2011年10月19~21日に開催された「INSIGHT OUT 2011」のセッション「PostgreSQLアーキテクチャ入門」の講演資料です。
「INSIGHT OUT 2011」の詳細については、以下を参照ください。
http://www.insight-tec.com/insight-out-2011.html
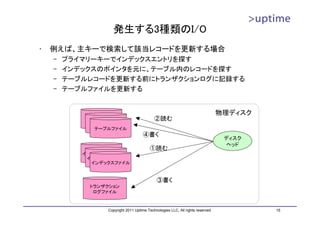
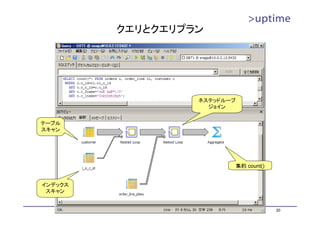
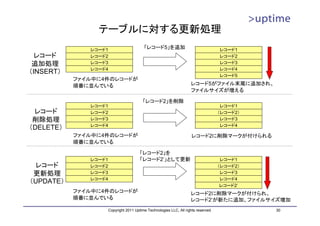
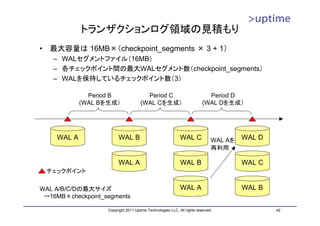
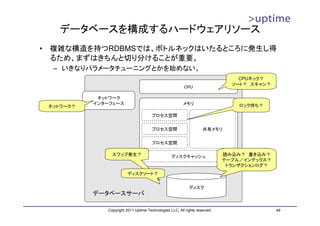
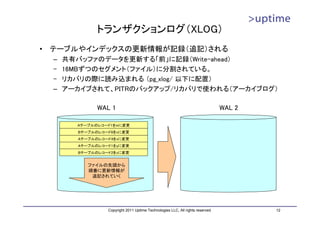
トランザクションログ領域の見積もり
• 最大容量は 16MB×(checkpoint_segments × 3 + 1)
– WALセグメントファイル(16MB)
– 各チェックポイント間の最大WALセグメント数(checkpoint_segments)
– WALを保持しているチェックポイント数(3)
Period B Period C Period D
(WAL Bを生成) (WAL Cを生成) (WAL Dを生成)
WAL A WAL B WAL C WAL Aを WAL D
再利用
WAL A WAL B WAL C
チェックポイント
WAL A/B/C/Dの最大サイズ WAL A WAL B
→16MB×checkpoint_segments
Copyright 2011 Uptime Technologies LLC, All rights reserved. 42
43.
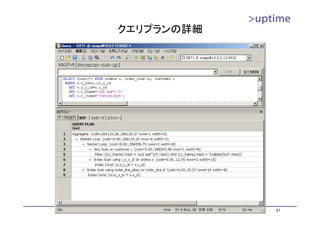
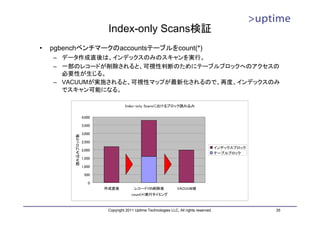
(参考)pgstattuple/pgstatindex
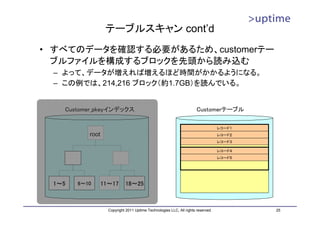
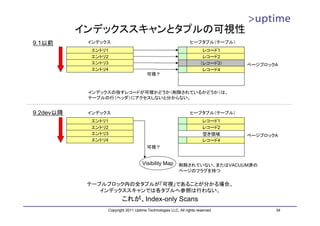
• テーブルとB-Treeインデックスの統計情報を表示するユーティリティ。
– contribモジュールとしてPostgreSQLソースに同梱
• 使い方
– cd ./contrib/pgstattuple ; make && make install
– CREATE EXTENSION pgstattuple;
http://www.postgresql.jp/document/9.1/html/pgstattuple.html
Copyright 2011 Uptime Technologies LLC, All rights reserved. 43
44.
(参考)pageinspect
• ページブロックの内容や統計情報を表示するユーティリティ。
– contribモジュールとしてPostgreSQLソースに同梱
• 使い方
– cd ./contrib/pageinspect ; make && make install
– CREATE EXTENSION pageinspect;
http://www.postgresql.jp/document/9.1/html/pageinspect.html
Copyright 2011 Uptime Technologies LLC, All rights reserved. 44
45.
(参考)xlogdump
• WALセグメントファイルの内容や統計情報を表示するユーティリティ。
– http://github.com/snaga/xlogdump
• 使い方
– README.xlogdump を参照
https://github.com/snaga/xlogdump/blob/master/README.xlogdump
Copyright 2011 Uptime Technologies LLC, All rights reserved. 45
46.
