Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Kohei KaiGai
PDF, PPTX
10,269 views
20170329_BigData基盤研究会#7
GPU/SSDがPostgreSQLを加速する ~ハードウェア性能を限界まで引き出すPG-Stromの挑戦~ (2017/03/29 BigData基盤研究会#7 発表資料)
Software
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 37
2
/ 37
3
/ 37
4
/ 37
5
/ 37
6
/ 37
7
/ 37
8
/ 37
9
/ 37
10
/ 37
11
/ 37
12
/ 37
13
/ 37
14
/ 37
15
/ 37
16
/ 37
17
/ 37
18
/ 37
19
/ 37
20
/ 37
21
/ 37
22
/ 37
23
/ 37
24
/ 37
25
/ 37
26
/ 37
27
/ 37
28
/ 37
29
/ 37
30
/ 37
31
/ 37
32
/ 37
33
/ 37
34
/ 37
35
/ 37
36
/ 37
37
/ 37
More Related Content
PDF
pgconfasia2016 lt ssd2gpu
by
Kohei KaiGai
PDF
PL/CUDA - Fusion of HPC Grade Power with In-Database Analytics
by
Kohei KaiGai
PDF
20170310_InDatabaseAnalytics_#1
by
Kohei KaiGai
PDF
SQL+GPU+SSD=∞ (Japanese)
by
Kohei KaiGai
PDF
20170127 JAWS HPC-UG#8
by
Kohei KaiGai
PDF
An Intelligent Storage?
by
Kohei KaiGai
PDF
20210731_OSC_Kyoto_PGStrom3.0
by
Kohei KaiGai
PDF
TPC-DSから学ぶPostgreSQLの弱点と今後の展望
by
Kohei KaiGai
pgconfasia2016 lt ssd2gpu
by
Kohei KaiGai
PL/CUDA - Fusion of HPC Grade Power with In-Database Analytics
by
Kohei KaiGai
20170310_InDatabaseAnalytics_#1
by
Kohei KaiGai
SQL+GPU+SSD=∞ (Japanese)
by
Kohei KaiGai
20170127 JAWS HPC-UG#8
by
Kohei KaiGai
An Intelligent Storage?
by
Kohei KaiGai
20210731_OSC_Kyoto_PGStrom3.0
by
Kohei KaiGai
TPC-DSから学ぶPostgreSQLの弱点と今後の展望
by
Kohei KaiGai
What's hot
PDF
(JP) GPGPUがPostgreSQLを加速する
by
Kohei KaiGai
PDF
20210511_PGStrom_GpuCache
by
Kohei KaiGai
PDF
並列クエリを実行するPostgreSQLのアーキテクチャ
by
Kohei KaiGai
PDF
20200828_OSCKyoto_Online
by
Kohei KaiGai
PDF
20190418_PGStrom_on_ArrowFdw
by
Kohei KaiGai
PDF
20171220_hbstudy80_pgstrom
by
Kohei KaiGai
PDF
SSDとGPUがPostgreSQLを加速する【OSC.Enterprise】
by
Kohei KaiGai
PDF
20171212_GTCJapan_InceptionSummt_HeteroDB
by
Kohei KaiGai
PDF
20170726 py data.tokyo
by
ManaMurakami1
PDF
20180217 FPGA Extreme Computing #10
by
Kohei KaiGai
PDF
20200806_PGStrom_PostGIS_GstoreFdw
by
Kohei KaiGai
PDF
[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...
by
Insight Technology, Inc.
PDF
20191115-PGconf.Japan
by
Kohei KaiGai
PDF
Cuda
by
Shumpei Hozumi
PDF
20211112_jpugcon_gpu_and_arrow
by
Kohei KaiGai
PDF
20181211 - PGconf.ASIA - NVMESSD&GPU for BigData
by
Kohei KaiGai
PDF
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
PDF
NVIDIA TESLA V100・CUDA 9 のご紹介
by
NVIDIA Japan
PDF
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
PDF
CUDAプログラミング入門
by
NVIDIA Japan
(JP) GPGPUがPostgreSQLを加速する
by
Kohei KaiGai
20210511_PGStrom_GpuCache
by
Kohei KaiGai
並列クエリを実行するPostgreSQLのアーキテクチャ
by
Kohei KaiGai
20200828_OSCKyoto_Online
by
Kohei KaiGai
20190418_PGStrom_on_ArrowFdw
by
Kohei KaiGai
20171220_hbstudy80_pgstrom
by
Kohei KaiGai
SSDとGPUがPostgreSQLを加速する【OSC.Enterprise】
by
Kohei KaiGai
20171212_GTCJapan_InceptionSummt_HeteroDB
by
Kohei KaiGai
20170726 py data.tokyo
by
ManaMurakami1
20180217 FPGA Extreme Computing #10
by
Kohei KaiGai
20200806_PGStrom_PostGIS_GstoreFdw
by
Kohei KaiGai
[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...
by
Insight Technology, Inc.
20191115-PGconf.Japan
by
Kohei KaiGai
Cuda
by
Shumpei Hozumi
20211112_jpugcon_gpu_and_arrow
by
Kohei KaiGai
20181211 - PGconf.ASIA - NVMESSD&GPU for BigData
by
Kohei KaiGai
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
NVIDIA TESLA V100・CUDA 9 のご紹介
by
NVIDIA Japan
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
CUDAプログラミング入門
by
NVIDIA Japan
Similar to 20170329_BigData基盤研究会#7
PDF
20180920_DBTS_PGStrom_JP
by
Kohei KaiGai
PDF
20221116_DBTS_PGStrom_History
by
Kohei KaiGai
PDF
20190925_DBTS_PGStrom
by
Kohei KaiGai
PDF
20191211_Apache_Arrow_Meetup_Tokyo
by
Kohei KaiGai
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PDF
20180914 GTCJ INCEPTION HeteroDB
by
Kohei KaiGai
PDF
20190516_DLC10_PGStrom
by
Kohei KaiGai
PPTX
爆速!DBチューニング超入門 〜DB性能の基礎とPG-Stromによる高速化〜 OSC2024 Online/Fall版
by
Toru Miyahara
PDF
[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...
by
Insight Technology, Inc.
