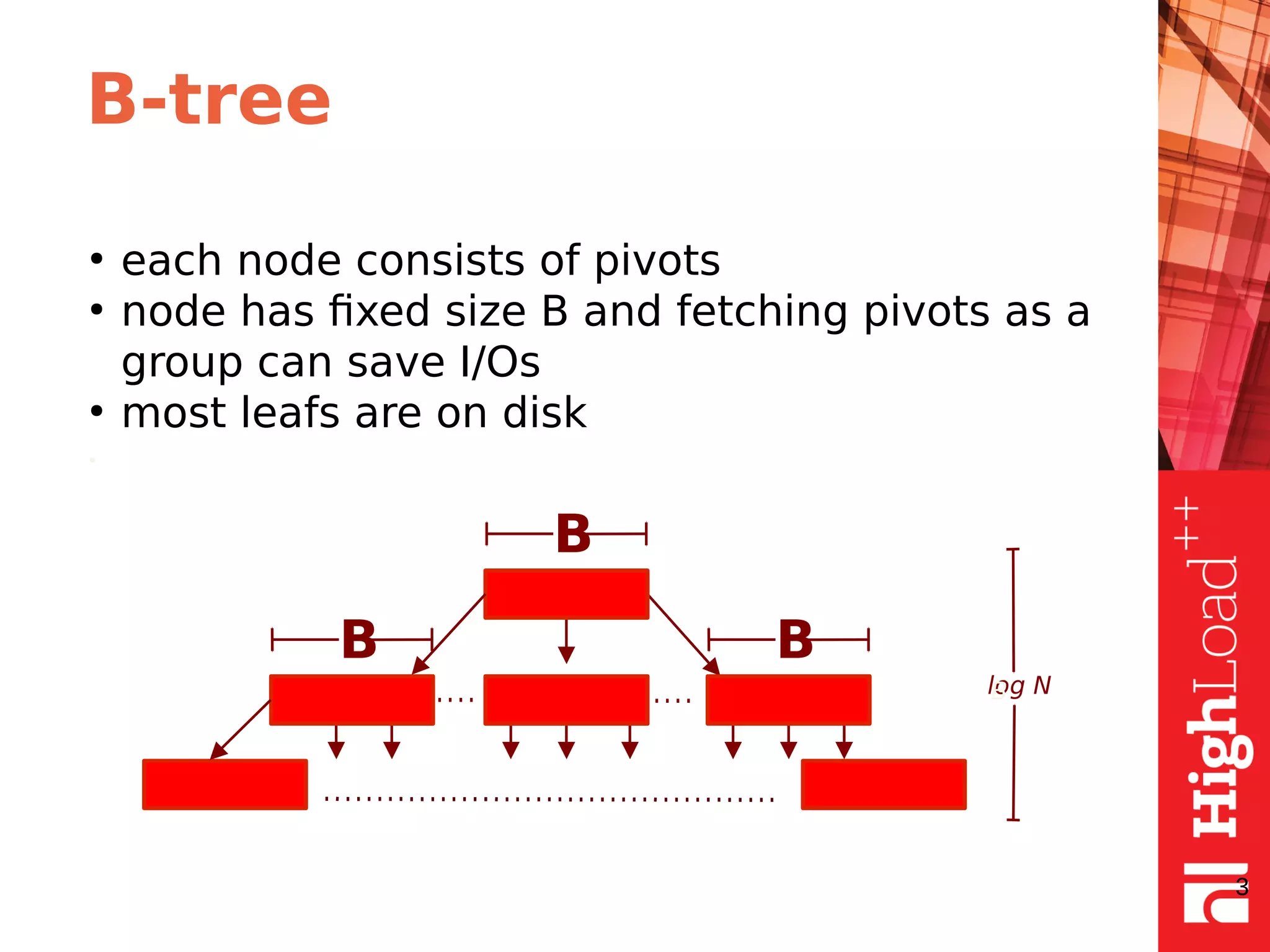
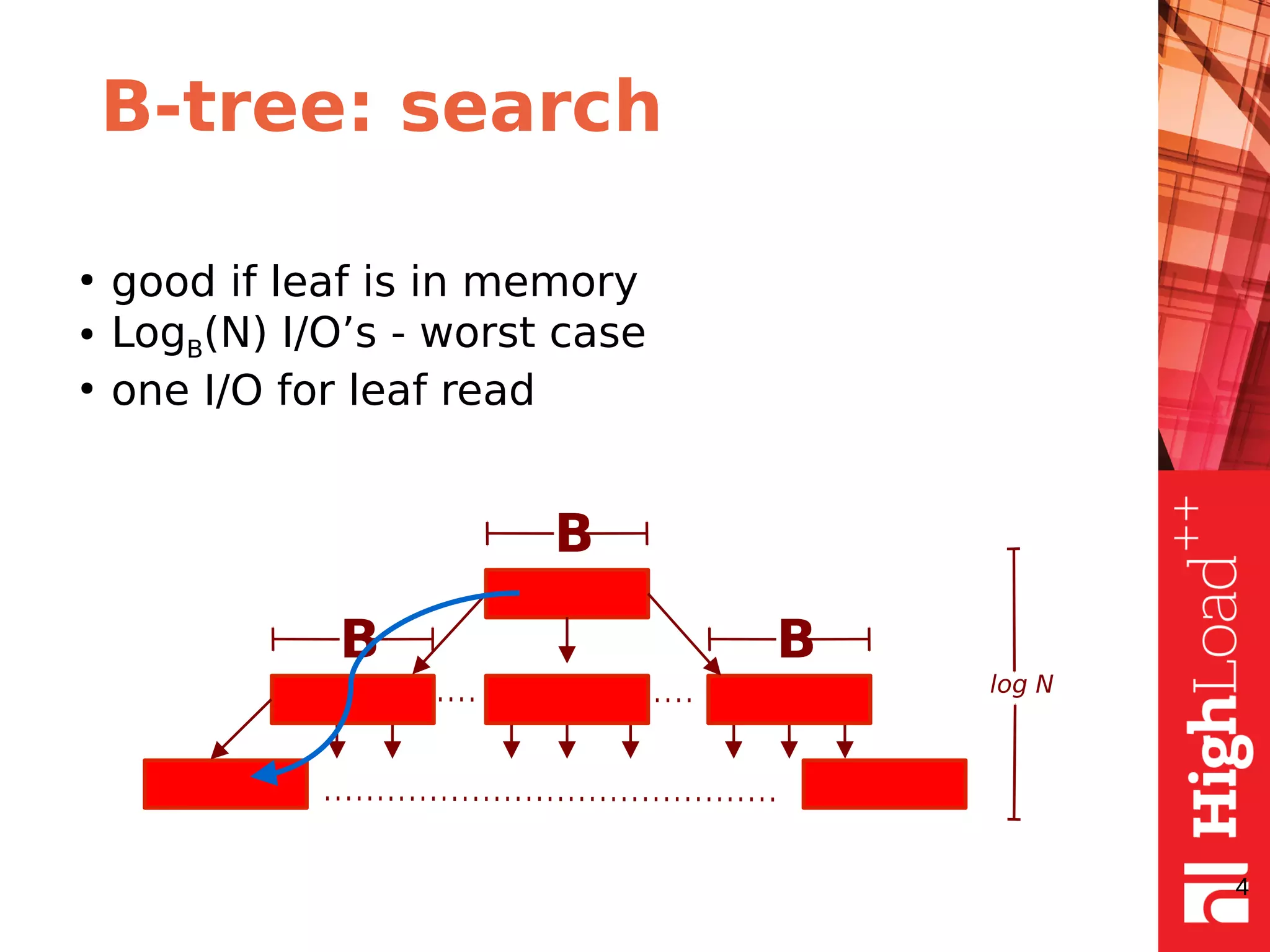
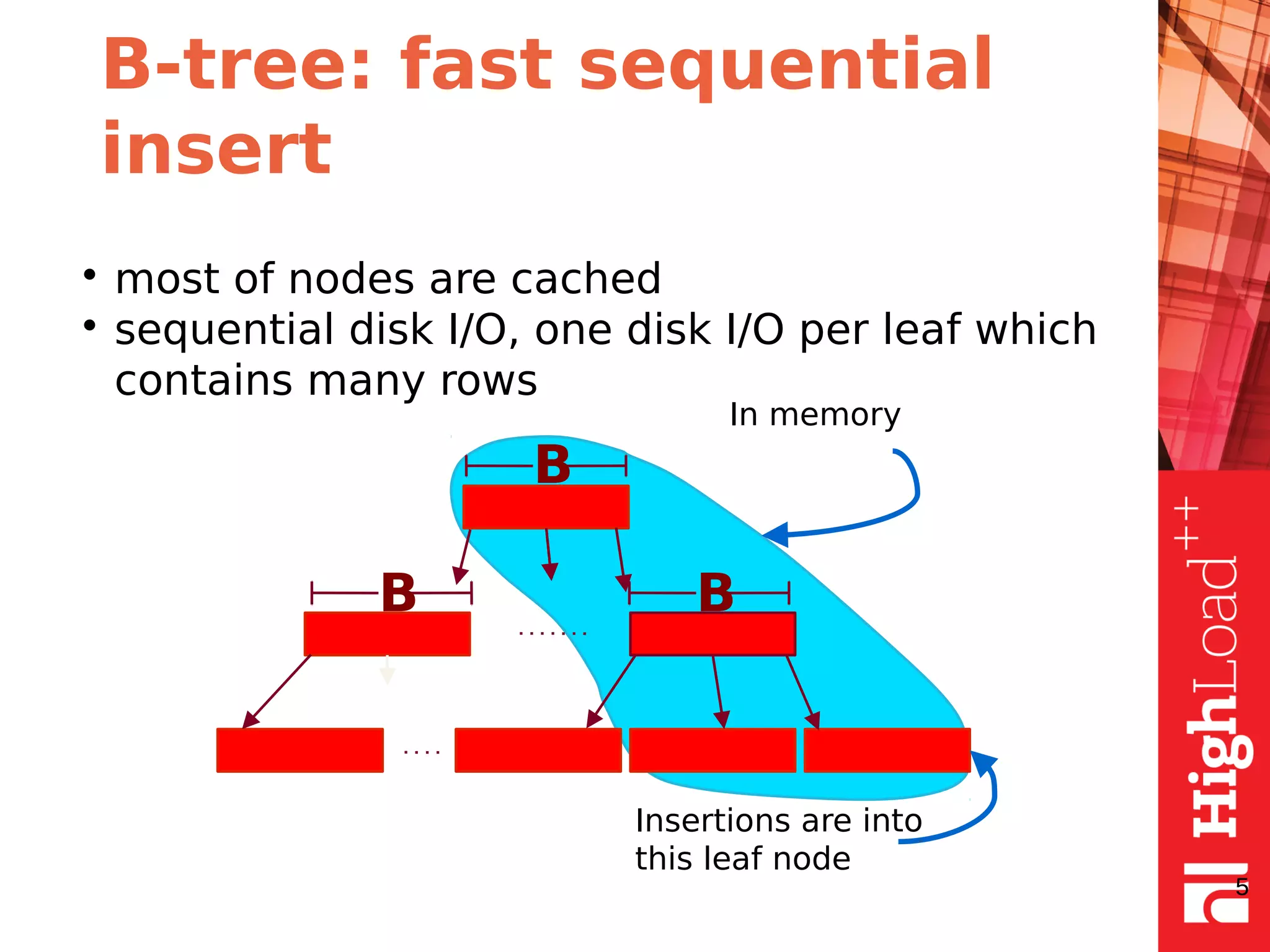
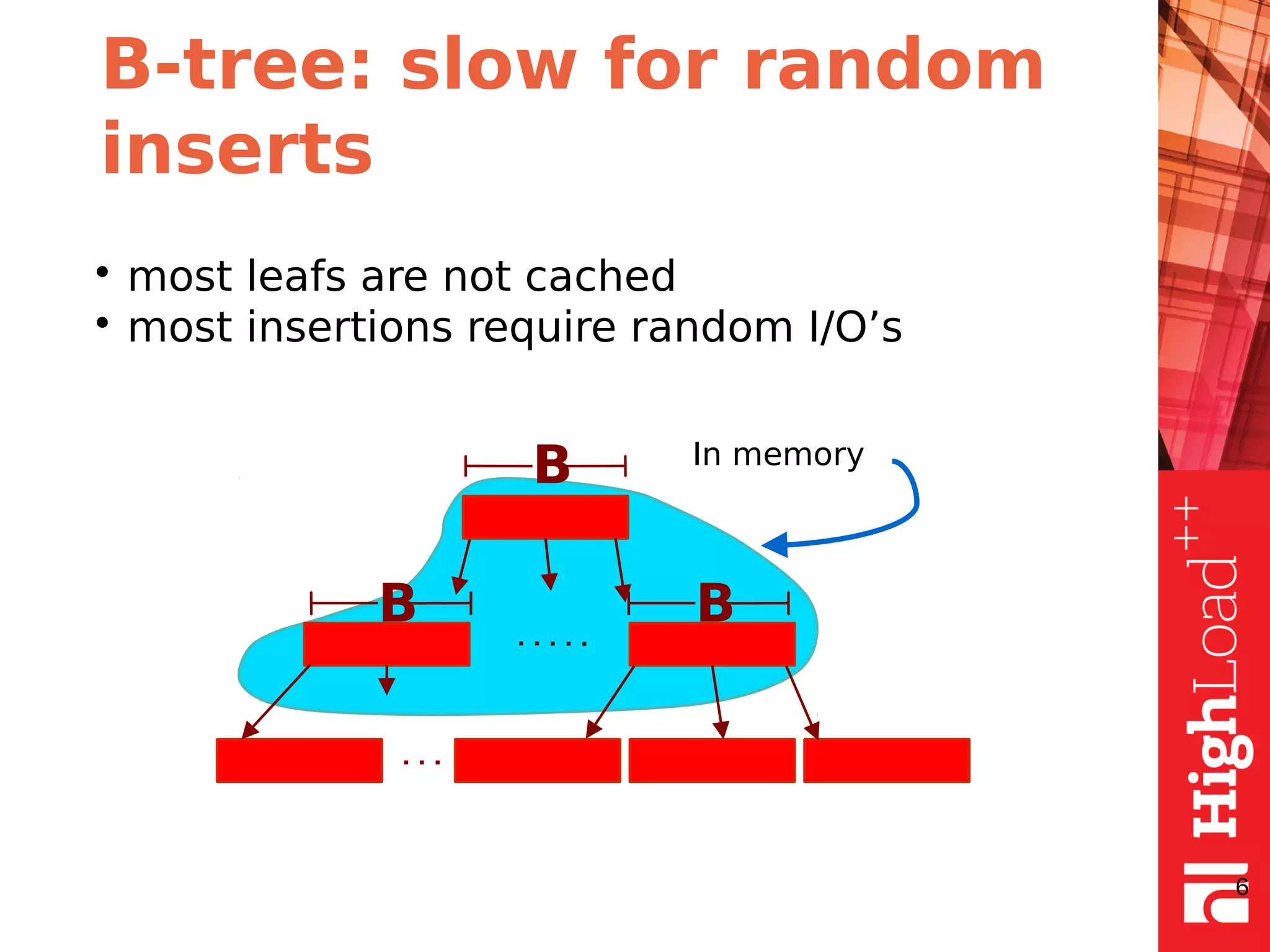



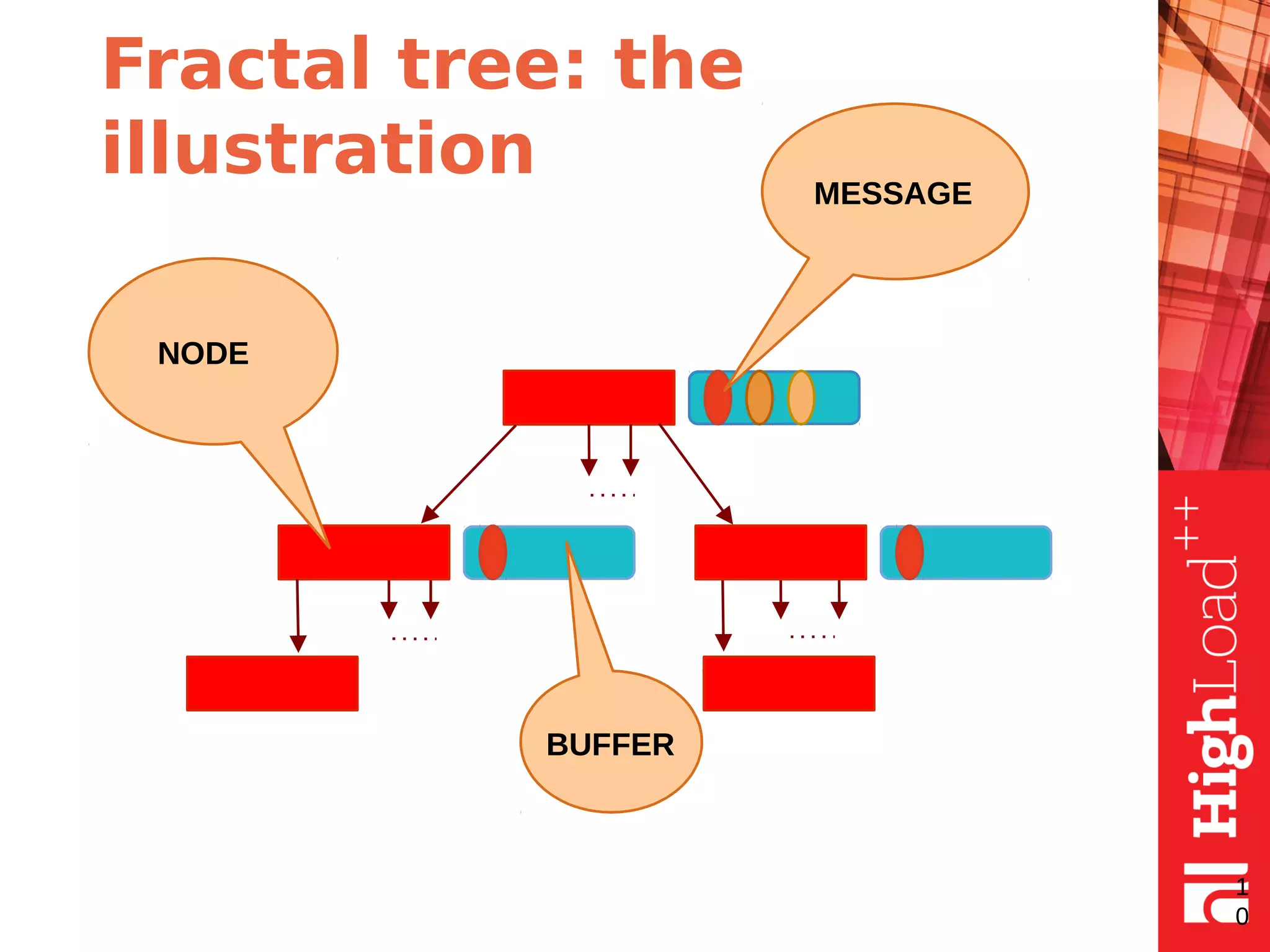
