Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
勇黒
Uploaded by
勇 黒沢
103 views
Prometheus超基礎公開用.pdf
Prom基礎勉強会用
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 48
2
/ 48
3
/ 48
4
/ 48
5
/ 48
6
/ 48
7
/ 48
8
/ 48
9
/ 48
10
/ 48
11
/ 48
12
/ 48
13
/ 48
14
/ 48
15
/ 48
16
/ 48
17
/ 48
18
/ 48
19
/ 48
20
/ 48
21
/ 48
22
/ 48
23
/ 48
24
/ 48
25
/ 48
26
/ 48
27
/ 48
28
/ 48
29
/ 48
30
/ 48
31
/ 48
32
/ 48
33
/ 48
34
/ 48
35
/ 48
36
/ 48
37
/ 48
38
/ 48
39
/ 48
40
/ 48
41
/ 48
42
/ 48
43
/ 48
44
/ 48
45
/ 48
46
/ 48
47
/ 48
48
/ 48
More Related Content
PDF
Re永続データ構造が分からない人のためのスライド
by
Masaki Hara
PDF
プログラムを高速化する話
by
京大 マイコンクラブ
PDF
スパースモデリング入門
by
Hideo Terada
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
PDF
双対性
by
Yoichi Iwata
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
PDF
C++ マルチスレッド 入門
by
京大 マイコンクラブ
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
Re永続データ構造が分からない人のためのスライド
by
Masaki Hara
プログラムを高速化する話
by
京大 マイコンクラブ
スパースモデリング入門
by
Hideo Terada
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
双対性
by
Yoichi Iwata
明日使えないすごいビット演算
by
京大 マイコンクラブ
C++ マルチスレッド 入門
by
京大 マイコンクラブ
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
What's hot
PDF
Deflate
by
7shi
PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
by
MITSUNARI Shigeo
PPTX
充足可能性問題のいろいろ
by
Hiroshi Yamashita
PDF
プログラミングコンテストでの乱択アルゴリズム
by
Takuya Akiba
PDF
2015年度GPGPU実践プログラミング 第6回 パフォーマンス解析ツール
by
智啓 出川
PDF
すごい constexpr たのしくレイトレ!
by
Genya Murakami
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
C++ マルチスレッドプログラミング
by
Kohsuke Yuasa
PDF
アプリケーションの性能最適化2(CPU単体性能最適化)
by
RCCSRENKEI
PDF
直交領域探索
by
okuraofvegetable
PDF
あなたの手元の本よりいい方法がある! UXデザインのプロはこうやってユーザーのインサイトを確実に見つける
by
Yoshiki Hayama
PDF
2015年度GPGPU実践プログラミング 第5回 GPUのメモリ階層
by
智啓 出川
PDF
20分くらいでわかった気分になれるC++20コルーチン
by
yohhoy
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
PDF
2章グラフ理論スピード入門
by
Teruo Kawasaki
PDF
AtCoder Regular Contest 039 解説
by
AtCoder Inc.
PPTX
WayOfNoTrouble.pptx
by
Daisuke Yamazaki
PDF
Marp入門
by
Rui Watanabe
PDF
Unityネイティブプラグインの勧め
by
KLab Inc. / Tech
PDF
条件分岐とcmovとmaxps
by
MITSUNARI Shigeo
Deflate
by
7shi
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
by
MITSUNARI Shigeo
充足可能性問題のいろいろ
by
Hiroshi Yamashita
プログラミングコンテストでの乱択アルゴリズム
by
Takuya Akiba
2015年度GPGPU実践プログラミング 第6回 パフォーマンス解析ツール
by
智啓 出川
すごい constexpr たのしくレイトレ!
by
Genya Murakami
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
C++ マルチスレッドプログラミング
by
Kohsuke Yuasa
アプリケーションの性能最適化2(CPU単体性能最適化)
by
RCCSRENKEI
直交領域探索
by
okuraofvegetable
あなたの手元の本よりいい方法がある! UXデザインのプロはこうやってユーザーのインサイトを確実に見つける
by
Yoshiki Hayama
2015年度GPGPU実践プログラミング 第5回 GPUのメモリ階層
by
智啓 出川
20分くらいでわかった気分になれるC++20コルーチン
by
yohhoy
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
2章グラフ理論スピード入門
by
Teruo Kawasaki
AtCoder Regular Contest 039 解説
by
AtCoder Inc.
WayOfNoTrouble.pptx
by
Daisuke Yamazaki
Marp入門
by
Rui Watanabe
Unityネイティブプラグインの勧め
by
KLab Inc. / Tech
条件分岐とcmovとmaxps
by
MITSUNARI Shigeo
Similar to Prometheus超基礎公開用.pdf
PPTX
Prometheus
by
Seiya Mizuno
PPTX
Prometheus on AWS
by
Mitsuhiro Tanda
PPTX
Prometheus入門から運用まで徹底解説
by
貴仁 大和屋
PDF
モニタリングプラットフォーム開発の裏側
by
Rakuten Group, Inc.
PDF
Prometheus at Preferred Networks
by
Preferred Networks
PDF
TUNA_con_kurosaway.pdf
by
勇 黒沢
PDF
Docker管理もHinemosで! ~監視・ジョブ機能を併せ持つ唯一のOSS「Hinemos」のご紹介~
by
Hinemos
PDF
K8s-icp-capsmalt-jjugccc2018spring
by
capsmalt
PPTX
PrometheusによるKubernetes環境の異常検知改善.pptx
by
TakashiTsukamoto4
PDF
BlockchainEXE_IBM特集 Cloud Satelliteで実現する分散クラウド時代のIBM Blockchain Platform An...
by
Tsuyoshi Hirayama
PDF
Cloud Satelliteで実現する分散クラウド時代のIBM Blockchain Platform Anywhereとエコシステム | 日本アイ・ビ...
by
blockchainexe
PDF
Prometheus 監視で変わるもの
by
Takehiro Sugita
PPTX
OSSで作るOpenStack監視システム
by
satsuki fukazu
PPTX
Security Operations and Automation on AWS
by
Noritaka Sekiyama
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
PDF
Prometeusについてはじめてみよう / Let's start Prometeus
by
Takeo Noda
PDF
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
PDF
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
PDF
クラウド開発に役立つ OSS あれこれ
by
Masataka MIZUNO
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
Prometheus
by
Seiya Mizuno
Prometheus on AWS
by
Mitsuhiro Tanda
Prometheus入門から運用まで徹底解説
by
貴仁 大和屋
モニタリングプラットフォーム開発の裏側
by
Rakuten Group, Inc.
Prometheus at Preferred Networks
by
Preferred Networks
TUNA_con_kurosaway.pdf
by
勇 黒沢
Docker管理もHinemosで! ~監視・ジョブ機能を併せ持つ唯一のOSS「Hinemos」のご紹介~
by
Hinemos
K8s-icp-capsmalt-jjugccc2018spring
by
capsmalt
PrometheusによるKubernetes環境の異常検知改善.pptx
by
TakashiTsukamoto4
BlockchainEXE_IBM特集 Cloud Satelliteで実現する分散クラウド時代のIBM Blockchain Platform An...
by
Tsuyoshi Hirayama
Cloud Satelliteで実現する分散クラウド時代のIBM Blockchain Platform Anywhereとエコシステム | 日本アイ・ビ...
by
blockchainexe
Prometheus 監視で変わるもの
by
Takehiro Sugita
OSSで作るOpenStack監視システム
by
satsuki fukazu
Security Operations and Automation on AWS
by
Noritaka Sekiyama
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
Prometeusについてはじめてみよう / Let's start Prometeus
by
Takeo Noda
Micrometer/Prometheusによる大規模システムモニタリング #jsug #sf_26
by
Yahoo!デベロッパーネットワーク
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
クラウド開発に役立つ OSS あれこれ
by
Masataka MIZUNO
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
Prometheus超基礎公開用.pdf
1.
Tech Dojo Prometheus 勉強会 ~概要と簡単な構築まで~ 日本アイ・ビー・エム株式会社 テクノロジー事業本部
カスタマーサクセス カスタマーサクセスマネージャー 黒沢 勇 2022/11/11
2.
Agenda 1. 監視とは? 2. Prometheus
基礎 • 何ができる? • アーキテクチャ • 向いていること、向いていないこと • IBM TechnologyとPrometheus 3. Hands on © 2022 IBM Corporation
3.
監視とは © 2022 IBM
Corporation
4.
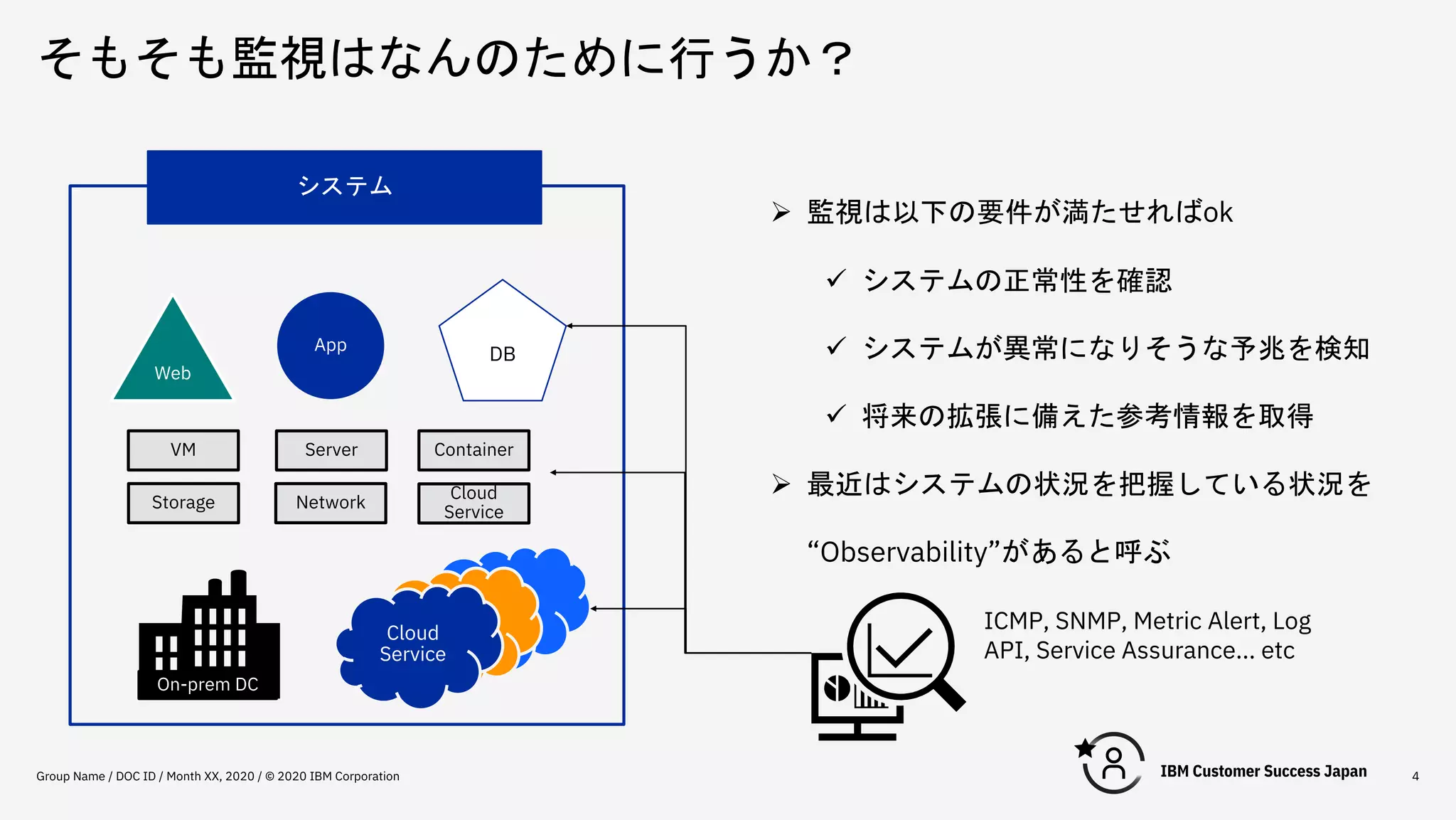
そもそも監視はなんのために行うか? Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 4 Container Web App DB VM Cloud Service On-prem DC システム Ø 監視は以下の要件が満たせればok ü システムの正常性を確認 ü システムが異常になりそうな予兆を検知 ü 将来の拡張に備えた参考情報を取得 Ø 最近はシステムの状況を把握している状況を “Observability”があると呼ぶ Server Storage Network Cloud Service ICMP, SNMP, Metric Alert, Log API, Service Assurance... etc
5.
主な監視の方式 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 5 メトリクス ログ トレーシング 監視対象が 何を行ったのかを文で記述 ex: プロセスAをUser BがKillした 数値データとして 監視対象の情報を取得 ex: CPU使用率、電源on/off ユーザのリクエストに対して、 どのコンポーネントがどれだけ の時間をかけたか表示
6.