PDF
The Digital Experiences with Postgresql in Taiwan
by
José Lin
PPTX
爆速DB「PG-Strom」について 『PG-Strom v5リリース記念 GPUを活用したビッグデータ分析基盤を構築しよう」』
by
VirtualTech Japan Inc./Begi.net Inc.
PPTX
爆速!DBチューニング超入門 〜DB性能の基礎とPG-Stromによる高速化〜 2025/2/21
by
VirtualTech Japan Inc./Begi.net Inc.
PDF
PL/CUDA - GPU Accelerated In-Database Analytics
by
Kohei KaiGai
PDF
PostgreSQLによるデータ分析ことはじめ
by
Ohyama Masanori
PDF
JTF2021w F3 postgresql frontline
by
Haruka Takatsuka
PDF
[B32] クイズと都市伝説から見る、ありのままのPostgreSQL by Shigeyuki Tokuhara
by
Insight Technology, Inc.
PPTX
MySQLメインの人がPostgreSQLのベンチマークをしてみた話
by
hiroi10
PDF
20201113_PGconf_Japan_GPU_PostGIS
by
Kohei KaiGai
PDF
[db tech showcase Tokyo 2016] D13: NVMeフラッシュストレージを用いた高性能高拡張高可用なデータベースシステムの実現方...
by
Insight Technology, Inc.
PDF
20220331_DSSA_MigrationToYugabyteDB
by
Masaki Yamakawa
20180920_DBTS_PGStrom_JP
by
Kohei KaiGai
20221116_DBTS_PGStrom_History
by
Kohei KaiGai
20190925_DBTS_PGStrom
by
Kohei KaiGai
20191211_Apache_Arrow_Meetup_Tokyo
by
Kohei KaiGai
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
20180914 GTCJ INCEPTION HeteroDB
by
Kohei KaiGai
20190516_DLC10_PGStrom
by
Kohei KaiGai
爆速!DBチューニング超入門 〜DB性能の基礎とPG-Stromによる高速化〜 OSC2024 Online/Fall版
by
Toru Miyahara
[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...
by
Insight Technology, Inc.
The Digital Experiences with Postgresql in Taiwan
by
José Lin
爆速DB「PG-Strom」について 『PG-Strom v5リリース記念 GPUを活用したビッグデータ分析基盤を構築しよう」』
by
VirtualTech Japan Inc./Begi.net Inc.
爆速!DBチューニング超入門 〜DB性能の基礎とPG-Stromによる高速化〜 2025/2/21
by
VirtualTech Japan Inc./Begi.net Inc.
PL/CUDA - GPU Accelerated In-Database Analytics
by
Kohei KaiGai
PostgreSQLによるデータ分析ことはじめ
by
Ohyama Masanori
JTF2021w F3 postgresql frontline
by
Haruka Takatsuka
[B32] クイズと都市伝説から見る、ありのままのPostgreSQL by Shigeyuki Tokuhara
by
Insight Technology, Inc.
MySQLメインの人がPostgreSQLのベンチマークをしてみた話
by
hiroi10
20201113_PGconf_Japan_GPU_PostGIS
by
Kohei KaiGai
[db tech showcase Tokyo 2016] D13: NVMeフラッシュストレージを用いた高性能高拡張高可用なデータベースシステムの実現方...
by
Insight Technology, Inc.
20220331_DSSA_MigrationToYugabyteDB
by
Masaki Yamakawa
More from Kohei KaiGai
PDF
20221111_JPUG_CustomScan_API
by
Kohei KaiGai
PDF
20210928_pgunconf_hll_count
by
Kohei KaiGai
PDF
20210301_PGconf_Online_GPU_PostGIS_GiST_Index
by
Kohei KaiGai
PDF
20201128_OSC_Fukuoka_Online_GPUPostGIS
by
Kohei KaiGai
PDF
20201006_PGconf_Online_Large_Data_Processing
by
Kohei KaiGai
PDF
20200424_Writable_Arrow_Fdw
by
Kohei KaiGai
PDF
20190926_Try_RHEL8_NVMEoF_Beta
by
Kohei KaiGai
PDF
20190909_PGconf.ASIA_KaiGai
by
Kohei KaiGai
PDF
20181212 - PGconfASIA - LT - English
by
Kohei KaiGai
PDF
20181212 - PGconf.ASIA - LT
by
Kohei KaiGai
PDF
20181210 - PGconf.ASIA Unconference
by
Kohei KaiGai
PDF
20181116 Massive Log Processing using I/O optimized PostgreSQL
by
Kohei KaiGai
PDF
20181016_pgconfeu_ssd2gpu_multi
by
Kohei KaiGai
PDF
20181025_pgconfeu_lt_gstorefdw
by
Kohei KaiGai
PDF
20180920_DBTS_PGStrom_EN
by
Kohei KaiGai
20221111_JPUG_CustomScan_API
by
Kohei KaiGai
20210928_pgunconf_hll_count
by
Kohei KaiGai
20210301_PGconf_Online_GPU_PostGIS_GiST_Index
by
Kohei KaiGai
20201128_OSC_Fukuoka_Online_GPUPostGIS
by
Kohei KaiGai
20201006_PGconf_Online_Large_Data_Processing
by
Kohei KaiGai
20200424_Writable_Arrow_Fdw
by
Kohei KaiGai
20190926_Try_RHEL8_NVMEoF_Beta
by
Kohei KaiGai
20190909_PGconf.ASIA_KaiGai
by
Kohei KaiGai
20181212 - PGconfASIA - LT - English
by
Kohei KaiGai
20181212 - PGconf.ASIA - LT
by
Kohei KaiGai
20181210 - PGconf.ASIA Unconference
by
Kohei KaiGai
20181116 Massive Log Processing using I/O optimized PostgreSQL
by
Kohei KaiGai
20181016_pgconfeu_ssd2gpu_multi
by
Kohei KaiGai
20181025_pgconfeu_lt_gstorefdw
by
Kohei KaiGai
20180920_DBTS_PGStrom_EN
by
Kohei KaiGai
20170329_BigData基盤研究会#7
1.
