Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
nishio
PPTX, PDF
48,850 views
勾配降下法の 最適化アルゴリズム
モメンタム、Nesterov accelerated gradientとAdagrad, Adadelta, Adamについて解説しました。
Education
◦
Read more
64
Save
Share
Embed
Embed presentation
Download
Downloaded 238 times
1
/ 32
2
/ 32
3
/ 32
4
/ 32
5
/ 32
6
/ 32
7
/ 32
8
/ 32
Most read
9
/ 32
10
/ 32
11
/ 32
12
/ 32
Most read
13
/ 32
14
/ 32
15
/ 32
16
/ 32
17
/ 32
18
/ 32
19
/ 32
20
/ 32
21
/ 32
22
/ 32
23
/ 32
24
/ 32
Most read
25
/ 32
26
/ 32
27
/ 32
28
/ 32
29
/ 32
30
/ 32
31
/ 32
32
/ 32
More Related Content
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
PDF
最適化超入門
by
Takami Sato
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
Union find(素集合データ構造)
by
AtCoder Inc.
深層生成モデルと世界モデル
by
Masahiro Suzuki
Optimizer入門&最新動向
by
Motokawa Tetsuya
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
最適化超入門
by
Takami Sato
ブラックボックス最適化とその応用
by
gree_tech
Union find(素集合データ構造)
by
AtCoder Inc.
What's hot
PDF
Control as Inference (強化学習とベイズ統計)
by
Shohei Taniguchi
PDF
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
by
Hironobu Fujiyoshi
PPTX
報酬設計と逆強化学習
by
Yusuke Nakata
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PDF
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
Batch normalization effectiveness_20190206
by
Masakazu Shinoda
PDF
強化学習の基礎的な考え方と問題の分類
by
佑 甲野
PDF
動画認識サーベイv1(メタサーベイ )
by
cvpaper. challenge
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
PDF
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
PDF
深層自己符号化器+混合ガウスモデルによる教師なし異常検知
by
Chihiro Kusunoki
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
クラシックな機械学習の入門 5. サポートベクターマシン
by
Hiroshi Nakagawa
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
Control as Inference (強化学習とベイズ統計)
by
Shohei Taniguchi
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
by
Hironobu Fujiyoshi
報酬設計と逆強化学習
by
Yusuke Nakata
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
ゼロから始める深層強化学習(NLP2018講演資料)/ Introduction of Deep Reinforcement Learning
by
Preferred Networks
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
Transformer メタサーベイ
by
cvpaper. challenge
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
Batch normalization effectiveness_20190206
by
Masakazu Shinoda
強化学習の基礎的な考え方と問題の分類
by
佑 甲野
動画認識サーベイv1(メタサーベイ )
by
cvpaper. challenge
深層学習の数理
by
Taiji Suzuki
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
機械学習による統計的実験計画(ベイズ最適化を中心に)
by
Kota Matsui
深層自己符号化器+混合ガウスモデルによる教師なし異常検知
by
Chihiro Kusunoki
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
クラシックな機械学習の入門 5. サポートベクターマシン
by
Hiroshi Nakagawa
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
Viewers also liked
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PDF
機械学習プロフェッショナルシリーズ 深層学習 chapter3 確率的勾配降下法
by
zakktakk
PDF
クラシックな機械学習の入門 6. 最適化と学習アルゴリズム
by
Hiroshi Nakagawa
PDF
20151112 kutech lecture_ishizaki_public
by
Kazuaki Ishizaki
PDF
はじめてのパターン認識 第5章 k最近傍法(k_nn法)
by
Motoya Wakiyama
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
線形?非線形?
by
nishio
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PDF
サルでもわかるディープラーニング入門 (2017年) (In Japanese)
by
Toshihiko Yamakami
PDF
Deep Convolutional Generative Adversarial Networks - Nextremer勉強会資料
by
tm_2648
PDF
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
機械学習の理論と実践
by
Preferred Networks
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
機械学習プロフェッショナルシリーズ 深層学習 chapter3 確率的勾配降下法
by
zakktakk
クラシックな機械学習の入門 6. 最適化と学習アルゴリズム
by
Hiroshi Nakagawa
20151112 kutech lecture_ishizaki_public
by
Kazuaki Ishizaki
はじめてのパターン認識 第5章 k最近傍法(k_nn法)
by
Motoya Wakiyama
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
線形?非線形?