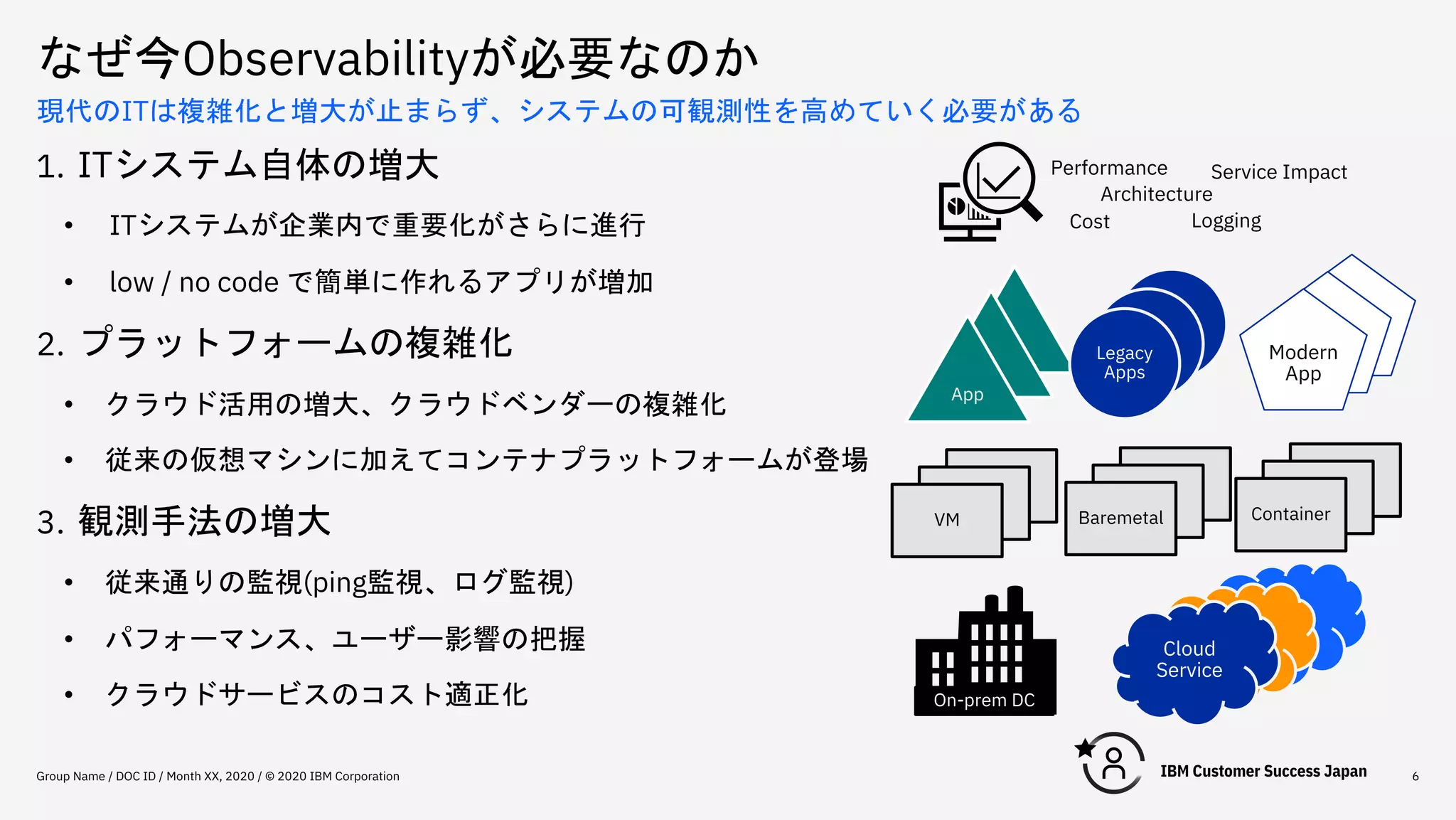
なぜ今Observabilityが必要なのか Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 6 現代のITは複雑化と増大が止まらず、システムの可観測性を高めていく必要がある 1. ITシステム自体の増大 • ITシステムが企業内で重要化がさらに進行 • low / no code で簡単に作れるアプリが増加 2. プラットフォームの複雑化 • クラウド活用の増大、クラウドベンダーの複雑化 • 従来の仮想マシンに加えてコンテナプラットフォームが登場 3. 観測手法の増大 • 従来通りの監視(ping監視、ログ監視) • パフォーマンス、ユーザー影響の把握 • クラウドサービスのコスト適正化 Cloud Service Container App Baremetal Legacy Apps Modern App VM On-prem DC Performance Architecture Cost Logging Service Impact
7.
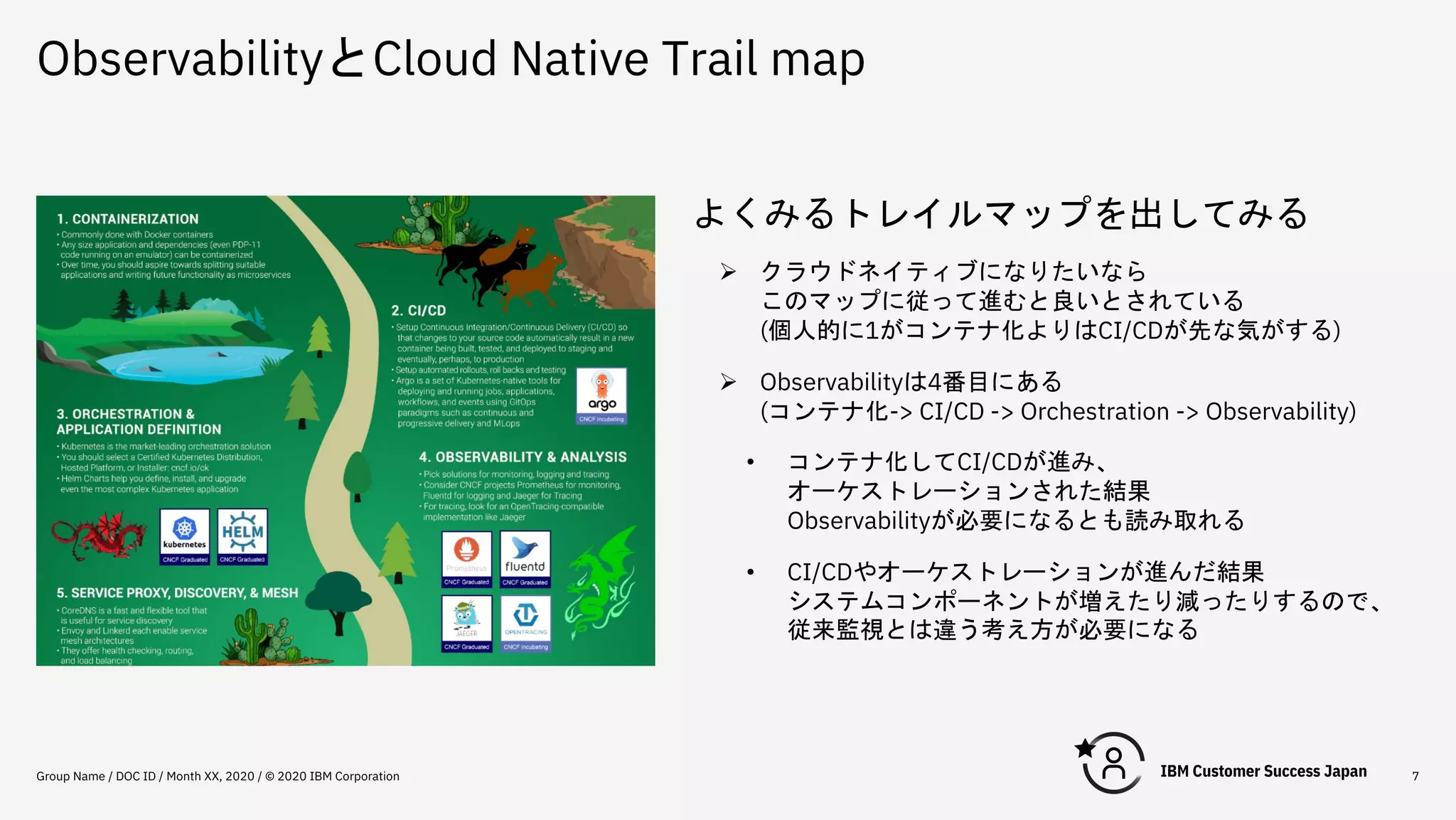
ObservabilityとCloud Native Trail
map Group Name / DOC ID / Month XX, 2020 / © 2020 IBM Corporation 7 よくみるトレイルマップを出してみる Ø クラウドネイティブになりたいなら このマップに従って進むと良いとされている (個人的に1がコンテナ化よりはCI/CDが先な気がする) Ø Observabilityは4番目にある (コンテナ化-> CI/CD -> Orchestration -> Observability) • コンテナ化してCI/CDが進み、 オーケストレーションされた結果 Observabilityが必要になるとも読み取れる • CI/CDやオーケストレーションが進んだ結果 システムコンポーネントが増えたり減ったりするので、 従来監視とは違う考え方が必要になる
8.
Prometheus 基礎 何ができる? Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation
9.
Prometheusとは Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 9 ü オープンソースの監視システムの一種 ü Sound Cloud 社のエンジニアによって2012年に開発 ü Google社のBorgmonにインスパイアを受けて開発 • BorgmonはBorg (k8sの前身)の監視システムとして開発 • Borgmonは分散システムのモニタリング用として最適化 (この特徴をPrometheusは継承) ü 2016年にCNCFのプロジェクトメンバーとして追加 ü 2018年にCNCFのGraduated Project化 (CNCFが十分成熟したとみなした)
10.
Prometheusは何を取得するためのものか? Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 10 メトリクスを取得するためのツールである
11.
主な監視の方式(再掲) Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 11 メトリクス ログ トレーシング 監視対象が 何を行ったのかを文で記述 ex: プロセスAをUser BがKillした 数値データとして 監視対象の情報を取得 ex: CPU使用率、電源on/off ユーザのリクエストに対して、 どのコンポーネントがどれだけ の時間をかけたか表示
12.
Prometheusの特徴4選 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 12 Prometheus Key-value型 ラベル Pull型モデルと Service Discovery Exporterの豊富さ
13.
Prometheusの特徴4選 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 13 Prometheus Key-value型 ラベル Pull型モデルと Service Discovery Exporterの豊富さ
14.
メトリクスとラベル Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 14 PrometheusはラベルとメトリクスをKeyにして値を引いてくる node_cpu_seconds_total {instance=“localhost:9100“} 0.9 メトリクス名 ラベル Key Value ü 上記例はCPUの利用時間を取得するnode_cpu_seconds_totalの例 ü 実際にはrate (node_cpu_seconds_total[5m])のような形でPromQLクエリを実行して値を取得 ※ node_cpu_seconds_total で絞り込みをかけるときには instanceラベル以外にもCPU番号ラベル、CPUのモード(idleなど)を表すラベルも使う
15.
Prometheus 基礎 アーキテクチャ Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation
16.
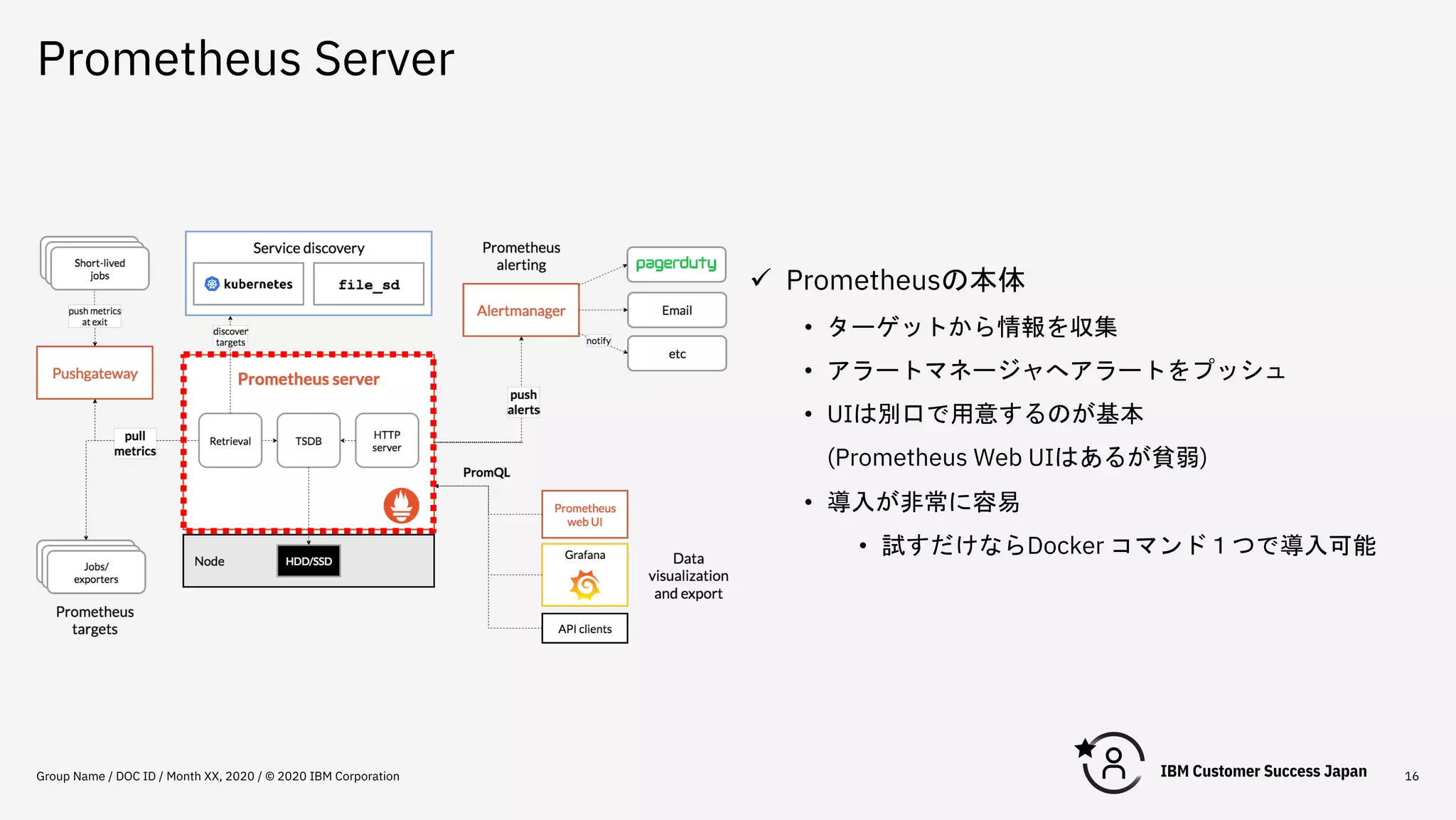
Prometheus Server Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation 16 ü Prometheusの本体 • ターゲットから情報を収集 • アラートマネージャへアラートをプッシュ • UIは別口で用意するのが基本 (Prometheus Web UIはあるが貧弱) • 導入が非常に容易 • 試すだけならDocker コマンド1つで導入可能
17.