GPU/SSDがPostgreSQLを加速する ~ハードウェア性能を限界まで引き出すPG-Stromの挑戦~ The PG-Strom Development
Team 海外 浩平 <kaigai@kaigai.gr.jp> / @kkaigai
2.
The PG-Strom Project 自己紹介 BigData基盤研究会#7
- GPU/SSDがPostgreSQLを加速する2 ▌海外 浩平 (KaiGai Kohei) Tw: @kkaigai https://github.com/kaigai ▌PostgreSQL開発 (2006~) SELinux対応、FDW機能強化、 CustomScan-Interface、etc... ▌PG-Strom開発 (2012~) GPUを用いたPostgreSQL向け 解析系クエリ高速化モジュール PG-Stromの設計目標: ヘテロジニアスなハードウェアの能力を最大限に引き出し、 高度なデータ解析能力を手軽に使えるようにする。
3.
The PG-Strom ProjectBigData基盤研究会#7
- GPU/SSDがPostgreSQLを加速する3 SQLアクセラレータとしてのGPU
4.
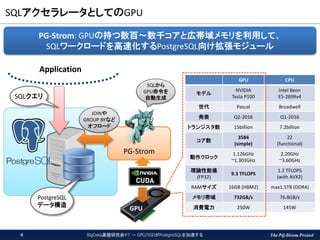
The PG-Strom Project PG-Strom SQLアクセラレータとしてのGPU Application GPU JOINや GROUP
BYなど オフロード SQLから GPU命令を 自動生成 PG-Strom: GPUの持つ数百~数千コアと広帯域メモリを利用して、 SQLワークロードを高速化するPostgreSQL向け拡張モジュール SQLクエリ PostgreSQL データ構造 GPU CPU モデル NVIDIA Tesla P100 Intel Xeon E5-2699v4 世代 Pascal Broadwell 発表 Q2-2016 Q1-2016 トランジスタ数 15billion 7.2billion コア数 3584 (simple) 22 (functional) 動作クロック 1.126GHz ~1.303GHz 2.20GHz ~3.60GHz 理論性能値 (FP32) 9.3 TFLOPS 1.2 TFLOPS (with AVX2) RAMサイズ 16GB (HBM2) max1.5TB (DDR4) メモリ帯域 732GB/s 76.8GB/s 消費電力 250W 145W BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する4
5.
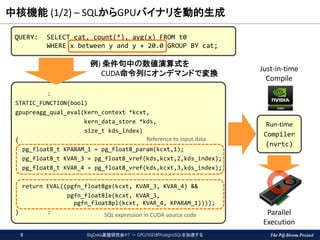
The PG-Strom Project 中核機能
(1/2) – SQLからGPUバイナリを動的生成 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する5 QUERY: SELECT cat, count(*), avg(x) FROM t0 WHERE x between y and y + 20.0 GROUP BY cat; : STATIC_FUNCTION(bool) gpupreagg_qual_eval(kern_context *kcxt, kern_data_store *kds, size_t kds_index) { pg_float8_t KPARAM_1 = pg_float8_param(kcxt,1); pg_float8_t KVAR_3 = pg_float8_vref(kds,kcxt,2,kds_index); pg_float8_t KVAR_4 = pg_float8_vref(kds,kcxt,3,kds_index); return EVAL((pgfn_float8ge(kcxt, KVAR_3, KVAR_4) && pgfn_float8le(kcxt, KVAR_3, pgfn_float8pl(kcxt, KVAR_4, KPARAM_1)))); } : 例) 条件句中の数値演算式を CUDA命令列にオンデマンドで変換 Reference to input data SQL expression in CUDA source code Run-time Compiler (nvrtc) Just-in-time Compile Parallel Execution
6.
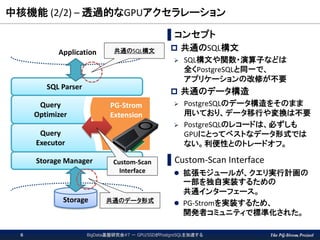
The PG-Strom Project 中核機能
(2/2) – 透過的なGPUアクセラレーション ▌コンセプト 共通のSQL構文 SQL構文や関数・演算子などは 全くPostgreSQLと同一で、 アプリケーションの改修が不要 共通のデータ構造 PostgreSQLのデータ構造をそのまま 用いており、データ移行や変換は不要 PostgreSQLのレコードは、必ずしも GPUにとってベストなデータ形式では ない。利便性とのトレードオフ。 ▌Custom-Scan Interface 拡張モジュールが、クエリ実行計画の 一部を独自実装するための 共通インターフェース。 PG-Stromを実装するため、 開発者コミュニティで標準化された。 Query Optimizer Query Executor PG-Strom Extension Storage Manager SQL Parser Application Storage 共通のSQL構文 共通のデータ形式 Custom-Scan Interface BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する6
7.
The PG-Strom Project GPUによるSQL実行高速化の一例 BigData基盤研究会#7
- GPU/SSDがPostgreSQLを加速する7 ▌Test Query: SELECT cat, count(*), avg(x) FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ..., ...] GROUP BY cat; t0 contains 100M rows, t1...t8 contains 100K rows (similar to star schema) 40.44 62.79 79.82 100.50 119.51 144.55 201.12 248.95 9.96 9.93 9.96 9.99 10.02 10.03 9.98 10.00 0 50 100 150 200 250 300 2 3 4 5 6 7 8 9 QueryResponseTime[sec] Number of joined tables PG-Strom microbenchmark with JOIN/GROUP BY PostgreSQL v9.5 PG-Strom v1.0 CPU: Xeon E5-2670v3 GPU: GTX1080 RAM: 384GB OS: CentOS 7.2 DB: PostgreSQL 9.5 + PG-Strom v1.0
8.
