Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
貴仁 大和屋
PPTX, PDF
35,371 views
Prometheus入門から運用まで徹底解説
Tech Festa 2017で登壇した「Prometheus入門から運用まで徹底解説」のスライドです
Technology
◦
Read more
50
Save
Share
Embed
Embed presentation
Download
Downloaded 176 times
1
/ 94
2
/ 94
3
/ 94
4
/ 94
5
/ 94
6
/ 94
7
/ 94
Most read
8
/ 94
9
/ 94
10
/ 94
Most read
11
/ 94
12
/ 94
13
/ 94
14
/ 94
15
/ 94
16
/ 94
17
/ 94
18
/ 94
19
/ 94
20
/ 94
21
/ 94
22
/ 94
Most read
23
/ 94
24
/ 94
25
/ 94
26
/ 94
27
/ 94
28
/ 94
29
/ 94
30
/ 94
31
/ 94
32
/ 94
33
/ 94
34
/ 94
35
/ 94
36
/ 94
37
/ 94
38
/ 94
39
/ 94
40
/ 94
41
/ 94
42
/ 94
43
/ 94
44
/ 94
45
/ 94
46
/ 94
47
/ 94
48
/ 94
49
/ 94
50
/ 94
51
/ 94
52
/ 94
53
/ 94
54
/ 94
55
/ 94
56
/ 94
57
/ 94
58
/ 94
59
/ 94
60
/ 94
61
/ 94
62
/ 94
63
/ 94
64
/ 94
65
/ 94
66
/ 94
67
/ 94
68
/ 94
69
/ 94
70
/ 94
71
/ 94
72
/ 94
73
/ 94
74
/ 94
75
/ 94
76
/ 94
77
/ 94
78
/ 94
79
/ 94
80
/ 94
81
/ 94
82
/ 94
83
/ 94
84
/ 94
85
/ 94
86
/ 94
87
/ 94
88
/ 94
89
/ 94
90
/ 94
91
/ 94
92
/ 94
93
/ 94
94
/ 94
More Related Content
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PDF
DockerとPodmanの比較
by
Akihiro Suda
PDF
BuildKitの概要と最近の機能
by
Kohei Tokunaga
PDF
KubernetesでRedisを使うときの選択肢
by
Naoyuki Yamada
PDF
Kubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー
by
Toru Makabe
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
Building the Game Server both API and Realtime via c#
by
Yoshifumi Kawai
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
Dockerからcontainerdへの移行
by
Kohei Tokunaga
DockerとPodmanの比較
by
Akihiro Suda
BuildKitの概要と最近の機能
by
Kohei Tokunaga
KubernetesでRedisを使うときの選択肢
by
Naoyuki Yamada
Kubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー
by
Toru Makabe
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
Building the Game Server both API and Realtime via c#
by
Yoshifumi Kawai
What's hot
PDF
コンテナにおけるパフォーマンス調査でハマった話
by
Yuta Shimada
PDF
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
PDF
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
HTTP/2 入門
by
Yahoo!デベロッパーネットワーク
PPTX
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Dockerからcontainerdへの移行
by
Akihiro Suda
PPTX
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
PDF
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き)
by
Hiro H.
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PDF
Vacuum徹底解説
by
Masahiko Sawada
PDF
細かすぎて伝わらないかもしれない Azure Container Networking Deep Dive
by
Toru Makabe
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PDF
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
PDF
マイクロサービス 4つの分割アプローチ
by
増田 亨
PPTX
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
PPTX
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
コンテナにおけるパフォーマンス調査でハマった話
by
Yuta Shimada
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
HTTP/2 入門
by
Yahoo!デベロッパーネットワーク
Kubernetes環境に対する性能試験(Kubernetes Novice Tokyo #2 発表資料)
by
NTT DATA Technology & Innovation
Dockerからcontainerdへの移行
by
Akihiro Suda
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き)
by
Hiro H.
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
Vacuum徹底解説
by
Masahiko Sawada
細かすぎて伝わらないかもしれない Azure Container Networking Deep Dive
by
Toru Makabe
Docker Compose 徹底解説
by
Masahito Zembutsu
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
分散トレーシング技術について(Open tracingやjaeger)
by
NTT Communications Technology Development
マイクロサービス 4つの分割アプローチ
by
増田 亨
本当は恐ろしい分散システムの話
by
Kumazaki Hiroki
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
Viewers also liked
PPTX
Prometheus on AWS
by
Mitsuhiro Tanda
PDF
Ansible101
by
Hideki Saito
PPTX
コンテナのネットワークインターフェース その実装手法とその応用について
by
Tomofumi Hayashi
PPTX
博士学生が語る、4K/8K/VR配信基盤の最先端とコンテンツ配信の未来
by
Takuma Nakajima
PPTX
(2017.8.27) Elasticsearchと科学技術ビッグデータが切り拓く日本の知の俯瞰と発見
by
Mitsutoshi Kiuchi
PPTX
標的型攻撃からどのように身を守るのか
by
abend_cve_9999_0001
PDF
Light and shadow of microservices
by
Nobuhiro Sue
PDF
Rancherで作る お手軽コンテナ運用環境!! ~ Kubenetes & Mesos 牧場でコンテナ牛を飼おう!~
by
Masataka Tsukamoto
PDF
情シスのひみつ
by
cloretsblack
PDF
「ITエンジニアリングの本質」を考える
by
Etsuji Nakai
PDF
Elasticsearchと科学技術ビッグデータが切り拓く日本の知の俯瞰と発見 前半(15分): SPIAS のご紹介と主な課題
by
Yasushi Hara
PDF
強化学習による 「Montezuma's Revenge」への挑戦
by
孝好 飯塚
PDF
170827 jtf garafana
by
OSSラボ株式会社
PDF
Internetトラフィックエンジニアリングの現実
by
J-Stream Inc.
