More Related Content
What's hot

PDF

PDF

PDF

PDF

PDF

PPTX

PDF

PDF

PPTX

PDF

PPTX

PPTX

PDF

PDF
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法 
PDF

PDF

PDF
PRML上巻勉強会 at 東京大学 資料 第1章前半 
PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話) 
PDF

PDF
Similar to PRML輪読#10

PDF

PDF

PDF

PDF

PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法) 
PDF
Bishop prml 10.2.2-10.2.5_wk77_100412-0059 
PDF
PRML 10.3, 10.4 (Pattern Recognition and Machine Learning) 
PDF

PPT

PDF

PDF

PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4 
PDF

PDF

PDF

PDF

PDF

PDF

PPTX

PDF
PRML輪読#10
- 1.
- 2.
- 3.
はじめに
• 観測データXが与えられた時に,以下を求めたい
– 潜在変数Z の事後分布 p(Z|X)とそれを⽤いた期待値
• ⼀般の確率モデルでは事後分布を解析的に導出できなかったり,潜在変数の
次元が⾼すぎて直接その空間を扱えない
• 近似推論法
– 確率的な近似推論(11章)
• メリット:厳密な計算が可能
• デメリット:計算量が膨⼤で,⼤規模な問題に適応困難
– 決定的な近似推論(10章)
• メリット:⼤規模な問題でも適応でき,確定的な解が求まる
• デメリット:近似した結果しか求まらない
3
この積分が簡単に求まる => 解析的に解ける
- 4.
10.1 変分推論
• 前準備
–モデルのパラメータを確率変数と考え,潜在変数に含める
– 全てのパラメータに対して事前分布が与えられたベイズ的なモデルを考える
– 観測データ:
– 潜在変数 :
• ⽬的
– 確率モデルによって同時分布 p(X,Z) が定められた時,
– 事後分布 p(Z|X) および周辺尤度(モデルエビデンス) p(X) の近似を求める
• 変分法の多くの問題は汎関数の値を最適化するもの
– 関数:変数を⼊⼒,関数の値を出⼒
– 汎関数:関数を⼊⼒,汎関数の値を出⼒
4
- 5.
10.1 変分推論
• 周辺分布(周辺対数尤度)の分解
–Zに関する分布q(Z)を使って周辺対数尤度 を分解
– (EM法と違ってパラメータベクトルθが現れない)
– 下限L(q)を分布q(Z)について最適化して最⼤化=KL(q||p)の最⼩化
• KLが0のときqは真の事後分布p(Z|X)に⼀致(これはモデル上不可能と仮定)
• ある制限したクラスのq(Z)を考え,その中でKLを最⼩にするものを真の事後分布の近似とする
5引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 6.
- 7.
- 8.
10.1.1 変分推論 -分布の分解
• 変分推論法における最適解
– 全ての因⼦を適当に初期化し,因⼦の⼀つ⼀つを(10.9)に従って改良
• 下限は各因⼦について凸であるため収束する
8
⾃分以外の分布の期待値によって
その分布の最適解が求まる
引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 9.
10.1.2 変分推論 -分解による近似の持つ性質
• 分解による近似の例
– 真の事後分布を分解によって近似することでどんな不正確さが⽣じるか?
9引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 10.
10.1.2 変分推論 -分解による近似の持つ性質
• 分解による近似の例
– 真の事後分布を分解によって近似することでどんな不正確さが⽣じるか?
– KL(q‖p)を最⼩化して求めたq(z) = 変分推論
– KL(p‖q)を最⼩化して求めたq(z) = EP法(10.7節)
10
平均は正しく捉えられているが,
q(z)の分散はp(z)の分散が最⼩になる⽅向によって制御
それと直⾏する⽅向の分散は過⼩評価