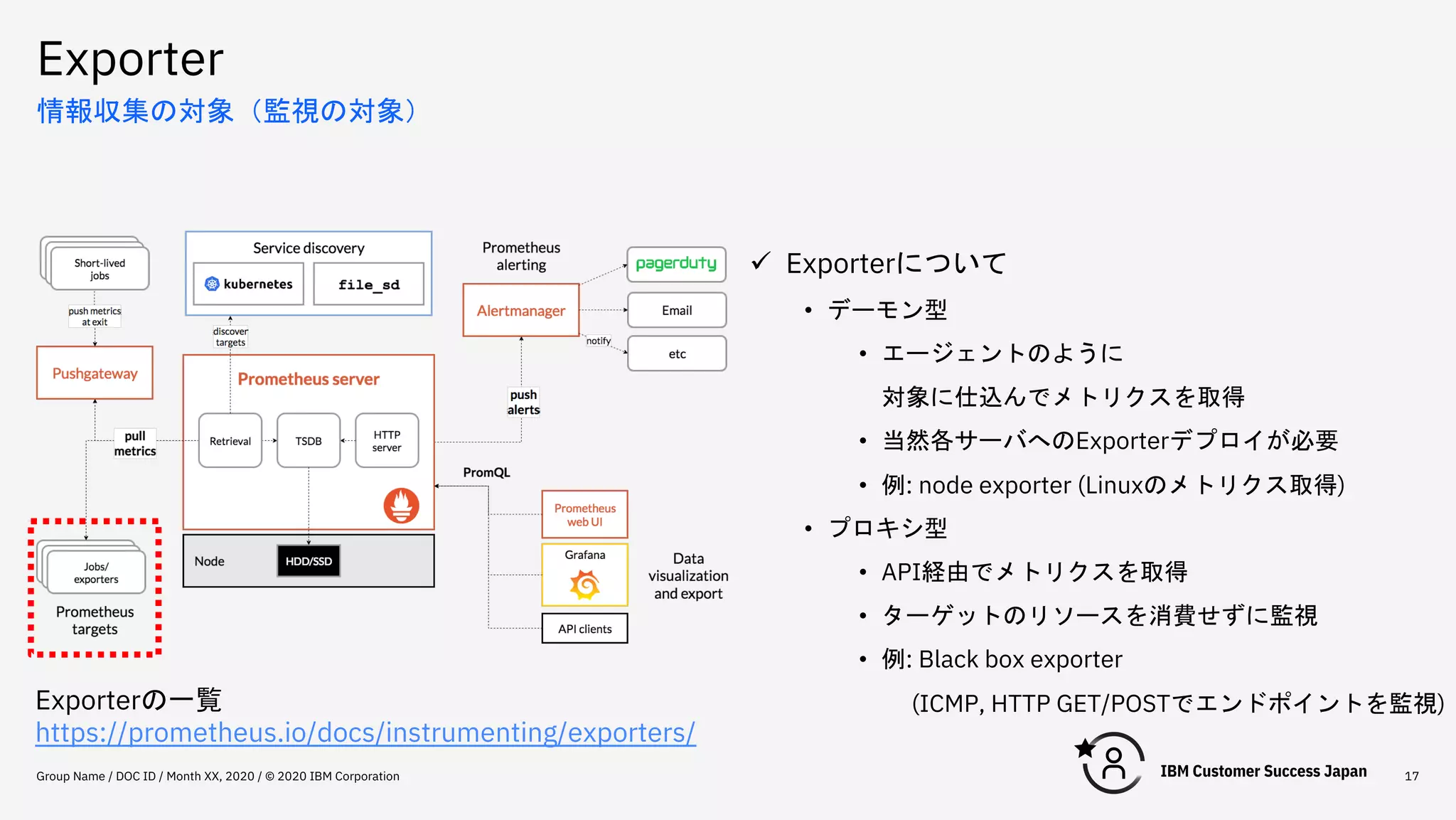
Exporter Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 17 情報収集の対象(監視の対象) ü Exporterについて • デーモン型 • エージェントのように 対象に仕込んでメトリクスを取得 • 当然各サーバへのExporterデプロイが必要 • 例: node exporter (Linuxのメトリクス取得) • プロキシ型 • API経由でメトリクスを取得 • ターゲットのリソースを消費せずに監視 • 例: Black box exporter (ICMP, HTTP GET/POSTでエンドポイントを監視) Exporterの一覧 https://prometheus.io/docs/instrumenting/exporters/
18.
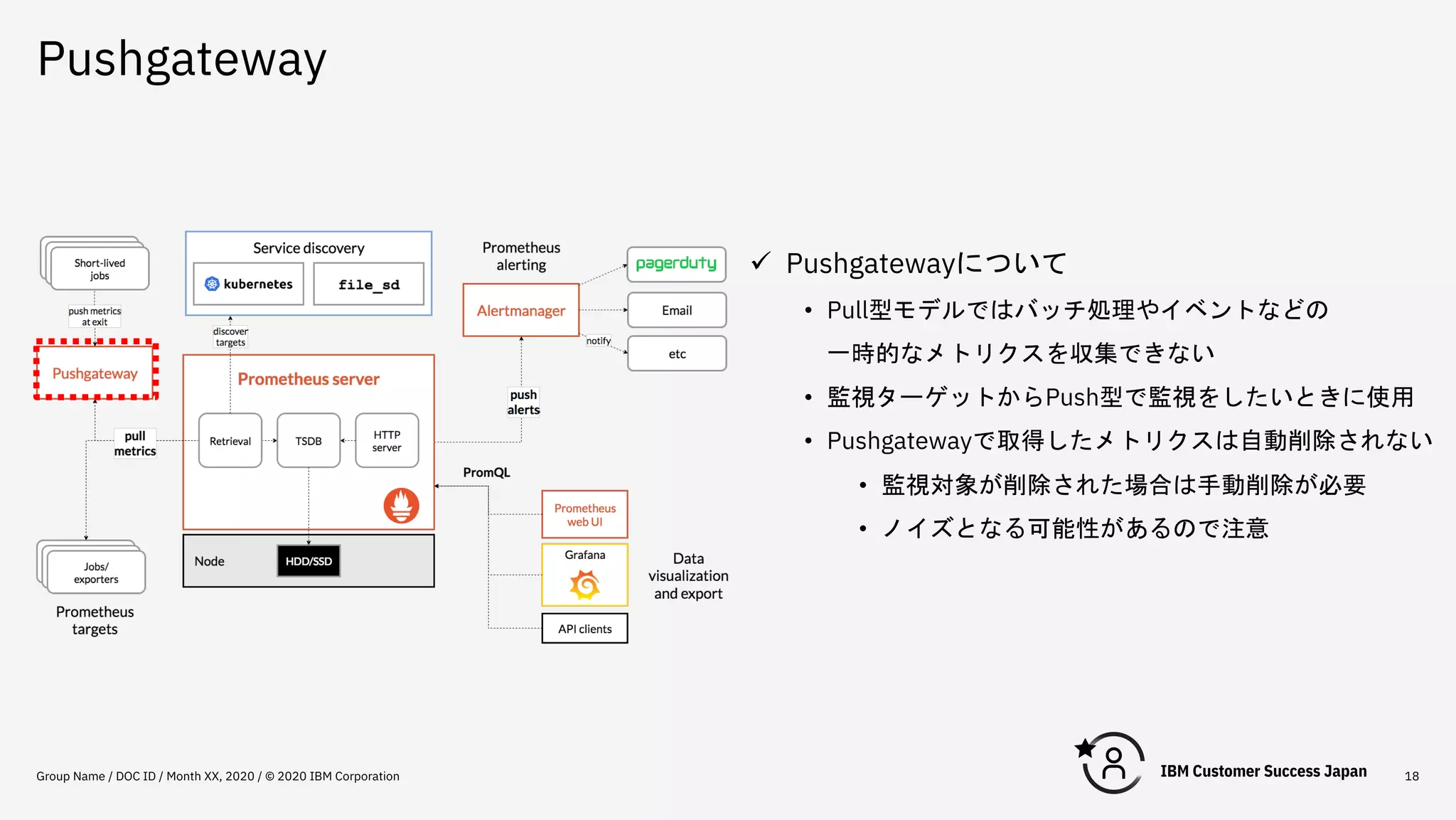
Pushgateway Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 18 ü Pushgatewayについて • Pull型モデルではバッチ処理やイベントなどの 一時的なメトリクスを収集できない • 監視ターゲットからPush型で監視をしたいときに使用 • Pushgatewayで取得したメトリクスは自動削除されない • 監視対象が削除された場合は手動削除が必要 • ノイズとなる可能性があるので注意
19.
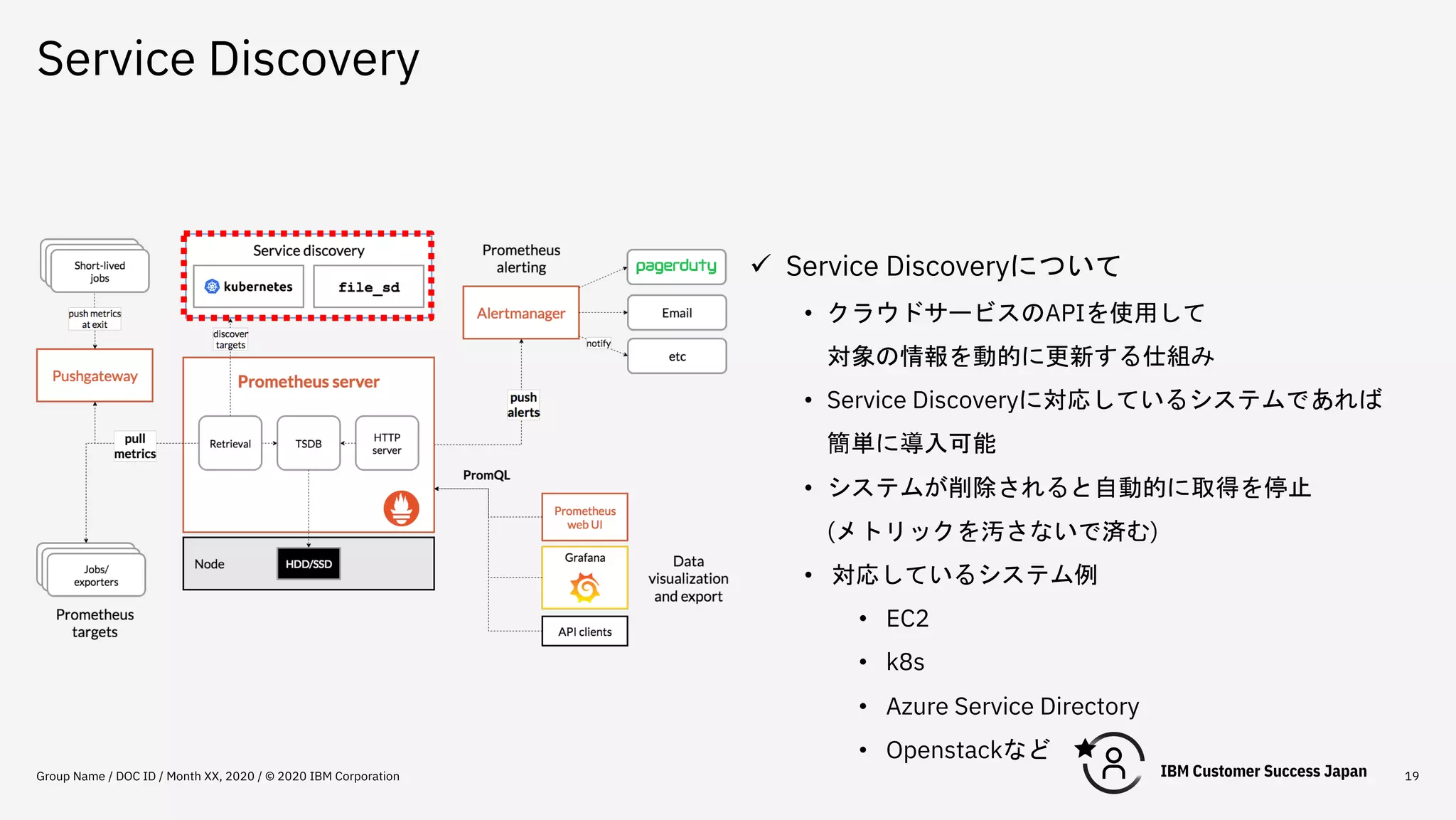
Service Discovery Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation 19 ü Service Discoveryについて • クラウドサービスのAPIを使用して 対象の情報を動的に更新する仕組み • Service Discoveryに対応しているシステムであれば 簡単に導入可能 • システムが削除されると自動的に取得を停止 (メトリックを汚さないで済む) • 対応しているシステム例 • EC2 • k8s • Azure Service Directory • Openstackなど
20.