Prometheus on AWS
by
Mitsuhiro Tanda
Ansible101
by
Hideki Saito
コンテナのネットワークインターフェース その実装手法とその応用について
by
Tomofumi Hayashi
博士学生が語る、4K/8K/VR配信基盤の最先端とコンテンツ配信の未来
by
Takuma Nakajima
(2017.8.27) Elasticsearchと科学技術ビッグデータが切り拓く日本の知の俯瞰と発見
by
Mitsutoshi Kiuchi
標的型攻撃からどのように身を守るのか
by
abend_cve_9999_0001
Light and shadow of microservices
by
Nobuhiro Sue
Rancherで作る お手軽コンテナ運用環境!! ~ Kubenetes & Mesos 牧場でコンテナ牛を飼おう!~
by
Masataka Tsukamoto
情シスのひみつ
by
cloretsblack
「ITエンジニアリングの本質」を考える
by
Etsuji Nakai
Elasticsearchと科学技術ビッグデータが切り拓く日本の知の俯瞰と発見 前半(15分): SPIAS のご紹介と主な課題
by
Yasushi Hara
強化学習による 「Montezuma's Revenge」への挑戦
by
孝好 飯塚
170827 jtf garafana
by
OSSラボ株式会社
Internetトラフィックエンジニアリングの現実
by
J-Stream Inc.
Similar to Prometheus入門から運用まで徹底解説
PDF
Prometheus超基礎公開用.pdf
by
勇 黒沢
PDF
Prometheus at Preferred Networks
by
Preferred Networks
PPTX
Prometheus
by
Seiya Mizuno
PDF
Docker技術情報アップデート 2015年7月号
by
Masahito Zembutsu
PPTX
PrometheusによるKubernetes環境の異常検知改善.pptx
by
TakashiTsukamoto4
PDF
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
PPTX
Prometheus最初に悩む3つのこと
by
貴仁 大和屋
PPTX
Clovaにおける機械学習モジュールの配信&運用基盤の紹介
by
LINE Corporation
PDF
モニタリングプラットフォーム開発の裏側
by
Rakuten Group, Inc.
PDF
160724 jtf2016sre
by
OSSラボ株式会社
PDF
運用に自動化を求めるのは間違っているだろうか
by
Masahito Zembutsu
PDF
Twitterのリアルタイム分散処理システム「Storm」入門
by
AdvancedTechNight
PDF
捕鯨!詳解docker
by
雄哉 吉田
PDF
160901 osce2016sre
by
OSSラボ株式会社
PDF
Rancher/k8sを利用した運用改善の取り組み(Rancher Day 2019)
by
Michitaka Terada
PDF
GitLab Meetup Tokyo #1 LT:「わりと大きい会社でGitLabをホスティングしてみた話」
by
Taisuke Inoue
PDF
Architecting on Alibaba Cloud - Fundamentals - 2018
by
真吾 吉田
PDF
デブサミ2014-Stormで実現するビッグデータのリアルタイム処理プラットフォーム ~ストリームデータ処理から機械学習まで~
by
Takanori Suzuki
PDF
Stormの注目の新機能TridentAPI
by
AdvancedTechNight
PDF
[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南
by
Google Cloud Platform - Japan
Prometheus超基礎公開用.pdf
by
勇 黒沢
Prometheus at Preferred Networks
by
Preferred Networks
Prometheus
by
Seiya Mizuno
Docker技術情報アップデート 2015年7月号
by
Masahito Zembutsu
PrometheusによるKubernetes環境の異常検知改善.pptx
by
TakashiTsukamoto4
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
Prometheus最初に悩む3つのこと
by
貴仁 大和屋
Clovaにおける機械学習モジュールの配信&運用基盤の紹介
by
LINE Corporation
モニタリングプラットフォーム開発の裏側
by
Rakuten Group, Inc.
160724 jtf2016sre
by
OSSラボ株式会社
運用に自動化を求めるのは間違っているだろうか
by
Masahito Zembutsu
Twitterのリアルタイム分散処理システム「Storm」入門
by
AdvancedTechNight
捕鯨!詳解docker
by
雄哉 吉田
160901 osce2016sre
by
OSSラボ株式会社
Rancher/k8sを利用した運用改善の取り組み(Rancher Day 2019)
by
Michitaka Terada
GitLab Meetup Tokyo #1 LT:「わりと大きい会社でGitLabをホスティングしてみた話」
by
Taisuke Inoue
Architecting on Alibaba Cloud - Fundamentals - 2018
by
真吾 吉田
デブサミ2014-Stormで実現するビッグデータのリアルタイム処理プラットフォーム ~ストリームデータ処理から機械学習まで~
by
Takanori Suzuki
Stormの注目の新機能TridentAPI
by
AdvancedTechNight
[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南
by
Google Cloud Platform - Japan
Prometheus入門から運用まで徹底解説
1.
Prometheus 入門から運用まで徹底解説 株式会社ホワイトプラス システム開発Gマネジャー 大和屋貴仁 July
Tech Festa 2017 googleエンジニアが作った監視システム
2.
大和屋貴仁 株式会社ホワイトプラス システム開発G マネジャー Microsoft MVP
for Azure(2011-2018 Qiita : @t_Yamatoya http://sqlazure.jp/r
3.
富士フィルムイメージングシステムズと 共同開発したRFID検証。 宅配ネットクリーニングのリネット 会員数20万人突破! Golang、RFIDなど新しい技術や物を活用したサービス改善に興味のあるエンジニア募集!!
4.
Prometheus の話をはじめる前に、 何故、Prometheusか?
5.
SRE サイトリライアビリティエンジニアリング ――Googleの信頼性を支えるエンジニアリングチーム
6.
Prometheusは、特にルール言語にBorgmonと多くの 類似点があります。 依然としてBorgmonはGoogle内部のものですが、ア ラートを発するためのデータソースとして時系列デー タを扱うという発想は、今日ではPrometheus、 Riemann、Heka、Bosunといったオープンソースの ツールを通じて広く受け入れられており… Prometheus と google SRE
サイトリライアビリティエンジニアリング ――Googleの信頼性を支えるエンジニアリングチーム
7.
