Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
matsuolab
6,758 views
PRML輪読#6
東京大学松尾研究室におけるPRML輪読資料です。
Education
◦
Read more
14
Save
Share
Embed
Embed presentation
Download
Downloaded 331 times
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
Most read
6
/ 27
7
/ 27
Most read
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
Most read
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PDF
PRML輪読#14
by
matsuolab
PDF
PRML輪読#7
by
matsuolab
PDF
PRML輪読#4
by
matsuolab
PDF
PRML輪読#9
by
matsuolab
PDF
PRML輪読#10
by
matsuolab
PDF
PRML輪読#5
by
matsuolab
PDF
PRML輪読#12
by
matsuolab
PDF
PRML輪読#3
by
matsuolab
PRML輪読#14
by
matsuolab
PRML輪読#7
by
matsuolab
PRML輪読#4
by
matsuolab
PRML輪読#9
by
matsuolab
PRML輪読#10
by
matsuolab
PRML輪読#5
by
matsuolab
PRML輪読#12
by
matsuolab
PRML輪読#3
by
matsuolab
What's hot
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
PRML輪読#8
by
matsuolab
PDF
PRML輪読#2
by
matsuolab
PDF
PRML 第4章
by
Akira Miyazawa
PDF
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
PDF
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PPTX
PRML読み会第一章
by
Takushi Miki
PPTX
PRML6.4
by
hiroki yamaoka
PPTX
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PPTX
PRML 2.3 ガウス分布
by
KokiTakamiya
PDF
PRML上巻勉強会 at 東京大学 資料 第5章5.1 〜 5.3.1
by
Len Matsuyama
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
PRML第3章_3.3-3.4
by
Takashi Tamura
PDF
PRML輪読#1
by
matsuolab
PDF
PRML輪読#11
by
matsuolab
PDF
PRML 2.3節 - ガウス分布
by
Yuki Soma
PDF
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
PPTX
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
by
Nagayoshi Yamashita
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PRML第6章「カーネル法」
by
Keisuke Sugawara
PRML輪読#8
by
matsuolab
PRML輪読#2
by
matsuolab
PRML 第4章
by
Akira Miyazawa
PRML第3章@京大PRML輪講
by
Sotetsu KOYAMADA(小山田創哲)
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PRML読み会第一章
by
Takushi Miki
PRML6.4
by
hiroki yamaoka
PRML第9章「混合モデルとEM」
by
Keisuke Sugawara
PRML 2.3 ガウス分布
by
KokiTakamiya
PRML上巻勉強会 at 東京大学 資料 第5章5.1 〜 5.3.1
by
Len Matsuyama
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PRML第3章_3.3-3.4
by
Takashi Tamura
PRML輪読#1
by
matsuolab
PRML輪読#11
by
matsuolab
PRML 2.3節 - ガウス分布
by
Yuki Soma
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
パターン認識と機械学習(PRML)第2章 確率分布 2.3 ガウス分布
by
Nagayoshi Yamashita
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
Similar to PRML輪読#6
PDF
Prml sec6
by
Keisuke OTAKI
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
ガウス過程回帰の導出 ( GPR : Gaussian Process Regression )
by
Kenji Urai
PDF
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
PDF
20190721 gaussian process
by
Yoichi Tokita
PDF
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PPTX
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
PDF
Prml6
by
Arata Honda
PDF
Chapter6.4
by
Takuya Minagawa
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PDF
PRML セミナー
by
sakaguchi050403
PDF
PRML 3.3.3-3.4 ベイズ線形回帰とモデル選択 / Baysian Linear Regression and Model Comparison)
by
Akihiro Nitta
PDF
PRML10-draft1002
by
Toshiyuki Shimono
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
PRML 6.4-6.5
by
正志 坪坂
PDF
PRML 6.1章 カーネル法と双対表現
by
hagino 3000
PDF
[PRML] パターン認識と機械学習(第2章:確率分布)
by
Ryosuke Sasaki
PDF
PRML 10.4 - 10.6
by
Akira Miyazawa
PDF
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
Prml sec6
by
Keisuke OTAKI
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
Stanでガウス過程
by
Hiroshi Shimizu
ガウス過程回帰の導出 ( GPR : Gaussian Process Regression )
by
Kenji Urai
PRML_titech 2.3.1 - 2.3.7
by
Takafumi Sakakibara
20190721 gaussian process
by
Yoichi Tokita
PRML復々習レーン#9 6.3-6.3.1
by
sleepy_yoshi
PILCO - 第一回高橋研究室モデルベース強化学習勉強会
by
Shunichi Sekiguchi
Prml6
by
Arata Honda
Chapter6.4
by
Takuya Minagawa
[PRML] パターン認識と機械学習(第3章:線形回帰モデル)
by
Ryosuke Sasaki
PRML セミナー
by
sakaguchi050403
PRML 3.3.3-3.4 ベイズ線形回帰とモデル選択 / Baysian Linear Regression and Model Comparison)
by
Akihiro Nitta
PRML10-draft1002
by
Toshiyuki Shimono
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PRML 6.4-6.5
by
正志 坪坂
PRML 6.1章 カーネル法と双対表現
by
hagino 3000
[PRML] パターン認識と機械学習(第2章:確率分布)
by
Ryosuke Sasaki
PRML 10.4 - 10.6
by
Akira Miyazawa
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
PRML輪読#6
1.