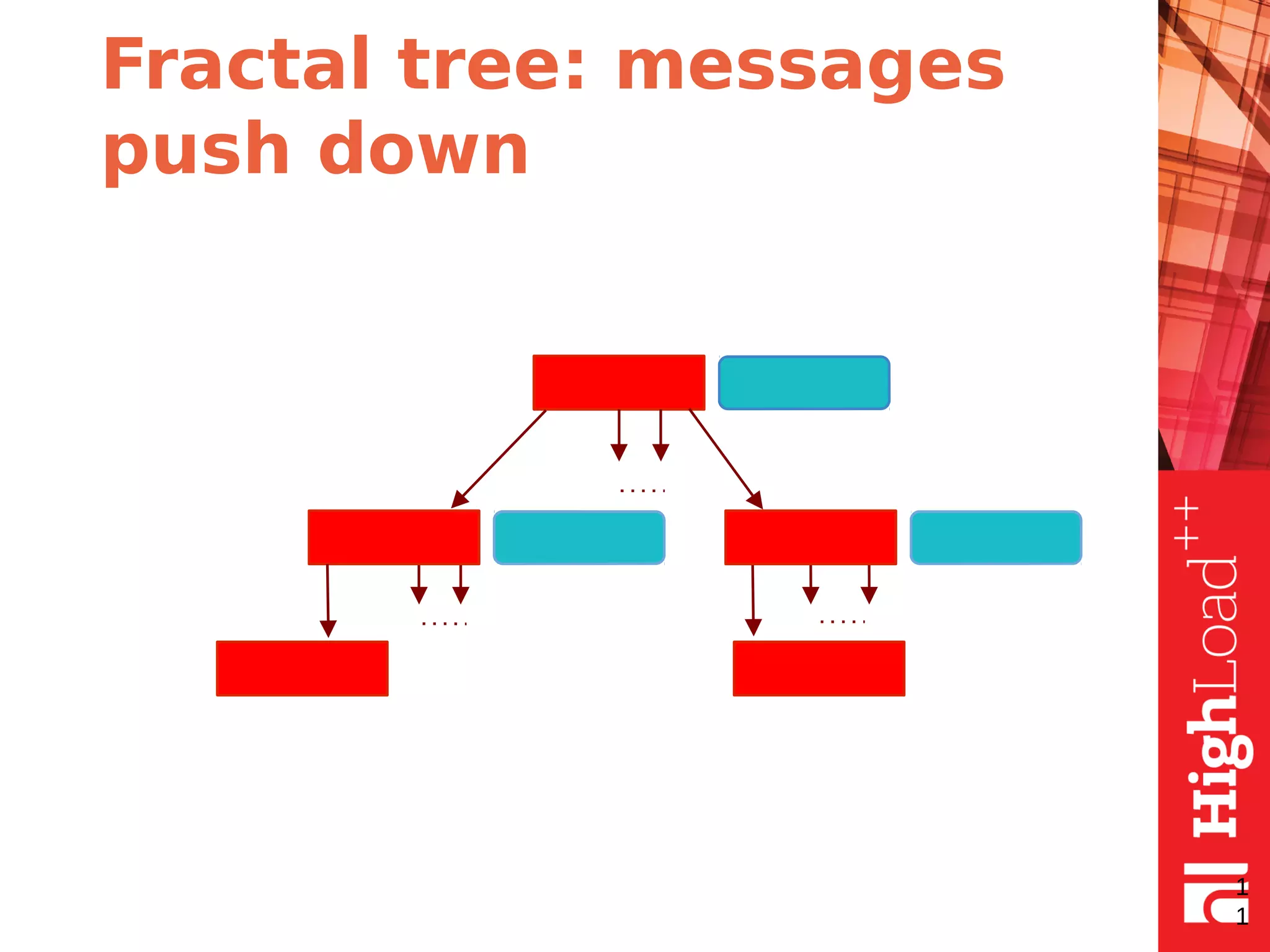
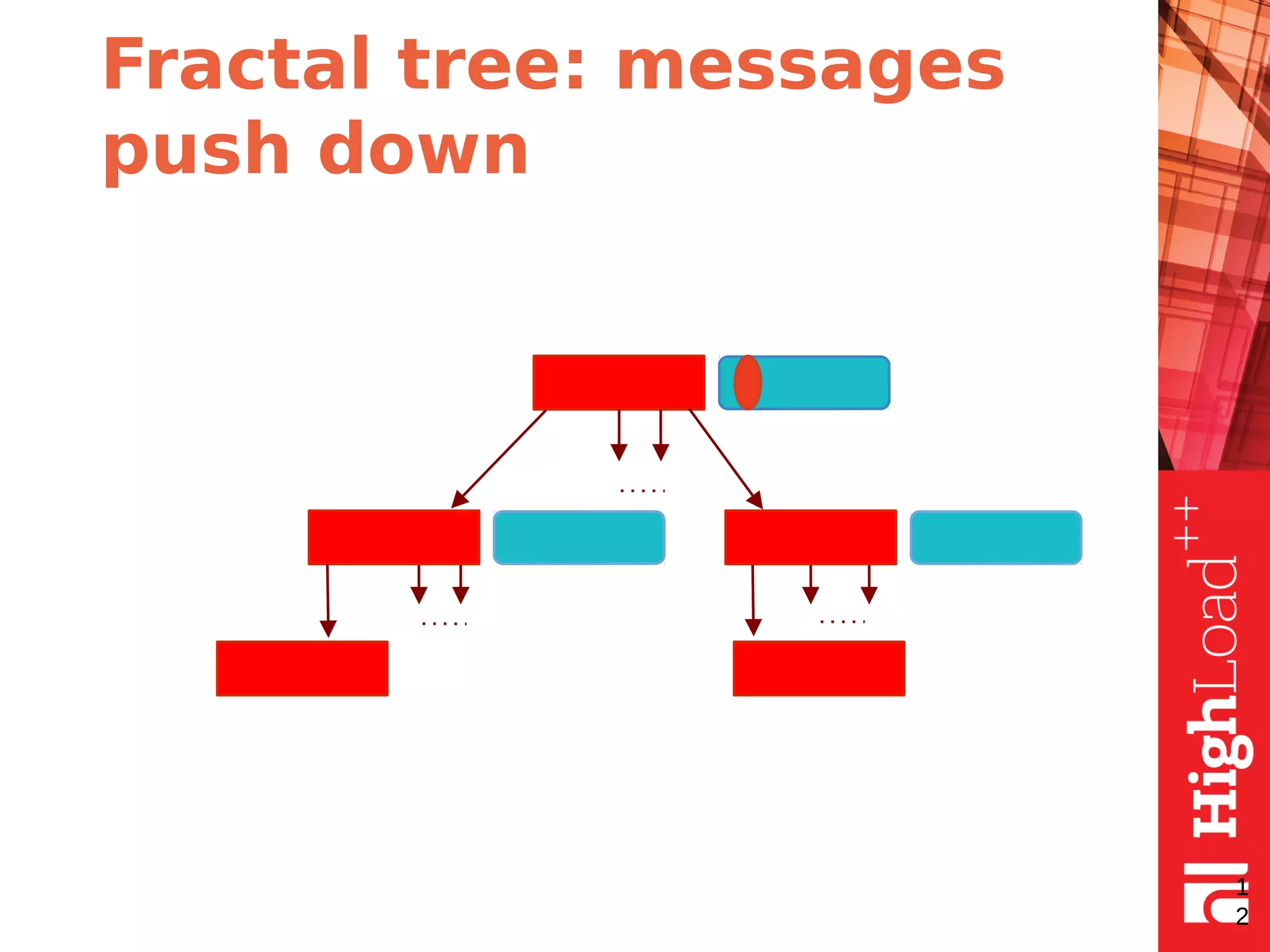
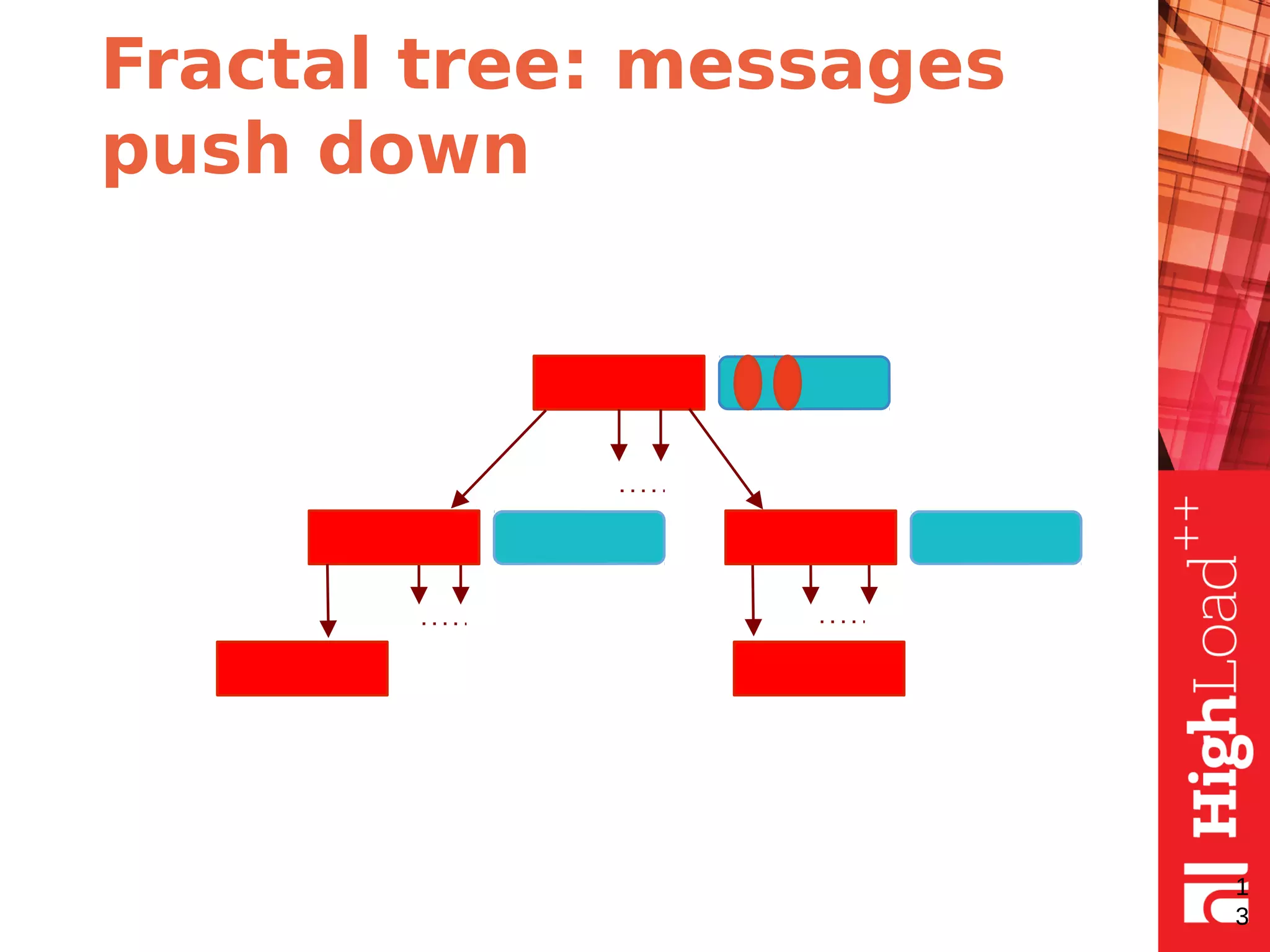
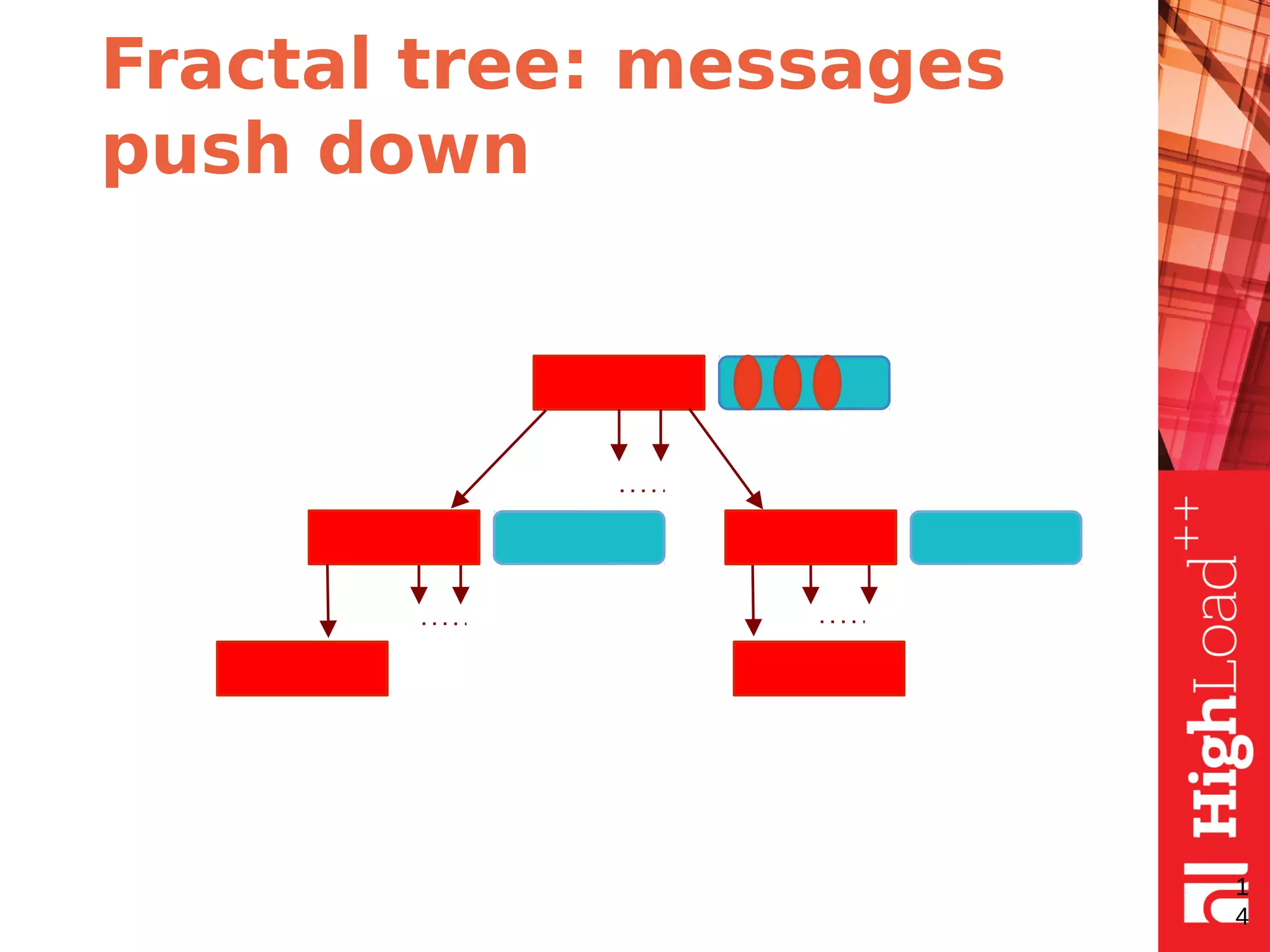