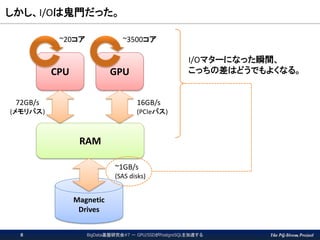
The PG-Strom Project しかし、I/Oは鬼門だった。 Magnetic Drives RAM CPU
GPU 16GB/s (PCIeバス) 72GB/s (メモリバス) ~1GB/s (SAS disks) ~3500コア~20コア I/Oマターになった瞬間、 こっちの差はどうでもよくなる。 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する8
9.
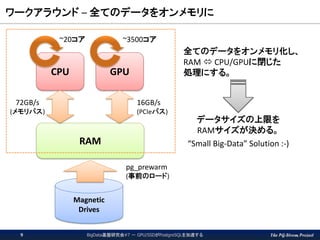
The PG-Strom Project ワークアラウンド
– 全てのデータをオンメモリに Magnetic Drives RAM CPU GPU 16GB/s (PCIeバス) 72GB/s (メモリバス) pg_prewarm (事前のロード) ~3500コア~20コア 全てのデータをオンメモリ化し、 RAM CPU/GPUに閉じた 処理にする。 データサイズの上限を RAMサイズが決める。 “Small Big-Data” Solution :-) BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する9
10.
The PG-Strom Project SSD-to-GPU
P2P DMAへ BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する10
11.
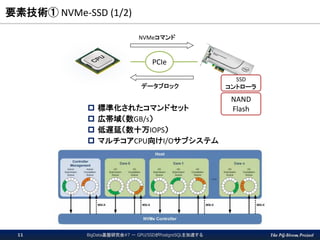
The PG-Strom Project 要素技術①
NVMe-SSD (1/2) 標準化されたコマンドセット 広帯域(数GB/s) 低遅延(数十万IOPS) マルチコアCPU向けI/Oサブシステム PCIe SSD コントローラ NAND Flash NVMeコマンド データブロック BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する11
12.
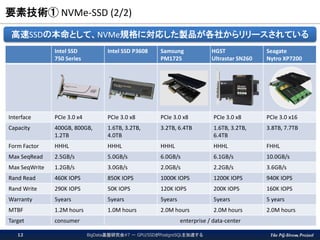
The PG-Strom Project 要素技術①
NVMe-SSD (2/2) BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する12 Intel SSD 750 Series Intel SSD P3608 Samsung PM1725 HGST Ultrastar SN260 Seagate Nytro XP7200 Interface PCIe 3.0 x4 PCIe 3.0 x8 PCIe 3.0 x8 PCIe 3.0 x8 PCIe 3.0 x16 Capacity 400GB, 800GB, 1.2TB 1.6TB, 3.2TB, 4.0TB 3.2TB, 6.4TB 1.6TB, 3.2TB, 6.4TB 3.8TB, 7.7TB Form Factor HHHL HHHL HHHL HHHL FHHL Max SeqRead 2.5GB/s 5.0GB/s 6.0GB/s 6.1GB/s 10.0GB/s Max SeqWrite 1.2GB/s 3.0GB/s 2.0GB/s 2.2GB/s 3.6GB/s Rand Read 460K IOPS 850K IOPS 1000K IOPS 1200K IOPS 940K IOPS Rand Write 290K IOPS 50K IOPS 120K IOPS 200K IOPS 160K IOPS Warranty 5years 5years 5years 5years 5 years MTBF 1.2M hours 1.0M hours 2.0M hours 2.0M hours 2.0M hours Target consumer enterprise / data-center 高速SSDの本命として、NVMe規格に対応した製品が各社からリリースされている
13.
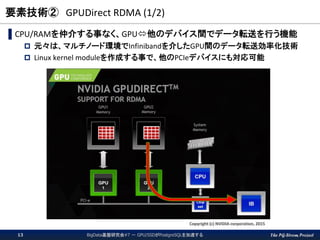
The PG-Strom Project 要素技術②
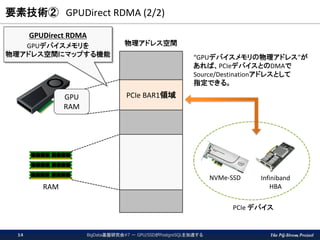
GPUDirect RDMA (1/2) ▌CPU/RAMを仲介する事なく、GPU他のデバイス間でデータ転送を行う機能 元々は、マルチノード環境でInfinibandを介したGPU間のデータ転送効率化技術 Linux kernel moduleを作成する事で、他のPCIeデバイスにも対応可能 Copyright (c) NVIDIA corporation, 2015 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する13
14.
The PG-Strom Project 要素技術②
GPUDirect RDMA (2/2) 物理アドレス空間 PCIe BAR1領域GPU RAM RAM NVMe-SSD Infiniband HBA PCIe デバイス GPUDirect RDMA GPUデバイスメモリを 物理アドレス空間にマップする機能 “GPUデバイスメモリの物理アドレス”が あれば、PCIeデバイスとのDMAで Source/Destinationアドレスとして 指定できる。 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する14
15.
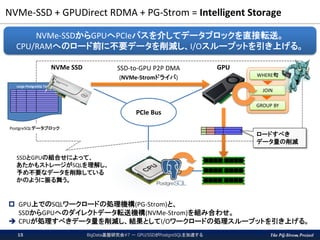
The PG-Strom Project NVMe-SSD
+ GPUDirect RDMA + PG-Strom = Intelligent Storage BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する15 GPU上でのSQLワークロードの処理機構(PG-Strom)と、 SSDからGPUへのダイレクトデータ転送機構(NVMe-Strom)を組み合わせ。 CPUが処理すべきデータ量を削減し、結果としてI/Oワークロードの処理スループットを引き上げる。 NVMe-SSDからGPUへPCIeバスを介してデータブロックを直接転送。 CPU/RAMへのロード前に不要データを削減し、I/Oスループットを引き上げる。 Large PostgreSQL Tables PCIe Bus NVMe SSD GPUSSD-to-GPU P2P DMA (NVMe-Stromドライバ) WHERE句 JOIN GROUP BY PostgreSQLデータブロック ロードすべき データ量の削減 SSDとGPUの組合せによって、 あたかもストレージがSQLを理解し、 予め不要なデータを削除している かのように振る舞う。
16.