→事後分布をコンパクトに近似しすぎる
平均は正しく捉えられているが,
⾮常に低い確率しか持たないはずの変数領域に
多くの確率質量が割り当てられている
多峰分布の⼀つを近似
多峰分布の平均を近似
- 11.
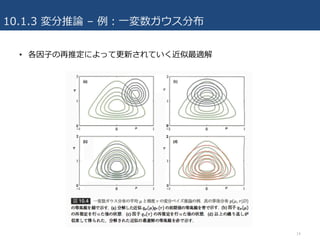
10.1.3 変分推論 –例:⼀変数ガウス分布
• 以後,変分推論の例が何度か出て来るが,基本的な流れは以下
– 確率モデルを定義し,同時分布の尤度関数を求める
• パラメータに共役事前分布を導⼊
– 事後分布の分解を仮定
– (10.9)から更新式を求める
– 計算
11
- 12.
10.1.3 変分推論 –例:⼀変数ガウス分布
12引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 13.
10.1.3 変分推論 –例:⼀変数ガウス分布
13引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 14.
- 15.
10.1.4 変分推論 –モデル⽐較
• 事前確率p(m)を持つ複数のモデルの候補を⽐較したい場合
– 観測データXの下で事後確率p(m|X)を近似する
– 別のモデルは内部構造も異なり,隠れ変数Zの次元も異なる可能性があり,複雑
– よって,分解は ではなく を考える
– Lをq(m)について最⼤化すると
15
- 16.
- 17.
10.2.1 例:変分混合ガウス分布 -変分事後分布
• 同時分布
• 推定事後分布(変分近似)を潜在変数とパラメータに分解
17引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 18.
10.2.1 例:変分混合ガウス分布 -変分事後分布
1. 変分事後分布の因⼦q(Z)の最適解(更新式)を求める
1. (10.9)から最適な因⼦分布の対数を求め,Zに依存しない項を定数に含める
2. 両辺の指数をとる
3. 正規化条件(各nについてznkがkについて⾜し合わせると1)から因⼦q(Z)の最適解と負担率を求める
18
- 19.
10.2.1 例:変分混合ガウス分布 -変分事後分布
2. 変分事後分布の因⼦ の最適解(更新式)を求める
1. 負担率から3つの統計量を定義
2. (10.9)から最適な因⼦分布の対数を求める
3. と分解される
19
πだけを含む項
μとΛだけを含む項
に分解
変分近似で置いた仮定以上に
さらに分解される
→「導出された分解」
引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 20.
10.2.1 例:変分混合ガウス分布 -変分事後分布
3. さらに分解された𝑞(𝜋)と𝑞(𝜇, Λ)をそれぞれ求める
1. 𝑞(𝜋)
2. 𝑞(𝜇, Λ)
20引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 21.
10.2.1 例:変分混合ガウス分布 -変分事後分布
21
• 混合ガウス分布の変分ベイズ法による解法と最尤推定のためのEMアルゴリズムによる
解法は似ている
• N → ∞ の極限ではベイズ的な解は最尤推定のEMアルゴリズムの解に収束
• 変分ベイズの計算コストは,負担率の計算および重み付き和による共分散⾏列と
その逆⾏列の計算(=EMと全く同じ)が多くを占める
• ベイズの利点
• 最尤推定のように混合ガウス分布の要素が「縮退」して特異なデータのみを説明
してしまう現象が起こらない
• 混合要素数Kに⼤きな値を選んでも過学習が起きない
• 最適な混合要素数を交差検証などを使わなくても求められる可能性がある
引⽤:https://www.slideshare.net/takao-y/ss-28872465
- 22.
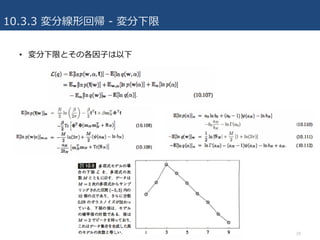
10.2.2 例:変分混合ガウス分布 -変分下限
• 求めたモデルについて下限が容易に求まる
– パラメータの再推定を⾏う際に収束を判定する⽬的で下限の値を観察
– 下限は決して減少しないので,数式や実装が正しいかのチェックにも有効
22
- 23.
- 24.
10.2.4 例:変分混合ガウス分布 -混合要素数の決定
• 混合要素のラベルだけが異なるもの(=観測変数の確率密度が全く同じになる別
の設定)が存在
– K個の混合要素を持つ混合モデルにはK!個の等価なパラメータ設定