Borgmanとは • 10年以上に渡って利用されているgoogle内部のモニタ リングツールの名称 • カスタムスクリプトを実行するのではなく、共通の データ公開フォーマットを利用する
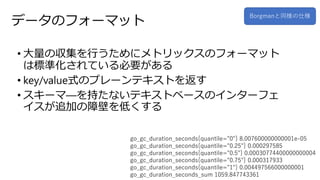
8.
データのフォーマット • 大量の収集を行うためにメトリックスのフォーマット は標準化されている必要がある • key/value式のプレーンテキストを返す •
スキーマ―を持たないテキストベースのインターフェ イスが追加の障壁を低くする go_gc_duration_seconds{quantile="0"} 8.007600000000001e-05 go_gc_duration_seconds{quantile="0.25"} 0.000297585 go_gc_duration_seconds{quantile="0.5"} 0.00030774400000000004 go_gc_duration_seconds{quantile="0.75"} 0.000317933 go_gc_duration_seconds{quantile="1"} 0.004497566000000001 go_gc_duration_seconds_sum 1059.847743361 Borgmanと同様の仕様
9.
ターゲットの発見 • データ収集をする対象を自動で検出する • サービスディスカバリ(Service
Discovery)を利用すること でリストのメンテナンスコストを下げる Borgmanと同様の仕様
10.
データの収集 • 指定された間隔でターゲットのURIからフェッチする • HTTP経由でターゲットをスクレイピングする •
フェッチ時に合成変数も記録する • ホスト名とポート番号に解決できるか • レスポンスを返したか • 収集が完了した時刻 Borgmanと同様の仕様 % curl http://webserver:80/varz http_requests 37 errors_total 12
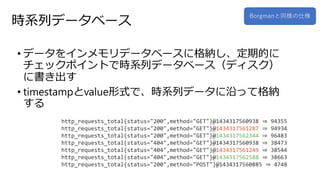
11.
時系列データベース • データをインメモリデータベースに格納し、定期的に チェックポイントで時系列データベース(ディスク) に書き出す • timestampとvalue形式で、時系列データに沿って格納 する Borgmanと同様の仕様 http_requests_total{status="200",method="GET"}@1434317560938
⇒ 94355 http_requests_total{status="200",method="GET"}@1434317561287 ⇒ 94934 http_requests_total{status="200",method="GET"}@1434317562344 ⇒ 96483 http_requests_total{status="404",method="GET"}@1434317560938 ⇒ 38473 http_requests_total{status="404",method="GET"}@1434317561249 ⇒ 38544 http_requests_total{status="404",method="GET"}@1434317562588 ⇒ 38663 http_requests_total{status="200",method="POST"}@1434317560885 ⇒ 4748
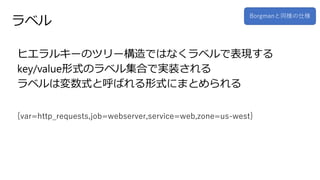
12.
ラベル ヒエラルキーのツリー構造ではなくラベルで表現する key/value形式のラベル集合で実装される ラベルは変数式と呼ばれる形式にまとめられる Borgmanと同様の仕様 {var=http_requests,job=webserver,service=web,zone=us-west}
13.
クエリ式 • クエリを実行するとベクタ内で最新の値をもつ行が返 される • 期間を指定することができる Borgmanと同様の仕様 {var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west}
10 {var=http_requests,job=webserver,instance=host1:80,service=web,zone=us-west} 9 {var=http_requests,job=webserver,instance=host2:80,service=web,zone=us-west} 11 {var=http_requests,job=webserver,instance=host3:80,service=web,zone=us-west} 0 {var=http_requests,job=webserver,instance=host4:80,service=web,zone=us-west} 10 {var=http_requests,job=webserver,service=web,zone=us-west}[10m] {var=http_requests,job=webserver,instance=host0:80, ...} 0 1 2 3 4 5 6 7 8 9 10
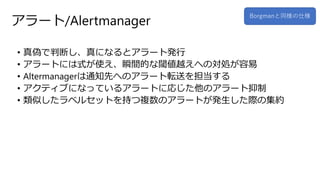
14.
アラート/Alertmanager • 真偽で判断し、真になるとアラート発行 • アラートには式が使え、瞬間的な閾値越えへの対処が容易 •
Altermanagerは通知先へのアラート転送を担当する • アクティブになっているアラートに応じた他のアラート抑制 • 類似したラベルセットを持つ複数のアラートが発生した際の集約 Borgmanと同様の仕様
15.
BorgmanとPrometheusの類似点まとめ • データフォーマット:プレーンテキストのkey/value • Target
Discovery • データの収集方法:URLフェッチ、スクレイピング • 時系列データベース • ラベル • クエリ式 • アラート
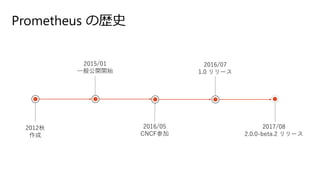
16.
Prometheus の歴史 2012秋 作成 2016/05 CNCF参加 2015/01 一般公開開始 2016/07 1.0 リリース 2017/08 2.0.0-beta.2
リリース
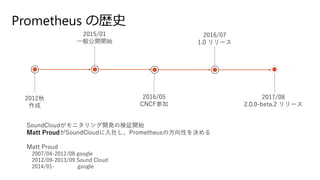
17.
Prometheus の歴史 2012秋 作成 2016/05 CNCF参加 2015/01 一般公開開始 2016/07 1.0 リリース 2017/08 2.0.0-beta.2
リリース SoundCloudがモニタリング開発の検証開始 Matt ProudがSoundCloudに入社し、Prometheusの方向性を決める Matt Proud 2007/04-2012/08 google 2012/09-2013/09 Sound Cloud 2014/01- google
18.