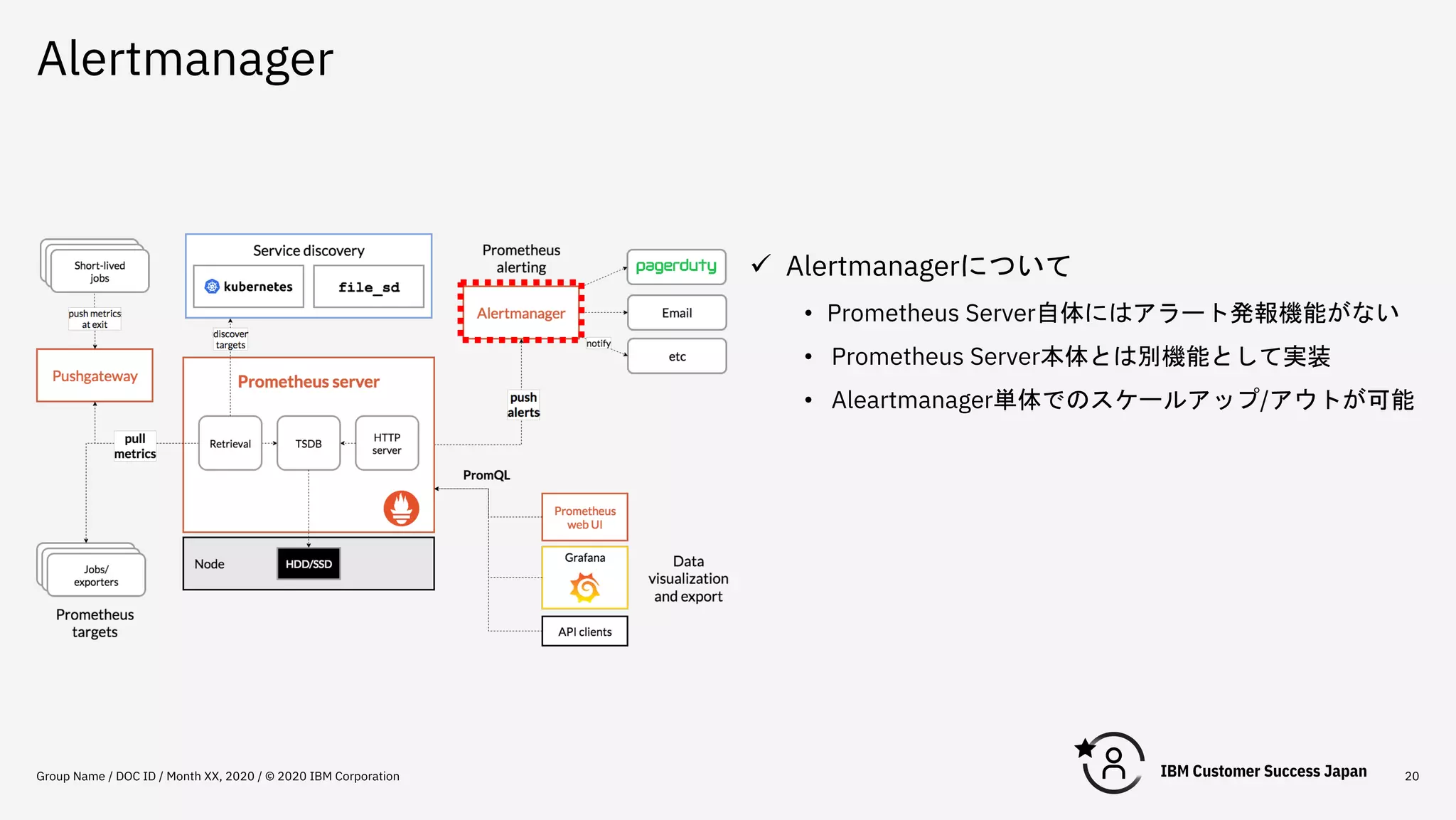
Alertmanager Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 20 ü Alertmanagerについて • Prometheus Server自体にはアラート発報機能がない • Prometheus Server本体とは別機能として実装 • Aleartmanager単体でのスケールアップ/アウトが可能
21.
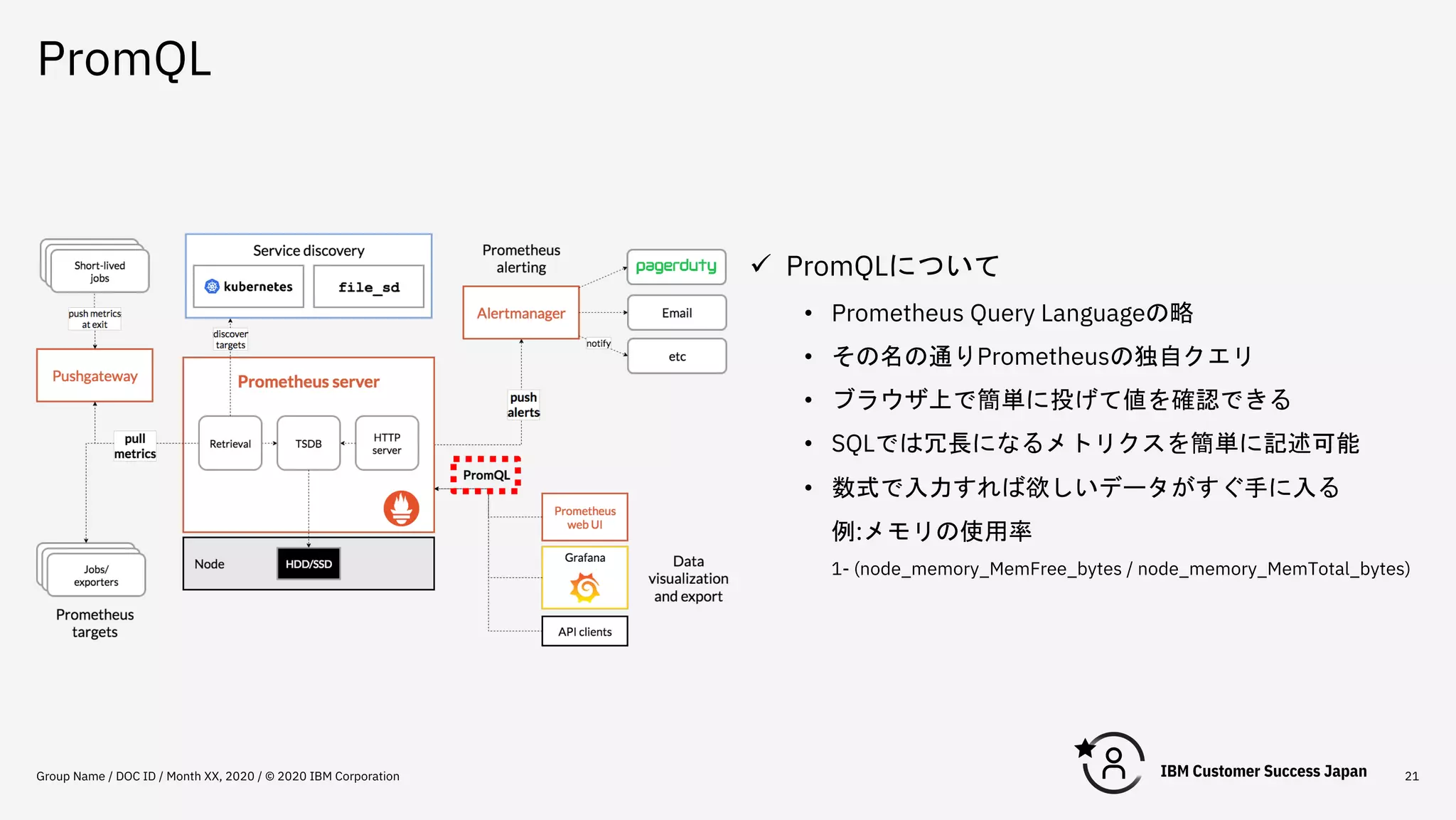
PromQL Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 21 ü PromQLについて • Prometheus Query Languageの略 • その名の通りPrometheusの独自クエリ • ブラウザ上で簡単に投げて値を確認できる • SQLでは冗長になるメトリクスを簡単に記述可能 • 数式で入力すれば欲しいデータがすぐ手に入る 例:メモリの使用率 1- (node_memory_MemFree_bytes / node_memory_MemTotal_bytes)
22.
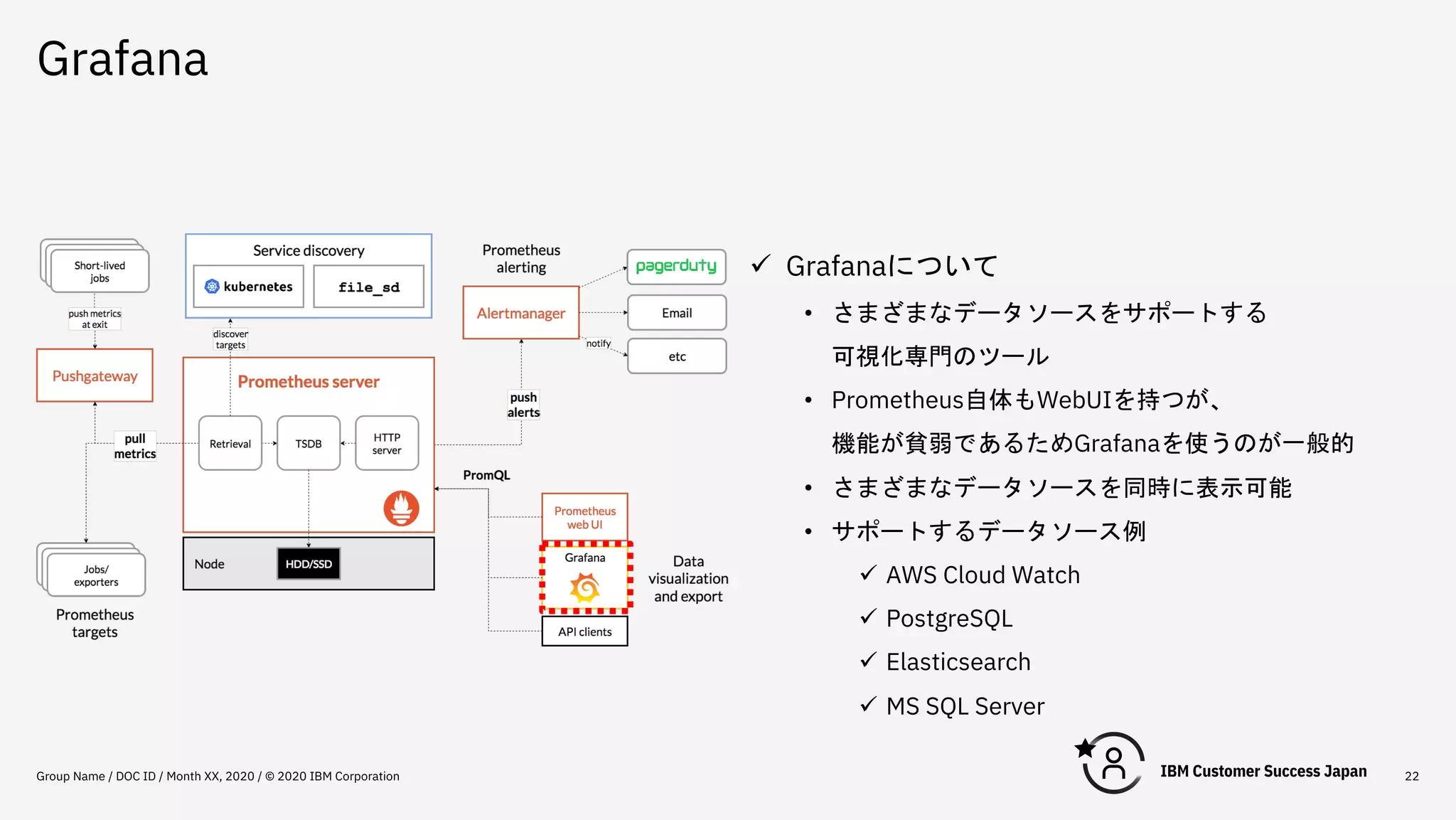
Grafana Group Name /
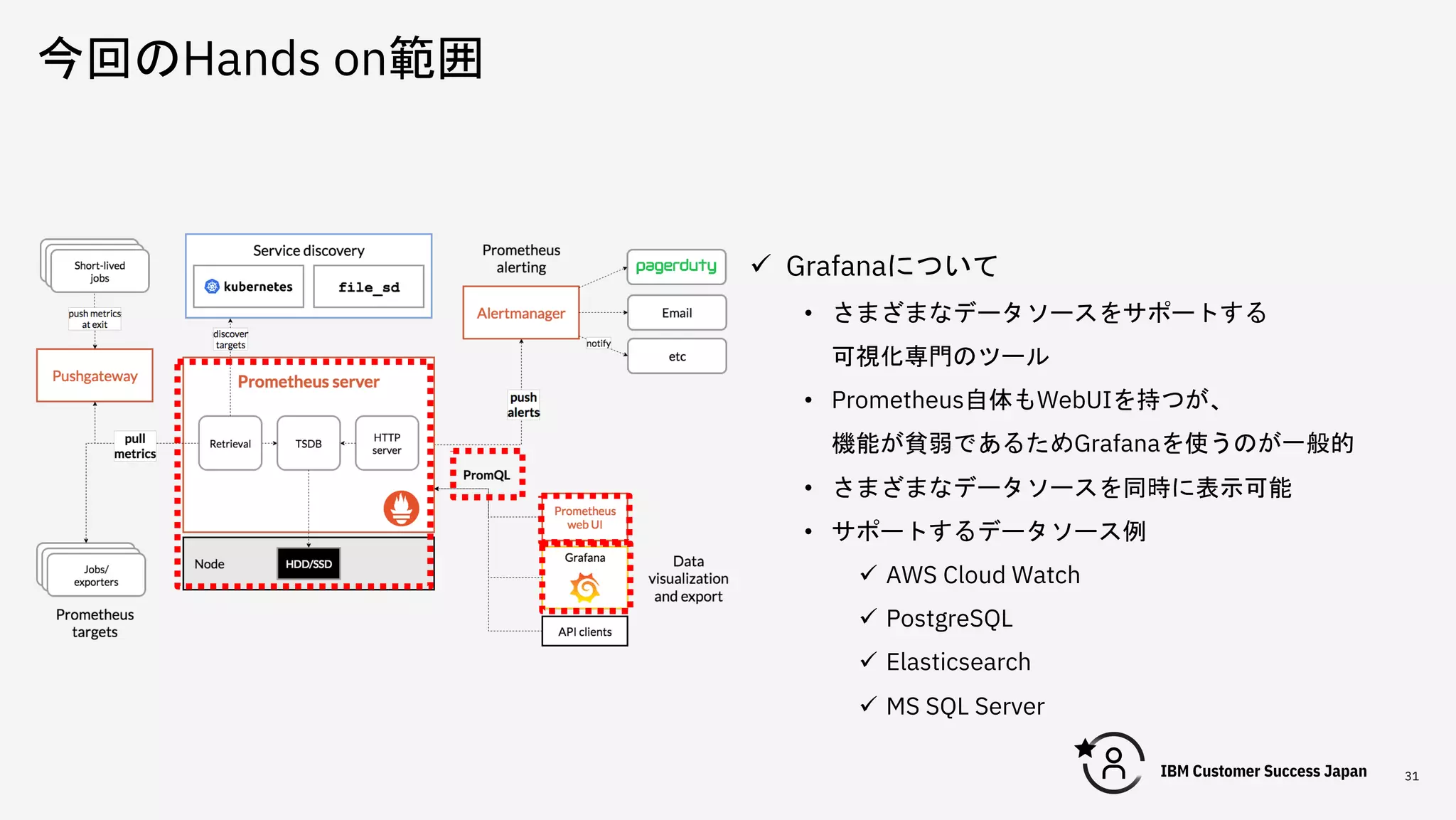
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 22 ü Grafanaについて • さまざまなデータソースをサポートする 可視化専門のツール • Prometheus自体もWebUIを持つが、 機能が貧弱であるためGrafanaを使うのが一般的 • さまざまなデータソースを同時に表示可能 • サポートするデータソース例 ü AWS Cloud Watch ü PostgreSQL ü Elasticsearch ü MS SQL Server
23.
