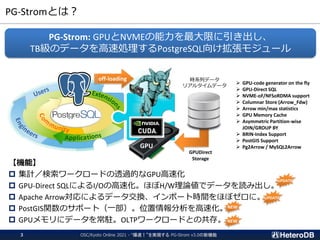
統計情報を利用したクエリの最適化(1/3)
Arrowのスキーマ定義を利用したArrow_Fdw外部テーブルの定義
postgres=# IMPORT FOREIGNSCHEMA flineorder_sort
FROM SERVER arrow_fdw INTO public
OPTIONS (file '/dev/shm/flineorder_sort.arrow');
IMPORT FOREIGN SCHEMA
Arrowのmin/max statisticsを利用した問合せ例
postgres=# EXPLAIN ANALYZE
SELECT count(*) FROM flineorder_sort
WHERE lo_orderpriority = '2-HIGH'
AND lo_orderdate BETWEEN 19940101 AND 19940630;
QUERY PLAN
------------------------------------------------------------------------------------------
Aggregate (cost=33143.09..33143.10 rows=1 width=8) (actual time=115.591..115.593 rows=1loops=1)
-> Custom Scan (GpuPreAgg) on flineorder_sort (cost=33139.52..33142.07 rows=204 width=8)
(actual time=115.580..115.585 rows=1 loops=1)
Reduction: NoGroup
Outer Scan: flineorder_sort (cost=4000.00..33139.42 rows=300 width=0)
(actual time=10.682..21.555 rows=2606170 loops=1)
Outer Scan Filter: ((lo_orderdate >= 19940101) AND
(lo_orderdate <= 19940630) AND (lo_orderpriority = '2-HIGH'::bpchar))
Rows Removed by Outer Scan Filter: 2425885
referenced: lo_orderdate, lo_orderpriority
Stats-Hint: (lo_orderdate >= 19940101), (lo_orderdate <= 19940630) [loaded: 2, skipped: 8]
files0: /dev/shm/flineorder_sort.arrow (read: 217.52MB, size: 2357.11MB)
Planning Time: 0.210 ms
Execution Time: 153.508 ms
(11 rows)
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
29
30.
統計情報を利用したクエリの最適化(2/3)
列方向だけでなく、行方向での絞り込みと同義
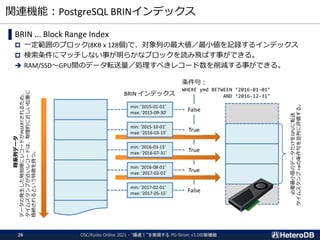
Full Table Scanof Row-Data
(PostgreSQL Heap)
Full Table Scan of Column-Data
(Arrow_Fdw; no Stats-Hint)
Full Table Scan of Column-Data
with Min/Max Stats Hint
Only referenced
columns
ts BETWEEN ‘2021-04-01’
AND ‘2021-06-30’
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
30
31.