by
nishio
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
Deep learning実装の基礎と実践
by
Seiya Tokui
サルでもわかるディープラーニング入門 (2017年) (In Japanese)
by
Toshihiko Yamakami
Deep Convolutional Generative Adversarial Networks - Nextremer勉強会資料
by
tm_2648
IIBMP2016 深層生成モデルによる表現学習
by
Preferred Networks
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
機械学習の理論と実践
by
Preferred Networks
More from nishio
PDF
量子アニーリングマシンのプログラミング
by
nishio
PDF
夏プロ報告
by
nishio
PDF
ITと経営
by
nishio
PDF
部分観測モンテカルロ計画法を用いたガイスターAI
by
nishio
PDF
交渉力について
by
nishio
PDF
If文から機械学習への道
by
nishio
PDF
組織横断型研究室構想
by
nishio
PDF
2017首都大学東京情報通信特別講義
by
nishio
PDF
強化学習その5
by
nishio
PDF
良いアイデアを出すための方法
by
nishio
PDF
強化学習その4
by
nishio
PDF
強化学習その3
by
nishio
PDF
強化学習その2
by
nishio
PDF
強化学習その1
by
nishio
PDF
機械学習キャンバス0.1
by
nishio
PDF
首都大学東京「情報通信特別講義」2016年西尾担当分
by
nishio
PDF
Wifiで位置推定
by
nishio
PDF
ESP8266EXで位置推定
by
nishio
PDF
Raspberry Piで Wifiルータを作る
by
nishio
PDF
Wifiにつながるデバイス(ESP8266EX, ESP-WROOM-02, ESPr Developerなど)
by
nishio
量子アニーリングマシンのプログラミング
by
nishio
夏プロ報告
by
nishio
ITと経営
by
nishio
部分観測モンテカルロ計画法を用いたガイスターAI
by
nishio
交渉力について
by
nishio
If文から機械学習への道
by
nishio
組織横断型研究室構想
by
nishio
2017首都大学東京情報通信特別講義
by
nishio
強化学習その5
by
nishio
良いアイデアを出すための方法
by
nishio
強化学習その4
by
nishio
強化学習その3
by
nishio
強化学習その2
by
nishio
強化学習その1
by
nishio
機械学習キャンバス0.1
by
nishio
首都大学東京「情報通信特別講義」2016年西尾担当分
by
nishio
Wifiで位置推定
by
nishio
ESP8266EXで位置推定
by
nishio
Raspberry Piで Wifiルータを作る
by
nishio
Wifiにつながるデバイス(ESP8266EX, ESP-WROOM-02, ESPr Developerなど)
by
nishio
勾配降下法の 最適化アルゴリズム
1.
勾配降下法の 最適化アルゴリズム (Adagrad, Adadelta, Adam) 2016-10-07 サイボウズ・ラボ 西尾泰和
2.
このスライドの目的 • 勾配降下法はDeep Learningの学習で重要な役 割を果たす最適化手法 •
Deep Leaningに限らず応用分野の広いツール • ここ数年でアルゴリズムの改良が提案されて いるのでそれについて整理する 2
3.
勾配降下法 最適化(関数の最小値を求めること)の方法の一つ 関数が微分できることが条件 各点での微分(=勾配)をみて、一番勾配が急な方 向に降りていく* 3 * 一番原始的な「最急降下法」の場合
4.
勾配が0の点 3通りある 4
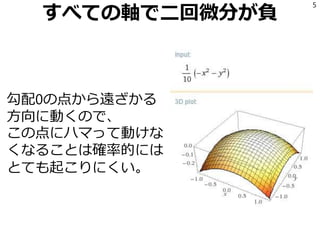
5.
すべての軸で二回微分が負 勾配0の点から遠ざかる 方向に動くので、 この点にハマって動けな くなることは確率的には とても起こりにくい。 5
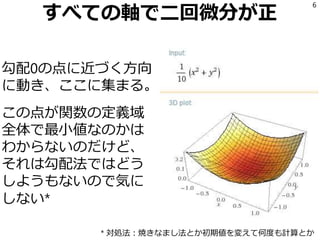
6.
すべての軸で二回微分が正 勾配0の点に近づく方向 に動き、ここに集まる。 この点が関数の定義域 全体で最小値なのかは わからないのだけど、 それは勾配法ではどう しようもないので気に しない* 6 * 対処法:焼きなまし法とか初期値を変えて何度も計算とか
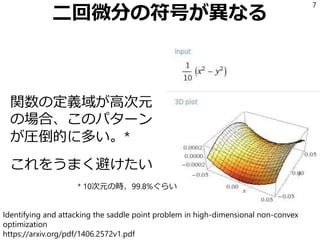
7.