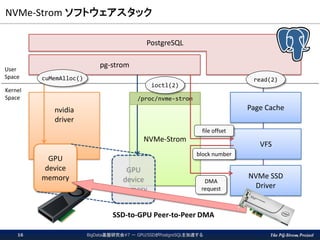
The PG-Strom Project NVMe-Strom
ソフトウェアスタック BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する16 pg-strom NVMe-Strom VFS Page Cache NVMe SSD Driver nvidia driver GPU device memory GPU device memory PostgreSQL file offset DMA request block number SSD-to-GPU Peer-to-Peer DMA cuMemAlloc() /proc/nvme-strom ioctl(2) read(2) User Space Kernel Space
17.
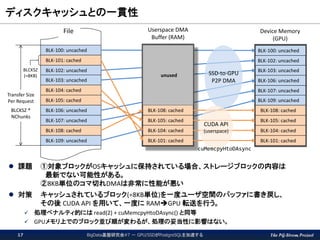
The PG-Strom Project ディスクキャッシュとの一貫性 BigData基盤研究会#7
- GPU/SSDがPostgreSQLを加速する17 課題 ①対象ブロックがOSキャッシュに保持されている場合、ストレージブロックの内容は 最新でない可能性がある。 ②8KB単位のコマ切れDMAは非常に性能が悪い 対策 キャッシュされているブロック(=8KB単位)を一度ユーザ空間のバッファに書き戻し、 その後 CUDA API を用いて、一度に RAMGPU 転送を行う。 処理ペナルティ的には read(2) + cuMemcpyHtoDAsync() と同等 GPUメモリ上でのブロック並び順が変わるが、処理の妥当性に影響はない。 BLK-100: uncached BLK-101: cached BLK-102: uncached BLK-103: uncached BLK-104: cached BLK-105: cached BLK-106: uncached BLK-107: uncached BLK-108: cached BLK-109: uncached BLCKSZ (=8KB) Transfer Size Per Request BLCKSZ * NChunks BLK-108: cached BLK-105: cached BLK-104: cached BLK-101: cached BLK-100: uncached BLK-102: uncached BLK-103: uncached BLK-106: uncached BLK-107: uncached BLK-109: uncached BLK-108: cached BLK-105: cached BLK-104: cached BLK-101: cached unused SSD-to-GPU P2P DMA File Userspace DMA Buffer (RAM) Device Memory (GPU) CUDA API (userspace) cuMemcpyHtoDAsync
18.
The PG-Strom Project ベンチマーク
(1/3) – 測定環境 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する18 CPU2CPU1 SSD x2 Tesla K80 GPU Tesla K20 GPU (未使用) ▌サーバスペック/SW構成 Model: DELL PowerEdge R730 CPU: Xeon E5-2670v3 (12C, 2.3GHz) x2 RAM: 384GB (うち128GBのみ使用) HDD: SAS 300GB x8 (RAID5) OS: CentOS7.2 (3.10.0-327.el7) SW: CUDA 7.5.17 NVIDIA driver 352.99 PostgreSQL 9.6.1 PG-Strom v2.0devel ▌GPUスペック NVIDIA Tesla K80 2x 2496 CUDA cores (560MHz) 2x 12GB GDDR5 RAM (240GB/s) ▌SSDスペック Intel SSD 750 (400GB) x2 Interface: PCIe 3.0 x4 (NVMe 1.2) Max SeqRead: 2.2GB/s
19.
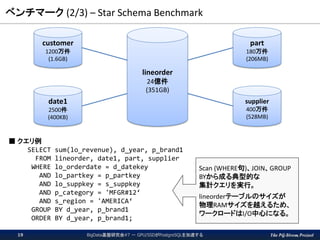
The PG-Strom Project ベンチマーク
(2/3) – Star Schema Benchmark BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する19 ■ クエリ例 SELECT sum(lo_revenue), d_year, p_brand1 FROM lineorder, date1, part, supplier WHERE lo_orderdate = d_datekey AND lo_partkey = p_partkey AND lo_suppkey = s_suppkey AND p_category = 'MFGR#12‘ AND s_region = 'AMERICA‘ GROUP BY d_year, p_brand1 ORDER BY d_year, p_brand1; customer 1200万件 (1.6GB) date1 2500件 (400KB) part 180万件 (206MB) supplier 400万件 (528MB) lineorder 24億件 (351GB) Scan (WHERE句)、JOIN、GROUP BYから成る典型的な 集計クエリを実行。 lineorderテーブルのサイズが 物理RAMサイズを越えるため、 ワークロードはI/O中心になる。
20.
The PG-Strom Project ベンチマーク
(3/3) – データ集計SQL/処理スループット 0 500 1000 1500 2000 2500 3000 3500 4000 4500 Q1-1 Q1-2 Q1-3 Q2-1 Q2-2 Q2-3 Q3-1 Q3-2 Q3-3 Q3-4 Q4-1 Q4-2 Q4-3 クエリ処理スループット[MB/s] PostgreSQL SSDx1 PostgreSQL SSDx2 PG-Strom SSDx1 PG-Strom SSDx2 DBサイズ353GBに対し、WHERE句、JOIN、集約/GROUP BY処理を実行。I/Oが支配的なワークロード。 SSD2枚のケース:PostgreSQLは1.6GB/s程度で頭打ちだが、PG-Stromは現状でも3.8GB/sの処理能力を達成。 SSDドライバやSQL実装の改善で、処理スループットの理論限界値 (SSD2枚で 4.4GB/s)を目指す。 HW) CPU: Xeon E5-2670v3, GPU: NVIDIA Tesla K80, RAM: 128GB, SSD: Intel SSD 750(400GB) x2 SW) OS: CentOS7, CUDA7.5, PostgreSQL 9.6.1, PG-Strom 2.0devel SSD x1枚構成の 理論限界値 [2.2GB/s] SSD x2枚構成の 理論限界値 [4.4GB/s] 調査中 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する20
21.