統計情報を利用したクエリの最適化(3/3)
ログデータの“タイムスタンプ“に統計情報を付加するのがお勧め。
Pg2Arrowだけでなく、他のツールが生成したArrow ファイルに、
後付けで統計情報を埋め込むためのツールを準備中。
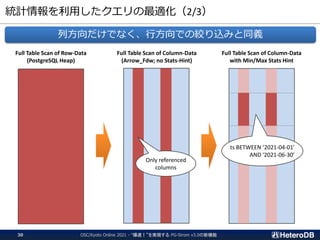
列/行双方の絞り込みで、上手くハマれば強烈に速くなる
254.905
99.587
10.052
1.191
0
50
100
150
200
250
300
Query
Response
Time
[sec]
(shorter
is
better)
Query response time of SSBM Q1_2 [mod]
PostgreSQL v13.3 PG-Strom v3.1dev [Row-Data]
PG-Strom v3.1dev [Apache Arrow; No Stats Hint] PG-Strom v3.1dev [Apache Arrow; with Stats Hint]
select sum(lo_extendedprice*lo_discount) as revenue
from flineorder_sort, date1
where lo_orderdate = d_datekey
and d_yearmonthnum = 199401
and lo_discount between 4 and 6
and lo_quantity between 26 and 35;
select sum(lo_extendedprice*lo_discount) as revenue
from flineorder_sort, date1
where lo_orderdate = d_datekey
and d_yearmonthnum = 199401
and lo_discount between 4 and 6
and lo_quantity between 26 and 35;
and lo_orderdate between 19940101 and 19940131;
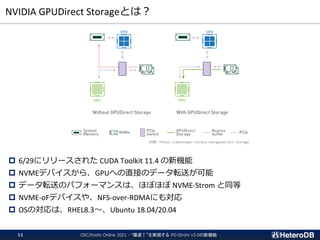
GPU-Direct SQLの効果
Apache Arrowの効果
min/max statisticsの効果
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
31






![背景:SSD-to-GPUダイレクトSQL(2/2)
クエリ実行スループット = (879GB DB-size) / (クエリ応答時間 [sec])
SSD-to-GPU Direct SQLの場合、ハードウェア限界(8.5GB/s)に近い性能を記録
CPU+Filesystemベースの構成と比べて約3倍強の高速化
➔ 従来のDWH専用機並みの性能を、1Uサーバ上のPostgreSQLで実現
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
10
2,443 2,406 2,400 2,348 2,325 2,337 2,346 2,383 2,355 2,356 2,327 2,333 2,313
8,252 8,266 8,266 8,154 8,158 8,186
7,933
8,094
8,240 8,225
7,975 7,969 8,107
0
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
9,000
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
Query
Execution
Throughput
[MB/s]
Star Schema Benchmark (s=1000, DBsize: 879GB) on Tesla V100 x1 + DC P4600 x3
PostgreSQL 11.5 PG-Strom 2.2 (Row data)](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-10-320.jpg)
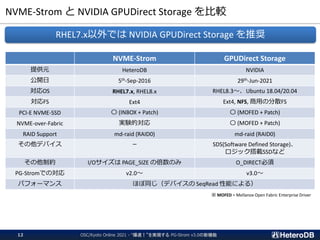
![GPU-Direct SQLの性能測定
クエリ実行中の読み出し速度は、理論値に近い10.0GB/s
0
2,000
4,000
6,000
8,000
10,000
0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 380
Total
Storage
Read
Throughput
[MB/sec]
Elapsed Time [sec]
Total Storage Read Throughput
during Query Execution [Q1_1]
Query Execution
with GPUDirect Storage
Query Execution with PostgreSQL Heap Storage
nvme1
nvme2
nvme3
nvme4
nvme1
nvme2
nvme3
nvme4
測定に用いたIntel DC P4510のカタログスペックは SeqRead: 2750MB/s
➔ 4本で理論速度 11.0GB/s に対し、クエリ実行中の読み出し速度 10.0GB/s を達成。
(ファイルシステムだと高々3.8GB/s程度)
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
13](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-13-320.jpg)

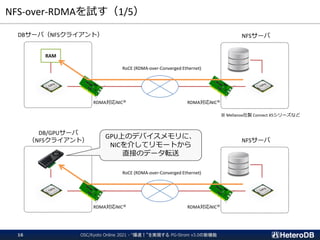
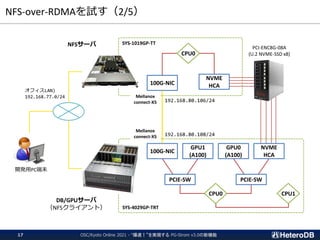
![NFS-over-RDMAを試す(3/5)
NFSサーバ側の設定
# modprobe svcrdma
# modinfo svcrdma
filename: /lib/modules/4.18.0-240.22.1.el8_3.x86_64/extra/mlnx-nfsrdma/svcrdma.ko
:
# echo rdma 20049 > /proc/fs/nfsd/portlist
# cat /proc/fs/nfsd/portlist
rdma 20049
rdma 20049
tcp 2049
tcp 2049
NFSクライアント側の設定
# modprobe rpcrdma
# modinfo rpcrdma
filename: /lib/modules/4.18.0-240.22.1.el8_3.x86_64/extra/mlnx-nfsrdma/rpcrdma.ko
:
# grep nvfs_ops /proc/kallsyms
ffffffffc319ddc8 b nvfs_ops [rpcrdma]
ffffffffc0c256c0 b nvfs_ops [nvme_rdma]
ffffffffc00dc718 b nvfs_ops [nvme]
# mount -o rdma,port=20049 192.168.80.106:/mnt/nfsroot /opt/nvme1
# dd if=/opt/nvme1/100GB of=/dev/null iflag=direct bs=32M
3106+1 records in
3106+1 records out
104230305696 bytes (104 GB, 97 GiB) copied, 11.8926 s, 8.8 GB/s
MOFEDドライバ版を使用
MOFEDドライバ版を使用
※但し、自分で再ビルドしないと
GPUDirect Storage対応機能が有効になっていない
nvidia-fsモジュールとの連携が有効になっている。
rdmaオプションをつけてNFSマウント
NFS-over-RDMAあり: 8.8GB/s
NFS-over-RDMAなし: 3.2GB/s
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
18](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-18-320.jpg)
![NFS-over-RDMAを試す(4/5)
SF=500 (DB: 453GB) の Star Schema Benchmark データに対してクエリを実行
スループット = 453.6GB / (クエリ応答時間)
➔ ローカルのNVME-SSDには劣るものの、最大で 8.2GB/s 程度の処理レートを達成
(ただし、NFSサーバ側のH/Wが原因で律速している可能性はある。
Skylake-SPの場合、P2P-DMAが8.5GB/s程度で頭打ちになっていた。)
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
Query
Execution
Throughput
[MB/s]
SSBM Query Execution Throughput with GPUDirect SQL
(Local NVME vs NFS over RDMA)
PG-Strom v3.0 [PCI-E NVME] PG-Strom v3.0 [NFSoRDMA]
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
19](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-19-320.jpg)
![NFS-over-RDMAを試す(5/5)
Star Schema Benchmark実行中のI/O帯域を計測(iostat, nfsstat使用)
Local NVME-SSD実行時に謎の速度変化があるが、概ねクエリの
実行スループットと同等のデータ読み出し速度
➔ 性能10%ダウン程度で、共有ファイルシステムが使えるなら十分アリでは?
0
2000
4000
6000
8000
10000
0 20 40 60 80 100
Storage
Read
Throughput
[MB/s]
Elapsed Time [sec]
Storage Read throughput under GPUDirect SQL
(Local NVME vs NFS-over-RDMA)
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
20](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-20-320.jpg)

![ログデータ処理に Apache Arrow を使うメリット
① 列データなので、クエリで参照された列だけをロードすればよい
➔ I/Oの量が減り、それに伴いクエリ応答時間が短くなる。
② DBへデータをインポートする必要がない
➔ OS上でファイルコピーすれば、それで準備完了。
21.13 20.54 20.43 18.88 18.65 18.30 16.08 20.70 19.36 20.00 19.05 19.73 19.35
64.98 64.88 65.39 63.48 58.08 64.28 58.16 60.27 58.32 62.36 58.30 58.86 58.24
587.16
463.37 467.69
324.90
198.93
328.96
192.64
245.48 247.13
228.83
164.63 173.41 163.08
0.0
100.0
200.0
300.0
400.0
500.0
600.0
Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3
Number
of
rows
processed
per
second
[million
rows/sec]
Star Schema Benchmark
(SF=999 [875GB], 1xTesla A100 (PCI-E; 40GB), 4xDC P4510(1.0TB; U.2)
PostgreSQL v13.3 [Heap; row-data] PG-Strom v3.0 [Heap; row-data] PG-Strom v3.0 [Apache Arrow; column-data]
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
24](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-24-320.jpg)