(参考)pgestimate
• テーブル/インデックスファイルサイズ見積もりツール
http://www.uptime.jp/go/pgestimate
Copyright 2011 Uptime Technologies LLC, All rights reserved. 46







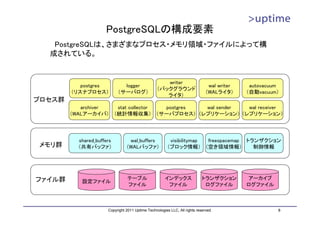

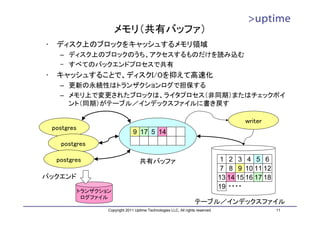
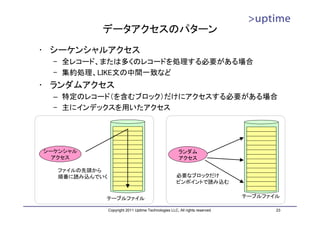
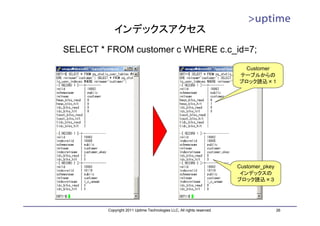
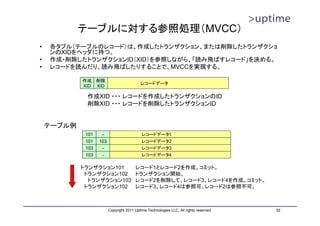
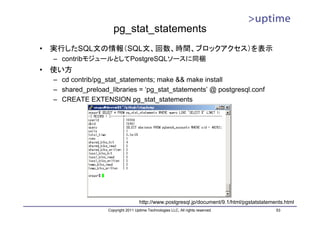
![テーブルファイル
• 8kB単位のブロック単位で管理
• ブロックの中に実データのレコード(タプル)を配置
– 基本的に追記のみ
– 削除したら削除マークを付加する(VACUUMで回収)
– レコード更新時は「削除+追記」を行う。
DBT1=# SELECT * FROM
pgstattuple('customer');
-[ RECORD 1 ]------+-----------
レコード1 table_len | 1754857472
レコード2 ブロック1 tuple_count | 3456656
レコード3
tuple_len | 1703225491
レコード4 tuple_percent | 97.06
レコード5 ブロック2 dead_tuple_count | 695
dead_tuple_len | 350038
dead_tuple_percent | 0.02
free_space | 31391624
ブロック3
free_percent | 1.79
DBT1=#
Copyright 2011 Uptime Technologies LLC, All rights reserved. 13](https://image.slidesharecdn.com/postgresqlinsightout-111021033956-phpapp02/85/PostgreSQL-INSIGHT-OUT-2011-13-320.jpg)
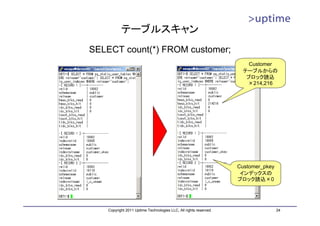
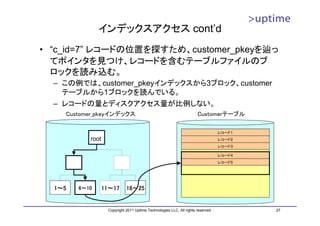
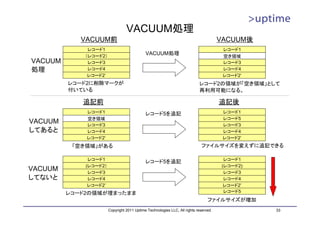
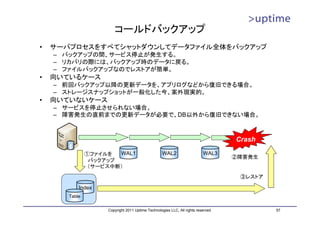
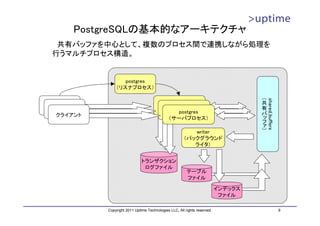
![インデックス(B-Tree)ファイル
• ブロック(8kB単位)をノードとする論理的なツリー構造を持つ
– ルート、インターナル、リーフの各ノードから構成
– ルートノードから辿っていく
– リーフノードは、インデックスのキーとレコードへのポインタを持つ
DBT1=# SELECT * FROM
インデックスファイル pgstatindex('customer_pkey');
-[ RECORD 1 ]------+----------
version | 2
root tree_level | 2
index_size | 108953600
root_block_no | 217
internal_pages | 66
leaf_pages | 13233
empty_pages | 0
deleted_pages | 0
1~5 6~10 11~17 18~25 avg_leaf_density | 90.2
leaf_fragmentation | 0
DBT1=#
Copyright 2011 Uptime Technologies LLC, All rights reserved. 14](https://image.slidesharecdn.com/postgresqlinsightout-111021033956-phpapp02/85/PostgreSQL-INSIGHT-OUT-2011-14-320.jpg)