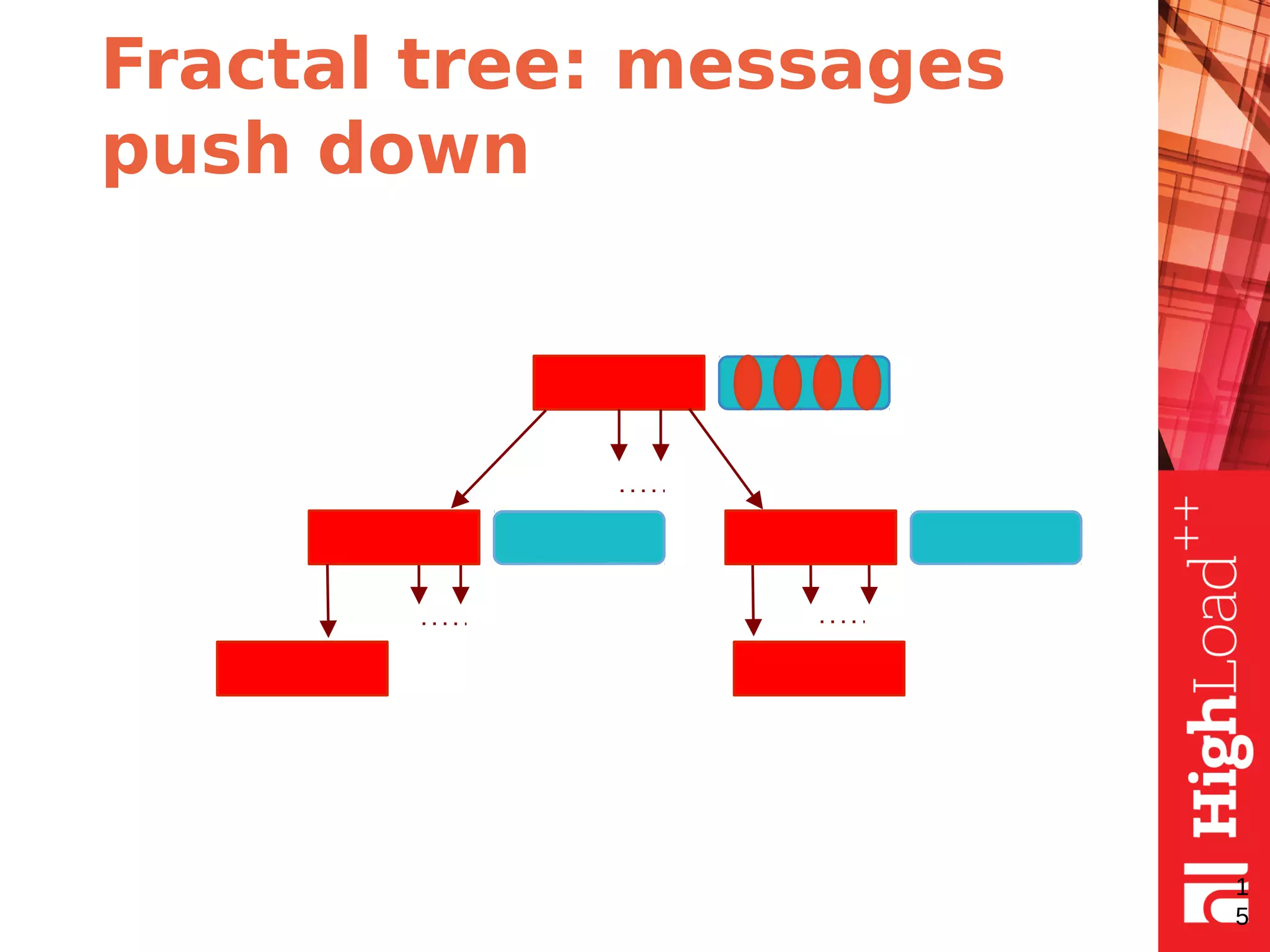
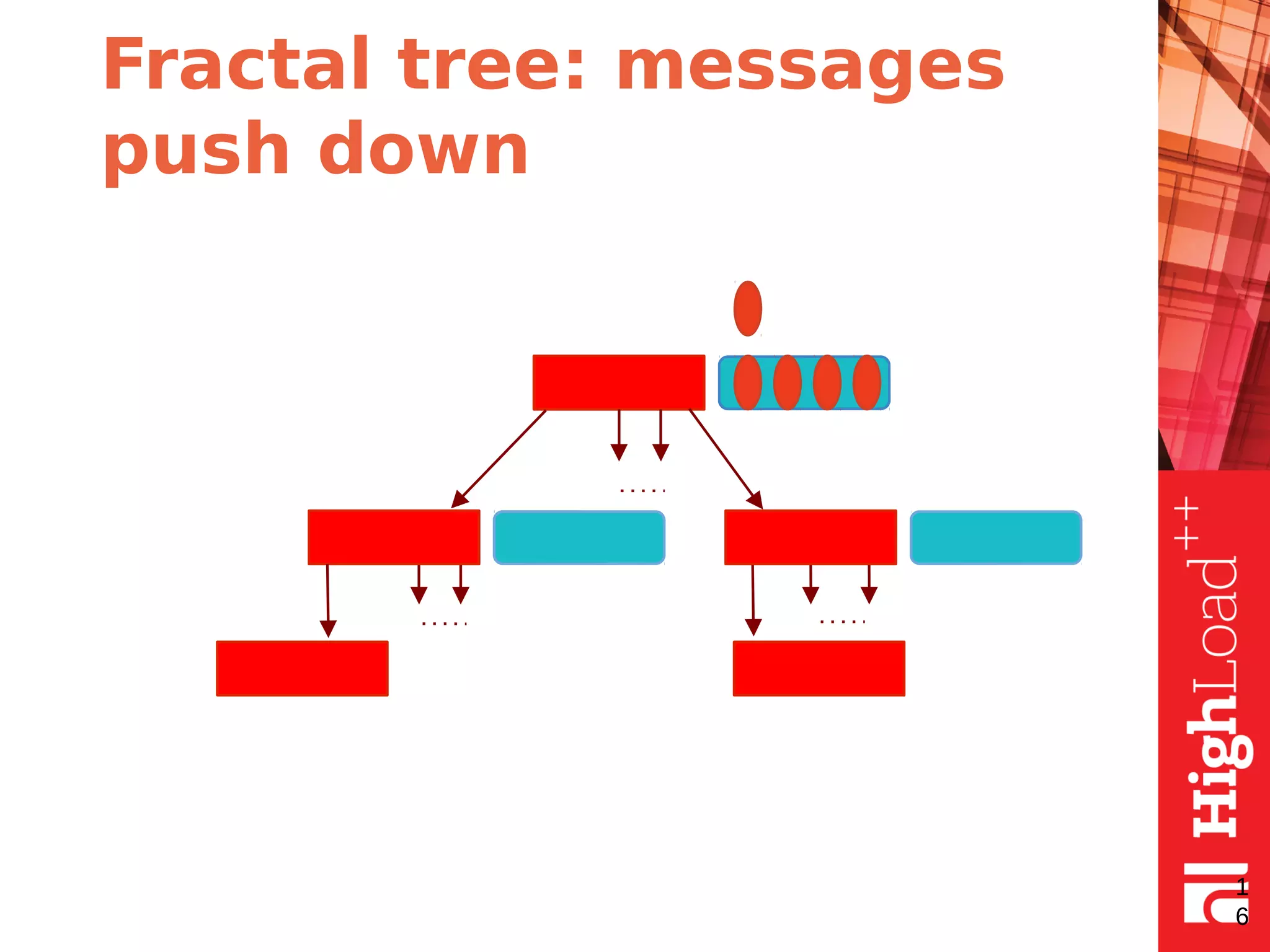
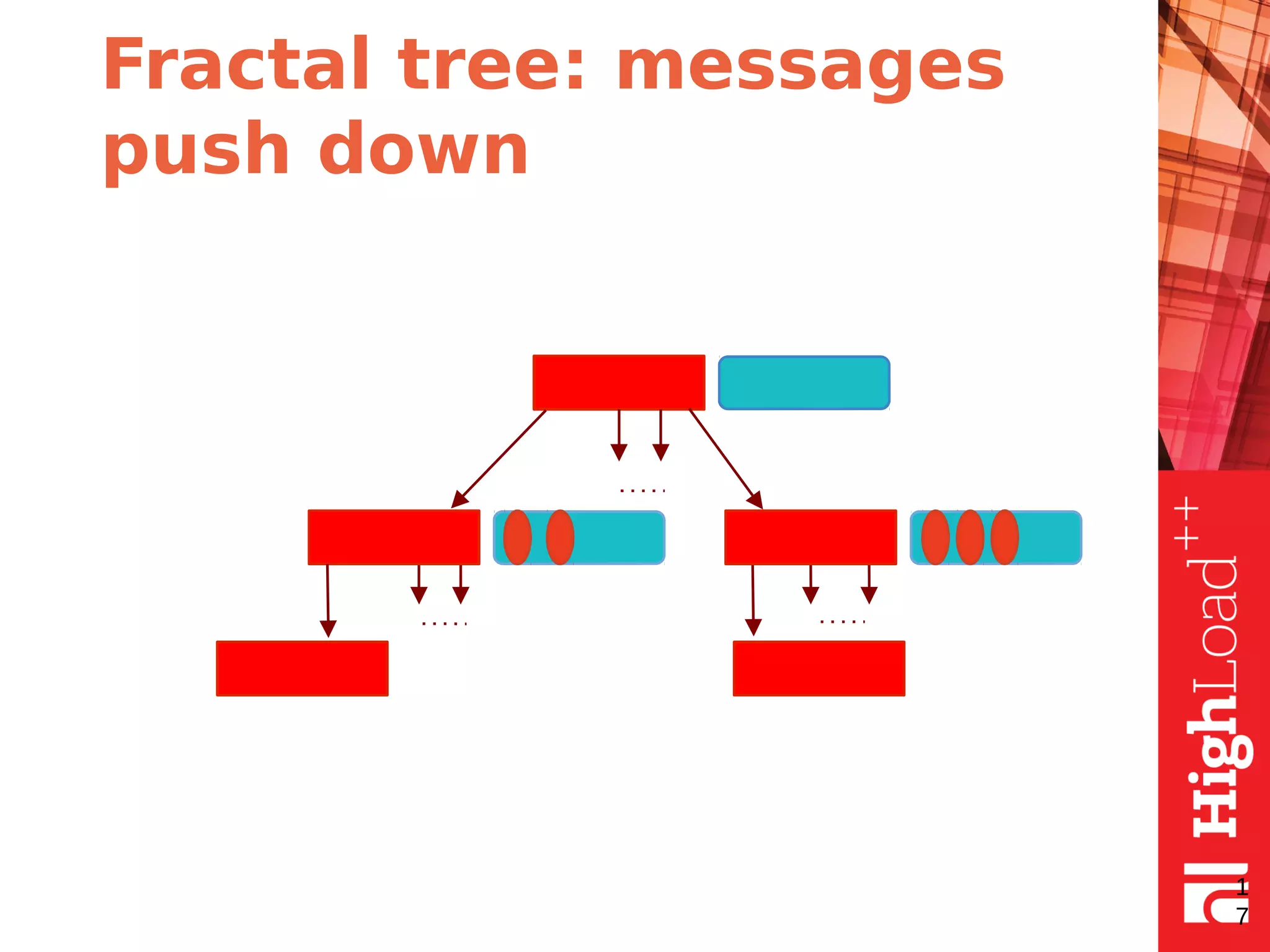



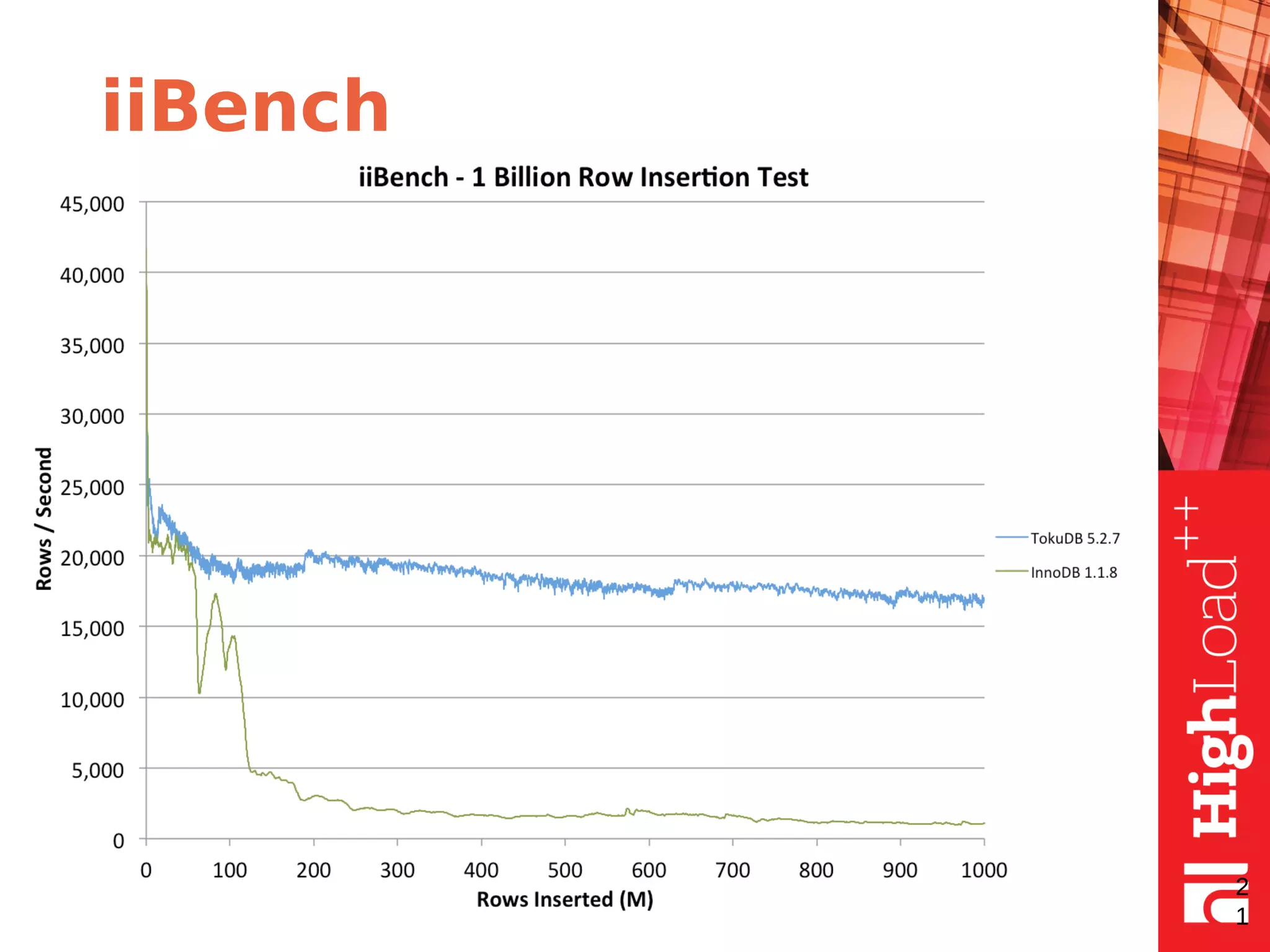
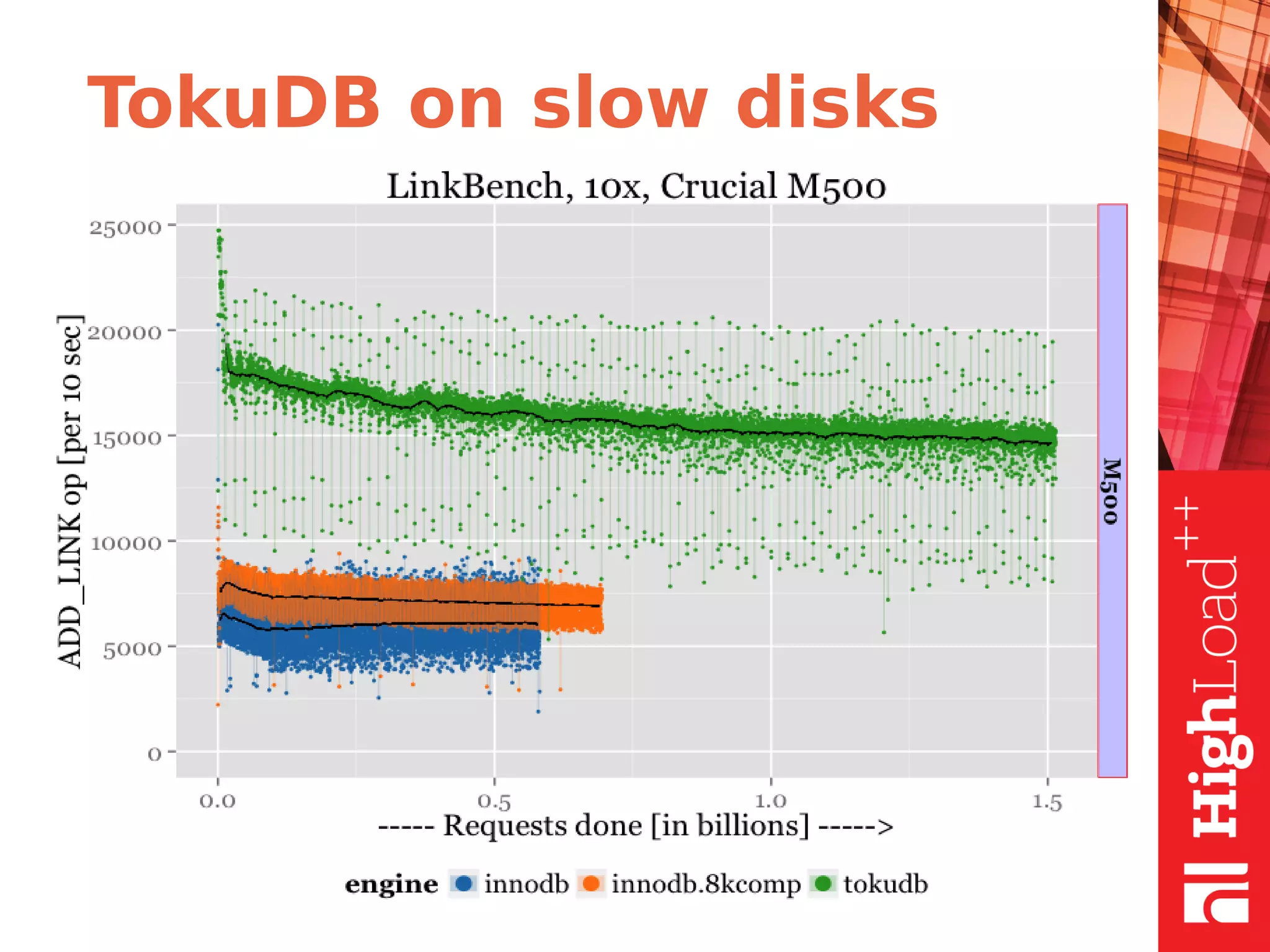