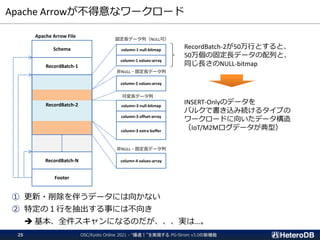
![Apache Arrowファイルに統計情報を埋め込む(1/2)
Apache Arrow File
Header “ARROW1¥0¥0”
Schema Definition
RecordBatch-1
RecordBatch-k
Footer
• Schema Definition (copy)
• RecordBatch[0] (offset, size)
:
• RecordBatch[k] (offset, size)
• Terminator “ARROW1”
RecordBatch-0
ArrowSchema
_num_fields = 3
ArrowField
name = “device_id”
type=Uint32
ArrowField
name = “attribute”
type=Float64
ArrowField
name = “ts”
type=TimeStamp
custom_metadata[]
ArrowKeyValue
key = “min_values”
value=“…”
ArrowKeyValue
key = “max_values”
value=“…”
Apache Arrowデータ形式は、
Schema(表に相当)とField(列に相当)に
カスタムの Key-Value 値を埋め込む事を許容する。
➔ 標準のデータ形式に一切手を加えることなく、
Record-Batch毎の最小値/最大値を記録する事ができる。
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
27](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-27-320.jpg)
![Apache Arrowファイルに統計情報を埋め込む(2/2)
統計情報付き Apache Arrow ファイルの生成
$ pg2arrow -d postgres -o /dev/shm/flineorder_sort.arrow ¥
-t lineorder_sort --stat=lo_orderdate --progress
RecordBatch[0]: offset=1640 length=268437080 (meta=920, body=268436160) nitems=1303085
:
RecordBatch[9]: offset=2415935360 length=55668888 (meta=920, body=55667968) nitems=270231
$ ls -lh /dev/shm/flineorder_sort.arrow
-rw-r--r--. 1 kaigai users 2.4G 7月 19 10:45 /dev/shm/flineorder_sort.arrow
生成された統計情報の確認
$ python3
>>> import pyarrow as pa
>>> X = pa.RecordBatchFileReader('/dev/shm/flineorder_sort.arrow')
>>> X.schema
lo_orderkey: decimal(30, 8)
:
lo_suppkey: decimal(30, 8)
lo_orderdate: int32
-- field metadata --
min_values: '19920101,19920919,19930608,19940223,19941111,19950730,1996' + 31
max_values: '19920919,19930608,19940223,19941111,19950730,19960417,1997' + 31
lo_orderpriority: fixed_size_binary[15]
:
lo_shipmode: fixed_size_binary[10]
-- schema metadata --
sql_command: 'SELECT * FROM lineorder_sort'
RecordBatch ごと、最小値/最大値を埋め込み
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
28](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-28-320.jpg)
![統計情報を利用したクエリの最適化(1/3)
Arrowのスキーマ定義を利用したArrow_Fdw外部テーブルの定義
postgres=# IMPORT FOREIGN SCHEMA flineorder_sort
FROM SERVER arrow_fdw INTO public
OPTIONS (file '/dev/shm/flineorder_sort.arrow');
IMPORT FOREIGN SCHEMA
Arrowのmin/max statisticsを利用した問合せ例
postgres=# EXPLAIN ANALYZE
SELECT count(*) FROM flineorder_sort
WHERE lo_orderpriority = '2-HIGH'
AND lo_orderdate BETWEEN 19940101 AND 19940630;
QUERY PLAN
------------------------------------------------------------------------------------------
Aggregate (cost=33143.09..33143.10 rows=1 width=8) (actual time=115.591..115.593 rows=1loops=1)
-> Custom Scan (GpuPreAgg) on flineorder_sort (cost=33139.52..33142.07 rows=204 width=8)
(actual time=115.580..115.585 rows=1 loops=1)
Reduction: NoGroup
Outer Scan: flineorder_sort (cost=4000.00..33139.42 rows=300 width=0)