– 最尤推定:パラメータの初期値に依存して⼀つの特定の解を⾒つけるため,このような冗⻑性
は起きない
– ベイズ推定:全ての可能なパラメータ設定について周辺化を⾏う.混合要素数Kを⼀定として
いる場合は問題ないが,異なるKを⽐較する場合は問題.
• Kの決め⽅
a. さまざまなKの値を持つモデルを学習して⽐較
b. 混合⽐πの確率分布を完全にベイズ的に考えず,パラメータとして下限最⼤化を残りのパラ
メータによる変分事後分布qの更新と交互に⾏う
• データをあまり説明しない混合要素の混合係数は0に近づきモデルから除去(関連⾃動決定)
• Kの初期値を⼤きくして学習を⼀度実⾏するだけでOK
24
- 25.
10.2.5 例:変分混合ガウス分布 -導出された分解
• 導出された分解(induced factorization)
– 変分事後分布を分解する仮定と真の同時分布のもつ条件付き独⽴性から導出
– 有効分離に基づくグラフィカルテストで⾒つけられる
25
- 26.
10.3 変分線形回帰
• 変分推論のもう⼀つの例として3.3節のベイズ線回帰モデルを取り上げる
–エビデンス最⼤化:αとβに対する積分を対数周辺尤度を最⼤にする点推定で近似
– 完全なベイズモデル:超パラメータについても積分を⾏う
• 厳密な積分は不可能だが,変分ベイズ法によって近似解は⾒つけられる
• (線形回帰モデルではエビデンス最⼤化と同じ解が求まる)
• 準備
– αに事前分布を導⼊(2.3.6節より,ガウス分布の精度パラメータの共役事前分布はガンマ分布)
– すべての変数の同時分布は次式
26
- 27.
10.3.1 変分線形回帰 -変分分布
• 最初の⽬的:事後分布p(w,α|t)の近似を求める
– 変分事後分布の分解は
– ⼀般的な結果(10.9)からこの分布の各因⼦を再推定していく⽅程式を求める.
– αの分布は
– wの分布は
– q(w)とq(a)のどちらかのパラメータを初期化して収束基準を満たすまで交互に再推定
27
- 28.
- 29.
- 30.
10.4 指数型分布族
• 2章:指数型分布族とその共役事前分布が演じる役割に関して議論
– 多くの統計モデルで出てくる分布が指数型分布であり、パラメータベクトルの最尤推定
がしやすく、任意の分布について共役事前分布が存在することなどなど
• 本章で議論する多くのモデルでは、完全データの尤度は指数型分布族から得
られるが、観測データの周辺尤度関数に関しては⼀般にそうではない
– 例)ガウス混合モデルでは観測値xnと対応する隠れ変数znの同時分布は指数型分布に属
するが、xnの周辺分布は混合ガウス分布であり、指数型分布族に属さない.
• これまで:モデルにふくまれる変数を観測変数と隠れ変数に分類
• → 本章:潜在変数Zとパラメータθを区別
– パラメータは内包的変数(データ集合のサイズによらず数が固定)
– 潜在変数は 外延的変数(データ集合のサイズに従い数が増える)
– 例)ガウス混合モデルではインジケータ変数zknは潜在変数で、平均μk、精度Λk、混合
⽐πkはパラメータ.
30
- 31.
10.4 指数型分布族
• 独⽴同分布のデータの場合を考える
–データの値をX, 潜在変数Zとする
– 観測値と潜在変数の同時分布が⾃然パラメータηを使った以下の指数型分布で表せると
する.
– ηは共役事前分布を⽤いて以下のようにかけるとする.
– 変分分布は潜在変数とパラメータに分けられ( )、(10.9)より、以下のよ
うに各n毎に独⽴な項の和に分解できる.
– したがって, q*(Z)の解もnについて分解できて、 となる. (10.2.5節)
• 両辺の指数を取って、以下の式得る.
31
- 32.
10.4 指数型分布族
• 同様に、パラメータの変分近似についても以下のようにできる
–両辺の指数をとって、正規化定数を加えて
• なお変数の定義は以下.
• q*(zn)とq*(η)の解には相互依存性があるので、⼆段階の繰り返しで解く.
– 変分Eステップでは, 潜在変数の事後分布q(zn)から⼗分統計量の期待値E[u(xn, zn)]を求
め、これを使いパラメータの事後分布q(η)を改良する.
– 変分Mステップでは、改良したパラメータの事後分布を使って⾃然パラメータの期待値
E[ηT]を求め、これから潜在変数の事後分布をまた改良する.
32
- 33.
- 34.
- 35.
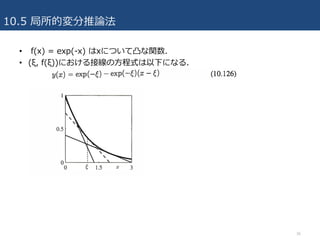
10.5 局所的変分推論法
• 10.1節や10.2節で議論した変分ベイズ法は、「⼤域的」な⽅法