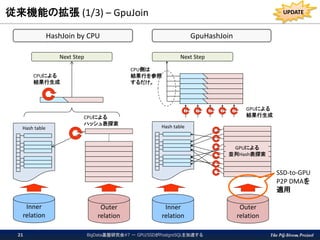
The PG-Strom Project 従来機能の拡張
(1/3) – GpuJoin BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する21 Inner relation Outer relation Inner relation Outer relation Hash table Hash table Next Step Next Step CPU側は 結果行を参照 するだけ。 CPUによる ハッシュ表探索 CPUによる 結果行生成 GPUによる 結果行生成 GPUによる 並列Hash表探索 HashJoin by CPU GpuHashJoin SSD-to-GPU P2P DMAを 適用 UPDATE
22.
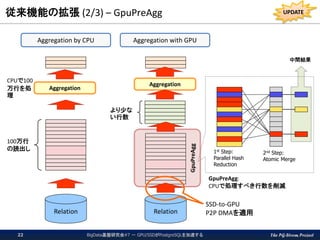
The PG-Strom Project GpuPreAgg 従来機能の拡張
(2/3) – GpuPreAgg BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する22 Aggregation by CPU Aggregation with GPU Relation Relation Aggregation Aggregation 1st Step: Parallel Hash Reduction 2nd Step: Atomic Merge 100万行 の読出し CPUで100 万行を処 理 より少な い行数 GpuPreAgg: CPUで処理すべき行数を削減 中間結果 SSD-to-GPU P2P DMAを適用 UPDATE
23.
The PG-Strom Project 従来機能の拡張
(3/3) – EXPLAINで確認 nvme=# EXPLAIN SELECT sum(lo_extendedprice*lo_discount) as revenue FROM lineorder,date1 WHERE lo_orderdate = d_datekey AND d_year = 1993 AND lo_discount BETWEEN 1 AND 3 AND lo_quantity < 25; QUERY PLAN ---------------------------------------------------------------------------------------------------- Aggregate (cost=32629401.85..32629401.86 rows=1 width=32) -> Custom Scan (GpuPreAgg) (cost=32629397.25..32629400.31 rows=204 width=32) Reduction: NoGroup GPU Projection: pgstrom.psum((lo_extendedprice * lo_discount)) Features: outer-bulk-exec, output-slot-format -> Custom Scan (GpuJoin) on lineorder (cost=6569.11..32597251.98 rows=45032443 width=10) GPU Projection: lineorder.lo_extendedprice, lineorder.lo_discount Outer Scan: lineorder (cost=6715.83..35072613.81 rows=315350477 width=14) Outer Scan Filter: ((lo_discount >= '1'::numeric) AND (lo_discount <= '3'::numeric) AND (lo_quantity < '25'::numeric)) Depth 1: GpuHashJoin (nrows 315350477...45032443) HashKeys: lineorder.lo_orderdate JoinQuals: (lineorder.lo_orderdate = date1.d_datekey) KDS-Hash (size: 0B, nbatched: 1) Features: output-row-format, nvme-strom -> Seq Scan on date1 (cost=0.00..78.95 rows=365 width=4) Filter: (d_year = 1993) (16 rows) BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する23 UPDATE
24.
The PG-Strom Project PG-Strom
v2.0 開発状況 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する24 •GPUデバイスメモリのホストマッピングと、SSD-to-GPU P2P DMA要求の発行 ① NVMe-Strom: 基本機能の実証 •PostgreSQL v9.6のCPU並列 (Partial Scan) 対応 •GpuScanへのNVMe-Stromモードの追加 ② PG-Strom: GpuScan + NVMe-Stromの統合 •PostgreSQL v9.6の新オプティマイザへの対応 •GpuJoin/GpuPreAggの直接スキャンモードでのNVMe-Stromの使用 ③ PG-Strom: JOIN/GROUP BY対応 •ソフトウェアRAID-0区画に対するストライピングREAD機能のサポート ④ NVMe-Strom: MD RAID-0対応 •テスト、テスト、デバッグ、改善、、、 ⑤ 品質改善・安定化 / Quality improvement and stabilization ⑥ PG-Strom v2.0!! (2017/2Q~3Q) 現在のステータス
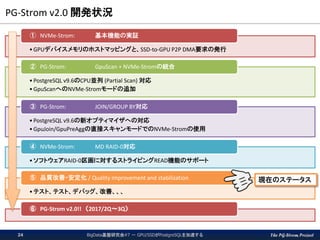
25.
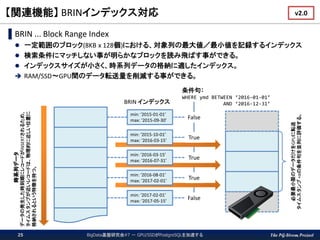
The PG-Strom Project 【関連機能】
BRINインデックス対応 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する25 ▌BRIN ... Block Range Index 一定範囲のブロック(8KB x 128個)における、対象列の最大値/最小値を記録するインデックス 検索条件にマッチしない事が明らかなブロックを読み飛ばす事ができる。 インデックスサイズが小さく、時系列データの格納に適したインデックス。 RAM/SSD~GPU間のデータ転送量を削減する事ができる。 時系列データ データの発生した時刻順にレコードがINSERTされるため、 タイムスタンプが近いレコードは、物理的に近しい位置に 格納されるという特徴を持つ。 BRIN インデックス 条件句: WHERE ymd BETWEEN ‘2016-01-01’ AND ‘2016-12-31’ False True True True False min: ‘2015-01-01’ max: ‘2015-09-30’ min: ‘2015-10-01’ max: ‘2016-03-15’ min: ‘2016-03-15’ max: ‘2016-07-31’ min: ‘2016-08-01’ max: ‘2017-02-01’ min: ‘2017-02-01’ max: ‘2017-05-15’ 必要最小限のデータだけをGPUに転送 タイムスタンプ+αの条件句を並列に評価する。 v2.0
26.