PRML輪読会 2017 第6章 カーネル法 東京⼤学⼯学部システム創成学科 B4
⻄村弘平
2.
構成 6.1 双対表現 6.2 カーネル関数の構成 6.3
RBFネットワーク 6.4 ガウス過程 2
3.
概要 • 3章~5章では線形・⾮線形なパラメトリックなモデルによる予測 – 𝑦
𝑋, 𝑊 = 𝑊&Φ 𝑋 , • 訓練データは𝑤を学習したら捨てる. • 予測時にも訓練データ点の全部あるいは⼀部を利⽤するパターン認識法を考える. – ex. 最近傍法(2.5.2節参照) • 新しいテスト点は訓練データの中で最も近いサンプルと同じラベルが割り当てられる. – メモリベース法 • ⼊⼒空間における任意の2つのベクトルの類似度を測る指標が必要になる. • カーネル関数 – 𝑘 𝑋, 𝑋* = 𝜙 𝑋 & 𝜙(𝑋*) • 𝜙(𝑋): 特徴空間への⾮線形写像 • 元の次元から特徴空間次元に移して内積をとる関数 – 2つのベクトルの類似度を定めるようなもの • 特徴空間次元に移すメリット – 線形分離可能になる – パラメトリックな線形モデルはカーネル関数の線形和で表現可能 • 𝜙(𝑥)を直接扱わなくて良くなる. 3
4.
6.1 双対表現(1) • 多くの線形モデルは双対表現で表すことでカーネル関数が現れる. •
ex. 線形回帰モデルの⼆乗和誤差 – J‘(w) = 0 とすると, – ただし, Φはn番⽬の列が𝜙 𝑥4 &となるような計画⾏列で, – 最⼩⼆乗法のアルゴリズムを𝑤を使わずに で表現する: 双対表現 4
5.
6.1 双対表現(2) • 𝑤
= Φ& 𝑎を に代⼊ • 𝐾47 = 𝜙 𝑥4 & 𝜙 𝑥7 = 𝑘(𝑥4, 𝑥7)と定められるグラム⾏列𝐾 = ΦΦ& を定義する. • ⼆乗和誤算関数: • の解: • 予測関数: • 双対関数の意義 5 カーネル関数 全てがカーネル関数𝑘 𝑋, 𝑋* で表現されるため, 常にカーネル関数を通じて 問題を扱うことができ, 特徴ベクトル𝜙(𝑋)を明示的に考えることを避け, 高次 元・無次元の特徴ベクトルを間接的に扱うことができる
6.
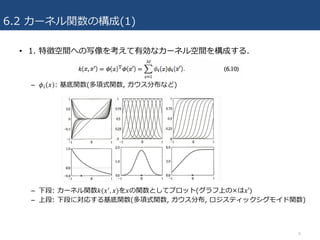
6.2 カーネル関数の構成(1) • 1.
特徴空間への写像を考えて有効なカーネル空間を構成する. – 𝜙8 𝑥 : 基底関数(多項式関数, ガウス分布など) – 下段: カーネル関数𝑘(𝑥*, 𝑥)を𝑥の関数としてプロット(グラフ上の×は𝑥′) – 上段: 下段に対応する基底関数(多項式関数, ガウス分布, ロジスティックシグモイド関数) 6
7.
6.2. カーネル関数の構成(2) • 2.