–全ての確率変数についでの完全な事後分布の近似を直接求める
• もう⼀つの「局所的」な⽅法をこの章ではやる
– モデルの各変数または変数群の関数に対する上限や下限を⾒つけていく
– 例えば、ある⼀つの条件付き確率p(y|x)の上下限を探すのは、得られる分布を簡単にす
るためである. こうした局所的な近似を複数の変数について順番に⾏い、計算可能な近
似を得る.
• KLダイバージェンスの議論で、対数関数の凸性が⼤域的な変分ベイズ法で
の下限を構成するときに中⼼的な役割を果たすことを⾒てきた.
• 局所的変分法の枠組みでも、凸性は中⼼的な役割を演じる.
35
- 36.
- 37.
10.5 局所的変分推論法
• η:=-exp(-ξ)と定義すると,ξ=-log(-η)なので,
• 凸関数の性質から、fの接線は常に関数の下限になるので、もともとの関数
を以下のような形で書くことができる
• 新たなパラメータηを導⼊する対価として、凸な関数f(x)をより簡単な⼀次
関数で近似することができた.
• これは⼀般に凸双対性の理論で説明されることである.
37
- 38.
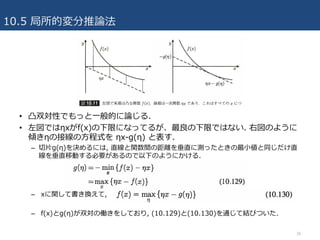
10.5 局所的変分推論法
38
• 凸双対性でもっと⼀般的に論じる.
•左図ではηxがf(x)の下限になってるが、最良の下限ではない. 右図のように
傾きηの接線の⽅程式を ηx-g(η) と表す.
– 切⽚g(η)を決めるには, 直線と関数間の距離を垂直に測ったときの最⼩値と同じだけ直
線を垂直移動する必要があるので以下のようにかける.
– xに関して書き換えて,
– f(x)とg(η)が双対の働きをしており, (10.129)と(10.130)を通じて結びついた.
- 39.
10.5 局所的変分推論法
39
• 双対の関係を,当初の例 f(x)=exp(-x)に適⽤する. (10.129)より, xの値は
ξ=-ln(-η)で与えられるので, g(η)は前と同じく以下のように得られる.
• 凹な関数に関しても、同様の議論でʼmaxʼをʼminʼと⼊れ替えれば、上限をえ
ることできる.
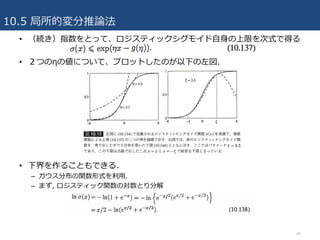
• パターン認識でよく現れる重要な例は、次式で定義されるロジスティックシ
グモイド関数である.
– これは、凹でも凸でもないが、対数を取ると凸になる. (10.133)より、対応する共役
な関数は以下のようにかける.
– これは変数の値が1となる確率がηのときの⼆値エントロピー関数で、(10.132)を⽤い
ると、対数シグモイド関数の上限が得られる.
- 40.
- 41.
10.5 局所的変分推論法
41
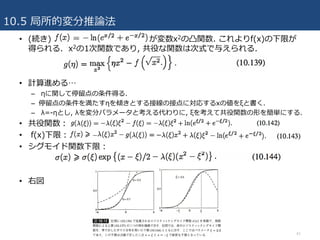
• (続き)が変数x2の凸関数. これよりf(x)の下限が
得られる. x2の1次関数であり, 共役な関数は次式で与えられる.
• 計算進める…
– ηに関して停留点の条件得る.
– 停留点の条件を満たすηを傾きとする接線の接点に対応するxの値をξと書く.
– λ=-ηとし, λを変分パラメータと考える代わりに, ξを考えて共役関数の形を簡単にする.
• 共役関数:
• f(x)下限:
• シグモイド関数下限:
• 右図
- 42.
10.5 局所的変分推論法
42
• どうやって下限を使うのか.
•ロジスティックシグモイド関数σとガウス確率密度pについて、以下の積分
を計算したいとする.
• こうした計算は予測分布を求めるときに必要になる. 不等式σ(a)≧f(a,ξ)が
成り⽴つ時(変分下限(10.144)を⽤いている), (10.145)は, 以下のように評
価できる.
• 関数Fを最⼤化できれば、Iの良い近似になる.
- 43.
- 44.
- 45.
10.6.1 変分事後分布
45
• (10.153)の対数取ると,
•右辺に事前分布p(w)=Ν(w|m0, S0)を代⼊すると,
• (10.155)の形から, 変分事後分布q(w)は適当なガウス分布N(w|mN,SN)で
表せることがわかる.
– 2次の項に着⽬すると精度, 1次の項に着⽬すると平均mNは以下の様にかける.
• こうして, ラプラス近似のように事後分布のガウス分布近似を得た. 今回は
さらに変分パラメータ{ξn}nが加わり柔軟になっているので、より⾼い精度
期待できる.
- 46.
10.6.2 変分パラメータの最適化
46
• 変分事後分布がq(w)=N(w|mN,SN)とガウス分布で近似できた.