Prometheus 基礎 向いていること、向いていないこと Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation
24.
Prometheusが得意なこと Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 24 Ø 導入が容易 • 本体はメトリクスの収集とクエリの実行のみ Ø スケールするシステムへの適用 • サービスディスカバリ機能でシステムがボコボコ発生しても大丈夫 • Exporterが豊富にあり、標準的なシステムならすぐに仕込める(設定が少ない) Ø 機能ごとのスケール • 各コンポーネントが独立しているのでPrometheus自体のスケールがしやすい
25.
Prometheusが苦手なこと(できないこと) Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 25 Ø ログの管理 • Promehteusはログの管理を目的としていません • アプリケーションの完全な可視化を行うためにはログも必要 別途ログ管理、可視化システムを導入しましょう Ø データの完全性の保証 • Prometheusはデータの完全性を保証しない Ø サポートの提供 • 当然issueはGithubから頑張って解決
26.
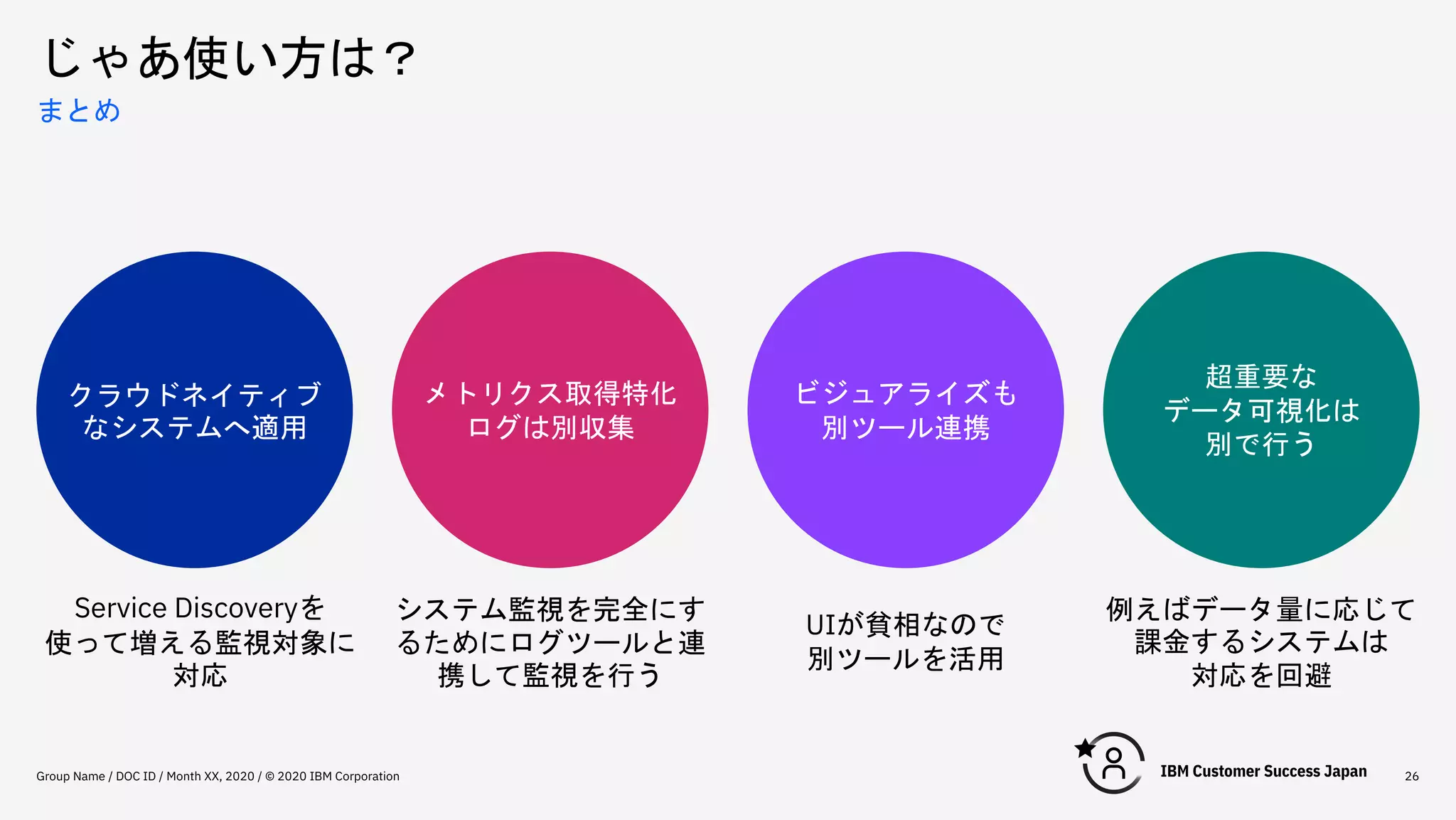
じゃあ使い方は? Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 26 まとめ クラウドネイティブ なシステムへ適用 メトリクス取得特化 ログは別収集 ビジュアライズも 別ツール連携 超重要な データ可視化は 別で行う Service Discoveryを 使って増える監視対象に 対応 システム監視を完全にす るためにログツールと連 携して監視を行う UIが貧相なので 別ツールを活用 例えばデータ量に応じて 課金するシステムは 対応を回避
27.
大規模監視を行う上で考慮すべき点 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 27 コスト 冗長性/パフォーマンス Prometheus自身の監視 各コンポーネントの負荷を見て 冗長性を高める サービスは金がかかる ある程度の規模になったら オンプレの方がコストメリット が出る 他のシステムを使って Prometheus自身を監視する
28.
おすすめの書籍 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 28 Docs / Gitを眺めるだけでは全体感を知るのは厳しい https://www.oreilly.co.jp/books/9784873118642/ 監視とは何かが分かる本。 Prometheusに関わらず、監視をきちんと勉強したい方におすすめ
29.
おすすめの書籍 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 29 Docs/Gitを眺めるだけでは全体感を知るのは厳しい 私もこれから読むレベルですが内容が少し高度らしいです 基礎から学べるとの文言に偽りなし。
30.
Call to Action Group
Name / DOC ID / Month XX, 2020 / © 2020 IBM Corporation 30 実際に始めてみよう(Prometheus実践ガイドより) 1. 実際にDeploy してみる 2. node exporterをDeployしてメトリクスを収集する 3. サービスディスカバリを使用して自動管理する 4. メトリクスを可視化する 5. Alertmanagerでアラートを発報する 6. エクスポータを自作する 7. エコシステムと連携する
31.
今回のHands on範囲 31 ü Grafanaについて •
さまざまなデータソースをサポートする 可視化専門のツール • Prometheus自体もWebUIを持つが、 機能が貧弱であるためGrafanaを使うのが一般的 • さまざまなデータソースを同時に表示可能 • サポートするデータソース例 ü AWS Cloud Watch ü PostgreSQL ü Elasticsearch ü MS SQL Server
32.
Deploy方法 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 34 prometheus 本体 • バイナリを利用する • 比較的簡単 • wgetでひっぱり、tarで解凍するだけ - wget https://github.com/prometheus/prometheus/releases/download/v2.40.4/prometheus-2.40.4.linux-386.tar.gz - tar xfvz prometheus-2.40.4.linux-386.tar.gz - ./prometheus & • ソースコードからビルドをかける • GO環境が必要だったりするので面倒。 • Docker コンテナを利用する • docker runですぐ起動可能 - docker run –m –name prom –d –p 9090:9090 prom/prometheus:v2.40.4
33.
Deploy方法 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 35 Grafana • パッケージマネージャを利用する • 比較的簡単 - wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add - - echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list - sudo apt-get update - sudo apt-get install grafana - sudo systemctl start grafana-server • Docker コンテナを利用する • docker runですぐ起動可能 - docker run –name grafana –d –p 3000:3000 grafana/grafana:8.3.6
34.
Deploy方法 36 node exporter • 監視対象のコンソールで以下のコマンドを実行 •
wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0/node_exporter-1.4.0.linux-amd64.tar.gz • tar xvfz node_exporter-1.4.0.linux-amd64.tar.gz • cd node_exporter-1.4.0.linux-amd64/ • ./node_exporter & • Prometheus server上のコンソールでprometheus.ymlファイルを編集し、赤字部分を追加 (文頭を必ず揃えること、ifconfigあたりで監視対象のIPアドレスは調べてください) scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: "node" static_configs: - targets: [”<your_node_exporter_ip>:9100"] #your node exporter ipはlocalhostでもOK
35.
Deploy 方法 Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation 37 alert manager • Alert managerのコンソールで以下のコマンドを実行 • wget https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz • tar xvfz alertmanager-0.23.0.linux-amd64.tar.gz • cd alertmanager-0.23.0.linux-amd64.tar.gz • ./alertmanager &
36.
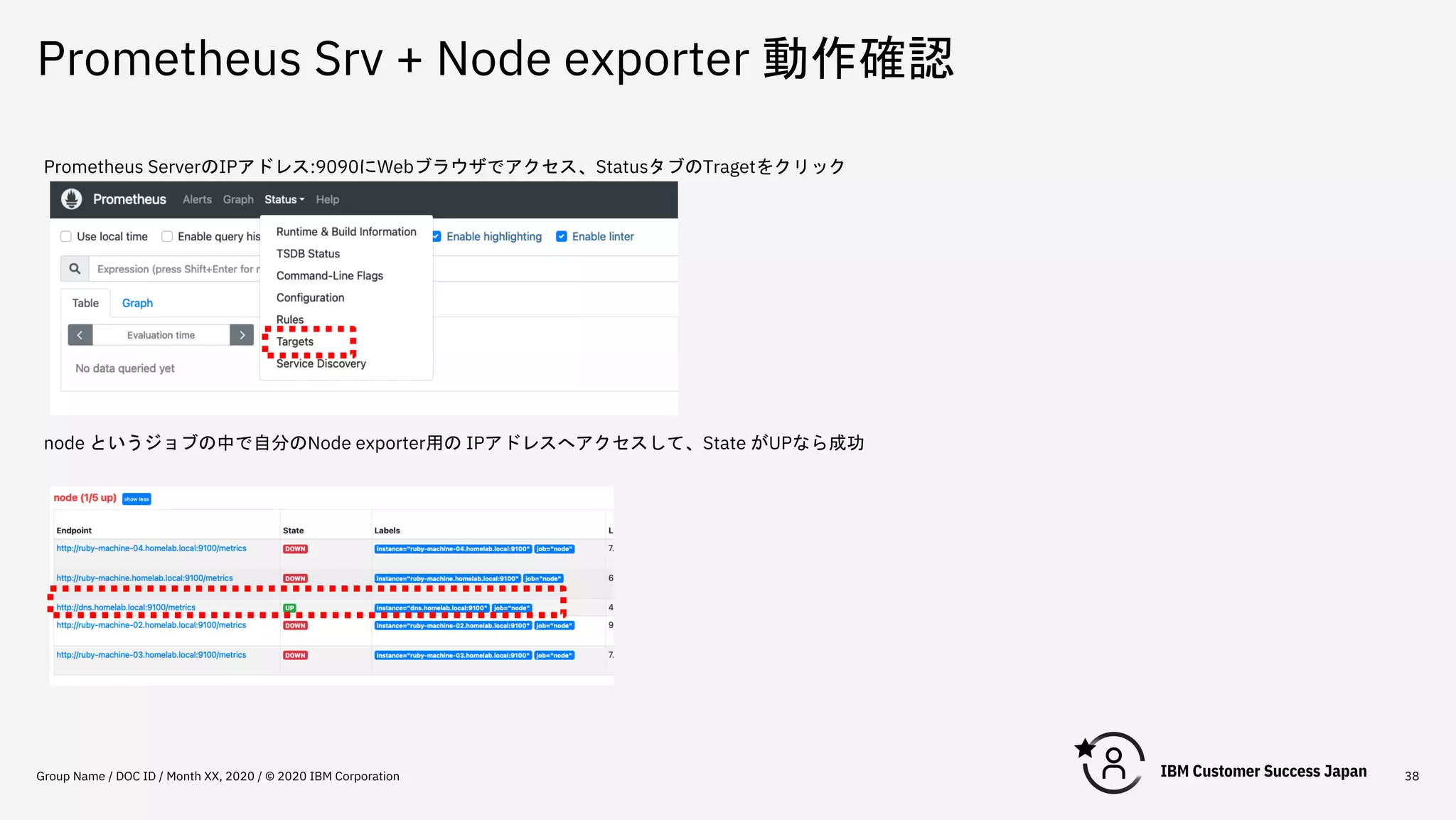
Prometheus Srv +
Node exporter 動作確認 Group Name / DOC ID / Month XX, 2020 / © 2020 IBM Corporation 38 Prometheus ServerのIPアドレス:9090にWebブラウザでアクセス、StatusタブのTragetをクリック node というジョブの中で自分のNode exporter用の IPアドレスへアクセスして、State がUPなら成功
37.