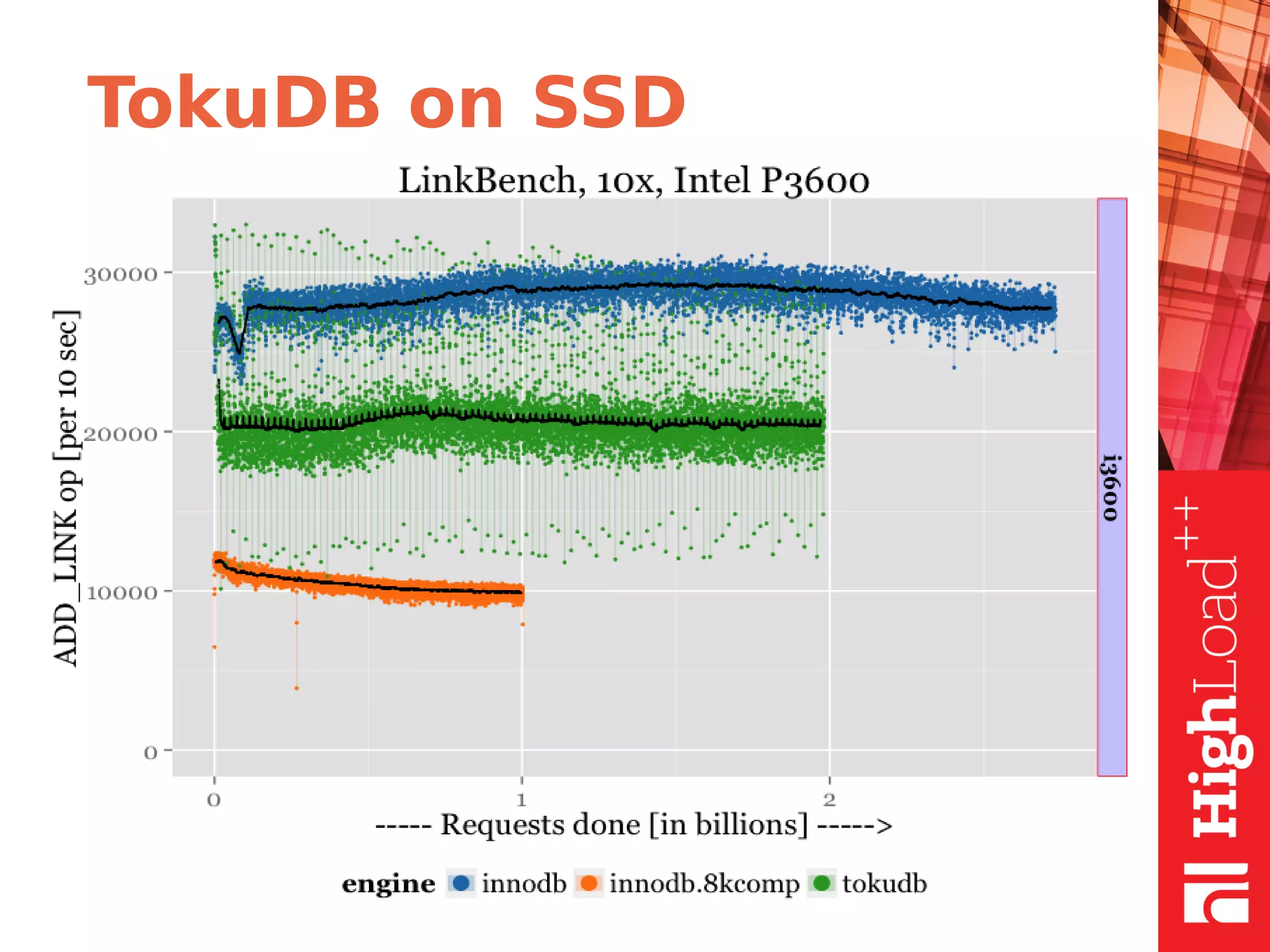

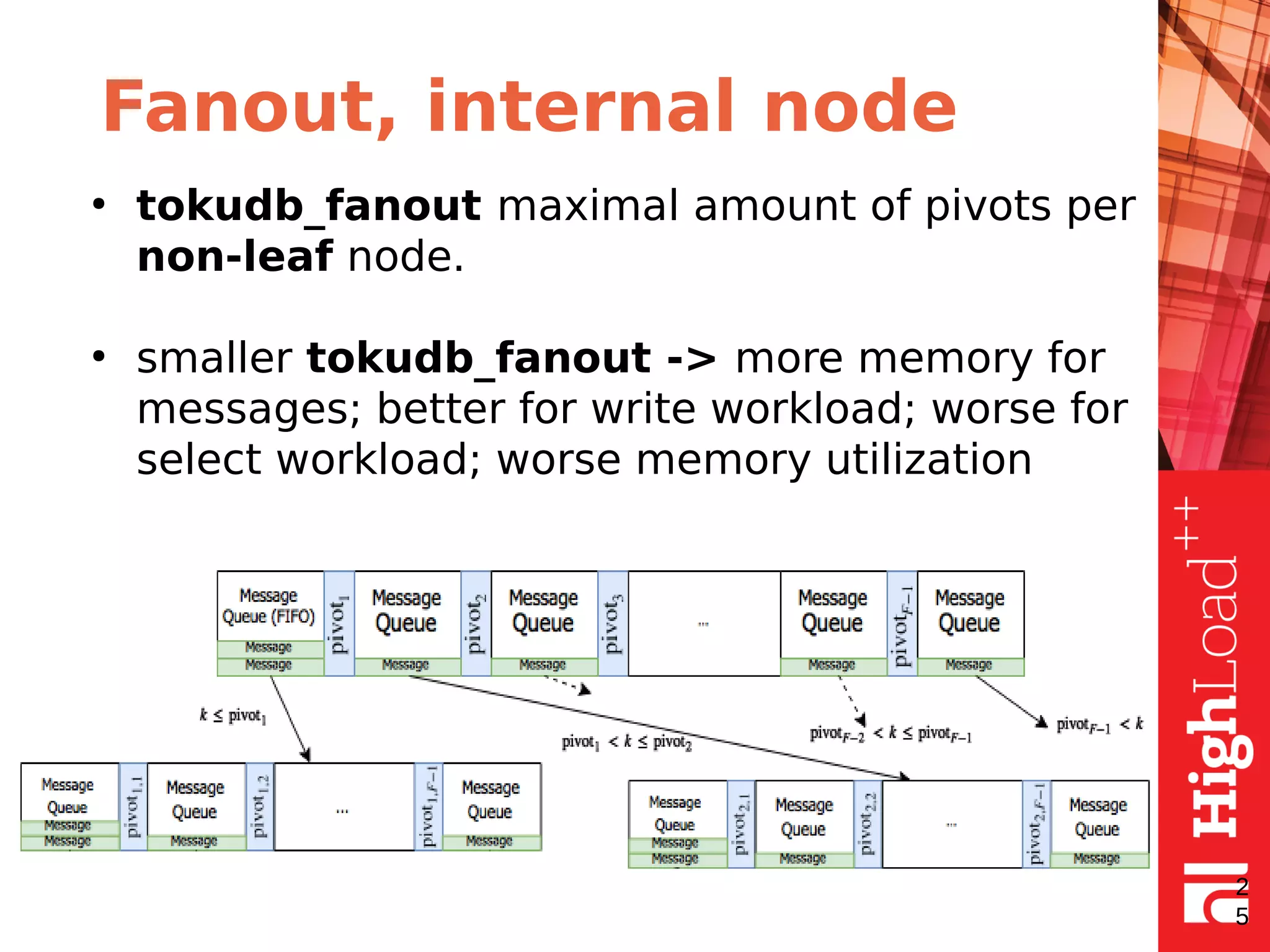

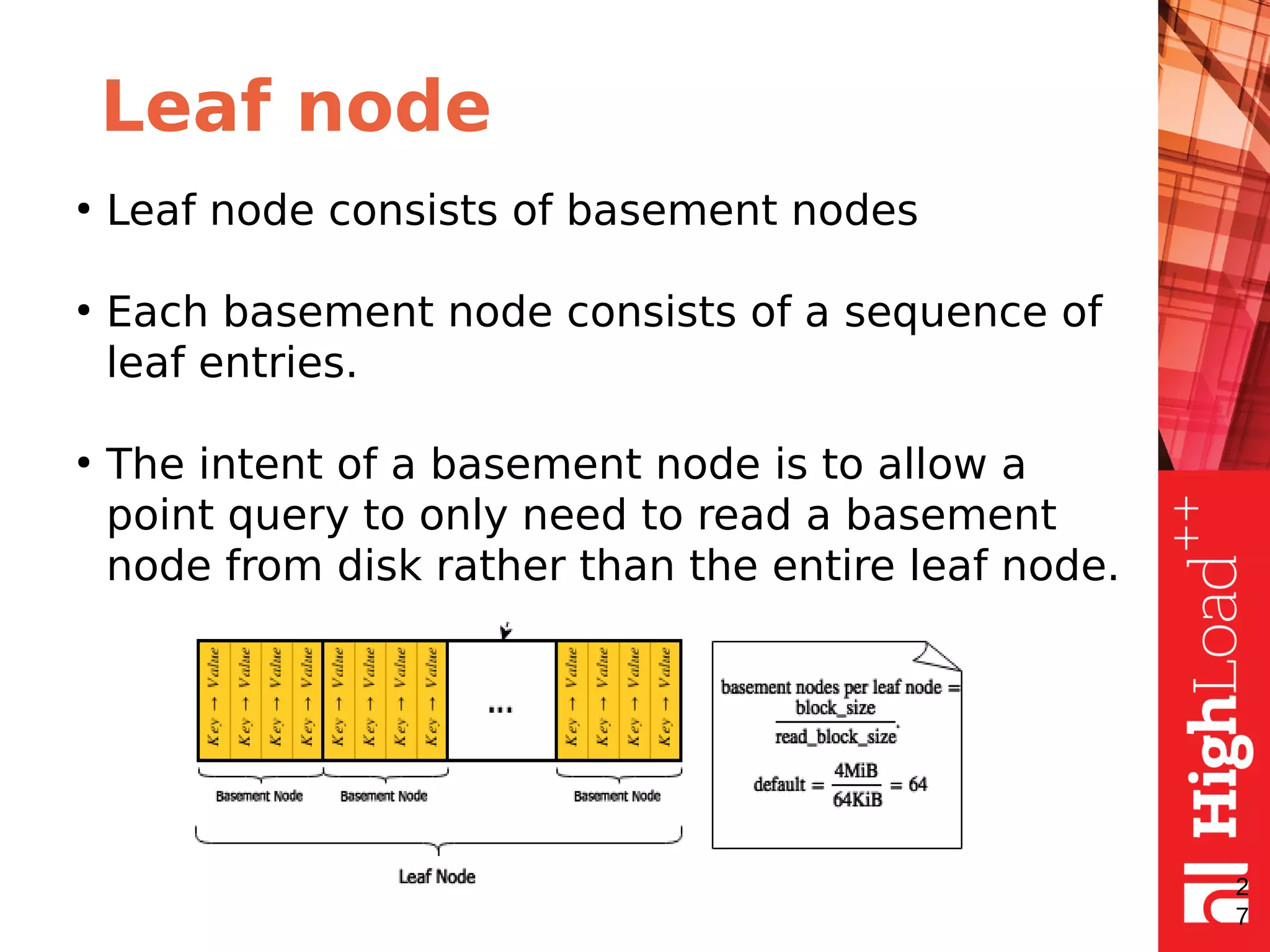



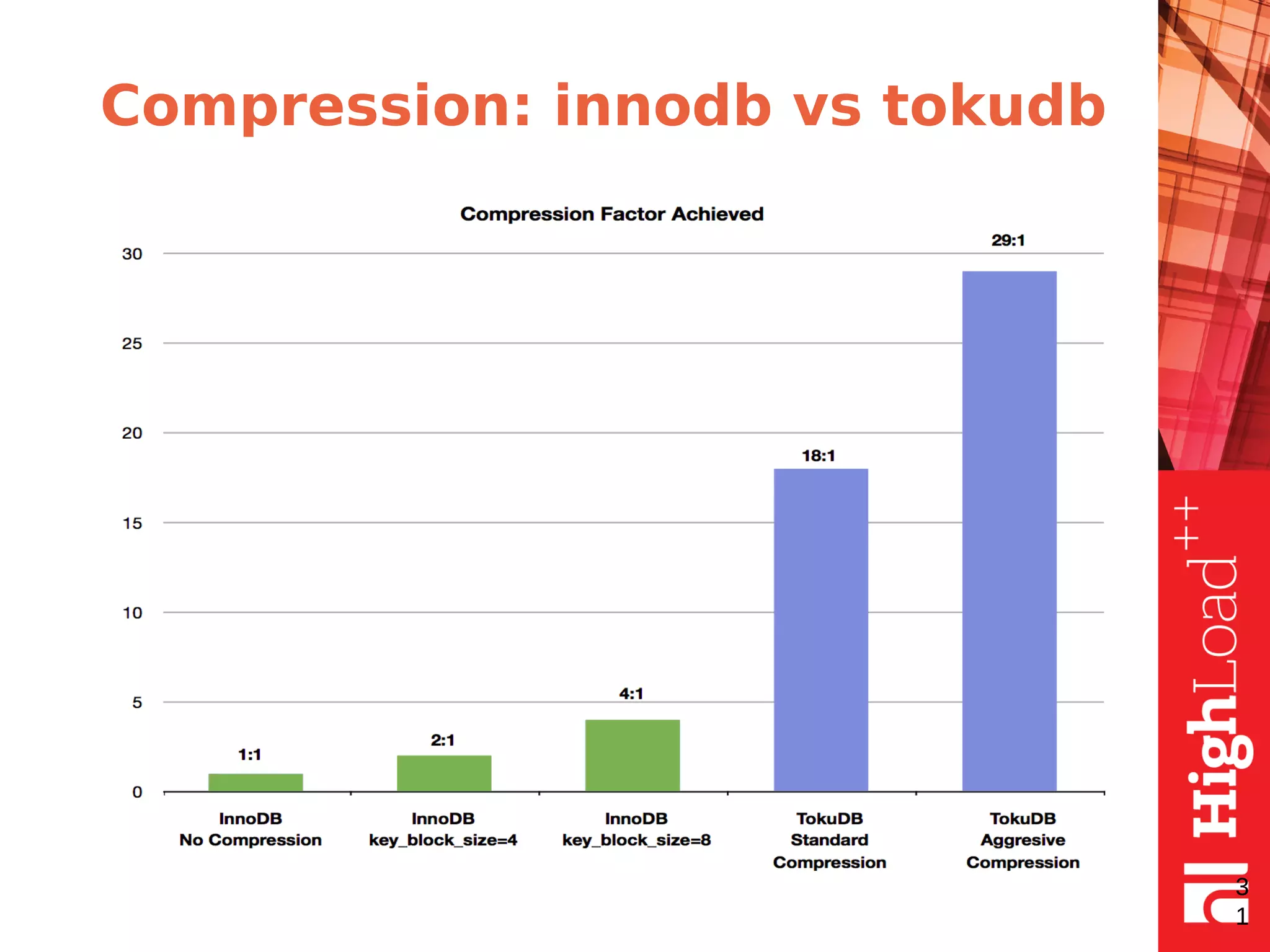