二回微分の符号が異なる 関数の定義域が高次元 の場合、このパターン が圧倒的に多い。* これをうまく避けたい 7 * 10次元の時、99.8%ぐらい Identifying and
attacking the saddle point problem in high-dimensional non-convex optimization https://arxiv.org/pdf/1406.2572v1.pdf
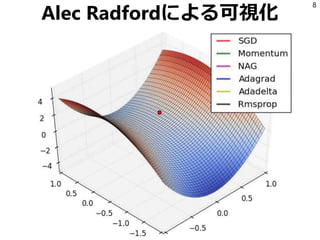
8.
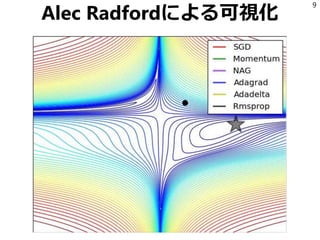
Alec Radfordによる可視化 8
9.
Alec Radfordによる可視化 9
10.
各アルゴリズム解説 • 最急降下法 • モメンタム •
Nesterov accelerated gradient • Adagrad • Adadelta • Adam 10
11.
最急降下法 1. 現在位置𝑥𝑡での勾配𝑔(𝑥𝑡)を計算 2. その勾配に学習率𝜂を掛けたもので位置を更新 11 𝑥
𝑡+1 = 𝑥 𝑡 − 𝜂𝑔(𝑥 𝑡)
12.
モメンタム アイデア「慣性を付けたらいいんじゃない?」 1. 現在位置𝑥𝑡での勾配𝑔(𝑥𝑡)に学習率を掛ける 2. 前回の更新量に0.9ぐらいの減衰率を掛ける 3.
両方使って位置を更新 12 𝑥 𝑡+1 = 𝑥 𝑡 + 𝛾(𝑥 𝑡 − 𝑥 𝑡−1) − 𝜂𝑔(𝑥 𝑡)
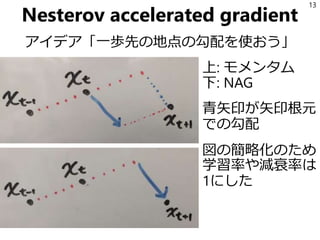
13.
Nesterov accelerated gradient アイデア「一歩先の地点の勾配を使おう」 13 上:
モメンタム 下: NAG 青矢印が矢印根元 での勾配 図の簡略化のため 学習率や減衰率は 1にした
14.
Nesterov accelerated gradient 数式的には
𝑣𝑡 = 𝛾 𝑥𝑡 − 𝑥𝑡−1 として モメンタム 𝑥𝑡+1 = 𝑥𝑡 + 𝑣𝑡 − 𝜂𝑔(𝑥𝑡) NAG 𝑥𝑡+1 = 𝑥𝑡 + 𝑣𝑡 − 𝜂𝑔(𝑥𝑡 + 𝑣𝑡) 14
15.
Adagrad ここまでの話はいったん全部忘れて 「そもそも学習率がどの軸でも同じって おかしいんじゃないの?」 特に確率的勾配降下法と組み合わせて 使うことを考えた場合 「まれにしか観測されない特徴」 →「その軸方向の勾配が多くの場合ゼロ」 まれな特徴が観測されたときには その軸方向には大きく学習したい 15
16.
Adagrad そこで各軸方向の勾配の二乗和を溜めておいて 学習率をその平方根*で割ることで まれな特徴に対して学習率を高めにする。 学習率は他の方法と比べて10倍くらい大きくし ておく。ゼロ除算を避けるために分母に小さい値 を足す。 16 * RMS: Root
mean square
17.
Adagradの問題点 勾配の二乗は常に非負なので 学習率は単調非増加。 学習初期に勾配のきついところを通ると それ以降ずっとその軸方向の学習率が 小さくなってしまう。 これでいいのか? 17
18.
Adadelta アイデア1「過去の勾配の二乗和全部を使うん じゃなくて、最近のだけ使おう」 最近n件を取っておくのはメモリ消費が大きいの で指数平滑移動平均を使う 18 ADADELTA: AN ADAPTIVE
LEARNING RATE METHOD https://arxiv.org/pdf/1212.5701v1.pdf
19.
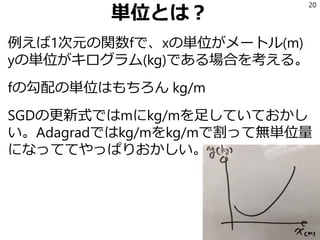
Adadelta アイデア2「単位を合わそう」 Adagradに限らず、SGDやモメンタムでも 「単位があっていない」 19
20.