カーネル関数を直接定義する. – カーネル関数として有効であることを保証する必要がある. • 特徴空間におけるスカラー積であることを保証しなければならない. – ex. 𝑘 𝑥, 𝑧 = 𝑥& 𝑧 ; • 𝜙のスカラー積となるので有効なカーネル関数である. – 有効なカーネルであるための必要⼗分条件 7 関数𝑘(𝑋, 𝑋* )が有効なカーネル ⇕ 任意の{𝑋4}に対して要素が𝑘(𝑥4, 𝑥7)であるグラム⾏列𝐾が半正定値である
8.
6.2 カーネル関数の構成(3) • ⾊々なカーネル関数 –
⼀般化された多項式カーネル – ガウスカーネル • 無限次元への写像と等価 – ⽣成モデルから構成されるカーネル • 2つの⼊⼒𝑋と𝑋′の確率がともに⼤きいときに2つの⼊⼒が似ているとされる. – シグモイドカーネル • グラム⾏列が必ずしも半正定値にならない. • サポートベクターマシンとニューラルネットワークが表層的に類似したものとなるため よく使われる. 8 𝑘 𝑋, 𝑋* = 𝑋& 𝑋* + 𝑐 A (𝑐 > 0) 𝑘 𝑋, 𝑋* = exp (− 𝑋 − 𝑋* ; / 2𝜎; ) 𝑘 𝑋, 𝑋* = 𝑝 𝑋 𝑝(𝑋* ) 𝑘 𝑋, 𝑋* = 𝑋& 𝑋* + 𝑐 A (𝑐 > 0)
9.
6.3 RBFネットワーク • 線形回帰モデル(3章) •
基底関数の選び⽅ – ⼀般的にRBF(動径基底関数) – RBFはその中⼼𝜇Lからの動径のみに依存している. • RBFを導⼊する動機 – 正確に⽬標変数の値を再現する関数補間 • ⽬的変数のノイズによって過学習する可能性あり – ⼊⼒変数にノイズが含まれる場合の補間 • Nadaraya-Watsonモデル 9
10.
6.3 RBFネットワーク(2) • ⼊⼒変数に確率分布𝑣(𝜉)に従う確率変数𝜉で表されるノイズが含まれるとき, ⼆乗和誤算関数は •
変分法により – ℎ(𝑥 − 𝑥4)は正規化されている. 10
11.
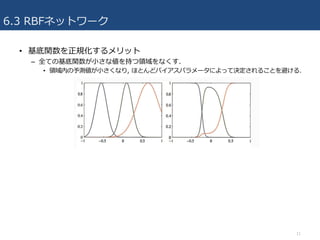
6.3 RBFネットワーク • 基底関数を正規化するメリット –
全ての基底関数が⼩さな値を持つ領域をなくす. • 領域内の予測値が⼩さくなり, ほとんどバイアスパラメータによって決定されることを避ける. 11
12.
6.3.1 Nadaraya-Watsonモデル (1) •
訓練集合{𝑥4, 𝑡4}について同時分布𝑝(𝑥, 𝑡)の推定にParzan推定法を⽤いると – 𝑓(𝑥, 𝑡)は密度関数の要素で各データ点中⼼ – 同時分布: – 回帰関数 12
13.
6.3.1 Nadaraya-Watsonモデル(2) • 回帰関数をカーネル関数で表す –
簡単のため, 密度関数の各要素の平均を0とする. • 全ての𝑥に対して, • また, 以下の式を仮定すると • 回帰関数は 13
14.
6.4 ガウス過程 • 6.4節の⽬標 –
ベイズ的な視点においても確率的識別モデルに対して⾃然にカーネルが現れることを確 認する. • ガウス過程とは • ガウス過程の考え⽅ 14 任意の点集合{𝑥R, 𝑥;, … , 𝑥4}に対する{𝑦 𝑥R , 𝑦 𝑥; , … , 𝑦 𝑥4 }の同時分布が ガウス分布に従うもの. パラメータ𝑤の事前分布𝑝(𝑤)を決めるのではなく, 関数𝑦(𝑥)の事前分布 𝑝(𝑦)を直接定義する
15.
6.4.1 線形回帰再訪(1) • 線形回帰モデルy
𝑋 = 𝑊& 𝜙(𝑋)を考える. • 𝑤の事前分布として次の等⽅的ガウス分布を考える. – 𝛼は分布の精度 – 1つの𝑤に対して𝑦(𝑥)が決まるため, 𝑤の事前分布を与えることと𝑦(𝑥)の事前分布を与え ることは同値 • 訓練データに対応する{𝑦 𝑋R , … , 𝑦 𝑋V }の同値分布を求める • 𝑌 = 𝑦 𝑥R , 𝑦 𝑥; , … , 𝑦 𝑥4 = Φ𝑤とすると • ここで𝐾は 15
16.