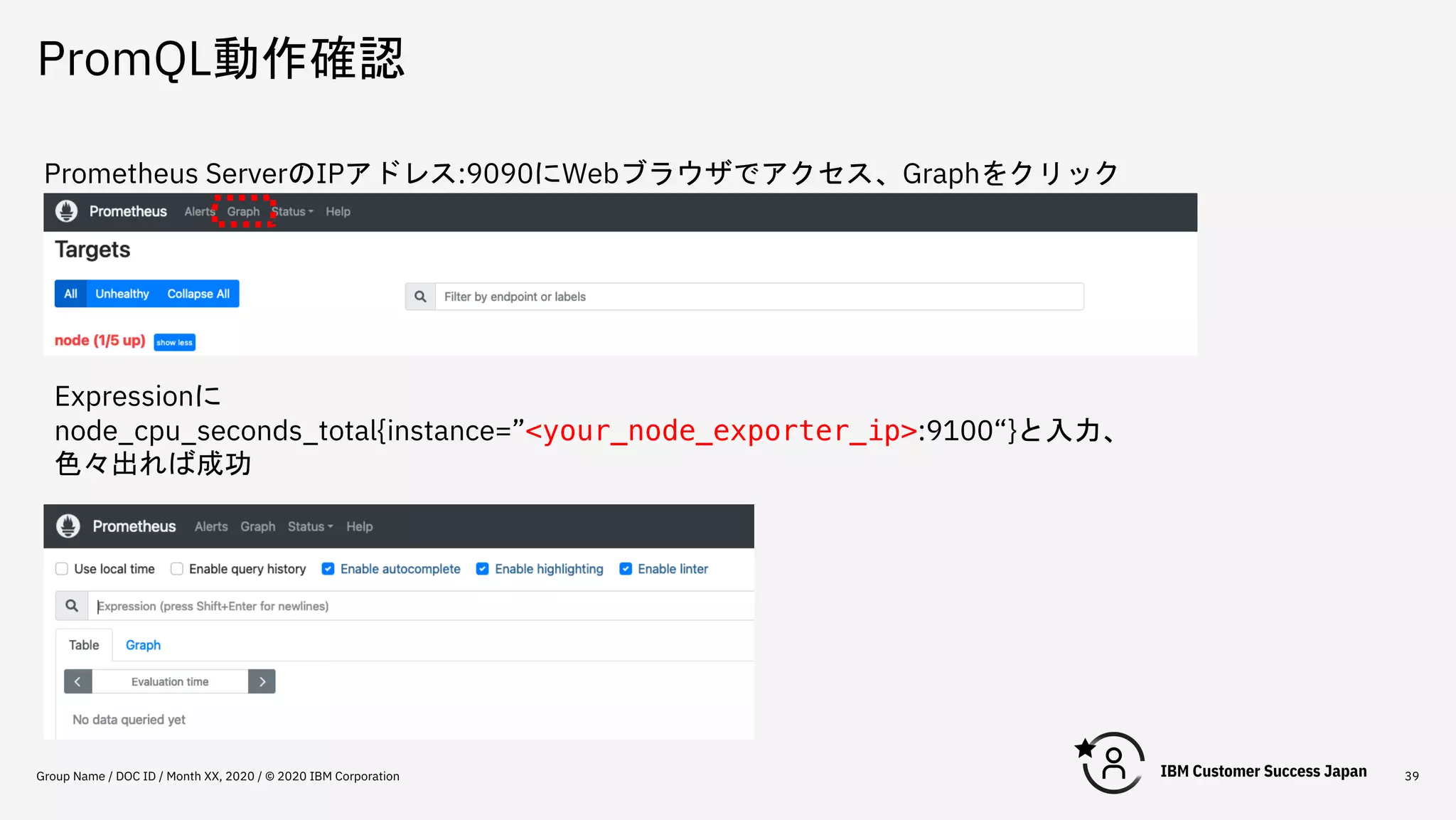
PromQL動作確認 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 39 Prometheus ServerのIPアドレス:9090にWebブラウザでアクセス、Graphをクリック Expressionに node_cpu_seconds_total{instance=”<your_node_exporter_ip>:9100“}と入力、 色々出れば成功
38.
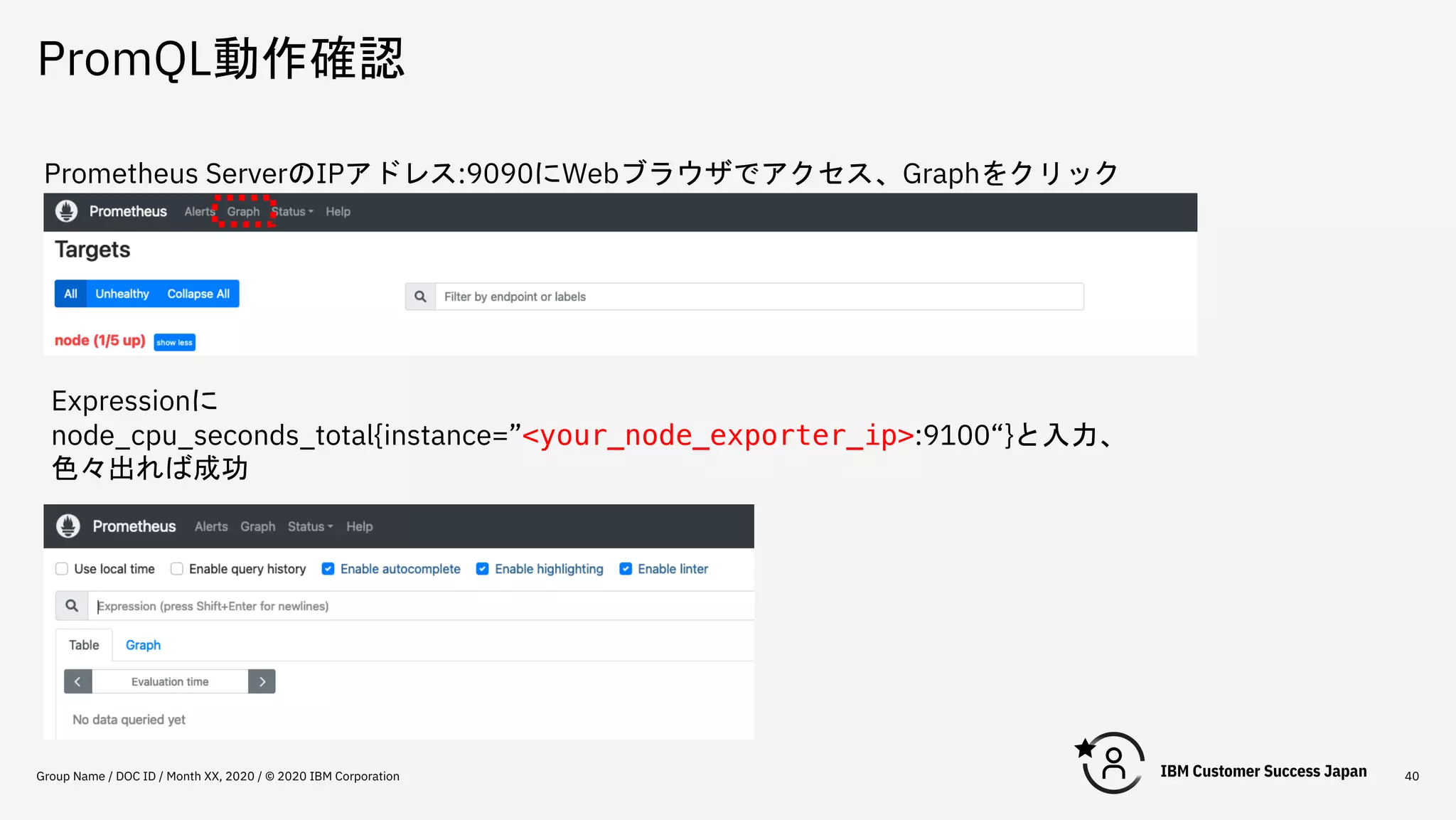
PromQL動作確認 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 40 Prometheus ServerのIPアドレス:9090にWebブラウザでアクセス、Graphをクリック Expressionに node_cpu_seconds_total{instance=”<your_node_exporter_ip>:9100“}と入力、 色々出れば成功
39.
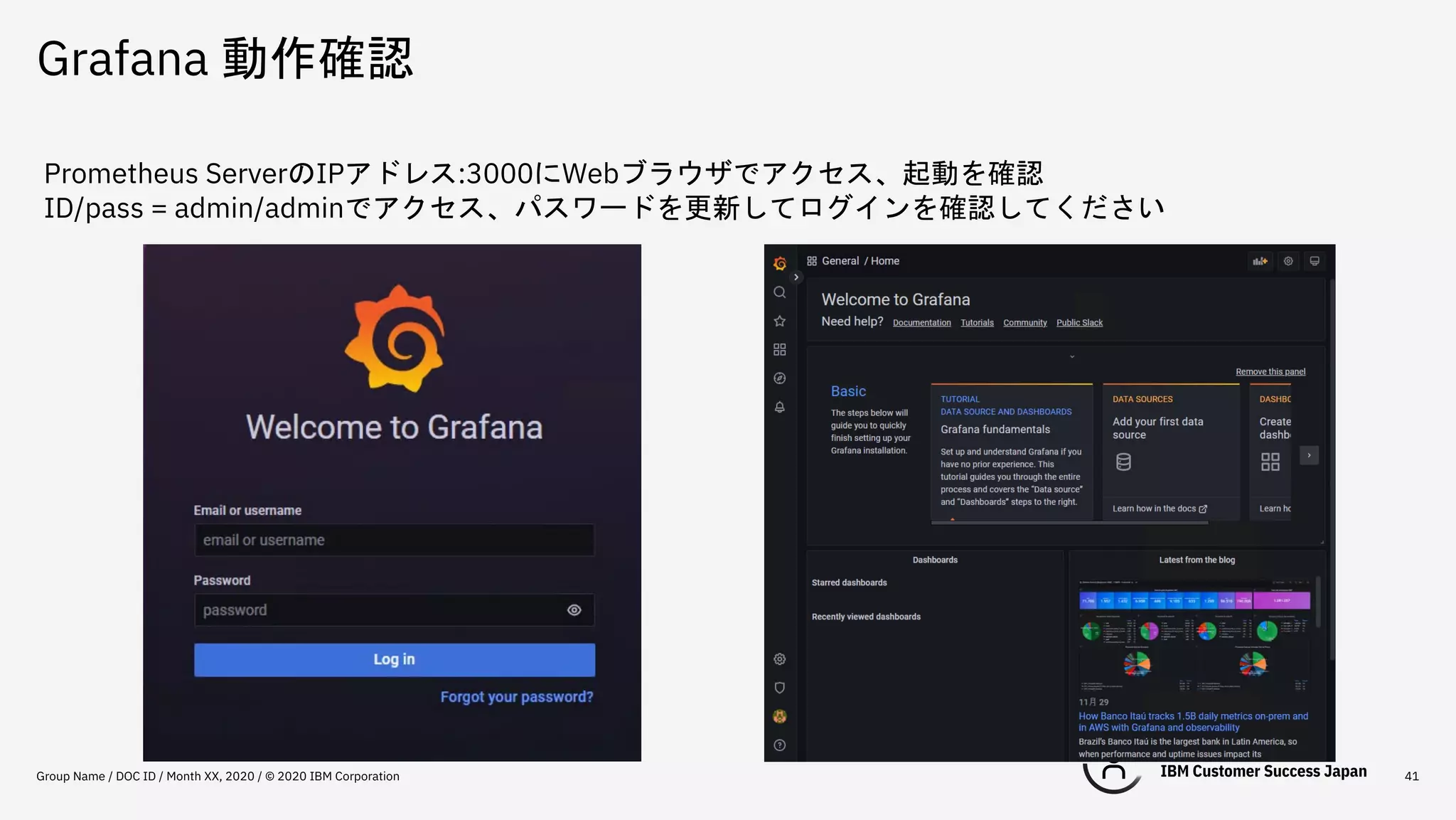
Grafana 動作確認 Group Name
/ DOC ID / Month XX, 2020 / © 2020 IBM Corporation 41 Prometheus ServerのIPアドレス:3000にWebブラウザでアクセス、起動を確認 ID/pass = admin/adminでアクセス、パスワードを更新してログインを確認してください
40.
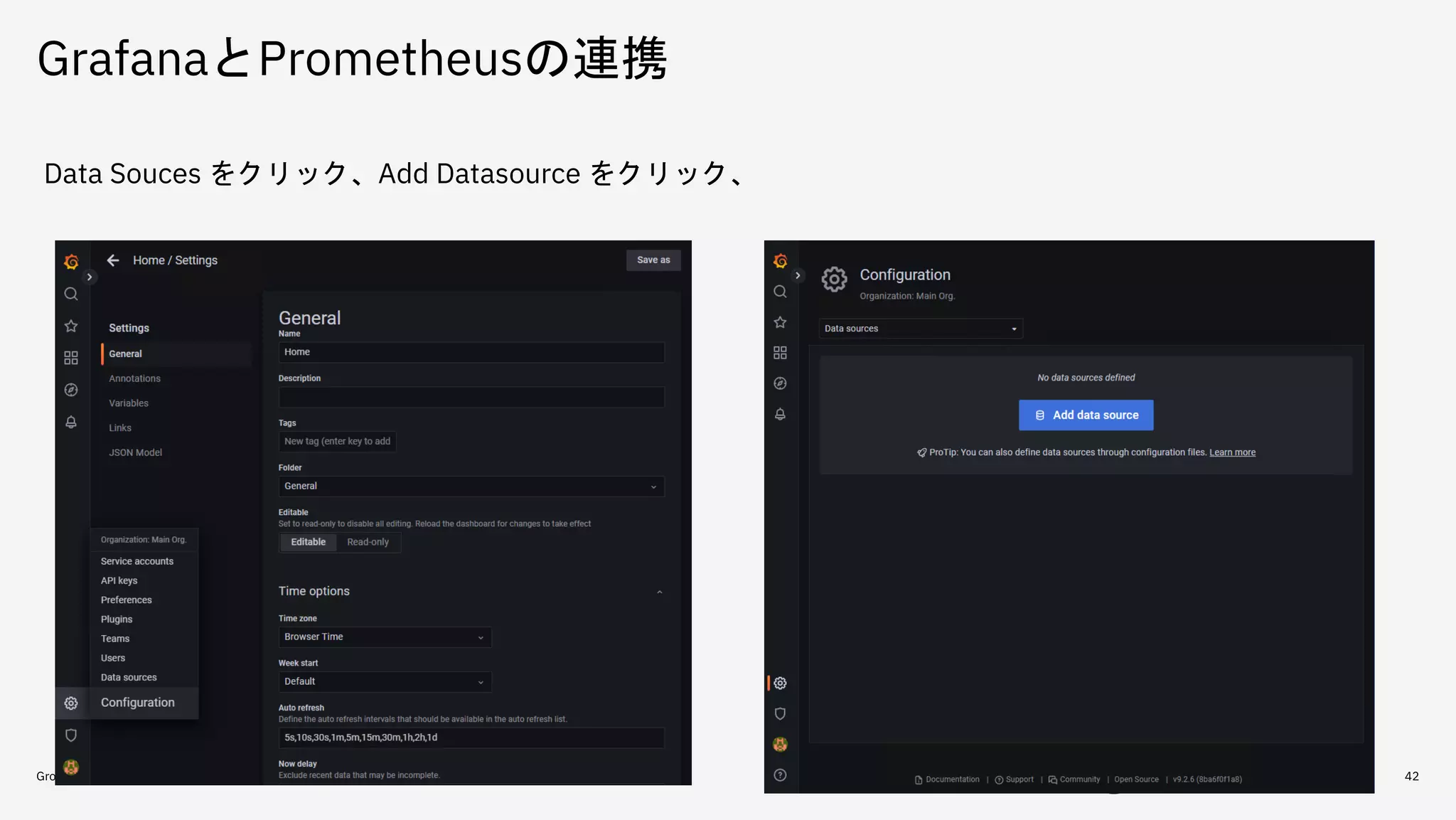
GrafanaとPrometheusの連携 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 42 Data Souces をクリック、Add Datasource をクリック、
41.