• 平均mNと分散SNはどちらもξに依存しているので, ξの最適化を考える.
• いつも通り周辺尤度の下からの近似を考える.
• 次に ξnを決めるには、この後の⽅法に2通りある.
– 1. wを潜在変数とみなしてEMアルゴリズムを⽤いる
– 2. wに対する積分を計算し, ξを直接最⼤化する
• まずは、1つ⽬のEMアルゴリズムを使う⽅法から⾒てく.
- 47.
- 48.
- 49.
10.6.2 変分パラメータの最適化
49
• 2つ⽬の⽅法は,解析的な⽅法.
– 下限の定義(10.159)でのwに対する積分で, 被積分項がガウス分布に似た形をしている
ことに注意して, 積分が解析的に実⾏できることを利⽤する. (→ 演習10.35)
– 積分を計算した後, 結果をξnに関して微分. (10.163)のEMによる⽅法と同じ再推定⽅程
式になることがわかる.
• 解析的に計算した下限
• データが順番に到着する⽅法でも適⽤可能.
– wのガウス事後分布を事前分布p(w)で初期化し, 保持しておく. データ点が到着するた
び, 事後分布を(10.151)を使い, 正規化することで新しい事後分布に更新.
- 50.
10.6.3 超パラメータの推論
50
• ベイズロジスティック回帰モデルで,今までwを定める超パラメータαは既
知の定数としてきたが, αもデータから推測できると嬉しい.
• ⼤域的な変分法と, 局所的変分法を⼀つの枠組みに統合し, 周辺尤度の下限
を常に保持することで達成できる.
• wの事前分布として, 以下の等⽅ガウス分布を仮定.
• 共役事前分布p(α)は以下のガンマ分布とする.
• このモデルの周辺尤度は次式になる.
• ここで同時分布は次式で与えられる.
- 51.
10.6.3 超パラメータの推論
51
• (10.168)はwとαについての解析的に解けない積分だが,同じモデル内で局
所的変分法と⼤域的な変分法の両⽅を使うことで扱うことができる.
• まず, 変分分布q(w,α)を導⼊し, いつもどおり(10.2)の分解を⾏うと, 今回
は次式になる.
• 下限項とカルバック…項は次で定義される.
• これでもまだ尤度因⼦p(t|w)の形から, 下限L(q)は積分できない. したがっ
て, 前と同様に局所的な下限をロジスティックシグモイドの各因⼦に適⽤す
うる. (10.152)よりL(q)の下限が得られ, それが対数周辺尤度の下限にもな
る.
- 52.
10.6.3 超パラメータの推論
52
• 次に,変分分布が下のように, パラメータと超パラメータに分解できると仮
定.
• この分解により, ⼀般的な結果(10.9)を⽤いて, 各因⼦分布の最適解を求め
ることが可能. 最初にq(w)を考える. Wに依存しない項を除くと次を得る.
– logh(w,ξ)に(10.153)を, logp(w|α)に(10.165)を代⼊して次式を得る.
• これはwの⼆次関数なので、q(w)はガウス分布だとわかる.
• よっていつも通り平⽅完成すると, 次式成り⽴つ.
– ただし
- 53.
10.6.3 超パラメータの推論
53
• 同様に,因⼦q(α)の最適解は次式から得られる.
• lnp(w|α)に(10.165)を, lnp(α)に(10.166)を代⼊して次式得る.
• これは、ガンマ分布の対数の形になってるのでなので、以下のようにかける.
– ただし,
• 最後にξの推定を⾏う⽅法を考える. 下界の最⼤化をすることでおこなう. ξ
に関連する項に着⽬し, 依存しない項除きαで積分すると次式得る.
• (10.159と)全く同じ形なので、前の結果より,
- 54.
- 55.
10.7 EP法
55
• もうひとつの決定性の近似推論:EP法(期待値伝搬法)
•これまで説明した変分ベイズ法同様、この近似もKLダイバージェンスの最
⼩化基づいているが、その使い⽅が逆で、異なる性質の近似になっている.
• p(z)が固定された確率分布とした時, KL(p||q)をq(z)について最⼩化する問
題考える. q(z)が指数型分布族なら, (2.194)より, q(z)は以下の様に書ける.
• このときKLダイバージェンスは, ηの関数として考えて, 以下になる.
• ここで定数項は, ⾃然パラメータηとは独⽴. 指数型分布族の仮定の元,
KL(p||q)の最⼩化はηに関する勾配を0と置いて, 以下得られる.
• (2.226)と合わせて, (最適解は⼗分統計量の期待値の⼀致に対応)
- 56.
10.7 EP法
56