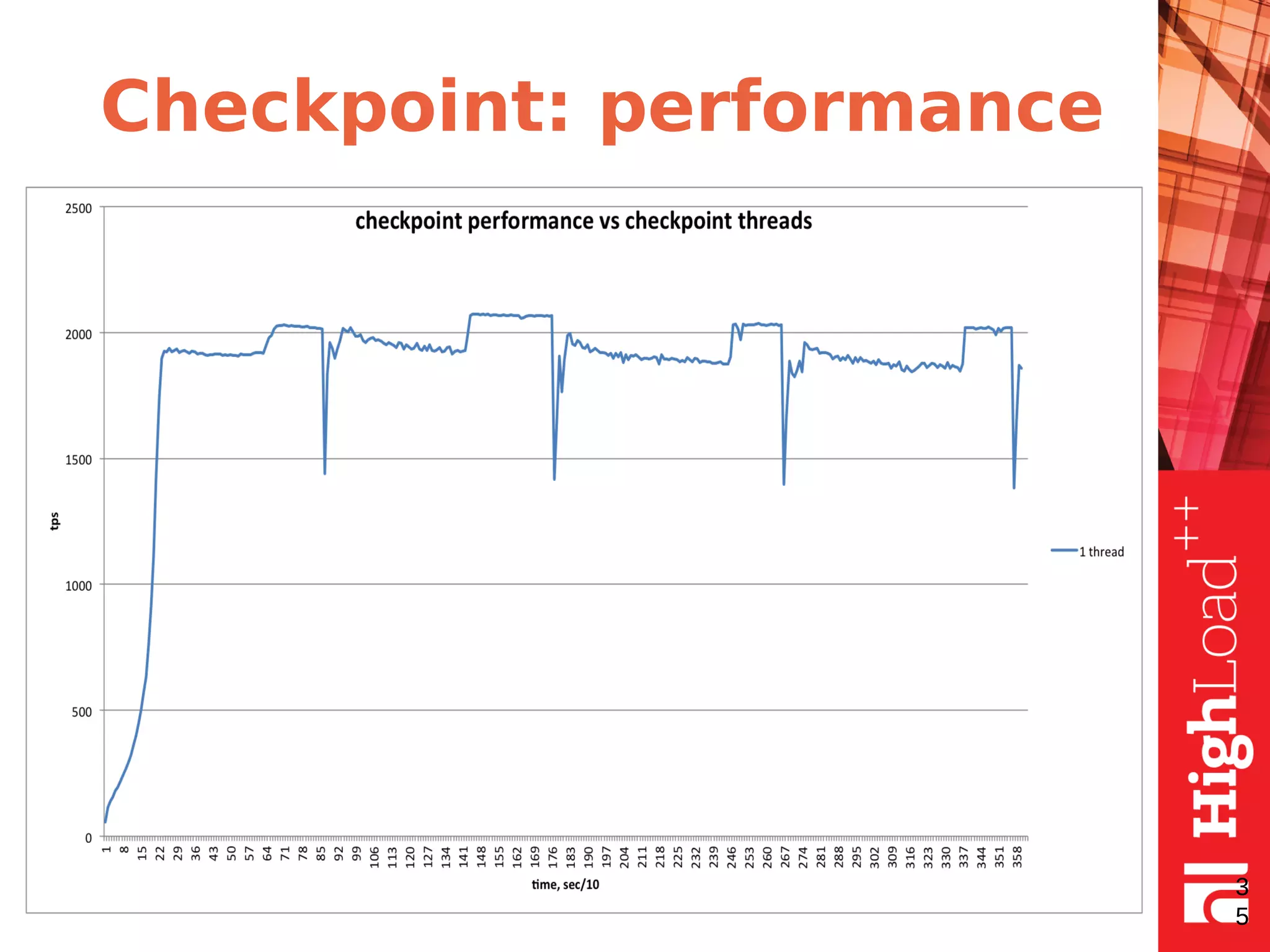





The document discusses B-trees and fractal trees, which are data structures used in databases. It explains that fractal trees are similar to B-trees but store changes in message buffers within nodes to reduce disk I/O for random inserts compared to B-trees. The document provides details on parameters like fanout, node size, basement node size, and compression that can be tuned in fractal trees to optimize performance for different workloads and storage types.













![[db tech showcase Tokyo 2017] A11: SQLite - The most used yet least appreciat...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-keynote-20170905-170911071000-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