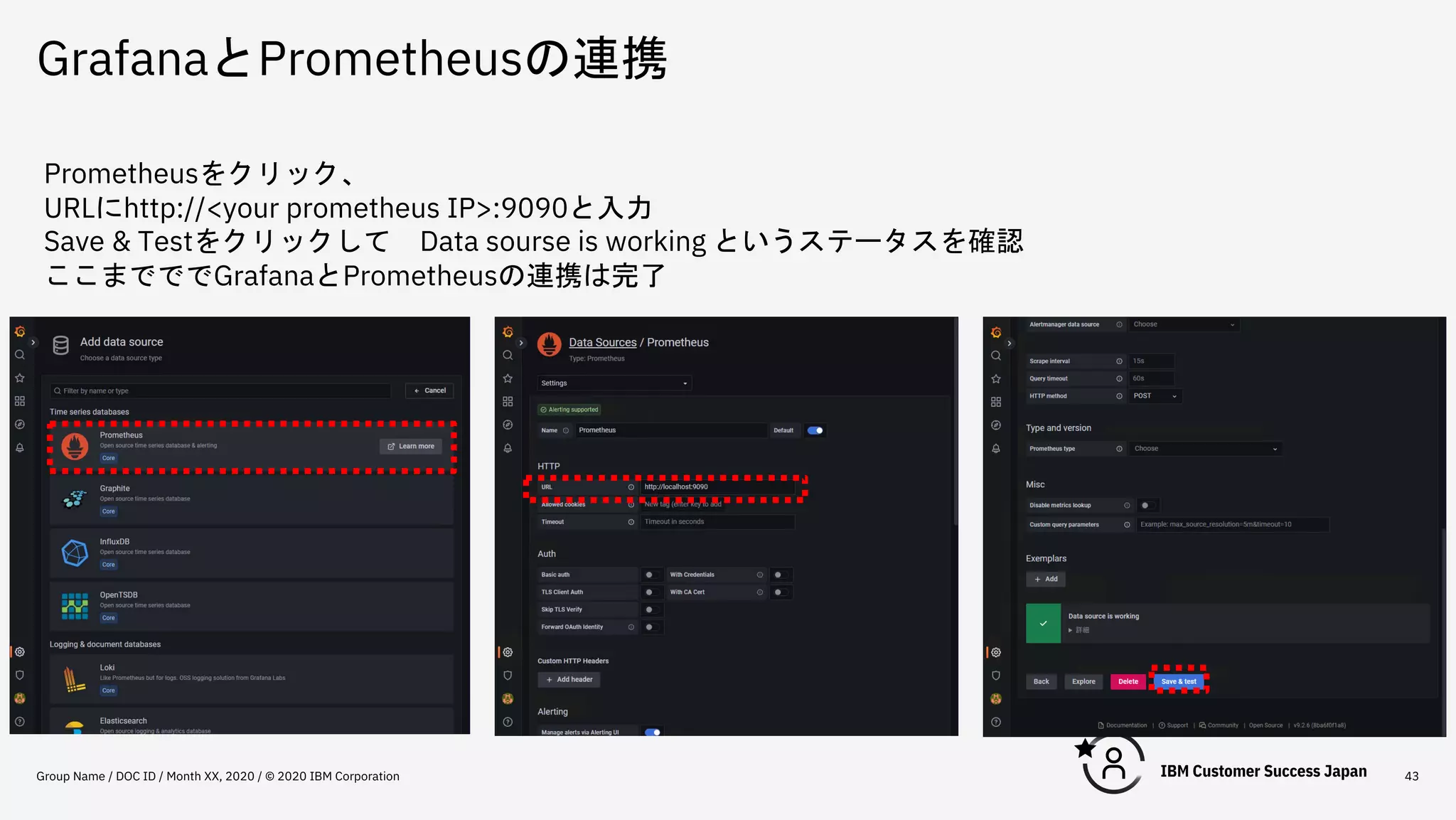
GrafanaとPrometheusの連携 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 43 Prometheusをクリック、 URLにhttp://<your prometheus IP>:9090と入力 Save & Testをクリックして Data sourse is working というステータスを確認 ここまでででGrafanaとPrometheusの連携は完了
42.
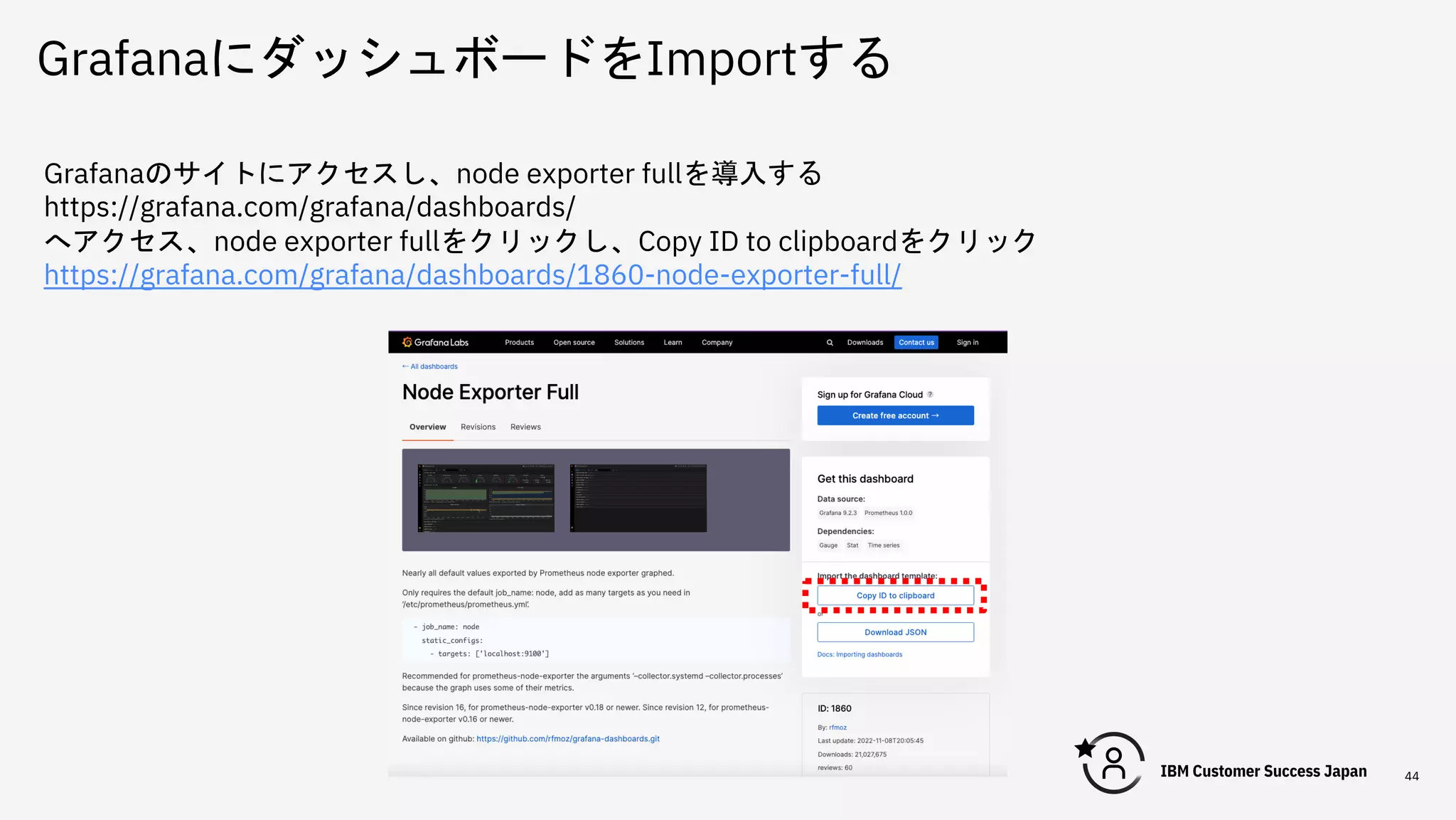
GrafanaにダッシュボードをImportする 44 Grafanaのサイトにアクセスし、node exporter fullを導入する https://grafana.com/grafana/dashboards/ へアクセス、node
exporter fullをクリックし、Copy ID to clipboardをクリック https://grafana.com/grafana/dashboards/1860-node-exporter-full/
43.
GrafanaにダッシュボードをImportする Group Name /
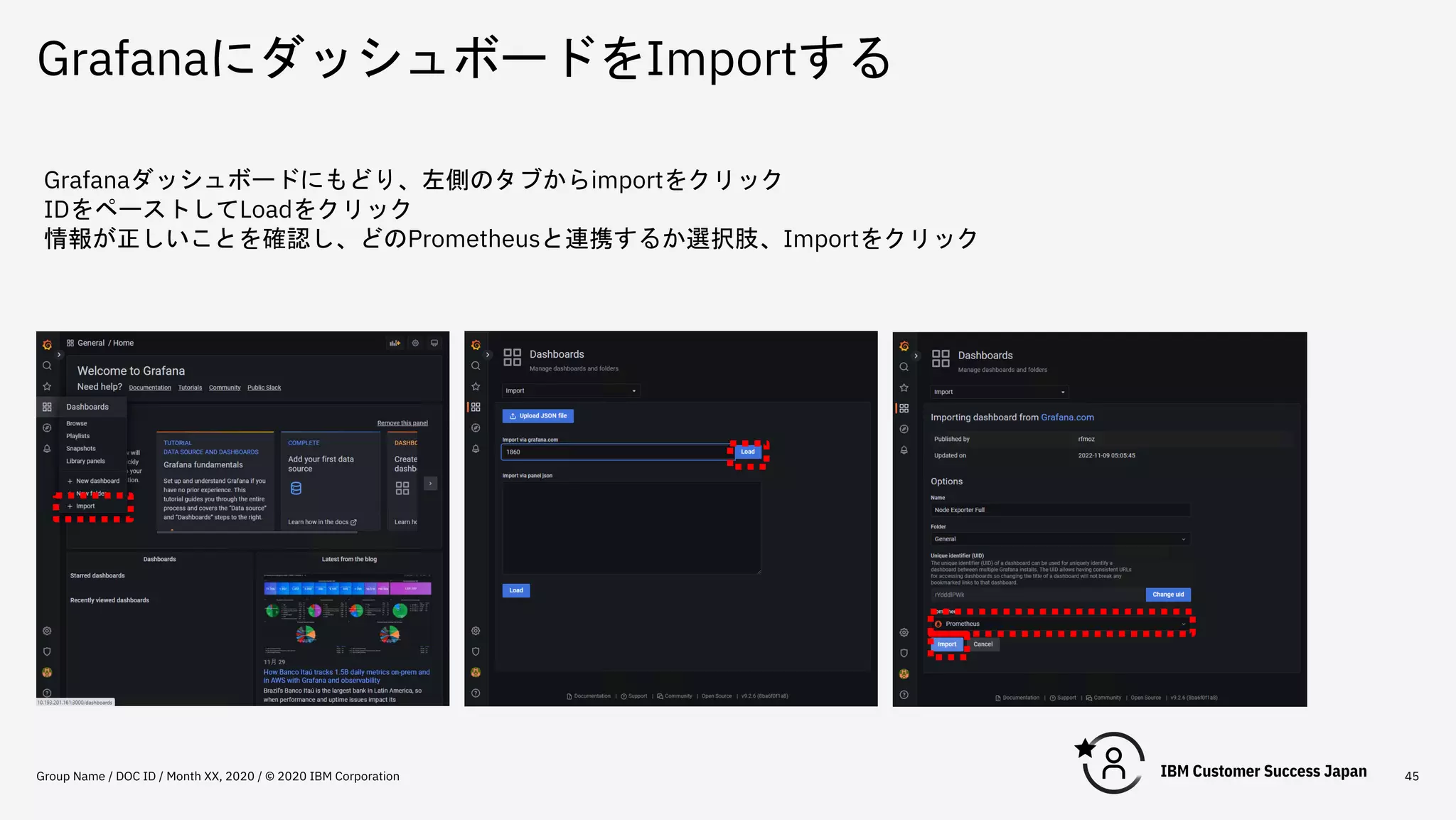
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 45 Grafanaダッシュボードにもどり、左側のタブからimportをクリック IDをペーストしてLoadをクリック 情報が正しいことを確認し、どのPrometheusと連携するか選択肢、Importをクリック
44.