Prometheusの機能 • モニタリングシステムと時系列DB • 測定 •
メトリックス収集と保存 • 保存したメトリックスに対するクエリ • アラート • ダッシュボード • 注力 • OSモニタリング • 動的クラウド環境
19.
Prometheusがしないこと • 生ログ・イベントデータの収集 • リクエストトレース •
例外発見 • 長期保存ストレージ • 自動水平スケール • ユーザー/認証管理
20.
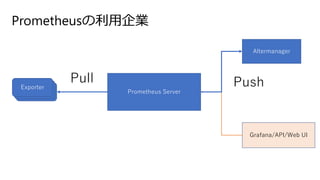
Prometheusの利用企業 • AbemaTV /
Cyberagent • Line • Yahoo!Japan • Freee • ホワイトプラス
21.
Prometheus 入門
22.
Prometheusの利用企業 Prometheus ServerExporterExporterExporter Pull Grafana/API/Web UI Altermanager Push
23.
Prometheusの構築 • 構築は単一バイナリを動かすだけでOK • プリコンパイルされたバイナリをダウンロードして実行 •
Sourceからmake • Dockerコンテナー docker run -p 9090:9090 -v /prometheus-data prom/prometheus -config.file=/prometheus-data/prometheus.yml
24.
設定:Prometheus.yml • Service Discoveryを利用する •
EC2をTargetにしてみる • localhostも対象にしてみる global: scrape_interval: 5s scrape_configs: - job_name: 'prometheus' scrape_interval: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'node' ec2_sd_configs: - region: ap-northeast-1 access_key: secret_key: port: 9100 relabel_configs: - source_labels: [__meta_ec2_tag_Name] target_label: instance
25.
exporterを動かす • 監視対象でexporterを動かします • node_exporter:
*NIXカーネル用のハードウェアとOSのメト リックス収集。 node_exporter -- collectors.enabled="conntrack,diskstats,entropy,filefd,filesystem,loadavg,mdadm,meminfo,netdev,netstat, stat,textfile,time,vmstat" >/dev/null 2>&1 &
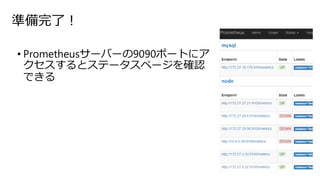
26.
準備完了! • Prometheusサーバーの9090ポートにア クセスするとステータスページを確認 できる
27.
ビジュアライズ表示 • 標準でもグラフ機能はある • けど、ダッシュボードなどのビジュアライズはGrafanaなどの ビジュアライズツールに委任する方針 •
PrometheusにアクセスできるNW環境にGrafanaをイン ストール • Dockerで用意するのが簡単 # create /var/lib/grafana as persistent volume storage docker run -d -v /var/lib/grafana --name grafana-storage busybox:latest # start grafana docker run -d -p 3000:3000 --name=grafana --volumes-from grafana-storage grafana/grafana
28.
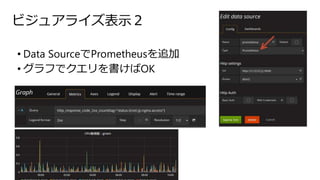
ビジュアライズ表示2 • Data SourceでPrometheusを追加 •
グラフでクエリを書けばOK
29.
Service Discovery
30.
手動でtaarget設定する • 新しいサーバー追加するとConfig更新が必要 • バージョンミスマッチ •
サーバーの喪失 scrape_configs: - job_name: microservice1 target_groups: - targets: [‘server1:8003’] - targets: [‘server2:8003’] - targets: [‘server3:8003’] - targets: [‘server4:8003’] - job_name: otherjob target_groups: - targets: [‘server3:8086’] - targets: [‘server4:8087’]
31.
Service Discovery • DNS •
Consul / Azure / ec2 • ファイル - job_name: pandora-exporter_nbg1 target_groups: dns_sd_configs: consul_sd_configs: - server: 127.0.0.1:8500 datacenter: nbg1 services: - pandora-exporter - job_name: service2-exporter_fra1 target_groups: dns_sd_configs: consul_sd_configs: - server: 127.0.0.1:8500 datacenter: fra1 services: - service2-exporter
32.
提供されているSD • azure • consul •
dns • ec2 • file • gce • kubernetes • marathon • openstack • triton • zookeeper : nerve_sd_config / serverset_sd_config
33.
relabelling
34.
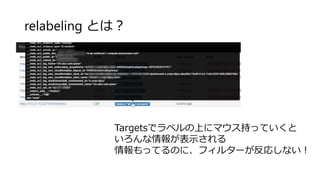
その1 ラベル何に使うの? node_load15{instance=“hoge-jp-green",job="node"} これがラベル 初期設定だと、IPがインスタンスに表示される ラベルにある項目でしかメトリックスは絞り込めない ラベルに無いものは使えない
35.
relabeling とは? Targetsでラベルの上にマウス持っていくと いろんな情報が表示される 情報もってるのに、フィルターが反応しない!
36.
relabeling とは? しれっと、Before relabeling
と記載されている
37.
relabeling とは? relabeling って? https://prometheus.io/docs/operating/configuration/#<relabel_config> いろんな情報あるけど、 最後には消しちゃうから 必要なものは定義して明示的に残してね
38.
relabeling とは? __meta_ で始まるラベルは破棄されるので 必要であればrelabellingする
39.
relabeling とは? 結果、こんな定義にしてEC2のタグ名を無事取得 scrape_configs: - job_name:
'node' ec2_sd_configs: - region: ap-northeast-1 access_key: secret_key: port: 9100 relabel_configs: - source_labels: [__meta_ec2_tag_Name] target_label: instance
40.