• (続き)これらの結果を使い,近似推論の実⽤的なアルゴリズムを導出してみ
る.
• 多くの確率モデルでは, データDと隠れ変数θの同時分布は因⼦の積の形でか
ける.
– 例) 各データ点xnに対応する因⼦fn(θ)=p(xn|θ)があり, 事前分布に対応する因⼦
f0(θ)=p(θ)となっている場合
• 予測を⾏うために, 事後分布p(θ|D)や⽐較を⾏うためにモデルエビデンス
p(D)が必要
– (10.188)から以下2式与えられる.
• 上の式で与えられた隠れ変数θに対する周辺化、予測のための事後分布に対
する周辺化を厳密に⾏うのは不可能
• → 何らかの近似が必要.
• EP法では事後分布を同じように因⼦の積として与える近似に基づく.
- 57.
10.7 EP法
57
• EP法は,
–各因⼦の最適化を、他の因⼦による近似全てを条件として順番に⾏って最適化するので、
近似精度悪くならない.
– 最初に各因⼦f~
i(θ)を初期化した後, 各因⼦を巡回して, 1つずつ近似を改良していく.
(前で説明した変分ベイズ推論での因⼦の更新と似てる)
– 因⼦f~
i(θ)を改良したいとする. この因⼦を全体の積から取り除き,
– を得る.
– この⽅法は、近似が残りの因⼦によって定まる⾼い確率の領域で、最も正確になること
を保証している.
- 58.
10.7 EP法
58
• (つづき)実際に前述のことを⾏うためには:
•まず最初に、因⼦f~i(θ)を現在の近似事後分布から除き, 正規化されていな
い分布を得る.
– 除算を使う⽅が簡単なのでそうしている.
• 因⼦fj(θ)をかけると、以下の分布が得られる.
• ここでZjは正規化定数
• これにより, 改良された因⼦f~j(θ)は, 以下のKLダイバージェンスを最⼩化
することで求めることができる.
- 59.
10.7 EP法
59
• (10.187)の結果からqnew(θ)のパラメータは,⼗分統計量の期待値を
(10.196)の対応するモーメントと⼀致させることで得られる.
– 例:q(θ)をガウス分布N(θ|μ, Σ)と選べば, μは正規化されていない分布の平均, Σはそ
の共分散に取れば良い.
• → ⼀般的には、どんな指数型分布族の分布についても、正規化さえできれ
ば必要な期待値は簡単に得られる.
– 理由: ⼗分統計量の期待値は(2.226)で与えられているように, 正規化係数を微分すれば
求められるから.
• EP法による近似の例↓
- 60.
10.7 EP法
60
• (10.193)から,改良された因⼦f~
j(θ)は, qnew(θ)を残りの因⼦で割ることで
得られる. (また10.195を⽤いた)
• 係数Kは(10.199)の両辺に を掛け, 積分すると得られる.
– (ここでqnew(θ)が正規化されていることを前提として使っている.)
• Kの値は, ゼロ次のモーメントを⼀致させることで得られる.
– これと10.197をあわせると, K=Zjであることがわかり, (10.197)の積分を求めるとK
の値が得られる.
• 実際の推定では, 因⼦全体について数パスの更新を⾏って各因⼦を順に改良
していく. この時事後分布p(θ|D)は(10.191)で近似され、モデルエビデン
スp(D)は(10.190)を⽤い、因⼦fi(θ)をその近似f~i(θ)で置き換えて近似さ
れることになる.
- 61.
- 62.
10.7 EP法
62
• EP法の特別な場合として,仮定密度フィルタリング(ADF)/モーメント⼀致
法と呼ばれる⽅法がある.
– ⼀番最初以外の因⼦を全て1に初期化し, 因⼦を1パスで⼀度だけ順番に更新する.
– → 順番に到着する観測データ点から学習し, 次の学習点を観測する前にその情報を捨て
てしまうオンライン学習に適している.
• EP法⻑所①:⼀⽅バッチ学習の場合には, 観測データ点のもつ情報を何回も
利⽤してより精度を上げることができ, これがEP法の中⼼的なアイデアに
なっている. (ADFよりEPの⽅がバッチ学習に適している)
• EP法の⽋点①:更新が収束する保証がない.
• KLダイバージェンスの形の違い. 変分ベイズはKL(q||p), EP法はKL(p||q)
を最⼩化する.
– EP法⽋点②:混合モデルの場合, 結果が良くない.
• 複峰性の場合, 事後分布の全ての峰をカバーしようとしてしまうため.
– EP法⻑所①:ロジスティックな形のモデルの場合だと, 局所的変分法やらプラス近似よ
り勝ることが多い.
- 63.
10.7.1 例: 雑⾳データ問題
