






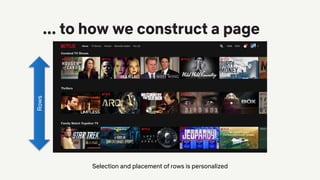
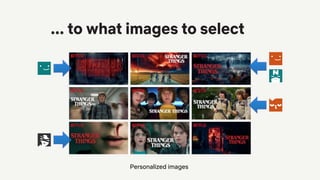
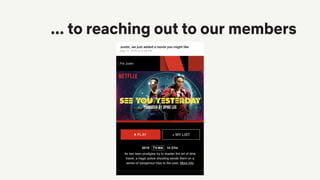
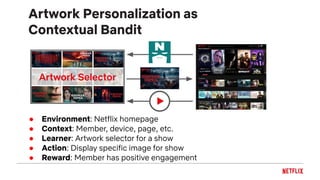
![Everything is a recommendation!
Over 80% of what
people watch
comes from our
recommendations
Overview in [Gomez-Uribe & Hunt, 2016]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-10-320.jpg)






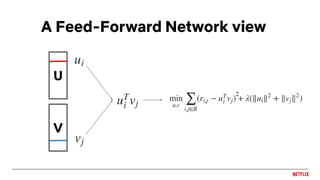
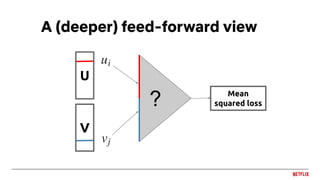
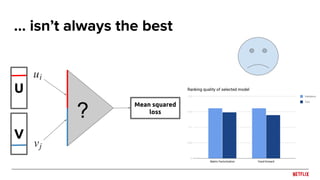
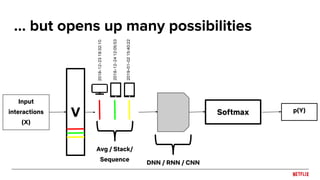
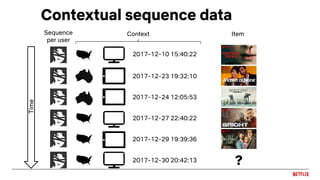
![Sequence prediction
● Treat recommendations as a
sequence classification problem
○ Input: sequence of user actions
○ Output: next action
● E.g. Gru4Rec [Hidasi et. al., 2016]
○ Input: sequence of items in a sessions
○ Output: next item in the session
● Also co-evolution: [Wu et al.,
2017], [Dai et al., 2017]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-22-320.jpg)
![Leveraging other data
● Example: YouTube Recommender
[Covington et. al., 2016]
● Two stage ranker: candidate
generation (shrinking set of items
to rank) and ranking (classifying
actual impressions)
● Two feed-forward, fully
connected, networks with
hundreds of features](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-23-320.jpg)

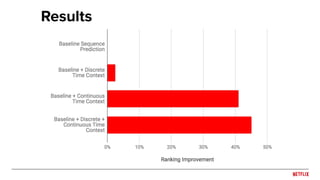

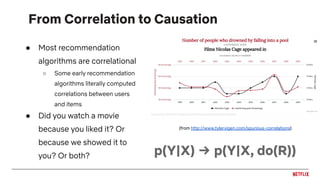
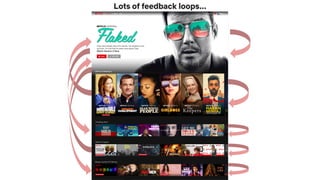
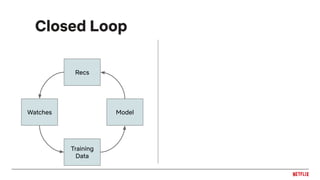
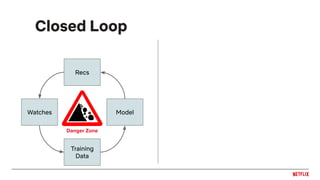
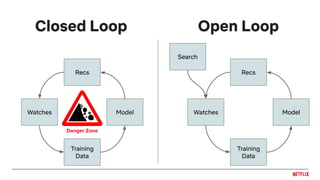
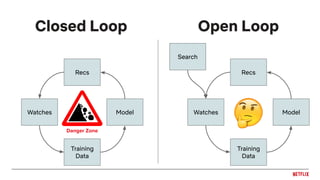
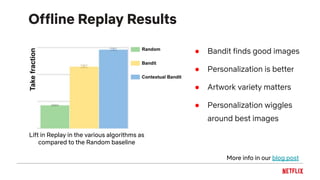
![Feedback loops
Impression bias
inflates plays
Leads to inflated
item popularity
More plays
More
impressions
Oscillations in
distribution of genre
recommendations
Feedback loops can cause biases to be
reinforced by the recommendation system!
[Chaney et al., 2018]: simulations showing that this can reduce the
usefulness of the system](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-29-320.jpg)
![Debiasing Recommendations
● IPS Estimator for MF [Schnabel et al., 2016]
○ Train a debiasing model and reweight the data
● Causal Embeddings [Bonner & Vasile, 2018]
○ Jointly learn debiasing model and task model
○ Regularize the two towards each other
● Doubly-Robust MF [Wang et al., 2019]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-35-320.jpg)