Relabellingとは • Targetのメタデータを取り込み、収集する対象を選択 • 選択すると使用できる •
既定 • __address__ラベル • instanceラベル
41.
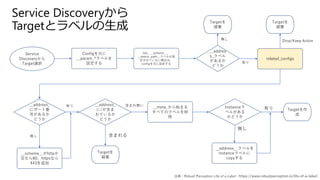
Service Discoveryから Target選択 Configを元に __param_*ラベルを 設定する Job、__scheme__、 __metric_path__ラベルが設 定されていない場合は、 configを元に設定する __addres s_ラベル があるか どうか Targetを 破棄 relabel_configs Targetを 破棄 __address_ にポート番 号があるか どうか __scheme__がhttpか 空なら80、httpsなら 443を追加 __address_ に/が含ま れているか どうか __meta_から始まる すべてのラベルを削 除 Instanceラ ベルがある かどうか __address__ラベルを instanceラベルに copyする Targetを 破棄 Targetを作 成 無し 有り 含まれる 含まれ無い 有り 無し Drop/Keep Action無し 有り 出典:Robust Perception
Life of a Label : https://www.robustperception.io/life-of-a-label/ Service Discoveryから Targetとラベルの生成
42.
対象の選択 • 目的のデータを選択する方法 • 構造が少ない場合は、正規表現 relabel_configs: -
source_labels: ["__meta_consul_tags"] regex: ".*,production,.*” action: keep
43.
維持[keep]と破棄[drop] • もっとも単純なrelabellingの操作 • keepとdrop •
Keep • 正規表現に合致すると、操作を継続します • 合致しない場合は、処理を終了し、次の対象に移ります • Drop • 正規表現に合致すると処理を終了し、次の対象に移ります
44.
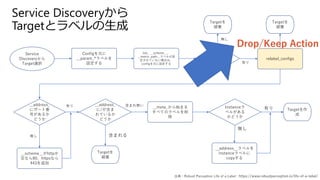
Service Discoveryから Target選択 Configを元に __param_*ラベルを 設定する Job、__scheme__、 __metric_path__ラベルが設 定されていない場合は、 configを元に設定する __addres s_ラベル があるか どうか Targetを 破棄 relabel_configs Targetを 破棄 __address_ にポート番 号があるか どうか __scheme__がhttpか 空なら80、httpsなら 443を追加 __address_ に/が含ま れているか どうか __meta_から始まる すべてのラベルを削 除 Instanceラ ベルがある かどうか __address__ラベルを instanceラベルに copyする Targetを 破棄 Targetを作 成 無し 有り 含まれる 含まれ無い 有り 無し Drop/Keep Action 無し 有り 出典:Robust Perception
Life of a Label : https://www.robustperception.io/life-of-a-label/ Service Discoveryから Targetとラベルの生成
45.
2つのラベルに合致させたい場合 • source_labels • リストで好きなように複数のラベルを指定できる •
結果 • セミコロンで分割されて連結 • separator • セパレターを変更できます • 欠落しているラベルには空文字列が設定される • relabel_configs • リストで、好きなように複数のactionを設定できる • dropかkeepで処理が完了するまで、アクションが適用される
46.
ラベルの変更 • Relabellingのメイン機能は、置換です • Source_lablesにregexを適用し、合致したものを replacementで置き換え、target_labelに結果を書き込み ます •
空ラベルはラベルが削除されたことを表します • __metaラベルはrelabellingの後、削除されます
47.
EC2のNameタグをジョブ名にする例 relabel_configs: - source_labels: ["__meta_ec2_tag_Name"] regex:
"(.*)” action: replace replacement: "${1}” target_label: "job"
48.
デフォルトのものはもっとシンプルに書ける relabel_configs: - source_labels: ["__meta_ec2_tag_Name"] target_label:
"job"
49.
インスタンスラベル • サービスディスカバリー • __address__にhost:port
を格納 • relabellingの終了までに、instanceラベルがない場合 • デフォルトで、__address__の値を設定 • EC2インスタンスIDやZookeeperのパスを設定可能 • 他のラベルを読みやすいインスタンス名として追加は 避ける
50.
その他のラベル • schema、metrics_path、paramsはデフォルト • http/httpsかを確認できます •
__param_* ラベル • 各URLパラメーターの最初の値が含まれる • 最初の値をrelabelできる
51.
Query
52.
ラベル {instance=“example1-com-green",job="node"} 0.005 {instance=“example2-com-green",job="node"} 0.005 {instance=“example3-com-green",job="node"}
0.005 node_load1{instance=~"(-hokan-jp|-batch|wh-plus-com|futon-jp|kutsu-jp|-jp)-green"} / count by(job, instance)(count by(job, instance, cpu) (node_cpu{instance=~"(-hokan-jp|-batch|wh-plus-com |futon-jp|kutsu-jp|-jp)-green"})) クエリ
53.
node_load1[1m]の[1m]て何? irate(node_load1{instance=~".*-blue"}[1m]) 使い始めぐらいで、こういうクエリを見て フィーリングでクエリを書き始めてしまえる。あら、素敵。 クエリ書いてて、あれ?てなって、そーいえば[1m]の結果て何が返ってる??
54.
node_load1[1m]の[1m]て何? Range vector って? https://prometheus.io/docs/querying/basics/#range-vector-selectors 現在から[
]で指定した時間前までの 範囲内の値を すべて返す結果セット [5m]なら過去5分間 [1h]なら過去1時間 の記録全てを返すという意味
55.
node_load1[1m]の[1m]て何? Range vector って? https://prometheus.io/docs/querying/basics/#range-vector-selectors 現在から[
]で指定した時間前までの 範囲内の値を すべて返す結果セット [5m]なら過去5分間 [1h]なら過去1時間 の記録全てを返すという意味 5秒間隔で収集していると、1分範囲にすると約12個結果セットが返ってくる
56.
node_load1[1m]の[1m]て何? Range vector って? https://prometheus.io/docs/querying/basics/#range-vector-selectors 現在から[
]で指定した時間前までの範囲内 データ収集インターバールの指定時間が10秒にしてるときに [9s]とすると結果セットが1つ、2つとばらける
57.