63
•Minka(2016)におけるEP法の適⽤例.
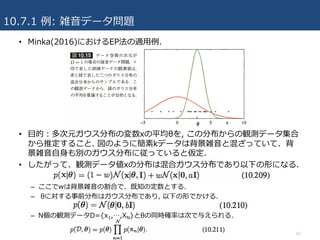
• ⽬的:多次元ガウス分布の変数xの平均θを, この分布からの観測データ集合
から推定すること. 図のように簡素kデータは背景雑⾳と混ざっていて、背
景雑⾳⾃⾝も別のガウス分布に従っていると仮定.
• したがって、観測データ値xの分布は混合ガウス分布であり以下の形になる.
– ここでwは背景雑⾳の割合で、既知の定数とする.
– θに対する事前分布はガウス分布であり, 以下の形でかける.
– N個の観測データD={x1,…,XN}とθの同時確率は次で与えられる.
- 64.
10.7.1 例: 雑⾳データ問題
64
•(10.211)より、事後分布は2N個のガウス分布の混合分布となるため、この
問題を正確に解くための計算量はデータ集合のサイズに従って指数的に増加
してしまい、ある程度⼤きな値のNについては、正確な値を求めることはで
きない.
• EP法をこの雑⾳データ問題に適⽤するには, まず因⼦をf0(θ)=p(θ)および
fn(θ)=p(xn|θ)とする. 次に, 近似分布を指数型分布族から選ぶが, 今回の例
では以下の等⽅ガウス分布を選ぶ.
• したがって、因⼦近似は指数⼆次関数の形式になる
– ここで, n=1,…,Nであり, f~0(θ)は事前分布p(θ)に等しい.
– ※ 右辺N(θ|・,・)という表記は必ずしも, 正しく定義されたガウス密度であるという意
味ではなく, 単に都合いい略記⽅である.
– 近似f~n(θ)はまず, n=1,…,Nについて1に初期化される.
• 次に因⼦fn(θ)を1つずつとり, (10.205), (10.206), (10.207)を適⽤して
因⼦近似を繰り返し改良していく.
- 65.
10.7.1 例: 雑⾳データ問題
65
•最初に, q(θ)から現在の推定値f~
n(θ)を(10.205)のように除算して除き,
q|n(θ)を得る. (|はバックスラッシュのつもり…。)この平均と分散は以下で
与えられる.
• 次に, 正規化定数Znを(10.206)を⽤いて計算し以下を得る.
• 同様にqnew(θ)の平均と分散を, q|n(θ)fn(θ)のものと⼀致させると, 以下得る.
– ここで,
• ↑は, 観測点xnが背景雑⾳に属さない確率という意味持つ.
• 次に, (10.207)⽤いて, 改良された因⼦f~
n(θ)のパラメータは以下になる.
- 66.
10.7.1 例: 雑⾳データ問題
66
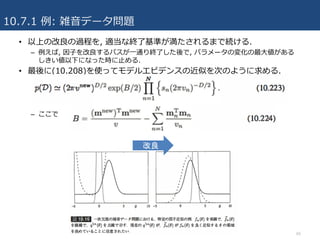
•以上の改良の過程を, 適当な終了基準が満たされるまで続ける.
– 例えば, 因⼦を改良するパスが⼀通り終了した後で, パラメータの変化の最⼤値がある
しきい値以下になった時に⽌める.
• 最後に(10.208)を使ってモデルエビデンスの近似を次のように求める.
– ここで
改良
- 67.
- 68.
10.7.2 グラフィカルモデルとEP法
68
• これまでのEP法の議論では,分布p(θ)に含まれる因⼦fi(θ), 及び近似分布
q(θ)に含まれる近似因⼦f~(θ)はθ全体の関数だとしてきた.
• ここでは, 各因⼦が変数θ全体でなく, その⼀部のみ依存する場合を考える.
– → このような制限は8章の確率的グラフィカルモデルの考え⽅を使うとうまく表せる.
– 因⼦グラフを使うと有向グラフと無向グラフの両⽅を表現できる.
• 近似分布が完全に分解できる場合を考える.
• まず最初に(10.17)からKLダイバージェンスKL(p||q)を近似分解された分
布qについて最⼩化すると, 各因⼦の最適解は単純にpの対応する周辺分布に
なることを思い出す…(a)
• いま, 積和アルゴリズム(8.4.4)の議論で導⼊した, (図10.18)の左側の因⼦
グラフを考える.
– この時同時分布は次式で与えられる.
– ここで同じ分解持つ次式の近似分解q(x)を探したい.
- 69.
10.7.2 グラフィカルモデルとEP法
69
• (続き)なお,正規化定数が省略されているが, これは通常の確率伝播と同様
に, 局所的な正規化によって最後に求められる.
• 各因⼦を変数ごとに分解した近似を考えると,
– これは前のページの図10.18の右側の因⼦グラフの形になる. 各因⼦が分解されている
ため, 全体の近似分布q(x)⾃体も完全に分解されている.
• ここで, EP法をこの完全に分解された近似に適⽤する.