単位とは? 例えば1次元の関数fで、xの単位がメートル(m) yの単位がキログラム(kg)である場合を考える。 fの勾配の単位はもちろん kg/m SGDの更新式ではmにkg/mを足していておかし い。Adagradではkg/mをkg/mで割って無単位量 になっててやっぱりおかしい。 20
21.
ニュートン法 ニュートン法の場合は 「yの値をfの勾配で割ったもの」 をxの更新に使う。 先ほどの例なら「kg を kg/m
で割ったもの」 でmの値の更新をすることになる。 これなら単位はおかしくない。 21
22.
Adadeltaの単位合わせ 「過去のxの更新差分の平均」を 「過去の勾配の平均」で割って 今の勾配を掛けたものを xの更新差分とする。→単位OK 22 * RMS: Root
mean square
23.
単位合わせのメリット 単位のあってないSGDでは関数fの最適化と fを単に10倍した関数の最適化とで 振る舞いが違う(後者が10倍大きい幅で更新する) この差を吸収するのが「学習率」なる値で 後者の関数の最適化において 更新幅が大きくなりすぎないようにするためには 10倍小さい学習率にする必要がある。 Adadeltaではyの単位が影響しないので、この目 的で学習率をチューニングする必要がない 23
24.
学習率不要 論文中の数式、上から最急降下法、モメンタム、 Adagrad、Adadelta。Adadeltaだけ学習率ηがな いことに注目。 24
25.
Adam adaptive moment estimation 勾配の1乗を溜めこむモメンタム 勾配の2乗を溜めこむAdagrad これって要するに1次と2次のモーメント推定 じゃないか!というのがAdamのアイデア 25 ADAM:
A METHOD FOR STOCHASTIC OPTIMIZATION https://arxiv.org/pdf/1412.6980v8.pdf
26.
アルゴリズム 26
27.
抜粋 𝑚 𝑡 ←
𝛽1 𝑚 𝑡−1 + 1 − 𝛽1 𝑔𝑡 𝑣𝑡 ← 𝛽2 𝑣𝑡−1 + 1 − 𝛽2 𝑔𝑡 2 𝜃𝑡 ← 𝜃𝑡−1 − 𝛼 𝑚 𝑡 𝑣𝑡 + 𝜖 27 mが1次のモーメント(モメンタム相当) vが2次のモーメント、これの平方を分母に置くのが Adagradの「勾配のRMSを分母に置く」に相当。 * RMS: Root mean square
28.
Adamは単位おかしい AdamはAdagradとRMSPropから派生しているの で、Adadeltaが指摘した「単位おかしい」問題は そのまま引き継いでしまっている。 28
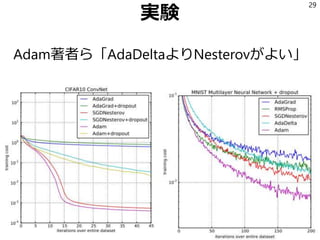
29.
実験 Adam著者ら「AdaDeltaよりNesterovがよい」 29
30.
Adam筆者らによる解釈 なぜNesterovがAdagradよりよいのか? CNNの実験では2次のモーメントがゼロにvanish 2次のモーメントしか使ってないAdagradは無力 1次のモーメントが収束の高速化に寄与したので はないか。 一方1次のモーメントを使っているNesterovより もさらに性能が良いのは「軸ごとの学習率」が効 いているのではないか 30
31.
疑問点 「 CNNの実験では2次のモーメントがゼロに vanish」 それβが小さいとかαとεの比がおかしいとかじゃ ないのか……? βが小さいと過去のデータを素早く忘れすぎる。 2次のモーメントがεに比べて小さい件は、εを小 さくしてαも同率で小さくすれば済む話。 そもそも初期値依存の激しい問題で1回の実験結 果を見て議論してもアレなので初期値とパラメー タを変えて何度も実験してほしい。 31
32.
感想 Adamはモメンタム系とAdagradの「各軸ごとの 学習率」の良いとこどりをしているが、Adadelta の「単位正しく」は取り込んでいない。 そこも取り込んだ手法が今後生まれるのかもしれ ない。 32
Download





























![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)








