PromQL SQL: SELECT job, instance,
method, status, path, rate(value, 5m) FROM api_http_requests_total PromQL: rate(api_http_requests_total[5m])
58.
PromQL SQL: SELECT city, AVG(value) FROM
temperature_Celsius WHERE country=”germany” GROUP BY city PromQL: avg by(city) (temperature_celsius{country=”germany”})
59.
PromQL SQL: SELECT errors.job, errors.instance,
[…more labels…], errors.value / total.value FROM errors, total WHERE errors.job=”foo” AND total.job=”foo” JOIN […some more complicated stuff here…] PromQL: errors{job=”foo”} / total{job=”foo”}
60.
Exporter
61.
Exporter • 監視するサーバーにexporterという単一バイナリを配置 • daemonとして動かすだけ
62.
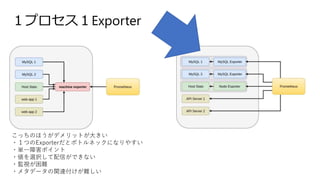
1プロセス1Exporter こっちのほうがデメリットが大きい ・1つのExporterだとボトルネックになりやすい ・単一障害ポイント ・値を選択して配信ができない ・監視が困難 ・メタデータの関連付けが難しい
63.
exporterの種類 https://prometheus.io/docs/instrumenting/exporters/ に100以上リストアップされています
64.
exporterのライブラリ https://prometheus.io/docs/instrumenting/exporters/ で提供されています Clojure Go Java/JVM Python-Django
65.
node_exporterを利用したカスタムメトリック /var/log など特定ディレクトリを監視したい場合 -collector.textfile.directory で /var/lib/node_exporter/textfile_collector.を指定している その配下にCronなどでファイルを出力するとメトリックを追 加できる 形式:*.promで、指定フォーマットに従う必要がある
66.
Grafana連携
67.
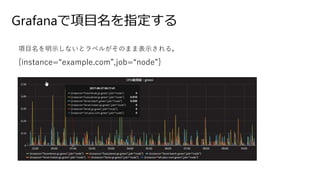
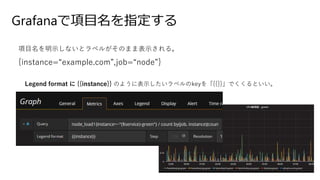
Grafanaで項目名を指定する 項目名を明示しないとラベルがそのまま表示される。 {instance=“example.com”,job=“node”}
68.
Grafanaで項目名を指定する 項目名を明示しないとラベルがそのまま表示される。 {instance=“example.com”,job=“node”} Legend format に
{{instance}} のように表示したいラベルのkeyを「{{}}」でくくるといい。
69.
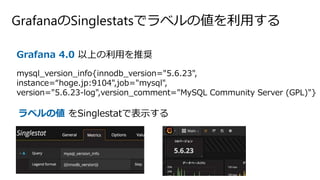
GrafanaのSinglestatsでラベルの値を利用する Grafana 4.0 以上の利用を推奨 mysql_version_info{innodb_version="5.6.23", instance=“hoge.jp:9104",job="mysql", version="5.6.23-log",version_comment="MySQL
Community Server (GPL)"} ラベルの値 をSinglestatで表示する
70.
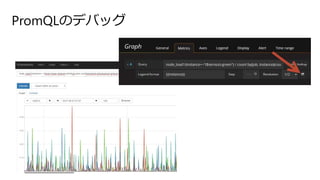
PromQLのデバッグ
71.
PromQLのデバッグ ブラウザエクステンション https://github.com/weaveworks/weavecloud-browser-extension
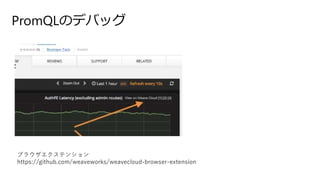
72.
Alerts
73.
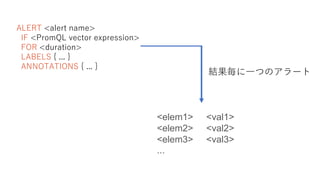
ALERT <alert name> IF
<PromQL vector expression> FOR <duration> LABELS { ... } ANNOTATIONS { ... } <elem1> <val1> <elem2> <val2> <elem3> <val3> ... 結果毎に一つのアラート
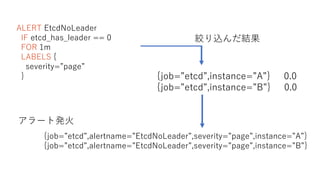
74.
ALERT EtcdNoLeader IF etcd_has_leader
== 0 FOR 1m LABELS { severity=”page” } {job=”etcd”,alertname=”EtcdNoLeader”,severity=”page”,instance=”A”} {job=”etcd”,alertname=”EtcdNoLeader”,severity=”page”,instance=”B”} {job=”etcd”,instance=”A”} 0.0 {job=”etcd”,instance=”B”} 0.0 絞り込んだ結果 アラート発火
75.
ALERT HighErrorRate IF sum
rate(request_errors_total[5m])) > 500 {} 534 閾値が絶対値 サービスの成長に伴い閾値の調整が必要になる
76.
ALERT HighErrorRate IF sum
rate(request_errors_total[5m])) > 500 {} 534
77.
ALERT HighErrorRate IF sum
rate(request_errors_total[5m])) > 500 {} 534
78.
ALERT HighErrorRate IF sum
rate(request_errors_total[5m])) > 500 {} 534
79.
ALERT HighErrorRate IF sum
rate(request_errors_total[5m]) / sum rate(requests_total[5m]) * 100 > 1 {} 1.8354
80.
