Downloaded 46 times











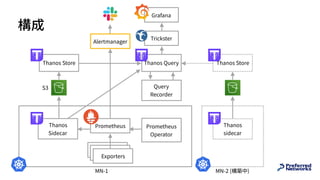


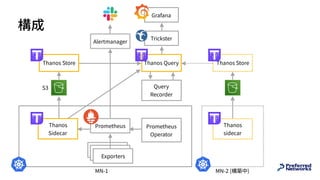

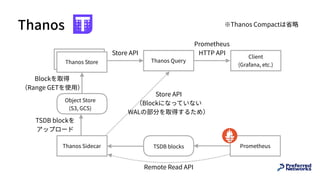






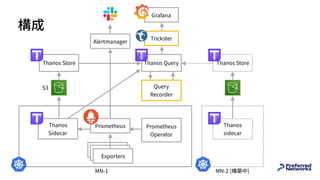
![Recording Rule
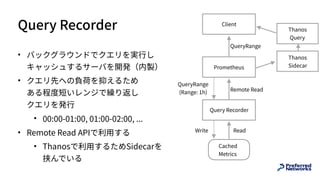
• Recording Rule
• クエリの結果をメトリックとして保存する機能
• Cons: 過去にさかのぼってレコードすることはできない
ので、あとから追加することは困難
# 例
- record: "instance_path:requests:rate5m"
expr: 'rate(requests_total{job="myjob"}[5m])'](https://image.slidesharecdn.com/prometheusatpfn-190604040936/85/Prometheus-at-Preferred-Networks-27-320.jpg)

Prometheus Tokyo Meetup #2 PFN荒井良太の講演資料を公開します。 Preferred Networks (PFN)ではオンプレミスのKubernetesクラスタで機械学習基盤を構築しており、そのモニタリングにPrometheusを利用しています。PFNでのPrometheusの利用事例、Thanosを利用したスケーラブルなPrometheusのデプロイなどをご紹介しています。 https://prometheus.connpass.com/event/127574/
![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)








![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)





