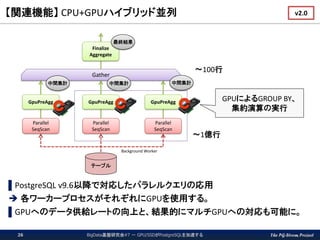
The PG-Strom Project 【関連機能】
CPU+GPUハイブリッド並列 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する26 ▌PostgreSQL v9.6以降で対応したパラレルクエリの応用 各ワーカープロセスがそれぞれにGPUを使用する。 ▌GPUへのデータ供給レートの向上と、結果的にマルチGPUへの対応も可能に。 Parallel SeqScan GpuPreAgg Gather Background Worker Parallel SeqScan GpuPreAgg Parallel SeqScan GpuPreAgg Finalize Aggregate テーブル 中間集計 中間集計 中間集計 最終結果 GPUによるGROUP BY、 集約演算の実行 ~1億行 ~100行 v2.0
27.
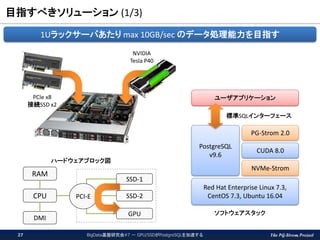
The PG-Strom Project 目指すべきソリューション
(1/3) BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する27 PCIe x8 接続SSD x2 NVIDIA Tesla P40 CPU RAM DMI SSD-1 SSD-2 GPU 1Uラックサーバあたり max 10GB/sec のデータ処理能力を目指す PCI-E ハードウェアブロック図 ソフトウェアスタック Red Hat Enterprise Linux 7.3, CentOS 7.3, Ubuntu 16.04 NVMe-Strom CUDA 8.0 PostgreSQL v9.6 PG-Strom 2.0 ユーザアプリケーション 標準SQLインターフェース
28.
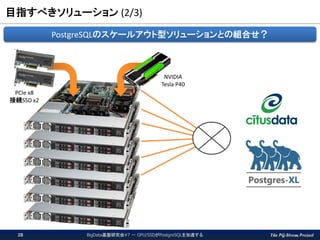
The PG-Strom Project 目指すべきソリューション
(2/3) BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する28 PCIe x8 接続SSD x2 NVIDIA Tesla P40 PostgreSQLのスケールアウト型ソリューションとの組合せ?
29.
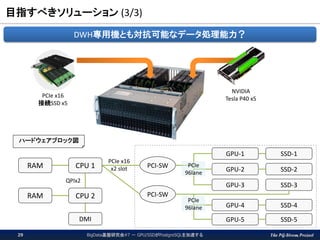
The PG-Strom Project 目指すべきソリューション
(3/3) BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する29 PCIe x16 接続SSD x5 NVIDIA Tesla P40 x5 ハードウェアブロック図 DMI GPU-1 PCI-SW PCI-SW QPIx2 GPU-2 GPU-4 GPU-5 SSD-1 SSD-2 SSD-3 SSD-4 SSD-5 GPU-3 RAM RAM CPU 1 CPU 2 PCIe x16 x2 slot PCIe 96lane PCIe 96lane DWH専用機とも対抗可能なデータ処理能力?
30.
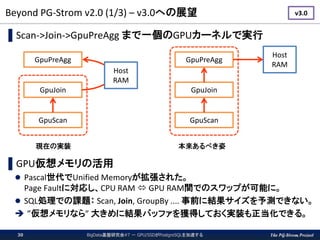
The PG-Strom Project Beyond
PG-Strom v2.0 (1/3) – v3.0への展望 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する30 ▌Scan->Join->GpuPreAgg まで一個のGPUカーネルで実行 ▌GPU仮想メモリの活用 Pascal世代でUnified Memoryが拡張された。 Page Faultに対応し、CPU RAM GPU RAM間でのスワップが可能に。 SQL処理での課題: Scan, Join, GroupBy .... 事前に結果サイズを予測できない。 ”仮想メモリなら” 大きめに結果バッファを獲得しておく実装も正当化できる。 v3.0 GpuPreAgg GpuJoin GpuScan Host RAM GpuPreAgg GpuJoin GpuScan Host RAM 本来あるべき姿現在の実装
31.
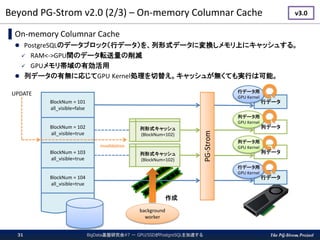
The PG-Strom Project Beyond
PG-Strom v2.0 (2/3) – On-memory Columnar Cache BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する31 ▌On-memory Columnar Cache PostgreSQLのデータブロック(行データ)を、列形式データに変換しメモリ上にキャッシュする。 RAM<->GPU間のデータ転送量の削減 GPUメモリ帯域の有効活用 列データの有無に応じてGPU Kernel処理を切替え。キャッシュが無くても実行は可能。 BlockNum = 101 all_visible=false BlockNum = 102 all_visible=true BlockNum = 103 all_visible=true BlockNum = 104 all_visible=true 列形式キャッシュ (BlockNum=102) 列形式キャッシュ (BlockNum=102) background worker 作成 UPDATE invalidation PG-Strom 行データ 行データ用 GPU Kernel 列データ 列データ用 GPU Kernel 行データ 行データ用 GPU Kernel 列データ 列データ用 GPU Kernel v3.0
32.
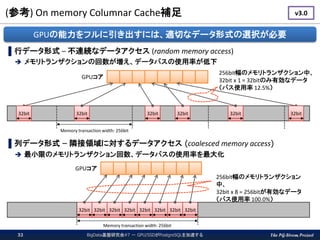
The PG-Strom Project (参考)
On memory Columnar Cache補足 BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する32 ▌行データ形式 – 不連続なデータアクセス (random memory access) メモリトランザクションの回数が増え、データバスの使用率が低下 ▌列データ形式 – 隣接領域に対するデータアクセス (coalesced memory access) 最小限のメモリトランザクション回数、データバスの使用率を最大化 32bit Memory transaction width: 256bit 32bit 32bit32bit 32bit 32bit 32bit 32bit 32bit 32bit 32bit 32bit 32bit 32bit Memory transaction width: 256bit 256bit幅のメモリトランザクション 中、 32bit x 8 = 256bitが有効なデータ (バス使用率 100.0%) 256bit幅のメモリトランザクション中、 32bit x 1 = 32bitのみ有効なデータ (バス使用率 12.5%) GPUコア GPUコア GPUの能力をフルに引き出すには、適切なデータ形式の選択が必要 v3.0
33.