ALERT HighErrorRate IF sum
rate(request_errors_total[5m]) / sum rate(requests_total[5m]) * 100 > 1 {} 1.8354 高エラー/低トラフィック 低エラー/高トラフィック 合計
81.
ALERT HighErrorRate IF sum
by(instance, path) rate(request_errors_total[5m]) / sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01 {instance=”web-2”, path=”/api/comments”} 2.435 {instance=”web-1”, path=”/api/comments”} 1.0055 {instance=”web-2”, path=”/api/profile”} 34.124 アラート発火
82.
ALERT HighErrorRate IF sum
by(instance, path) rate(request_errors_total[5m]) / sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01 {instance=”web-2”, path=”/api/v1/comments”} 2.435 アラート発火 インスタンス1 インスタンス2~100
83.
ALERT HighErrorRate IF sum
without(instance) rate(request_errors_total[5m]) / sum without(instance) rate(requests_total[5m]) * 100 > 1 {method=”GET”, path=”/api/v1/comments”} 2.435 {method=”POST”, path=”/api/v1/comments”} 1.0055 {method=”POST”, path=”/api/v1/profile”} 34.124 アラート発火
84.
Alertmanager
85.
Alertmanagerの機能 • 同じアラート群をまとめる • 誰に送るかルーティングする •
再送やクローズのコントロール
86.
アラートルール アラートルール アラートルール
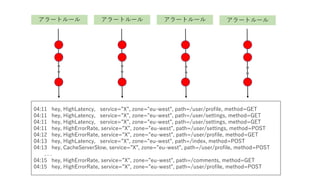
アラートルール 04:11 hey, HighLatency, service=”X”, zone=”eu-west”, path=/user/profile, method=GET 04:11 hey, HighLatency, service=”X”, zone=”eu-west”, path=/user/settings, method=GET 04:11 hey, HighLatency, service=”X”, zone=”eu-west”, path=/user/settings, method=GET 04:11 hey, HighErrorRate, service=”X”, zone=”eu-west”, path=/user/settings, method=POST 04:12 hey, HighErrorRate, service=”X”, zone=”eu-west”, path=/user/profile, method=GET 04:13 hey, HighLatency, service=”X”, zone=”eu-west”, path=/index, method=POST 04:13 hey, CacheServerSlow, service=”X”, zone=”eu-west”, path=/user/profile, method=POST . . . 04:15 hey, HighErrorRate, service=”X”, zone=”eu-west”, path=/comments, method=GET 04:15 hey, HighErrorRate, service=”X”, zone=”eu-west”, path=/user/profile, method=POST
87.
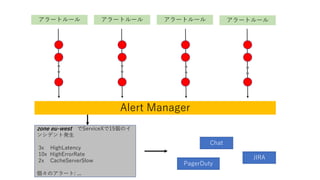
アラートルール アラートルール アラートルール
アラートルール Alert Manager zone eu-west でServiceXで15個のイ ンシデント発生 3x HighLatency 10x HighErrorRate 2x CacheServerSlow 個々のアラート: ... Chat JIRA PagerDuty
88.
Alertmanagerのアラート群 route: receiver: infra #
default receiver group_by: ['alertname', 'Service', 'Stage', 'Role'] group_wait: 30s # wait for aggregating alert group_interval: 5m # wait for alert (next time) repeat_interval: 3h # wait for alert (re-sending same one) 同じアラート、 同じサービス、 同じステージ、 同じロール が30秒以内に来たら、同じアラートとみなす 5分毎にアラート発砲する 次回送信されるのは、3時間後
89.
Alertmanagerの送信先 メール・Webhook・Slack・Hipchat・PagerDuty・OpsGenie
90.
{alertname=”DatacenterOnFire”, severity=”huge-page”, zone=”eu-west”} {alertname=”LatencyHigh”,
severity=”page”, ..., zone=”eu-west”} ... {alertname=”LatencyHigh”, severity=”page”, ..., zone=”eu-west”} {alertname=”ErrorsHigh”, severity=”page”, ..., zone=”eu-west”} ... {alertname=”ServiceDown”, severity=”page”, ..., zone=”eu-west”} アクティブになったら、 同一リージョンのすべてのアラートをミュートにする
91.
macOSのメニューバー • Line Engineerが書いたBitBarが便利 https://engineering.linecorp.com/ja/blog/detail/147
93.
Prometheus というgoogleのノウハウが組み込まれた 監視ツールのお話しでした バージョン2の開発が進んでおり、間もなくリリースされる予定
94.
http://sqlazure.jp/r/ コンタクト
Download










![クエリ式
• クエリを実行するとベクタ内で最新の値をもつ行が返
される
• 期間を指定することができる
Borgmanと同様の仕様
{var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west} 10
{var=http_requests,job=webserver,instance=host1:80,service=web,zone=us-west} 9
{var=http_requests,job=webserver,instance=host2:80,service=web,zone=us-west} 11
{var=http_requests,job=webserver,instance=host3:80,service=web,zone=us-west} 0
{var=http_requests,job=webserver,instance=host4:80,service=web,zone=us-west} 10
{var=http_requests,job=webserver,service=web,zone=us-west}[10m]
{var=http_requests,job=webserver,instance=host0:80, ...} 0 1 2 3 4 5 6 7 8 9 10](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-13-320.jpg)






![設定:Prometheus.yml
• Service Discoveryを利用する
• EC2をTargetにしてみる
• localhostも対象にしてみる
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
ec2_sd_configs:
- region: ap-northeast-1
access_key:
secret_key:
port: 9100
relabel_configs:
- source_labels: [__meta_ec2_tag_Name]
target_label: instance](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-24-320.jpg)



![手動でtaarget設定する
• 新しいサーバー追加するとConfig更新が必要
• バージョンミスマッチ
• サーバーの喪失 scrape_configs:
- job_name: microservice1
target_groups:
- targets: [‘server1:8003’]
- targets: [‘server2:8003’]
- targets: [‘server3:8003’]
- targets: [‘server4:8003’]
- job_name: otherjob
target_groups:
- targets: [‘server3:8086’]
- targets: [‘server4:8087’]](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-30-320.jpg)




![relabeling とは?