6.4.1 線形回帰再訪(2) • 𝑤はガウス分布に従う変数集合 –
その線形結合である𝑦⾃⾝もガウス分布に従う. – 平均と分散を求めれば, 𝑦の分布も定まる. • ガウス過程の重要な点 – 同時分布が平均や共分散といった2次までの統計量で記述される. – 𝑦(𝑋)の平均は0とされることが多いのでガウス過程はカーネル関数として与えられる. 16
17.
6.4.2 ガウス過程による回帰(1) • ⽬標変数にノイズが含まれることを考慮 –
各観測値に対してノイズは独⽴に決定する. – ノイズはガウス分布に従う. – ⽬標値の同時分布は等⽅的なガウス分布に従う. – ガウス過程の定義より, • 周辺分布𝑝(𝑦)は平均が0で共分散がグラム⾏列𝐾であるガウス分布になるので – 周辺分布𝑝(𝑡)は, • 𝑝 𝑡 = ∫ 𝑝 𝑡 𝑦 𝑝 𝑦 𝑑𝑦 = 𝑁(𝑡|0, 𝐶) • ここで共分散⾏列𝐶は – 𝐶 𝑋4, 𝑋7 = 𝑘 𝑋4, 𝑋7 + 𝛽^R 𝛿47 17 誤差(ノイズ)⽬標値
18.
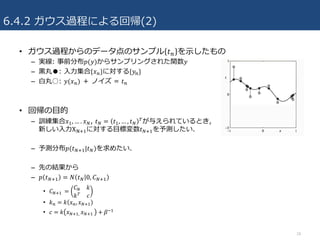
6.4.2 ガウス過程による回帰(2) • ガウス過程からのデータ点のサンプル
𝑡4 を⽰したもの – 実線: 事前分布𝑝(𝑦)からサンプリングされた関数𝑦 – ⿊丸●: ⼊⼒集合{𝑥4}に対する{𝑦4} – ⽩丸○: 𝑦(𝑥4) + ノイズ = 𝑡4 • 回帰の⽬的 – 訓練集合𝑥R, … . 𝑥V, 𝑡V = 𝑡R, … , 𝑡V &が与えられているとき, 新しい⼊⼒XbcRに対する⽬標変数𝑡VcRを予測したい. – 予測分布𝑝(𝑡VcR|𝑡V)を求めたい. – 先の結果から – 𝑝 𝑡VcR = 𝑁 𝑡V 0, 𝐶VcR • 𝐶VcR = 𝐶V 𝑘 𝑘& 𝑐 • 𝑘4 = 𝑘 𝑥4, 𝑥VcR • 𝑐 = 𝑘 𝑥VcR, 𝑥VcR + 𝛽^R 18
19.
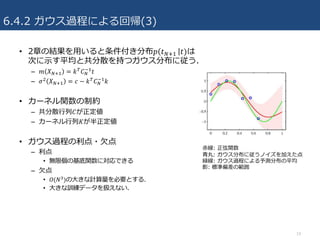
6.4.2 ガウス過程による回帰(3) • 2章の結果を⽤いると条件付き分布𝑝
𝑡VcR 𝑡)は 次に⽰す平均と共分散を持つガウス分布に従う. – 𝑚 𝑋VcR = 𝑘& 𝐶V ^R 𝑡 – 𝜎; 𝑋VcR = 𝑐 − 𝑘& 𝐶V ^R 𝑘 • カーネル関数の制約 – 共分散⾏列𝐶が正定値 – カーネル⾏列𝐾が半正定値 • ガウス過程の利点・⽋点 – 利点 • 無限個の基底関数に対応できる – ⽋点 • 𝑂(𝑁f)の⼤きな計算量を必要とする. • ⼤きな訓練データを扱えない. 19 ⾚線: 正弦関数 ⻘丸: ガウス分布に従うノイズを加えた点 緑線: ガウス過程による予測分布の平均 影: 標準偏差の範囲
20.