The PG-Strom Project OLTPの世界
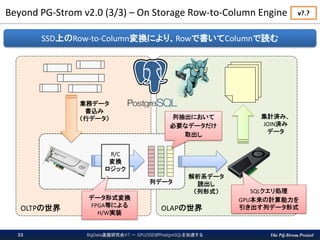
OLAPの世界 Beyond PG-Strom v2.0 (3/3) – On Storage Row-to-Column Engine BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する33 SSD上のRow-to-Column変換により、Rowで書いてColumnで読む R/C 変換 ロジック 列データ 解析系データ 読出し (列形式) 業務データ 書込み (行データ) データ形式変換 FPGA等による H/W実装 SQLクエリ処理 GPU本来の計算能力を 引き出す列データ形式 集計済み、 JOIN済み データ 列抽出において 必要なデータだけ 取出し v?.?
34.
The PG-Strom Project まとめ ▌PG-Strom
GPUを用いたPostgreSQLの検索高速化モジュール SQLからGPUプログラムを自動生成し、数千コアで並列実行 しかし、I/Oが鬼門だった。 ▌NVMe-Stom コンセプト: GPUでのSQL処理とGPUDirect RDMA機能の組合せにより、 ストレージブロックをCPU/RAMへロードするより前にデータ量を削減する。 CPUが捌かねばならないデータ量/レコード数を減らす。 プロトタイプ性能値: NVMe-SSD (SeqRead 2.2GB/s) x2台のmd-raid0構成で、 既にクエリ処理スループット3.8GB/sまで達成。 当面の目標は、単体ノード10GB/s級スループットの実現 対応ワークロード: WHERE句、JOIN、集約関数/GROUP BY BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する34
35.
The PG-Strom Project Resources ▌Repository
https://github.com/pg-strom/devel https://github.com/pg-strom/nvme-strom ▌Documentation http://strom.kaigai.gr.jp/manual.html ▌Ask me Tw: @kkaigai E-mail: kaigai@kaigai.gr.jp BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する35
36.
The PG-Strom ProjectBigData基盤研究会#7
- GPU/SSDがPostgreSQLを加速する36 Any Questions?
37.
Questions?
Download



![The PG-Strom Project
GPUによるSQL実行高速化の一例
BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する7
▌Test Query:
SELECT cat, count(*), avg(x)
FROM t0 NATURAL JOIN t1 [NATURAL JOIN t2 ..., ...]
GROUP BY cat;
t0 contains 100M rows, t1...t8 contains 100K rows (similar to star schema)
40.44
62.79
79.82
100.50
119.51
144.55
201.12
248.95
9.96 9.93 9.96 9.99 10.02 10.03 9.98 10.00
0
50
100
150
200
250
300
2 3 4 5 6 7 8 9
QueryResponseTime[sec]
Number of joined tables
PG-Strom microbenchmark with JOIN/GROUP BY
PostgreSQL v9.5 PG-Strom v1.0
CPU: Xeon E5-2670v3
GPU: GTX1080
RAM: 384GB
OS: CentOS 7.2
DB: PostgreSQL 9.5 +
PG-Strom v1.0](https://image.slidesharecdn.com/20170329pgstrom-170423125059/85/20170329_BigData-7-7-320.jpg)


![The PG-Strom Project
ベンチマーク (3/3) – データ集計SQL/処理スループット
0
500
1000
1500
2000
2500
3000
3500
4000
4500
Q1-1 Q1-2 Q1-3 Q2-1 Q2-2 Q2-3 Q3-1 Q3-2 Q3-3 Q3-4 Q4-1 Q4-2 Q4-3
クエリ処理スループット[MB/s]
PostgreSQL SSDx1 PostgreSQL SSDx2 PG-Strom SSDx1 PG-Strom SSDx2
DBサイズ353GBに対し、WHERE句、JOIN、集約/GROUP BY処理を実行。I/Oが支配的なワークロード。
SSD2枚のケース:PostgreSQLは1.6GB/s程度で頭打ちだが、PG-Stromは現状でも3.8GB/sの処理能力を達成。
SSDドライバやSQL実装の改善で、処理スループットの理論限界値 (SSD2枚で 4.4GB/s)を目指す。
HW) CPU: Xeon E5-2670v3, GPU: NVIDIA Tesla K80, RAM: 128GB, SSD: Intel SSD 750(400GB) x2
SW) OS: CentOS7, CUDA7.5, PostgreSQL 9.6.1, PG-Strom 2.0devel
SSD x1枚構成の
理論限界値 [2.2GB/s]
SSD x2枚構成の
理論限界値 [4.4GB/s]
調査中
BigData基盤研究会#7 - GPU/SSDがPostgreSQLを加速する20](https://image.slidesharecdn.com/20170329pgstrom-170423125059/85/20170329_BigData-7-20-320.jpg)
























![[20170922 Sapporo Tech Bar] 地図用データを高速処理!オープンソースGPUデータベースMapDってどんなもの?? by 株式会社...](https://cdn.slidesharecdn.com/ss_thumbnails/20170922mapd-170926064811-thumbnail.jpg?width=640&height=640&fit=bounds)




![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)











![[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b15postgresqlntt-oss-center-150619073139-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






![[B32] クイズと都市伝説から見る、ありのままのPostgreSQL by Shigeyuki Tokuhara](https://cdn.slidesharecdn.com/ss_thumbnails/b32-140630204144-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2016] D13: NVMeフラッシュストレージを用いた高性能高拡張高可用なデータベースシステムの実現方...](https://cdn.slidesharecdn.com/ss_thumbnails/efmcwyyftdwdehhr3b4y-signature-06a70abedb3d16e5e7bcb9b2ba8014302148552ca76b90497742e559ab641b61-poli-160726094411-thumbnail.jpg?width=640&height=640&fit=bounds)