(actual time=10.682..21.555 rows=2606170 loops=1)
Outer Scan Filter: ((lo_orderdate >= 19940101) AND
(lo_orderdate <= 19940630) AND (lo_orderpriority = '2-HIGH'::bpchar))
Rows Removed by Outer Scan Filter: 2425885
referenced: lo_orderdate, lo_orderpriority
Stats-Hint: (lo_orderdate >= 19940101), (lo_orderdate <= 19940630) [loaded: 2, skipped: 8]
files0: /dev/shm/flineorder_sort.arrow (read: 217.52MB, size: 2357.11MB)
Planning Time: 0.210 ms
Execution Time: 153.508 ms
(11 rows)
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
29](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-29-320.jpg)
![統計情報を利用したクエリの最適化(3/3)
ログデータの“タイムスタンプ“に統計情報を付加するのがお勧め。
Pg2Arrowだけでなく、他のツールが生成した Arrow ファイルに、
後付けで統計情報を埋め込むためのツールを準備中。
列/行双方の絞り込みで、上手くハマれば強烈に速くなる
254.905
99.587
10.052
1.191
0
50
100
150
200
250
300
Query
Response
Time
[sec]
(shorter
is
better)
Query response time of SSBM Q1_2 [mod]
PostgreSQL v13.3 PG-Strom v3.1dev [Row-Data]
PG-Strom v3.1dev [Apache Arrow; No Stats Hint] PG-Strom v3.1dev [Apache Arrow; with Stats Hint]
select sum(lo_extendedprice*lo_discount) as revenue
from flineorder_sort, date1
where lo_orderdate = d_datekey
and d_yearmonthnum = 199401
and lo_discount between 4 and 6
and lo_quantity between 26 and 35;
select sum(lo_extendedprice*lo_discount) as revenue
from flineorder_sort, date1
where lo_orderdate = d_datekey
and d_yearmonthnum = 199401
and lo_discount between 4 and 6
and lo_quantity between 26 and 35;
and lo_orderdate between 19940101 and 19940131;
GPU-Direct SQLの効果
Apache Arrowの効果
min/max statisticsの効果
OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能
31](https://image.slidesharecdn.com/20210731osckyotopgstromv3-210731020512/85/20210731_OSC_Kyoto_PGStrom3-0-31-320.jpg)






















![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)


![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)









![[db tech showcase Tokyo 2016] D13: NVMeフラッシュストレージを用いた高性能高拡張高可用なデータベースシステムの実現方...](https://cdn.slidesharecdn.com/ss_thumbnails/efmcwyyftdwdehhr3b4y-signature-06a70abedb3d16e5e7bcb9b2ba8014302148552ca76b90497742e559ab641b61-poli-160726094411-thumbnail.jpg?width=640&height=640&fit=bounds)








![[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b15postgresqlntt-oss-center-150619073139-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] D33: Deep Learningや、Analyticsのワークロードを加速するには-Ten...](https://cdn.slidesharecdn.com/ss_thumbnails/d33-170912071011-thumbnail.jpg?width=640&height=640&fit=bounds)



![[db tech showcase Tokyo 2016] D24: データベース環境における検証結果から理解する失敗しないフラッシュ活用法 第三章 ~デ...](https://cdn.slidesharecdn.com/ss_thumbnails/d6uypm5osrop0rxlhdef-signature-2d11c0bd82acade7267e98773c5eb2fdeb5e2d37143247ecfa1a77486c63a28f-poli-160721021336-thumbnail.jpg?width=640&height=640&fit=bounds)













