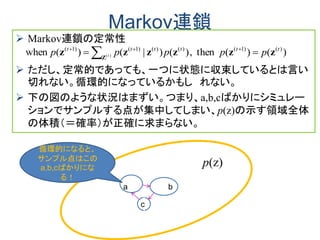
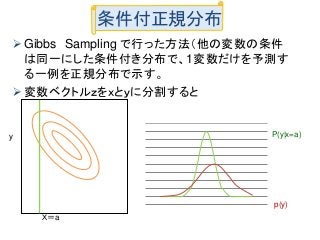
Sampling Gibbs
1
)|()|(
)|()|(
,1min
|)|(
|)|(
,1min
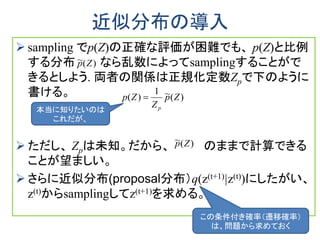
|)(
~
ˆ
|)(
~
ˆ
,1min),(
HastingMetroplis
)|()(
)|()(
)|(|
)|(|
z
)(
)(
)(
)(
)(
)(
)(
)(
)(
)(
)()(
)(
)(
)()(
)(
)(
)()(
)()(
)(
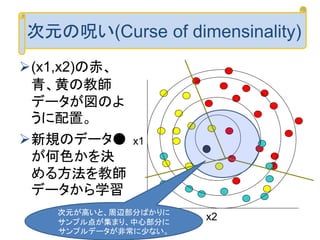
は常に採用されるよって、新規のデータ
法を書き換えるこれを利用して
に注意は固定されていることを更新するときには
k
t
k
new
k
new
k
new
k
t
k
new
k
t
k
t
k
t
k
new
tnew
kk
new
k
new
k
t
newt
kk
t
k
t
k
new
tnew
k
t
newt
k
new
tnew
k
k
new
k
new
k
tt
k
t
k
t
k
newnew
k
new
k
tnewt
k
k
t
k
newtnew
k
k
new
k
t
kk
zzpzpzzp
zzpzpzzp
zzqzpzzp
zzqzpzzp
zzqzp
zzqzp
zzA
zpzzpzp
zpzzpzp
zzpzzq
zzpzzq
z
z z



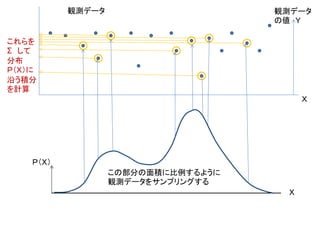
![Samplingによるシミュレーションを用いる局面
EM,VBでは以下の更新式を解析解として求めておき、
繰り返し計算を行うようになる。
繰り返し
P(Z,X| θold,M)argmaxθexp(E[logP(Z,X| θold,M)])でθを推定
この途中で行う期待値計算E[logP(Z,X | θold,M)])の中で
周辺化などの積分計算の解析解を求めることが困難
である場合は、その部分を期待値計算で用いる確率
分布p(Z)にかなうようにsamplingしたデータでシミュ
レーションによって計算する。](https://image.slidesharecdn.com/sampling1-140313100650-phpapp01/85/10-3-320.jpg)




































![[PRML] パターン認識と機械学習(第2章:確率分布)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter2-171002030018-thumbnail.jpg?width=640&height=640&fit=bounds)






















