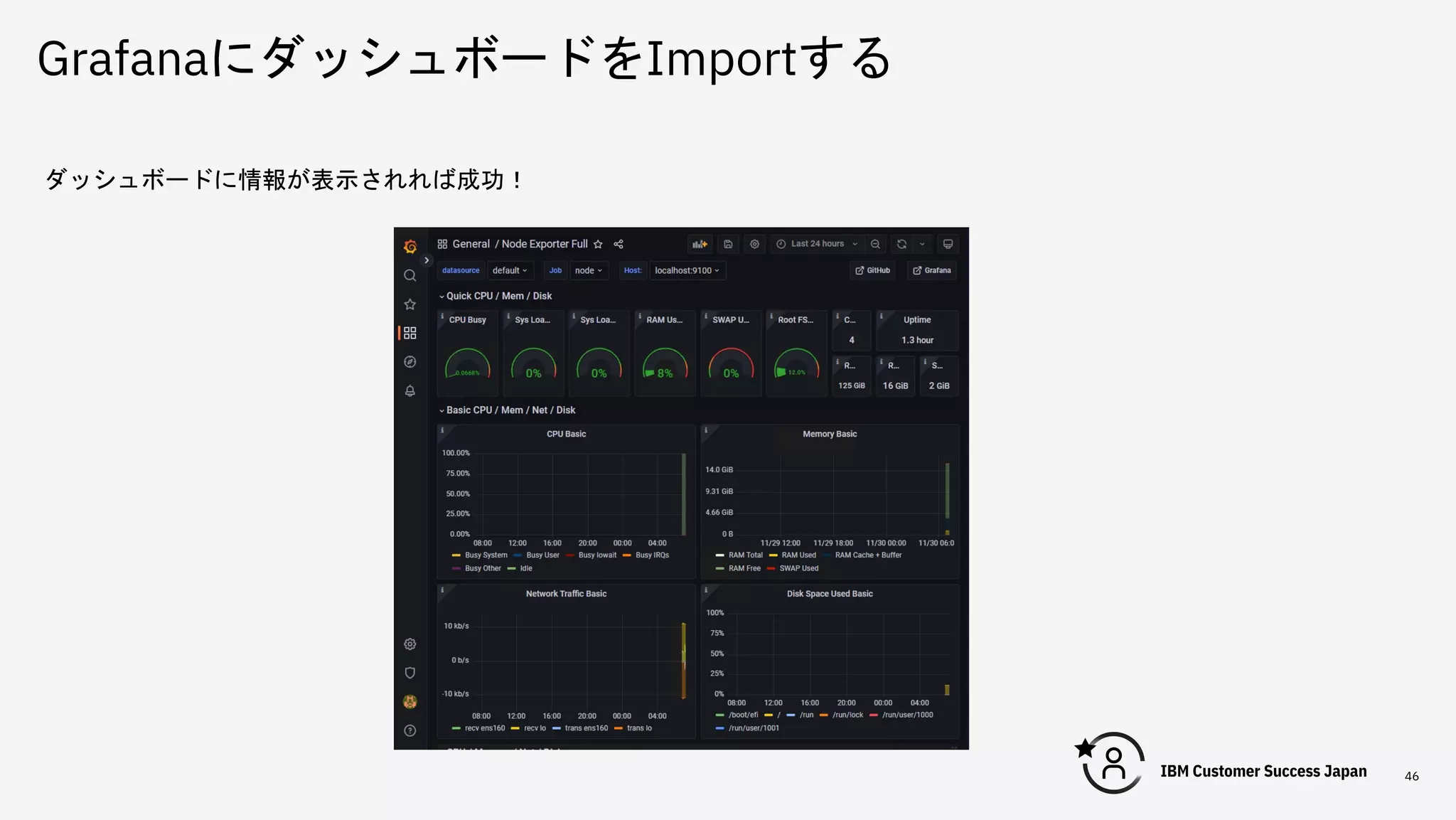
GrafanaにダッシュボードをImportする 46 ダッシュボードに情報が表示されれば成功!
45.
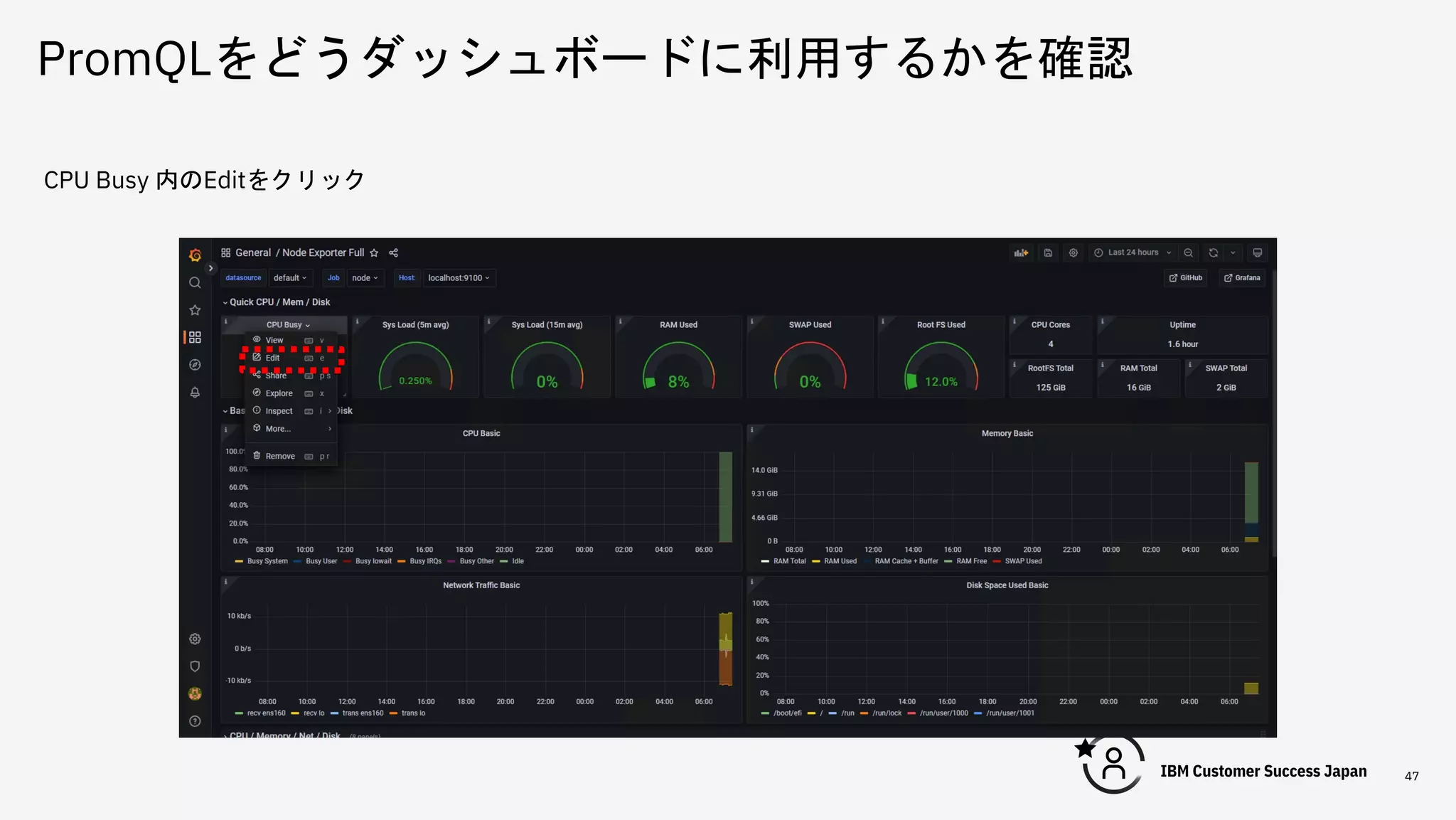
PromQLをどうダッシュボードに利用するかを確認 47 CPU Busy 内のEditをクリック
46.
PromQLをどうダッシュボードに利用するかを確認 48 Metric Browser のexplain
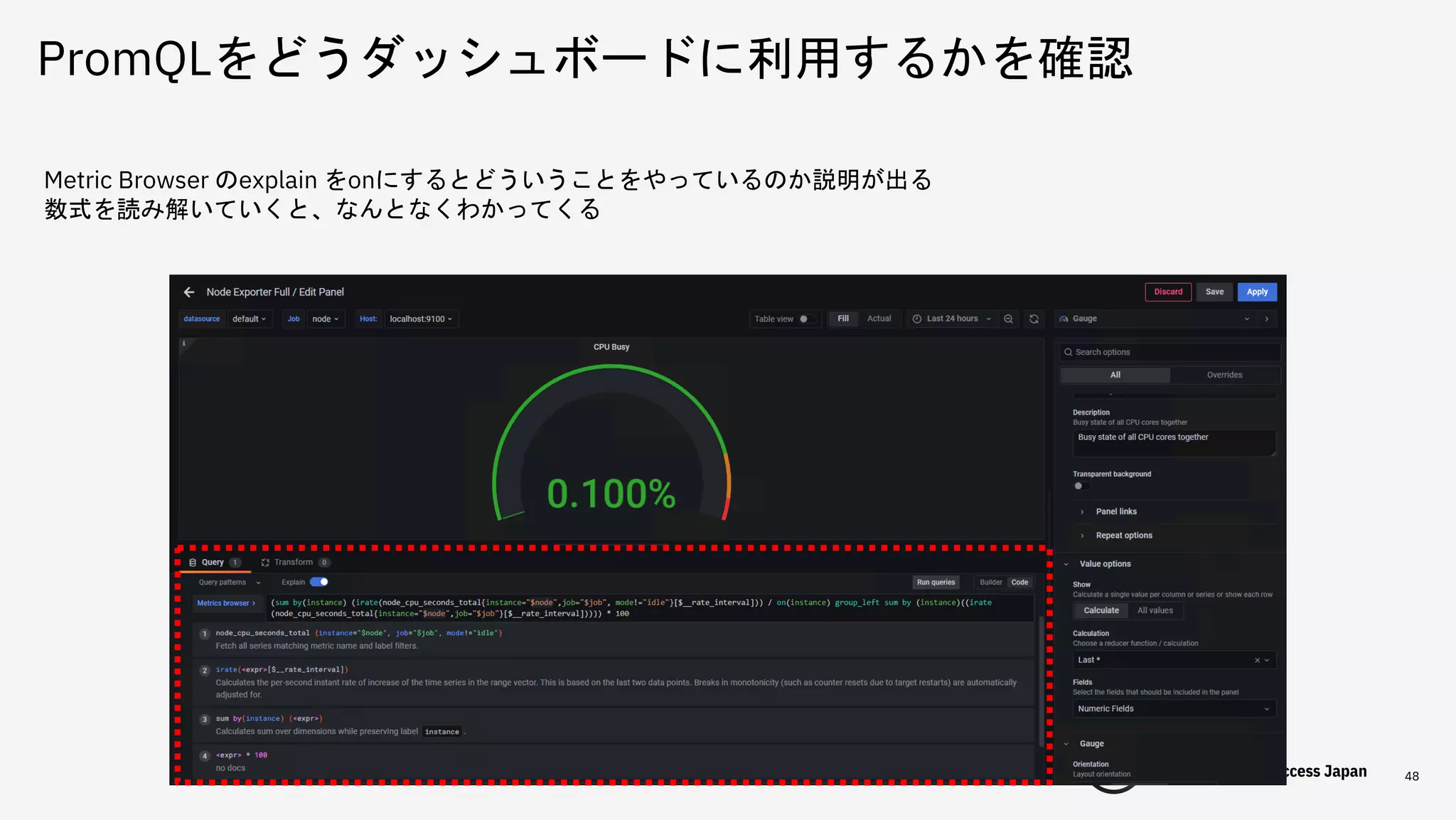
をonにするとどういうことをやっているのか説明が出る 数式を読み解いていくと、なんとなくわかってくる
47.
次回予告 Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 49 • 同じような環境用意してk8sとPrometheusの連携をやりたい • 他のDB系のデータがどう見えるのかを見てみたい • IBM製品との連携を見せたい • Slackでの連携どんな感じなのかみたい
48.
Group Name /
DOC ID / Month XX, 2020 / © 2020 IBM Corporation 56
Download









![メトリクスとラベル
Group Name / DOC ID / Month XX, 2020 / © 2020 IBM Corporation 14
PrometheusはラベルとメトリクスをKeyにして値を引いてくる
node_cpu_seconds_total {instance=“localhost:9100“} 0.9
メトリクス名 ラベル
Key Value
ü 上記例はCPUの利用時間を取得するnode_cpu_seconds_totalの例
ü 実際にはrate (node_cpu_seconds_total[5m])のような形でPromQLクエリを実行して値を取得
※ node_cpu_seconds_total で絞り込みをかけるときには
instanceラベル以外にもCPU番号ラベル、CPUのモード(idleなど)を表すラベルも使う](https://image.slidesharecdn.com/prometheus-221217030140-c57383b5/75/Prometheus-pdf-14-2048.jpg)










![Deploy方法
36
node exporter
• 監視対象のコンソールで以下のコマンドを実行
• wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0/node_exporter-1.4.0.linux-amd64.tar.gz
• tar xvfz node_exporter-1.4.0.linux-amd64.tar.gz
• cd node_exporter-1.4.0.linux-amd64/
• ./node_exporter &
• Prometheus server上のコンソールでprometheus.ymlファイルを編集し、赤字部分を追加
(文頭を必ず揃えること、ifconfigあたりで監視対象のIPアドレスは調べてください)
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node"
static_configs:
- targets: [”<your_node_exporter_ip>:9100"]
#your node exporter ipはlocalhostでもOK](https://image.slidesharecdn.com/prometheus-221217030140-c57383b5/75/Prometheus-pdf-34-2048.jpg)
















































![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

