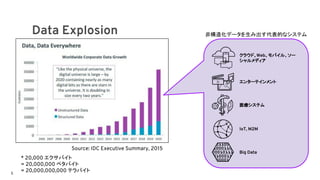
Data Explosion
Source: IDCExecutive Summary, 2015
医療システム
エンターテインメント
クラウド、Web、モバイル、ソー
シャルメディア
Big Data
非構造化データを生み出す代表的なシステム
IoT, M2M
* 20,000 エクサバイト
= 20,000,000 ペタバイト
= 20,000,000,000 テラバイト5
6.
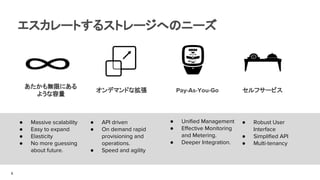
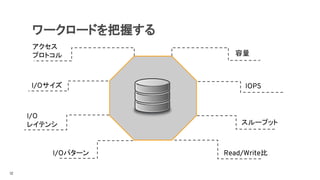
エスカレートするストレージへのニーズ
● Massive scalability
●Easy to expand
● Elasticity
● No more guessing
about future.
あたかも無限にある
ような容量
オンデマンドな拡張 Pay-As-You-Go
● API driven
● On demand rapid
provisioning and
operations.
● Speed and agility
● Unified Management
● Effective Monitoring
and Metering.
● Deeper Integration.
セルフサービス
● Robust User
Interface
● Simplified API
● Multi-tenancy
6
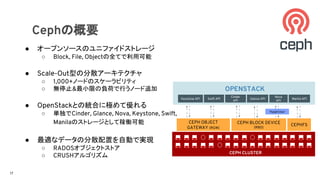
Cephの概要
● オープンソースのユニファイドストレージ
○ Block,File, Objectの全てで利用可能
● Scale-Out型の分散アーキテクチャ
○ 1,000+ノードのスケーラビリティ
○ 無停止&最小限の負荷で行うノード追加
● OpenStackとの統合に極めて優れる
○ 単独でCinder, Glance, Nova, Keystone, Swift,
Manilaのストレージとして稼働可能
● 最適なデータの分散配置を自動で実現
○ RADOSオブジェクトストア
○ CRUSHアルゴリズム
CEPH BLOCK DEVICE
(RBD)
CEPH OBJECT
GATEWAY (RGW)
OPENSTACK
Keystone API Swift API
Cinder
API
Glance API
Nova
API
Hypervisor
CEPH CLUSTER
Manila API
CEPHFS
17
18.
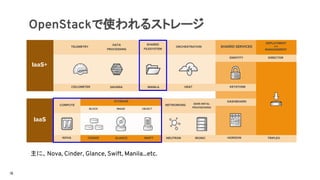
OpenStackで使われるストレージ
IaaS+
IaaS
TELEMETRY ORCHESTRATION
CEILOMETER SAHARAHEAT
DATA
PROCESSING
COMPUTE
NOVA
NETWORKING
NEUTRON IRONICCINDER GLANCE SWIFT
STORAGE
BLOCK IMAGE OBJECT
BARE-METAL
PROVISIONING
HORIZON TRIPLEO
DASHBOARD
SHARED SERVICES
IDENTITY
KEYSTONE
DIRECTOR
DEPLOYMENT
and
MANAGEMENT
MANILA
SHARED
FILESYSTEM
主に、Nova, Cinder, Glance, Swift, Manila...etc.
18
19.
SCALE ENCRYPTION RE-BALANCINGSNAPSHOTS REPLICATION CRUSH
RED HAT
SUPPORT
ONLINE
UPGRADES
STORAGE
CONSOLE
Ceph FS - 53%
Ceph RBD - 65%
CONTAINERIZED
CEPH
HYPER
CONVERGENCE
Red Hat Ceph Storageの特徴と機能
19
20.
OpenStack環境で標準的に利用されるCeph
* April 2017OpenStack User Survey : https://www.openstack.org/assets/survey/April2017SurveyReport.pdf
Which OpenStack block storage (Cinder) drivers are in use? Which OpenStack Shared File Systems (Manila) driver(s) are you using ?
20
21.
node2node1 node3 node4node5 node6node3node1
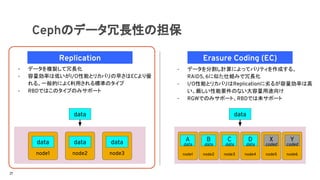
Cephのデータ冗長性の担保
data
node2
datadata data
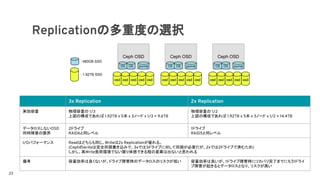
Replication
- データを複製して冗長化
- 容量効率は低いがI/O性能とリカバリの早さはECより優
れる。一般的によく利用される標準のタイプ
- RBDではこのタイプのみサポート
data
A
Erasure Coding (EC)
- データを分割し計算によってパリティを作成する、
RAID5, 6に似た仕組みで冗長化
- I/O性能とリカバリはReplicationに劣るが容量効率は高
い。厳しい性能要件のない大容量用途向け
- RGWでのみサポート、RBDでは未サポート
B C X Y
coded codeddata data data
D
data
21















































![[日本仮想化技術] 2014/6/5 OpenStack最新情報セミナー資料](https://cdn.slidesharecdn.com/ss_thumbnails/140605openstackcephbenchmark-140605203155-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