![● Uncertainty around user interests and new items
● Sparse and indirect feedback
● Changing trends
● Break feedback loops
● Want to explore to learn
Why contextual bandits for recommendations?
▶Early news example: [Li et al., 2010]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-37-320.jpg)
![Bart [McInerney et al., 2018]
● Bandit selecting both items and explanations for
Spotify homepage
● Factorization Machine with epsilon-greedy explore
over personalized candidate set
● Counterfactual risk minimization to train the bandit](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-38-320.jpg)



![List-wise [Zhao et al., 2017] or Page-wise recommendation [Zhao et al. 2018]
based on [Dulac-Arnold et al., 2016]
Embeddings for actions](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-44-320.jpg)
![● Generator to choose user action from recommendation
● Reward trained like a discriminator
● LSTM or Position-Weight architecture
● Learning over sets via cascading Deep Q Networks
○ Different Q function per position
GAN-inspired as a user simulator
[Chen et al., 2019]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-45-320.jpg)
![● Train candidate generator using
REINFORCE
● Exploration done using softmax with
temperature
● Off-policy correction with adaptation for
top-k recommendations
● Trust region policy optimization to keep
close to logging policy
Policy Gradient for YouTube
Recommendations [Chen et al., 2019]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-46-320.jpg)


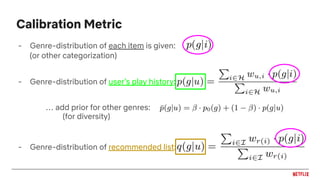
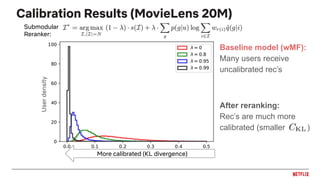
![Calibrated Recommendations [Steck, 2018]
● Fairness as matching distribution of user interests
● Accuracy as an objective can lead to unbalanced predictions
● Simple example:
● Many recommendation algorithms exhibit this behavior of exaggerating the
dominant interests and crowd out less frequent ones
30 action70 romance
30% action70% romance
User:
Expectation:
100% romanceReality: Maximizes accuracy](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-49-320.jpg)
![Fairness through Pairwise Comparisons
[Beutel et al., 2019]
● Recommendations are fair if likelihood of clicked item being ranked above
an unclicked item is the same across two groups
○ Intra-group pairwise accuracy - Restrict to pairs within group
○ Inter-group pairwise accuracy - Restrict to pairs between groups
● Training: Add pairwise regularizer based on randomized data to collect
fairness feedback](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-52-320.jpg)


![Page/Slate Optimization
● Select multiple actions that go together and
receive feedback on group
● Personalizing based on within-session
browsing behavior [Wu et al., 2015]
● Off-policy evaluation for slates
[Swaminathan, et al., 2016]
● Slate optimization as VAE [Jiang et al., 2019]
● Marginal posterior sampling for slate bandits
[Dimakopoulou et al., 2019]](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-55-320.jpg)

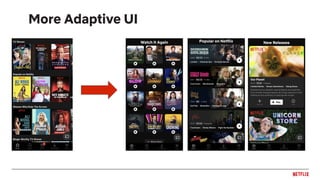
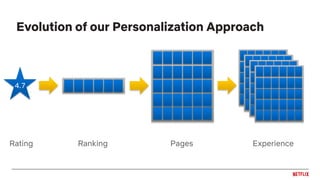

![Applications as tasks
● Many related personalization tasks in a
recommender system
● Examples:
○ [Zhao et al., 2015] - Outputs for different tasks
○ [Bansal et al., 2016] - Jointly learn to recommend
and predict metadata for items
○ [Ma et al., 2018] - Jointly learn watch and enjoy
○ [Lu et al., 2018] - Jointly learn for rating prediction
and explanation
○ [Hadash et al., 2018] - Jointly learn ranking and
rating prediction
User
history
Ranking
Page
Rating
Explanation
Search
Image
Context ...](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-60-320.jpg)
![Other views
● Users-as-tasks: Treat each user as a task and learn from others users
○ Example: [Ning & Karapis, 2010] finds similar users and does
support vector regression
● Items-as-tasks: Treat each item as a separate model to learn
● Contexts-as-tasks: Treat different contexts (time, device, region, …)
as separate tasks
● Domains-as-tasks: Leverage representations of users in one domain
to help in another (e.g. different kinds of items, different genres)
○ Example: [Li et al., 2009] on movies <-> books](https://image.slidesharecdn.com/2019-06-recenttrendsinpersonalization-190616000611/85/Recent-Trends-in-Personalization-A-Netflix-Perspective-61-320.jpg)




The document discusses recent trends in personalization within Netflix's recommendation system, emphasizing the importance of personalizing content to enhance user satisfaction and retention. Key trends include the adoption of deep learning, causal analysis to mitigate feedback loops, and the use of bandits and reinforcement learning for improved long-term recommendations. Additional considerations involve ensuring fairness in recommendations and personalizing the user experience at various levels.



































