6.4.3 超パラメータの学習 • ガウス過程による予測は共分散関数の選択に依存 –
パラメトリックな関数族を考えて, そのパラメータ𝜃をデータから推定 • 超パラメータの学習⽅法 – 尤度関数𝑝(𝑡|𝜃)を評価する. – 簡単には, 対数尤度関数を最⼤化する𝜃の点推定を⾏う. • 共役勾配法などの効率的な最適化アルゴリズムが⽤いられる. 20
21.
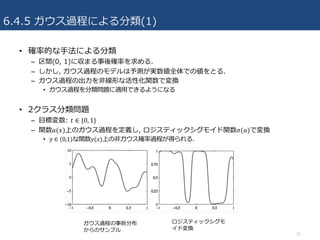
6.4.5 ガウス過程による分類(1) • 確率的な⼿法による分類 –
区間(0, 1)に収まる事後確率を求める. – しかし, ガウス過程のモデルは予測が実数値全体での値をとる. – ガウス過程の出⼒を⾮線形な活性化関数で変換 • ガウス過程を分類問題に適⽤できるようになる • 2クラス分類問題 – ⽬標変数: 𝑡 ∈ {0, 1} – 関数𝑎(𝑥)上のガウス過程を定義し, ロジスティックシグモイド関数𝜎(𝑎)で変換 • 𝑦 ∈ (0,1)な関数𝑦(𝑥)上の⾮ガウス確率過程が得られる. 21 ガウス過程の事前分布 からのサンプル ロジスティックシグモ イド変換
22.
6.4.5 ガウス過程による分類(2) • ⽬標変数𝑡の確率分布はベルヌーイ分布になる. –
𝑝 𝑡 𝑎 = 𝜎 𝑎 j 1 − 𝜎 𝑎 R^j • ガウス過程の分類の⽬標 – 予測分布𝑝 𝑡VcR 𝑡)の決定 22
23.
6.4.5 ガウス過程による分類(3) • 導出の流れ –
𝑎VcR = {𝑎 𝑋R , … , 𝑎 𝑋V }のガウス過程事前分布を考える. – 𝑡VcRに対する⾮ガウス事前分布が導かれる. – 𝑡Vが与えられた下での予測分布が与えられる. • 𝑎VcRに対するガウス過程事前分布は – 𝑝 𝑎VcR = 𝑁 𝑎VcR 0, 𝐶VcR ) – 回帰問題と異なり, 共分散⾏列にノイズが含まれない. • ⾏列の正定値性を保証するためノイズのような項を⼊れる. 23
24.
6.4.5 ガウス過程による分類(4) • 2クラス分類問題なので𝑝
𝑡VcR 𝑡V)を求めれば良い. – この積分を解析的に解くのは不可能 – サンプリング, またはガウス分布による近似 • ガウス分布による近似 – ラプラス近似を⽤いた⽅法(次節) – 変分推論法に基づく⽅法(10章) – EP法を⽤いる⽅法(10章) 24 𝜎(𝑎VcR)
25.
6.4.6 ラプラス近似 • 𝑝
𝑎VcR 𝑡V)のラプラス近似 • 以下の4章の近似式を⽤いて解ける 25
26.
ガウス過程のまとめ • ガウス過程のモデルは共分散がカーネル関数になる – ハイパーパラメーターが平均と分散になる. •
ガウス過程での回帰・分類問題 – 予測分布𝑝 𝑡VcR 𝑡V)を求める • ガウス過程の利点・⽋点 – 利点:無限個の基底関数に対応できる – ⽋点:𝑂(𝑁f)の⼤きな計算量を必要とする • 訓練データ数N – 基底関数の数Mがデータ数Nより⼤きい時に有効 26
27.
参照 • パターン認識と機械学習 下 –
C.M. ビショップ (著), 元⽥ 浩 (監訳), 栗⽥ 多喜夫 (監訳), 樋⼝ 知之 (監訳), 松本 裕治 (監訳), 村⽥ 昇 (監訳) • Pattern Recognition and Machine Learning – Kernel Methods , 池宮由楽 – https://www.slideshare.net/yukaraikemiya/6-15415589 • PRML勉強会 第6章 カーネル法 – 岩橋研究室 ⽊村⼤輝 – https://speakerdeck.com/muzun/prml-6zhang-kanerufa-at-chang-gang • ガウス過程の基礎と教師なし学習 – 統計数理研究所 持橋⼤地 – https://deepx-company.slack.com/archives/G46AJEKRC/p1490759266651275 27
Download










































![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)






![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)