– 因⼦を全て初期化し終わり, 因⼦f~
b(x2,x3)=f~
b2(x2)f~
b3(x3)を改良する分布に選んだと
する. この分布を全体の近似分布から除くと, 以下得る.
– 次に, この式に正しい因⼦fb(x2, x3)を掛けると, 以下を得る.
• いま, KL(p^||qnew)を最⼩化するqnew(x)を探す. 結果は(a)で述べた通り,
qnew(z)は変数xiごとの因⼦の積からなり, 各因⼦はp^(x)の対応する周辺分
布となる. その4つの周辺分布は以下で与えられる.
- 70.
10.7.2 グラフィカルモデルとEP法
70
• (続き)qnew(x)は,以上の4つの周辺分布を全て掛け合わせることで得られる.
• q(x)の中でf~
b(x2,x3)を更新する際に変化するのは, fbに含まれる変数, すな
わちx2とx3を含む項だけであるのがわかる.
• 改良されたf~
b(x2, x3)=f~
b2(x2)f~
b3(x3)を得るためには, qnew(x)を単に
q|b(x)で割ればよく, 以下得られる.
• これらは, 確率伝播(8.4.4節)で受け渡されるメッセージと同じ
– ここでは変数ノードから因⼦ノードへのメッセージは, 因⼦ノードから変数ノードへの
ものに含まれている.
• 上の結果では, メッセージが双⽅向に同時に受け渡されるため, わずかに普
通の確率伝播とは異なる.
• EP法のアルゴリズムを少し変えて, ⼀回に⼀つの因⼦だけを更新すれば, 標
準的な積和アルゴリズムが得られる.
- 71.
10.7.2 グラフィカルモデルとEP法
71
• 次に下の分布で定義される,⼀般的な因⼦グラフについて考える.
• ここで, θiは因⼦fiに関連する部分集合である. この分布を, 完全に分解した
以下の分布で近似する.
– ここで, θkはそれぞれの変数ノードに対応. 他の項を全て固定した上で, f~
jl(θl)の項を改
良したいとする. 最初にq(θ)からf~
j(θj)の項を取り除くと, 以下が得られる.
– 次に厳密な因⼦fj(θj)をこれに掛ける. f~
jl(θl)の項を改良するためには, θlへの関数依存
性だけ考えればよいので, 次の式の対応する周辺分布を考えるだけで良い.
– ⽐例定数を除くと, これはfj(θj)と, q|j(θ)の中でθjの関数になっている項全部の積の周辺
分布を考えることになる.
• 理由: i≠jである他の項f~
i(θi)は, 後でq|i(θ)で割るときに, 分⺟と分⼦でキャンセルしてしまう
ためである.
– よって次式を得る.
– これは図8.50で⽰した例と同じ積和アルゴリズムであり, 変数ノードから因⼦ノードへ
のメッセージが消去されていると考えられる.
- 72.
- 73.
参考⽂献
• パターン認識と機械学習 下
–C.M. ビショップ (著), 元⽥ 浩 (監訳), 栗⽥ 多喜夫 (監訳), 樋⼝ 知之 (監訳), 松本 裕治 (監訳), 村⽥ 昇 (監訳)
• 変分推論法(変分ベイズ法)(PRML第10章) - SlideShare
– http://machine-learning.hatenablog.com/entry/2016/01/23/123033
• 変分近似(Variational Approximation)の基本(1)
– https://www.slideshare.net/takao-y/ss-28872465
• Prml14th 10.7 - SlideShare
– https://www.slideshare.net/ruto5/prml14th-107
73






























![10.4 指数型分布族
• 同様に、パラメータの変分近似についても以下のようにできる
– 両辺の指数をとって、正規化定数を加えて
• なお変数の定義は以下.
• q*(zn)とq*(η)の解には相互依存性があるので、⼆段階の繰り返しで解く.
– 変分Eステップでは, 潜在変数の事後分布q(zn)から⼗分統計量の期待値E[u(xn, zn)]を求
め、これを使いパラメータの事後分布q(η)を改良する.
– 変分Mステップでは、改良したパラメータの事後分布を使って⾃然パラメータの期待値
E[ηT]を求め、これから潜在変数の事後分布をまた改良する.
32](https://image.slidesharecdn.com/prml10-170726093308/85/PRML-10-32-320.jpg)