結果、こんな定義にしてEC2のタグ名を無事取得
scrape_configs:
- job_name: 'node'
ec2_sd_configs:
- region: ap-northeast-1
access_key:
secret_key:
port: 9100
relabel_configs:
- source_labels: [__meta_ec2_tag_Name]
target_label: instance](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-39-320.jpg)

![対象の選択
• 目的のデータを選択する方法
• 構造が少ない場合は、正規表現
relabel_configs:
- source_labels: ["__meta_consul_tags"]
regex: ".*,production,.*”
action: keep](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-42-320.jpg)
![維持[keep]と破棄[drop]
• もっとも単純なrelabellingの操作
• keepとdrop
• Keep
• 正規表現に合致すると、操作を継続します
• 合致しない場合は、処理を終了し、次の対象に移ります
• Drop
• 正規表現に合致すると処理を終了し、次の対象に移ります](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-43-320.jpg)


![EC2のNameタグをジョブ名にする例
relabel_configs:
- source_labels: ["__meta_ec2_tag_Name"]
regex: "(.*)”
action: replace
replacement: "${1}”
target_label: "job"](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-47-320.jpg)
![デフォルトのものはもっとシンプルに書ける
relabel_configs:
- source_labels: ["__meta_ec2_tag_Name"]
target_label: "job"](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-48-320.jpg)




![node_load1[1m]の[1m]て何?
irate(node_load1{instance=~".*-blue"}[1m])
使い始めぐらいで、こういうクエリを見て
フィーリングでクエリを書き始めてしまえる。あら、素敵。
クエリ書いてて、あれ?てなって、そーいえば[1m]の結果て何が返ってる??](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-53-320.jpg)
![node_load1[1m]の[1m]て何?
Range vector って?
https://prometheus.io/docs/querying/basics/#range-vector-selectors
現在から[ ]で指定した時間前までの
範囲内の値を
すべて返す結果セット
[5m]なら過去5分間
[1h]なら過去1時間
の記録全てを返すという意味](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-54-320.jpg)
![node_load1[1m]の[1m]て何?
Range vector って?
https://prometheus.io/docs/querying/basics/#range-vector-selectors
現在から[ ]で指定した時間前までの
範囲内の値を
すべて返す結果セット
[5m]なら過去5分間
[1h]なら過去1時間
の記録全てを返すという意味
5秒間隔で収集していると、1分範囲にすると約12個結果セットが返ってくる](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-55-320.jpg)
![node_load1[1m]の[1m]て何?
Range vector って?
https://prometheus.io/docs/querying/basics/#range-vector-selectors
現在から[ ]で指定した時間前までの範囲内
データ収集インターバールの指定時間が10秒にしてるときに
[9s]とすると結果セットが1つ、2つとばらける](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-56-320.jpg)
![PromQL
SQL:
SELECT job, instance, method, status, path, rate(value, 5m)
FROM api_http_requests_total
PromQL:
rate(api_http_requests_total[5m])](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-57-320.jpg)

![PromQL
SQL:
SELECT errors.job, errors.instance, […more labels…],
errors.value / total.value
FROM errors, total
WHERE errors.job=”foo” AND total.job=”foo” JOIN
[…some more complicated stuff here…]
PromQL:
errors{job=”foo”} / total{job=”foo”}](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-59-320.jpg)






![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534
閾値が絶対値
サービスの成長に伴い閾値の調整が必要になる](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-75-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-76-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-77-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-78-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m]) /
sum rate(requests_total[5m]) * 100 > 1
{} 1.8354](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-79-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m]) /
sum rate(requests_total[5m]) * 100 > 1
{} 1.8354
高エラー/低トラフィック
低エラー/高トラフィック
合計](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-80-320.jpg)
![ALERT HighErrorRate
IF sum by(instance, path) rate(request_errors_total[5m]) /
sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01
{instance=”web-2”, path=”/api/comments”} 2.435
{instance=”web-1”, path=”/api/comments”} 1.0055
{instance=”web-2”, path=”/api/profile”} 34.124
アラート発火](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-81-320.jpg)
![ALERT HighErrorRate
IF sum by(instance, path) rate(request_errors_total[5m]) /
sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01
{instance=”web-2”, path=”/api/v1/comments”} 2.435
アラート発火
インスタンス1
インスタンス2~100](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-82-320.jpg)
![ALERT HighErrorRate
IF sum without(instance) rate(request_errors_total[5m]) /
sum without(instance) rate(requests_total[5m]) * 100 > 1
{method=”GET”, path=”/api/v1/comments”} 2.435
{method=”POST”, path=”/api/v1/comments”} 1.0055
{method=”POST”, path=”/api/v1/profile”} 34.124
アラート発火](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-83-320.jpg)


![Alertmanagerのアラート群
route:
receiver: infra # default receiver
group_by: ['alertname', 'Service', 'Stage', 'Role']
group_wait: 30s # wait for aggregating alert
group_interval: 5m # wait for alert (next time)
repeat_interval: 3h # wait for alert (re-sending same one)
同じアラート、
同じサービス、
同じステージ、
同じロール
が30秒以内に来たら、同じアラートとみなす
5分毎にアラート発砲する
次回送信されるのは、3時間後](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-88-320.jpg)


































































![[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南](https://cdn.slidesharecdn.com/ss_thumbnails/external2021-211216025522-thumbnail.jpg?width=640&height=640&fit=bounds)